
基于时域滤波多频段谱减法的语音增强
2017-10-18 02:59:08张小宇刘云清赵馨
长春理工大学学报(自然科学版) 2017年4期
张小宇,刘云清,赵馨
(长春理工大学 电子信息工程学院,长春 130022)
基于时域滤波多频段谱减法的语音增强
张小宇,刘云清,赵馨
(长春理工大学 电子信息工程学院,长春 130022)
传统的多频段语音增强是将频域分割成各个频段,并对每个频段单独进行语音增强,但是因为相邻频带的共振峰影响清晰语音估计,导致了语音识别效果不理想,为了减少相邻频带的共振峰带来的影响,提出了一种时域滤波中多频带语音增强的方法,通过将时域中的未处理语音过滤成各种等效的基于矩形带宽的子带,然后在每个频带中使用基于离散余弦变换(DCT)谱减法来估计清晰语音,并结合使用各个频带信噪比(SNR)获得频带特定加权因子。在SNR为0~10dB的汽车噪声、餐厅噪声、列车噪声、白色噪声和工厂噪声的环境下基于时域多频段语音增强算法增强效果优于现有的技术。
谱减法;多频带;DCT
语音通信系统的性能特征在于语音质量和可懂度,然而,这些因素容易受到外部噪声源干扰而劣化。在这些源中,背景噪声是最常见的,并且其以加法方式影响语音信号。这需要有效的语音增强算法来提高语音信号的质量和可理解性,从而提高系统的性能并降低听众的疲劳[1]。语音增强算法的作用是去除噪声并增强语音特定分量,从而产生清晰、无噪声的语音。目前的工作重点是频谱处理方法,其比较成功的方法是谱减法[2]。在文献[4-7]中有对基本谱减法的一些改进,这些语音增强算法需要对噪声频谱进行估计,可以使用语音活动检测器[3]或使用噪声估计算法[4]来估计。
频域语音增强的噪声去除方法主要使用傅里叶变换(FT)衍生的频谱。这种方法不仅可以增强未处理语音的幅度频谱,同时可以保持未处理语音的相位不受干扰,因为这是纯净语音可能的最佳相位[5]。然而,当使用未处理语音的相位信息时,语音可以被增强的程度是有限的[6]。为了克服该限制,可以从提供符号信息的方法入手,而不是用相位的实际变换(诸如离散余弦变换(DCT))导出频谱。此外,与FT相比,DCT提供了高分辨率和能量压缩[7]。在文献[8,9]中,作者使用阈值方法去除DCT域中的未处理语音中的噪声。DCT的能量压缩属性在语音增强中是非常重要的,因为语音的整体质量受到有声段质量的影响,对于该有声段,大多数能量被限制为低频分量而不是无声语音段。
虽然这些技术显著改善了语音质量,但是它们作为单个实体作用于整个频带,而语音和噪声分量并不是均匀地分布在所有的频带上。因此提出了改进的多频谱谱减法,将未处理语音频谱线性或非线性的划分各个子带,并且独立地对每个子带执行噪声去除。同时因为磁极相互作用的问题,一个频带中的频谱分量对相邻频带中的频谱分量是有影响的;并且与纯净语音不同,增强语音不能通过直接组合每个子带中的频率而使用逆傅里叶变换,即:通过傅里叶变换给每个频带不同的权重,将信号分解成含有不同权重的频率分量;未处理语音由于噪声的不均匀分布,频域频带划分将导致子带具有不同的信噪比(SNR),当每个子带中的语音分量被增强时,每个子带的SNR改变,即频率分量的分布也与之前的不同。所以在使用导出原始未处理语音的权重就会导致纯净语音的不准确估计。为了克服这些问题,使用时域滤波可能更合适。
本文提出了改进的语音增强技术,通过使用DCT在语音段中能量压缩方面的优点,以及用于时域滤波生成的多频带可以减少频谱域滤波中极点之间的相互作用的优点。在谱减法中,由于噪声分量不均匀分布在所有的频带上,因此将频带特定的加权因子分配给每一个子带,该带特定加权因子在低SNR频带上大于高SNR频带,并且基于相应频带SNR来计算。
1 基于DCT的谱减法(SSDCT)
谱减法是通过从未处理语音频谱分量中减去噪声分量来估计干净的语音频率分量。假设语音s(n)和噪声分量d(n)不相关,并且所考虑的噪声是背景噪声,其本质上是加性。
即:

一般使用FT将未处理语音变换到频域,然而现在主要是利用DCT的优点,使用DCT(类型II):

其中,X(k),S(k)和D(k)分别表示未处理语音,纯净语音和噪声的DCT导出的幅度谱。噪声的幅度D(k)是从未处理语音中的无音段估计的。
使用谱减法估计纯净语音频谱幅度:

其中,α为增强高信噪比段的过减因子,β是噪声的频谱下限参数,类似于离散傅里叶变换(DFT),处理后的频谱和相位(未处理语音频谱分量的符号信息)组合以获得增强的语音信号。
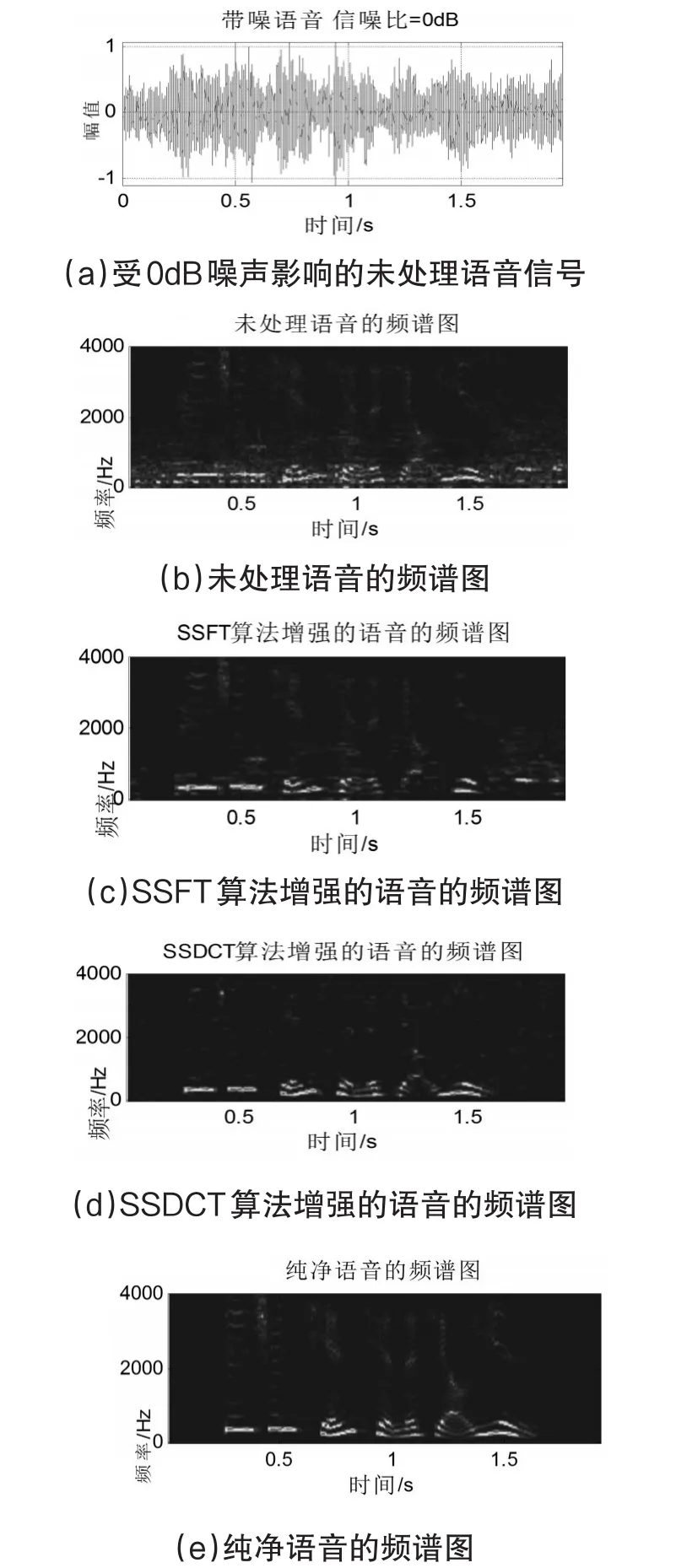
图1 基于SSFT和SSDCT的谱减法算法的比较
为了进行比较,该系统实现了基于全波段FT的谱减法(SSFT)算法[10]。如图1(a)-(e)所示,给出了受0dB的餐厅噪声影响的语音信号、噪声语音信号的频谱图,通过SSFT和SSDCT算法增强的语音信号以及干净的语音信号的频谱图。在图1(c)中通过SSFT增强的语音中,话语的几个低频分量不被保留。然而,在图1(d)中通过SSDCT增强的这些信息分量,通过保留提高语音质量。为了进一步改善语音质量,在各种SNR水平下对未处理语音数据执行时域滤波多频带谱减法(TMB-SS)。
2 时域滤波多频段谱减法(TMBSS)
由于噪声和语音频谱分量不均匀分布在所有频带上,因此多频带谱减法优于全频谱减法。从子带中的语音分量减去噪声分量,则可以更好的降低噪声。子带语音频谱可以通过将频率段分成不同的频带或通过在时域中将信号滤波到不同的频带,然后估计频谱来获得。在这个系统中是通过时域滤波获得多个子带,因为它可以减少相邻频带频谱分量的影响。提出的语音增强算法TMB-SS的框图如图2所示。为了进一步改善子频带级别的降噪,基于等效矩形带宽(ERB)尺度提取多个子带。ERB尺度与人类听觉系统高度相关,并且与其他临界频带尺度相比,它能更精确地模拟低频分量[11]。ERB滤波器的带宽计算为:

