
基于基本块指纹的二进制代码同源性分析
2017-10-13 20:08刘露平
网络安全技术与应用 2017年3期
◆颜 颖 方 勇 刘 亮 刘露平 贾 鹏
基于基本块指纹的二进制代码同源性分析
◆颜 颖 方 勇 刘 亮 刘露平 贾 鹏
(四川大学电子信息学院 四川 610065)
二进制代码同源性分析在代码的专利保护和恶意代码溯源分析中有重大意义,本文提出了一种基于基本块指纹的、以更细粒度的对比分析算法来确定二进制代码同源性的方法。该方法从基本块中提取三个指纹信息:跳转逻辑特征、代码序列特征和子函数名特征,将基本块的控制流程图根据跳转逻辑表示成由0、1构成的序列以计算基本块跳转逻辑特征的相似度,利用基于滑动窗口的点距阵方法计算代码序列特征的相似度,并用Levenshtein Distance算法计算基本块子函数名特征的相似度,最后综合计算出二进制代码基本块的相似度,从而进行二进制代码同源性分析。实验结果表明,三种指纹信息的综合对比分析能有效区别基本块的异同,进行二进制代码基本块的同源性分析。
二进制;指纹;同源性比较;控制流程图;代码序列
0 引言
近年,无论是甲骨文公司起诉谷歌非法使用自己的多行Java代码事件,还是银行SWIFT系统被攻击后,安全团队根据恶意代码追查背后的攻击者,无不显示出分析代码同源性在实际应用中的重要性。二进制代码同源性的分析不仅能鉴别代码作者是否有抄袭行为以维护知识产权,而且能对恶意代码的家族进行聚类[1]以追溯和确定恶意代码的作者或组织。
在现有的代码同源性分析技术研究中,大致分为基于源码和基于二进制代码的同源性分析技术两个方向。
基于源码的同源性分析的依据有四类:基于语义的相似性、基于编程风格的相似性、基于文本的相似性以及抽象语法树的代码同源性鉴别技术。基于文本的相似性检测方法比较简单,易于操作,缺点但该方法忽略了源代码本身的语义特征,代码抄袭者很容易利用这一点逃过鉴别,漏检率较高。基于编程风格的检测方法需要利用模块检测方法确定克隆的位置,这会导致耗费大量人力而难以实现自动化,可行性较差。而基于抽象语法树的检测方法是依靠语法分析生成属性存储结构,保存树节点相关信息再进行比对,该方法技术实现复杂,理论上有很大误检可能。
基于源代码的同源性分析技术的首要条件就是要有完整的源代码,但实际运用中由于企业知识产权和专利的保护,源代码是不会公开的。因此基于二进制代码的同源性分析技术的重要性便显现出来。
现阶段的二进制代码同源性分析技术中,基本以控制流程图的特征[2]来进行同源性的分析。崔宝江等分别提出了“基于基本块签名和跳转关系的二进制文件比对技术”、 “二进制文件同源性检测的结构化相似度计算”和“基于特征提取的二进制代码比较技术”。这些方法阐述的基本策略是:提取反汇编代码后的代码基本块,用小素数乘积法[3]对基本块处理后对264取模的值作为基本块的指纹签名;用基本块的出入度表示该基本块的调用频率;用基本块中子函数调用次数表示该基本块的活跃程度;用IDA插件提取代码基本块的控制流程图;最后综合两个代码基本块的控制流程图和指纹签名及出入度和子函数调用频率的吻合度来确定这两段代码的相似性和同源性。该策略中小素数乘积法克服了代码重排对签名的影响,但是在应用过程中素数的乘法增长快、开销大,在考虑效率的情况下,基本块内的语句最好在14条以内[4],适用性受到限制。
