
基于WEB的警务多语言语料库的构建
2017-11-03 08:27:29季铎刘皓
中国刑警学院学报 2017年5期
季 铎 刘 皓
(1 中国刑事警察学院网络犯罪侦查系 辽宁 沈阳 110035;2 中国刑事警察学院网络信息中心 辽宁 沈阳 110035)
基于WEB的警务多语言语料库的构建
季 铎1刘 皓2
(1 中国刑事警察学院网络犯罪侦查系 辽宁 沈阳 110035;2 中国刑事警察学院网络信息中心 辽宁 沈阳 110035)
针对多语种警务语料库在构建过程中遇到的资源分散和人工整理难的突出问题,提出了一种基于Web数据获取的多语种警务语料库的构建方法,该方法采用了频繁序列模式和文本分析技术实现了对网页中多语种语料库的自动抽取。经实验证明,该方法可进行多语言数据的自动采集,在少量人工参与的前提下,实现了多语言数据的大规模采集和处理。
Web信息 挖掘语料库 构建 警务语料库
随着对外开放的不断深入,外国人来华旅游、从事商务、定居等现象日益增多。与此同时,公安工作中与外国人交流的情况也越来越频繁,小到外国人迷路寻求帮助,大到公安机关在行政管理和刑事管辖工作中,涉及外籍人员、组织、驻外机构等有关事务的管理,涉外警务的比重在不断增加。但不同的母语,造成双方沟通存在障碍。因此开展面向警务活动的多语言处理技术的研究迫在眉睫。
纵观国内外的研究,警务相关的大数据正在被不断应用于情报获取的实战应用中[1],但专业面向多语言警务活动的语料库资源鲜有报道。也正是由于相关基础资源的缺乏,使得涉及警务文本的处理技术只能利用传统数据和模型,极大影响了相关技术的性能,导致部分技术无法真正在警务工作中发挥作用。
本文通过构建Web的警用多语言语料库,不仅可以为公安民警在与外国人的交流中提供翻译帮助,保障紧急情况下的语言沟通顺畅,也可以为后期面向多语言网络舆情的分析和发现等提供基础保障。
1 WEB语言语料库构建流程
大规模真实文本的处理需求日益迫切,基于语料库的语言学研究受到越来越广泛的重视。特别是随着互联网等信息技术的不断发展,采用网络及自然语言等多学科技术对语料库进行收集、存储、转换及标记等研究已是未来信息技术发展的重要内容[2]。本文建立了一个基于Web的警用多语言语料库,解决相关警用系统缺乏多语言语料库的问题。其建设流程为:
(1)网页的解析和处理:Web页面作为半结构化文本[3]1,由HTML语言标签和文本内容组成,语料库需要解析页面内容,在此过程中采用DOM(Document Object Model)树思想,将半结构化的HTML构建成DOM树,其叶子节点为HTML中的内容。通过DOM树,网页的页面内容被分为多个片段,抽取这些片段,页面HTML源文件将被解析为除去标签以外的页面内容,并且这些内容用指定分割符,分割为多行,为后期的句对挖掘提供基础。
(2)双语句对的获取:基于频繁序列模式对已经判定为双语网页的页面进行双语资源的挖掘。即把特征选择得到的FSP放入规则库,将网页DOM树的叶子节点内容按照文本元素形式化为模式片段,若某模式片段与规则库中的规则相同,则提取该叶子节点中的内容为双语资源[4]1。
(3)多语句对的自动关联:相对于中、英、日等互联网信息丰富的语言,维、蒙等小语种语料资源稀有,且很难直接获得小语种到中文的翻译资源。本文提出一种基于英语为中间语的多语言句对自动对齐的技术,利用英语句子的相似度计算,自动建立句对间的对齐关系,并最终构建多文种的语料库,为机器翻译、跨语言检索等警用系统提供资源保障。
基于Web的警用多语言语料库构建技术利用多语言关键词寻找符合要求的双语页面,将翻译片段在网页中的模式形式化为规则并添加进规则库,利用模式匹配的方法寻找页面中的其他双语资源,并使用机器学习的方法不断学习新规则,对规则库进行扩充,最后以英语为媒介实现多语言语料库的构建,其总体流程如图1所示。
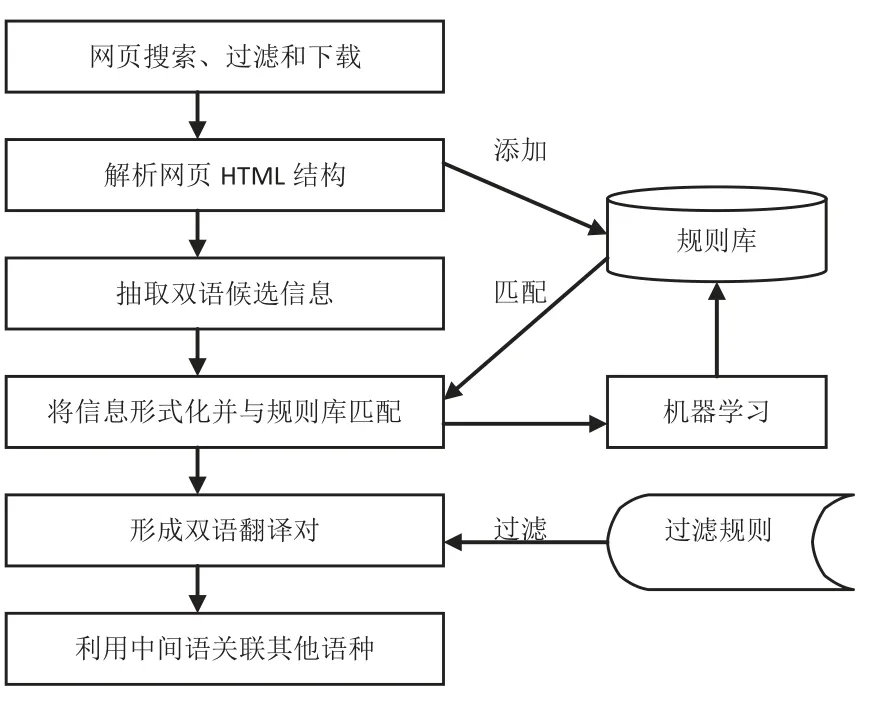
图1 多语言语料库构建基本流程
2 语言语料库构建的关键技术实现
2.1 DOM树和频繁模式序列提取
根据W3C DOM规范,HTML DOM是一种与浏览器、平台语言无关的接口,可以访问页面其他的标准组件。它将网页中的各个元素都看作一个对象,从而使网页中的各个元素可以被计算机语言所获取[3]5。通过解析器将网页文档进行结构解析,生成该文档的结构化的对象树(DOM树),并存储于内存中。将HTML文档转化为DOM树结构如图2所示,叶子节点的内容即是我们需要的文本内容。
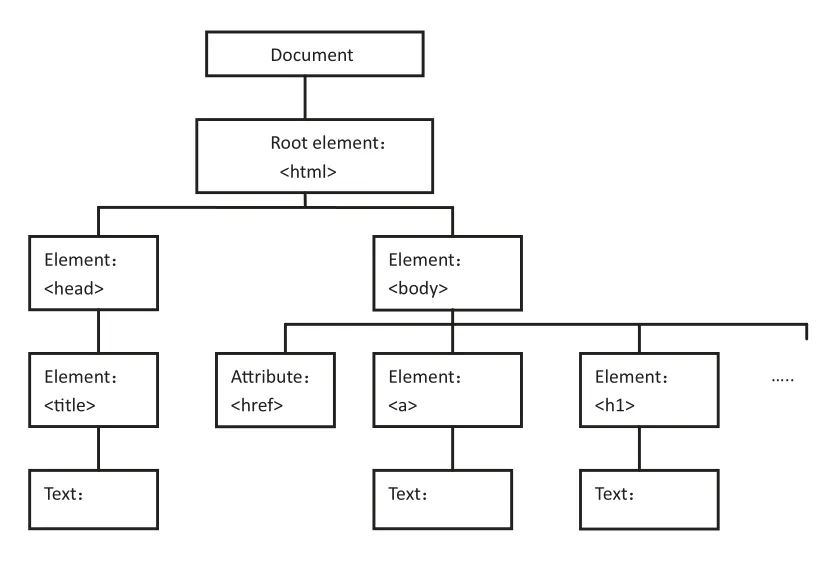
图2 HTML文档转化为DOM树结构
我们利用DOM树来提取频繁序列模式的过程如下:
Step1 将HTML文档转化为DOM树的结构。
Step2 把DOM树中叶子节点中的内容形式化。
Step3 如果形式化后的模式串长度小于规定的长度(依据具体实验结果选取),则把这个模式化列为考察的模式串。
