
结合语言学特征和自编码器的英语作文自动评分①
2017-10-13 12:06魏扬威黄萱菁
计算机系统应用 2017年1期
魏扬威, 黄萱菁
结合语言学特征和自编码器的英语作文自动评分①
魏扬威, 黄萱菁
(复旦大学计算机科学与技术学院, 上海 201203) (复旦大学上海市智能信息处理重点实验室, 上海 201203)
近年来, 越来越多的大规模英语考试采用了自动评分系统. 因此, 对英语作文自动评分的研究有着非常重要的价值. 我们先依据英语作文写作技巧提取了大量语言学特征, 再分别使用自编码器, 特征值离散化方法对特征进行重构, 最后我们使用分层多项模型来输出文章的最终得分. 实验表明, 该方法能取得很好的预测效果, 而且面对不同主题的作文进行预测时也能显示出较好的鲁棒性. 相比于传统自动评分方法皮尔森相关系数高出9.7%, 具有良好的实际应用价值.
自动评分; 自编码器; 离散化; 文本特征提取
英语作文自动评分使用自然语言处理相关技术, 让计算机系统对于目标文章给出合适的得分. 随着很多英语等级认证考试报名人数的增加和计算技术的发展, 一些自动评分的软件已经正式被使用. 国外最有代表性的自动评分系统有: Project Essay Grade(PEG), 于1966年由美国的杜克大学(University of Duke)的Ellis Page等人开发[1]; intelligent Essay Assessor(IEA), 由美国科罗拉多大学(University of Colorado)开发[2]. e-rater评分系统, 已经正式被用来评测TOEFL和GRE考试中文章的质量[3]. 性能优异的自动评分系统结合文本纠错的功能[4,5]能减少人的工作量, 极大地节约人力物力资源.
英语作文自动评分的方法研究一直是一项具有挑战性的, 且不断被完善的任务. 1996年Arthor Daigon通过对文章语言形式的考察进行文章质量评测[6]; 1998年, Leah S. Larkey使用了基于文本分类的方法取得了性能的提升[7]; 2011-2014年, Isaac Persing和Vincent Ng等人发表了一系列的文章, 使用了回归方法分别从文章的组织结构[8], 文章和对应主题的相关性[9], 还有文章表达的清晰度方面[10]对文章质量进行评估; 2013年, Hongbo Chen和Ben He使用了排序的方法, 通过先对文章质量进行排序再进行划分等级来对文章评分[11].
自编码器(autoencoder)是人工神经网络的一种, 通常用来学习特征的有效编码. 2006年Hinton发表在science上的文章[17]提出了自编码器, 引发了这几年科学界对人工神经网络研究的热潮. Hinton在文中使用了自编码器对图像的特征矩阵进行压缩编码. 自编码器也可以用于我们的英语自动评分任务, 一方面可以降低特征的维数, 另一方面可以通过重构捕捉到原始特征中最重要的信息.
1 自编码器
一篇英语作文的原始特征直接用来进行分类或者回归, 往往很难得到很好的评分预测结果. 我们可以先使用自编码器对原始特征进行重编码, 再使用编码结果来对文章的评分进行预测.
自编码器主要是学习一个近似等式:
这里的X表示输入矩阵, w表示权重矩阵, b表示偏置. 自编码器包括编码和解码的两层结构. 通过编码可以得到特征的另外一种表示方式, 再通过解码将编码结果还原出来. 如果最终输出的还原结果和输入非常接近, 那么编码结果就可以看成是输入的近似代替.
自编码器的意义不在于还原输入数据, 而是体现在对隐层神经元的限制. 如图1所示, 为了进行压缩编码, 我们将隐层神经元的数量设置为2, 这样就可以将输入的5维特征压缩到2维. 当隐层神经元的数量大于输入特征的维度时, 可以得到特征的高维稀疏编码结果.
显然, 自编码器的目标函数是输出结果和输入之间的重构误差尽可能小. 其计算公式如式(2)所示:
当然, 为了避免系统的过拟合, 我们还要加入一个正则化项来控制模型的复杂度增长:
(3)
如果我们训练的是稀疏自编码器, 需要在目标函数中再增加一个约束项, 控制模型的稀疏性. 这里引入激活的概念, 如果最后传递函数的输出结果非常接近于0, 那么我们认为该神经元没有被激活. 而如果最后传递函数输出的结果接近于1, 那么该神经元被激活了. 通常来说, 传递函数为sigmoid函数:
或者是:
(5)
再引入稀疏性参考, 通常是一个非常接近于0的值, 比如0.05. 然后计算和的信息增益, 用来描述这两者之间分布的差别.
