
FusionCache: 采用闪存的iSCSI存储端融合缓存机制
2017-11-08 02:22孟祥辉曾学文叶晓舟
哈尔滨工业大学学报 2017年11期
孟祥辉, 曾学文, 陈 晓, 叶晓舟
(1.中国科学院声学研究所 国家网络新媒体工程技术研究中心, 北京100190; 2.中国科学院大学, 北京 100049)
FusionCache: 采用闪存的iSCSI存储端融合缓存机制
孟祥辉1,2, 曾学文1, 陈 晓1, 叶晓舟1
(1.中国科学院声学研究所 国家网络新媒体工程技术研究中心, 北京100190; 2.中国科学院大学, 北京 100049)
针对原生的iSCSI目标端控制器缺乏独立的缓存模块问题,为了进一步提高存储区域网的整体性能,在iSCSI target软件中引入了一种基于闪存的融合缓存机制FusionCache. FusionCache利用闪存和DRAM组成统一的融合缓存架构,闪存充当DRAM的扩展空间,DRAM分为缓存块元数据区和前端缓存区. 元数据区基于基数树管理缓存块元数据,用于加速缓存块的查找;前端缓存区基于回归拟合统计并预测缓存块访问热度,并吸收大量写入对闪存带来的冲击,只允许热点数据进入闪存. FusionCache采用改进的LRU算法对缓存块进行替换,并且在写回过程中考虑iSCSI会话状态. 实验结果表明:FusionCache能降低对后端磁盘设备的访问频率,提高I/O响应的速度和吞吐. 与只采用DRAM的缓存机制以及原生iSCSI target相比,FusionCache的I/O访问延时分别降低了33%和60%,吞吐分别提高了25%和54%;相较于Facebook提出的Flashcache机制,FusionCache的吞吐性能提高了18%,延时降低了27%;FusionCache还具有良好的读缓存命中率;此外,FusionCache能够减少闪存的写入次数,提高闪存使用寿命. FusionCache提供良好的网络存储效率,并且降低了使用成本.
网络存储性能;缓存机制;iSCSI target;闪存
近年来存储介质技术的进步和个人云存储业务的迅速发展,使得网络存储系统再次成为学术界和工业界研究的热点,存储区域网(Storage Area Network,SAN)是解决数据密集型应用I/O性能瓶颈的重要手段,其中IP SAN采用iSCSI[1]协议. 在云计算和大数据时代,海量的网络数据尤其是视频流量爆炸性增长给存储系统带来了巨大的挑战. 如何在大规模和高负载的应用环境下,进一步提高网络存储系统的性能成为亟待解决的问题.
作为网络存储系统的一个重要部分,缓存系统一直以来是存储领域提高性能需要研究的关键课题. 文献[2-3]利用本地磁盘缓存远端目标设备上的数据,来降低访问延时,减轻存储服务器的负载. 然而,磁盘性能受限,固态硬盘(Solid State Drive, SSD)等基于闪存的设备更适合用作网络存储的缓存. 文献[4-5]利用 SSD作为内存的补充来构建主机端的高速缓存架构,并在网络存储环境下,针对SSD缓存提出几种不同的改进cache策略,其性能提升比磁盘缓存优势明显;在云架构中,文献[6-7]利用SSD缓存提高虚拟机(Virtual Machine,VM)环境中的存储性能.
以上研究大多是基于客户端缓存进行研究,很少对iSCSI target(即IP SAN的存储端)软件进行优化. 文献[8-9]基于iSCSI target端,从网络设备[8]缓存和NUMA节点[9]缓存的角度进行研究,但并未利用到高速的闪存设备进行加速. 文献[10-12]在存储端利用闪存构建高速缓存架构,保证响应时间的同时提高闪存设备的寿命,是针对操作系统通用块层或者文件系统级的优化,而iSCSI target控制器软件本身依然缺乏独立的缓存模块. 相关工作都是从iSCSI target软件之外的角度进行研究,很少关注iSCSI target软件本身. 针对以上问题,为进一步提高SAN的整体性能,本文为iSCSI target控制器软件提出独立缓存模块,即基于闪存的iSCSI存储端融合缓存机制FusionCache. 与先前工作最大的不同是本文考虑iSCSI target自身的处理特征,着重研究为iSCSI target软件引入基于闪存的缓存机制. FusionCache利用闪存和DRAM共同构成统一的块I/O缓存空间,闪存作为DRAM的扩展,而非传统的第二级缓存. DRAM划分为两个区间,分别用于快速查找缓存块和提高闪存耐久性. 闪存的缓存空间利用改进的最近最少使用(Least Recently Used, LRU)原则组织. FusionCache能降低对后端磁盘设备的访问频率,提高I/O响应的速度和吞吐.
