
虚拟环境下硬件事务内存辅助的同步机制*
2017-09-18 00:28余倩倩董明凯陈海波
计算机与生活 2017年9期
余倩倩,董明凯,陈海波
上海交通大学 并行与分布式系统研究所,上海 200240
虚拟环境下硬件事务内存辅助的同步机制*
余倩倩+,董明凯,陈海波
上海交通大学 并行与分布式系统研究所,上海 200240
虚拟化;硬件事务内存;同步机制
1 引言
随着虚拟化潮流的兴起,多台独立的虚拟机被整合在一台物理机中,从而充分利用硬件的处理性能。流行的系统虚拟化工具有VMware[1]、Xen[2]、KVM(kernel-based virtual machine)[3]等。在现有的虚拟化架构中,虚拟机监视器(virtual machine manager,VMM)负责模拟和调度物理硬件资源,为虚拟机提供虚拟化资源。理想状态下,虚拟化环境能够提供近似于物理机器的性能,这需要虚拟机监视器提供有效的资源模拟和调度,以此来满足虚拟机对物理资源的需求。
对于处理器资源的模拟与调度,虚拟机监视器将每一个虚拟处理器(virtual CPU,vCPU)视为一个进程,并通过向虚拟处理器提供物理处理器的时间片的方式来实现对虚拟处理器的调度。一个虚拟处理器的调度过程为:虚拟机监视器将该虚拟处理器进程分配到某一物理处理器上,从而为虚拟机提供处理器资源。虚拟机监视器负责初始化以及保存和恢复虚拟处理器的状态,从而使得虚拟机能够有效工作。一个虚拟处理器的抢占过程通常在硬件辅助下实现,方法为:中断发生后,虚拟机退出并将控制权传给虚拟机监视器,后者在中断处理函数中,负责保存虚拟处理器的状态信息,包括寄存器信息、虚拟机退出原因等,然后切换运行其他的进程。该方法能够简单地实现虚拟机监视器对虚拟处理器的调度机制,同时提供较优的性能,因此被广泛应用于各系统虚拟化工具中。
然而,上述方法也容易因为双重调度问题而引发效率问题。双重调度[4-5]指,在虚拟机监视器调度虚拟处理器的同时,虚拟机内部的内核调度器也在调度虚拟机内部的进程。在双重调度的情况下,一方面,虚拟机监视器调度虚拟处理器,使后者运行于分散的时间片上,不能保证其连续运行[6],与物理处理器产生了语义缝隙[4];另一方面,虚拟机内部的内核调度器认为虚拟处理器的运行是连续的,可能要求不同的虚拟处理器相互协作来完成同步机制。然而,当一个虚拟处理器被抢占时,其将处于无法响应状态,也就无法完成同步机制的协作任务,导致其他虚拟处理器的运行被阻塞,产生较大的性能影响。
在Linux操作系统中,排队自旋锁(ticket spinlock)是同步机制的基础构成。操作系统一般通过排队自旋锁来实现互斥性,同时保证系统的公平性和可伸缩性。排队自旋锁多用于处理短暂的、不可抢占的任务。在虚拟化环境中,虚拟处理器的引入使得排队自旋锁的公平性和可伸缩性变得不确定,产生了自旋锁持锁者被抢占问题[7]和自旋锁等候者被抢占问题[8],即当一个持有或等待排队自旋锁的虚拟处理器被抢占后,可能引起其他处理器的等待,阻塞整个系统,从而浪费了处理器资源。因此,优化虚拟化环境下同步机制的性能对系统整体性能是至关重要的。
硬件事务内存(hardware transactional memory)[9-10]的出现,允许一组指令原子性地执行,且不需要多处理器之间的相互协作,拥有低开销和易使用的优点。更重要的是,事务区间内的整体代码段只可能原子性地提交或者整个被中断及回退,使得硬件事务内存拥有不被打断的特性。即使在虚拟化环境下,若虚拟处理器被抢占,那么该处理器上的硬件事务内存将会发生中断,也同样能够保证硬件事务内存拥有不被打断的特性。近年来,硬件事务内存在英特尔处理器中被广泛使用,为优化同步机制提供了新的方向。如何更好地利用硬件事务内存缓解双重调度问题,来提高虚拟化环境下同步机制的效率,同时最大程度地维护同步机制的公平性和可伸缩性,是一个非常重要的研究课题。
本文硬件事务内存的辅助下,提出了一种优化虚拟化环境下同步机制的方法,设计了一种新的同步机制,实现了对系统性能和公平性的提升。
本文组织结构如下:第2章介绍了虚拟化环境下同步机制相关的背景和工作,包括排队自旋锁的工作原理和虚拟机监视器的基本调度机制;第3、第4章介绍了SPINRTM的设计与实现,包括所涉及的硬件事务内存的应用,以及对虚拟机操作系统与虚拟机监视器中各组件的修改;第5章是针对SPINRTM的测试结果,并且和未加修改的排队自旋锁进行了对比和分析;第6章是本文工作的总结和展望。