(7)
其中, S2表示隐层中神经元的总数, j是对隐层神经元的索引. 对于稀疏编码, 我们将上式的信息增益也作为惩罚项加入目标函数中. 因此对于稀疏自编码器, 其目标函数为式(8)所示. 其中是一个系数, 表示对稀疏性惩罚的力度, 这个值越大表示对稀疏性要求越高.
在有了压缩编码和稀疏编码自编码器的目标函数之后, 我们可以进一步利用优化算法, 如梯度下降法, 来对目标函数进行优化以得到最优的网络结构. 在英语作文自动评分任务中, 对于提取的原始特征, 我们可以进一步使用自编码器进行重构. 通过控制隐层神经元的数量, 一方面压缩编码进行特征压缩, 另一方面稀疏编码将特征重构到高维.
2 特征值离散化
机器学习系统进行数据训练时, 有时候会遇到少量的异常样本. 比如英语作文自动评分任务, 其中一维特征是平均每句话中第一人称代词所占的比例. 这个比例不会太高, 一般来说低于0.25, 一些异常学生作文在该维取值可能达到了0.8, 0.9或者更高. 为了削弱这些异常样本的影响, 我们可以使用不同的区间来对特征值进行分段. 比如这里我们可以取0~0.1, 0.1~0.2, 0.2~0.3, 0.3~0.4和0.4~1这几个区间. 不论异常作文在该维度的取值是0.8还是0.9统统归到0.4~1这个区间中, 其本身的特征值并不会加入系统训练. 这样可以大大减少异常样本对系统整体性能的干扰.
特征离散化关键问题就在于分割区间的选择[18], 不同的分割区间直接影响到系统的性能. 我们首先将所有样本都归为一个区间中, 使用信息增益的方式, 来决定是否进一步分割区间, 再递归地分割其每个子区间. 首先是特征对应的熵, 如式(9)所示:
其中是特征对应的取值的集合,是上取值F对应的比例. 下面我们使用分割边界对特征划分, 划分之后其熵值计算方法为:
(10)
其中1和2分别是集合对应分割边界的两个子集. 因此信息增益为:
当然我们不能无限对特征值区间进行分割, 因此, 我们需要增加一个停止分割条件[19]:
(12)
其中,是集合中的元素个数, 使用以下公式进行计算:
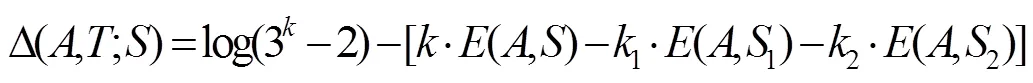
其中表示中元素的个数,1和2分别表示1和2中元素的个数. 有了上述条件之后, 我们在对连续特征进行分割的时候就会逐渐收敛, 最终停止得到最优的分割结果.
离散化能够进一步提升特征值的表达能力, 离散化之后的多维特征, 每个特征都可以有不同的权重, 因此特征的表达能力得到进一步提升, 系统更加稳定. 我们在进行自动评分时, 可以对于提取到的原始特征首先进行离散化, 离散化后的高维特征再使用自编码器重编码. 重构的特征最后分别使用支持向量机进行回归或者分层多项模型进行分类, 以输出一篇学生作文的最终得分.
3 文本的特征表示
一般地, 对英语作文的评价主要基于三个大的方面: 词汇的使用, 即词汇使用是否正确, 词汇量是否丰富, 是否高级优美; 语法的使用, 即语法结构是否正确, 语法结构是否复杂(不能过于单一), 句子是否通顺; 话语的长短和连贯性, 即句子和句子之间结构是否紧凑.
2002年Eli Hinkel研究了母语是英语的学习者和母语非英语的学习者的英语写作在词法、从句和句子间关系三个方面应用的差异, 提供了指导英语写作的一些技巧[12]. 我们认为这些差异和技巧能反映英语学习者的文章质量, 因此从这些角度出发, 提取了一些语言学特征. 大多数现有的评分系统往往给出的只是简单的特征, 如文章长度, 句子长度, 停用词的个数. 但是这些特征都不能直接反应文章的写作水平, 我们这里提取的特征, 每一项都旨在考察文章的表述能力和语言的运用能力, 更加细致地考察了作者的写作功底. 因此, 我们的特征能更好地完成作文评分的任务.
