
文本挖掘技术在公安领域案件分析中的应用
2017-09-18 02:32魏文燕
湖南警察学院学报 2017年3期
魏文燕,吕 鑫,高 琰
(1.中南大学,湖南 长沙410012;2.长沙市公安局,湖南 长沙 410005)
文本挖掘技术在公安领域案件分析中的应用
魏文燕1,吕 鑫2,高 琰1
(1.中南大学,湖南 长沙410012;2.长沙市公安局,湖南 长沙 410005)
为辅助民警办案,提高搜集情报、侦查破案的能力,结合公安领域案件文本数据的特点,将文本挖掘技术应用于公安领域案件的分析处理中,提出了一个基于文本挖掘技术的案件信息处理框架。框架主要包括:信息抽取模块,案件分类模块。信息抽取模块主要运用正则表达式方法,可以有效地提取出所需求的线索信息,在完成线索信息提取之后,将具有相同线索信息的案件进行串并案。在案件分类模块中,构建了层次SVM分类器和规则分类器,将两者结合对案件进行分类。在一定规模的数据集下对该框架进行了功能和性能测试,获得了较为满意的结果。
案件分析;信息抽取;文本挖掘;SVM分类
随着社会的发展,各行各业都积累了许多有意义的数据资料,公安领域也不例外,案件信息以每年百万条的速度递增。目前公安部门虽然有完善的案件信息管理系统,可以方便地对案件进行查询、筛选、统计等处理,为警务人员减少了一定的劳动量,但是依靠这些传统方法,很难挖掘出有价值的线索。因此,为有效维护社会信息条件下的国家安全和社会稳定,公安机关就必须加强对各类信息的全面整合、综合分析和预警监测,不断提高搜集情报、侦查破案、处置重大警情的能力[1]。
公安领域的案件信息都是以文本的形式记录在案的,这些案件文本中包含着各种重要的线索,如涉案电话号码、网址等,提取出这些线索可以有效地帮助案件的侦破和串并案的发现。其次,业务人员在录入案件的时候还需选择案件类别,由于许多因素干扰,登记的案件类别可能并不是准确的,不利于公安研判分析。因此借助机器学习下文本分类技术将案件自动分类,不仅可以节省人力,还能保证一定的案件分类准确率,提高公安研判分析效率。目前,已有不少专家学者对公安领域的数据分析进行了研究,如李晓冰论述了利用Excel对诈骗案件源数据进行存储和统计分析,根据统计分析的结果提取对案件分析有效的训练样本,然后应用Apriori算法进行关联规则分析,对诈骗案件内部属性之间存在的关系进行挖掘[2]。如图像方面的应用研究:方世强论述了将数字图像处理技术应用于进行机动车车牌识别的技术和重要性[3];谭炽烈论述了在海量数据时代将智能分析技术应用于公安领域的视频监控[4]。其他还有改进公安办公方式的研究,聂展云利用智能手机、平板电脑等智能化移动终端由于其携带方便、移动性强、操作简单、用户体验好、应用丰富等特性,开发移动警务平台,更好地应用于各级公安民警的实战工作[5]。