2 背景
2.1 硬件事务内存
事务内存[11]允许一组指令原子性地执行,并且完全与多处理器架构中的其他处理器隔离开来,不需要多处理器的相互协作。它是一种并行控制机制,类似于数据库中用来并行访问共享数据的数据库事务。与其他同步机制(比如自旋锁)相比,事务内存具有语义清晰和易于编程的特点。由于软件事务内存普遍开销巨大,而硬件事务内存不仅开销小,而且在近年来广泛内置于处理器之中,故本文仅讨论硬件事务内存。本文以英特尔公司的硬件事务内存——限制性事务内存为例,进行研究与设计。
英特尔事务同步扩展[12](Intel transactional synchronization extension)是英特尔公司针对限制性内存的扩展指令集。这一扩展允许处理器使用硬件事务内存,以一种乐观的方式来实现同步机制。在事务区间内的代码运行时,由硬件负责监控多个线程之间是否发生冲突,并在事务无法成功提交时,中断和回滚事务,再交由软件来处理失败的事务。该技术通过硬件实现了同步机制,又隐藏了其实现细节,仅仅向软件提供了同步机制的接口,简化了编程的难度。不仅如此,该技术允许程序员将限制性事务内存作为同步机制的一条快速路径,将普通软件锁作为一条慢速路径(回退机制),是软件锁的一种有效替代方式。
如果一个事务的执行成功提交了,那么硬件将保证事务区间里的所有内存修改都会同时生效。对于其他逻辑处理器而言,这些内存修改会原子性地出现。上述事件被称为原子性提交。任何事务区间内的内存修改都只有在原子性提交之后,才能对其他处理器可见。由于一个事务内存的成功提交保证了事务区间内代码段的原子性,程序员可以将事务区间内的代码段指定为临界区间代码,从而使用事务内存这种乐观的同步机制实现方式来代替锁这种悲观的实现方式。即使当同步机制对于该事务区间代码段的执行实际是多余的时,该事务内存也能够在不需要线程间进行同步的情况下原子性提交,使得该代码段生效。
如果一个事务的执行中断了,那么处理器就不能原子性地提交该事务。在这种情况下,处理器会回滚该事务。上述事件被称为事务中断。在一个事务中断发生时,处理器会丢弃在事务区间内做出的所有修改,恢复处理器架构的状态至事务开始之前,形成该事务从未发生的假象,并且非事务性地恢复执行流。基于硬件事务内存的设计特点,一个失败的事务可能被重试多次,并且在多次失败后显式地获取一把锁,来保证执行流向前发展。
2.2 内核排队自旋锁
内核排队自旋锁的设计通过模拟一条先进先出的队列来实现有序的同步机制。在具体实现中,每个自旋锁维护一个2 Byte的整形变量,并将其划分为两个1 Byte的整形变量:Next和Owner。这两个变量表示队列中的两个票号,分别对应于入队的票号和出队的票号。Next表示这个队列中管理者要分发的下一个票号;Owner表示这个队列中当前正在接受服务的票号。
在初始化时,自旋锁维护的两个整形变量被赋值为0。获取锁时,spin_lock函数体会原子性地获取锁变量的值,同时将next变量的值加1。next变量增加之前的值也就是该线程获取的票号,会作为其取锁顺序的依据。当这个票号与自旋锁owner变量的值相等时,系统则判断该线程成功获取了该排队自旋锁;当这个票号与owner变量的值不等时,系统则判断该线程未能成功获取锁,此时该线程将会阻塞在这个变量上,直到自旋锁owner变量增长到与该线程票号相等的数值。值得注意的是,在内核排队自旋锁中,处理器在获取锁之前会关闭中断,即不会发生进程调度。因此,在等待锁获取成功的时间段中,该处理器会处于忙等状态,而无法处理其他任务。
在非排队自旋锁(即普通自旋锁)的实现中,所有处理器可能会同时竞争同一把锁,“争抢”谁能够第一个获取锁。该机制既没有一个明确的锁获取顺序,也不能保证获取锁的最长等待时间。而在排队自旋锁的实现中,各线程能够依据其最初的到达时间来有序地获取锁;多线程的运行时间能够得到均衡;最长等待时间也会有所下降(更重要的是,这成为了确定性事件,有一个确定的顺序)。虽然排队自旋锁的实现引入了额外的处理器开销,但是相对于普通自旋锁中频繁引发的高速缓存未命中的开销,尤其对于时下流行的多处理器架构而言,这样的额外开销是十分小的,几乎可以忽略。从系统内核的角度考虑,维护各处理器之间的公平性比节省这样的开销要重要得多。
2.3 锁持有者抢占和锁等待者问题