Step4 考察每个模式串在HTML中的情况。如果该模式串的支持度大于阈值,则将该模式串加入到频繁模式序列中。
定义本文中的频繁序列模式:分析DOM树(一篇网页)中的所有叶子节点,将叶子节点中的内容通过算法转化为对应的模式串,如果该模式串在本网页中的出现次数超过我们设定的阈值(依据具体实验结果选取),则认为该模式串为频繁序列模式,该模式可作为判断一篇网页是否是双语网页的特征。
2.2 频繁序列模式的挖掘
使用数据挖掘中“频繁序列模式”的概念[4]4,在DOM树中对任意叶子节点的文本内容看作序列设定阈值Tr,若在序列S中出现的次数超过阈值,则认为S为频繁序列模式。
在模式串获取的过程种,取不同的文本元素,如制表格式符号、数字及特殊符号、中文字符集、英文字符集等。叶子节点中的对应的文本元素序列在网页中的支持度大于阈值,即为频繁序列模式。例如模式“1傘(かさ)【名】 伞”即形式化为“N J(SJ)S【C】SC”。
提取出频繁模式作为特征后,采用TF-IDF的特征权重计算方法:
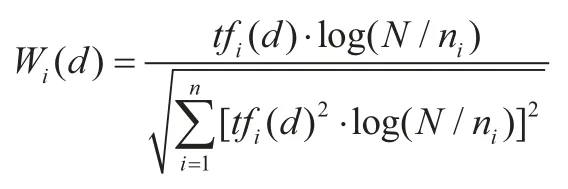
tfi(d)表示特征ti在文本d中出现的频率,N为文本集中的总文本数,ni为出现特征ti的文本总数。
3 警务多语言语料库的应用系统
通过基于Web的数据获取方法,本文于2016年4月20日到4月30日进行网络的数据的挖掘,总计获取中英维3种语言的数据13200条,后经人工过滤去重,最终保留5000句多语句对,并按公安工作分为交通违章、制假贩假、强制执行、户籍护照、报警求助、接待外警、案件调查、涉毒涉赌、突发事件9类。
基于该警务语料库,构建了警用的语言的应用系统,并利用计算机语音语言处理技术设计了一款人机交互的APP软件,在移动终端中进行应用测试。该软件系统无需手工输入,直接语音输入。
软件以公安实际业务需求为开发目标,并重点针对该领域进行了多项技术优化,实现了基于语音处理技术的输入和输出、基于自动翻译技术的文本翻译以及基于语料库的例句匹配等功能,具体功能如图3所示。
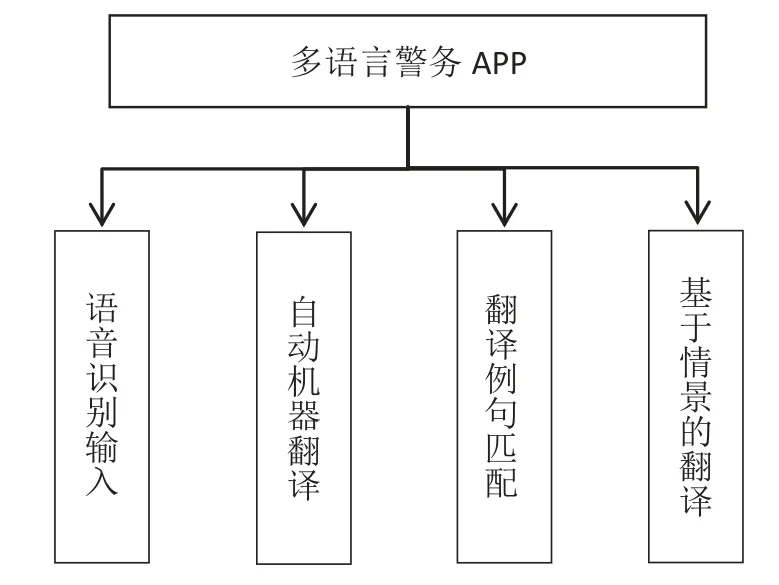
图3 系统主要功能
利用和借鉴开源平台搭建系统,语音识别技术采用科大讯飞语音识别包,智能翻译系统利用百度翻译云平台,并应用apicloud开源编译平台和html5语言开发。系统界面如图4所示。
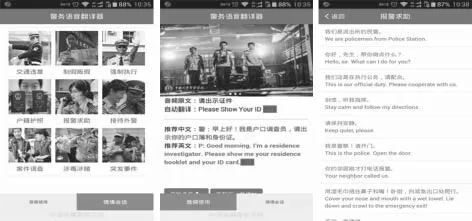