一、系统概述
本文所提出的案件文本挖掘系统的框架重点为两个功能模块,案件要素抽取功能模块和案件自动分类功能模块,基于这两个功能模块可深入开展业务应用,如利用提取的案件要素信息进行聚类、串并案件;将案件正确分类后进行研判等业务应用。系统的框架结构如图1所示。
二、案件要素抽取
(一)案件要素抽取的工作内容
案件要素抽取是提取案件中有用的信息点,或者说有利于破案的线索。根据公安方面提出的要求,需要提取目标信息点为作案时间、涉案金额、身份证号、涉案网址、涉案银行账号、电话号码、QQ号码、交通工具、作案人员结构、公交线路、公交站点。作案时间可用于统计某个时间段内的总体或某类犯罪案件发生频率,涉案金额主要应用于统计犯罪案件造成的经济损失,其他的信息点均为重要的破案线索,利用线索的相关性,可对案件做进一步处理,如串案、并案。其中,提取的作案时间如“2016年1月1日”,“2016年10月”,格式化为“2016/01/01”、“2016/10”;涉案金额描述形式多样,如“被偷现金500元,苹果手机一台,现价值约为2000元,共计损失2500元”,所提取涉案金额为2500,为了保证后期统计的正确性,所以将分散的涉案金额进行合计或只提取合计损失金额,最终只保留一个总金额;提取的交通工具信息点的描述形如“一辆银白色轿车”、“无牌黑色面包车”;作案人员的描述形如“一个中年男子”、“两名男子和一名女子”等,提取并修整为“□男□女”格式,如“2男1女”。

图1 系统的框架结构
这部分应用正则表达式匹配方法。正则表达式在文本匹配和文本抽取方面有着强大的功能,在实际工作中如匹配用户邮箱,手机号码,抽取网页内容和网络安全检测等领域有着广泛的应用[6]。对于案件文本,虽然是以半结构化文本的形式记录在库的,但其内容本身结构并不复杂,比较单一,符合时间、地点、人物、事件此类简单的语法结构。难点在于必须考虑正则表达式的容错性,因此,在充分研究分析案件文本数据之后,详尽罗列出各项信息抽取的规则,并测试修改,最终整合成正则表达式。将正则表达式匹配案件文本中的语句,抽取相应的信息。示例如下表所示:
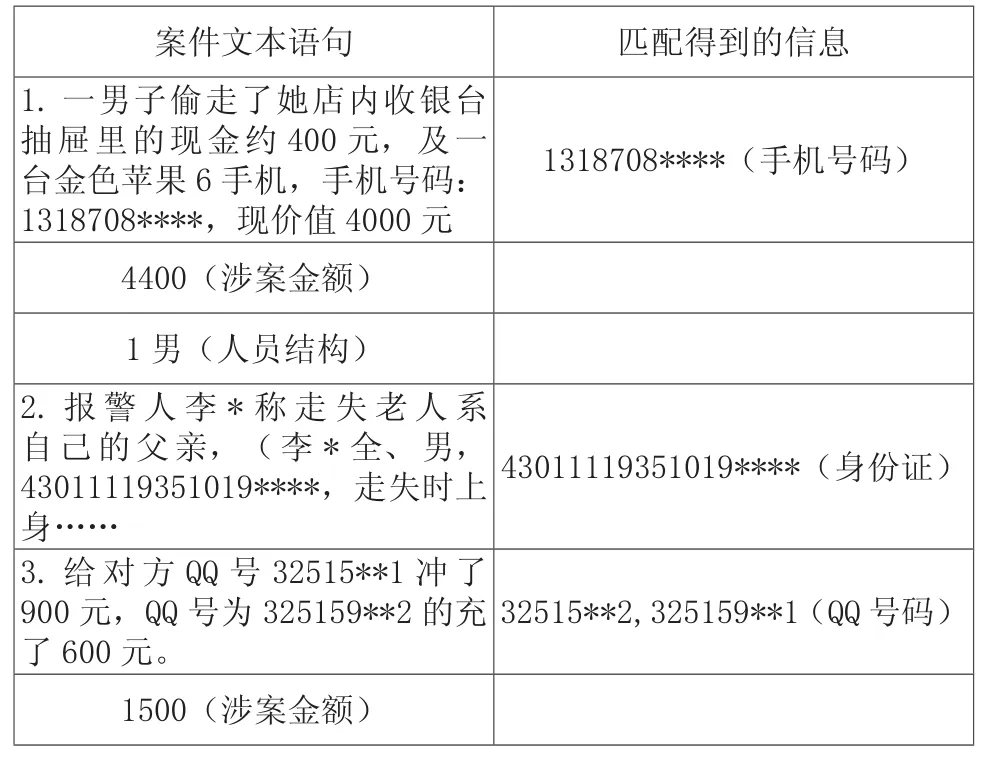
表1 信息抽取示例表
二、案件要素抽取的主要应用
(一)简化案件信息录入。自动填充相关信息项,使警务人员免于重复冗余的信息录入;