在虚拟机监视器和虚拟机内核调度器的双重调度下,虚拟机内核中的同步机制可能会引发严重的性能问题。相关的常见场景有锁持有者被抢占问题和锁等待者被抢占问题。
锁持有者被抢占问题指,一个虚拟处理器在成功获取排队自旋锁之后,释放该锁之前,被抢占。该问题将导致其他虚拟处理器在获取锁时,只能忙等,无法进展,余下的时间片就会被浪费。如图1,vCPU0和vCPU1先后获取了排队自旋锁,vCPU0在临界区间中被抢占,导致vCPU1只能忙等,后续时间片整个被浪费。由于虚拟处理器的时间片调度粒度一般为毫秒级别,而排队自旋锁的等待粒度一般为微秒级别,当上述问题发生时,该锁的获取时间将被延长千倍级别,这一影响就变得不可忽视。
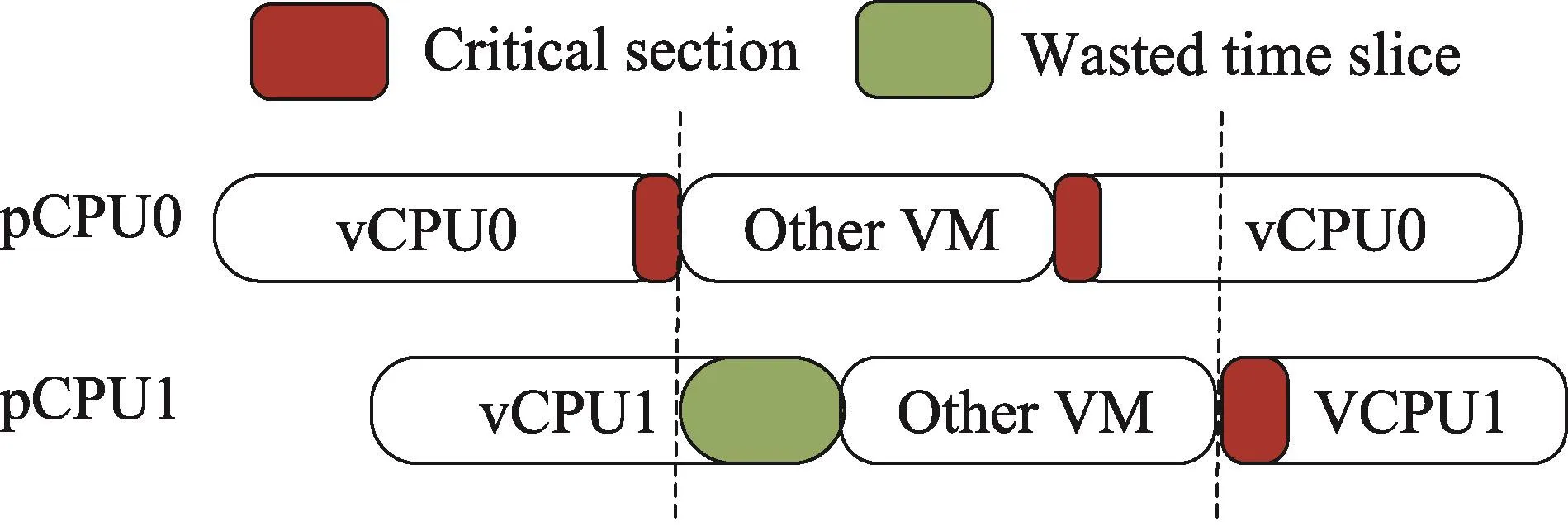
Fig.1 Lock holder example图1 锁持有者问题例图
锁等待者被抢占问题指,一个虚拟处理器在获取排队自旋锁票号,进入等待后,被抢占。该问题将导致票号在此虚拟处理器之后的线程只能忙等,无法进展。如图2,vCPU0、vCPU1、vCPU2先后获取了排队自旋锁,vCPU0释放排队自旋锁后,由于vCPU1被抢占,使得vCPU2只能忙等,剩余时间片被浪费。与锁抢占者问题一样,上述问题也会带来不可忽视的负面影响。
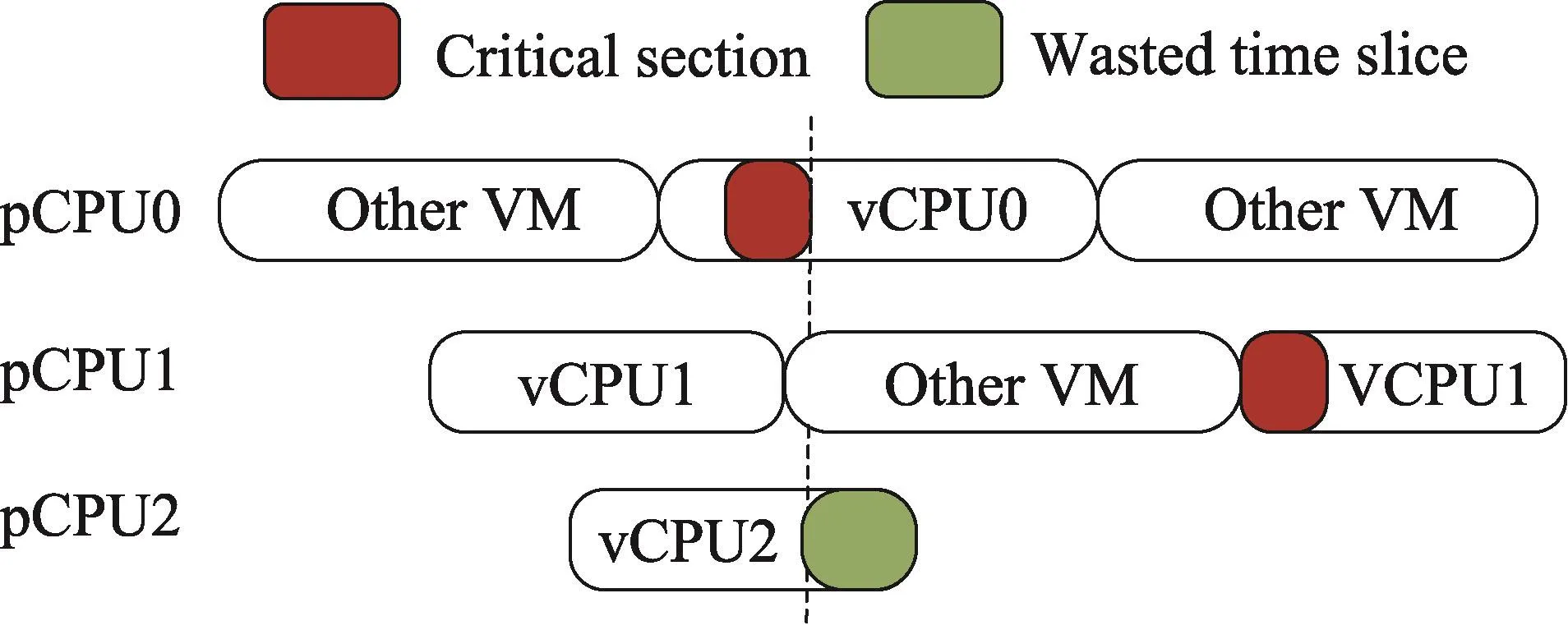
Fig.2 Lock waiter example图2 锁等待者问题例图
3 设计与实现
3.1 限制性事务内存的特性利用
锁持有者抢占问题和锁等待者抢占问题有一个共性:在问题发生时,持有锁或者等待锁的虚拟处理器被虚拟机监视器所抢占。由于在抢占机制实现中,虚拟处理器会首先收到一个来自物理处理器的中断,若这个虚拟处理器此时已经开启了硬件事务内存,则硬件事务内存能够通过物理处理器引发的事务中断来感知抢占事件,从而做出回退措施,并对锁持有者抢占问题和锁等待者抢占问题做出相应的处理。
详细地来说,在一个虚拟机运行时,一个虚拟处理器占用物理处理器的一个时间片。当一个虚拟处理器被抢占时,这个虚拟处理器会接收到来自物理处理器的一个中断,如果该虚拟处理器的限制性事务内存已经开启,那么此时硬件事务内存就会被中断。作为结果,这个虚拟处理器的执行流就会跳转到限制性事务内存的回退路径上,同时虚拟机监视器的执行流也会跳转到抢占处理函数上,并且限制性事务内存中所做的所有内存修改都会被回退,恢复到限制性事务内存开启前的状态。这一硬件特性是本文设计中利用的最核心的特性。通过限制性事务内存的这一特性,来对虚拟处理器的抢占做出额外的判断与操作,从而提高同步机制在虚拟环境下的效率。
在实际测试中发现,虚拟机监视器的控制流优先级高于限制性事务内存回退路径的控制流。因此,在抢占中断发生时,物理处理器的控制流会跳转至虚拟机监视器的抢占回调函数中。
3.2 硬件事务内存辅助排队自旋锁的设计
3.2.1SPINRTM的设计
多核处理器程序通常需要使用同步机制保护共享数据的访问。其中,锁是一种悲观的同步机制实现方式,通常适用于竞争较高的场景;事务内存是一种乐观的实现方式,通常适用于竞争较低的场景。在朴素的设计方式中,使用硬件事务内存直接代替排队自旋锁会产生大量的事务中断。这是由于在竞争较高的情况下,共享数据的访问在事务区间中产生大量的数据冲突,这些冲突导致了限制性事务内存的频繁中断,进而产生巨大的开销。频繁的事务中断不仅会回滚事务开启后提交前在临界区间的所有修改,浪费处理器资源,而且会引发大量的事务重试,重复事务内存的开启与临界区间内的指令,极大地加剧了硬件事务内存的同步开销。为了避免这种情况对系统整体性能的影响,本文提出了一种新的设计方式:使用限制性事务内存来辅助内核排队自旋锁的同步机制。这一设计利用排队自旋锁来避免大量的数据冲突,同时利用限制性事务内存来避免双重调度产生的效率问题。伪代码见图3。

Fig.3 Pseudo code图3 伪代码
3.2.2 锁持有者问题的解决
为了解决锁持有者问题,必须保证临界区间代码段的不被打断性,即一个虚拟处理器不能在持有锁的时候被抢占。