图4 警务语料库翻译软件界面
4 总结与展望
本文利用Web信息挖掘方法自动构建了多语言的警务语料库,包括交通违章、制假贩假、强制执行、户籍护照、报警求助、接待外警、案件调查、涉毒涉赌、突发事件等应用情景,涉及语种包括中、英、维3种语言,基本满足了公安工作的实际需求。
未来,我们将在语料库的数据量和应用广度上继续丰富语料库内容,并重点对东南亚地区语种进行深入研究,为解决我国一路一带经济发展中遇到的公共信息安全问题提供更多的数据支持。
[1]张姝,赵铁军,杨沐昀,李生.面向事件的多语平行语料库构建研究[J].计算机应用研究,2005(11):23-24.
[2]罗阳,季铎,张桂平,等.面向单一双语网页的双语资源挖掘方法[J].中文信息学报,2011(1):111-112.
[3]潘庆红.基于Web标准的精品课程教学网站技术架构研究[J].当代教育论坛(综合研究),2011(12):116-117.
[4]刘硕.大数据环境下的公安情报服务基本模式探析[J].中国刑警学院院报,2015(3):29-32.
TP391.2
A
2095-7939(2017)05-0118-03
10.14060/j.issn.2095-7939.2017.05.024
2017-05-19
2015年中央高校青年项目。
季铎(1981-),男,辽宁葫芦岛人,中国刑事警察学院网络犯罪侦查系副教授,主要从事网络舆情监控与自然语言处理研究。
(责任编辑:于 萍)
猜你喜欢
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
电子制作(2018年10期)2018-08-04 03:24:38
电子制作(2017年2期)2017-05-17 03:54:56
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
广州市公安管理干部学院学报(2016年1期)2016-08-02 05:44:18
电子测试(2015年18期)2016-01-14 01:22:58
语言与翻译(2015年4期)2015-07-18 11:07:45
长春教育学院学报(2015年20期)2015-06-05 12:22:12
警察技术(2015年4期)2015-02-27 15:37:20
警察技术(2015年1期)2015-02-27 15:35:46
