
一种降低DRAM系统刷新功耗的混合主存设计
2017-10-13 03:29赵彦卿薛晓勇林殷茵
复旦学报(自然科学版) 2017年3期
杨 凯,赵彦卿,徐 娟,薛晓勇,林殷茵
(复旦大学 专用集成电路与系统国家重点实验室,上海 201203)
一种降低DRAM系统刷新功耗的混合主存设计
杨 凯,赵彦卿,徐 娟,薛晓勇,林殷茵
(复旦大学 专用集成电路与系统国家重点实验室,上海 201203)
传统计算机体系结构中主存由动态随机存取存储器(DRAM)构成,而DRAM的刷新功耗随容量的增大而急剧增大.为应对这一问题,业界开始关注新型非易失性存储器(NVM).NVM具有掉电后数据不会丢失、不需刷新的优势,然而它们仍然处于研究阶段,单颗芯片的容量和价格不足以媲美DRAM,距离大批量投入商用仍有一段距离,因此,DRAM和NVM的新型混合主存结构被认为是下一代主存.本文提出一种Significance-Aware Pages Allocation(SA-PA)混合主存设计方案,通过将关键页分配到DRAM中,非关键页分配到相变存储器(PCM)中,采用DRAM和PCM并行结构,并采用Reset-Speed技术提高PCM的写速度,从而实现在不过分降低系统性能的前提下降低系统功耗的目的.结果表明,本文提出的SA-PA混合主存结构使得系统功耗平均下降25.78%,而系统性能仅下降1.34%.
动态随机存储器; 相变存储器; 混合主存结构; 刷新功耗; 页分配
传统的主存由动态随机存取存储器(Dynamic Random Access Memory, DRAM)构成,DRAM通过电容两边的电荷来存储数据,而电荷会不断泄漏,因此DRAM需要进行周期性刷新操作来保持数据完整.固态技术协会(Joint Electron Device Engineering Council, JEDEC)标准规定DRAM的刷新周期为64ms,即每隔64ms DRAM所有行需要完成一次刷新操作.因此,随着DRAM容量的不断增加,DRAM的行数也不断增加,这意味着需要以更短的刷新间隔,即更高的刷新频率完成DRAM的刷新操作;另外,随着工艺尺寸的微缩,DRAM存储单元的漏电问题越来越严重,刷新电流不断增大.当DRAM的容量达到64Gb时,刷新功耗几乎占到总功耗的50%[1].所以,DRAM刷新功耗的增大成为目前其面临的巨大挑战,如何降低DRAM刷新功耗成为业界研究的热点.
新型非易失性存储器(Non-Volatile Memory, NVM)包括相变存储器(Phase-Change Memory, PCM)[2]、磁存储器(Magnetic Random Access Memory, MRAM)[3]、阻变存储器(Resistive Random Access Memory, RRAM)[4]等,因其不需要刷新被认为是下一代DRAM的替代者.然而它们仍然处于研究阶段,单颗芯片的容量和价格与DRAM相距甚远,距离量产商用仍有一段距离,因此,DRAM和NVM的新型混合主存结构应运而生.混合主存结合了DRAM和NVM两者的优势,DRAM的速度快,而NVM无需刷新功耗且背景功耗小.本文提出了一种SA-PA(Significance-Aware Pages Allocation)混合主存设计,通过将关键页放在DRAM中,非关键页放在PCM中,采用DRAM和PCM并行结构,并采用Reset-Speed技术提高PCM的写速度,从而在系统性能微降的情况下实现有效降低功耗的目的.
1 研究背景
1.1PCM的基本结构和工作原理
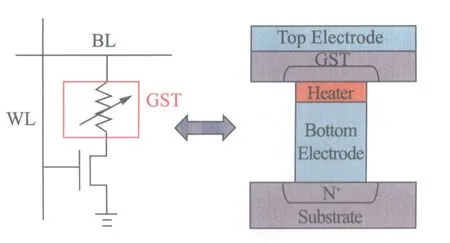
图1 PCM单元结构示意图[2]Fig.1 Illustration of PCM bit cell structure
PCM是一种新型的非易失性存储器,它是利用物质相的变化导致阻值变化来实现信息存储.其1T1R型存储单元结构如图1所示[2].WL(Word Line)表示存储单元的字线,BL(Bit Line)表示存储单元的位线.PCM中的“1R”由GST相变材料和加热电极(Heater)构成.当施加一个时间短而幅度大的电流(脉宽在10ns左右,幅度在200μA左右),Heater加热使温度升高到熔点以上,GST相变材料中有小部分熔化,中断电流后,GST相变材料快速冷却,凝固后停留在原子有序度很低的非晶态,此时“1R”表现为高阻,存储数据记为“0”;当施加一个时间长而幅度小的电流(脉宽通常为几十到100ns,幅度为几十μA),Heater加热使温度升高至晶化温度以上、熔点以下,GST相变材料开始结晶,原子有序度逐渐升高,最后转变成晶态,此时“1R”表现为低阻,存储数据记为“1”.对“1R”两端加一个小电压,根据电阻的高低即可读出所存储的数据.