在实现中,有两种方式:一是延长锁持有者的时间片长度,使该虚拟处理器能够在被抢占前完成临界区间的代码段,并释放该锁;二是延迟临界区间的执行时间,使它完全在下一个时间片中被执行。由于延长虚拟处理器时间片的方法会进一步影响虚拟机监视器中调度机制的公平性,本文采用了后一种方式,即延迟临界区间的执行时间。在传统的排队自旋锁中,这种方式是难以实现的,因为在虚拟处理器获取锁时,处理器无法预知其是否会在临界区间内被打断,所以也无法决定这个获取锁的操作是否需要被延迟。而在硬件事务内存的辅助下,可以使用事务内存的中断和回滚功能,来模拟达到延迟的效果。在事务内存发生中断时,这个事务中做的所有内存修改都将被回滚,恢复到事务发生之前的状态。事务中断后的状态与事务未开始时的状态是一致的,因此这个效果就可以等效为事务被延迟执行。
通过延迟整个临界区间的执行,当一个虚拟处理器被抢占时,其他虚拟处理器依然能够进入临界区间而不被其阻塞,这一方法能够有效地缓解锁持有者问题带来的性能影响。
3.2.3 锁等待者问题的解决
首先,SPINRTM能够有效缓解锁持有者问题。SPINRTM减短了虚拟处理器获取一个锁时的等待时间,因而降低了锁等待者抢占问题的发生概率。而通过降低发生的概率,SPINRTM能够缓解锁等待者问题带来的性能影响。
此外,文献[13]通过半虚拟化技术主动唤醒被抢占的虚拟处理器(锁等待者);文献[8]通过放宽锁获取的顺序,来允许其他虚拟处理器率先获取锁。这两种方法都能够有效缓解锁等待者问题。SPINRTM与以上两种方法是完全兼容的。
3.3 虚拟机监视器与虚拟机内核的协同实现
3.3.1 虚拟机内核的预先处理
每个虚拟机内核会在启动时,向虚拟机监视器申请注册一块共享内存。在这块共享内存中,会保存虚拟机监视器中被抢占排队自旋锁的信息,用以帮助虚拟机监视器来协助虚拟处理器释放锁。这些信息包括排队自旋锁的地址和票号。
3.3.2 虚拟机监视器解锁
在虚拟处理器被抢占后,控制流会进入虚拟机监视器的抢占回调函数中。在这个回调函数中,虚拟机监视器会检查该虚拟处理器是否是一个锁持有者,并且在检测出是锁持有者时,协助该虚拟处理器释放锁。此时,虽然该虚拟处理器仍然持有锁,但是它在持锁后做的所有内存修改都已经被硬件事务内存恢复,因此可以释放锁而不引起正确性问题。
虚拟机监视器的解锁分为两个步骤:一是判断虚拟处理器是否为一个锁抢占者;二是释放该锁。
在本文的实现中,对锁抢占者的判断基于PC寄存器(program counter)的地址。一个锁持有者在被抢占时,它开启的限制性事务内存就会被中断,使得控制流(即PC)指向限制性事务内存的回退路径地址上。在限制性事务内存没有中断时,PC是不会指向此地址的。因此,通过PC地址的判断,能够分辨出一个虚拟处理器是否为一个锁持有者。在Linux内核3.18.24的具体实现中,由于内联函数的原因,这样的PC地址可能有3个,需要分别进行判断。另外,需要在虚拟机启动前,事先获取这些地址。
释放锁的实质非常简单,就是对锁的票号进行原子性增加。此处有一个需要注意的地方就是,锁的增加量可能为1,也可能为2。在默认配置的虚拟机内核中(半虚拟化锁不开启),这个增加量为1。而在开启了半虚拟化锁的内核中,由于半虚拟化锁的实现需要,票号的最后一个比特被用作额外标示,因此锁的增加量调整为2。虚拟机监视器也需要对这项配置事先了解,以正确解锁。本文的实现中,虚拟机监视器在启动前已获取具体的增加量。
3.3.3 虚拟机内核的回退路径
限制性事务内存中断后,虚拟处理器的控制流会跳转到回退路径上。此时,中断处理函数需要对两种可能的情况进行处理:一是中断原因来自虚拟机内部;二是中断原因来自虚拟机外部,比如抢占和其他中断。当中断原因来自虚拟机内部时,虚拟机内核可以继续重试事务内存,或者放弃事务内存回退至原始的排队自旋锁。当中断原因来自虚拟机外部时,中断处理函数需要判断该虚拟处理器是否被抢占,如果被抢占,是否被协助释放了锁。在锁没有被协助释放的情况下,中断函数的处理机制与第一种情况类似。而在锁被协助释放的情况下,中断处理函数就需要重新获取锁,以保证临界区间的互斥性。
中断处理函数对锁是否被协助释放的判断方法如下。在限制性事务内存开启之前保存票号,并在回退路径上将再次读取的票号与之比对,若不相等,则锁已被协助释放。原因有两点:首先,协助释放锁必然导致两个票号不相等。抢占与协助释放锁必然发生在限制性事务内存开启之后,回退路径开始之前。如果协助释放锁的操作发生了,那么虚拟处理器记录下的票号就对应释放锁之前的票号,再读的票号就对应释放锁之后的票号,两个票号必然是不等的。其次,两个票号不相等必然是因为虚拟监视器协助释放了锁。在事务开启之前,该虚拟处理器已经获取了排队自旋锁,因此其他虚拟处理器无法进行获取锁和释放锁的操作。此时,仅有该虚拟处理器自身和虚拟机监视器能够执行释放锁的操作。因此,这个锁的释放只能来自于虚拟机监视器。
