
基于播存结构的雾架构内容协同分发机制
2017-11-01 17:14扈晓娜
计算机应用与软件 2017年10期
扈晓娜 杨 鹏 刘 旋
(东南大学计算机科学与工程学院 江苏 南京 210000)
(东南大学计算机网络和信息集成教育部重点实验室 江苏 南京 211189)
基于播存结构的雾架构内容协同分发机制
扈晓娜 杨 鹏 刘 旋
(东南大学计算机科学与工程学院 江苏 南京 210000)
(东南大学计算机网络和信息集成教育部重点实验室 江苏 南京 211189)
雾计算是一种将云服务推向用户边缘的计算范型,其主要采用用户被动拉取内容的方式来加速内容分发,缺乏主动推送能力。因此,提出利用具备主动推送力度强的播存结构来辅助雾架构以实现内容的主动推送。在此基础上,针对边缘内容协同分发,提出一种基于软件定义的内容协同分发机制,具体包括多粒度协同存储机制、软件定义策略和域内多节点协同策略。最后利用原型系统进行实验测试与结果分析,结果验证该机制能够高效减少用户请求时延,提升用户体验。
雾计算 播存结构 软件定义 协同分发
0 引 言
近年来,“云计算”这个词语深刻地变革了IT学术界和产业界。随着企业的积极参与和政府的积极推动,与云计算相关的产业在我国得以迅猛发展。云计算具有动态、灵活及按需计算的基本特征,它克服了传统应用系统的资源独占、数据中心业务密度低和系统资源利用率低等弊病。但是,在实际的应用过程中,云计算存在着一定的短板和缺憾,具体体现在:对延迟敏感的应用不能奏效;消耗大量的网络带宽。因此,2011年思科首次提出雾计算的概念。2012年,思科研发组的Bonomi等[1]详尽地描述了雾计算的概念,并指出大自然中雾更是接近地面的云,故用雾计算恰当地描述介于云计算与终端计算的中间态。
雾计算的本质就是扩大了以云计算为特征的网络计算范式[2],将网络计算从网络的中心扩展到网络的边缘,从而更加广泛地运用于更多的应用形态和服务类型。雾计算在互联网模型中的位置如图1所示。云数据中心是互联网的中心,PC和移动在终端等位于互联网的边缘,而雾计算的服务器即雾节点位于两者的边界之上。雾计算的提出充分表明了网络边缘分发的重要性和必然趋势。然而,当前雾计算架构中主要采用边缘缓存的形式进行内容分发,严重局限于被动的“用户拉取”的形式,很大程度上缺乏内容推送的主动性,且内容分发消耗互联网带宽。

图1 互联网模型
近年来,李幼平等[3-5]为解决现有互联网的“带宽瓶颈”、“数字鸿沟”等问题提出广播和预存的播存结构新机制。播存结构的基本思想是通过广播通道将从互联网中爬取的热门内容主动推送到网络边缘,方便终端用户直接从最近最优的边缘服务器中获取所需内容。该机制能够提升终端用户的体验、节约互联网的核心带宽。播存结构的广播分发机制决定了它有以下两大重要优势:主动推送力度强;内容分发不消耗互联网带宽。
鉴于播存结构的两大优势正好能弥补当前雾计算架构的缺乏主动性、内容分发消耗互联网带宽的缺点,本文将播存结构融入到雾计算架构中,提出一种基于播存结构的雾计算架构。在此基础上,针对边缘内容协同分发,重点研究广播分发与Web缓存构成的“推拉结合”的内容协同分发机制——基于软件定义的内容协同分发机制。