(二)支持多维度分析统计案件。在作案时间、涉案金额、身份证号、银行账号、电话号码、QQ号码、涉案网址、人员结构、交通工具、公交线路、公交站点这11个维度下对案件进行综合统计分析,有助于案件材料的归纳整理工作;
(三)自动串并案件。在原导入的案件数据的基础上,返回“串并编号”和“串并要素”。则具有相同“串并编号”的案件即为系统自动串并的案件,“串并要素”即为同组串并案件具有的相同要素信息(涉案网址、涉案银行账号、电话号码、QQ号码)。警务人员通过“串并编号”的最大值即可掌握串并案件的总组数,快速了解正在活动的犯罪团伙数量;同一“串并编号”的数量反映出每组案件的规模,从而能够科学安排警力优先针对社会影响较大的多发性案件开展侦查;通过相同的“串并编号”可将相关案件线索串联起来,更有效的侦破打击违法犯罪。所抽取出的案件要素为串并案件提供依据,串并案的意义不仅在于为侦查活动提供情报信息,还在于能够增加案件信息(特别是近年来流行的电信诈骗、微信诈骗等),促使公安机关受理案件,及时发现此类案件新的诈骗特点,是侦查人员全面了解案情,及时调整主动侦查的方向[7]。
三、案件分类
案件分类功能模块的工作流程如下图所示:
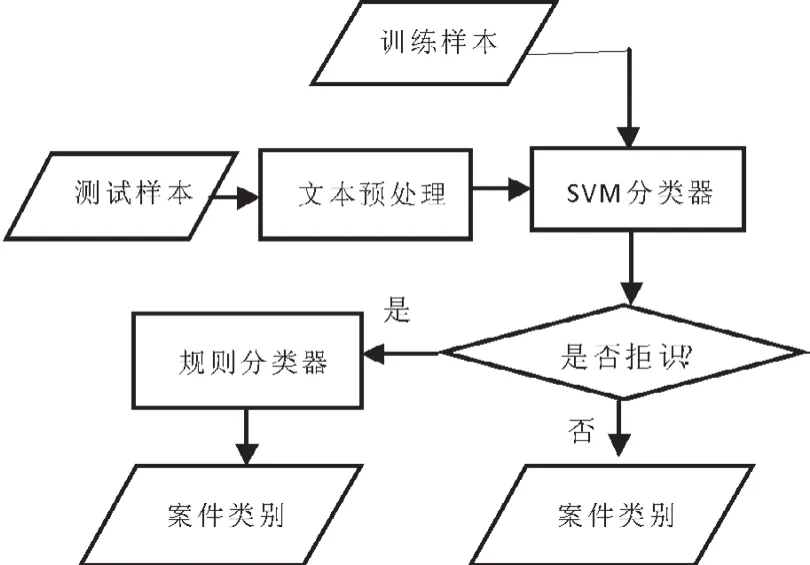
图2 案件分类工作流程图
(一)文本预处理
在案件分类之前,需要做好案件文本预处理工作,本文中的文本预处理具体流程如下图3所示。
中文分词是文本预处理流程的第一步。本文采用分词效果和运行速度都较为优秀的“Jieba”分词。“Jieba”

图3 文本预处理流程图
分词是一款目前应用广泛、口碑较好的分词工具。该分词工具可以让用户自行添加自定义词典和停用词词典,这两个特性对于案件文本的分词,具有实际应用价值,案件文本中包含不少公安领域专业词汇和地区、道路等名称词汇,将这些特殊词汇添加至自定义词典,同时将区分度差的高频词汇放入停用词典,可显著提升分词效果。
第二步,将案件文本转换成计算机能够理解的表示形式。本文采用向量空间模型(Vector Space Model,VSM)表示案件文本。该模型的主要思想是:将每一文档都映射为由一组规范化正交词条矢量张成的向量空间中的一个点。对于所有的文档类和未知文档,都可以用此空间中的词条向量(T1 , W1 , T2 , W2 ,…, Tn , Wn)来表示(其中,Ti为特征向量词条;Wi为Ti 的权重)[8]。一般需要构造一个评价函数来表示词条权重,其计算的唯一准则就是要最大限度地区别不同文档。传统的特征项的权重计算方法还有TF/IDF方法,布尔模型方法等,本文采用TF/IDF权重计算方法。
