
面向链路比特流的未知帧关联分析
2017-10-13 22:12薛开平王劲松薛颖杰
电子与信息学报 2017年2期
薛开平 柳 彬 王劲松 李 威 薛颖杰
面向链路比特流的未知帧关联分析
薛开平*①柳 彬①王劲松②李 威①薛颖杰①
①(中国科学技术大学信息科学技术学院 合肥 230027)②(西南电子电信技术研究所成都 610041)
在电子对抗中,截获到对方的通信比特流序列之后,当链路协议类型未知时,现有的协议解析工具往往无法分析比特流所承载的有用信息。为了获取比特流承载信息,首先需要切分比特流得到链路帧。该文根据链路帧结构的一般规律,提出一种基于数据挖掘的比特流切分算法。通过频繁序列统计、关联规则分析以及关联规则整合,识别出比特流中标识帧起始的多重关联规则序列。测试结果表明,该算法能够从未知比特流中提取有效的切分标识,正确实现比特流切分。与同类基于数据挖掘的比特流分析方法相比,该算法复杂度低,输出结果唯一且可信度高。
链路比特流;未知帧;频繁统计;关联分析;切分
1 引言
目前的协议解析工具,如Wireshark, Tcpdump,能有效完成面向已知协议的解析工作。但在日益激烈的电子对抗中,侦听者所截获的通信比特流往往协议类型完全未知,此时面向已知协议的解析工具将不起作用。为了分析截获的比特流承载信息,关键的一步首先是对其进行切分而获得链路帧,在此基础上才能进行后续解析工作。面向链路比特流的未知帧关联分析旨在寻找一种方法,从完全未知的链路比特流中寻找能指示帧起始的序列标识,基于此对比特流进行切分获得链路帧,使后续对未知帧的解析成为可能。
由于缺乏关于链路协议的先验知识,导致面向链路比特流的未知帧识别和解析困难,目前国内外相关研究较少。文献[1]基于隐式马尔科夫模型,结合报文长度和到达时间间隔两种行为模式对应用协议进行分类。文献[2]提出一种基于多模式匹配的网络视频流分类算法。文献[3]基于载荷部分字节的编码,实现对混合流量按应用类型进行有效分类。然而文献[1-3]都只适用于对网络层以上的协议进行识别分类。文献[4-7]着眼于安全协议。其中,文献[4]提出了一种深度包检测和流检测相结合的针对加密流量的应用识别算法。文献[5]基于序列模式挖掘提取协议关键词序列,并结合密文特征解析安全协议格式。文献[6]提出了一种基于主体行为特征的安全协议会话识别方法。文献[7]利用随机性检测识别比特流的加密部分和未加密部分,但该方法分类粒度较粗,无法按帧切分比特流。此外,文献[8]提出了一种基于地址信息将未知帧分离为点对点数据的方法,但前提是已将比特流正确切分成帧。文献[9]借鉴数据挖掘中频繁集和关联规则的概念[10],但结果中存在冗余序列干扰。文献[11]可以识别标志帧起始的特征序列,但其输出中同样存在冗余序列,且在缺乏先验知识时无法验证输出是否正确。
本文基于链路帧结构的一般规律,通过频繁序列统计和关联分析获取二重关联规则集合,并利用关联规则有向图进行整合,获得多重关联规则序列,基于此进行比特流有效切分。本文的创新点包括:(1)利用有向图整合二重关联规则,得到唯一的多重关联规则作为输出结果,有效消除了输出结果的冗余;(2)提供了一种判断输出结果合理性的方法,为用户调整门限参数提供参考,确保最终结果正确可信。本文接下来的结构安排如下:第2节介绍未知帧关联分析的基本原理;第3节给出算法的具体流程;第4节给出算法的实际数据测试结果;最后对本文进行了总结。
