
基于信息熵的空间插值影响因素分析
2017-10-17 03:13樊子德刘慧敏
地理信息世界 2017年6期
张 成,樊子德,刘慧敏,邓 敏
(1. 中南大学 地理信息系,湖南 长沙 410083;2. 中国科学院 地理科学与资源研究所,北京 100101)
0 引 言
现阶段,空间数据被广泛应用于各类科学研究中,如气象及空气污染的监测,土壤成分及水文分析等[1-3]。然而,由于地形条件、技术手段和经济水平等因素的限制,一些地点的空间数据获取困难。此外,空间数据在采集时往往会存在缺失的现象,这都给数据的进一步分析带来了挑战[4-5]。为了估计缺失采样数据并且获得高精度空间表面模型,空间插值通过已有空间观测数据对待求点的属性值进行插补,最终得到供人使用的高精度表面数据。
目前关于空间插值的研究主要针对空间插值方法的优化,对于空间插值影响因素的研究较少,人们在使用插值方法时大多是主观选择,插值结果的分析具有许多不确定性。因此,空间插值影响因素的有效度量对于空间数据插值分析非常重要,对空间数据插值的算法选择,精度预估具有重要意义。
1 国内外研究现状及本文策略
国内外关于采样数据缺失的研究起步较早[6-7]。20世纪30年代,英国统计学教授Yates针对实验中出现的数据缺失,没有采用以往删除或忽略的方法,而是对缺失数据进行了估算处理[8]。1977年,Rubin等人首次提出针对缺失数据进行有效估算的EM算法,并在之后得到进一步扩展[9-10]。近年来,我国数据缺失的学术研究逐步展开,提出了许多相关研究方法,具有代表性的有:金勇进在1998年深入探讨了缺失数据插补中对辅助信息的利用[11],而庞新生则在2009年讨论了分层抽样条件下多重插补方法[12]等。
空间数据区别于一般的调查数据,是用来描述现实目标的形状大小以及位置和分布特征的数据。空间数据的不确定性可以分为以下几类:时域不确定性、属性不确定性、位置不确定性、逻辑一致性和数据完整性[13]。对于空间数据的不完备性分析,现有研究还较少,具有代表性的有:李正泉等针对反距离空间插值法(IDW)在实际运用中存在的缺陷,提出了一种调和反距离加权(AIDW)空间插值方式[14];刘新立等研究了空间不完备信息条件下的区域自然灾害风险评估[15];Simolo对空间数据的缺失行了分析,指出了缺失的两种应对方法[16];李序颖在2005年讨论了空间自回归模型的建立以及利用其对缺失值进行插补的方法[17]。Xu和Wang在2013年对我国历史气象数据进行了缺失的分析,并用PBSHADE方法进行了修复[18]。王劲峰等提出一种将研究区域分为采样层、分区层和报告层的三明治估计方法[19-20]。
分析现有关于空间数据插值研究可以发现,现有方法针对空间插值的影响因素并没有提出一个便于计算和分析的指标,多数只是从质的角度分析而缺少量化计算。另一方面,以往方法未能提出一整套框架来整合插值影响因素分析指标,计算往往不够全面。因此本文从空间数据的信息熵入手,从3个方面分析影响空间插值的因素,给出空间数据可插值性的信息熵计算框架。
2 基于信息熵的空间插值影响因素分析
1948年Shannon在他著名的《通信的数学原理》论文中指出:“信息是用来消除随机不确定性的东西”,并提出了“信息熵”的概念(借用了热力学中熵的概念),来解决信息的度量问题[21]。信息熵即为信源的信息选择不确定性的度量,也即为消除一定的不确定性必须获得与此不确定性相等的信息量。设X是一个信息源随机变量,它发出的信息对应概率为P1,P2,…,Pn,那么X的信息熵可以表达为:

式中,X为随机变量,Pi为输出概率函数,对数一般取2为底,单位为比特(bit)。从经典信息熵理论出发,已有许多研究将其应用到空间分析领域。Sukhov提出了统计学角度的地图信息量计算方法[22],随后刘慧敏等将信息熵用于度量地图信息量[23-24],李大军研究了空间数据的位置不确定性,通过引入信息熵建立了一系列不确定性模型[25]。
2.1 空间插值影响因素信息熵计算框架
地图描述的角度具有从元素层次到邻域层次再到整体层次的特点,从微观到宏观描述了空间数据的信息。其中,在元素层次,空间数据的采样点个数对空间插值有着正相关的影响;在邻域层次,不同空间数据的分布模式对应不同的插值模式,空间分布越均匀则可插值性越高;在整体层次,不同的插值粒度对插值有很大影响。并且这3个层次的信息来源是相对独立的。因此,本研究分别选取3个层次具有典型代表性的特征指标,求得所选取的特征指标值的大小,在此基础上计算地图上空间数据的信息量,进而分析空间插值的影响因素,研究的流程图如图1所示。

图1 本文研究流程图Fig. 1 The flow chart of this research
地图信息熵的大小由特征多样性和差异性决定,建立基于特征的空间信息熵计算模型,表达为:

式中,wi为特征w上第i个标准化的定量描述;I(X)为特征w产生的信息熵。在元素层次,空间插值的影响只需要考虑采样点自身的属性,即采样点密度对插值的影响。采样点密度越高信息熵越大,反之则信息熵越小;在领域层次,采样点空间信息熵的大小由采样点的分布范围和差异性决定;在整体层次,从宏观角度对采样点信息量进行度量,即插值粒度。
2.2 采样点密度对空间插值精度影响分析
采样点密度,即单位面积上采集的样本点数。采样点密度越高,越能准确地描述研究对象的空间分布特征,插值的准确性越高。但随着采样点密度的增加,计算复杂度随之增加,插值精度最终会收敛。将不同采样点密度监测数据计算插值结果的平均绝对误差(MAE)和均方根误差(RMSE)绘制成图,如图2所示。其中横轴为点数(n),即采样点个数,纵轴为MAE和RMSE。假设采样点空间均匀分布,采样点密度增加对插值精度带来明显的提高,当采样点密度达到一定程度后,采样点密度增加带来的精度提高明显降低直至平稳。采样点密度与插值精度直接相关,即采样点密度越高,插值精度越高。实际插值计算中,在采样成本和计算能力允许的条件下,采样点密度越高越好。

图2 采样点密度对插值结果精度影响图Fig. 2 The influence chart of sampling point density on interpolation accuracy
2.3 采样点分布对空间插值精度影响分析
采样点分布,即采样点在整个研究区域内的空间分布情况,对空间插值结果有着重要影响。采样点分布方式对空间插值结果的影响体现在采样数据对空间变异性和相关性上,对原始数据分别按照均匀、随机、不均匀(聚集)3种采样分布方式进行空间插值,计算插值结果的MAE和RMSE,并绘制折线图如图3所示。当采样点密度一定时,数据分布越均匀,越能更好地表现研究对象的空间分布特征。当数据分布不均匀时,难以表现整个研究区域的空间分布特征,同时会产生边界效应,这样往往造成插值结果的不合理。当采样点数据过多,出现数据饱和的情况下,可以随机选点进行插值,得出的插值结果精度依然可以达到要求。

图3 不同采样点分布插值结果精度图Fig. 3 The accuracy chart of interpolation results of diあerent sampling points distribution
2.4 插值粒度对空间插值精度影响分析
插值粒度即插值计算中的插值网格大小。根据空间插值的基本理论:位置越靠近的点,越可能具有相似的属性值;距离越远的点,属性值越可能有较大差异。插值粒度越高越能更好地逼近待求点的属性值,在原始采样数据相同时,插值粒度越大,插值结果的精度越高,并最终收敛于某一精度。随机选取一些采样点作为原始数据,按照不同的插值粒度进行普通克里金插值,插值结果精度如图4所示。插值粒度与插值精度直接相关,在一定范围内,插值精度随着插值粒度的增加得到有效的提高;另一方面,随着插值粒度逐渐增加,最终所带来的收益趋于平稳。