3.1 词法特征
词法特征是对于英语写作水平最基本的考察, 词法的特征能反应文章作者对于词汇和短语的掌握能力. 如表1所示, 其中列举类、语言活动类、分析类、结果类和模糊类等是作者表述中常用的关键性名词词汇; 动词的不同时态以及动词不定式和动名词能够考察作者对于动词形式变换的熟练程度; 形容词和副词在句法中常用作修饰成分, 能考察作者对于不同修饰词其修饰程度的把握. 学生英语作文中词汇量不能过于狭窄, 不能仅仅使用某一类的词.

表1 词法特征
3.2 从句特征
传统的特征提取往往只有词汇级别的考察. 但是仅仅考察作者对于词法使用的能力是不够的, 假如一篇作文通篇堆砌高级的词汇或者精美的短语, 可是全部使用单一的简单句、短句子, 按照作文评测的标准不能给予高分. 另一方面, 如果只考察词汇, 系统很容易被学生作文刻意使用一些词汇所欺骗[20]. 从句的特征考察的正是作者运用复杂句式的能力, 如果文章中使用的词汇优美准确, 而且能够很好地运用各类从句使句法不再单一, 这样的文章是有理由给予较高分数的.

表2 从句级别的特征
3.3 句子间关系
如果作者的文章中对于词汇和从句已经能够很好的掌握, 可是句子和句子之间不连贯没有逻辑, 我们显然不能给予这篇文章很高的得分. 因此我们加入了句子间关系的特征, 用来考察作者文章对于前后句子连贯性句子间逻辑性的掌握. 如表3所示, 主要考察前后句的并列, 平行, 递进, 因果, 转折关系, 以及后一句是否是对前一句的说明或者限制. 以上就是我们全部的语言学特征. 首先从词法方面, 考察了英语作文中对各类词汇的掌握情况, 每类词汇都有其特定的表达含义和语气. 同时还考察了动词和形容词的词法活用, 反映了学生对于基本的语法知识、句子成分的理解. 然后我们考察了英语作文中从句的使用情况, 各类从句运用得是否恰当能极大地反映英语写作水平的高低. 最后考察的是句子的前后关系, 我们认为好的文章不仅要能有好的词汇表达, 好的从句使用, 还要在文章的组织结构上要有一定的逻辑性, 连贯性. 其中从句级别特征和句子间关系特征在提取的时候, 我们先使用Stanford parser进行句法分析[13], 再从句法分析树上进行匹配.

表3 句子间关系的特征
4 数据集
本项研究的数据集在kaggle上公开, kaggle是一个机器学习比赛的公共平台, 我们可以免费注册账号下载其举办的比赛的训练数据. 该数据集是7-10年级的第一语言学习者的英语作文, 一共包含8个子集, 每个子集都是独立的数据, 独立的主题, 平均文章长度都不同. 数据集概况见表1, 其中数据子集2在kaggle中给出了2项评分, 我们在这里选取了第1项评分, 即写作应用项作为其最终得分.

表4 数据集
如表4中所示, 文章类型主要是论述类、叙事类、说明类和回答问题类. 论述文、叙事文或者说明文要求作者的文章描述一个故事或者新闻. 而回答问题类则要求作者先阅读一段材料, 再根据阅读材料最后给出的问题和要求写一篇文章. 8个数据子集的主题各自不同, 其中, 子集1要求谈论计算机对生活带来的影响; 子集2是谈论图书馆是否需要对图书内容进行审查; 子集3-6是先阅读材料再根据提示写作文, 4篇材料也都不同; 子集7要求写一篇关于耐心的故事; 子集8说明笑是人际关系中的一个重要元素, 要求写一篇关于笑的文章.
5 实验
5.1 实验评测

(15)
(16)
其中A,E分别表示第篇文章的人工评分和系统评分,表示文章的总数. 皮尔森相关系数用来反映系统评分和人工评分的线性相关程度, 取值范围在[-1,1]之间, 值越大说明相关性越高. 接近于0表示人工评分和系统评分几乎没有相关性, 接近于1表示人工评分和系统评分几乎一致, 而小于0则表示人工评分和系统评分负相关.表示系统得分和人工得分之间的平均偏差,表示系统得分和人工得分之间的均方偏差. 相关系数用来作为最主要的评测指标, 平均偏差和均方偏差作为参考. 我们进行5折交叉验证, 对于每个数据子集, 随机切分成5份, 每次使用其中3份训练, 在第4份上调整参数, 在最后1份上进行测试.