2 未知帧关联分析原理
2.1链路帧结构特征
链路帧一般由帧头、数据段、校验和帧尾4部分组成,如图1所示。某些特定类型的链路帧可能省略其中某些部分,例如WiFi的控制帧不含数据段。

图1 链路帧一般格式
帧格式中帧头包含帧同步序列,以及地址域、控制域等常用域。同步序列是一个特殊的模式序列,用于使接收方能从接收的比特流中区分帧的起始与终止,一种链路协议的同步序列在通信过程中始终不变。地址域、控制域等常用域的长度以及在特定帧的帧头中的位置通常是固定的,因此这些常用域之间的相对位置固定,即存在固定位置差。与同步序列类似,它们也能起到辅助界定帧起止的作用。这种帧头结构的组成规律可以概括如图2所示,其中固定域是帧头中内容和位置均固定的比特字段,可变域的内容在通信过程中往往会发生改变。这种固定域和可变域间隔出现的帧头结构在各种链路帧中普遍存在,是从比特流中识别链路帧头结构的基础,寻找到帧头结构后就可以基于此将比特流切分成链路帧。

图2 链路帧头结构
2.2 相关定义和概念
为描述链路帧头部存在的固定序列及其位置关系,首先对比特流做一些定义。
频繁序列用于描述帧头部的同步序列和常用域。在缺乏关于比特流的先验知识时,以平均出现次数为基准,其中为待统计的序列长度,取值可变,理论上认为出现次数大于该值的序列是“频繁”的,但为了不过早排除帧头部的有关序列,实际操作时一般取。设置上限参数是为了限制参与后续分析的频繁序列数量,有利于提高算法效率。

(2)
3 未知帧切分算法
本文所提出的未知帧切分算法包括4个步骤:(1)设定频繁度门限区间,从比特流中筛选出满足频繁度要求的序列,然后两两考察频繁序列,寻找序列间的关联规则;(2)为充分考虑关联规则间的联系,将得到的所有关联规则按一定方式组织成有向图;(3)为有向图的序列节点分配坐标,整合参与形成有向图的二重关联规则,获得多重关联规则;(4)根据多重关联规则在比特流中出现的频率判断其合理性,根据判断结果调整频繁度门限区间,确保获得的结果正确可信。
3.1 频繁统计与关联分析
频繁统计通过对比特流中的序列计数,筛选出满足频繁度区间要求的序列参与后续关联分析[12]。传统单模式匹配算法[13,14]一次只能寻找一个特定模式序列,由于待统计的序列长度不一,每种长度又对应多个序列,利用多模式匹配算法[15,16]能够只扫描一次源数据找到多个模式,更适合比特流中的序列统计。结合比特流特征,将多模式匹配AC算法[17]稍作改进,可有效面向比特流进行频繁序列统计,扫描一次源数据即可得所有长度比特序列的计数[9],再从中选出满足门限要求的序列即可。
在链路帧承载的上层数据未知时,可假定帧头之外的帧数据段比特流是随机的。通常在链路帧中数据段远长于帧头,数据段大量的随机比特会干扰帧头固定序列的寻找。通过频繁统计得到的比特序列多数来自数据段,不能作为帧分界标识。根据对帧结构特征的分析可知,帧头固定序列间存在位置差固定的关联规则。由于数据段比特流具有随机性,来自数据段的序列成为频繁序列存在偶然性,且它们在比特流中出现的位置具有随机性,这种“伪频繁序列”之间存在关联规则的概率很低。因此可以认为,比特流中序列间位置差固定的关联规则一般来自帧头。
