
基于文本挖掘的商品推荐
2017-09-15 07:17:39张俊伟王硕宁王忠建
哈尔滨商业大学学报(自然科学版) 2017年4期
张俊伟,杨 柳,王硕宁,王忠建
(1. 哈尔滨商业大学 计算机与信息工程学院,哈尔滨 150028;2. 黑龙江旅游职业技术学院 基础学部,哈尔滨 150028)
基于文本挖掘的商品推荐
张俊伟1,杨 柳2,王硕宁2,王忠建1
(1. 哈尔滨商业大学 计算机与信息工程学院,哈尔滨 150028;2. 黑龙江旅游职业技术学院 基础学部,哈尔滨 150028)
对电子商务网站的评论文本进行分词、去停用词等整理,通过词频统计提取特征词,应用词频-逆文档频率提高特征词的类别区分能力以增加特征词的准确性.在收集大量的电子商务网站的评论文本及一系列预处理后构建了特征词词库.采用词语相似度计算方法用于关键词向量与特征词词库相似度的计算.根据相似度计算结果对用户评论的商品进行排序以实现对用户商品的推荐.设计了商品推荐系统并完成了实验程序.利用收集到的用户评论文本完成了对商品的推荐实验,并对实验结果进行了考察与分析.
特征词;相似度计算;商品推荐
随着互联网、电子商务的发展,国内外的各种电子商务网站上都采用不同的推荐和促销手段.其中网站的商品推荐是比较盛行的方法之一.这种推荐系统能够依据用户的信息需求主动将信息提供给用户,这对用户购买商品、选择购买的商品是一种非常有效而重要的解决方案[1].
基于文本挖掘的商品推荐系统就是利用用户的评论文本对评论商品进行排序,主动的将顾客真正的目标商品展现出来,真正挖掘出用户潜在需求的商品[2].
通过研究用户对商品的评论,有针对性的为用户提供产品和信息服务.这种针对性易于保证用户需要的商品信息和服务可以快捷的被用户所接收,从而将这些浏览者转变为可能的购买者.这种推荐服务可以为用户大大缩减从大量同类商品中挑选更优质商品的时间.其次,消费者可以在接受网站推荐到购买的过程中感受到很好的消费体验从而增加对使用的网站的忠诚度. 所以,优秀的商品推荐系统既可以降低购买时间,又可以提升客户购买体验[3].
我们不难发现注重对电商网站的评论文本进行深入探究具有非常重大的意义与价值.消费者可以通过商品的推荐获得大量的有价值的信息,利用用户评论文本进行的信息挖掘,进而用于商品的排序、推荐的结果就是使用户购物更加便捷.它降低了用户购买商品时的决策成本,促进了交易量的增长,提高了用户网络购物的效率.
国外很早就展开了对文本挖掘的研究工作,在许多方面都做了十分深层次的探究而且获得了很多有实际意义的结果,这些方面包括自动取得特征词、文本分类技术和提取半结构化的信息技术等[4].
国内对于文本挖掘的研究,从1998年开始在国家重点基础研究发展规划中将文本挖掘作为研究的重要内容[5].很多高等院校、科研院所和各种信息公司都作为这项技术的主要的研究场所和机构,同时也获得了很好的成绩.
1 特征词及相似度计算
1.1特征词库
构建特征词词库即构建人工语料库,是通过人工选择的方法,建立起相应的词库,使得词库中的词语满足预先定义的条件.在基于文本挖掘的商品推荐研究中,特征词词库的构建尤为重要.一个好的、全面的特征词词库可以直接反映出所匹配的评论的好坏程度,从而反映出商品的可推荐程度.
通过深入实际的研究发现,电子商务网站的主要消费者群是年轻人,要考虑到他们日常说话的习惯用语,分析他们最在意的商品评价和最常用的评价语言.并且特征词词库中的词需要从真实的电子商务网站中获取,通过对获取到的商品评论进行分析,判断该评论的好评、差评之分,对凸显好评、差评的词语如好、漂亮、舒适、难看、垃圾等进行记录,并且分类存入数据库中.