4 测试与分析
本文通过测试对SPINRTM的性能和公平性进行评估。测试在Intel Xeon®E5-2650 V3@2.3 GHz的处理器上进行,共20个CPU并配有128 GB内存。为了测试的准确性,关闭了超线程支持和Turbo Boost功能。
测试给每台虚拟机配置了20个虚拟处理器和8GB内存。本地和虚拟机都搭载了Linux内核3.18.24。测试选择了3个基准程序来检测系统性能,Kernbench、Apache[14]和Pbzip2[15],分别属于处理器密集型、内存密集型和输入输出密集型工作。基准配置(Baseline)采用未修改的虚拟机内核与虚拟机监视器。
4.1 处理器密集型测试
图4显示了运行Kernbench基准程序的性能结果。本测试中,Kernbench会重复编译系统内核,取5次运行时间平均值作为结果。本测试中配置的虚拟机内存为8 GB,大于一个系统内核的大小,因此Kernbench主要体现为一个处理器密集型基准程序。在基准配置的1台和4台虚拟机的结果比对中,4台虚拟机的运行时间要小于1台机器的4倍。可以发现,虽然配备了更多的虚拟机,使得虚拟资源超载了物理资源,实际上系统的整体效率却得到了提升。这是因为在Kernbench中,虚拟处理器的资源成为瓶颈,而锁竞争对整体性能的影响很小。在超载情况加剧时,并不引发锁的效率问题,反而能进一步提高处理器的利用率。SPINRTM比基准配置提供了更低的性能,其原因在于限制性事务内存的使用增加了同步机制的开销,限制性事务内存的中断和处理更加剧了这一问题。
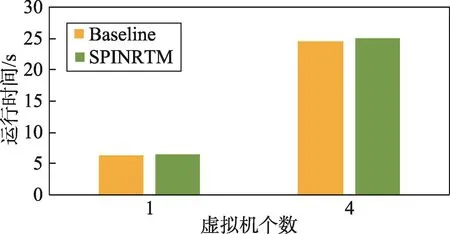
Fig.4 Execution time of Kernbench图4 Kernbench运行时间示意图
4.2 内存密集型测试
图5显示了运行Apache的性能结果。在本测试中,Apache会向本机发送10 000个包,取平均吞吐量作为结果。当运行4台虚拟机时,取所有虚拟机的吞吐量之和。频繁的发包与收包包含了大量的内存操作,因此Apache是一个内存密集的基准测试程序。在测试结果中可以发现,当运行4台虚拟机时,系统的整体总吞吐量小于运行1台虚拟机时的整体吞吐量,这是因为受到了双重调度的严重影响。相比基准配置的性能,在运行1台虚拟机时,由于限制性事务内存的处理开销,SPINRTM给系统带来了额外的开销。然而,在4台虚拟机的运行结果中,由于Apache程序频繁的内存操作,使得内核需要通过排队自旋锁来进行内存管理,在这一过程中,引入了严重的双重调度问题。SPINRTM通过对双重调度问题的缓解,提升了Apache程序的性能。
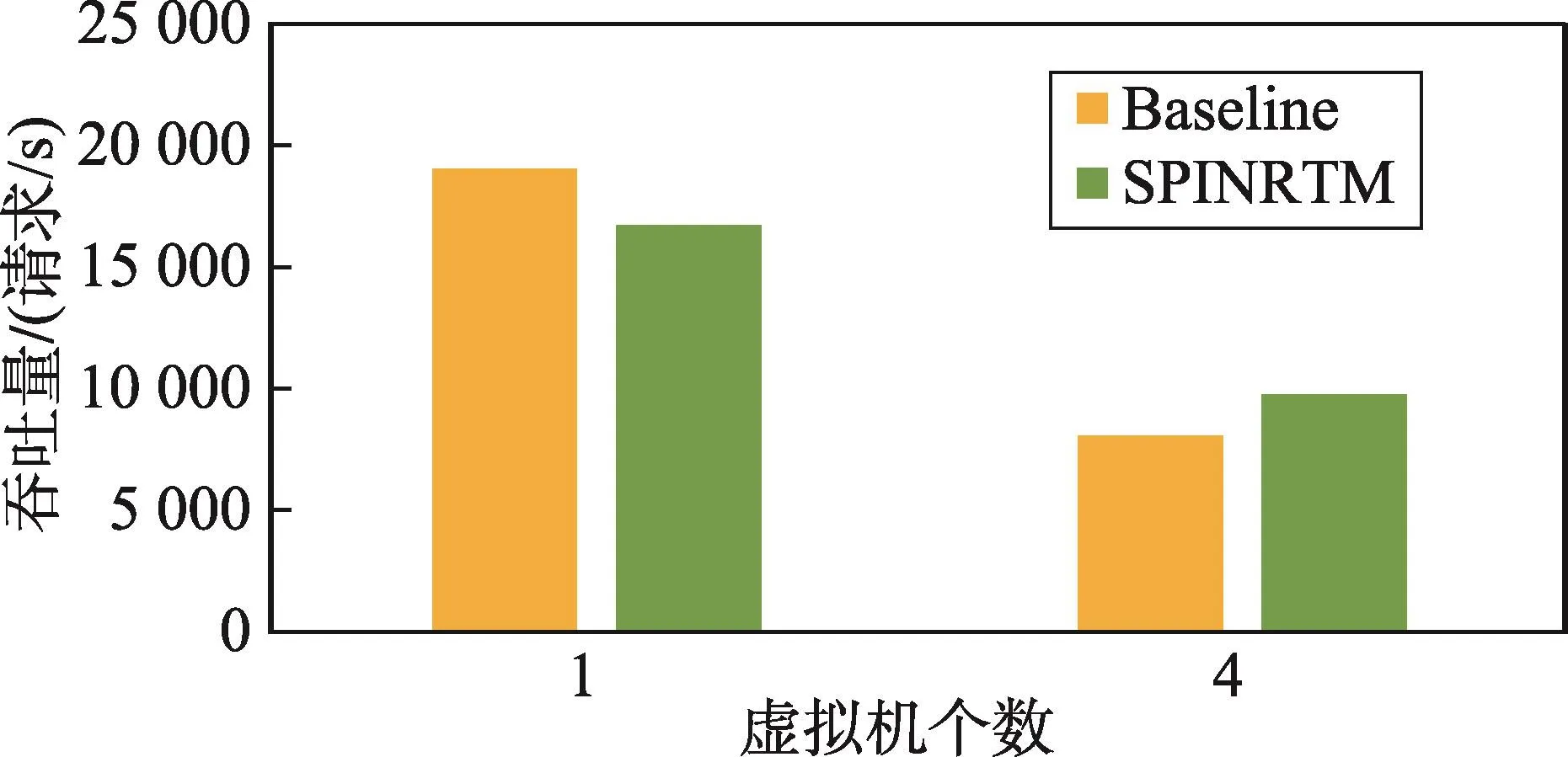
Fig.5 Throughput ofApache图5 Apache吞吐量示意图
4.3 输入输出密集型测试
图6显示了运行Pbzip2的性能结果。在本测试中,Pbzip2会解压缩一个大小为4 GB的文件,取5次运行时间的平均值作为结果。由于Pbzip2的解压过程需要系统频繁地从磁盘读出写入数据,使得Pbzip2成为一个输入输出密集型基准程序。与Apache相似,当运行4台虚拟机时,系统的运行时间大于运行1台虚拟机时的4倍,同样受到了双重调度的影响。相比基准配置的性能,在运行1台虚拟机时,SPINRTM就能小幅度地提高系统性能,缩短运行时间;在运行4台虚拟机时,SPINRTM的性能提升就变得更加明显。原因在于,Pbzip2不仅对系统资源的分配效率有很大的要求,涉及大量的排队自旋锁操作,而且频繁、昂贵的磁盘操作增加了双重调度问题的发生频率,延长了等待时间。因此,SPINRTM有效地缓解了这一问题。
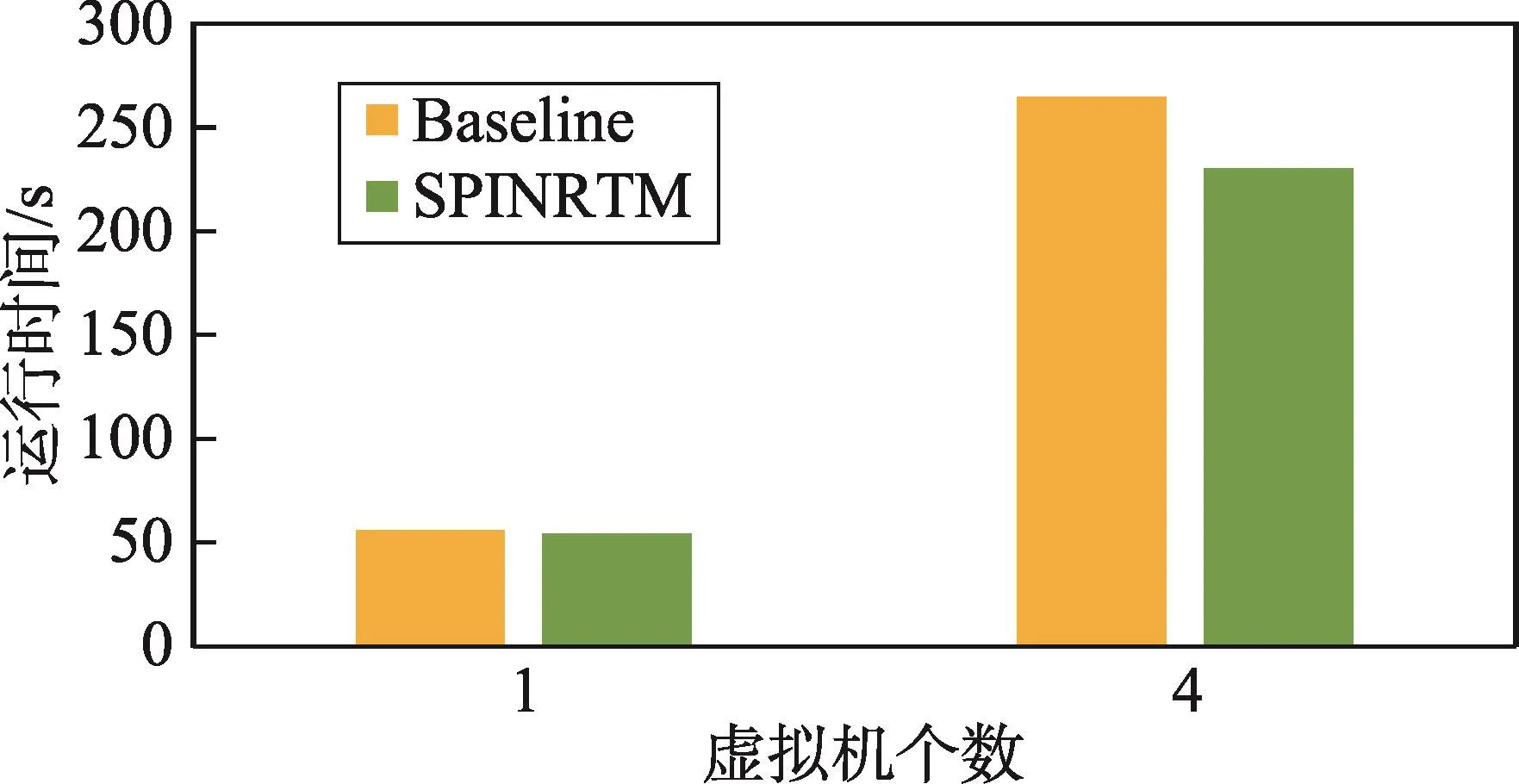
Fig.6 Runtime of Pbzip2图6 Pbzip2运行时间示意图
4.4 公平性测试
为了比较各虚拟机之间的公平性问题,本文计算了各基准程序在多虚拟机运行时测试结果的标准差,将SPINRTM与基准配置的结果相比较,结果如表1所示。
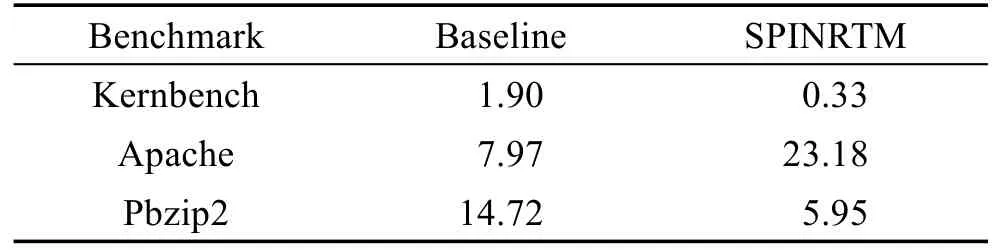
Table 1 Performance standard deviation表1 性能标准差