其中,fc是以Hz为单位的滤波器的中心频率。滤波器的上限截止频率和下限截止频率(fu和fl)为:
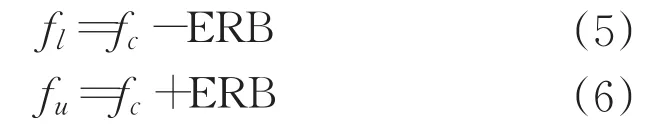
然后未处理语音信号通过这些滤波器获得临界频带信号,未处理语音信号以临界频带信号的组合表示:

其中,M表示临界频带的数目,xi(n)是第i个临界频带中的未处理语音信号。
在这个系统中,使用时域滤波是为了减少相邻频带的影响,并且基于ERB将未处理语音信号划分为子带。SS-DCT单独地应用于每个频带,用于估计在临界频带级的纯净语音频谱。由于噪声频谱分量并不是均匀分布在所有临界频带内,因此在每个子带信号中需要实现的噪声减少量和信号失真(SD)是不同的。所以应该在其它频带上增强一个子带,减小低SNR频带与高SNR频带的SD,加权因子是在频带级别上提供对噪声减少和SD的附加程度的控制。所以,基于相应的频带SNR将频带特定加权因子γi引入每个临界频带。过减因子(αi)通过仅处理子带信号来强调段中的噪声去除,而γi在频带级上提供对噪声去除的附加程度的控制。因此,除了过减因子之外,在当前工作中提出带特定加权因子(γi)。估计的纯净语音频谱由下式给出:


图2 语音增强算法TMB-SS的框图
其中,βi是取决于在每个临界频带中估计的噪声的频谱下限参数。高SNR频带与低SNR频带相比具有较低的加权因子,并且基于使用单独频带SNR计算的平均SNR来分类。根据经验观察,当加权因子的范围在1和2.5之间时,可以实现更好的噪声去除。因此取最高SNR的频带的加权因子为1,最低SNR的频带的加权因子为2.5。对于具有中间SNR的频带,使用在1.08和2.04之间(步长为0.08)的加权因子。使用客观测量法来评估频带特定加权因子对所提出的语音增强算法(TMB-SS)的性能影响,所获得的分数在表1中列出。从得分可以看出,当使用γi时,SD(SD)和背景失真(BD)的量减少,说明改进了语音增强的质量。
最后,组合每个临界频带估计的清晰语音信号,获得如下式中的增强语音信号