在构建特征词词库时,本文采用了词频-逆文档频率的方法对选取的特征词作进一步的处理,提高它的类别区分能力以增加特征词的准确性.计算词频-逆文档频率(TF-IDF)的方法多种多样.词频(TF)指的是某一词汇在一段文本中出现的次数除以这段文本的总词数.例如,某一段文本的词汇数量是1 000个,“美丽”一词出现了20次,则可以得到词语“美丽”在这段文本中的词频是0.02.计算文件频率(DF)的方法是先计算多少个文本中出现过词语“美丽”,然后除以文本集合里包含的文本总个数.所以,如果词语“美丽”在50份文本出现过,而文本集合中的文本总数是5 000,那么它的频率为0.01.最后,就可以计算出这个词的词频-逆文档频率的数值.就像上文所提到的,词语“美丽”在文本集合中的词频-逆文档频率数值为2.词频的计算如式(1).
(1)
计逆文档频率时,通常需要一个语料库以模拟语言的使用环境,如式(2).
(2)
TF-IDF算法是建立在这样一个假设之上的:要想找到一个特征词使它能够很好的起到区分其它文本的作用,那么这个特征词应该满足在该文本中出现的次数较多,但是在其它的文本中出现的次数较少.所以通过使用逆文档频率(IDF),用词频和逆文档频率的乘积作为衡量标准的目的为尽量挑选重要的词汇来作为特种词,并且忽略次要的和对文本影响较小的词.
我们会选择尽可能多的与评价相关的词语,扩充特征词词库,以提高关键词向量匹配时的准确率.根据对不同电子商务网站评论文本的大量观察,总结出关于好评与差评的各类特征词,它们可以反映出对商品的褒贬评价,再通过词频-逆文档频率的方法筛选使其具有很强的代表性与标志性,部分特征词词库的内容如表1所示.
表1特征词词库的部分内容

好评关键词差评关键词好评关键词差评关键词好不好太棒了丑喜欢垃圾美观掉色漂亮难看合身难闻舒服差劲靓丽不符物超所值不值好评失望
1.2相评论文本的预处理
随着数据库越来越复杂化,数据量也越来越庞大,难免受噪音数据和不一致性数据等的影响.文本数据也是一样,在这种情况下直接提取的原始文本集往往是不规则的、噪音大的,对文本挖掘的质量影响也较大.提高文本数据的质量,能够加快提取有价值信息的速度,从而提升文本挖掘模型的质量.文本挖掘的过程中非常关键的一个部分就是对文本进行预处理,它可以为后续算法实现提供保障.文本获取到电子商务网站中的评论文本,首要步骤就是对评论进行预处理.
1.2.1 评论文本的分词
网购的评论文本指的是客户在购买商品后在评论系统上的留下的关于商品的描述.网购评论比较简短,很多不是完整的句子,只是简单的被拼凑到一起的关键词.即使京东在用户评论专栏为用户设计了指定的优缺点输入模块,还是有很多客户在对商品进行评论时,不依据要求的格式来写,很多客户评论优缺点混在一起.这样句子的倾向性就不明确.例如:“衣服不错,号码偏小,物流太慢”的例句中,“衣服不错”属于褒义词,“号码偏小”、“物流太慢”表示的是客户存在的不满,是贬义的.处理这种文本时,如果仅仅研究整个文本的褒义和贬义倾向得出结论会有所遗漏,不会得到完整的结果.要使研究的结论更加真实有效,句子就需要依据设定的规则来断句,使一个完整的句子变成很多较短的句子甚至词语.
综合比较众多的分词系统,本文采用中国科学院计算技术研究所研制的ICTCLAS分词系统对获取到的文本进行分词处理.该系统采用层叠隐马尔可夫模型,可以进行中文分词、词性标注、命名实体识别、新词识别等处理,具有良好的分词性能以及广泛的适用性,使用者可以自定义词典,且支持繁体中文、GBK、UTF-8、UTF-7、Unicode等多种编码方式.目前最新版本的分词速度更是理论上达500 KB/s左右,分词精度也接近98.45%.
1.2.2 去停用词处理
在提取评论文本的关键词时,为了让得到的关键词更准确、更全面的反映出该文本的好评差评意向,需要对经过分词处理之后的文本进行去停用词处理,并且为了达到更好的实验效果需要进行人工校对.
1.2.3 提取评论关键词
评论文本经过分词并去停用词处理后得到大量的该商品的评论词,接下来需要对这些评论词进行整理与词频统计来提取关键词.对同一商品评论文本进行预处理之后,可得到按词频排序的关键词及其词频数值,从而提取关键词.