可以发现基准配置本身就有一定偏移量,这是由于虚拟机监视器的调度本身就不能完全保证虚拟机之间的公平性,虚拟机内核的一些通信机制,如锁,更加剧了这一问题。比对两种配置的标准差结果,虽然SPINRTM没有提升Kernbench的性能,却降低了它的不公平性。Apache的结果恰恰相反,SPINRTM提升了性能,却小幅度加剧了不公平问题,但是影响较小,可以忽略。Pbzip2在性能和公平性上都得到了提升。
总体来看,SPINRTM能够保护虚拟机之间的公平性,并且与其总体性能无关。
5 相关工作
最初,虚拟机监视器通过要求每个虚拟机同时调度[16]的方式来解决虚拟机内核中同步机制的问题,即要求同一个虚拟机的所有虚拟处理器同时被调度,或者同时被抢占。上述方法被VMware ESX[17]的虚拟机调度器采用。然而,该方法对虚拟处理器的最大支持数量以及虚拟机监视器的调度器算法施加了很多限制。其后,协同调度[18]是一种新的解决方法,即由虚拟机监视器动态地为一个虚拟机指定其协同调度和异步调度的虚拟处理器。该调度对虚拟处理器的选择方法是基于虚拟机内核对于长期阻塞的排队自旋锁的检测。文献[19]提出了一种自适应的虚拟机放置框架和算法,根据资源的需求,动态调整虚拟机资源。最后,在虚拟机动态自适应调度法[20]中,提出了一种平衡调度机制,将一个虚拟机的单个虚拟处理器与物理处理器联系起来,而不要求这些虚拟处理器被协同调度。这一方法同样增加了主机端(host)的负担。
半虚拟化自旋锁是一种通过半虚拟化技术来优化排队自旋锁效率的机制。它首次在文献[7]中被提出,采用了一种避免抢占的策略,通过虚拟机内核向虚拟机监视器发送提示,来防止排队自旋锁持有者被抢占。这一提示向虚拟机监视器表明,当前虚拟处理器是一个排队自旋锁的持有者,正进入一个不可被抢占的临界区间。半虚拟化技术在半虚拟化排队自旋锁[13]中又一次被采用,并被整合入虚拟机监视器Xen和内核虚拟机KVM的代码中。该文用一个计数器来检测一个虚拟处理器等待排队自旋锁的时间。当等待时间异乎寻常得长,也就是当虚拟处理器用在等待上的自旋次数超过一定阈值时,该虚拟处理器就会向当前虚拟机监视器发送一个超调用(hypercall),表示当前虚拟处理器被一个其他虚拟处理器持有的排队自旋锁阻塞了。随之,虚拟机监视器就会停止调度(抢占)当前被阻塞的虚拟处理器,直到该排队自旋锁被释放。这两种方法都能够提供较好的性能。然而,半虚拟化技术要求对虚拟机内核进行修改,从而会产生兼容问题和标准化问题。并且,这些方法只能解决排队自旋锁持有者被抢占的问题,而忽略了排队自旋锁等待者被抢占的问题。
硬件辅助的方式也能够被用来缓解虚拟环境下同步机制的效率问题。例如,处理器的暂停-循环-退出机制,现在的处理器一般均支持这一机制。首先,虚拟机内核中的自旋锁在每一次自旋时,都会执行一句暂停语句。然后,当一个物理处理器检测到过多的暂停时,即在一个短时间内暂停指令的执行次数超过一个预先设定的阈值时,虚拟机监视器就会产生一个虚拟机退出指令。此时,虚拟机监视器将会抢占当前虚拟处理器,同时寻找并调度另一个等待被执行的虚拟处理器。这样做的目的在于,期望新的虚拟处理器能够执行有用的指令,而不是忙等,从而将更多的处理器时间用在处理有效的指令上。这种方式也有缺点:虽然提高了物理处理器的有效利用率,却也影响了虚拟处理器之间的公平性。
6 结束语
双重调度是虚拟环境下不容忽视的问题。本文研究了内核的同步机制和虚拟机监视器的调度机制,结合硬件事务内存的特点,提出了一种虚拟环境下由硬件事务内存辅助的同步机制SPINRTM。SPINRTM在内核排队自旋锁的基础上,由硬件事务内存辅助,使虚拟机监视器与虚拟处理器相互协助,有效地帮助系统缓解了虚拟环境下双重调度产生的问题,提升性能,保护公平性。未来的工作中,还将考虑该设计在其他平台上的进一步优化。
[1]Rosenblum M.Virtual platformTM—a virtual machine monitor for a commodity PC[C]//Proceedings of the Symposium of High-Performance Chips,Stanford,Aug 15-17,1999.
[2]Barham P,Dragovic B,Fraser K,et al.Xen and the art of virtualization[J].ACM SIGOPS Operating Systems Review,2003,37(5):164-177.