图4 不同插值粒度的插值精度图Fig. 4 The interpolation accuracy of diあerent interpolation granularities
3 实验算例分析
空间数据的可插值性取决于采样数据的不确定性。采样密度大,分布均匀,插值的不确定性小;采样密度小,分布随机甚至不均匀时,插值的不确定则大。信息熵指标对于不确定性问题的度量有明显的优势。为了验证本文方法的可行性,选取2013年12月至2014年11月北京市PM2.5浓度共35个监测站数据进行实验,35个监测站点按监测职能分为:城区环境评价点12个、郊区环境评价点11个、对照点及区域点7个、以及交通污染监控点5个,空间分布如图5所示。
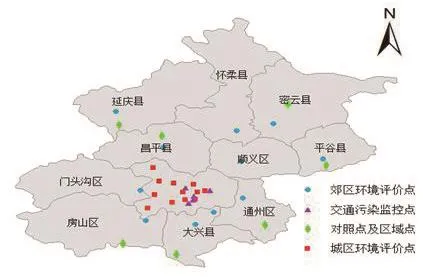
图5 原始数据分布散点图Fig. 5 The scatter of original data distribution
3.1 采样点密度和分布信息熵指标验证
本研究选取采样点分布密度作为度量指标,设采样点分布密度为A,按如下方法进行计算:首先根据不同采样点分布情况的采样点数据绘制Voronoi图,采样点分布密度A即为每一个Voronoi区域的面积Si和整个研究区域的总面积S的比值,表达为:A=Si/S,将其代入信息熵计算公式(1),可以得到采样点分布的信息熵计算公式为:
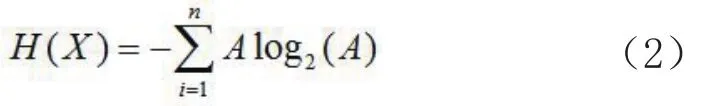
根据信息熵的定义,当事件出现的概率一样时,信息熵最大。因此信息熵的大小跟两点有关,一是采样点的密度,二是其分布情况。采样点密度越高,分布越均匀,则信息熵越大;反之则信息熵越小。将上述不同采样点密度和分布情况带入信息熵公式(2)中,为直观表示不同采样点分布计算结果,添加一组理想值数据,即采样点在研究区域中完全均匀分布,计算信息熵值并将得到的结果绘制成图,其中横轴为采样点数,纵轴为信息熵,如图6所示。
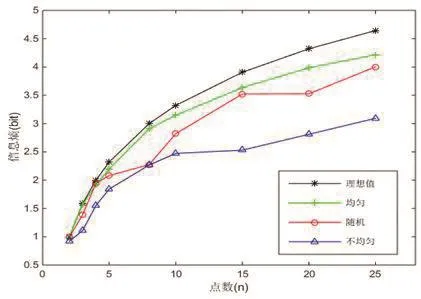
图6 采样点分布情况信息熵图Fig. 6 The information entropy diagram of sampling points distribution
由信息熵曲线可知,随着点数的增加,4种采样分布情况的信息熵逐渐增加。相同的采样密度下,理想值数据的信息熵都是最大的,其次是均匀分布的情况,再者是随机分布,不均匀分布的信息熵最小。对于相同的采样密度,3种采样分布情况的不确定性由小到大分别是:均匀分布、随机分布、不均匀分布。随着采样点点数的增加,信息熵增长速度逐渐变小,这主要有两方面原因:一是随着点要数增加,地图信息趋于饱和,信息量增长减缓;二是分布多样性也是影响地图信息量的因素之一,在实际操作中,无法保证采样点绝对的空间均匀分布。实际应用中,预设插值的信息熵大小,选取合适的采样点分布情况,不仅可以减少采样密度,同时也能保证插值结果的准确性。
3.2 最佳插值粒度选择
插值粒度是空间插值的指标之一,当无法直接获得待求点特征值的时候,用与待求点邻近的特征值代替是常用的方法。插值粒度越大,参与计算的相邻点越多,越可能得到距离待求点相近的特征值,可以减小偶然误差。选择合适的插值粒度的前提是,既要保证插值结果的准确性,也要考虑到计算量的关系。不同的插值粒度将整个研究区域平均分成若干部分,每一块的面积和研究区域总面积的比值为指标B,带入信息熵公式中得到公式(2),将计算结果绘制成如图7所示,具体步骤与上一实验相同。
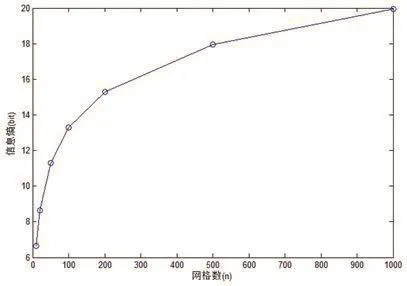
图7 插值粒度信息熵图Fig. 7 The information entropy diagram of interpolation granularity
随着插值粒度的提高,信息熵明显增加。插值粒度达到一定程度后,随着插值粒度的进一步增加,信息熵增加趋于平稳,最终收敛于某一点,其原因是插值密度达到一定程度后,特征距离过小,对于获得准确的特征点的帮助不大。随着插值粒度的增加,信息熵变大,不确定性变大,变量所包含的信息量变大,即插值粒度越大,越可能获取到待求点相近的特征值。另一方面,插值粒度越大,插值粒度的收益逐渐降低,计算量越大,对于计算机软件硬件的要求越高,所以在插值时需要选择合适的插值粒度。实际应用中,可以预先设定一个预期的信息熵值,然后对比分析得出所需要的插值粒度。
为了准确探讨本研究区域内PM2.5浓度插值在现有监测数据基础上的精确性,基于上述不同采样点分布和插值粒度信息熵指标结果,计算信息熵增长率如图8所示。由图8可以发现,不同采样点分布和插值粒度信息熵增长率随着采样点个数和插值粒度的增加逐步降低,最终趋于平稳。