1.3相似度计算
本文的计算公式参考了《基于同义词词林的词语相似度计算方法》得出评论文本的关键词与特征词词库中的特征词的相似度计算方法:评论文本关键词与特征词的相似度用Sim表示,n表示两个词汇所在分枝层的分支数,k表示两个分支间的距离.
(I)若两义项不在同一树上则相似度由式(3)计算:
Sim(A,B)=f
(3)
(II)若两义项在同一树上:
1)若不同编码出现在第2层,则由式(4)计算.

(4)
如:“人”表示为“Aa01A01=”,“少儿”表示为“Ab04B01=”.由于A开头的编码个数为1 309个,所以n=1 309,在第2层,人的编码是a,少儿的编码是b所以k=1.
2)若不同编码出现在第3层,则由式(5)计算.
(5)
如:“人”表示为“Aa01A01=”,“弟弟”表示为“Aa03A03=”.
3)若不同编码出现在第4层,则由式(6)计算.
(6)
4)若不同编码出现在第5层,则由式(7)计算.
(7)
a、b、c、d、f参数的值经过预备实验获得:a=0.65、b=0.8、c=0.9、d=0.96、f=0.1.另外,一个词可能有多个编码,相似度的计算取最大值,如果程序中的测试词、比较词等没在《同义词词林》中出现则相似度为0.
接下来将举例说明词语相似度的计算方式,例如计算某商品评论文本中的关键词“好看”和特征词词库中的“优秀”这两个词语的语义相似度.在《同义词词林》中查询两个词语的编码,得出“好看”和“优秀”两个词语的编码分别为“Ed24A01”和“Ed03A01”,将它们的编码从左往右比较,前两级编码相同,第三级编码不同,一个词到另一个词所经过的分支数就是它们的距离,可见它们在词林中的词语距离为21,根据相似度-距离计算公式(8):
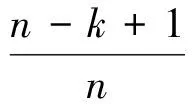
(8)
其中:n=307,k=21,根据以上公式计算出“好看”和“优秀”的词语相似度为0.72.
另外,如果两个词不在一棵树上,根据商品评论的实际情况相似度计为0.接下来将关键词与词库中的特征词逐一进行相似度计算,与好评词库的计算结果计为正值,与差评词库的计算结果计为负值,将结果累加求和并且除以匹配次数,即为该关键词与词库的匹配结果.
2 商品推荐系统实现
电子商务网站的迅速发展使企业与个人用户快速增加,随之用户对网站提供功能的要求也随之增加,因此购物网站中的各种推荐系统应运而生.这种推荐系统可以解决很多实际生活中存在的问题.与此同时,所有的电子商务网站都为消费者体统了一个评价商品的平台,用户可以按照对商品的认识对他们所购买过的商品进行评价,其中包含了用户在购买过程中的任何感受,这样的平台提升了用户的体验,也及时给商家反馈了需要改进的地方.几乎每一个想要购买商品的客户都会事先翻阅该商品的评论,得知是否满足自己的需求.但是,在实际体验中可以发现,某一商品的评论可能是大量的,有些评论可能文字叙述很长但是内容空洞毫无实际意义.如果消费者对评论逐一查看会费时费力.这样就需要对这些评论文本采用文本挖掘的技术处理.本文经过对电子商务网站的评论进行深入分析,设计了基于文本挖掘的商品推荐系统.它可以利用文本挖掘技术对以往购买过商品的用户的评论进行有效、深入挖掘,发掘其中蕴含的好评与差评倾向,将这种评价倾向具体化成为商品的得分,并且利用商品的得分将评价较好的商品推荐给用户,达到了对用户评价的充分利用.
基于文本挖掘的商品推荐的处理过程如图1所示.

图1 基于文本挖掘的商品推荐的处理过程
处理过程主要由4个模块组成:
1)构建特征词词库模块:通过对电子商务网站大量商品评论的分析,采用词频-逆文档频率的方法总结出好评、差评相关的特征词,归类整理构建好评与差评的特征词词库.
2)文本的预处理模块:使用分词软件对商品的评论文本进行分词处理,去掉停用词,并提取出关键词,统计词频得到该商品的关键词向量.
3)相似度匹配模块:将某商品的关键词向量与特征词词库采用内积的方法进行匹配,通过相似度计算得到对商品评价的得分.
4)商品的推荐模块:系统将同类商品根据相似度计算得到的得分进行排序,将排名靠前的商品推荐给用户,并显示商品根据评论的排名.