特征降维有两上级方法。一类称为特征选择(Term Selection),另一类称为特征抽取(Term Extraction)。降维后生成的特征集合的每一个元素具有更强的代表性,维数的减少意味着耗费更少的计算资源[9]。
本文采用的特征降维的方法:
建立停用词集合,分词过程中筛去停用词;
建立公安领域的同义词词典,经过同义词替换减少特征集合的维度;
在分词过程中,对分词的结果进行词性标注,筛去词性为人名的词。
(二)基于SVM的文本分类
案件自动分类模块是指训练好的分类器对给定的未知类别案件文本,自动将其归为某一类别。浙江大学的程春惠等人曾将改进的朴素贝叶斯算法应用于犯罪案件文本的分类,取得较高的分类准确率。本文分类器采用的算法为支持向量机(Support Vector Machine,SVM)分类算法。其具有坚实的理论依据和成功的实践经验,在许多领域(如手写数字识别,物体识别和文本分类)得到应用[10]。
对于支持向量机分类器,选择合适的核函数、调整类别权重与获取满意的分类准确率休戚相关。常用的核函数有线性核(Linear Kernel)、多项式核(Polynomial Kernel)、径向基核函数(Radial Basis Function)、Sigmoid核(Sigmoid Kernel)等[11]。本文的实验,对比分析了在相同数据条件下,采用线性核函数可以达到较高的准确率,这与许多文献的结论一致[12]。
现实中,每天被录入的案件种类繁多,常见的有电信诈骗、入室盗窃等,比较少见的有吸毒赌博、集资诈骗等。因此,本文根据总体案件文本类别数量不均衡的特征,采用了自动调整类别权重平衡模式,类别权重值与该类出现的频率成反比。设当前样本总数为n_ samples ,案件类别共有n_classes类,属于类别y的案件出现次数为count(y),类别y的权重值计算公式为……1
(三)层次分类结构
本文通过分析案件文本、案件类别和省厅案件细分化文件,发现案件的类别与类别之前存在层次关系,比如某一条关于在道路上实施抢劫财物的案件,不同的警务人员给定的类别就可能不同,其可被分为“抢劫”或“拦路抢劫”,实际上,拦路抢劫属于抢劫的一个类别,换而言之,“抢劫”是上级类别,“拦路抢劫”属于“抢劫”的下级类别。鉴于这种情况,本文合理地将分类器设计为层次结构,自顶向下,逐层分类。采用双层分类结构(类似于两层树结构),训练时,先将所有样本以上级类别作为标签训练上级分类器(根分类器),然后根据各个上级的案件样本子集,以下级类别作为标签训练出每个下级分类器(子分类器)。当给定一个案件样本,首先经过上级分类器获得上级类别,再经下级分类器获得下级类别(最终类别),如图4。

