
PORSC:融合用户个性化特征的在线评论情感分类模型
2017-10-13 03:35宋晓勇陈年生
复旦学报(自然科学版) 2017年3期
宋晓勇,吕 品,陈年生
(上海电机学院 电子信息学院,上海 201306)
PORSC:融合用户个性化特征的在线评论情感分类模型
宋晓勇,吕 品,陈年生
(上海电机学院 电子信息学院,上海 201306)
针对传统在线评论情感分类忽视了用户个性化的问题,提出了一种融合用户个性化特征的在线评论情感分类(PORSC)方法,该方法为每一类型用户构建一个在线评论情感分类器.PORSC模型由2部分构成: 一部分是具有学习评论中常见情感信息的全局情感分类模型;另一部分是能捕捉每种类型用户的个性化特征的特定用户类型分类模型.为解决PORSC模型在训练中的数据稀疏问题,引入多任务学习方法,以协同方式训练分类器,以并行方式解决了PORSC模型中参数的优化问题.通过在2个实际中文产品评论数据集和一个公开的英文评论数据集上实验,并与已有基线方法进行比较与综合分析,结果表明PORSC模型在一定程度上提高了在线评论情感分类的精度.
用户个性; 在线评论; 情感分类; 多任务学习
随着Web技术的发展,社会媒体上的主观性文本急剧增长.分析这些海量信息有广泛的应用,例如: 用户建模、个性化推荐、风险管理以及股票价格预测等[1-2].因此,主观性文本的情感分类已成为工业界和学术界研究的热点.近年来情感分类的研究成果主要从上下文知识、一词多义、主题间的关系等角度开展研究.
从上下文知识的角度,主要研究了3个问题: 1) 上下文信息的确定;2) 上下文信息的表示;3) 上下文信息如何与机器学习方法融合.例如: Wu等[3]定义微博中的词与词的关联、词与情感的关联为上下文,并将它们形式化为监督学习算法的一个正则项.Ren等[4]把一个tweet的回复、作者和该tweet所属主题作为上下文,以词嵌入向量的方式表示它们,并用神经网络模型学习上下文知识.文献[5]则在文献[6]的上下文基础上又增加了长距离的上下文,用二值特征0/1对这些上下文编码,最后用层次化的长期记忆(Long Short-Term Memory, LSTM)方法对tweet的上下文建模,该方法对长距离上下文建模效果极佳.
在一词多义方面,研究的主要思路是寻找词与其所在领域/主题之间的关系,旨在获取词的常见情感与特定情感.Wu等[7]基于多任务学习,提出了以一种协同方式为多个领域训练情感分类器的方法.该方法把每一个领域的情感分类器分解为2个组件: 通用组件和特定领域的组件.通用组件用于捕捉全局情感信息,并对其进行跨领域训练,以获得更好的归纳能力.特定领域的组件用该领域的标签数据训练,以获取该领域的专门的情感信息.然后,还研究了领域之间的2种不同关系: 基于上下文内容的领域间关系和基于情感词分布的领域间关系.用领域关系构建领域相似图,用正则项将领域间的相似性编码到特定领域的情感分类器中.文献[5]构建了2种神经网络模型: TEWE(Topic-Enriched Word Embeddings)和TSWE(Topic and Sentiment-Enriched Word Embedding),其目的是在情感分类中使用主题信息,以达到解决词在不同主题下可能具有不同情感极性的问题.高琰等[8]提出利用深度学习(Deep Learning, DL)方法自动建立产品评论的情感词典,实现了产品评论情感特征的自动提取,在一定程度上通过情感特征的语义关联解决了一词多义问题.
在主题间的关系方面,研究思路主要是考虑主题间的相对次序对情感分类性能的影响.文献[9]研究了主题之间的次序关系对情感分类的影响.首先,训练LDA(Latent Dirichlet Allocation)模型得到主题的概率分布,并对其进行降序排列;然后,用降序排列的主题分布构建主题共现矩阵;最后,用上面2个矩阵对测试样本进行正负情感极性分类.实验结果表明主题序列对情感分类有重要的作用.文献[4,6]在Twitter的情感分类中也研究了词与主题的关系,但其焦点是如何利用主题解决一词多义的问题.李超雄等[10]提出了一种主题情感混合模型,其目的是研究不同时间段内主题和情感的变化趋势.
