
大数据环境下数据挖掘在高校图书馆中的应用研究
2017-10-13 20:08严春来
网络安全技术与应用 2017年3期
◆严春来
大数据环境下数据挖掘在高校图书馆中的应用研究
◆严春来
(攀枝花学院图书馆 四川 617000)
随着大数据时代的到来,对海量数据的分析和处理以及提取可用信息是高校图书馆面临的新挑战。本文阐述了数据挖掘技术的内涵和技术背景,讨论了数据挖掘技术在图书馆中读者分析、个性化服务、馆藏维护与采访、书目推荐、离线数据分析等方面的应用。
图书馆;大数据;数据挖掘
0 引言
随着网络和数据库技术的发展,快速增长的海量数据收集、存放在大量数据储存库中,要理解和处理他们已经远远超出人的能力。目前大多数仍然依据传统的数据分析技术来分析这些数据,而呈PB级增长的海量数据堆积起来已经形成了“数据坟墓”,从而导致了“数据丰富,信息贫乏”的现状,这显然不能满足不断增长的社会需求。为了更好地理解和处理这些海量数据,找出其中潜在的规律和联系,以便指导决策,研究者们提出,知识发现(KDD)技术和数据挖掘(Data Mining,DM)方法可以达到这一目的。它们是强有力的数据处理方式,可以把海量数据转化成有用知识信息,从而跨越了数据与知识之间的鸿沟。当前,信息化、数字化、智慧化成为高校图书馆发展的主要方向,其职能也随之逐渐地发生变化,除传统的读者服务和教育职能外,正在成为读者提高、领导决策、学校发展的知识库,如何将数据挖掘技术应用于图书馆管理系统,从海量读者借阅数据信息中,发掘出其潜在的规律、关联,根据挖掘结果分析预测有关图书的需求情况,为师生提供更好地个性化图书服务,是高校图书馆工作者在新时期所面临的具体任务。
1 数据挖掘技术的背景与定义
1.1 数据挖掘的背景
1.1.1 数据挖掘的商业背景
数据挖掘首先是需要商业环境中收集了大量数据并要求挖掘的知识是有价值的。对商业而言,有价值主要表现在三个方面:降低开销;提高收入;增加股票价格。在商业运营中,数据挖掘主要用作以下四种工具:数据挖掘作为研究工具;数据挖掘提高过程控制;数据挖掘作为市场营销工具;数据挖掘作为客户关系管理CRM工具。
1.1.2 数据挖掘的技术背景
数据挖掘是八十年代,投资人工智能研究项目失败后,人工智能转入实际应用时提出的。它是一个新兴的、面向商业应用的人工智能研究。选择数据挖掘这一术语,表明了与统计、精算、长期从事预言模型的经济学家之间没有技术的重叠。数据挖掘技术包括三个主要部分:算法和技术、数据、建模能力。与数据挖掘密切相关的技术包括:机器学习、统计、决策支持系统、数据仓库、OLAP(联机分析处理)、DataMart(数据集市)、多维数据库等。
1.1.3 数据挖掘的社会背景
数据挖掘号称能通过历史数据的分析,预测客户的行为,而事实上,客户自己可能都不明确自己下一步要作什么。所以,数据挖掘的结果,没有人们想象中神秘,它不可能是完全正确的。客户的行为是与社会环境相关联的,所以数据挖掘本身也受社会背景的影响。
1.2 数据挖掘的定义
数据挖掘是一个新兴、交叉学科领域,根据 W. J. Frawley 等人的定义,数据挖掘即为从大量的、不完全的、有噪声的、随机的数据中提取含在其中的、人们事先不知道的、有用的信息和知识的过程。
1.3 数据挖掘的一般过程
数据挖掘技术的一般步骤为,首先对问题进行定义,然后收集该问题的数据并作分析处理,接下来编写并执行数据挖掘算法,最后对执行结果进行分析和评估。图1展示了数据挖掘的一般过程。系统的数据挖掘是一个不断循环、优化的过程。
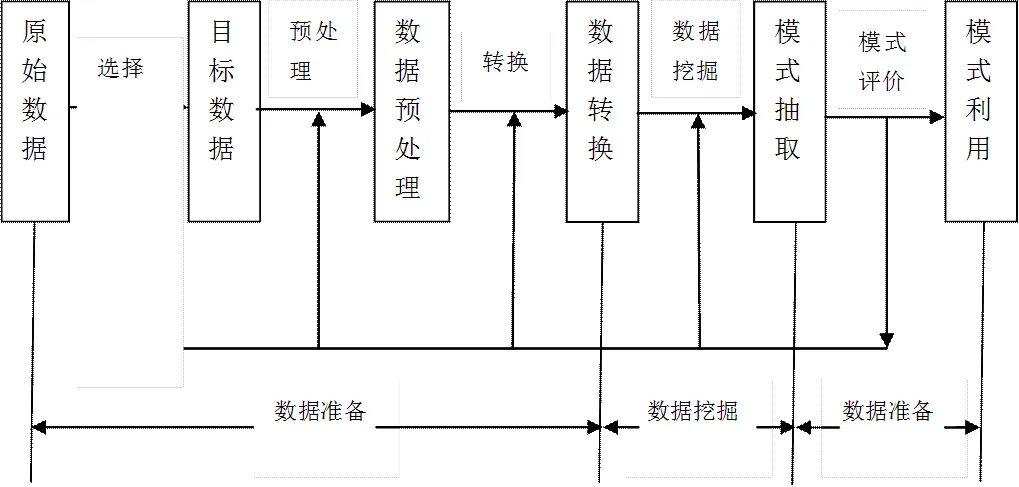
图1 数据挖掘一般过程示意图
2 数据挖掘相关技术
2.1 分类
分类是用一个函数把各个数据项映射到某个预定义的类,或者说是开采出关于该类数据的描述或模型。数据分类方法有决策树分类方法、统计方法、神经网络方法、粗集方法等。例如,利用当前借阅历史数据可以建立各种借阅行为的分类规则,对于新来的读者,根据其就可以知道此人的借阅意愿、兴趣。
2.2 频繁模式挖掘
频繁模式挖掘是在事务数据库(Transaction Database)中不同商品之间的联系规则,也就是在数据中频繁出现的模式,包括项集、子序列和子结构。
2.3 聚类