1.2国际上已有的降低DRAM系统刷新功耗的方案
Liu等[5]提出了一种通过降低存储器局部刷新频率来实现系统低功耗的算法方案——Flikker算法.具体做法是将DRAM分为正常刷新(High Refresh)区域和低频率刷新(Low Refresh)区域,关键数据分配至正常刷新区域,非关键数据分配至低频率刷新区域,通过降低刷新功耗从而实现降低系统功耗的目的.Flikker算法如图2所示,程序编写者定义程序中的关键对象(Critical Objects)和非关键对象(Non-Critical Objects);当程序开始运行时,Runtime System将关键对象在缓存(Cache)中分配在关键页,将非关键对象分配在非关键页;然后操作系统通过虚拟地址-物理地址的映射,将关键页分配在DRAM的正常刷新区域,非关键页分配在低频率刷新区域.正常刷新区域采用JEDEC标准-64ms刷新周期进行刷新,确保关键数据的可靠性;低频率刷新区域以1s刷新周期进行刷新,大大降低了刷新功耗.
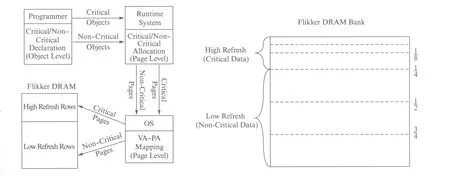
图2 Flikker系统示意图[5]Fig.2 Illustration of Flikker system
然而,Flikker方案存在以下2个问题:
1) 保存在低刷新频率区域的非关键数据可能会因无法保持而出错,从而导致程序出错;
2) 刷新频率越低,出错率越高,说明刷新功耗降低程度和出错率是互相制约的,因此Flikker方案能降低的功耗有限.
2 SA-PA混合主存设计
2.1SA-PA混合主存结构框图
为了解决Flikker方案中低频率刷新带来的出错率问题,本文提出一种共同SA-PA混合主存结构,如图3所示.混合主存由DRAM和PCM共同构成,内存控制器中包含DRAM Controller、PCM控制器以及定制分配器.应用程序中,关键对象和非关键对象由程序员定义;当应用程序被系统调用,Runtime System将关键对象分配至Cache中的关键页,将非关键对象分配至非关键页;当Cache和主存通信,操作系统通过内存控制器中的定制分配器将关键页分配到DRAM,将非关键页分配到PCM;同样的,当Cache要从主存中读取数据,若是关键数据则访问DRAM,非关键数据则访问PCM.
将非关键数据分配在PCM中,不仅可以有效地解决出错率的问题,而且由于PCM的特性,可从静态功耗与刷新功耗两方面降低系统功耗.然而,PCM取代部分DRAM也带来了系统性能降低的问题,因此在PCM控制器中加入响应序列(ReSp Queue),用来提高PCM的写速度.