1 缓存架构
传统使用SSD闪存的方法,一般把SSD当作二级缓存,或者SSD与HDD构成混合存储,对DRAM不命中的请求再下发到SSD,但两级缓存的请求访问模式有很大不同. 本文考虑到这一点,在设计系统架构时,把SSD当作DRAM的扩展空间,DRAM空间有限,还要保证对缓存命中与否的快速判断,所以只把缓存块(Cache Block)元数据单独存放在DRAM,SSD存储缓存块内容. DRAM与SSD联合构成完整的缓存空间,对后端设备表现为统一缓存,并对客户端透明.
iSCSI Enterprise Target(IET)控制器软件分为用户层和内核层,对数据的处理工作大部分在内核层完成. IET以block I/O(即bio)的形式对I/O请求进行处理,不经过虚拟文件系统以及Linux Page Cache,软件本身没有针对block I/O的缓存模块. IET对用户请求的封装结构为tio(即target I/O),因此需要在请求递交给通用块层之前截获tio,并根据提出的缓存策略对请求进行处理.
基于以上考虑,在IET软件中提出的FusionCache架构见图1. IET软件本身包括3个组件:NTHREAD,WTHREAD和iSCSI Response, WTHREAD负责iSCSI数据(即tio)的读写流程,因此FusionCache最适合嵌入在WTHREAD中. 提出的缓存架构中,tio解析模块负责提取出目标数据的位置信息,包括目标扇区和对应的内存地址;DRAM管理模块负责管理DRAM上的metadata cache和front cache的空间;SSD管理模块对闪存上的缓存块进行组织管理;LRU链表使用改进的LRU算法对缓存块进行替换;bio构造模块根据缓存策略向通用块层发出bio请求.
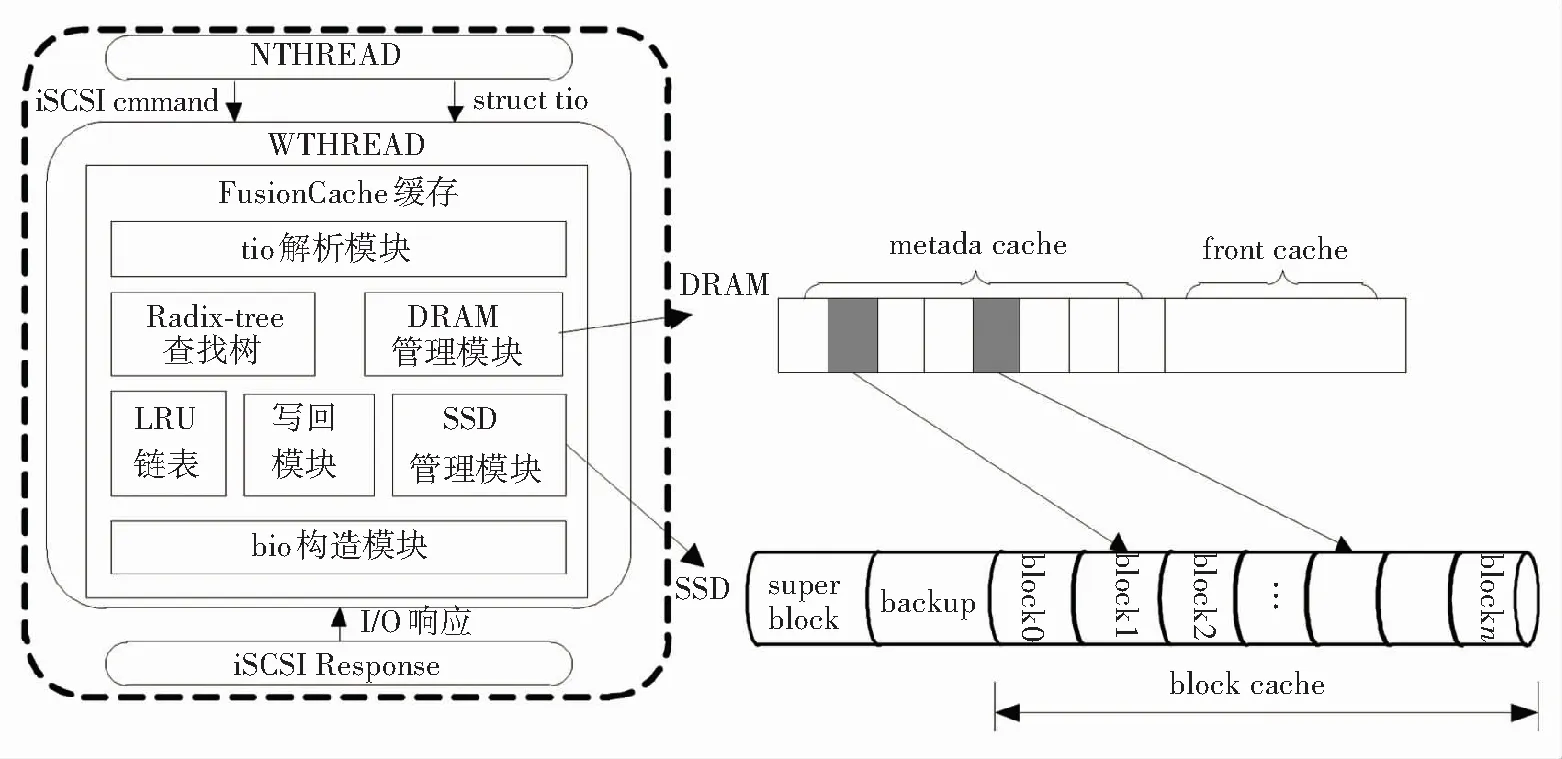
图1 IET缓存系统架构
2 设计与实现
2.1DRAM中的缓存设计
DRAM缓存空间包括metadata cache和front cache,前者管理缓存块元数据,后者担当SSD的前端,对进入SSD缓存的数据进行筛选.