1 相关工作
1.1 播存结构
播存结构的提出是为了解决现有互联网的“带宽瓶颈”、“数字鸿沟”等问题,其基本工作机制如图2所示。广播服务器(B端)从互联网爬取热门的信息资源,将这些信息资源通过广播渠道推送到网络边缘服务器(S端)和终端用户(C端),方便终端用户可以从最近的边缘服务器上获取内容。这种机制的最大特征就是可以分担核心网络的负载、节约核心网络带宽以及提升终端用户的体验。但是,单纯的广播推送缺乏与用户的交互,缺乏感知用户的能力。因此,李幼平院士又提出数据广播中的统一内容定位UCL(Uniform Content Locator)自动标引技术[6]。UCL是网络信息资源的描述结构,是信息资源的“元数据”,是内容提供者和用户之间的一种有效的沟通手段。一方面内容提供者利用UCL来表达内容的语义信息,另一方面用户通过UCL快速了解信息内容。

图2 播存结构
1.2 内容协同
近年来,缓存技术飞速发展,在网络中形成了多种形式,包括Web缓存、CDN缓存、P2P缓存等。相对而言Web缓存是最简单、部署代价小且较高效的一种缓存形式。Web缓存的基本思想是利用客户访问的时间局部性原理,通过在缓存节点上缓存一个副本,来提升终端用户的响应速度。
域内多节点的内容协同是指当本地不存在终端请求的资源时,如何快速且充分的利用域内的资源来获取所需信息。其中文献[7]提出Soccer(Services over Content-Centric Routing)策略,其主要是基于蚁群算法实现的,通过探测各个节点的缓存状态来动态调整转发策略。文献[8]提出了一种基于邻居缓存的路由策略,即每个节点维护一个邻居节点信息表,通过查看邻居节点缓存信息表来决定下一跳的地址。此外文献[9]还提出通过多路径转发来自适应的选择最优的通信路径,文献[10]提出通过传递探测信息来感知更优的路径。目前有关多节点协作机制的研究大部分是基于分布式的。
这些基于分布式的内容协同机制可以保证用户获取内容的可靠性,保证整个网络的稳定性,易于扩展。但是需要消耗更多资源,整个机制相对繁琐,更适合于比较复杂的网络。而本文的研究点主要是针对网络边缘,这种分布式的内容协同机制无法满足需求。
综上所述,本文提出一种基于播存结构的雾计算架构FCA-BS(Fog Computing Architecture Based on Broadcast Storage Structure)。在该架构的基础上,提出一种更适合于边缘网络的内容分发机制:基于软件定义的内容协同分发机制。该机制首先实现Web缓存内容和广播内容的多粒度内容协同存储,然后通过控制器中的软件定义策略对雾计算架构中的边缘节点进行集中控制,最终实现域内多节点协同。
2 基于播存结构的雾计算架构
2.1 雾计算