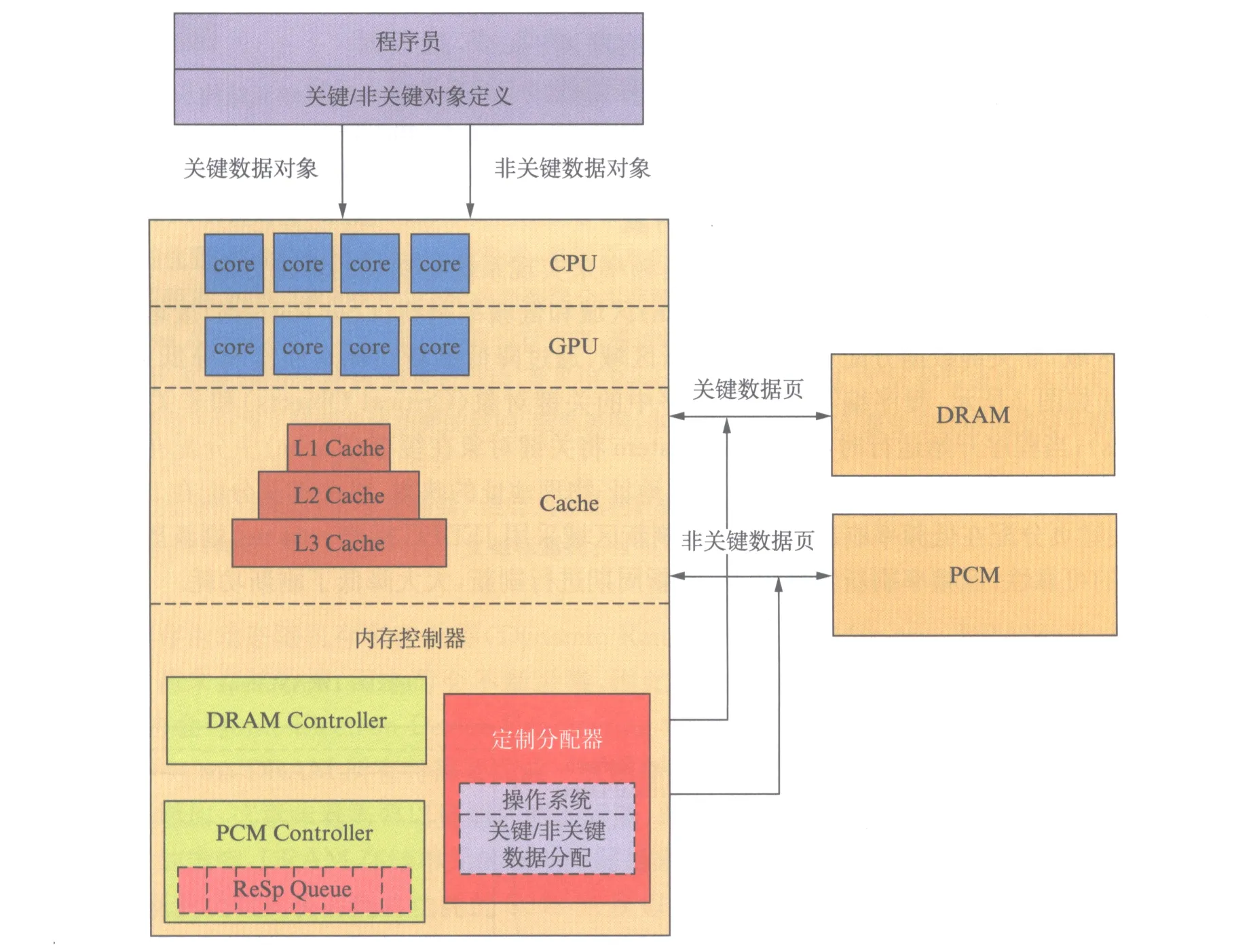
图3 SA-PA混合主存结构框图Fig.3 Diagram of SA-PA hybrid main memory architecture
SA-PA中Cache数据结构如图4所示.Valid是数据有效标识位,Valid=1表示该数据有效,否则无效;Dirty是数据改写标识位,Dirty=1表示该数据被改写,且还未写回到主存,Dirty=0表示该数据和主存中相应位置的数据保持一致;PRE和DONE标识位与提高PCM写速度的技术有关,具体在本文第4节说明,PRE=1表示CPU向PCM发送Reset-Speed命令,DONE=1表示PCM完成了Reset-Speed并反馈给CPU;CRIT是关键数据标识位,CRIT=1表示该数据是关键数据,需分配至DRAM中,CRIT=0表示该数据是非关键数据,需分配至PCM中.

图4 SA-PA结构中Cache数据结构Fig.4 Cache data structure in the SA-PA architecture
2.2SA-PA混合主存结构操作算法
图5是SA-PA混合主存结构的操作算法.如图所示,程序员预先在应用程序中定义好关键数据和非关键数据.程序加载后,如果系统收到读请求,分配器根据数据类型识别是否是关键数据;若是关键数据,则内存控制器将该读请求发送给DRAM,找到数据后将数据输出到总线,将数据读入Cache中的关键页,并将标识位CRIT置1;若是非关键数据,则内存控制器将该读请求发送给PCM,数据经过总线读入Cache的非关键页,并将标识位CRIT置0.如果系统收到写请求,分配器根据标识位识别是关键页还是非关键页;若是关键页,则内存控制器将写请求发送至DRAM,将相应的关键数据写入DRAM;若是非关键页,则内存控制器将写请求发送至PCM,将相应的非关键数据写入PCM.