分析以上已有研究工作可知: 1)它们都忽视了用户的个性化特征;2)除文献[8-9]研究对象为在线评论外,其他工作的研究对象都是微博.尽管文献[11]在情感分类中考虑了用户的个性化特征,但研究对象仍为微博.微博的鲜明特点是内容短、噪音多、主题多样化.本文的研究工作虽然与其类似,但研究对象为在线评论.在线评论与微博的最大区别在于在线评论的主题单一,内容长短不受限制,每个用户只需根据自己的体验发表意见,不存在微博中的响应现象.因此,只需要对每种类型用户的个性化特征建模,研究这些特征对情感分类器性能的影响,而不需要考虑每个用户的社会关系.
基于以上观察,本文提出了一种具有用户个性化特征的情感分类方法——个性化的在线评论情感分类(Personalized Online Reviews Sentiment Classification, PORSC)方法.该方法的核心思想是为每种类型用户构建一个个性化的在线评论情感分类器.该分类器由全局分类器和特定用户分类器2部分构成.其中,利用所有用户评论信息构建全局分类器,以获得所有用户共享的全局情感;以协同方式,利用每个特定类型用户的评论训练特定类型用户分类器,捕捉每类用户的个性化特征.为解决特定类型用户分类器的数据稀疏问题,采用了协同方式的多任务学习方法,应用文献[11]提出的加速分布式算法,以并行方式解决了PORSC模型中的优化问题.
1 具有用户个性化特征的情感分类

1.1具有用户个性化特征的情感分类模型
已知不同类型用户的评论信息和其对应的情感标签.构建具有用户个性化特征的情感分类模型的目的是训练一个鲁棒的全局情感分类器,捕获所有类型用户共享的情感;训练一个针对特定用户类型的情感分类器捕获不同类型用户的个性化特征.因此,根据以上思想,在所有训练样本集上的评价决策风险函数R如下式所示:
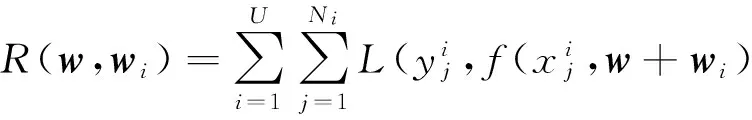
(1)
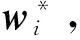
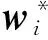
(2)
式中: ‖w‖2和‖wi‖2是L2范数的正则项,引入L2范数的目的是减少参数空间,避免过拟合;λ是非负正则项系数,用于控制正则化强度.通过式(2)的分解,w能较好地捕获全局情感信息,其分类结果不会受到某类用户偏见的影响,因而能使整个模型具有更高泛化能力.因此,在对用户类型没有任何先验知识的情况下,w能对未知类型用户的评论进行分类.此外,wi能更好地捕获每种类型用户的个性和喜好,并且不会受到全局情感信息引起的干扰.
1.2模型的等价变换
由于评论信息量大,单台计算机的计算能力和存储能力受到限制,因此,本文借鉴文献[11]的思想,采用他们提出的分布式加速算法让PORSC模型具有并行执行能力.基于此,按用户类型把评论分成N组,Un表示分组n的评论集,每一组数据用一个独立结点处理,独立结点既可以是一台计算机,也可以是一个CPU核.本文实验采用的是多核形式.