为了进行对比我们分别引入了两个baseline系统, 其中baseline1系统是kaggle在该比赛中用的baseline, 使用文章的单词数和文章的字符个数对文章的得分进行预测. 对于baseline2系统我们提取了一些目前系统中常用的特征, 文章的字符长度, 文章的单词长度, 文章中疑问句和感叹句个数, 高级词汇个数, 拼写错误个数, 停用词个数, n-gram和POS n-gram等特征, 并且结合Hongbo Chen于2012年发表在IEEE上的文章[16]中使用的特征, 来进行评分.
5.2 特征效果对比
我们首先使用最简单的方法来对比不同特征对于系统的影响, 直接用支持向量机(SVM)对于提取的特征进行回归[14]. 具体使用的是libsvm[15].
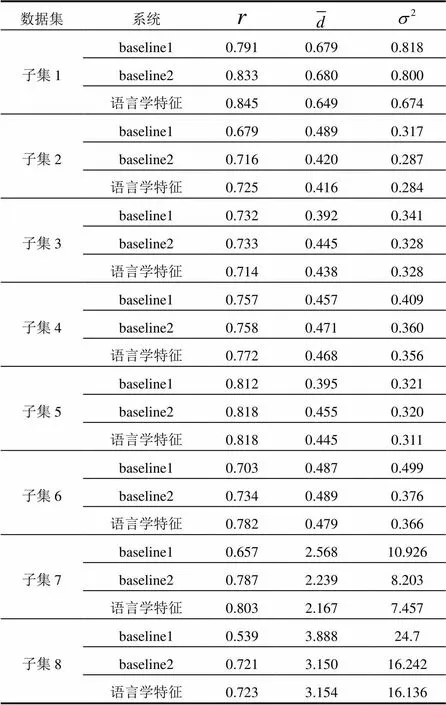
表5 实验结果
如表5中所示, 我们的语言学特征在这8个子集中的7个子集上取得了最高的人机评测相关系数. 下面我们看一下这8个子集上的整体评测效果, 因为每个子集的评分区间不同, 所以我们先对得分区间进行归一化, 其公式如式(17)所示.

其中,表示文章的得分, max()表示所在子集的最高分, min()表示所在子集的最低分.
归一化之后, 我们再来看8个子集上的整体效果. 从全部数据结果来看, 相比于baseline1系统和baseline2系统, 语言学特征系统评分在相关系数方面分别取得了14.1%和5.4%的性能提升.

表6 8个子集整体效果
5.3 自编码器
下面我们使用编码器对于提取到的特征进行重构, 语言学特征系统提取到的原始特征总共194维, 我们分别进行压缩编码和稀疏编码, 实验效果如表7所示.

表7 自编码器特征重构
表7中20维~140维是使用自编码器进行特征的压缩编码, 200维~2000维是使用自编码器进行特征的稀疏编码. 其中特征压缩到100维时, 此时的相关系数达到0.787, 比直接使用支持向量机进行回归效果提升了3.4%.
5.4 特征值离散化
我们再结合特征值的离散化, 先使用基于于信息增益的方法, 将连续特征离散化到高维的二值特征. 再使用自编码器来进行特征压缩. 其实验效果如表8所示. 使用特征值离散化后, 原始特征194维扩展到了15800维二值的0,1特征. 我们再使用自编码器对这15800维特征进行压缩重编码. 如表8所示, 当自编码器将特征维数压缩到1000维时相关系数达到0.803, 相比于未经过特征值离散化效果提升了2.0%.