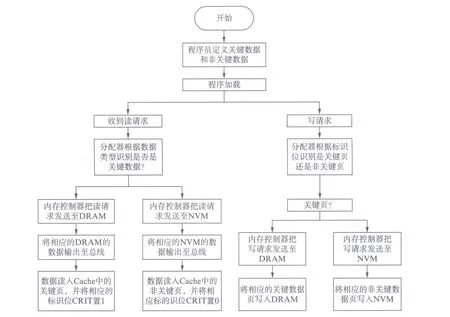
图5 SA-PA混合主存操作算法Fig.5 Operation algorithm of SA-PA hybrid main memory architecture
2.3关键数据和非关键数据划分
关键数据和非关键数据的划分是SA-PA算法中最为重要的问题.关键数据和非关键数据的比例越低,分配到PCM中的数据越多,那么系统功耗节省得越多,但是PCM的写速度使得系统的性能变差得越多,因此,系统的功耗和性能相互矛盾,两者如何折衷取决于关键数据和非关键数据的划分.
Flikker算法中[5]统计了几个常用程序的不同数据类型的内存占用量,如表1所示.内存空间分为代码(code)区、全局(global)/静态(stack)存储区、堆区和栈区、相应地,程序中的函数代码存放在代码区,全局变量、静态数据和常量存放在全局/静态存储区,动态变量存储在堆区,局部变量存储在栈区.局部变量根据其使用频率和周期,可以进一步分为Crit-Heap和Noncrit-Heap.
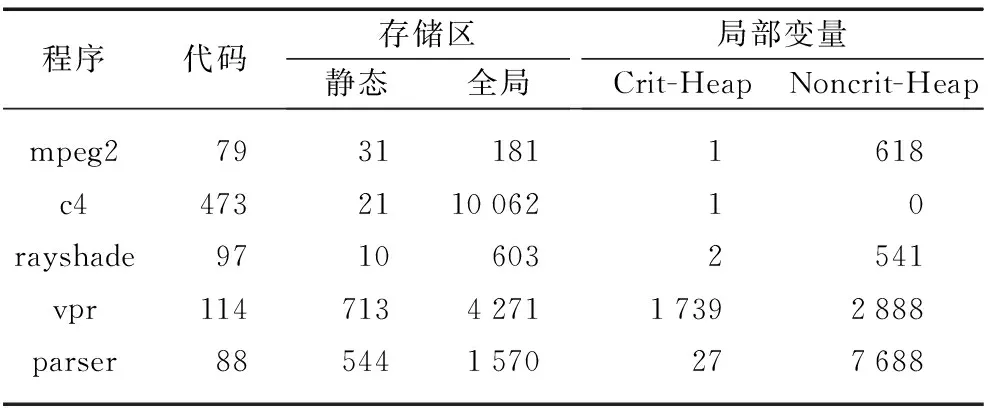
表1 不同数据类型的内存占用量[5](以4kB页为单位)
如表2所示,本文提出3种关键数据和非关键数据的划分模式: 高性能模式只将非关键堆数据划分为非关键数据,其他为关键数据;性能-功耗折衷模式将代码和全局数据中的全局变量划分为关键数据,其他为非关键数据;低功耗模式只将代码划分为关键数据,其他为非关键数据.根据表1,对各种不同的数据类型的内存访问量取平均值,估算得到关键数据与非关键数据的比例: 高性能模式为2∶1;性能-功耗折衷模式为1∶4;低功耗模式为1∶37.

表2 在SA-PA结构中关键数据与非关键数据的3种划分模式
3 SA-PA效果评估
基于Gem5+Dramsim2仿真平台对SA-PA方案进行效果评估,3种方案的参数配置如表3所示.Baseline采用40MB的DRAM,刷新周期为64ms;Flikker方案中设定关键数据和非关键数据比例为1∶4,正常刷新的DRAM容量为8MB,以64ms进行刷新,低频率刷新的DRAM容量为32MB,以1s进行刷新: SA-PA方案中评估性能-功耗折衷模式,设定关键数据和非关键数据比例为1∶4,DRAM容量为8MB,以64ms刷新,PCM容量为32MB,不需刷新.

表3 SA-PA方案效果评估仿真实验参数配置
采用SPLASH2测试程序集中的7个测试程序进行仿真: FFT、Radix、WaterSpatial、WaterNSquared、FMM、LUContig和OceanContig,并计算其平均值,SA-PA混合主存结构功耗仿真结果如图6所示.