为实现PORSC模型的并行执行,为每一个分组n保持w的一个备份vn.于是,式(2)的优化问题可等价地表示为求式(3)满足一定约束条件的最小值:
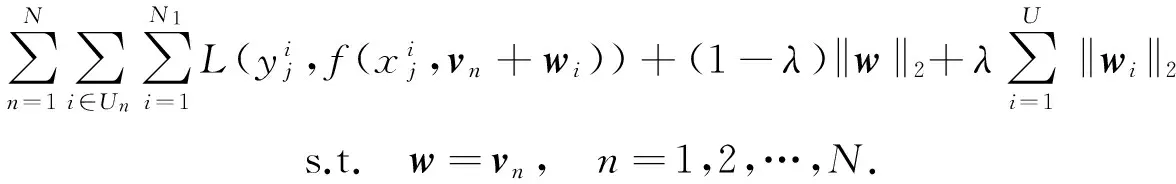
(3)
为了使用文献[11]的分布式加速算法,可将式(3)转化为如式(4)所示的带参数的拉格朗日函数τ:
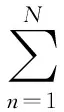
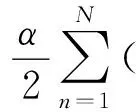
(4)
式中:un∈F×1是对偶变量;α为正惩罚系数;θ={w,wi,i=1,2,…,U}.按交替更新乘子法(Alternating Direction Method of Multipliers, ADMM)的思想[12],变量θ,vn和un在每一次迭代中必须按如下方式顺序更新:
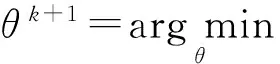
(5)
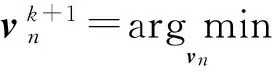
(6)
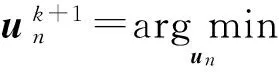
(7)
1.3模型参数的更新优化
对于参数集θk+1而言,w和wi分别由式(8)和(9)更新.由于w和wi的优化都是不平滑的凸问题,所以w的更新采用了近端算法[13].在并行更新wi时采用了文献[11]的方法:
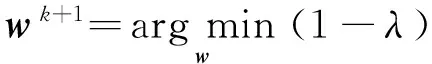
(8)
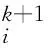
(9)
可在不同用户组上并行更新vn和un.在用户组Un中的结点vn可由式(10)更新,un可由式(11)更新:
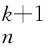
(10)
(11)
参数vn的更新也是一个凸问题.实验中使用平滑的分类损失函数L时,采用快速迭代的阈值收缩算法(Fast Iterative Shrinkage-Thresholding Algorithm, FISTA)进行优化[14].当使用不平滑的分类损失函数L时,采用子梯度下降法优化[11].
2 实 验
2.1数据集
本文选取了3个在线评论数据集作为实验语料.前2个数据集通过淘宝客的应用程序编程接口(Application Programming Interface, API),用iPhone 6和华为荣耀8作为查询爬虫得到.苹果iPhone 6的评论数据集记为Dataset1,华为荣耀8的评论数据集记为Dataset2.每个数据集中的用户类型先按性别分类,再按年龄段分类,共6类: 女性青年、女性中年、女性老年、男性青年、男性中年和男性老年.第3个数据集是英文书评数据集Book Crossing(http:∥www.informatik.uni-freiburg.de),这是一个推荐系统常用的公开测评数据集.使用该数据集的目的是观察PORSC模型在公开数据集上是否也具有优越性.数据集Book Crossing记为Dataset3.
Dataset1数据集包含78235条评论,Dataset2数据集包含64265条评论,Dataset3数据集中包含1048576 条评论.在数据集Dataset1和Dataset2的预处理过程中,先采用Jieba分词工具包对评论进行分词,然后用Bigram特征表示每一篇评论,每条评论的情感标签由人工标注.由于数据集Dataset3是已预处理好的数据集,表示用户情感的评论不是用文字描述,而是用0~10的整数表示,数字越大意味着用户对该书的评价越高.为了抽取数据集Dataset3中用户的特征,统计分析了与该数据集相关的用户年龄信息,结果发现阅读书箱的年龄段从高到低分别在18~35岁、35~45岁、45~60岁这3个年龄段,60岁以上的用户从网上购买书籍并阅读的人极少,实验中把大于5的评分作为褒义情感,小于5的评分作为贬义情感.实验中将这3个年龄段粗略分类为: 青年、中青年、中老年作为用户类型反映用户的个性化特征.从每个数据集随机选取10000条评论作为测试样本.在训练数据集上执行10-fold交叉验证,实现分类模型的参数选择.评估模型性能的标准采用分类的精确度.分类的精确度等于分类结果正确的次数除以测试数据的总数.
