
基于粒子群聚类的KNN微博舆情分类研究
2017-11-03 08:27:30林伟
中国刑警学院学报 2017年5期
林 伟
(福建警察学院侦查系 福建 福州 350007)
基于粒子群聚类的KNN微博舆情分类研究
林 伟
(福建警察学院侦查系 福建 福州 350007)
基于数据挖掘的微博情感分类是网络舆情监控的重要方法,其中KNN算法具有简单有效、无需估计参数等优点,适用于微博舆情分类。微博舆情分类实质上是对微博上的负面情感及时监控,KNN会因在情感分类时处理大量的计算影响算法效率。因此,采用粒子群聚类算法在情感分类前裁剪微博训练样本空间,以减少分类时的计算量。实验结果表明,基于粒子群聚类的KNN算法能够有效提高微博情感分类的性能。
KNN 微博情感分类 特征选择 粒子群聚类
随着互联网和通讯技术的发展,人们在网络虚拟空间中呈现出的情感倾向、互动交流等往往是现实社会的延伸,涉及道德、民生、贪腐等民众关注的热点敏感话题信息极易被网络催生和激化,将矛盾放大、以点概面、以偏概全形成各类攻击,具有强大的蛊惑和煽动力,导致矛盾升级进而影响社会稳定[1]。据第38次《中国互联网络发展状况统计报告》显示,截至2016年9月,我国微博用户月活跃数3.906亿,日活跃数1.05亿,人均月使用次数52次,微博在追踪热点、发表热点评论、关注兴趣话题等方面都是用户的首选平台[2]。为此,通过数据挖掘算法对微博进行情感分类及时监控网络上带有煽动、攻击等“负面”言论,进而掌握舆论导向,具有重要的现实意义[3]。
在数据挖掘领域,常用的分类算法有:K最近邻(KNN)、贝叶斯、支持向量机及神经网络等,其中KNN算法具有简单有效、无需估计参数等优点,适用于类似微博舆情这样样本容量比较大的类域的分类。然而,微博舆情分类实质上是对微博上的“负面”情感及时监控,KNN会因在情感分类时处理大量的计算影响算法效率。因此,本研究中将采用粒子群聚类算法在情感分类前裁剪微博训练样本空间,以减少分类时的计算量。
1 相关工作
1.1 特征选择
为降低特征空间维数及计算量、防止数据过份拟合,应从微博训练集的原始特征空间中按照一定的评估函数筛选出对情感分类贡献较大的前N个特征子集,即特征选择。文献[4]对文本分类领域常见的几种特征选择算法进行了详细比较,指出信息增益(IG)和卡方统计(CHI)表现最好,因此本研究用信息增益做为特征选择的评估函数。
信息增益是通过计算某特征词t出现前后的信息熵来衡量其对分类的贡献,与特征词的信息量成正比关系,在数据挖掘领域广泛应用,计算公式如下:
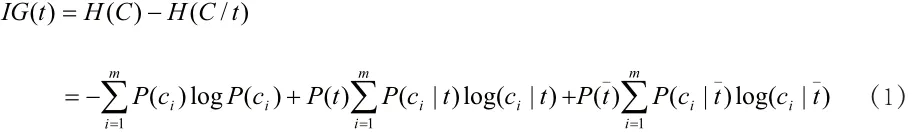
其中,P(ci)表示ci类在微博训练集中出现的
_概率;P(t)、P(t)分别表示微博训练集中包含或不包含特征词t的微博样本概率;P(ci|t)表示微博训练集
_中包含特征词 并且属于ci类的条件概率;P(ci|t)表示微博训练集中不包含特征词t并且属于ci类的条件概率。
1.2 微博向量表示
微博的内容是方便人类阅读的自然语言,计算机无法理解与计算,因此要对微博以结构化的特征向量形式存储以便计算机处理,在文本分类领域一般用向量空间模型(VSM)来表示。一条微博(Micro-blog)经切词分词算法预处理后,用向量空间模型描述为:m=<w(t1),w(t2),w(t3)...,w(td)> ,其中n为向量空间的维数,w(ti)为特征词ti在微博向量中的权重值,一般使用词频—逆文档频(TF-IDF)来计算,同时将各项特征词ti权值规范在[0,1]之间,其计算公式为[5]:
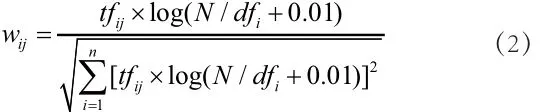
其中,tfij为特征词ti在微博样本mj中的出现次数,N训练微博总数,dfi是特征词ti在微博中的文档频率。
1.3 KNN分类算法
KNN算法是文本分类常用的算法之一,具有简单有效、鲁棒性、无需估计参数等优点,应用到微博舆情分类中其基本思想是[6]:计算待测微博样本与已知训练微博样本的情感相似度,找出与待测微博样本相似度最大的K个最近邻微博样本,K个微博样本中情感倾向较多的类别为该测试微博的情感类别,基本步骤如下:
(1)始初化K的值,K为最近邻数。
(3)评估待试微博Mj与训练集中所有微博样本Mi的情感相似度,我们使用欧式距离计算:
(4)根据公式(3)的计算结果进行排序,选出计算值最大的K个微博,作为微博Mj情感最近邻。
(5)计算待测试微博样本与类别C的)情感相似度:
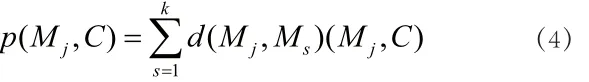
其中,Mj在类别 中出现(Mj,C)为1,否则为0,微博Mj的情感类别决策为:
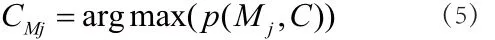
2 KNN算法中微博训练集裁剪
虽然KNN算法简单有效,但随着微博训练集规模的增加,需要计算待测试微博样本与训练集中所有微博样本的情感相似度来找出K最近邻,随着大数据浪潮的到来,当训练微博样本集达到一定级别时,计算与每个微博情感相似耗时将剧增,KNN算法的效率问题凸显。特别是在舆情监控领域,应及时监控网络上带有煽动、攻击等“负面”言论从而引导舆论导向,因而对情感分类算法的实时性要求高,下面讨论用粒子群算法对微博训练集进行裁剪,以提高KNN算法应用在微博情感分类中的性能。
2.1 粒子群算法
粒子群算法基本思想是[7]:随机初始化粒子群,粒子i的位置为:Xi=(x1,x2,...,xn),飞行速度
为:Vi=(v1,v2,...,vn),Xi和Vi为n维空间。粒子i通过由目标函数决定的适应值来不断迭代找到最优解,同时通过跟踪自己目前的最好位置pbest和粒子群全局最优位置gbest来更新自己。找到pbest和gbest后,通过公式(6)和(7)来分别更新自己的速度与位置。
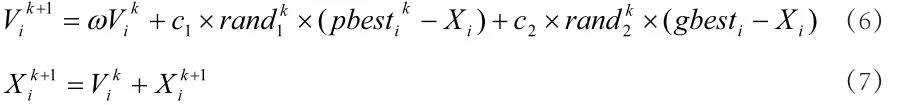
其中,Vi为粒子的速度,rand()为随机数,Xi为粒子的当前位置,c1,c2是学习因子,ω为惯性因子。
2.2 聚类算法
聚类算法的基本思路就是按照一定的度量规则将数据进行归类或分组,使用组(也称为簇)内的数据具有较高的相似性,而组间的数据具有较大的差异性。应用到微博训练样本中其数学描述为:设有微博训练集M={M1,M2,M3,...,MN},其中Mi是个d维的向量,N为训练集中微博总数。对于训练集M的聚类,就是通过一定算法划分为{C1,C2,...,Cc},通过求解训练集中的划分满足以下条件:样本情感相似度用公式(3)计算[8]。
为了发现c个簇的最优划分,聚类问题一般定义成一个性能函数的最优(最小)问题,使得类间总离散度和Jm达到最小,计算公式为:
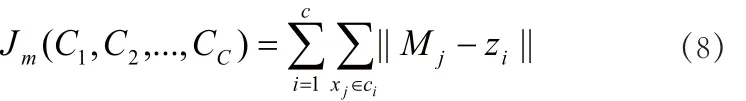
其中,z1,z2,...,zc分 别为C1,C2,...,Cc的簇 中心。
||Mj−zi||为Mj到聚类中心zi的距离,满足公式(9),Mj则 属第i类。

2.3 基于粒子群聚类的微博训练集裁剪