以上所述的方法都是针对于整个文件的比对结果来确定相似度和同源性的,比对方法中涉及的都是基本块与基本块的关系。但是在如今的恶意代码的分析工作中,经常遇到一个恶意程序只是引用或借鉴了已知恶意程序的某一功能模块,如果用整个文件的匹配度来确定两个代码文件的同源性,往往会因漏报而降低正确率。由此,本文提出了一种针对于基本块的内部指纹、以更细粒度的对比分析方法来进行二进制代码同源性的度量。
1 二进制代码同源性分析算法
本文实验中的基本块由IDA逆向工具提取,一个视图下的控制流程图视为一个完整的基本块,该基本块常以ret指令、call指令或jmp指令结束。以Win XP 系统下的kernel32.dll中的LoadLibraryA为例,在控制流程图下的一个基本块如图1所示。
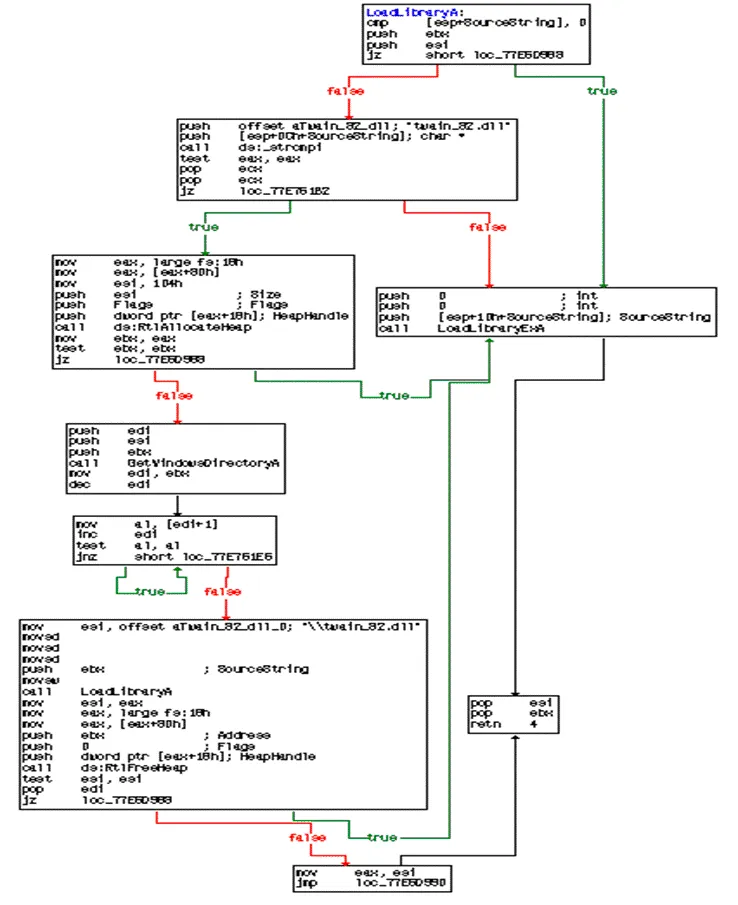
图1 win XP 32位LoadLibraryA控制流程图
1.1 基本块跳转逻辑特征
现阶段的二进制代码同源性分析技术中,基本以控制流程图的特征来进行同源性的分析。
提取基本块的所有完整执行流程中的跳转逻辑,生成跳转逻辑序列,表示如下:L=(n,t1,t2,t3,….,tn),t有两种取值:在跳转处为true的分支,t=1;在跳转处为false的分支,t=0;为call、jmp的分支,略过。
设基本块A和基本块B,基本块A的执行流程有CA个,基本块B的执行流程有CB个,基本块A和基本块B的执行流程中的跳转逻辑表示为:
基本块A和基本块B的跳转逻辑相似度L-Similarity可表示为:
对于n值相等的两个跳转逻辑序列才计算其相似度。对于的,或许有几个的值与它相等。
以图1为例,跳转逻辑序列集为:
以win7 32位系统下的kernel32.dll的LoadLibraryA为对比,将图1所示基本块的控制流程图转换为跳转逻辑序列集:
由公式(1)得
1.2 基本块代码序列特征
在生物学上,常用矩阵作图法计算DNA序列的相似度,其原理如下:构成DNA序列的四种碱基对分别表示为{A,C,G,T},将生物分子序列抽象为对应的字符串,进行序列比较的两个序列分别放在矩阵的X轴和Y轴上,当对应的行与列的序列字符匹配时,就在矩阵对应的位置做“点”标记,最终形成点矩阵。如果两条序列完全相同,则点矩阵中所有的点将构成一条对角线,如图2。
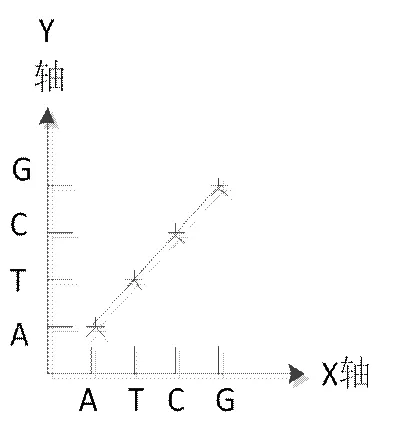
图2 完全相似序列点阵图
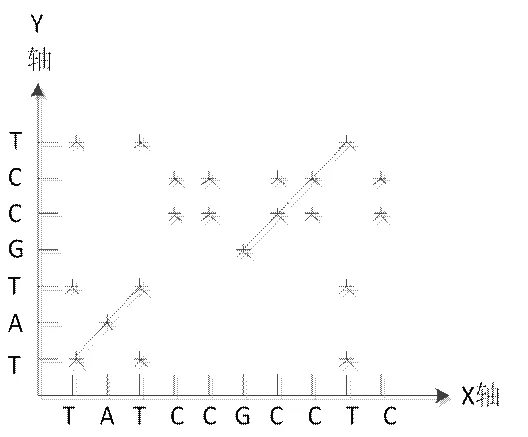
图3 非等长不完全相似序列点阵图
如果两条序列存在相同子串,则对于每一个相同的子串对都有一条与对角线平行的由标记点组成的斜线,如图3。所以找两条序列的最佳比对实际上就是在矩阵标记图中找非重叠平行斜线的最长的组合。
当两条序列中有很多匹配的字符时会形成很多点标记,导致点阵图变得复杂和模糊,此时便需要引入滑动窗口来代替一次一个点位的比较。设滑动窗口为H,相似度阈值为h(h 因此,本文借鉴了生物学上计算DNA序列相似度的矩阵作图法和打分矩阵[5]的方法及思路,利用二维数组编程模拟点矩阵,实现对可执行二进制汇编代码序列的相似性度量。 对需要比较的两个二进制汇编代码序列提取汇编指令操作符,分别表示为: 滑动窗口值设为H,打分规则为: sequenceA和sequenceB比对得出打分矩阵ScoreMatrix,扫描ScoreMatrix得到打分矩阵非重叠平行斜线的最长组合的序列长度: sequenceA和sequenceB中出现的相同序列长度为SC。 