2.2模型有效性评估
为验证PORSC模型的有效性,主要观察: 同时对全局情感信息和特定用户类型的情感信息建模,PORSC能否改进在线评论情感分类的性能.为此,实现了PORSC模型的3个不同版本.它们分别是只有全局情感分类器的PORSC_Global;只有特定用户类型的情感分类器PORSC_Personlized;具有上述2种情感分类器的PORSC.分别在3个数据集上测试了以上3个版本,实验结果如图1所示.
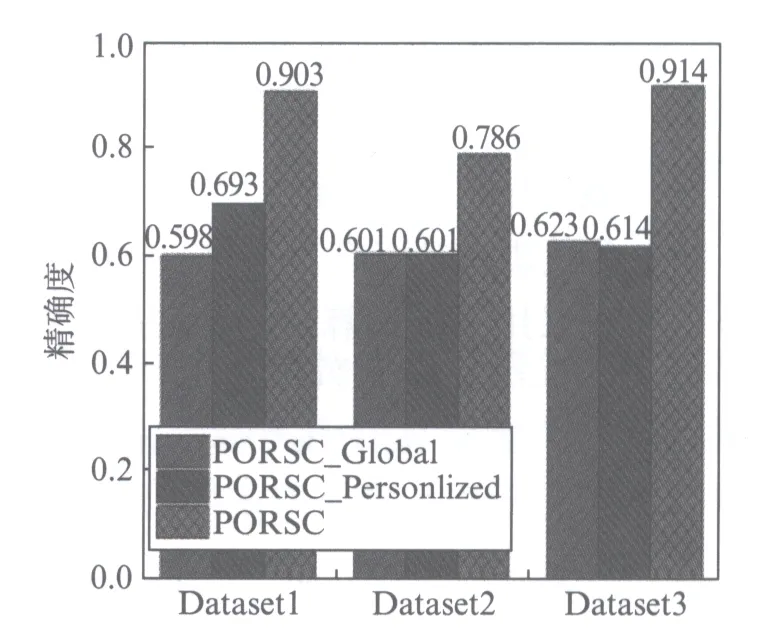
图1 3个不同版本PORSC模型的情感分类精确度Fig.1 Accuracies of sentiment classification based on three different versions of PORSC
从图1可知,PORSC_Global和PORSC_Personlized的情感分类精度在中文评论语料和英文评论语料上都不是很高,而将两者结合起来,能显著改进在线评论的情感分类精度.其中,PORSC模型在数据集Dataset3上的分类精确度要高于前2个数据集的精确度,这是因为书籍评论数据集的情感用数字表示,表示每条评论的特征数目只有4个,分别为用户名、书名和用户年龄、用户所在地区特征;而前2个数据集中每条评论首先需要分词,表示每条评论的特征由数据集对应的词典大小决定.由于实验只考虑了形容词、副词或部分动词表示的情感对分类的贡献,没有考虑名词表示情感的情况,所以导致前2个中文评论数据集中对分类有贡献的特征数目不固定.如果一篇评论用形容词或副词表示情感较少,而名词体现出来的情感也存在,则该评论被误判的概率较大;另一方面,针对某一句子,可能会产生不同的分词.因而,分词过程本身也会对分类精确度产生一定的影响.
2.3模型性能评估
参与模型性能评估的基线方法有: 支持向量机(Support Vector Machine, SVM)、最大熵(Maximum Entropy, ME)、逻辑回归(Logistic Regression, LR)、正则化多任务学习[15](Regularization Multi-Task Learning, RMTL)方法、具有l2,1范数正则项的多任务特征学习(Multi-Task Feature Learning withl2,1-norm Regularization, MTFL21R)[16]以及潜在因子模型(Latent Factor Model, LFM)的个性化情感分类[17].前3种参与比较的基线方法与后3种的区别在于后3种基线方法采用了并行方式.
SVM_Personlized, ME_Personlized和LR_Personlized分别表示在特定用户类型的数据集上训练和测试支持向量机、最大熵和逻辑回归这3种基线方法.类似地,基线方法SVM_Global, ME_Global和LR_Global分别表示在所有用户的数据集上进行训练和测试.PORSC_SVM, PORSC_ME和PORSC_LR表示本文提出的具有用户个性化在线评论情感分类器,它们分别使用了平方损失、hinge损失和对数损失.表1列出了所有方法在3个数据集上的实验执行结果.