雾计算本质是分散的云计算节点,可以称之为边界计算。雾计算既继承了云计算的优点,也具有终端计算的优势,能够充分发挥终端的计算功能和本地就近处理的优势。雾计算更强调的是边缘网络计算。雾计算是半虚拟化架构的分布式服务计算模型,用户、应用或物联网终端可以在任何时候、从任何地方基于任何互联网设备访问自己的本地云(Local Cloud也可称为雾节点)[11]。雾计算的基本架构如图3所示。
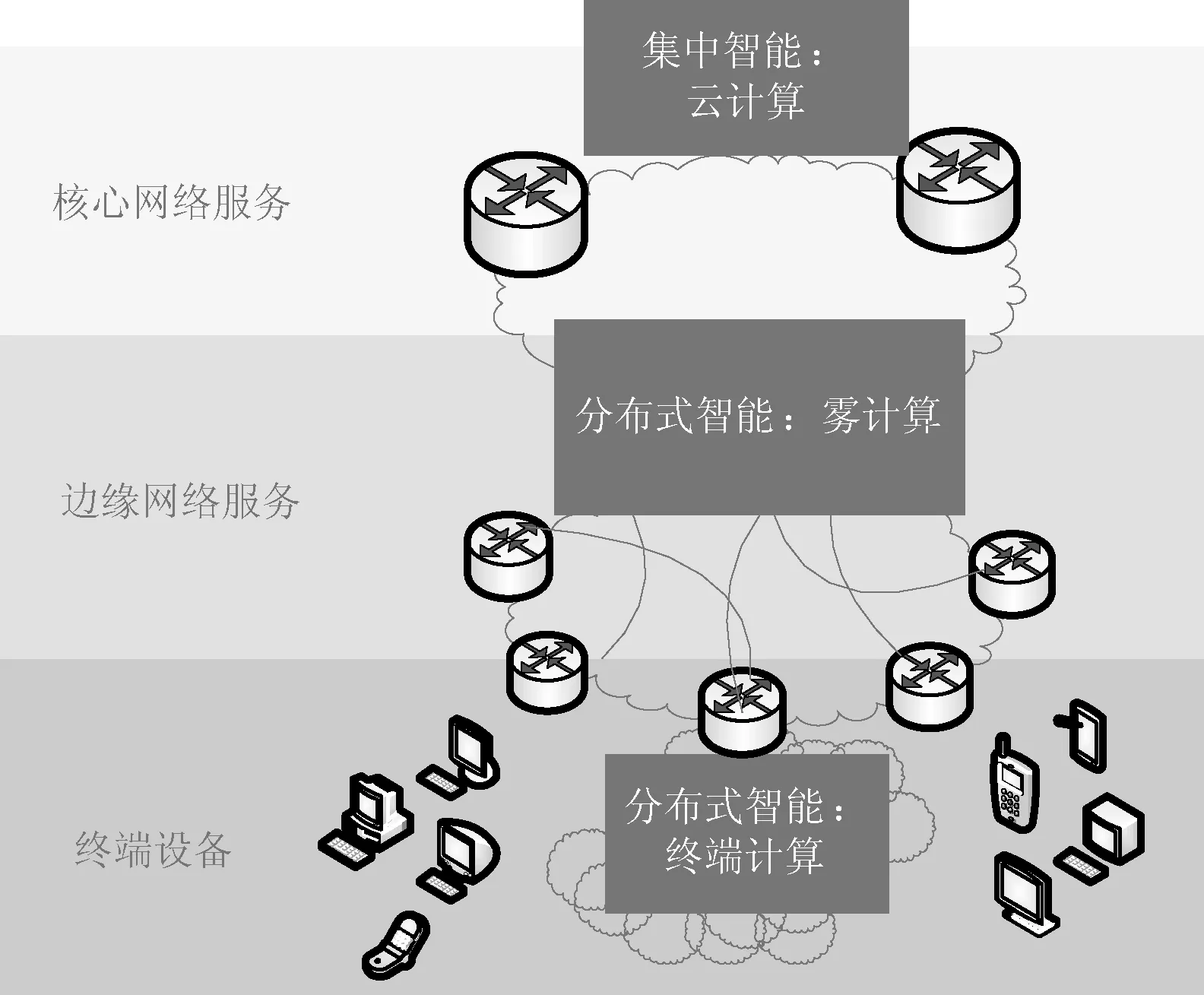
图3 雾计算架构
雾计算架构中主要通过在雾节点上进行内容缓存、计算等实现边缘内容分发,用户从雾节点上获取所需内容。当前的分发机制无法提前根据用户兴趣主动的向用户推送热门内容,因此本文对此提出优化方案:引入播存结构。将雾节点作为广播内容存储的边缘服务器,称之为雾服务器,通过雾服务器实现广播内容和Web缓存的协同分发,并借鉴软件定义网络的思想,引入控制器节点。
2.2 雾架构FCA-BS
雾计算的本质就是将服务计算扩展到网络边缘,工作重心落脚在边缘。播存结构也工作在网络边缘,因此基于播存结构的雾计算架构的重心在边缘网络,其整体架构如图4所示。
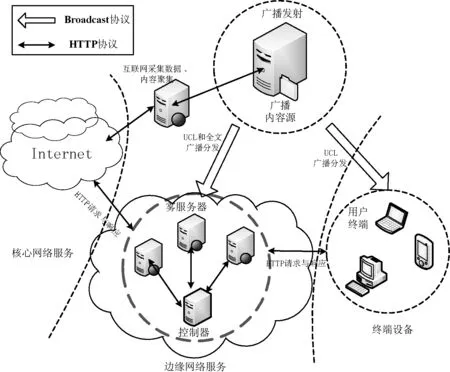
图4 基于播存结构的雾计算架构
雾计算中的节点被称为雾节点,其在新型雾计算架构中又作为边缘服务器的功能,因此将之称为雾服务器。FCA-BS主要包含四大模块:广播发射端、雾服务器端、控制器以及用户终端。其中内容采集服务端主要是从核心网中爬取最热门的信息资源,并对这些信息进行UCL语义标引,然后交给广播发射端。广播发射端将热门内容和UCL信息主动推送到雾服务器以及用户终端。雾服务器一方面会根据控制器发送的用户兴趣值来选择性的接收广播分发的内容,另一方面也会进行有价值的Web缓存,很大程度上保证终端用户的响应速度以及命中率。架构中的控制器主要用来对域内所有的雾服务器进行集中控制以及存储内容的协同。
3 FCA-BS中的内容协同分发机制
为解决无法利用现有网络中的大规模真实流量和丰富应用进行实验等问题,美国斯坦福大学Clean slate研究组[12]提出一种新型网络架构:软件定义网络SDN(Software Defined Network)。SDN的基本思想是把当前IP网络互连节点中决定报文如何转发的复杂控制逻辑从交换机/路由设备中等分离出来。由集中控制器(controller)下发统一的数据转发规则给交换设备,以便通过软件编程实现硬件对数据转发规则的控制,最终达到对流量进行自由操控的目的[13]。
本文借鉴SDN中的集中控制思想提出一种基于软件定义的内容协同分发机制。整个机制主要由多粒度协同存储机制、软件定义策略和域内多节点协同策略三个部分组成,下面将围绕这三方面展开叙述。
3.1 多粒度协同存储机制