3 实验结果
语音增强算法使用从TIMIT语料库和NOIZEUS数据库随机选择的句子进行评估。NOIZEUS是一个未处理语音语料库,包含30个话语,由三个男性和三个女性说话者说话,被来自AURORA数据库的八个真实世界噪声破坏。NOISEX-92是一个噪声数据库,包括八种不同的非固定噪声,如工厂、机枪、白噪声、粉红噪声等。将来自NOISEX-92和AURORA数据库的噪声以不同的SNR水平添加到TIMIT和NOIZEUS数据库中干净的语音中,获得未处理语音信号。在这个系统中,以0-10dB的SNR水平,添加五个不同的噪声,即:餐厅噪声、白噪声、工厂噪声(选自NOISEX-92)、汽车噪声和火车噪声(选自AURORA)。
3.1 SSFT与SSDCT
从SSFT和SSDCT算法的目标质量测量获得的观察结果讨论如下:
从PESQ值(参见表2)可以看出,在考虑所有的SNR条件下,对于列车噪声(改善为0.1-0.4),SSDCT产生的质量优于SSFT的语音。对于汽车,工厂和多余噪声,SSDCT的性能与SSFT的性能非常相似。
•对于除白噪声之外的所有噪声,SSDCT获得的整体质量分数与SSFT更接近,如表2所示。
•SSDCT的性能在SD和BD方面与SSFT相当,如表3所示。对于餐厅噪声,SSDCT将BD降低到与SSFT相比相当大的量,并且通过较高的BD分数来反映。
3.2 FMB-SS与TMB-SS
从FMB-SS和TMB-SS算法的客观质量测量,得出以下观察结果:
•TMB-SS算法在所有SNR水平上从受列车、餐厅噪声、白噪声和工厂噪声影响的语音中得出高度增强的语音,PESQ分数比FMB-SS提高了0.1-0.4,如表2所示。
在汽车噪声的情况下,TMB-SS执行更接近FMB-SS,并且在SNR>4dB(在PESQ值中改善0.1-0.3)时产生更好的性能。
由于TMB-SS比FMB-SS引入的背景和SD低,在表2中观察到增强语音的整体质量改善为0.1-0.3。
对于TMB-SS,在所有SNR级别的白噪声和工厂噪声,以及高于5dB SNR水平的汽车、火车和餐厅噪声,增强语音信号中的残留噪声(由BD分数测量)较低(参见表3),从而提高整体质量。
在所考虑的大多数噪声条件下,在语音增强中使用TMB-SS具有比FMB-SS低的SD量。
4 结论