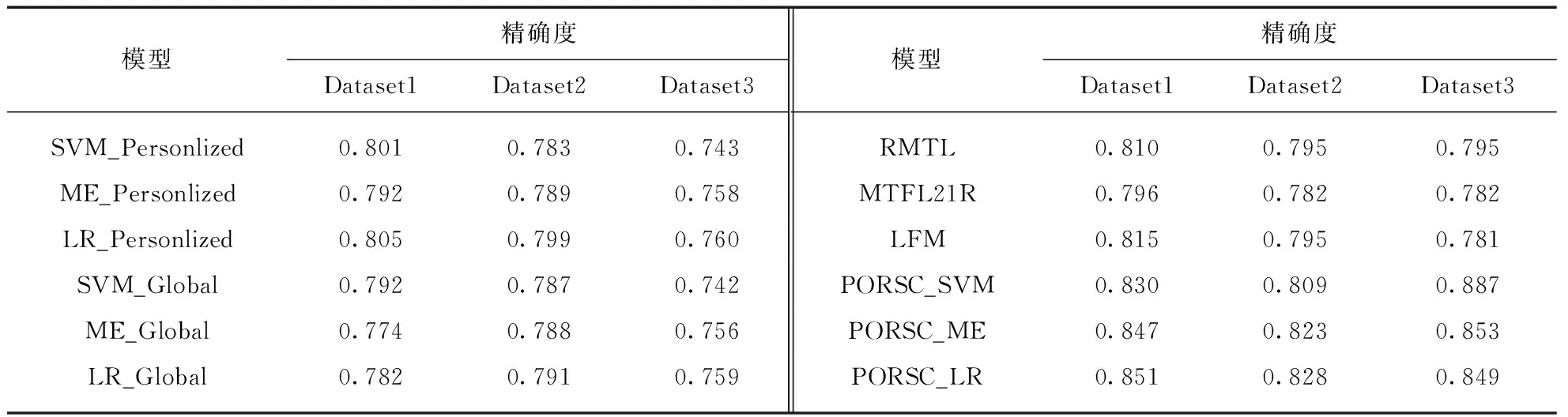
表1 不同模型在3个数据集上的情感分类精确度
观察不同模型在数据集Dataset1和Dataset2上的实验结果可知,PORSC_SVM, PORSC_ME和PORSC_LR都优于基线方法.这是因为: 1) 全局分类器不能捕捉每种类型用户的个性化特征.比如: 评论“iPhone6降价了”,对于青年学生类型用户,该评论表达的是一种正面情感,而对于投资者身份的青年类型用户,该评论在更大程度上表达的是一种负面情感;2) 在Dataset1和Dataset2数据集中,特定类型用户的情感分类器在训练过程有数据稀疏性问题.PORSC性能优于单个的全局分类器和单个的特定用户类型的情感分类器,是因为它能捕捉用户的个性化特征,同时还能利用不同类型用户共享的常见情感信息处理数据稀疏性问题.
观察不同模型在数据集Dataset3上的实验结果发现: 1) 模型SVM_Personlized,ME_Personlized和LR_Personlized与模型SVM_Global,ME_Global和LR_Global得到的分类精确度相差并不大.实验中前3种模型使用的特征分别是用户名、书名和用户类型(反映用户的个性化特征),后3种使用的特征分别是用户名、书名和用户所在地区.精确度相差甚微的结论说明了一个有趣现象: 用户的个性化特征能反映用户的居住区域,而且该结论与“25岁至35岁的人群在纽约地区购买图书较多”的规律十分吻合.2) 模型PORSC_SVM, PORSC_ME和PORSC_LR的分类精确度明显高于前面6种模型.这说明综合考虑用户个性化特征和用户所在地区能进一步提高个性化推荐的精度.
此外,PORSC还稍优于LFM、RMTL和MTFL21R.这意味着相比LFM,PORSC更适合于个性化的情感分类;相比已有的多任务学习方法,PORSC中的多任务学习更适合于个性化的在线评论情感分类.