验证序列之间的关联规则需要首先计算序列位置差,对于任意两个频繁序列和,相对位置差为有和两种可能的顺序,必须对两种情况都进行验证。验证时取和中出现次数较少者作为基准,假定为,对每一个,计算与其距离最近且在其前面出现的的位置差,并确定是否有常数满足关联规则置信度要求;再计算与其距离最近且出现在其后面的的位置差,并确定是否有常数满足关联规则置信度要求[9]。验证流程如图3所示。
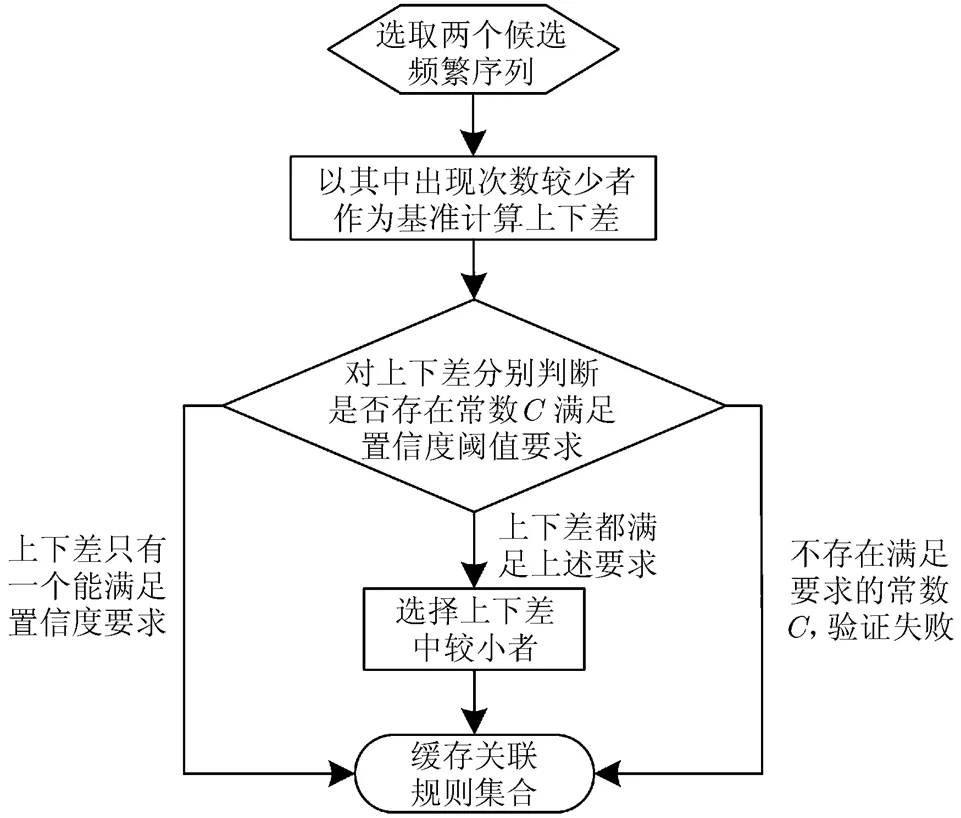
图3 关联规则验证流程
通过关联规则验证所得的是由若干关联规则组成的集合。在缺乏先验知识时,用户对集合中的关联规则依然无从挑选。为解决此问题,需要对集合中的关联规则进一步处理以获得唯一可信的输出。
3.2 关联规则有向图的生成
实验中发现,通过3.1节获得的集合中的关联规则之间会存在3种类型的联系:
(1)一条关联规则的后继是另一条关联规则的先导;
(2)两条关联规则存在公共的先导,此时两条关联规则的后继可能存在公共子序列;
(3)两条关联规则存在公共的后继,此时两条关联规则的先导可能存在公共子序列。
图4所示是关联规则之间3种联系的具体示例:图4(a)中序列既是关联规则的后继,又是关联规则的先导;图4(b)中关联规则与存在公共的先导,同时两条关联规则的后继和与先导间隔距离相差4 bit,的末尾与的开头存在长度为4 bit公共子序列0111;图4(c)中关联规则与存在公共的后继序列,同时两条关联规则的先导和与后继间隔距离相差3 bit,的开头与的末尾存在长度为5 bit公共子序列00001。

图4 关联规则之间的3种联系
关联规则之间的这些联系提供了通过生成有向图对关联规则进行整合的基础。
为充分发现集合中关联规则之间的联系,可将关联规则按如下方式组织成带权重有向图:(1)两个序列充当节点;(2)序列的前后顺序决定有向图边的方向;(3)两个序列位置的间隔比特数充当有向边的权重。按照此方式,作为示例,将图4中4条关联规则组织成如图5所示的有向图。

图5 关联规则有向图
3.3 由有向图生成多重关联规则
有向图生成后,为整合各关联规则,获得能作为比特流切分标识的多重关联规则,需要首先确定有向图各节点序列在多重关联规则中的相对位置。为了确定各节点序列的相对位置,可以将节点序列的第一个比特在多重关联规则中出现的位置作为节点坐标,通过节点坐标间的差值表示节点的相对位置。为了计算节点序列坐标,首先将有向图用邻接矩阵形式表示。设是有个顶点的有向图,其中表示顶点集合,表示边的集合,则的邻接矩阵可定义为有如下性质的阶方阵:
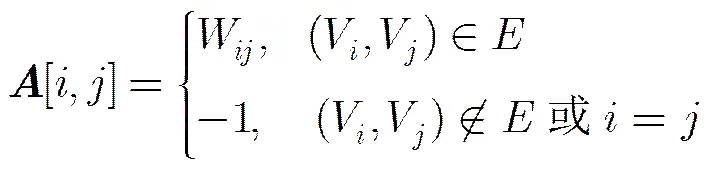
(4)
节点坐标只有相对意义,在计算坐标前,可任选一节点,为其坐标赋值0,再结合邻接矩阵即可计算出其余节点序列坐标。节点序列坐标计算过程如表1所示。

表1 有向图各节点坐标的计算

表2 节点坐标计算结果
根据节点序列坐标,可确定各节点序列在未知帧头部的顺序。实验中发现,计算坐标时会出现两序列坐标之差小于前一序列长度的情况。这是由于两序列存在公共子序列,此时需将存在公共子序列的两序列合并。如表2中=10100001,=00001100,坐标分别为-31, -28,两者坐标之差为3,小于的长度,末尾与开头存在公共子序列00001,这时将二者合并成序列10100001100,并将合并所得序列坐标设为(两者中坐标较小者)坐标即可。