编码:本研究中的粒子编码结构如表1所示,其中z1,z2,...,zc分别是划分为c类的每类簇中心(为d维向量,因此位置就是c×d维,每个粒子代表的是c个初始聚类中心的组合),vi为粒子飞行的速度,f(x)是自适应函数[7]如表1所示。

表1 粒子编码
根据粒子群算法和聚类算法的基本思想,基于粒子群聚类的微博训练集裁剪算法思路:输入初始微博训练集M,总数为N,加速常数c1,c2,惯性权重ω,需要聚的类数c。
(1)微博训练集M在切词分词的基础上,按1.1节和1.2节对微博进行预处理工作,将所有样本用向量空间模型(VSM)表示;
(2)初始化粒子群和相关参数(具体值见实验),从微博训练集中随机选出几个样本为原始聚类中心,初始化P个粒子的位置编码Xi,速度Vi=0;
(3)同时根据f(x)计算粒子的适应度,产生pbest和gbest;
(4)根据公式(6)和(7)更新所有粒子的速度和位置;
(5)根据粒子聚类中心编码,按最近邻法则对微博样本聚类分析及划分,然后重新计算聚类中心并更新粒子的适应度值;
(6)更新粒子的个最优位置pbest和全局最位置gbest;
(7)重复步骤(4)至(6)直到达到最大迭代次数。
通过以上算法输出以聚类中心的微博样本调整后的裁剪训练集,然后采用KNN分类算法对微博进行情感分类的处理,具体流程如图1所示。
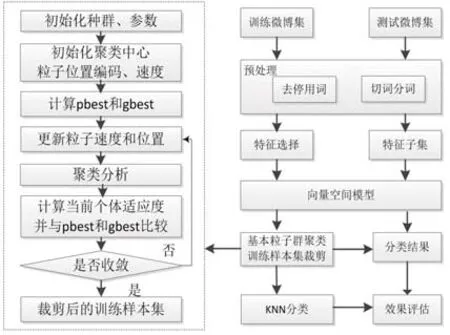
图1 基于粒子群聚类的KNN微博情感分类流程
3 实验分析
3.1 实验数据
实验语料库来源分别为新浪开放平台公开的API抓取的中文微博样本集和我们自己收集的部分私人微博,通过微博样本的人工标注,实验数据的样本结构如表2所示。
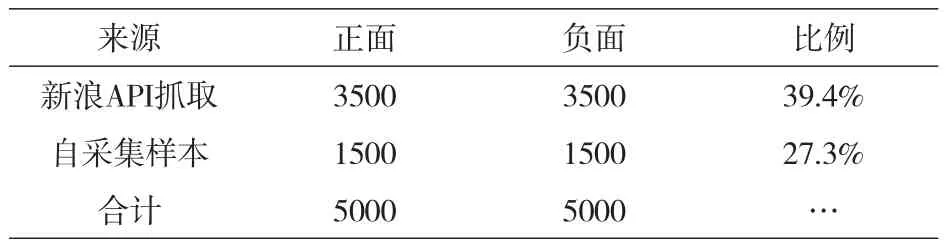
表2 微博样本结构
3.2 评价指标
为了有效评价微博情感分类性能的好坏,我选取F值作为评判算法有效性的指标 ,其计算公式为:

3.3 实验结果分析
本实验中切词分词工具选用中科院NLPIR汉语分词系统(2013版),开发平台为Visual Stdio.net 2015,在Windows环境下用C++语言实现,实验结果采取10次交叉验证方法,结果取平均值。从正面微博和负面微博中各取500条作为测试样本,剩下的作为训练样本。
实验1:统KNN分类。先用中科院NLPIR汉语分词系统(2013版)对训练微博样本集分别进行去停用词、切词分词等预处理工作得出微博的原始特征空间。再用信息增益算法计算排序,选出排名前N个特征子集构成特征向量。在此基础上对测试微博样本用特征子集构成向量空间模型并采用KNN分类算法进行情感分类。文献[9]对比了不同的K值得到的分类情况对比实验,指出K=18分类效果较佳。因此,本研究中取K=18,实验结果如图2所示。
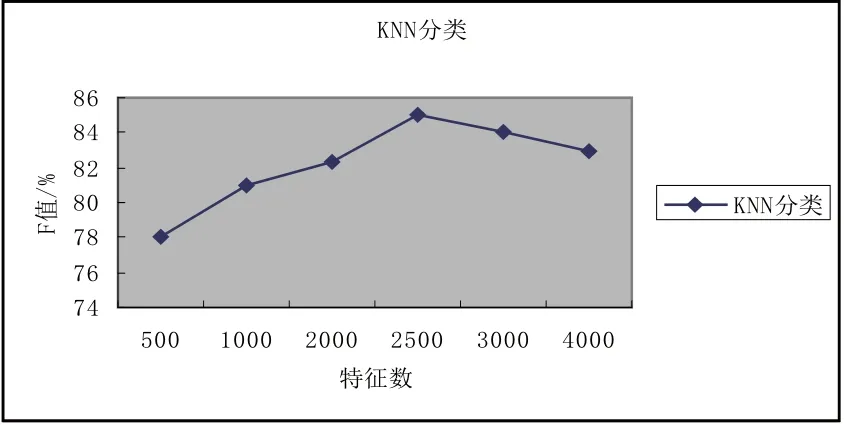
图2 KNN舆情分类结果
实验2:基于粒子群聚类的微博训练集裁剪的KNN分类。算法参数初始化为:最大迭代次数60次,c1=c2=2,rand()为(0,1)间取随机数,惯性权重 在迭代过程中线性下降。在实验过程中通过粒子群聚类将训练集数目从9000裁剪至6135,KNN在分类时的所需的计算工作量也减少了近1/3。从实验一可以看出,当特征数为2500时舆情分类的F值达到峰值。因此我们取特征数为2500,将传统的KNN分类与训练集经粒子群聚类裁剪后的KNN分类比对实验,实验结果如表3所示。结果表明:使用粒子群聚类算法对微博训练集裁剪,减少舆情分类计算量的同时并不影响微博情感分类效果。