1) metadata数据结构
为保证缓存算法的有效性和一致性,metadata数据结构须至少包含以下信息,见图2.
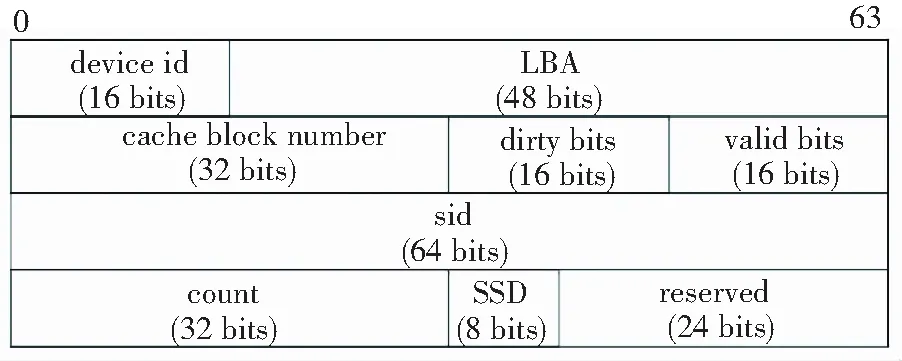
图2 metadata数据结构
元数据中每个字段代表的含义如下:
device id: 标识每一个后端磁盘设备或者LUN(Logic Unit Number);
LBA:即Logic Block Address,代表逻辑数据块block在一个LUN内的偏移或者编号;
cache block number: 标识SSD上一个缓存块的位置或者编号;
dirty bits: 脏数据标记,默认情况下每个缓存块包含16个扇区. 一个扇区在缓存中被修改而尚未同步到磁盘上时则为dirty(脏)状态,对应的dirty位为1,反之对应的clean状态为0. 16个扇区对应16个dirty位,只要有一个扇区为dirty,则该缓存块也为dirty.
valid bits: 与dirty bits类似,每一个bit代表缓存块中的一个扇区是否有效,1代表有效. 考虑到某个请求对齐到磁盘逻辑块之后可能不满一个block块大小,部分扇区的读写则无意义,所以用valid bits标识有效数据,以免不必要的读写.
Sid:标识一个iSCSI会话,用于辅助write back过程;
count: 缓存块访问计数,用于热度预测;
SSD:标识当前缓存块是否在SSD上,因为在某个短暂时间内缓存块可能在front cache中;
reserved: 预留位,方便后续扩展功能.
2) 基于radix tree的缓存查找
考虑到hashtable存在冲突的情况,一旦冲突需要二次查找,而且hashtable的大小是固定值,不容易确定. FusionCache基于radix tree快速查找闪存中的缓存块. 此外,radix tree支持并行查找操作,可以方便地在多核平台上进行扩展和优化.
FusionCache根据16bits的device id和48bits的 LBA构成一个64bits的变量index,并以此index作为查询的索引. 因此,radix tree保存了目标逻辑块地址和缓存块元数据的映射关系. 图3表示一个简化的查询过程.
假设index的高位全为0,低18位有效,每6位一组. 树高度为3,每个节点slot数量为64. 对于index1,高位000 000对应第一层的第0号slot,001 000对应第二层的第8号slot,低位010 000对应第三层的第10号slot,叶子节点对应一个缓存块元数据,其index索引值即为528.
