
基于交互式机器翻译的译文查询行文预测技术
2017-11-16 09:28:10杨倩倩秦旭明
电子科技 2017年11期
杨倩倩,秦旭明
(惠州工程职业学院,广东 惠州 5610000)
基于交互式机器翻译的译文查询行文预测技术
杨倩倩,秦旭明
(惠州工程职业学院,广东 惠州 5610000)
随着信息交流的密切,人工翻译工作量大,且收益较低,矛盾凸显。文中基于此背景以交互式机器翻译技术(IMT)为核心,针对各类用户翻译过程中查询调用行为出现的频繁鼠标、键盘切换问题,提出了一种交互机器替代的智能预测模型。此预测模型采用翻译条件选择机制,搭配对齐模型、翻译模型、语言模型等进行全面语义分析,在较大程度上保证了查词行为预测的可行性。经过测试,在人工双语对齐类语料中,预测准确性达64.99%,尤其在各类语义明确的名词类句段预测时,精确度可达72.28%。基于此种执行效率,机器交互翻译系统虽无法完全替代人工翻译过程,但可大幅减少重复、底层的劳动行为,使人从机械的操作中解放出来。在改善用户交互翻译体验的同时,大幅提升工作效率。
交互机器翻译;对齐模型;语言模型;翻译预测
近年来,由于大规模语料翻译需求的扩大,使得机器翻译的研究和应用得以快速发展,机译速度不断提升。然而,无论基于哪种翻译规则的机译系统均无法有效地解决模糊性语义和多重语境下,复杂语段的精准表达问题。导致机器翻译质量低下,无法满足人们研究和学习的要求。针对这种情况,国内外众多研究机构陆续开始深入研究机器翻译系统的改良与优化。
在此背景下,Kay最早提出了交互式机器翻译系统,由用户自己负责复杂类语段的内容定义,消除歧义,并确定语义走向[1-3]。随后由机器规则系统对照用户所提供的内容进行原文翻译,这样的工作方式使翻译质量得到较大提升,也使得翻译的自由度和使用范围更广。但该种工作方式只在某些特定的翻译应用中具备优势,而在大部分常规翻译需求中,译文质量参差不齐,无法保持一定水准的翻译精度。另外,消除语法歧义的工作对于翻译用户而言难度较高,尤其对陌生语种,缺乏实践操作的可行性[4-8]。
随后,研究逐渐从人机交互过程转移到了译文后编辑处理中来,期望通过人机整合来实现效率和质量的提升。虽国内外众多翻译交互系统为此提出了多种解决方案,如快捷键操作、切换设定等,却均不够完善[9-12]。因此,本文基于译文和原意的对齐关系,尝试进行查询操作的预测行为分析,在输入检测过程中预测可能出现的翻译结果,减少大量的人工对比与切换行为,实现高质、省时的文献翻译。
1 预测模型组建
文献翻译过程中,用户为保证翻译质量,经常要对单词进行译文释义对照查询,工作量大。若是对整个翻译过程建立模型,可将实现交互的抽象过程分化由大量的源语片段S=s1,s2,s3…sn,以及与之对应的一组中间参考语段T=t1,t2,t3…tn构成[13-14]。规定当前所处翻译位置为i,则理论上翻译选择概率为p(sj|i,T)。因此,对于原文语段的翻译可转化为对概率P值最大的最优化解答。
可由式(1)表示最大概率值。
sj=argsjmax(sj|iT)
(1)
若假设每一种语义出现概率相等,可由贝叶斯公式推得式(2)
sj=argsjmaxp(sj|i,T)=
argsjmaxP(T|i,sj)p(i|sj)p(sj)=
argsjmaxP(T|i,sj)p(i|sj)
ln(sj)=argsjmax(lnp(T|i,sj)+lnp(i|sj))
(2)
考虑到上式各乘积项对结果ln(sj)的影响不同,可进行加权(w)运算,得
ln(sj)=argsjmax(w×lnp(T|i,sj)+(1-w)lnp(i|sj))
(3)
以上为预测概率模型的建立。通过原语单词sj、中间译文T关系和目标语义的对齐概率求得最优解,即最佳翻译。然而,上述模型只分抽象出单一语段与其对应中间译文的相关概率,无法在实际复杂语义环境中使用,还需进一步优化。
1.1 语段对齐概率模型分析
在复杂语段中可能包含多个词性相同的词汇。因此,若要精确表述原语词汇sj翻译到位置i的翻译概率,需要进一步将位置参数引入概率估计条件中,即建立p(i│j,sj)概率计算。但进行此类位置多层叠加型翻译计算,将会导致严重的数据系数问题,同时模型复杂程度过高,影响计算效率。因此,文中转而采用对齐概率模型来进行较长语段的概率估计。
引入Toutanova等人提出的基于上下文词汇关联模型的传统化对齐模型统计算法,求得期望最大值,并将所有特征参量(词性、语义标记、多重语义、抽象意及歧义)等包含在特征函数中,可得
本文选取对案例地各特征带有明显情感描述的评论,共861条,采用“-5,-3,-1,1,3,5”的分值分别表示“严重不满”“比较不满”“轻度不满”“一般满意”“比较满意”和“非常满意” 6种不同情感,通过等权赋值对旅游者情感及强度进行评分,计算公式为:

(4)
其中,Z^是归一化常数,与T参量和S参量有关;λt为模型参量;ft为特征函数,其内参量由具体语义和句法进行定义。
此外,可以根据句法及翻译需求来进行模型模板定义。表1列出了部分特征模板所代表的元素或位置参量信息,称为原子模板,其在概念上等同于当前翻译位置下的各类特征函数。

表1 原子特征模板范例
需要注意的是,原子模板仅表征了特征函数的一个单一属性,无法完整表征语段的具体含义。因此,在实际应用中需要建立复合原子模板。通过模板的不同组合,将参量数值化后,得到具体的语义表征,即一个二值特征函数式
(5)
由于翻译内容的复杂性,单一的原子模板无法全面表征。因此,本文准备了40个以上的复合模板来应对实际语段内的复杂结构和多重释义的选择。
1.2 相关概率模型计算
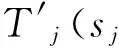
(6)
2 实验测试与分析
2.1 实验设置
首先,依据最大熵算法得出语料对齐概率模型,由式(6)得到相关概率模型。综合两式,取0.05等间隔下[0,1]间任意3个候选值,评分机制参考MRR(Mean Reciprocal Rank)定义如下
其中,Sh指代候选数量;Q指代当前译文;Ri指代翻译候选;n指代译文预测的数目;Scorrect(Ri)指代正确候选的位置; RR(Ri)指代当前位置的得分。
2.2 实验结果及数据分析
2.2.1 权值概率分析
数据预测正确率,如图1所示。权值[0,1],预测正确率峰值对应w=0.15,准确率达65,27%,MRR评分趋于54.23%,同步达到最大值点。

图1 预测正确率曲线和对应MRR
分析图中曲线可得,当w=0时,即仅当对齐模型存在时,翻译精确率为64.99%;当w=1取最大值,此时只存在相关概率模型,正确率降为25.32%。当两种概率模型混合存在时,正确率在峰值处提升了0.82个百分点,且整体正确率会随着相关概率模型权值的增加而降低。
2.2.2 语段词性的预测与分析
图2中列举了人工翻译对照的汉英双语材料中各类词性语段占比,明显看出名词与动词占有绝大部分比重。

图2 语段中各类词性占比
图3给出了语料库中各常用词性单词的预测正确率,从中可以看出:实词正确率最高。而通常语料中名词与动词占比最大。因此,基于这种语料查询预测方式下翻译质量将得到较大提升。而实验结果显示,影响实词翻译正确率(名词72.28%,动词63.7%)的主要因素在于:其他词性的单词翻译依据相关模型预测,而模糊翻译将降低翻译准确率。