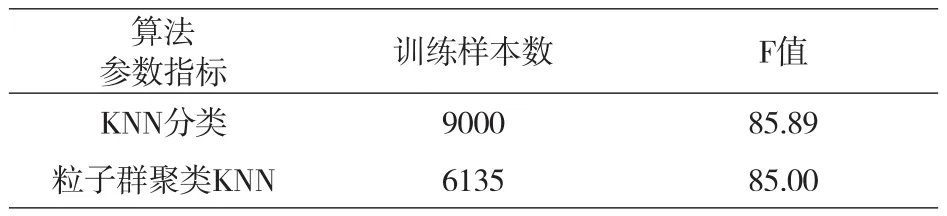
表3 基于粒子群聚类KNN与KNN对比
时间复杂度分析:由于在分类之前用粒子群聚类算法对微博训练集进行裁剪,会有一定的时间开销,但考虑微博舆情分类实质上是对微博上带有恶意、煽动及攻击性言论及时监控,进而掌握网络舆情动态,更多的是强调情感分析的实时性,而且对微博训练集裁剪可以在离线的环境下完成,因此,对练样本集裁剪并不会增加分类的时间损耗。
4 结语
基于数据挖掘的微博情感分类是网络舆情监控的重要方法,KNN虽是一种有效的分类算法,但由于会受到训练集规模的影响导致分类计算量大。本文介绍基于粒子群聚类的KNN分类中训练集的裁剪算法。实验结果表明,通过对微博训练集的裁剪,能够有效的降低舆情分类时的复杂度,而且还能适当提高分类的准确率。
[1]陶鹏.微时代背景下的虚拟社会治理[J].广东行政学院学报,2015(4):46-51.
[2]CNNIC.中国互联网络发展状况统计报告[EB/OL].(2016-10-12)[2016-12-12].http://www.idcps.com/news/20161012/92421.html.
[3]单月光.基于微博的网络舆情关键技术的研究与实现[D].成都:电子科技大学,2013:1-5.
[4]Yiming Yang.A Comparative Study on Feature Selection in Text Categorization[J].The ICML97,Nashville,1997.
[5]张霞,尹怡欣,于海燕,赵海成.基于模糊粒度计算的文本聚类研究[J].计算工程与应用,2010(13):53-55.
[6]于苹苹,倪建成,姚彬修,李淋淋,曹博.基于Spark框架的高效KNN中文文本分类算法[J].计算机应用,2016(12):3292-3297.
[7]王纵虎.聚类分析优化关键技术研究[D].西安:西安电子科技大学,2012:66-88.
[8]彭宏,蒋洋,王军.一种带混合进化机制的膜聚类算法.软件学报[J].2015(5):1001-1012.
[9]周庆平,谭长庚,王宏君,湛淼湘.基于聚类改进的KNN文本分类算法[J].2016(11):3374-3377.
TP-391
A
2095-7939(2017)05-0121-04
10.14060/j.issn.2095-7939.2017.05.025
2017-04-16
2017年福建省高校杰出青年科研人才培育计划资助项目;福建省教育厅基金(编号:JAT160561)。
林伟(1983-),男,福建仙游人,福建警察学院侦查系讲师,主要从事信息化侦查研究。
(责任编辑:于 萍)
猜你喜欢
计算机技术与发展(2018年8期)2018-08-21 02:08:14
电子测试(2017年15期)2017-12-18 07:19:27
中国机械工程(2017年22期)2017-12-02 01:52:34
中国民政(2016年16期)2016-09-19 02:16:48
中国民政(2016年10期)2016-06-05 09:04:16
中国民政(2016年24期)2016-02-11 03:34:38
智能系统学报(2015年4期)2015-12-27 09:38:39
中文信息学报(2015年4期)2015-04-21 08:29:12
电子设计工程(2015年6期)2015-02-27 12:04:53
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