基于播存结构的雾计算架构中目前有两种存储方式:Web缓存和广播存储。Web缓存的主特征是缓存细粒度的网页元素,如图片、视频和App等。广播存储则更偏向于粗粒度的网页全文,以便用户的请求可以一次响应,更方便高效。两者各有自己的特征和优势,因此本文提出维护两种粒度的存储方式,同时实现两种粒度内容的存储协同——多粒度协同存储机制。其基本思想:雾服务器每接收到一份广播内容后,对其进行内容过滤处理,并将得到的细粒度内容集合存储到Web缓存里。其中内容过滤算法CFA(Content Filtering Algorithm)如算法1所示。
算法1CFA
输入:广播流ts,白名单wl,热度阈值ps
输出:细粒度内容集fgs
1. cont = GetFromBroadcast(ts);
2. p = ComputeP(cont);
3. if(p > ps)
4. scon = ResloveContent(cont);
5. for(s in scon)
6. if(s∈wl ))
7. hash = ComputeHash(s);
8. AddFgs(s, hash);
9. end if
10. end for
11. hash = ComputeHash(cont);
12. InsertDb(cont, hash);
13. end if
14. return fgs;
雾服务器会对每份广播内容维护一个热度值,并对其周期性的更新,其计算过程如公式所示:
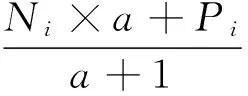
(1)
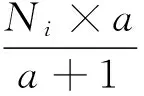
(2)
其中Pi代表这一计时周期的缓存内容的热度,Ni代表本周期内缓存内容被访问的次数,a为内容热度的权重系数,其值大于1。CFA中将用该热度值作为是否缓存的依据。
综上所述,多粒度协同存储机制可以充分利用广播分发的热门内容,发挥广播分发的作用,同时提升雾服务器Web缓存的命中率。
3.2 软件定义策略
软件定义本质思想就是将整个系统的控制层和业务层进行分离,由单独的控制服务器来管理整个系统。基于播存结构的雾计算架构中的控制器和雾服务器是双向交互的,一方面雾服务器定时的主动向控制器上报域内各个节点的缓存信息和服务信息等数据信息。另一方面控制器会根据自身维护的数据信息来动态调节各个雾服务器的缓存内容。控制器主要用来实现软件定义策略,下面重点从数据平面和控制平面两方面来分析软件定义策略。
3.2.1 数据平面
域内的所有雾服务器对应一台控制器。为了实现集中控制,控制器中将会维护整个域内雾服务器的拓扑信息表TIT(Topology Information Table),记录各个雾服务器之间的跳数。此外,每当雾服务器的内容有增加、删除和修改时,都会向控制器上报修改的信息;每当终端请求到达雾服务器之后,雾服务器都会向控制器上报本次请求的具体状态信息。控制器则根据各个节点上报的内容动态的调整所维护的域内的标引信息表(DIT)和服务信息表(SIT)。其主要内容分别如表1和表2所示。

表1 DIT

表2 SIT