[3]Kivity A,Kamay Y,Laor D,et al.KVM:the Linux virtual machine monitor[J].Proceedings of the Linux Symposium,2007,1:225-230.
[4]Jin Hai,Zhong Alin,Wu Song,et al.Virtual machine VCPU scheduling in the multi-core environment:issues and challenges[J].Journal of Computer Research and Development,2011,48(7):1216-1224.
[5]Song Xiang,Shi Jicheng,Chen Haibo,et al.Schedule processes,not VCPUs[C]//Proceedings of the 4th Asia-Pacific Workshop on Systems,Singapore,Jul 29-30,2013.New York:ACM,2013:1.
[6]Ahn J,Chang H P,Huh J.Micro-sliced virtual processors to hide the effect of discontinuous CPU availability for consolidated systems[C]//Proceedings of the 47th Annual IEEE/ACM International Symposium on Microarchitecture,Cambridge,UK,Dec 13-17,2014.Washington:IEEE Computer Society,2014:394-405.
[7]Uhlig V,LeVasseur J,Skoglund E,et al.Towards scalable multiprocessor virtual machines[C]//Proceedings of the 3rd Virtual Machine Research and Technology Symposium,San Jose,USA,May 6-7,2004.Berkeley,USA:USENIX Association,2004:43-56.
[8]Ouyang Jiannan,Lange J R.Preemptable ticket spinlocks:improving consolidated performance in the cloud[C]//Proceedings of the 9th ACM SIGPLAN/SIGOPS International Conference on Virtual Execution Environments,Houston,USA,Mar 16-17,2013.New York:ACM,2013:191-200.
[9]Dice D,Lev Y,Moir M,et al.Early experience with a commercial hardware transactional memory implementation[J].ACM SIGPLAN Notices,2009,44(3):157-168.
[10]Hammarlund P,Kumar R,Osborne R B,et al.Haswell:the fourth-generation Intel core processor[J].IEEE Micro,2014,34(2):6-20.
[11]Herlihy M,Eliot J,Moss B.Transactional memory:architectural support for lock-free data structures[J].ACM SIGARCH ComputerArchitecture News,1993,21(2):289-300.
[12]Rajwar R,Dixon M.Intel transactional synchronization extensions[R].Intel Developer Forum,San Francisco,2012.