2.4参数分析
本节分别在3个数据集上执行实验,探讨了PORSC模型中参数λ对PORSC模型性能的影响.参数λ控制了特定用户类型的个性化特征在PORSC模型中的相对重要性.图2给出了在3个数据集上的结果.

图2 参数λ的变化对3个不同版本PORSC模型的分类性能影响Fig.2 Performances of classification with respect to different λ values based on three different classifiers of PORSC
从图2可知,随着λ的增大,3个不同版本的PROSC模型的分类精确度先升高,后降低.模型在Dataset1和Dataset2数据集上的最佳λ值约为0.5,在Dataset3数据集上约为0.3.这说明当λ较小时,用户的个性化特征并没有完全体现,PORSC的性能不佳.随着λ的增大,PORSC的性能逐渐得到改进.另一方面,模型在Dataset1和Dataset2数据集上的曲线变化趋势较陡,当λ大约超过0.7时,可能由于过分强调用户的个性化特征,许多常见的情感信息丢失,性能又开始下降.对于Dataset3数据集,曲线变化趋势较平缓,在λ大约超过0.5时,分类精确度变化较小,这说明在该数据集中用户的居住区域在某种程度上也能反映用户的个性化特征.
2.5模型的时间复杂度
由于评论的数量巨大,因此,讨论模型PORSC中参数优化的时间复杂度非常重要.实验中使用Python实现参数w,wi,vn和un的加速更新算法,硬件使用Intel core i7和16GB内存.实验过程中,分别在一台计算机的1个核和5个核上分布各参数更新算法.实验结果取执行10-fold验证的平均值.图3显示了在3个数据集上,并行结点个数对模型训练时间的影响.
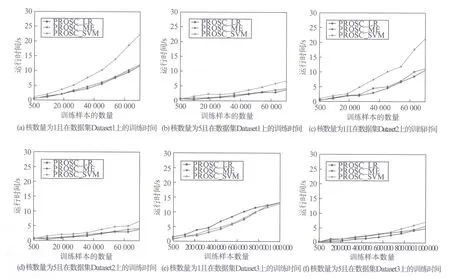
图3 不同的核数量与3个不同版本PORSC模型的运行时间的关系Fig.3 Relationships of between number of cores and running time of three different classifiers of PORSC
从图3可知,相比于1核,当同时在5核上并行执行参数更新时,算法运行时间更少.这意味着,整合更多的并行结点能加速训练过程.通过并行训练大量结点,分布式算法能有效减少PORSC模型的时间复杂度.此外,在PORSC模型中使用平方损失函数和对数损失函数的运行时间要少于hing损失函数的运行时间.这表明基于FISTA的参数更新算法对加速分布式算法的最耗时的步骤有加速作用.
3 结 语
本文研究了在线评论中不同用户的个性化特征对情感分类的影响.构建了一种个性化的在线评论情感分类(PORSC)模型.它由一个全局情感分类器与一个特定用户类型的情感分类器2部分构成.全局分类器用于学习在线评论中常见的情感知识,特定用户类型分类器用于学习不同类型用户的个性化特征.由于特定用户类型的数据具有稀疏性,提出以协同方式,同时训练多个不同类型用户的个性化情感分类器.为了改进PORSC模型的扩展性和有效性,借助于分布式算法实现模型的训练.在3个实际数据集上的实验结果表明PORSC模型能改进在线评论的情感分类精度.在此基础上,下一步的研究方向是如何把用户个性化特征建模结果应用于跨领域的情感分类问题.
[1] 高旸,周莉,张勇,等. 面向股票新闻的情感分类方法 [J].计算机学报,2010,2(S): 349-362.
[2] 赵传君,王素格,李德玉,等.基于分组提升集成的跨领域文本情感分类 [J].计算机研究与发展,2015,52(3): 629-638.
[3] WU F Z, SONG Y Q, HUANG Y F. Microblog sentiment classification with contextual knowledge regularization [C]∥29th AAAI Conference on Artificial Intelligence. Austin, USA: AAAI Press, 2015: 2332-2338.
[4] REN Y F, ZHANG Y, ZHANG M S,etal. Context-sensitive twitter sentiment classification using neural network [C]∥Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence. Arizona, USA: AAAI Press, 2016: 215-221.