该矩阵算法能检测出连续相同指令序列,并且能有效消除指令重排的影响,准确地得出两个指令序列的相似度。 1.3 基本块子函数名特征 由于每个代码作者在给函数和变量取名时会有一定的习惯和惯性思维[6],所以基本块中的字符特征能作为代码同源性检测的重要依据。 在二进制代码中,call指令常常会泄露一定的字符串特征,这些字符串有些是代码作者命名的,也有些是系统提供的API接口函数名。经过编译链接的可执行二进制代码在功能相同处调用的系统函数是相同的。因此本文从call指令的操作数中提取有效的子函数名作为另一重要的匹配特征。 子函数名的相似性判断采用俄国科学家Vladimir Levenshtein发明的Levenshtein Distance算法[7]。该算法的原理是计算两个字符串之间通过最少步骤使两个字符串相同。每个步骤的操作方法是修改、增加或者删除一个字符。这个最少步骤即为编辑距离ED。 设基本块A和基本块B,分别扫描A、B基本块所有的call指令,提取call指令的操作数即子函数名称,过滤掉为8个16进制数的函数名,得到两个字符串集StrA和StrB,并且m>n。 两个字符串集的相似度为: 以图1和图2为例,提取字符串特征: StrA=(6,_strcmpi,RtlAllocateHeap,LoadLibraryExA,LoadLibraryA,GetWindowsDirectoryA,RtlFreeHeap) StrB=(8,_strcmpi,LoadLibraryExA_0,LoadLibraryA,KernelBaseGetGlobalData,__imp_RtlAllocateHeap,GetWindowsDirectoryA_0,strncat_s,__imp_RtlFreeHeap) 对比结果如表1所示,因此: 表1 win xp与win7 32位kerlnel32.dll LoadLibrary子函数名特征对比 1.4 权重与阈值 为考虑到函数名变化太大无可比较性时(借鉴代码者很容易更改函数名),则字符串特征指纹信息的相似度会拉低总体相似度的值而产生漏报。所以,通过提供调节指纹信息权重的接口,来排除已确定可不予比较的因素或减小某一指纹信息的影响程度以减小误报率。即用u、v和(1-u-v)分别表示逻辑跳转特征、代码序列特征和子函数名特征的所占权重,通过调节权重比例,综合量化出两个基本块的整体相似度,总相似度可表示为公式(4)。 利用Win XP 32位系统与Win7 32位系统下的同名DLL文件以及常见文字处理工具notepad的不同版本作为实验样本,得出相关测试结果如表2。 表2 u=v=1/3 测试结果 在win XP和win7 32位的kernel32.dll的LoadLibrary基本块的对比中,Fsimilarity的值为0.8576,说明尽管系统版本不一样,但调用的子函数基本上是相同的,并且跳转逻辑相似度也远远高于表中其他对比项;在win7 32位的kernel32.dll的LoadLibrary与DllEntryPoint基本块的对比中,Fsimilarity为0说明两个基本块调用的子函数完全不同,这反映出两个基本块所完成的功能是完全不一样的,并且跳转逻辑的相似度也只有0.0370;用VS2010编译的Helloworld.exe与win7 