
多算法融合的电网用电量预测系统研究和实现
2017-09-20 03:13李文彬张春梅
现代计算机 2017年22期
李文彬,张春梅
(广东电网有限责任公司中山供电局,中山528400)
多算法融合的电网用电量预测系统研究和实现
李文彬,张春梅
(广东电网有限责任公司中山供电局,中山528400)
准确预测用电量是电网企业合理规划电网建设和提高经济效益的前提基础,该系统实现包括Random Forest、Extra⁃Trees、XGBoost、AdaBoost在内的多个算法对用电量进行预测,并在B/S架构下设计一个用电量预测系统,功能包括可视化每个用户的用电量和预测误差情况、自动选取预测算法和数据导入导出管理。系统的实现有助于直观地展示用电量预测结果,辅助管理层进行决策。
用电量预测;回归分析;集成学习;B/S架构
0 引言
电网企业需要掌握用电需求变化趋势,以便有计划地提供电力服务。用电量预测是电网企业的一项重要基础性工作,预测结果可能直接影响企业效益。同时,用电量预测也是制定电力发展规划的重要依据。准确地用电量预测系统可以确保电网安全运行,对合理设计电网改造、错峰用电、发电计划有着重要的参考价值,有助于实现节能减排等环境保护目标。
1 国内外现状
用电量预测根据预测周期可分为短期预测和中长期预测。短期负荷预测通常用来安排电力计划的调度,因此,对短期负荷预测,一般需要充分研究电力系统过去的变化规律和趋势,分析各种干扰因素。中长期预测主要用来确定大机组的运行方式,根据地区的实际情况,制定相关的电网改造和扩建规划,保证负荷用电量能够满足居民用电和工农业用电的需要。根据预测对象可分为地区负荷预测、微电网负荷预测、大客户负荷预测等。
根据预测算法划分,可分为以下几个类别[1]:(1)传统的基于历史数据统计的线性回归预测算法,包括线性回归法、移动平均法等方法;(2)时间序列预测方法,将用电量数据作为季节相关的时间序列数据处理。(3)灰度模型组合预测法,通过对负荷特性的分析,用累加残差的方法确定权重,在不同的阶段建立不同的灰度模型,利用了组合灰度模型提高预测的准确性[2]。(4)基于机器学习算法的智能预测方法,如神经网络、支持向量机[3]、粒子群算法、遗传算法等。
从预测模型的结构来看,可分为单算法模型和组合模型。合理的算法组合设计可以有效降低预测误差,如文献[4]通过将不同神经网络的预测结果作为神经网络的输入,实际负荷作为输出,运用多神经网络方法,很好的克服了单神经网络预测精度差的缺陷。
本文设计了一个用电量预测分析系统,通过多算法组合预测的方式进行用电量预测,并在B/S架构下加以实现,系统可以自动或手动选择预测算法、预测时段以及对预测结果和误差可视化。
2 预测算法设计
系统实现了Random Forest、ExtraTrees、XGBoost、AdaBoost四种预测算法,已知19个用电客户68个月的月用电量数据,前60个月的数据作为样本数据,后8个月的数据作为测试数据,使用预测的8个月数据与测试数据计算误差,为每个用户选取平均误差最小的算法进行实际预测。下面主要介绍Random Forest和Extrees算法的主要步骤和实现方法。
(1)Random Forest算法
Random Forest算法基于Bagging思想,本系统的算法基学习器采用CART回归树[5-7],用平方误差最小化准则进行输入空间划分,即基于最小二乘偏差(LSD)生成回归树。
Bagging也叫装袋,属于有放回抽样,给定一个训练集,Bagging算法从中均匀、有放回地选出m个子集作为新的训练集。在这T个训练集上使用回归算法,则可得到T个模型,再通过取平均值的方法,即可得到Bagging的结果。
Bagging算法是一种并行算法,学习效率较高。由于每个基学习器只学习一部分样本,可以有效降低方差,没有被抽取到的袋外样本可以用来对模型进行泛化能力的评价,已得到证明,袋外估计的精度与用同训练集大小一样的测试集估计的精度结果近似。
Random Forest算法以T个CART回归树作为基学习器模型,输出为T个CART回归树输出结果的平均值。Random Forest是二次随机算法,第一次随机采用Bootstrap采样,从N个训练样本中以有放回抽样的方式,取样N次,形成一个训练集(即Bootstrap取样),由于每次约有37%的样本未被抽中,可用未抽到的样本做袋外估计,评估其误差;第二次随机,对于每一个节点,随机选择m个特征,其中m应远小于总特征数M。决策树上每个节点的决定都是基于这些特征确定的。根据这m个特征,计算其最佳的分裂方式,由于m远小于M,所以每棵树都会完整成长而不会剪枝进行二次随机的原因是,如果训练集中,有几个特征对预测结果影响很大,那么这些特征将每次都会被决策树采用,从而使决策树之间的相关性增强,导致模型方差较大,而且对数据扰动过于敏感。