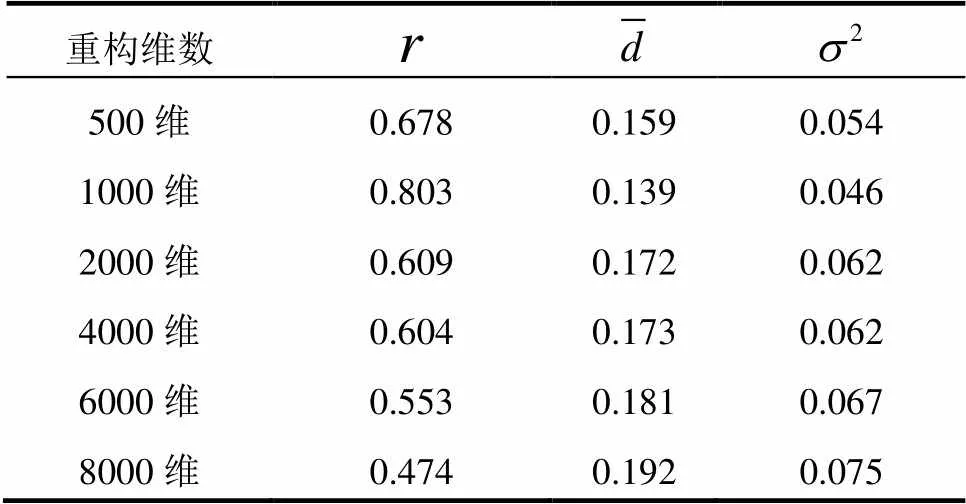
表8 特征离散化后的特征重编码
5.5 分层多项模型
考虑到我们使用支持向量机进行回归的输出结果是连续性的值, 而人工评分给出的是离散化的得分值, 因此我们可以尝试使用分类的方法进行自动评分. 然而一般的分类方式其类别和类别之间没有嵌套或者大小的关系, 这和我们的任务相违背. 这里我们使用分层多项模型(Hierarchical Multinomial Model)来进行分类, 在该模型中, 类别和类别之间有嵌套包含的关系,这和我们自动评分任务中得分和得分之间的关系非常吻合.具体使用的是matlab实现的机器学习工具包[1]http://cn.mathworks.com/help/stats/index.html. 为了进行对比, 我们同样将支持向量机的评分结

表9 回归和分类结果对比
如表9所示, 支持向量机回归输出的是离散的值, 其对作文评分的结果在规整到人工评测的边界之后, 人机相关系数从0.803下降到0.774. 相比之下, 分层多项模型虽然给出的人机相关系数是0.792, 但是因为是分类的结果所以不需要进一步规整, 相比于支持向量机的结果显然更优.
我们对于baseline1和baseline2同样加入了自编码器, 特征离散化, 分层多项模型进行测试. 结合语言学特征模型, 这三组系统的实验效果如图2所示. 纵向比较来看, 无论哪一组实验, 我们的语言学特征系统和两个baseline比较, 均能取得最优的效果. 横向来看, 相比于最原始的支持向量机回归, 我们的自编码器, 特征值离散化的使用均能使得系统的性能得到进一步提高. 因为回归得出的结果是连续性数值, 输出得分在规整之后系统性能必然会有所下降. 最后我们使用分层多项模型进行分类, 直接给与一篇作文输出离散的得分结果, 这相比于回归之后再规整的结果人机相关系数更高.
5.6 主题无关性
最后我们从主题依赖性的角度出发来考察这3组系统. 因为数据集包含8个子集, 因此我们将全部数据按主题的不同分成5份进行交叉验证, 使得训练用的作文和测试作文之间没有主题交叉. 其实验效果如下表所示. 可以看出, 两个baseline系统, 特别是baseline2系统中引入了大量n-gram等和文章主题相关的特征. 这直接导致了在预测其他主题作文时系统性能的下降. 而我们的语言学特征系统使用的都是主题无关特征, 在面对不同主题的测试样本时, 依然能保持很好的鲁棒性.

表10 8个子集间相互进行交叉验证
6 总结
本文依据英文写作的技巧, 提取了大量的主题无关特征. 然后通过特征离散化减少异常样本对系统的干扰, 自编码器对特征进一步重构以提高特征表达能力. 最后我们分析了作文评分任务的特点使用分层多项模型来输出文章的最终得分. 实验表明, 一方面我们的模型和特征要显著优于传统的方法, 另一方面我们的系统在测试不同主题的作文时显示出了良好的主题无关性.
1 梁茂成,文秋芳.国外作文自动评分系统评述及启示.外语电化教学,1997:18–24.
2 Attali Y, Burstein J. Automated essay scoring with e-rater®V. 2. The Journal of Technology, Learning and Assessment, 2006, 4(3): 3–30.