聚类是利用一些特征的组合来对样本作群体的分类,具体说就是把一组个体按照相似性归成若干类或簇。划分的原则是在同一个簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大,即为“最小化类间的相似性,最大化类内的相似性”原则。
2.4 时间序列分析
时间序列分析是一组按时间顺序发生的事件,研究者根据每一固定时间间隔的次序来记录事件结果,而时间序列数据最大的特点就是当中每一笔紧接着数据的记录时间间隔是相同的。如图书馆读者借阅的年度分布,股票市场固定时段价格变化,每月进出口贸易相关数字,每年人口出身率数字等分别为时间序列数据。
3 数据挖掘技术在图书馆中的应用
数据挖掘技术在高校图书馆中的应用涵盖了如下几个方面:个性服务与优化、内容评价、社区构建、绩效评价、采购优化(文献资源建设)、内部工作流程优化、用户行为分析、用户评价、知识发现和利用。
3.1 读者分析
数据挖掘在读者分析中包含三个方面:(1)统计分析:以统计的方式对数据仓库的数据进行分析,找出借阅率高的书籍跟借阅率高的读者,并分析代表的意义。(2)分类分析:利用借阅记录及读者信息库,分析读者的不同群体间借阅行为的差异,以了解读者的行为模式。(3)孤立点分析:学校图书馆服务全体读者,对于特殊需要用户,也要有所照顾。
3.2 个性化服务
一是做关联规则分析,从借阅记录库中找出读者借阅图书的共通性,进而推荐相关图书给读者。二是做时间序列分析,读者借阅馆藏时,可能会先借入门的书籍再借深入的书籍,如果把这些借阅的顺序特性找出来,下次读者借阅时主动推荐给读者。
3.3 馆藏维护与采访
利用聚类分析,找出不同群体之间不同的借阅行为,挖掘出每个群体间普遍出现的书籍类型,并把此做为图书采购的参考依据。不同的季节,会有不同的借阅行为,或者因为期末考试等。都会出现不同的借阅习惯,找出这样的规则,可以根据时段将某些图书放在显眼的位置或者加以推荐。
3.3 馆藏书目推荐
通过收集、加工和处理涉及用户借阅行为的大量信息,确定特定借阅群体或个体的兴趣,进而推断出下一步的消费行为,并以此为基础,对所识别的借阅群体进行特定内容的定向推荐。书目推荐服务由两个模块构成:书目检索模块和书目推荐模块。
3.4 离线数据分析中心
离线数据分心中心可以做如下基础数据挖掘:动态数据,包括读者构成属性、文献流通方式、读者借阅行为、读者信息行为的变化趋势分析;日志数据,包括在线情况、时段分析、关键字分析、来路分析、受访分析、访客详情、用户忠诚度分析;用户数字资源使用行为趋势分析、用户信息服务模式变化趋势分析;各种服务系统数据,针对各种服务系统,进行数量统计、时间序列分析等,根据系统特点,对用户使用情况、数据对象进行挖掘;事实数据,包括馆藏分布、人力资源、资金使用、设备配置等变化趋势分析。
4 结语
大数据时代,一方面给我们提供了海量的信息资源,无疑会给我们的读者服务提供足够的资源保证。另一方面,大量的冗余数据、垃圾数据给我们的收藏以及信息的开发带来了相当大的困难。因此对用户行为分析将有效提高图书馆服务质量,数据挖掘技术是改进图书馆工作有效的方法。数据挖掘是一个长期的过程,高校图书馆应该在数据挖掘方面持续地开展研究和实践。
[1]陈京民.数据仓库与数据挖掘技术[M].北京:电子工业出版社,2002.
[2]曾春,邢春晓,周立柱.个性化服务技术综述[J].软件学报,2002.
[3]董云鹏.数据挖掘技术在图书馆中的应用[J].现代情报,2006.
[4]赵嘉凌.数据挖掘在数字图书馆中的应用研究[J].计算机与网络,2010.
[5]郑建明,钱鹏.国内数字图书馆建设模式研究--以国家数字图书馆与中国高等教育数字图书馆为例[J].大学图书馆学报,2011.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
当代陕西(2019年14期)2019-08-26
小太阳画报(2018年1期)2018-05-14
中学数学杂志(初中版)(2016年5期)2016-11-01
信息通信技术(2015年6期)2015-12-26
导航定位学报(2015年2期)2015-06-05
小天使·一年级语数英综合(2014年8期)2014-06-26
智能系统学报(2013年1期)2013-01-28