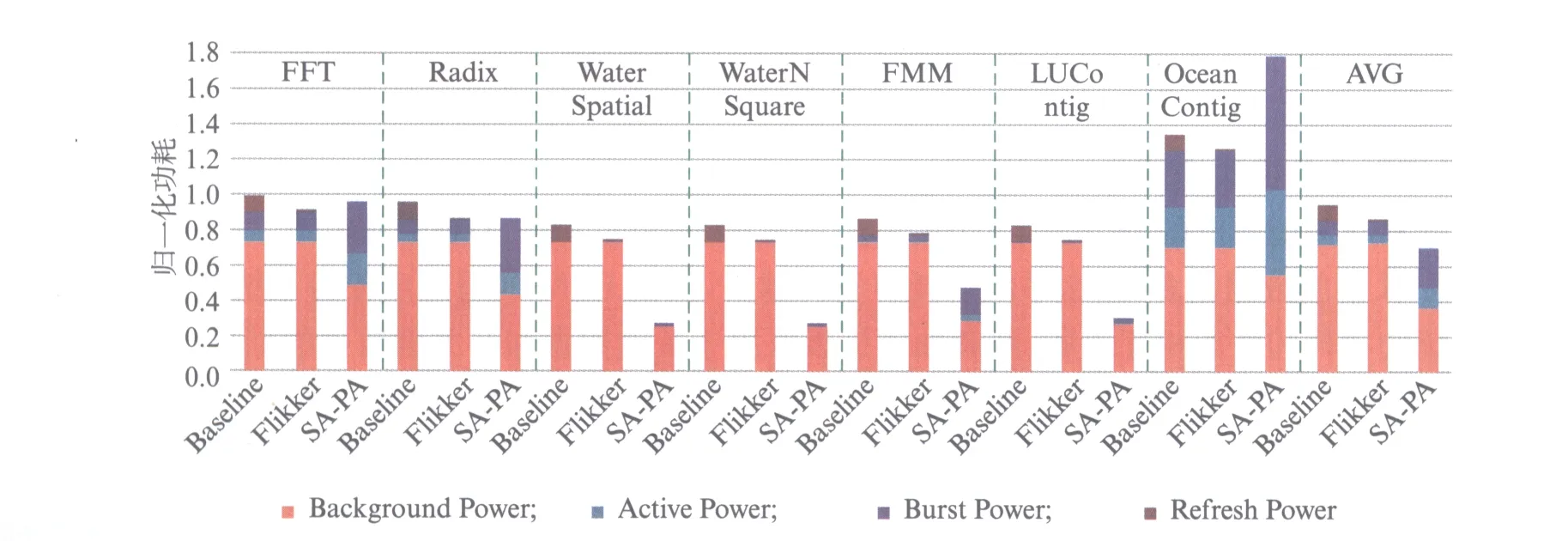
图6 本文提出的SA-PA混合主存结构功耗仿真结果Fig.6 Power simulation results of the proposed SA-PA hybrid main memory architecture
从仿真结果可以看出,SA-PA混合主存结构相比于Baseline来说功耗平均下降25.78%,而Flikker方案相比于Baseline功耗平均仅下降8.97%,SA-PA混合主存结构相比于Flikker方案功耗平均下降18.46%,这是因为Flikker方案仅仅减少了DRAM的刷新功耗部分,而SA-PA在无需刷新功耗的同时相比DRAM还降低了静态功耗.尤其地,对于WaterSpatial、WaterNSquared、FMM、LUContig来说,CPU对主存的访问较少,PCM的读写功耗较低,在这些特定应用环境中,SA-PA混合结构相比于Baseline功耗下降45.12%~67.42%.
SA-PA混合主存结构性能仿真结果如图7所示.系统性能由归一化CPI(Cycles Per Instrution,每条指令执行所需的时钟周期,并做归一化处理)来表征.从仿真结果可以看到,SA-PA混合主存结构相比于Baseline性能平均下降15.63%.由于刷新造成系统读写操作需等待,而Flikker降低了刷新频率,因此系统性能相比于Baseline提升0.28%.