3 Daigon A. Computer grading of English composition. The English Journal, 1966, 55(1): 46–52.
4 Landauer TK. Automatic essay assessment. Assessment in education: Principles, policy & practice, 2003, 10(3): 295–308.
5 Dale R, Anisimoff I, Narroway G. HOO 2012: A report on the preposition and determiner error correction shared task. The 7th Workshop on the Innovative Use of NLP for Building Educational Applications. June 3-8, 2012. 54–62.
6 Ng HT, Wu SM, Wu Y, et al. The CoNLL-2013 shared task on grammatical error correction. Proc. of the Seventeenth Conference on Computational Natural Language Learning. August 8–9, 2013.1–12.
7 Larkey LS. Automatic essay grading using text categorization techniques. Proc. of the 21st annual international ACM SIGIR conference on Research and development in information retrival. 1998. 90–95.
8 Persing I, Davis A, Ng V. Modeling organization in student essays. Proc. of the 2010 Conference on Empirical Methods in Natural Language Processing. 2010. 229–239.
9 Persing I, Ng V. Modeling prompt adherence in student essays. Proc. of the 52nd Annual Meeting of the Association for Computational Linguistics(ACL). June 2014. 1534–1543.
10 Persing I, Ng V. Modeling thesis clarity in student essays. Proc. of the 51st Annual Meeting of the Association for Computational Linguistics. August4-9, 2013. 260–269.
11 Chen H, He B. Automatic essay scoring by maximizing human-machine agreement. Proc. of the 2013 conference on Empirical Methods in Natural Language Processing. 2013. 1741–1752.
12 Hinkel E. Second language writers’ text: Linguistic and rhetorical features. Routledge, 2002.
13 Marneffe MCD, Cartney BM, Manning CD. Generating typed dependency parses from phrase structure parses. Proc. of Language Resources and Evaluation Conference. 2006.
14 Burges CJC. A tutorial on support vector machines for pattern recognition. Data mining and knowledge discovery, 1998, 2(2): 121–167.
15 Chang CC, Lin CJ. LIBSVM: A library for support vector machines. ACM Trans. on Intelligent Systems and Technology. April, 2011.
16 Chen H, He B, Luo TJ, et al. A ranked-based learning approach to automated essay scoring. Second International Conference on Cloud and Green Computing. 2012.
17 Hinton GE, Salakhutdinov RR. Reducing the dimensionality of data with neural networks. Science, 2006, 313(5786): 504–507.
18 Dougherty J, Kohavi R, Sahami M. Supervised and unsupervised discretization of continuous features. Machine learning: Proc. of the Twelfth International Conference. 1995. 12. 194–202.
19 Dougherty J, Kohavi R, Sahami M. Supervised and unsupervised discretization of continuous features. Machine Learning: Proc. of the 12th International Conference. San Mateo. Morgan Kaufmann Publishers. 1995. 194–202.
20 葛诗利.面向大学英语教学的通用计算机作文评分和反馈方法研究[博士学位论文].北京:北京语言大学,2008.
Automatic Essay Scoring Using Linguistic Features and Autoencoder
WEI Yang-Wei, HUANG Xuan-Jing
(School of Computer Science, Fudan University, Shanghai 201303, China) (Shanghai Key Laboratory of Intelligent Information Processing, Fudan University, Shanghai 201303, China)
In recent years, more and more large-scale English tests begin to use the automatic scoring system. Therefore, the research of this system is of great value. In this paper, we first extract a lot of features according to English writing guide. Then we use autoencoder and discretization algorithm to learn a different representation of features. Finally, we use a hierarchical multinomial model to output the final scores of articles. Experimental results indicate that this method not only achieves great performance for those essays of the same topic, but also shows good robustness when predicts essays of different topics. Compared with the traditional automatic score method, our approach achieves higher than 9.7% in term of Pearson Correlation Coefficient, with good practical values.
automatic essay scoring; autoencoder; discretization; textual feature extraction
国家自然科学基金(61472088)
2016-04-22;收到修改稿时间:2016-05-23
[10.15888/j.cnki.csa.005535]
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
小学生学习指导(中年级)(2021年12期)2021-12-30
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
锻压装备与制造技术(2021年5期)2021-11-13
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
汉字汉语研究(2020年2期)2020-08-13
南京大学学报(数学半年刊)(2020年1期)2020-03-19
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