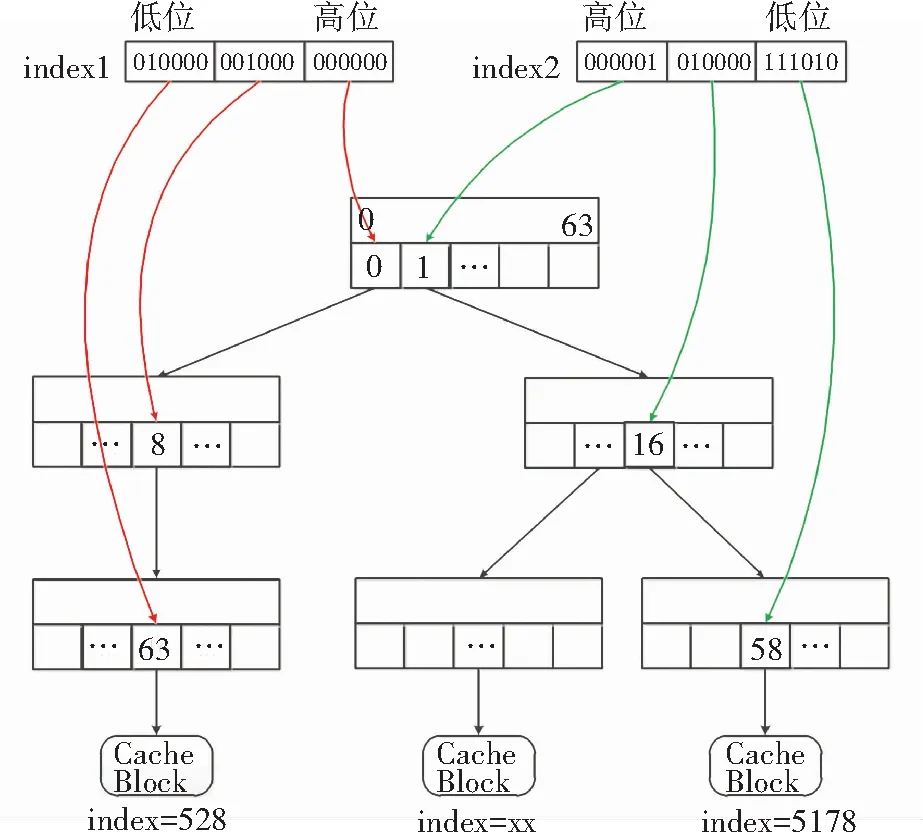
图3 radix tree查询过程
3) 基于回归拟合的热度预测
由于SSD的写入寿命有限,需要考虑减少写入和擦除带来的损耗. FusionCache使用内存中的一个区间构成front cache,担当SSD的前端来吸收大量写入带来的冲击. 所有的缓存数据首先要进入front cache,当front cache填满之后,根据metadata中的count信息统计其中缓存块的热度,并预测缓存块在未来被访问的概率. 只有热点数据才进入SSD,冷数据直接写入后端磁盘.
相关研究表明,存储设备中的文件热度与访问情况之间符合Zipf分布[13]. 即存储设备上的N个文件依据热度(访问频率)降序排序,则第k个文件的访问频率为C/k1-θ,参数C为
C=1/(1+1/2+1/3+…+1/N).
此即为Zipf分布定律
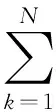
(1)
式中Z(k)为第k个文件被访问的概率. Zipf分布表明,在一段时间内,热度越高的文件被再次访问到的概率也越高. 文件的访问热度等于其所有数据块的热度,Zipf定律同样适用于数据块.
设缓存块bi的热度为hi(t)=mi(t)/N,其中mi为时间t之前缓存块bi的访问次数,N为所有缓存块的总的请求次数.
由于访问热度会随着时间动态改变,下一时刻的热度需要根据历史统计信息进行预测. 本文采用基于回归拟合的方法对缓存块的热度进行预测,具有较高的精度,而且复杂度较低. 根据预测结果对front cache中的缓存块进行预判,热度低的数据不允许进入SSD.

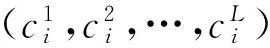
鉴于预测精度和计算量的均衡,相关研究表明周期数L在5~10之间比较合适[13]. 由于在L=5~10之间时,访问热度不会大幅波动,同时为了减少回归拟合计算的负担,选择二次回归便可以实现较高的预测精度.
FusionCache的一元二次回归模型为
服从N(0,σ2).
(2)
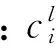
ε.
(3)
其系数矩阵为T
(4)
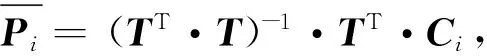

(1,(L+1),(L+1)2)·(A·Ci),
(5)
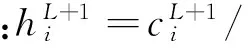
根据以上对访问热度的统计和预测,设定一个热度阈值Hthreshold,对front cache缓存块划分两个队列q1,q2:
q1中的数据写入到SSD,q2中的数据直接写到后端磁盘.
2.2闪存中的缓存设计
2.2.1 闪存数据布局
如图1所示,SSD可以划分为3个区域,分别为superblock区,metadata backup区,以及存放缓存块的cache block区. 其中,superblock是整个SSD缓存的“元数据”,保存SSD缓存的配置信息,比如缓存使用情况、缓存块大小等. backup区是DRAM中metadata cache的备份,保证缓存数据的非易失性或者持久性,在服务器故障重启时,凭借SSD中的metadata备份即可恢复原有的缓存数据到DRAM中,不需要从后端磁盘重新读取重复数据. Cache block区则存放实际的缓存块.