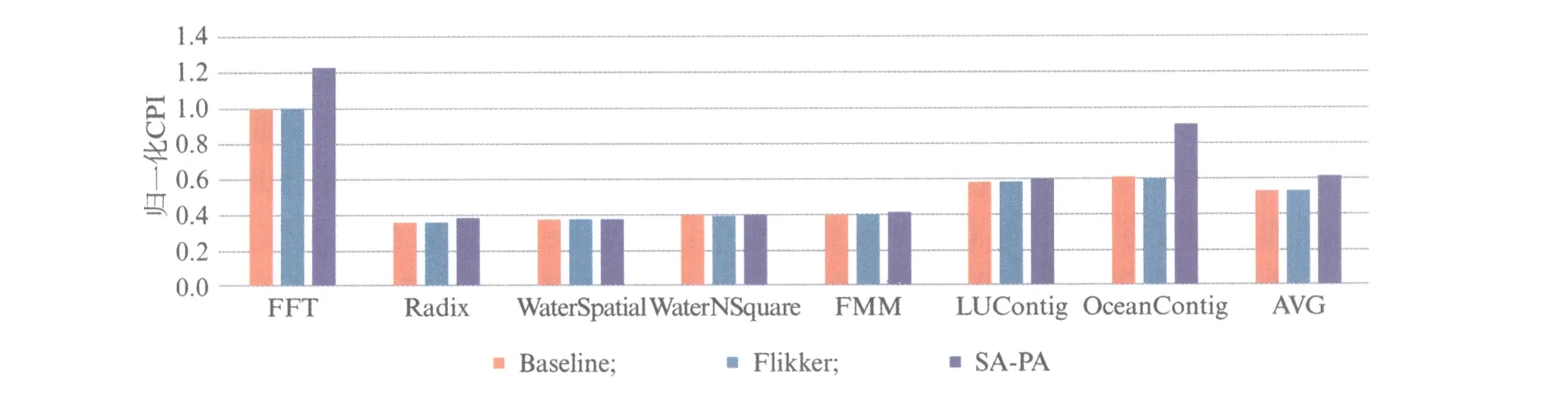
图7 本文提出的SA-PA混合主存结构系统性能仿真结果Fig.7 Performance simulation results of the proposed SA-PA hybrid main memory architecture
4 SA-PA中提高PCM写速度的方法
4.1采用Reset-Speed技术提高PCM写速度
由于PCM特殊的物理结构,PCM的Reset操作比Set操作的速度快得多,Set操作时间约为Reset的8倍[6].基于这一点,本文采用一种Reset-Speed(ReSp)方法用于SA-PA混合主存结构[7],来提高PCM的写速度,其结构框图如图8所示.
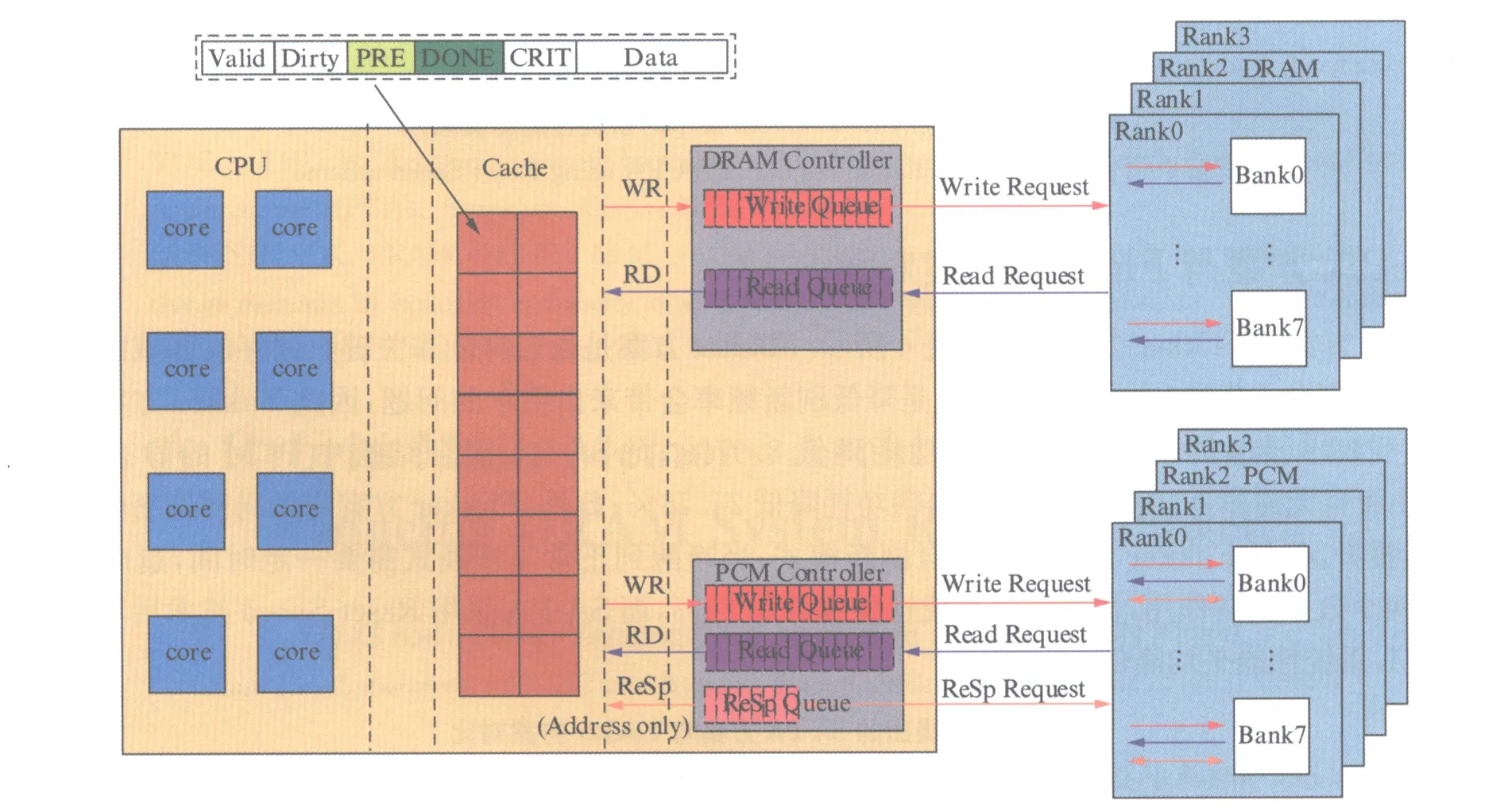
图8 在SA-PA结构中采用Reset-Speed技术提高PCM写速度结构框图Fig.8 Diagram of Reset-Speed scheme for improving PCM write speed in the SA-PA architecture
在PCM控制器中增加ReSp Queue, Reset-Speed操作发生在CPU对PCM访问的情况下,此时DRAM处于空闲状态.当Cache中的非关键数据(CRIT=0)被第一次被改写,Cache只需将该数据对应的地址传送给ReSp Queue,因此ReSp Queue比Write Queue和Read Queue都要小.然后PCM控制器向PCM发送Reset-Speed请求,并把ReSp Queue中的地址发送给PCM,PCM对相应地址的所有cell行全部进行Set操作,完成后反馈一个信号给CPU.随后CPU和Cache继续通信,CPU对Cache中的数据不断改写,但是因为相应的PCM行已经全部Set,所以此时无需再对PCM发送Reset-Speed请求,因此只有Cache中的非关键数据第一次被改写时,PCM控制器才向PCM发送Reset-Speed请求.当Cache中的非关键数据被驱逐,需要写回到PCM中,只需对需要写“0”的PCM存储单元进行Reset操作.因此,Reset-Speed操作时间的窗口是从Cache数据第一次被改写,到该数据被写回到PCM中.