图4 层次分类结构
基于层次结构的支持向量机分类器,对于样本类别之间具有层次关系的样本集,可以提高分类准确率。比如在案件样本中,“车扒”和“扒窃”均为样本类别名称,实际上“车扒”是属于“扒窃”的一种类型(在公交车上作案),如果将“车扒”和“扒窃”按同级类别进行分类,“车扒”类的分类准确率仅为0.855;而将“扒窃”作为上级类别,“车扒”作为“扒窃”的下一级类别,“车扒”类的分类准确率为0.975。
在上级分类层中,案件类别差异较大,而类别数目较少,使得特征降维后的特征向量的类别区分能力强,从原理上说,支持向量机的判决函数只与支持向量有关,如果支持向量差异明显,分类间隔的宽度就比较大,从而分类准确率提高。在上级分类的准确率得到充分保障基础上,从下层各个下级类别的案件样本子集中抽取出区分能力强的特征词,构成新的特征向量。各个下级类别的分类器都有属于自己的特征向量,能减少不相关类别的信息干扰,这有利于寻找到最优分类决策面。
通过训练集生成各个支持向量机分类器模型后,便可以进行案件分类,分类工作的基本步骤如下:
除了田园,文学里的另一个神话是故乡,且经常和田园神话纠缠在一起。前一段时间,大家都在写“每个人的故乡都在沦陷”,感叹一份曾经的美好在渐渐消失。随着城市化进程的推进,中国乡村开始凋敝,这是事实。但是很多感叹不是为了哀婉这个,倒像在构建一个关于过去的田园神话。
利用“jieba”分词对案件进行分词,剔除词性为人名的词,然后经过同义词替换。
根据上级类别L1,调用对应L1类别的下级分类器,假设该下级分类器的特征集为,采用TF/IDF权重计算方法向量化该案件得到新的特征向量,最后得到由该下级分类器预测出的最终案件类别。
(四)规则分类与SVM分类结合
在SVM分类过程中,分类器的置信度是一个值得重视的参量。在决策过程中,对测试样本分别计算各个子分类器的决策函数值,并选取分类器决策函数值最大所对应的类别作为测试样本的预测类别。多采用以决策函数值作为衡量置信度大小的标准[13],在预测时,记录了每条测试样本的每个SVM分类器的决策函数值。本文经过分析研究和实验,对满足以下情况的案件样本拒识:
各个分类器的决策函数值均为负数;
仅一个分类器的决策函数值为正数,但其值很小,小于1;
出现三个及以上的分类器的决策函数值为正数。
通过对分类器的判决结果进行基于决策函数的置信度评估,拒识置信度水平相对较低的决策结果,接受置信度水平较高的决策结果。对于被拒识的案件,本文调用规则匹配分类器确定其类别。