缓存操作的基本单位是cache block,如果设置太小,则缓存块元数据会占据太多空间;如果block太大,则算法精度会降低,算法会失真. 不同的应用场景,I/O访问模式不同,即便是同样的数据库应用,I/O大小也会变化. 因此缓存块大小的设定没有普适性的值. Flashcache和dm-cache的默认缓存块大小为4K,SQL Server和Oracle默认的块大小都是8KB. 本文默认使用8K大小的缓存块,占用两个内存page,有利于数据预读和减小元数据所占空间. 当然,也可以根据特定应用场景的I/O访问模式自定义缓存块大小并保存到superblock中.
2.2.2 改进的LRU算法
SSD缓存根据数据访问的时间局部性原则,不仅考虑缓存块上一次访问的时间,同时结合前文所述的访问热度进行缓存替换.
进入SSD的缓存根据热度分为3个级别:hot(热点数据),warm(暖数据)和cold(冷数据),算法分别使用3个不同级别的LRU队列(Qhot,Qwarm,Qcold)管理对应的cache数据,见图4.
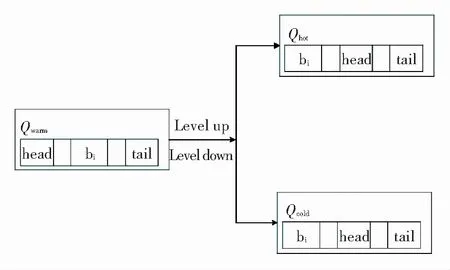
图4 改进的LRU
热度高的队列中cache 比热度低的队列cache 块生存时间更久,Qwarm和Qcold队列中的 cache块被命中时,则分别将其升级到更高一级队列中,Qhot和Qwarm队列中cache块在一段时间内没有被命中则会降级到更低一级的队列中. 当SSD缓存空间用尽发生替换时,只在Qcold中进行,不需要DRAM的cache信息进行判断. 所以,cache块的访问频率能够在不同级别的 LRU队列得到体现.
2.2.3 write-back过程
iSCSI协议允许initiator和target之间建立多个会话,每个会话允许使用多个连接. 所以,SSD缓存块的写回过程应该考虑会话状态.
SSD缓存空间较大,发生写回的频率较低,cold数据可能较长时间停留在SSD缓存,尤其是一个会话结束以后,相应的缓存块应该被写回到磁盘上. 因此,write-back策略根据metadata中的sid判断缓存块是否属于一个结束的会话,然后把属于已经结束的会话的全部缓存块都写回到磁盘. 若缓存已满,需要发生替换时,首先需要检查被替换的缓存块的dirty bits,对于dirty的缓存块应立即写回磁盘再替换,而clean状态的缓存块可以立即替换.
2.3读写流程
图5展示了读请求的处理流程,写过程与读相似. 需要注意的两点:一是无论对SSD缓存命中与否,都需要构造bio请求,因为对SSD和HDD磁盘的访问都属于块请求;二是无论是读还是写过程,都需要图5左下角的写前端缓存区过程,右半部分虚线框内为写前端缓存区子过程.
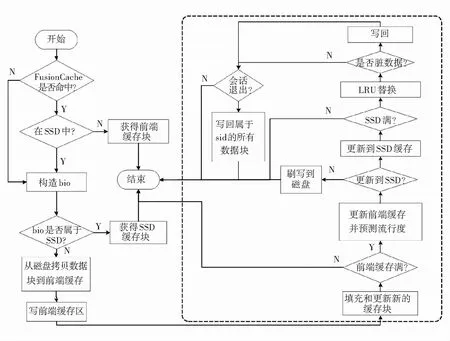
图5 缓存读流程图
当一个读请求到达target端,FusionCache首先检查是否命中缓存,若命中则存在两种可能:命中的缓存在front cache,则cache block将立即返回;命中的缓存在SSD中,则需要构造到SSD的bio请求,然后返回相应的cache block. 若未命中,则需要构造到HDD的bio请求,然后缺失的cache block会从HDD拷贝到front cache,即写前端缓存区过程:首先分配一个新的cache block并填充相关数据,若front cache此时未满则此次请求处理结束,继续处理其他请求;若front cache已满,则启动上述基于回归拟合的热度预测算法. 根据算法结果,热数据移动到SSD,冷数据直接进入HDD. 之后检测SSD状态,若SSD未满则此子过程返回;若SSD已满,则利用改进的LRU替换策略驱逐Qcold中的cache block. 在驱逐cache block时,FusionCache同时考虑dirty位状态和iSCSI会话状态. 若dirty位被置1,被驱逐的cache block须先同步到HDD;若检测到某个会话已经logout,那么所有属于该会话的cache block将会被写回到HDD.