节点标识对应于存储内容的雾服务器的唯一节点标识,端口号为从雾服务器获取内容的端口号,URL为内容全文的原始链接,Hash值是按照SHA1算法对URL进行Hash求值得到的,对应于UCL中的内容指纹。其中类型是指缓存信息所属类型,对应于UCL字段中的类型字段,比如娱乐、体育、国际等。命中类型字段包含3中类型:0未命中,1本地命中,2域内命中。
控制器会周期性地对SIT进行统计分析,并对每台雾服务器维护一个类别权重比值信息表(WIT),表征该周期内用户对各个类别的请求次数占总请求次数的权重的比值。控制器周期性地将统计的类别权重比值W发送给雾服务器。雾服务器将在下个周期依据该类别权重比值选择性地接收广播分发的内容。控制器间接的实现了对雾服务器缓存内容的动态调整,该动态调整策略可以提升雾服务器的命中率。其中某类别c的权重值计算如公式所示:

(3)

3.2.2 控制平面
控制器可以通过所维护的数据信息来控制雾服务器的域内转发策略。当雾服务器本地不存在终端用户请求的内容时,会向控制器发送一个查询请求,包含Hash和类别两个参数。控制器收到该请求后,先根据Hash值从DIT中找到存在所请求内容的所有节点集合nodes,然后根据控制器内的转发决策策略计算出nodes中最优的两个节点,最终将这两个节点的标示信息和端口号返回给雾服务器。选取两个节点是为确保域内最大概率命中。
转发决策策略先根据请求参数中的类别值从WIT表中获取节点的类别权重W,根据节点标识从TIT表中获取节点间的跳数H,并从SIT表计算出该节点在所请求类别上的命中率R,最后根据这三个因素计算出每个节点的转发价值F。其中转发价值F的计算如下所示:
F=αW+βH+(1-α-β)R
(4)

(5)
其中,x和y为常量参数,表征类别权重、节点间的跳数以及命中率三个因素所占的比重值。该值可根据实际的需求动态的调整,取值范围均为(-∞,+∞),但必须满足条件x+y≤0。转发决策算法FDA(Forwarding decision algorithm)的框架如算法2所示。
算法2FDA
输入:Hash值hash,类别c
输出:两个节点信息nif
1. nodes = GetFromSIT(hash);
2. for(node in nodes)
3. W = GetWFromWIT(c);
4. H = GetHFromTIT(node);
5. R = ComputeR(node);
6.F=αW+βH+(1-α-β)R;
7. end for
8. sort f and select top-2 node as nif;
9. return nif;
3.3 域内多节点协同策略
基于软件定义来实现域内节点协同的方式相比于分布式更加快速、高效。因为雾服务器自身不需要维护复杂的数据信息和控制信息,只需负责实现业务逻辑。当雾服务器本地存在用户请求资源时,直接响应终端用户;相反,若不存在,直接向控制器发送一个域内协同查询请求。控制器调用自身转发机制计算出域内存在所需内容的最佳节点信息,并返回给请求节点,请求节点直接将内容转发到域对应的IP和端口来获取资源。域内多节点协同中的客户端、雾服务器、控制器、Web缓存交互的时序图如图5所示。