规则匹配分类器是依据产生式规则的思想,建立事实数据库并设计规则库,基于现有的规则库示推理过程和行为。在所采用的确定性推理中,规则库中的所有规则、事实数据库中的所有事实和推导出来的结论都是正确的,它们要么成立要么不成立[14]。本文的规则匹配分类器是一个应用规则库(含875条规则,可进行增删改操作),利用逻辑关系匹配的方法检验案件文本信息的工具。规则库有多个属性列,分别为序号列,关键词列,排斥词列,类别名称列,上级类别列。规则以IF…THEN…的形式出现,IF所带的是前件(条件),THEN所带的是后件(结论),多个条件是通过逻辑运算AND,OR,NOT组合成复合条件,当完全满足条件才能推出对应的结论。例如,规则库中有这样一条规则:IF(被盗EXIT AND 卧室EXIT)AND NOT(酒店EXIT OR 旅馆EXIT)THEN(类别名称=入室盗窃,上级类别=盗窃)。
当给定一个案件,规则匹配分类器整体的匹配分类过程如图5所示:当出现遍历所有规则仍没有匹配成功,就说明对该案件分类失败。规则匹配分类器依赖于人工经验积累编写而成的规则库,适用于识别出现频率低、具备明显特征词的案件,如“纠纷”、“举报”、“涉毒”等类别的案件,对于逻辑关系复杂的案件类别容易产生错误,而且由于规则库中规则数量较多,对每一条待分类案件需要顺序遍历规则直到匹配符合,匹配每一条规则还需迭代各个关键词和排斥词,所以分类速度较慢,单条案件分类速度远慢于支持向量机分类的速度。因而本文采用以支持向量机分类为主,规则分类为辅的方法对案件进行分类,同时保证了分类速度和分类准确率。
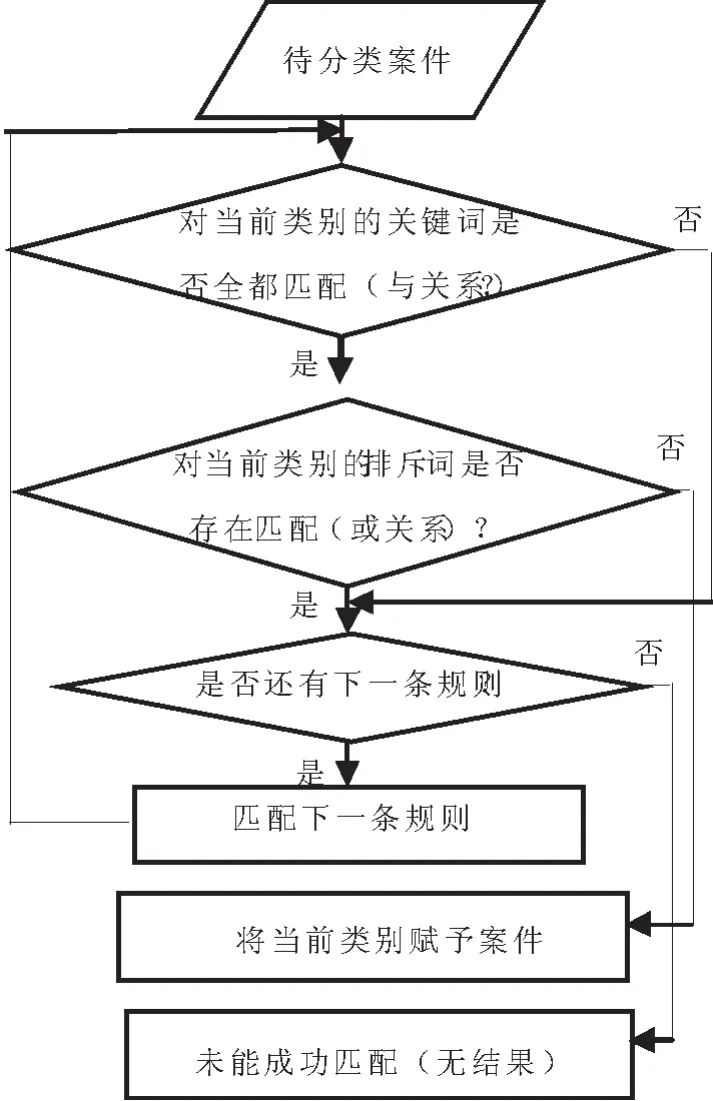
图5 匹配分类过程
四、实验与评估
本节对上述系统各模块的功能进行了测试和评估。本系统平台为Windows8.1 64 bit操作系统,实验程序所用的编写语言为Python2.7.9,数据库为MS Excel2013,程序界面简洁友好,简单易用。
(一)信息抽取评估与应用
本部分实验以2015年10月01日至2015年10月05日的8031条案件样本作为实验数据,对信息抽取功能进行了测试。
实验结果要素i被正确抽取的比例Pi为评价指标:

式中:rp为要素i被正确提取的案件个数,wp为要素i被错误提取的案件个数,up为要素i存在但未被提取的案件个数。
信息抽取效果如图6所示。
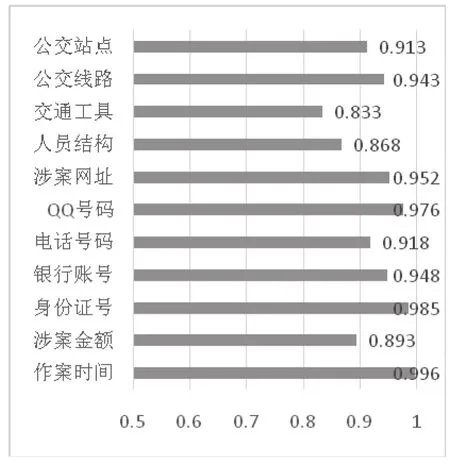