合并完成后,根据合并后序列的长度和序列坐标计算相邻序列的位置间隔,即可得多重关联规则。由表2中的节点坐标计算结果,进行序列合并后所得多重关联规则如图6所示。
3.4 多种关联规则的合理性判断
获得多重关联规则后,可判断其合理性:若未知比特流中包含条链路帧,则帧头在比特流中也会出现次。通过3.1节的关联分析所得集合中的关联规则来自帧头,因此它们出现的次数一般会与相等,受帧数据段偶然出现的关联规则干扰,部分关联规则出现次数可能略大于。通过对3.1节所得集合中各关联规则出现次数,即式(1)中的取平均值来估测值,设所得平均值为。再统计所得多重关联规则在比特流中出现的次数,设为。若,则认为结果合理;若与相差过大(),则结果不可信,需调整重新分析。
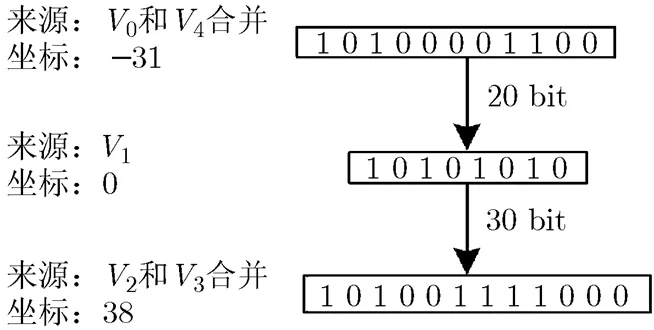
图6 多重关联规则
经过判断确定多重关联规则合理后,即可将其作为界定帧起始的标识切分比特流。
4 实验
本文采用实际数据对算法进行测试,使用Qt Creator 3.1.0平台实现所提出的算法,硬件配置为:Intel i5-2450M, 2.5 GHz,双核CPU, RAM 4 GB。
4.1 算法有效性验证
为验证算法的有效性,实验采用两组Wireshark实际抓获的数据集:Ethernet链路层数据,共1000个Ethernet帧,大小为1075 kb; WiFi链路层数据,共500个WiFi帧(382个数据帧,118个管理帧),大小为458 kb。为方便测试,测试中只统计长为8 bit的频繁序列,更长序列可以在此基础上通过序列合并获得。在1075 kb的Ethernet数据和458 kb的WiFi数据中,长8 bit的序列出现的平均次数分别为4300和1830。分别设定为(0.50,0.75)和(0.90,1.20),此时频繁度门限分别为2150-3225和1647-2196,置信度门限设为0.3。
实验结果如表3所示。可以看出,在数据量较大时,算法能够从中寻找到正确的比特流切分标识。

表3 Ethernet和WiFi数据测试结果
在原数据中进一步分析输出序列,以Ethernet数据集输出结果为例,确定输出序列在原数据帧中的相对位置及承载的含义,结果如表4所示:Ethernet数据集输出结果为6个长度不等的序列之间间隔若干比特的多重关联规则。最前面的序列“10101011”是Ethernet帧的特征序列,用于标识一个Ethernet帧的开始,后面的4个序列属于Ethernet帧头部源和目的MAC地址字段,最后一个序列属于Ethernet的IP负载首部IP版本号和长度字段。中间间隔比特位属于帧头部MAC地址字段,由于频繁度门限设置的原因被排除在频繁序列之外。基于这种来自Ethernet帧头的多重关联规则,方案可正确切分Ethernet比特流。
4.2 上下限比例参数对算法的影响

表4 算法输出结果承载含义

表5 频繁度门限区间对算法的影响
从表5可以看出,随着上下限比例参数差值增加,算法输出的多重关联规则序列长度增加,方案所耗时间增长。这是因为增大区间长度后,筛选得到的频繁序列更多,而方案所耗时间主要来自两两考察序列之间的关联规则,这部分的时间复杂度为(为频繁序列数目)。上下限比例参数差值增大后,结果可能包含错误信息。因为在上下限比例参数差值增大后,筛选得到的频繁序列更多,其中某些频繁序列可能在帧头不同位置出现多次,为不同位置的同一序列分配一个坐标导致结果出错。根据3.4节的合理性判断可发现这种错误,发现后适当缩小上下限差值即可。