3 实验与分析
使用IOMeter测试FusionCache性能,作为对比,测试原生的以及只使用内存DRAM作为缓存的iSCSI target,同时对比Facebook开源的Flashcache在iSCSI target端的表现. 此外,使用两种实际应用场景负载记录(workload trace)进行测试,I/O trace分别为Websearch[14]和Ads[15]. 测试环境见表1.

表1 测试环境配置
客户端上IOMeter测试结果见图6. 图6(a)展示几种机制在不同I/O请求块大小的吞吐性能,原生的IET默认块大小4K,所以在请求大小为4K时性能最高,只使用DRAM做缓存和使用FusionCache的IET默认块大小都是8K,所以请求大小在8K左右性能最高,继续增大块大小不会提高性能. FusionCache相对原生IET和只使用DRAM的缓存提升分别为54%和25%左右,比Flashcache提高18%左右. 由于SSD空间远大于DRAM,所以Flashcache的平均性能要稍好于FusionCache架构中只使用DRAM的情况.
图6(b)显示,随着请求块大小成倍增大,I/O平均响应时间整体呈指数上升. 集成缓存模块的IET,允许I/O请求在缓存中获得请求数据而无须到磁盘请求,所以响应时间大大缩短;但是DRAM空间不大,缓存的数据量有限,而SSD缓存的空间增大几十倍甚至上百倍,进一步减少了请求磁盘的次数. FusionCache相对原生IET和只使用DRAM的缓存带来的延时减少分别为60%和33%左右,比Flashcache减少27%左右.
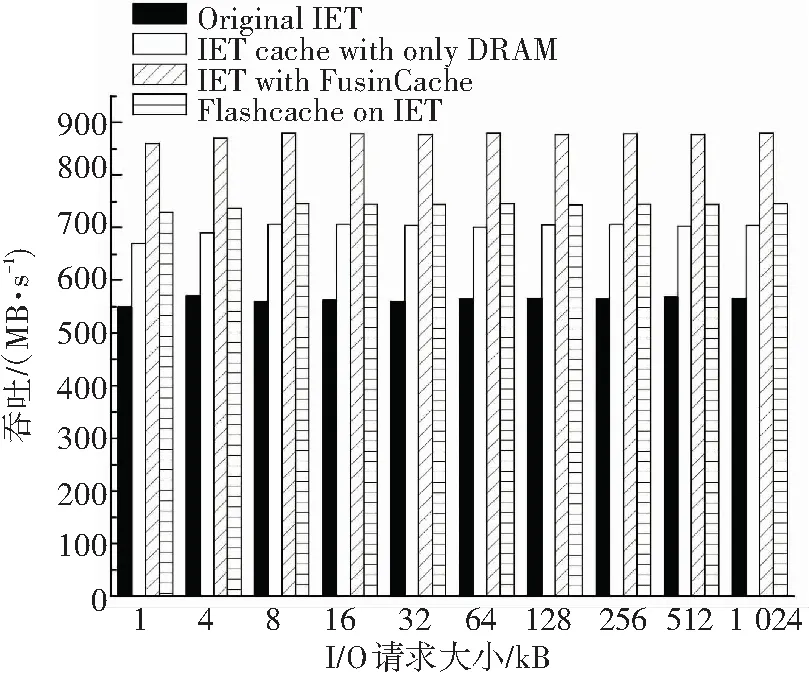
(a)吞吐量
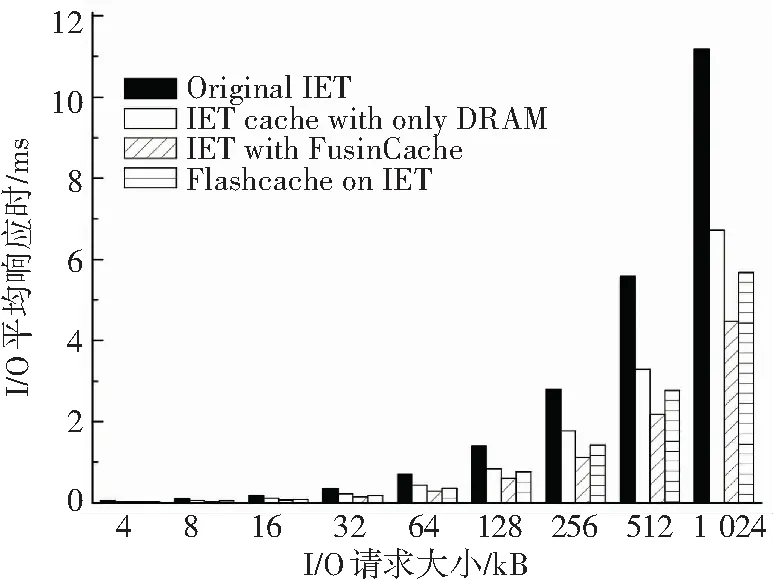
(b)延时
此外,以4 K,8 K,16 K请求大小对存储系统连续写入1小时(顺序),并统计对SSD的写入次数,以验证对SSD寿命的影响. 结果见图7,front cache减少了30%左右的SSD写入次数,因此可以提高SSD使用寿命,能够降低成本.