极端情况下,当PCM控制器向PCM发出Reset-Speed请求,PCM正在进行Reset-Speed操作且并未完成,而此时Cache中相应数据被驱逐需要写回到PCM时,即Dirty=0、PRE=1、DONE=0,那么PCM控制器向PCM发送Reset-Speed中止请求和数据写回请求,立即将数据写回到PCM的相应位置.因此,Reset-Speed技术中,写操作的优先级高于Reset-Speed操作.
Reset-Speed操作隐藏在CPU与Cache通信过程中,而Cache对PCM的写操作只发生Reset操作,因此Reset-Speed技术提高了PCM的写速度,弥补了引入PCM带来的系统性能降低问题.
4.2Reset-Speed技术效果评估
SA-PA采用Reset-Speed技术的系统性能仿真结果如图9所示.SA-PA_noReSp表示没有使用Reset-Speed技术的混合主存结构,SA-PA_withReSp表示采用Reset-Speed技术的混合主存结构.从仿真结果来看,SA-PA_withReSp相比于SA-PA_noReSp提升了12.35%,相比于Baseline仅下降1.34%.
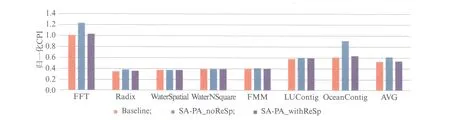
图9 SA-PA采用Reset-Speed技术的系统性能仿真结果Fig.9 Performance simulation results of SA-PA using Reset-Speed scheme
5 SA-PA方案与Flikker方案对比
SA-PA方案与Flikker方案对比如表4所示.Flikker方案是通过降低非关键数据存放区域的刷新频率,来降低该部分DRAM的刷新功耗,但是降低刷新频率会带来出错率的问题,因此Flikker方案中功耗降低程度受到出错率的限制,仿真表明功耗降低8.97%.而SA-PA混合结构中PCM的静态功耗比DRAM小而且无需刷新功耗,仿真结果表明功耗降低25.78%;此外,Flikker方案降低局部刷新频率造成系统性能提升,但是Flikker方案工作在自刷新模式,当唤醒到正常工作模式需要一定时间,造成系统性能降低,两个效果共同作用,仿真表明系统性能提升0.28%,而SA-PA采用Reset-Speed技术后写速度接近DRAM,系统性能平均降低1.34%.