图5 UCL请求时序图
4 实验及结果分析
4.1 原型系统设计
本文结合播存结构的基本架构,开发了基于播存结构的雾计算架构的原型系统。原型系统的基本架构如图2所示,由广播发送服务器、客户端、控制器以及多台雾服务器组成。整个原型系统的环境配置参数如表3所示。

表3 原型系统环境配置参数
面向雾计算的内同协同分发架构的原型系统主要由四大模块组成:广播分发模块、Web缓存模块、软件定义模块以及协同查询模块,原型系统整个模块的基本设计如图6所示。

图6 原型系统基本模块图
内容分发单元由广播分发模块以及Web缓存模块组成。广播分发模块首先从互联网采集热门信息,对其进行UCL语义标引并存储到本地库,定时将内容分发到各个服务器端。Web缓存模块解析用户请求中的网页元素模块,并以文件系统的方式缓存到本地。
协同控制单元包含软件定义模块以及协同查询模块。软件定义模块维护域内所有服务节点的缓存信息以及用户请求的命中状况,并通过对用户请求信息的分析,得到用户的兴趣类别并反馈给服务节点,以次提升整个系统的命中率。协同查询模块通过查询自身维护的服务节点信息来响应域内节点的协同查询请求。
4.2 测试过程及结果
实验的主要测试指标为网页的响应时延,分别针对大小为500、1 500、2 500、3 500、4 500 KB的网页进行测验,并就本地命中、服务端命中、协同命中以及外网获取四种情况进行对比,实验结果如图7、图8所示。
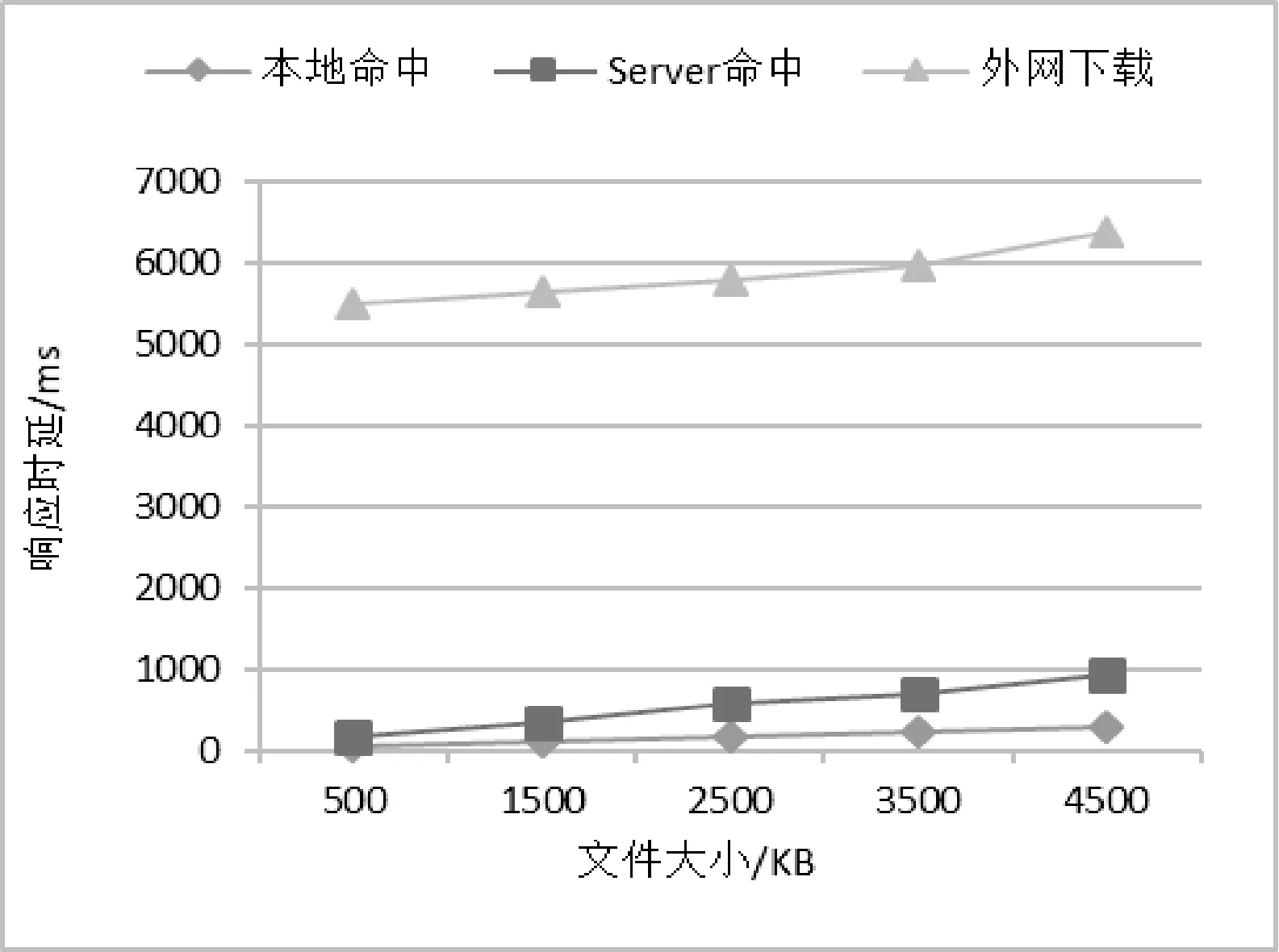
图7 本地命中/Server命中/外网下载响应时延对比

图8 Server命中/协同命中响应时延对比
实验结果表明:
1) 客户端能正确且完整地显示客户所请求的内容。
2) 本域命中(包含本地命中、Server端命中以及协同命中)的响应时延明显低于从外网获取的响应时延,从而提升用户体验。
3) 本地命中相比从外网获取的响应速度提高了至少15倍。
4) Server端命中的与本地命中的响应时延以及协同命中与Server端命中的响应时延之间的差距都随着文件的增加而线性增加,但总体差距不大,远远低于从外网获取的响应时延。
5 结 语
本文介绍了雾计算的基本概念以及当前雾计算架构的基本组成。针对当前雾计算架构以用户被动拉取内容为主、主动推送力度弱的问题,提出了将播存结构融入其中,构成新型的基于播存结构的雾计算架构。在新型的雾计算架构上,重点研究了基于软件定义的内容协同分发机制。实验验证该机制可以有效地提升边缘分发的性能,提升用户的体验。如何高效地利用广播缓存和Web缓存的内容以及实现更强力度的协同机制将是未来的研究重点。
[1] Bonomi F,Milito R,Zhu J,et al.Fog Computing and its Role in the Internet of Things[C]//Edition of the Mcc Workshop on Mobile Cloud Computing.ACM,2012:13-16.