图6 各信息要素被正确抽取率
信息抽取效果评估:
1. 金额提取基本准确,但有些案件的金额涉及案件实际发生金额和非实际发生金额,实际发生金额如“被盗一部手机,现价值2000元”,非实际发生金额如“对方打来电话说自己中了五千元大奖”,其中的“五千元”也会被提取出来,这种情况下提取的是非有效金额。
2. 身份证号码、电话号码、手机号码、QQ号码提取基本全面、完整,但如上文提到暂时还不能实现区分号码所属为受害者还是嫌疑人,后续研究将借助语义分析的方法改进[15]。
3. 案件中出现的时间基本都可以提取到,目前不能区分将报案时间和案件发生时间,需要进一步的改进。
(二)案件分类评估与应用
本案件分类模块可以随时导入、添加训练样本,获得新的分类器模型,使系统满足随时改善(提高分类准确率)的要求,也可以识别新类别的案件。
本文研究对象为盗窃、诈骗等涉及财产的财产案件,样本集中多为财产案件,少量为非财产案件。对于非财产案件采用本文的拒识方法予以拒识,并由规则分类器给出案件类别。
实验以准确率作为评价指标,定义公式如下:
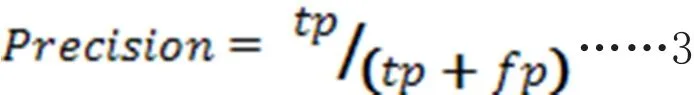
式中:tp是被正确地划分为正例的个数,fp是被错误地划分为正例的个数。
实验采用十折交叉验证法,对普通SVM分类(svm),层次SVM分类(hiersvm)、规则与层次SVM结合的分类(rule+hiersvm)的分类效果进行了比较,结果如下:
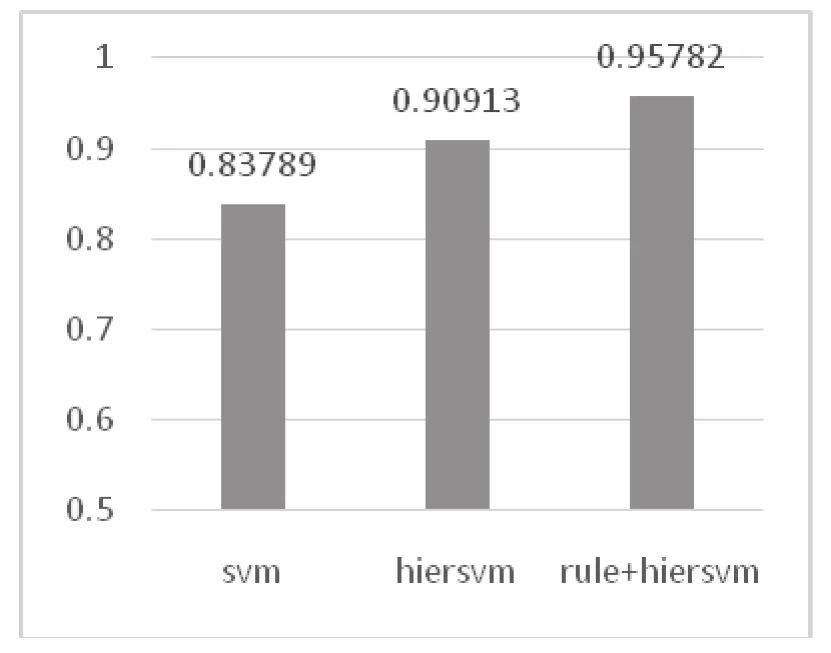
图7 分类器交叉验证实验结果
上表数据是对训练集进行交叉验证实验所得到的结果。其中SVM分类器均采用了以TF/ IDF方法计算词条权重,过滤了停用词、人名和同义词替换,核函数为线性核函数,对错误样本的惩罚因子设为1。
普通SVM分类器和层次SVM分类器的不同之处为层次SVM分类器具有层次关系结构。从图表中数据可以看到,层次SVM分类器相对于普通SVM分类器,分类准确率提高了7.124个百分点。本实验数据的层次结构比较简单,理论上来说,具有更复杂层次的实验样本数据更能凸显层次分类器的分类效果。而规则与层次SVM结合的分类又比单纯的层次SVM分类高出4.869个百分点,说明对于数量较少的非财产案件采用规则匹配分类更为合理。总体而言,规则与层次SVM结合的分类效果最优。
案件分类可应用于服务治安态势分析,预测各类案件的发生趋势,辅助警务人员决策。
[1]王晓鑫. 论“大数据”时代下的公安数据采集[J].中国科技博览,2015(5):234-234.