表4 本文提出的SA-PA方案与Flikker方案对比
6 结 论
针对目前DRAM遭遇的刷新功耗问题,国际上提出一些应对方法,比如Flikker方案通过降低刷新频率来降低功耗,但是会带来非关键数据出错的问题,功耗降低程度受到数据出错率的制约而无法下降太多.本文提出一种Significance-Aware Pages Allocation(SA-PA)混合主存设计方案,具体做法是通过将关键页分配在DRAM中,非关键页分配在PCM中,采用DRAM和PCM并行结构,并且采用Reset-Speed技术提高PCM的写速度,从而在不过分降低系统性能的情况下实现降低功耗的目的.基于Gem5+Dramsim2仿真实验平台对所提出的SA-PA混合主存结构进行效果评估.仿真结果表明,本文提出的SA-PA混合主存结构使得系统功耗平均下降25.78%,而系统性能仅下降1.34%.
[1] LIU J, JAIYEN B, VERAS R,etal. RAIDR: Retention-aware intelligent DRAM refresh [C]∥International Symposium on Computer Architecture(ISCA). Portland, USA: IEEE Press, 2012: 1-12.
[2] WU X, LI J, ZHANG L,etal. Power and performance of read-write aware hybrid caches with non-volatile memories [C]∥Design, Automation & Test in Europe Conference & Exhibition(DATE). Nice, France: IEEE Press, 2009: 737-742.
[3] KIM W, JEONG J H, KIM Y,etal. Extended scalability of perpendicular STT-MRAM towards sub-20nm MTJ node [C]∥International Electron Devices Meeting(IEDM). Washington DC, USA: IEEE Press, 2011: 24.1.1-24.1.4.
[4] WEI Z, TAKAGI T, KANZAWA Y,etal. Demonstration of high-density ReRAM ensuring 10-year retention at 85℃ based on a newly developed reliability model [C]∥International Electron Devices Meeting(IEDM). Washington DC, USA: IEEE Press, 2011: 31.4.1 -31.4.4.
[5] LIU S, PATTABIRAMAN K, MOSCIBRODA T,etal. Flikker: Saving DRAM refresh-power through critical data partitioning[C]∥International Conference on Architectural Support for Programming Languages and Operating Systems(ASPLOS). London, UK: ACM Press, 2012,47(4): 213-224.
[6] YUE J, ZHU Y. Accelerating write by exploiting PCM asymmetries [C]∥High Performance Computer Architecture(HPCA). Shenzhen, China: IEEE Press, 2013: 282-293.
[7] QURESHI M K, FRANCESCHINI M M, JAGMOHAN A,etal. PreSET: Improving performance of phase change memories by exploiting asymmetry in write times [C]∥International Symposium on Computer Architecture(ISCA). Portland, USA: IEEE Press, 2012: 380-391.
Abstract: In traditional computer architecture, main memory consists of Dynamic Random Access Memory(DRAM), but DRAM refresh power consumption increases rapidly with increasing capacity. To address this problem, the industry began to focus on the novel non-volatile memory(NVM). NVM have advantages of data won’t lost after power down and no refresh, but they are still in the research stage, and single-chip capacity and expensive price isn’t comparable to DRAM, so there is some time to be commercially used in large quantities, therefore, the novel hybrid DRAM and NVM architecture is considering as the next generation main memory. This paper presents a Significance-Aware Pages Allocation(SA-PA) hybrid main memory architecture design. With DRAM and PCM parallel structure, SA-PA allocates the critical pages in DRAM, and the non-critical pages in PCM. Furthermore, Reset-Speed technology is used in SA-PA for improving write speed of PCM. Simulation results show that, proposed SA-PA hybrid main memory architecture reduce system power consumption by an average 25.78%, while performance of the system fell only by 1.34%.
Keywords: dynamic random access memory; phase change memory; hybrid main memory architecture; refresh power; pages allocation
AHybridMainMemoryArchitectureDesignforReducingDRAMSystemRefreshPower
YANG Kai, ZHAO Yanqing, XU Juan, XUE Xiaoyong, LIN Yinyin
(StateKeyLaboratoryofASICandSystem,FudanUniversity,Shanghai201203,China)
TN402
A
0427-7104(2017)03-0328-08
2016-05-30
杨 凯(1992—),男,硕士研究生;林殷茵,女,教授,通信联系人,E-mail: yylin@fudan.edu.cn.
猜你喜欢
现代装饰(2022年5期)2022-10-13
中老年保健(2022年1期)2022-08-17
北京航空航天大学学报(2022年7期)2022-08-06
中学生数理化(高中版.高考理化)(2021年6期)2021-07-28
数学小灵通(1-2年级)(2020年4期)2020-06-24
个人电脑(2016年12期)2017-02-13
电子制作(2016年19期)2016-08-24
电源技术(2015年11期)2015-08-22
中国卫生(2014年12期)2014-11-12
中国商人(2013年1期)2013-12-04