[5] REN Y F, ZHANG Y, ZHANG M S,etal. Improving Twitter sentiment classification using topic-enriched multi-prototype word embeddings [C]∥Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence. Arizona, USA: AAAI Press, 2016: 3038-3044.
[6] HUANG M L, CAO Y J, DONG C. Modeling rich contexts for sentiment classification with LST [J]. MarXiv, 2016: 1605.01478v1[cs.CL].
[7] WU F Z, HUANG Y F. Collaborative multi-domain sentiment classification [C]∥2015 IEEE International Conference on Data Mining. Atlantic, USA: IEEE Computer Society, 2015: 459-468.
[8] 高琰,陈白帆,晁绪耀,等.基于对比散度-受限玻尔兹曼机深度学习的产品评论情感分析 [J].计算机研究与发展,2016,36(4): 1045-1049.
[9] SONG X L, LIANG J G, HU C C. Sentiment classification: A topic sequence-based approach [J].JournalofComputers, 2016,11(1): 1-9.
[10] 李超雄,黄发良,温肖谦,等.基于动态主题混合情感模型的微博主题情感演化分析方法 [J].计算机研究与发展,2015,35(10): 2905-2910.
[11] WU F Z, HUANG Y F. Personalized Microblog sentiment classification via multi-task learning [C]∥Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence. Arizona, USA: AAAI Press, 2016: 3059-3065.
[12] BOYD S, PARIKH N, CHU E,etal. Distributed optimization and statistical learning via the alternating direction method of multipliers [J].FoundationsandTrends®inMachineLearning, 2011,3(1): 1-122.
[13] PARIKH N, BOYD S. Proximal algorithms [J].FoundationsandTrendsinOptimization, 2013,1(3): 123-231.
[14] BECK A, TEBOULLE M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems [J].SIAMJournalonImagingSciences, 2009,2(1): 183-202.
[15] EVGENIOU T, PONTIL M. Regularized multi-task learning [C]∥KDD ′04 Proceedings of the teth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA: ACM, 2004: 109-117.
[16] LIU J, JI S W, YE J P. Multi-task feature learning via efficientl2, 1-norm minimization [C]∥UAI ′09 Proceedings of the Twenty-fifth Conference on Uncertainty in Artificial Intelligence. Arlington, Virginia, USA: AUAI Press, 2009: 339-348.
[17] SONG K S, FENG S, GAO W,etal. Personalized sentiment classification based on latent individuality of Microblog users [C]∥Proceedings of the 24th International Joint Conference on Artificial Intelligence.Buenos Aires, Argentina: AAAI Press, 2015: 2277-2283.
Abstract: Focusing on the issue that traditional sentiment classification models of online reviews usually omit the user personality, a model called PORSC was constructed for sentiment classification. The PORSC model contains two components, a global one and a user-specific one. The global classifier was used to learn the common sentiment knowledge shared by all users in online reviews. The user-specific classifier was applied to capture the user personality. To address the data sparseness problem in training for the PORSC model, the personalized sentiment classifiers of different kinds of users were trained in a collaborative way based on multi-task learning so that the parameters of the PORSC model can be optimized in parallel. The experimental results on two datasets from the real-life product online reviews and public English books reviews indicate that the proposed PORSC model can improve the accuracy of sentiment classification for online reviews effectively and efficiently.
Keywords: user personality;online reviews;sentiment classification;multi-task learning
PORSC:ASentimentClassificationModelIntegratingUserPersonalityforOnlineReviews
SONG Xiaoyong, LÜ Ping, CHEN Niansheng
(SchoolofElectronicInformation,ShanghaiDianjiUniversity,Shanghai201306,China)
TP311.5
A
0427-7104(2017)03-0359-07
2016-10-10
宋晓勇(1970—),男,实验师,E-mail: songxy@sdju.edu.cn.
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
文苑(2020年4期)2020-05-30
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
新闻传播(2018年12期)2018-09-19
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
汽车与新动力(2016年6期)2017-01-04
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
中国卫生(2015年1期)2015-01-22