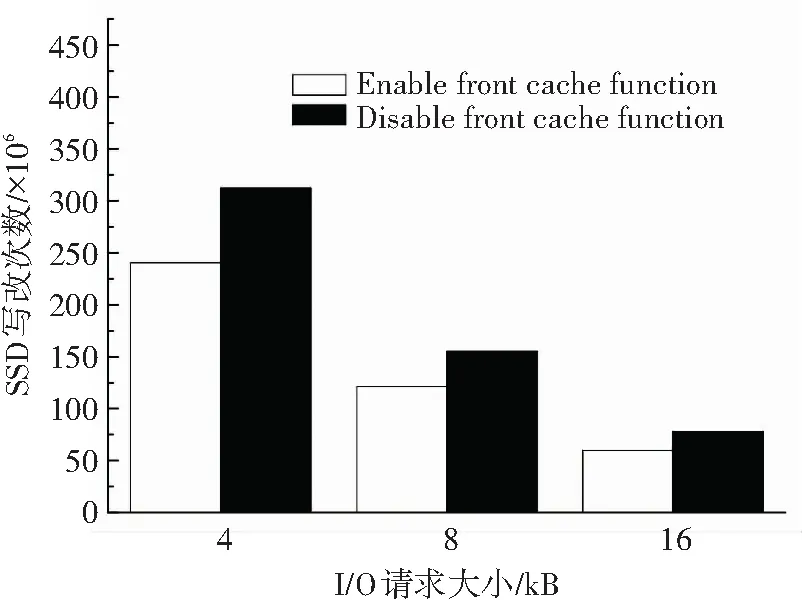
图7 SSD写入次数
为了测试稳定状态下Websearch和Ads两种traces负载下的缓存命中率和I/O吞吐,先使两个traces各自运行一小时再记录数据,以跳过缓存的热身(warm up)阶段,结果见图8. 图8(a)显示, 在两种trace下,FusionCache的读缓存命中率比只使用DRAM的分别提高30%和35%左右.
图8(b)显示,FusionCache的I/O吞吐在Websearch trace下,比原生IET和只用DRAM的方法分别提高60%和23%左右;在Ads trace下,FusionCache比另外两种方法分别提高54%和21%左右.

(a)缓存命中率
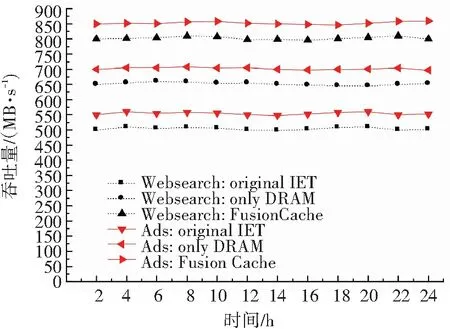
(b)I/O吞吐
4 结 论
本文针对IET控制器软件缺少独立缓存模块的问题,提出一种采用闪存的融合缓存机制FusionCache. FusionCache利用闪存和内存(DRAM)组成统一的融合缓存架构,闪存充当DRAM的扩展空间. 基于基数树(radix tree)管理缓存块元数据,用于加速缓存块的查找;基于回归拟合统计并预测缓存块访问热度,只允许热点数据进入闪存. 闪存采用改进的LRU算法对缓存块进行替换,并且在写回过程中考虑iSCSI会话状态. 实验结果表明,与其他方法相比,无论是采用IOMeter还是实际应用场景负载测试,其性能都要更好.
[1] SATRAN J, METH K, SAPUNTZAKIS C, et al. Internet Small Computer Systems Interface (iSCSI) [EB/OL]. (2004-04-27). https://www.ietf.org/rfc/rfc3720.txt.
[2] HENSBERGEN E V, ZHAO Ming. Dynamic policy disk caching for storage networking: IBM Research Report RC24123 [R].USA:IBM,2006.
[3] 尹洋, 刘振军,许鲁. 一种基于磁盘介质的网络存储系统缓存 [J]. 软件学报, 2009,20(10): 2752-2765.
YIN Yang, LIU Zhenjun, XU Lu. Cache system based on disk media for network storage[J].Chinese Journal of Software, 2009,20(10): 2752-2765.
[4] BYAN S, LENTINI J, MADAN A, et al. Mercury: Host-side flash caching for the data center [C]// IEEE Symposium on Mass Storage Systems and Technologies. Pacific Grove, CA: IEEE Publisher,2012: 1-12.
[5] KOLLER R, MARMOL L, RANGASWAMI R, et al. Write policies for host-side flash caches [C]// USENIX Conference on File and Storage Technologies. San Jose, CA: USENIX Publisher,2013: 45-58.