由于Random Forest的基学习器是CART回归树,并在训练集上进行Bootstrap采样,所以参数调整分为两部分,Bagging的参数和CART的参数。
①Bagging参数:
n_estimators,指基学习器最大迭代次数,一般是越大越好,但迭代次数增加,模型的训练时间也会增加。oob_score,是否考虑袋外样本来拟合模型,通常选择True,因为OOB误差结果近似于交叉验证。
②CART参数:
max_features,划分时考虑的最大特征数,增加max_features能提高算法性能,但是当其值过大时,会导致树的相关性增强。
max_depth,决策树的最大深度,越深模型则越复杂。
min_samples_split,内部节点再划分所需的最小样本数,对剪枝有较大影响。
min_samples_leaf,叶子结点最小样本数,对剪枝有较大影响。
由于基学习器之间没有依赖关系,并且训练Ran⁃dom Forest的过程也是训练每棵树的过程,所以可以进行并行化训练,对效率有很大提升。又因为在对特征的划分选择时采用的是随机抽取特征的方法,所以在高维度训练时仍能有较好的效率,并且可以通过改变特征值反映各个特征的重要程度。
(2)ExtraTrees算法
ExtraTrees算法是Random Forest的改进算法,主要区别在于:
①Random Forest基于Bagging思想,而ExtraTrees不采用Bootstrap采样,即使用所有的训练样本得到每棵决策树。
②Random Forest是在一个随机特征子集内得到最佳分裂属性,而ExtraTrees是随机的选择分裂属性,即对每一个特征,在它的特征取值范围内,随机选择一个分裂值,再计算看选取哪一个特征来进行分裂最好综上,ExtraTrees算法的优点是在分裂时随机选择分裂值,使得ExtraTrees的方差进一步减小,即对数据扰动的敏感性减小。
对于模型预测后的用电量误差,采用平方误差进行计算,并做了归一化处理。误差计算公式如下,其中Si,k为预测用电量数据,Ti,k为实际用电量数据:

3 预测系统设计
多算法电网用电量预测设计为三个模块:可视化模块、算法预测模块、数据导入导出模块。主要功能是:(1)预测未来的用电量数据,并根据误差对多个算法模型进行评价选优;(2)对用电量走势、算法误差实现可视化;(3)实现系统数据的导入与导出。系统总体架构图如图1所示。
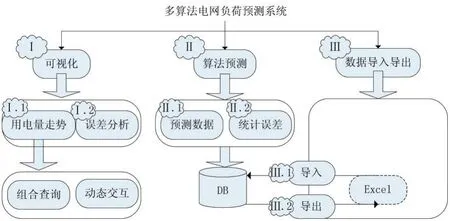
图1 系统总体架构图
可视化模块对用电量预测结果和预测误差进行可视化。选择筛选条件(包括算法模型、用电量区间、用户、年/季度/月、时间区间),利用上述条件进行预测,对预测结果可视化,直观展示用电量走势、误差结果,为决策者提供更加直观的结果展示。
算法预测模块实现了多个预测算法,并计算每个算法的平均误差。假设有N个月的用电量数据作为原始数据,将其中的前M个月作为训练数据,后面N-M个月的数据作为测试数据,预测结果与测试数据比对计算误差。系统支持自动或手动选择平均误差最小的算法进行实际预测。
数据导入模块的作用是,当有新的数据产生,可以通过Excel将新数据导入系统,然后对新数据调用预测算法,更新预测结果。数据导出模块支持选择筛选条件(包括算法模型、用电量区间、用户、年/季度/月、时间区间)后,利用上述条件进行组合查询,然后将符合条件的数据导出到Excel。预测和可视化过程只有在导入新数据时才进行,这样可以减少服务器资源的开销。
4 系统实现
系统基于B/S结构实现,前端采用BootStrap进行页面布局,服务器端采用PyCharm作为开发工具,后台服务基于Django框架,数据可视化采用Pygal,数据库工具为MySQL。
数据集为某电网公司19个用电客户68个月的月用电量数据。
在页面左侧选择筛选条件(算法模型、用电量区间、用户、年/季度/月、时间区间),在页面右侧会异步刷新,显示符合条件的各用户用电量走势图、最后一个时间单位的各用户占总量的百分比的饼状图、以及最后4个时间单位的各用户用电量列表。用电量走势图集成了工具条、添加/隐藏图线、图线加粗等交互功能。可视化模块页面如图2所示。图3为4个算法在19个用户上的平均误差柱状图。

图2 可视化模块页面

图3 算法平均误差柱状图(横坐标表示用户,纵坐标预测误差)
5 结语