为节省计算时间,在保证结果正确性的前提下,应选取尽可能短的频繁度门限区间。最短门限区间的具体取值(起点、终点)会受待分析的链路比特流数据的影响。在实际应用时,可结合3.4节的合理性判断,经过多次测试确定最短门限区间取值。根据实验经验,初次设置可取0.5作为门限区间中点,再经测试调整确定区间的具体取值。
4.3 与其他算法比较
文献[11]提出的比特流分割算法,输出结果是按出现次数降序排列的个关联规则。采用4.1节数据集,在设置关联规则置信度为0.9时,表6列出了算法输出中排名前5的关联规则序列(表中?表示间隔比特)。通过对比原数据分析,在Ethernet对应的输出结果中,第1位即为正确切分标志;WiFi数据对应输出的前5位中不含正确切分标志,正确标志最早出现在输出结果的第17位。在较大时,文献[11]能保证输出结果中包含正确比特流切分标志,但正确标志在输出中位置不定,缺乏先验知识时,用户对输出结果无从选择;在较小时,算法输出的个关联规则中可能不包含正确的切分标识,结果不可信。本文算法能提供唯一输出结果,有效消除输出中的冗余;同时根据3.4节的合理性判断与参数调整,可确保最终结果正确可信。与文献[11]相比,本文算法输出结果唯一且可信度更高。

表6 文献[11]算法输出结果
在与4.1节相同的数据集上,本文算法和文献[11]算法进行了运算时间的比较测试,实验结果如表7所示。由于算法的复杂度主要来自两两考察频繁序列之间的关联规则,文献[11]认为超过平均次数的序列均为频繁序列,未设置频繁度上限,需要考察的频繁序列数量超过本文算法,对相同的链路比特流数据,本文算法的处理效率高于文献[11]算法。

表7 不同算法运算时间比较(s)
以上实验结果表明,对帧头部存在位置差固定的关联规则的链路比特流,在设定合理门限后,算法能在相对较短的时间内获得有效的比特流切分标识,实现比特流切分。
5 结束语
对链路层截获的比特流数据,如何在缺乏先验知识的情况下获取其中承载的有用信息是一项重要的研究课题,分析有用信息的第1步要求正确切分比特流提取链路帧。本文分析了一般链路帧的帧格式特征,结合数据挖掘的关联分析方法,从未知比特流中寻找能作为未知帧切分标识的多重关联规则,基于此对未知比特流进行有效切分。最后结合实际数据,通过实验测试了方案的有效性,实验结果证明方案能有效寻找到比特流中标识帧起始的定界序列,为后续链路层数据的解析工作提供了支撑。当然方案还有改进的地方,例如频繁门限区间目前还需要多次测试后才能确定,如何自适应确定最佳频繁门限区间需要进一步研究;在切分比特流之后,如何在缺乏先验知识的情况下解析链路帧承载的信息也是下一步研究的重点。
[1] WRIGHT C, MONROSE F, and MASSON G M. HMM profiles for network traffic classification[C]. Proceedings of the 2004 ACM workshop on Visualization and data mining for computer security. ACM, Washington, D.C., USA, 2004: 9-15. doi: 10.1145/1029208.1029211.