[6] ARTEAGA D,ZHAO Ming. Client-side flash caching for cloud systems [C]// Proceedings of International Conference on Systems and Storage. Haifa, Israel:ACM Publisher, 2014:1-11.
[7] KOLLER R, MASHTIZADEH A J, RANGASWAMI R. Centaur: Host-side SSD caching for storage performance control[C]// IEEE International Conference on Autonomic Computing.Grenoble:IEEE Publisher,2015: 51-60.
[8] WANG Jun, YAO Xiaoyu, MITCHELL C, et al. A new hierarchical data cache architecture for iSCSI storage server[J]. IEEE Transactions on Computers, 2009,58(4): 433-447.
[9] REN Y, LI T, YU D, et al. Design, implementation, and evaluation of a NUMA-aware cache for iSCSI storage servers[J]. IEEE Transactions on Parallel and Distributed Systems, 2015,26(2): 413-422.
[10]SUEI P L, YEH M Y, KUO T W. Endurance-aware flash-cache management for storage servers[J].IEEE Transactions on Computers, 2014,63(10): 2416-2430.
[11]HUO Zhisheng, XIAO Limin, ZHONG Qiaoling, et al. A metadata cooperative caching architecture based on SSD and DRAM for file systems[C]//International Conference on Algorithms and Architectures for Parallel Processing. Zhangjiajie: Springer Publisher, 2015: 31-51.
[12]LIU Yi, GE Xiongzi, DU D H, et al. SSD as a cloud cache? carefully design about it[J].Taiwan Journal of Computers,2016,27(1): 26-37.
[13]SHANG Qiuli, ZHANG Wu, GUO Xiuyan, et al. An energy-saving scheduling scheme for streaming media storage systems[J].High Technology Letters, 2015,21(3): 347-357.
[14]MCNUTT B, BATES K. Umass trace repository: search engine I/O[EB/OL]. (2007-06-01). http://traces.cs.umass.edu/index.php/Storage/Storage.
[15]KAVALANEKAR S,WORTHINGTON B,ZHANG Qi, et al. Characterization of storage workload traces from production Windows servers[C]//IEEE International Symposium on Workload Characterization. Seattle:IEEE Publisher, 2008:119-128.
FusionCache:AFusionCacheMechanismforiSCSITargetBasedonFlashMemory
MENG Xianghui1,2, ZENG Xuewen1, CHEN Xiao1, YE Xiaozhou1
(1.National Network New Media Engineering Research Center, Institute of Acoustics, Chinese Academy of Sciences, Beijing 100190, China; 2.University of Chinese Academy of Sciences, Beijing 100049, China)
Focusing on the problem of lack of independent cache module of original iSCSI target controller, we introduce a fusion cache mechanism based on flash memory called FusionCache into the iSCSI target software to further improve the overall performance of the storage area network. FusionCache uses flash memory and DRAM to form a unified fusion cache architecture. The flash memory acts as DRAM’s expansion space, and DRAM is divided into cache block metadata area (metadata cache) and front-end buffer area (front cache). The metadata cache manages cache block metadata based on radix tree in order to accelerate the cache block searching; the front cache tallies and predicts the access popularity of the cache block based on regressing fitting model, and absorbs the impact of massive writes on flash memory to ensure that only the hot data is allowed to enter the flash memory. FusionCache uses the improved LRU algorithm to do cache replacement. Besides, it takes iSCSI session’s state into account during write-back. The experimental results show that: FusionCache is able to reduce access to backend disk devices, and improve I/O response speed. FusionCache reduces I/O access latency by 33% and 60%, and improves throughput by 25% and 54%, compared to cache mechanism with only DRAM and original iSCSI target, respectively. Compared with Flashcache proposed by Facebook, FusionCache improves throughput by 18% and reduces latency by 27%. FusionCache also has a good read cache hit rate. Besides, FusionCache reduces write amount of flash memory, thus extends its life. FusionCache provides good efficiency of network storage and reduces cost.
network storage performance; cache mechanism; iSCSI target; flash memory
10.11918/j.issn.0367-6234.201701022
TP393
A
0367-6234(2017)11-0066-07
2017-01-05
中国科学院战略性先导科技专项课题(XDA06010302),中科院创新研究院前瞻项目(Y555021601)
孟祥辉(1990—),男,博士
叶晓舟,yexz@dsp.ac.cn
(编辑苗秀芝)
猜你喜欢
石材(2022年4期)2022-06-15
南北桥(2022年2期)2022-05-31
电脑爱好者(2020年18期)2020-09-26
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
电脑爱好者(2019年2期)2019-10-30
军营文化天地(2018年2期)2018-12-15
信息安全研究(2018年2期)2018-02-28
电脑知识与技术·经验技巧(2017年9期)2018-02-24
产品可靠性报告(2017年7期)2017-09-05