系统融合了多个算法进行电网用电量预测,基于用户68个月的月用电量数据进行特征处理和分类建模,针对每个用户进行了最佳模型的自动筛选,有较强的灵活性。其中重点分析了Random Forest、ExtraTrees两种较优算法,在模型调优之后,得到了准确率较高的预测结果。
下一步的工作是针对用电量波动不规律的用户预测准确度不高的问题做进一步的算法优化,在可视化上能够更直观地把用电量数据、预测误差呈现出来,可以更方便地比较各种算法的预测性能。
[1]康重庆,夏清,刘梅.电力系统负荷预测[M].北京:中国电力出版社,2007:4-192
[2]余健明,燕飞,杨文宇,等.中长期电力负荷的变权灰色组合预测模型[J].电网技术,2005,29(17):26-29.
[3]潘峰,程浩忠,杨镜非,等.基于支持向量机的电力系统短期负荷预测[J].电网技术,2004,28(21):39-42.
[4]张亚军,刘志刚,张大波.一种基于多神经网络的组合负荷预测模型[J].电网技术,2006,30(21):21-25.
[5]李航.统计学习方法[M].北京:清华大学出版社,2012:67-73.
[6]周志华.机器学习[M].北京:清华大学出版社,2016:44-46.
[7]PeterHarrington.机器学习实战[M].北京:人民邮电出版社,2013:163-173.
Research and Im p lementation of Power Consum ption Forecasting System Based on MultiAlgorithm Fusion
LIWen-bin,ZHANGChun-mei
(Zhongshan Power Supply Bureau ofGuangdong PowerGrid Co.,Ltd.,Zhongshan 528400)
The accurate prediction of electricity consumption is the enterprise rational planning of power grid construction and improve the economic benefit of the premise,this system realizesmultiple algorithm including Random Forest,ExtraTrees,XGBoost,AdaBoost,to predict the power consumption,and designs a power consumption forecasting system based on B/S,the function of consumption and forecast the error, including the visualization ofeach user to automatically select the prediction algorithm and data importand exportmanagement.The imple⁃mentation of the system is helpful for the visual display of the electricity consumption forecasting results and the auxiliarymanagement.
李文彬(1983-),男,本科,助理工程师,从事领域为电力信息系统的建设和项目管理工作
2017-05-11
2017-07-26
1007-1423(2017)22-0075-04
10.3969/j.issn.1007-1423.2017.22.018
张春梅(1978-),女,本科,高级工程师,从事领域为电力信息系统的建设和项目管理工作
Electricity Consumption Forecasting;Regression Analysis;Ensemble Learning;B/SArchitecture
猜你喜欢
电力设备管理(2022年8期)2022-11-25
世界科学技术-中医药现代化(2022年3期)2022-08-22
北京测绘(2022年6期)2022-08-01
纺织标准与质量(2022年2期)2022-07-12
煤气与热力(2022年4期)2022-05-23
师道·教研(2022年1期)2022-03-12
北京测绘(2021年7期)2021-07-28
长江大学学报(自科版)(2021年6期)2021-02-16
电力勘测设计(2020年4期)2020-12-14
燃气轮机技术(2014年4期)2014-04-16