图3 各类词性正确率
3 结束语
本文以文献翻译过程的词义转化作为研究对象,引用交互式机器翻译方式进行语段翻译结果的可能性分析,通过建立对齐模型进一步提升复杂语段翻译的准确率。与传统的上下文预测方式相比,基于对齐模型和相关概率模型的预测法可有效缩小中间参量范围,提高模型翻译效率及预测准确率。同时,本文充分考虑了语段翻译存在的特征选择性,将其加入到翻译模型产量中,并以Niutrains语料库做了全面的实验分析。实验结果表明,名词、动词性语段为主的语料翻译质量较高,达72.28%,其他词性单词的翻译准确率相对较低。据此还可进行下一步的研究与模型改良,实现语料翻译质量的再提升。
[1] Kay M.The proper place of men and machines in language translation[J].Machine Translation,1997,12(1/2):3-23.
[2] Foster G,Isabelle P,Plamondon P.Target-text mediated interactive machine translation[J].Machine Translation,1997,12(1/2):175-194.
[3] Simard M,Ueffing N,Isabelle P,et a1.Rule—based translation with statistical phrase—based post—editing[C].Stroudsburg:Proceedings of the 2nd Workshop on Statistical Machine Translation,Association for Computational Linguistics,2007.
[4] Foster G,Langlais P,Lapalme G.User-friendly text pre-diction for translators[C].Stroudsburg:Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing,Association for Computational Linguistics,2002.
[5] Koehn P,Haddow B.Interactive assistance to human translators Using statistical machine translation methods[C]. Menlo Park: Proceedings of AAAI Conference on Artificial Intelligence,2011.
[6] Hassan S,Mihalcea R.Semantic relatedness using salient semantic analysis[C].Menlo Park:Proceedings of AAAI Conference on Artificial Intelligence,2011.
[7] Sanchis-Trilles G,Ortiz-Martinez D,Civera J,et a1.Improving interactive machine translation via mouse actions[C].Stroudsburg:Proceedings of the Conference on Empirical Methods in Natural Language Processing,Association for Computational Linguistics,2008.
[8] Toutanova K,Ilhan H T,Manning C D.Extensions to HMM-based statistical word alignment models [C].Stroudsburg:EMNL 2002:Proceedings of the ACL_02 Conference on Empirical Methods in Natural Language Processing,Association for Computational Linguistics,2002.
[9] Langlais P,Lapalime G.Trans type: development-evaluation cycles to boost translator’s productivity[J]. Machine Translation,2002,17(2):77-98.
[10] 张华.交互式机器翻译技术研究[D].沈阳:沈阳航空航天大学,2014.
[11] 付一韬.基于正向多约束的交互式机器翻译技术研究[D].沈阳:沈阳航空航天大学,2016.
[12] 程善伯.短语翻译系统中的交互翻译研究[D].南京:南京大学,2016.
[13] 季铎,马斌,叶娜.交互式机器翻译中译文查询行为的预测技术[J].计算机应用,2015,35(4):1009-1012.
[14] 庞观松,张黎莎,蒋盛益.跨语言智能学术搜索系统设计与实现[J].山东大学学报:工学版,2011,41(5):63-68.
Research on the Technology of Text Query Based on Interactive Machine Translation
YANG Qianqian,QIN Xuming
(Huizhou Engineering Vocational and Technical College,Huizhou 5610000,China)
Nowadays,the exchange of information is very close,and the translation and inquiry of documents become the high frequency behavior in the process of research and study. However,the workload of manual translation is too large,and the income is low. Based on the background of interactive technology to Machine Translation (IMT) as the core,to solve the problem of frequent switching behavior of mouse and keyboard call query all kinds of users in the translation process,put forward a prediction model of intelligent interactive machine replacement. This prediction model is based on the translation condition selection mechanism,with the alignment model,the translation model and the language model. After testing,the accuracy of prediction is 64.99%,which is more than 72.28%,especially in all kinds of semantic NOUN class. Based on the efficiency of the system,the system can not completely replace the manual translation process,but it can greatly reduce duplication,the bottom of the labor behavior,so that people from the mechanical operation of the liberation. While improving the user interaction translation experience and greatly improve work efficiency.
interactive Machine Translation; alignment model; language model; translation prediction
TP391.7
A
1007-7820(2017)11-110-04
2017- 05- 10
杨倩倩(1983-),女,讲师。研究方向:英语翻译。
10.16180/j.cnki.issn1007-7820.2017.11.030
猜你喜欢
中学生数理化·高一版(2021年3期)2021-06-09 06:10:16
新世纪智能(高一语文)(2020年5期)2020-07-24 08:27:10
教育文汇(综合版)(2020年4期)2020-06-15 11:34:42
电子测试(2018年10期)2018-06-26 05:53:50
海外华文教育(2016年1期)2017-01-20 08:21:58
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
中学生数理化·中考版(2015年10期)2015-09-10 07:22:44
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
外语学刊(2011年1期)2011-01-22 03:38:24