表1 具有和不具有带特定加权因子γi的TMB-SS的性能比较

表2 0-10dB各种噪声PESQ和整体质量的平均值
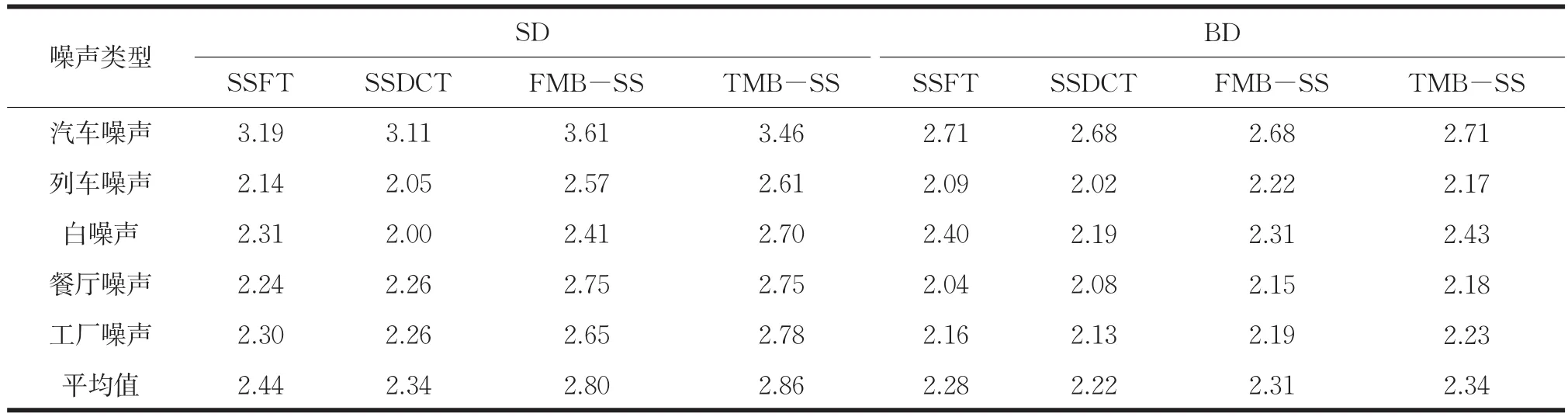
表3 0-10dB各种噪声SD和BD的平均值
为了解决频域多频带方法中的相邻频带频率分量的影响,提出了基于时域多频段语音增强算法,从实验结果可以看出,本文提出的算法比传统的语音增强方法增强效果好。PESQ值验证了改进的算法具有更好的语音质量,使用改进的算法具有比传统算法低的SD量和BD量。
[1]Lim JS,Oppenheim AV.Enhancement and bandwidth compression of noisy speech[J].Proceeding of the IEEE,2005,67(12):1586-1604.
[2]Boll S.Suppression of acoustic noise in speech using spectral subtraction[J].IEEE Transactions on Acoustics Speech and Signal Process,1979,27(2):13-120.
[3]陈欢,邱晓晖.改进谱减法语音增强算法的研究[J].计算机技术与发展,2014(04):69-71+76.
[4]Plapous C,Marro C,Scalart P.Improved signal-tonoise ratio estimation for speech enhancement[J].IEEE Trans Audio,Speech,Lang Process,2006,14(6):2098-2108.
[5]符成山.一种改进谱减法语音增强算法的研究[J].信息通信,2016(06):21-22.
[6]McAulay R,Malpass M.Speech enhancement using a soft-decision noise suppression filter[J].IEEE Trans Acoust Speech Signal Process,1980,28(2):137-145.
[7]Junqua JC,Reaves B,Mak B.A study of endpoint detection algorithms in adverse condition:incidence on a DTW and HMM recognizer[J].Proc Of European Conf on Speech Communication and Technology,1991,3(2):1371-1374.
[8]Martin R.Noise power spectral density estimation based on optimal smoothing and minimum statistics[J].IEEE Trans Speech Audio Process,2001,9(5):504-512.
[9]宁矿凤,王景芳.DCT域维纳滤波语音增强[J].计算机工程与应用,2015,51(8):226-230.
[10]Cohen I,Berdugo B.Noise estimation by minima controlled recursive averaging for robust speech enhancement[J].IEEE Signal Process Lett,2002,9(1):12-15.
[11]张君昌,刘海鹏,樊养余.一种自适应时移与阈值的DCT语音增强算法[J].西安电子科技大学学报,2014,41(6):155-159.
Speech Enhancement Based on Time Domain Filtering Multi-band Spectrum Subtraction
ZHANG Xiaoyu,LIU Yunqing,ZHAO Xin
(School of Electronic and Information Engineering,Changchun University of Science and Technology,Changchun 130022)
The traditional multi-band speech is enhanced due to the problem of the pole interaction between the various frequency bands,which leads to the unsatisfactory speech recognition effect.A method of multi-band speech enhancement in time domain filtering is proposed,clean speech is estimated by filtering unprocessed speech in the temporal domain into various equivalent rectangular bandwidth based subbands followed by discrete cosine transform(DCT)based spectral speech enhancement in each band using spectral subtraction and incorporates band-specific weighting factor obtained using respective band signal-tonoise ratio(SNR).It is observed that DCT-derived spectrum based temporal-domain multiband speech enhancement algorithm outperforms the existing techniques for car,babble,train,white,and factory noise in the 0–10 dB SNR levels.
spectral subtraction;multi–band;DCT
TN912.35
A
1672-9870(2017)04-0078-05
2017-06-05
吉林省科技攻关项目(20160204003GX)
张小宇(1990-),女,硕士研究生,E-mail:1179353525@qq.com
猜你喜欢
空间电子技术(2021年4期)2021-11-10 07:06:04
电脑知识与技术·经验技巧(2020年5期)2020-06-22 13:19:24
电子制作(2019年22期)2020-01-14 03:16:24
航天电子对抗(2019年4期)2019-06-02 08:22:44
测控技术(2018年11期)2018-12-07 05:49:02
电子测试(2017年15期)2017-12-18 07:18:51
系统工程与电子技术(2016年7期)2016-08-21 13:59:14
系统工程与电子技术(2016年2期)2016-04-16 05:16:50
西北工业大学学报(2015年4期)2016-01-19 03:31:55
电测与仪表(2015年12期)2015-04-09 11:44:50