[2] 孙钦东, 郭晓军, 黄新波. 基于多模式匹配的网络视频流识别与分类算法[J]. 电子与信息学报, 2009, 31(3): 759-762. doi: 10.3724/SP.J.1146.2008.00301.
SUN Q, GUO X, and HUANG X. Algorithm of network video stream recognition and classification based on multi-pattern matching[J].&, 2009, 31(3): 759-762. doi: 10.3724/SP.J.1146.2008.00301.
[3] 王变琴, 余顺争. 未知网络应用流量的自动提取方法[J]. 通信学报, 2014, 35(7): 164-171. doi: 10.3969/j.issn.1000-436x. 2014.07.020.
WANG B and YU S. Automatic extraction for the traffic of unknown network applications[J]., 2014, 35(7): 164-171. doi: 10.3969/j.issn. 1000-436x.2014.07.020.
[4] 高长喜, 吴亚飚, 王枞. 基于抽样分组长度分布的加密流量应用识别[J]. 通信学报, 2015, 36(9): 65-75. doi: 10.11959/j.issn. 1000-436x.2015171.
GAO C, WU Y, and WANG C. Encrypted traffic classification based on packet length distribution of sampling sequence[J]., 2015, 36(9): 65-75. doi: 10.11959/j.issn.1000-436x.2015171.
[5] 朱玉娜, 韩继红, 袁霖, 等. SPFPA: 一种面向未知安全协议的格式解析方法[J]. 计算机研究与发展, 2015, 52(10): 2200-2211. doi: 10.7544/issn1000-1239.2015.20150568.
ZHU Y, HAN J, YUAN L,. SPFPA: A format parsing approach for unknown security protocols[J]., 2015, 52(10): 2200-2211. doi: 10.7544/issn1000-1239.2015.20150568.
[6] 朱玉娜, 韩继红, 袁霖, 等. 基于主体行为的多方安全协议会话识别方法[J]. 通信学报, 2015, 36(11): 190-200. doi: 10.11959/j.issn.1000-436x.2015273.
ZHU Y, HAN J, YUAN L,. Towards session identification using principal behavior for multi-party secure protocol[J]., 2015, 36(11): 190-200. doi: 10.11959/j.issn.1000-436x.2015273.
[7] 邢萌, 王韬, 吴杨, 等. 一种提高链路层加密比特流识别率的新方法[J]. 计算机应用研究, 2015, 32(11): 3443-3447. doi: 10.3969/j.issn.1001-3695.2015.11.057.
XING M, WANG T, WU Y,. New method to improve identification rate of encrypted bit stream in data link layer[J]., 2015, 32(11): 3443-3447. doi: 10.3969/j.issn.1001-3695.2015.11.057.
[8] 郑杰, 朱强. 未知单协议数据帧的地址分析与研究[J]. 计算机科学, 2015, 42(11): 184-187. doi: 10.11896/j.issn.1002-137X. 2015.11.038.
ZHENG J and ZHU Q. Analysis and research on address message of unknown single protocol data frame[J].2015, 42(11): 184-187. doi: 10.11896/j.issn. 1002-137X.2015.11.038.
[9] 金凌. 面向比特流的未知帧头识别技术研究[D]. [硕士论文], 上海交通大学, 2011.
JIN L. Study on bit stream oriented unknown frame head identification[D]. [Master dissertation], Shanghai Jiao Tong University, 2011.
[10] WU X, ZHU X, WU G Q,. Data mining with big data[J]., 2014, 26(1): 97-107. doi: 10.1109/TKDE.2013.109.