32位的kernel32.dll的LoadLibrary基本块做对比发现Ssimilarity的值与前两项对比值较接近,这是因为这些对比中的二进制文件都是同一编译器生成的,在调用函数时的堆栈操作的代码特征是一样的,而在win7 32位系统自带的notepad.exe与asm编译的wordpad.exe的对比中,Ssimilarity的值却只有0.0571,这是因为虽然两个文字处理程序notepad.exe和wordpad.exe的功能大致相同,但是由不同语言、不同编译器生成的,不仅在调用函数时的堆栈操作的特征不一样,在功能实现的调用函数以及调用函数的顺序都是不一样的,反映在Ssimilarity上的结果就是Ssimilarity的值非常低。 本文从主流安全网站上收集到被曝光的10个APT组织流出的相关代码样本,将这些代码样本作为测试数据,对比传统的基于控制流程图的同源性检测方法,得到测试结果如表3。 实验中所用的同源测试样本来自于不同的APT组织被曝光的利用代码,由于这些被捕获到的代码样本并不是完整的可执行二进制文件,所以传统的基于控制流程图的同源性分析方法能检测出的同源样本数量有限,而本论文提出的方法能以更细粒度的分析策略检测出二进制可执行代码的同源性。 表3 同源样本检测对比结果 二进制代码的同源性分析对恶意代码的溯源和代码抄袭的确定有着重要的辅助作用。本文通过提取基本块内部的跳转逻辑、代码序列和子函数名的指纹信息,以更细粒度的对比分析算法来确定二进制代码同源性,该方法能对可执行二进制代码进行量化分析,以准确的代码特征取证完成二进制代码同源性的判断过程,得到准确结果。 [1]钱雨村,彭国军,王滢等.恶意代码同源性分析及家族聚类[J].计算机工程与应用,2015. [2]Kunhua Zhu,Yancui Li.Binary Software Copy Detection Scheme based on Fingerprint Signatures.Journal of Convergence Information Technology(JCIT)and Control Flow Graph[J],2012. [3]赵连朋.一种基于素数存储的关联规则算法[J].计算机工程与应用,2006. [4]王建新,杨凡,韩锋.二进制文件比对中的指令归并优化算法[J].计算机应用与软件,2013. [5]袁二毛,郭丹,胡学钢,吴信东.基于打分矩阵的生物序列频繁模式挖掘[J].模式识别与人工智能,2016. [6]董志强.编码心理学分析病毒同源性[J].信息安全与通信保密,2005. [7]Frederic P. Miller,Agnes F. Vandome,John McBrewster. Levenshtein Distance[M], 2013.
2 实验结果及分析


3 总结
猜你喜欢
中等数学(2021年8期)2021-11-22
数学大王·低年级(2019年10期)2019-11-25
中等数学(2019年4期)2019-08-30
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
火控雷达技术(2016年2期)2016-02-06
浙江共产党员(2014年12期)2014-07-10
天津医药(2012年2期)2012-11-28