图8 信息熵增长率图Fig. 8 The growth rate of information entropy diagram
根据信息熵增长率图收敛趋势,选取采样密度为10,插值粒度为100×100克里金插值方案对北京2014年4个季节进行插值。根据插值结果计算MAE和RMSE,统计结果见表1。

表1 全年插值结果精度Tab. 1 Interpolation results throughout the year
由表1可见,在选定插值方案下插值结果较理想,只有秋季插值结果较差,分析其原因是北京市秋季少雨和较冷的气象条件使得空气流动性差,污染物容易堆积形成雾霾,造成雾霾在秋季高发的状况。同时北京地势由西北向东南倾斜,南部地势低,大量污染物和水汽更容易在南部堆积,会对插值结果产生一定的偏差。总体而言,在现有监测条件和技术手段下,该插值方案在少量的采样点下能得到很高的插值精度,计算量小,可满足大部分北京市PM2.5浓度插值需求。
4 结束语
针对现有空间插值数据缺失的普遍情况,本文提出一种基于信息熵的空间数据可插值性评价方法。该方法以信息熵为参考指标,综合考虑不同采样数据的差异性,提出了一种空间数据可插值性的可行性指标。最后通过一组实际数据验证了本文方法的适用性。针对目前地理国情普查工作的开展,对连续的空间数据分析有着更高的要求,随着研究的深入,未来考虑将此方法扩展至时空插值研究,以及大数据环境下传统插值领域。
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01
西南石油大学学报(自然科学版)(2019年1期)2019-01-28
电子测试(2017年12期)2017-12-18
雷达学报(2017年6期)2017-03-26
测绘科学与工程(2016年4期)2016-04-17
电测与仪表(2016年10期)2016-04-12
电测与仪表(2016年14期)2016-04-11
池州学院学报(2015年3期)2016-01-05
电测与仪表(2014年11期)2014-04-04
测绘科学与工程(2014年2期)2014-02-27