[13]Raghavendra K T,Vaddagiri S,Dadhania N,et al.Paravirtualization for scalable kernel-based virtual machine(KVM)[C]//Proceedings of the 2012 International Conference on Cloud Computing in Emerging Markets,Bangalore,India,Oct 11-12,2012.Piscataway,USA:IEEE,2012:1-5.
[14]Knaus W A,Draper E A,Wagner D P,et al.APACHE II:a severity of disease classification system[J].Critical Care Medicine,1985,13(10):818-829.
[15]Gilchrist J.Parallel data compression with Bzip2[C]//Pro-ceedings of the 16th IASTED International Conference on Parallel and Distributed Computing and Systems,2004,16:559-564.
[16]Feitelson D G,Rudolph L.Gang scheduling performance benefits for fine-grain synchronization[J].Journal of Parallel and Distributed Computing,1992,16(4):306-318.
[17]Oglesby R,Herold S.VMware ESX server:advanced technical design guide(advanced technical design guide series)[M].[S.l.]:The Brian Madden Company,2005.
[18]Ousterhout J K.Scheduling techniques for concurrent systems[C]//Proceedings of the 3rd IEEE International Conference on Distributed Computing Systems,Miami,USA,1982:22-30.
[19]Shi Xuelin,Xu Ke.Utilization maximization model of virtual machine scheduling in cloud environment[J].Chinese Journal of Computers,2013,36(2):252-262.
[20]Weng Chuliang,Liu Qian,Yu Lei,el al.Dynamic adaptive scheduling for virtual machines[C]//Proceedings of the 20th International Symposium on High Performance Distributed Computing,San Jose,USA,Jun 8-11,2011.New York:ACM,2011:239-250.
附中文参考文献:
[4]金海,钟阿林,吴松,等.多核环境下虚拟机VCPU调度研究:问题与挑战[J].计算机研究与发展,2011,48(7):1216-1224.
[19]师雪霖,徐恪.云虚拟机资源分配的效用最大化模型[J].计算机学报,2013,36(2):252-262.

YU Qianqian was born in 1993.She is an M.S.candidate at Institute of Parallel and Distributed Systems,Shanghai Jiao Tong University.Her research interests include synchronizations,non-volatile memory and file systems,etc.
余倩倩(1993—),女,浙江永嘉人,上海交通大学并行与分布式系统研究所硕士研究生,主要研究领域为同步,非易失性内存,文件系统等。

DONG Mingkai was born in 1992.He is an M.S.candidate at Institute of Parallel and Distributed Systems,Shanghai Jiao Tong University.His research interests include synchronizations,non-volatile memory and file systems,etc.
董明凯(1992—),男,河北唐山人,上海交通大学并行与分布式系统研究所硕士研究生,主要研究领域为同步,非易失性内存,文件系统等。
Hardware Transactional Memory Assisted Synchronization Mechanism in Virtualized Environment*
YU Qianqian+,DONG Mingkai,CHEN Haibo
Institute of Parallel and Distributed Systems,Shanghai Jiao Tong University,Shanghai 200240,China
In a virtualized environment,there is a common existence of double scheduling problem.Moreover,overcommitment exacerbates the problem,and causes a significant performance downgrade.As a result,how to alleviate this problem while protecting the system’s fairness and improve its overall performance has become a critical issue.This paper studies the performance issue of synchronization mechanism caused by double scheduling problem,and proposes a new synchronization mechanism SPINRTM with the help of hardware transactional memory.On the one hand,SPINRTM takes advantage of hardware transactional memory to protect critical sections from being preempted,which effectively alleviates double scheduling problem.On the other hand,it is combined with ticket spinlock to protect the efficiency of hardware transactional memory and guarantee the fairness of the system.Evaluation results show that SPINRTM can protect the system's fairness and improve its performance at the same time when resources are overcommitted.
virtualization;hardware transactional memory;synchronization mechanism
the Ph.D.degree in computer systems architecture from Fudan University in 2009.Now he is a professor at School of Electronic Information and Electrical Engineering,Shanghai Jiao Tong University.His research interests include systems software and systems architecture,etc.
2016-09, Accepted 2016-11.

A
TP316.1
+Corresponding author:E-mail:kiki_yu@sjtu.edu.cn
YU Qianqian,DONG Mingkai,CHEN Haibo.Hardware transactional memory assisted synchronization mechanism in virtualized environment.Journal of Frontiers of Computer Science and Technology,2017,11(9):1429-1438.
10.3778/j.issn.1673-9418.1609034
*The National Natural Science Foundation of China under Grant No.61572314(国家自然科学基金面上项目);the National Key Research&Development Program of China under Grant No.2016YFB1000104(国家重点研发计划);the Zhangjiang High TechnologyAchievement Transformation Program under Grant No.201501-YP-B108-012(张江高科技园区高新技术成果转化项目).
CNKI网络优先出版: 2016-11-11, http://www.cnki.net/kcms/detail/11.5602.TP.20161111.1627.008.html
摘 要:在虚拟化系统中,双重调度问题普遍存在。过度负载的现象进一步加剧了双重调度问题,造成了不可忽视的性能下降。如何在保护系统公平性的同时,缓解双重调度问题带来的负面影响,提高系统的整体性能,成为一个重要的课题。通过研究双重调度引发的同步机制效率问题,结合硬件事务内存的特点,为虚拟机内核设计了新的同步机制SPINRTM。一方面,SPINRTM基于硬件事务内存不可被打断的特性,保护了虚拟机内的临界区间,使其不被打断,有效缓解了双重调度问题;另一方面,SPINRTM结合了传统的排队自旋锁,保护了硬件事务内存的运行效率,也维护了系统的公平性。测试证明,在超负载的情况下,SPINRTM能够在保护系统公平性的同时,提高系统的整体性能。
陈海波(1982—),男,2009年于复旦大学计算机系统结构专业获得博士学位,现为上海交通大学电子信息与电气工程学院教授、博士生导师,主要研究领域为系统软件,系统结构等。
猜你喜欢
节能与环保(2022年7期)2022-11-09
计算机系统应用(2022年5期)2022-06-27
今日农业(2021年9期)2021-07-28
现代装饰(2021年1期)2021-03-29
计算机技术与发展(2019年11期)2019-11-18
中国计算机报(2019年12期)2019-06-21
计算技术与自动化(2017年3期)2017-10-26
科技创新与应用(2017年3期)2017-02-18
信息化视听(2016年7期)2016-05-14