[2] Luan T H,Gao L,Li Z,et al.Fog Computing:Focusing on Mobile Users at the Edge[J].Computer Science,2015,42(7):170-173.
[3] 李幼平,杨鹏.共享文化大数据的新机制[J].中国计算机学会通讯,2013,9(5):36-40.
[4] 杨鹏,李幼平.基于播存思想的未来互联网次结构[J].复杂系统与复杂性科学,2015,12(2):18-22.
[5] 杨鹏,李幼平.播存网络体系结构普适模型及实现模式[J].电子学报,2015,43(5):974-979.
[6] 杨鹏,李幼平.二元互补未来互联网体系结构[J].复杂系统与复杂性科学,2014,11(1):53-59.
[7] Shanbhag S,Schwan N,Rimac I,et al.SoCCeR:services over content-centric routing[C]//Proceedings of the 2011 ACM SIGCOMM Workshop on Information-Centric Networking (ICN’11),Toronto,Canada,2011.New York,NY,USA:ACM,2011:62-67.
[8] Kotsia I,Patras I.Neighbor Cache Explore Routing Strategy in Named Data Network[J].Journal of Frontiers of Computer Science & Technology,2012,6(7):593-601.
[9] Yi C,Afanasyev A,Wang L,et al.Adaptive forwarding in named data networking[J].Acm Sigcomm Computer Communication Review,2012,42(3):62-67.
[10] Liu W,Okamura K,Li C.Ant Colony Based Forwarding Method for Content-Centric Networking[C]//International Conference on Advanced Information NETWORKING and Applications Workshops.IEEE Computer Society,2013:306-311.
[11] Zhu J,Chan D S,Prabhu M S,et al.Improving Web Sites Performance Using Edge Servers in Fog Computing Architecture[C]//IEEE Seventh International Symposium on Service-Oriented System Engineering.IEEE Computer Society,2013:320-323.
[12] Dave T.OpenFlow:Enabling Innovation in Campus Networks[J].Acm Sigcomm Computer Communication Review,2014,38(2):69-74.
[13] 张朝昆,崔勇,唐翯翯,等.软件定义网络(SDN)研究进展[J].软件学报,2015,26(1):62-81.
COLLABORATIVECONTENTDISTRIBUTIONMECHANISMINFOGCOMPUTINGARCHITECTUREBASEDONBRAODCASTSTORAGESTRUCTURE
Hu Xiaona Yang Peng Liu Xuan
(SchoolofComputerScienceandEngineering,SoutheastUniversity,Nanjing210000,Jiangsu,China)(KeyLaboratoryofComputerNetworkandInformationIntegrationMinistryofEducation,SoutheastUniversity,Nanjing211189,Jiangsu,China)
Fog computing is a computing paradigm that pushes cloud services to the user’s edge. It mainly accelerates content distribution through the method of users’ passively pulling content, and lacks active push capacity. Therefore, we propose to use the active push with strong broadcast structure to assist the fog computing architecture and to achieve the active push of the content. Then, a collaborative content distribution mechanism based on software definition is proposed for distributed content distribution, which includes multi-granularity cooperative storage mechanism, software definition strategy and multi-node cooperative strategy in the domain. Finally, the prototype system was used for the experimental test and result analysis. The result reveals that the mechanism can reduce the user request delay and improve the user experience.
Fog computing Broadcast storage structure Software definition Collaborative distribution
TP3
A
10.3969/j.issn.1000-386x.2017.10.001
2017-01-18。国家自然科学基金项目(61472080,61672155)。扈晓娜,硕士生,主研领域:未来网络,播存环境。杨鹏,副教授。刘旋,博士生。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
汽车工程(2021年12期)2021-03-08
网络安全和信息化(2020年9期)2020-12-31
铁道通信信号(2019年9期)2019-11-25
时代人物(2019年27期)2019-10-23
网络安全和信息化(2019年8期)2019-08-28
电子制作(2018年10期)2018-08-04
北京广播电视报(2017年36期)2018-02-28
北京广播电视报(2017年25期)2018-02-23
计算机测量与控制(2017年6期)2017-07-01