[2]李晓冰. 基于Apriori算法的诈骗案件关联规则挖掘研究[J].中国管理信息化, 2015(13):219-222.
[3]方世强. 浅谈数字图像处理技术识别车牌在公安领域中的应用和重要性[J]. 计算机光盘软件与应用, 2014(10):30-30.
[4]谭炽烈. 海量数据挖掘时代智能分析技术在公安领域的应用[J]. 中国安防, 2016(7):71-74.
[5]聂展云. 移动警务服务平台在公安领域的研究和实践[J].警察技术, 2014(3):44-46.
[6]周海. 基于正则表达式数据挖掘研究[J].电脑编程技巧与维护,2016(10):51-51.
[7]徐一鸣. 信息化侦查在微信诈骗案件中的应用探析[J].湖南警察学院学报,2016(3):35-35
[8]An J L, Wang Z O, Ma Z P. A new SVM multiclass classification method[J]. Information & Control, 2004, 33(3):262-267.
[9]张士豪, 顾益军, 张俊豪. 微博自动分类系统设计[J].信息网络安全,2016(1):81-87.
[10]Morales N, Toledo J, Acosta L. Path planning using a Multiclass Support Vector Machine[J]. Applied Soft Computing, 2016 (43):498–509.
[11]Brereton R G, Lloyd G R. Support Vector Machines for Classification and Regression[J]. Analyst, 2009, 135(2):230-67.
[12]赵晖. 支持向量机分类方法及其在文本分类中的应用研究[D].大连:大连理工大学,2006.
[13]赵行. SVM分类器置信度的研究[D].北京:北京邮电大学,2010.
[14]宁琳. 一种基于句法规则的文本挖掘技术的设计[J]. 现代情报, 2016(2):140-144.
[15]陈静. 基于知识的风险决策系统构架的研究[D]. 湖北大学, 2008.
[16]闫新娟. 基于隐马尔科夫模型和神经网络的入侵检测研究[D]. 南华大学, 2014.
Application of Text Mining Technology in the Field of Public Security
WEI Wen-yan1, LV Xin2, GAO Yan1
(1. School of Information Science and Engineering, Central South University, Changsha, Hunan, 410012; 2. Changsha Public Security Bureau, Changsha, Hunan, 410005)
In order to assist the police handling the case, improve the ability to collect intelligence, detect and solve the case, this paper analyzes the characteristics of text data in the field of public security cases, and applies text mining technology to the analysis and processing of public security cases, and proposes a framework of case information processing based on text mining technology. The framework mainly includes: information extraction module, case classification module. The information extraction module mainly uses the regular expression method, which can extract the cue information effectively. After the extraction of the cue information, the case with the same cue information will be concatenated. In the case classification module, a SVM classifier and a rule classifier are constructed, which combine the two cases to classify the cases. The function and performance of the framework are tested under a certain data set, and satisfactory results are obtained.
natural language processing; data mining; information extraction; SVM
D631.2
A
2095-1140(2017)03-0000-00
2017-3-19
魏文燕(1991- ),女,浙江余姚人,中南大学信息科学与工程学院2014级控制工程专业硕士研究生,主要从事数据挖掘、机器学习研究;吕 鑫(1987- ),男,湖南长沙人,长沙市公安局助理工程师,主要从事警务人工智能研究;高 琰(1974- ),女,中南大学副教授,博士,主要从事数据挖掘、智能信息处理研究。
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-29
数学小灵通(1-2年级)(2021年4期)2021-06-09
民族古籍研究(2018年1期)2018-05-21
Coco薇(2017年11期)2018-01-03
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
暨南学报(哲学社会科学版)(2016年9期)2017-01-15
新校长(2016年8期)2016-01-10
浙江大学学报(工学版)(2015年1期)2015-03-01
航天返回与遥感(2014年5期)2014-07-31