[11] 王和洲, 薛开平, 洪佩琳, 等. 基于频繁统计和关联规则的未知链路协议比特流切割算法[J]. 中国科学技术大学学报, 2013, 43(7): 554-560. doi: 10.3969/j.issn.0253-2778.2013.07.006.
WANG H, XUE K, HONG P,An unknown link protocol bit stream segmentation algorithm based on frequent statistics and association rules[J]., 2013, 43(7): 554-560. doi: 10.3969/j.issn.0253-2778.2013.07.006.
[12] AGRAWAL R, IMIELINSKI T, and SWAMI A. Mining association rules between sets of items in large databases[C]. Proceedings of ACM SIGMOD International Conference on Management of Data. Washington, D.C, USA, 1993: 207-216. doi: 10.1145/170036.170072.
[13] KNUTH D E, MORRIS,J J H, and PRATT V RFast pattern matching in strings[J]., 1977, 6(2): 323-350. doi: 10.1137/0206024.
[14] BOYER R S and MOORE J S. A fast string searching algorithm[J]., 1977, 20(10): 762-772. doi: 10.1145/359842.359859.
[15] HONG Y D, KE X, and YONG C. An improved Wu-Manber multiple patterns matching algorithm[C]. IEEE Performance, Computing and Communications Conference, Phoenix, Arizona, USA, 2006: 674-680. doi: 10.1109/.2006.1629469.
[16] FAN J J and SU K Y. An efficient algorithm for matching multiple patterns[J]., 1993, 5(2): 339-351. doi: 10.1109/69.219740.
[17] AHO A V and CORASICK M J. Efficient string matching: an aid to bibliographic search[J]., 1975, 18(6): 333-340. doi: 10.1145/360825.360855.
Data Link Bit Stream Oriented Association Analysis on Unknown Frame
XUE Kaiping①LIU Bin①WANG Jinsong②LI Wei①XUE Yingjie①
①(,,230027,)②(,610041,)
In the electronic countermeasure, the opponent’s bit stream can be captured. However, without any knowledge about the type of data link protocol, the existing protocol analyzing tools can not analyze the useful information from the bit stream. To further get the carried information, the bit stream should be segmented to frames firstly. According to the general rules of frame structure, a bit stream segmentation algorithm is proposed based on data mining, in which, the multi-association rule indicating the beginning of frames can be identified by using frequent sequence statistics, association analysis and association rules integration. The test results show that, this algorithm can extract the valid segmentation flag from unknown bit stream and segment the bit stream correctly. Compared to the similar data mining based bit stream analyzing algorithms, this algorithm can be more efficient and produce a unique result which is of high reliability.
Data link bit stream; Unknown frame; Frequent statistics; Association analysis; Segmentation
TP393
A
1009-5896(2017)02-0374-07
10.11999/JEIT160289
2016-03-28;改回日期:2016-07-25;
2016-10-09
薛开平 kpxue@ustc.edu.cn
国家自然科学基金(61379129),中国科学院青年创新促进会人才基金(2016394)
The National Natural Science Foundation of China (61379129), Youth Innovation Promotion Association CAS (2016394)
薛开平: 男,1980年生,副教授,研究方向为下一代Internet网络、网络安全与分布式网络.
柳 彬: 男,1991年生,硕士生,研究方向为网络安全与协议分析.
王劲松: 男,1980年生,工程师,研究方向为大数据挖掘和数据可视化.
李 威: 男,1992年生,硕士生,研究方向为网络安全协议设计与分析.
薛颖杰: 女,1992年生,硕士生,研究方向为网络安全和加密技术.
猜你喜欢
汽车实用技术(2022年4期)2022-03-07
中国西部(2021年4期)2021-11-04
移动通信(2021年5期)2021-10-25
云南民族大学学报(自然科学版)(2021年3期)2021-06-24
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
四川师范大学学报(自然科学版)(2018年4期)2018-07-04
廊坊师范学院学报(自然科学版)(2017年3期)2017-10-11
数字通信世界(2017年1期)2017-02-13
湖湘论坛(2015年3期)2015-12-01
中国交通信息化(2014年3期)2014-06-05