3 实验及分析
3.1实验数据及实验
通过对大量商品评论进行的分析、考察,总结出了商品评价倾向的特征词从而构建了特征词词库.再对评论文本进行预处理,将评论文本信息筛选、提取,得到商品对应的关键词向量,最后利用词语相似度计算得出每一个关键词与词库匹配的结果.根据匹配结果计算出该商品的得分,从而更加直观的得到商品的可推荐程度.
为了实验随机挑选了“天猫购物”网站上的10种相同价位的手机,并以其中的“红米NOTE3”为示例,该商品经过评论文本的预处理得到以词频作为权重的关键词向量,并且经过词语相似度计算得到每一个关键词的匹配结果如表2所示.
表2商品“红米NOTE3”的关键词向量
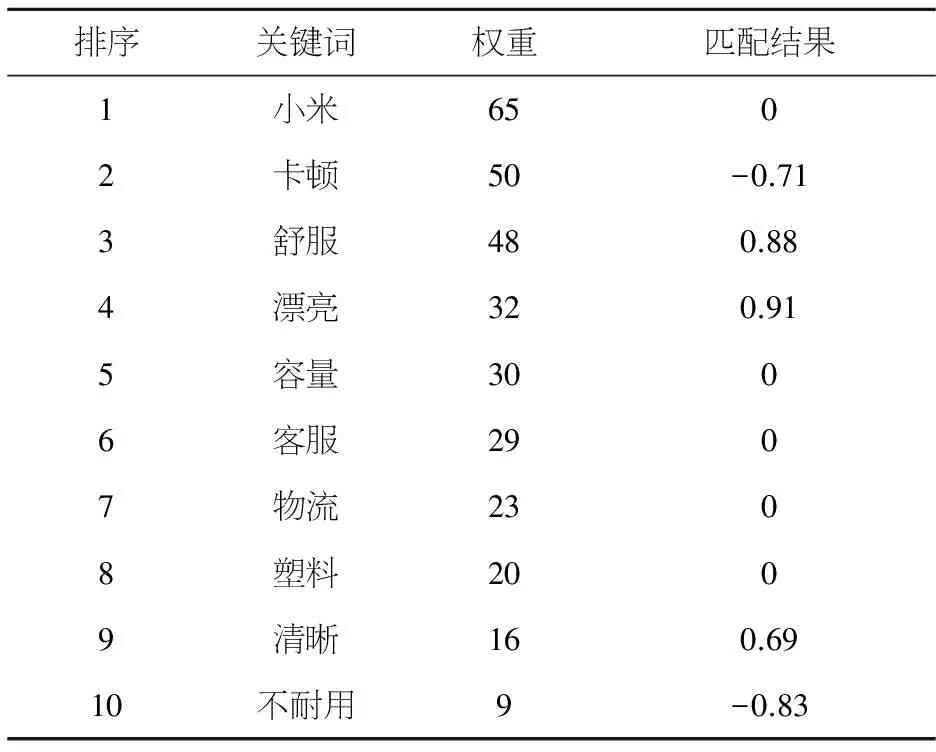
排序关键词权重匹配结果1小米6502卡顿50-0.713舒服480.884漂亮320.915容量3006客服2907物流2308塑料2009清晰160.6910不耐用9-0.83
将每个关键词的权重与匹配得分之积累加求和,结果即为该商品的得分,表示它的可推荐程度.以商品“红米NOTE3”的关键词向量为例,该商品的得分通过公式(9)计算.
(9)
其中:D表示关键词的权重,R表示关键词与特征词词库的匹配结果,计算得出“红米NOTE3”的商品得分为39.43,计算过程如式(10)所示.
Score=-0.71×50+0.88×48+0.91×32+0.69×16-0.83=39.43
(10)
为了收集可用而且比较典型的评论样本,通过电子商务网站收集并整理了消费者在购买并切身体验后发表的对商品的评论,并最终选定了最具代表性的“天猫”购物网站作为数据采集对象.
获取评论文本要本着控制变量的原则,所以选取价格相近的同种商品进行比较,本文收集了“天猫”购物网站上相同价位的十种手机的共1 000条评论文本数据用于评价实验.在文本预处理阶段首先要对评论文本进行分词处理,再经过去停用词和关键词提取等文本预处理工作,得到评论文本的关
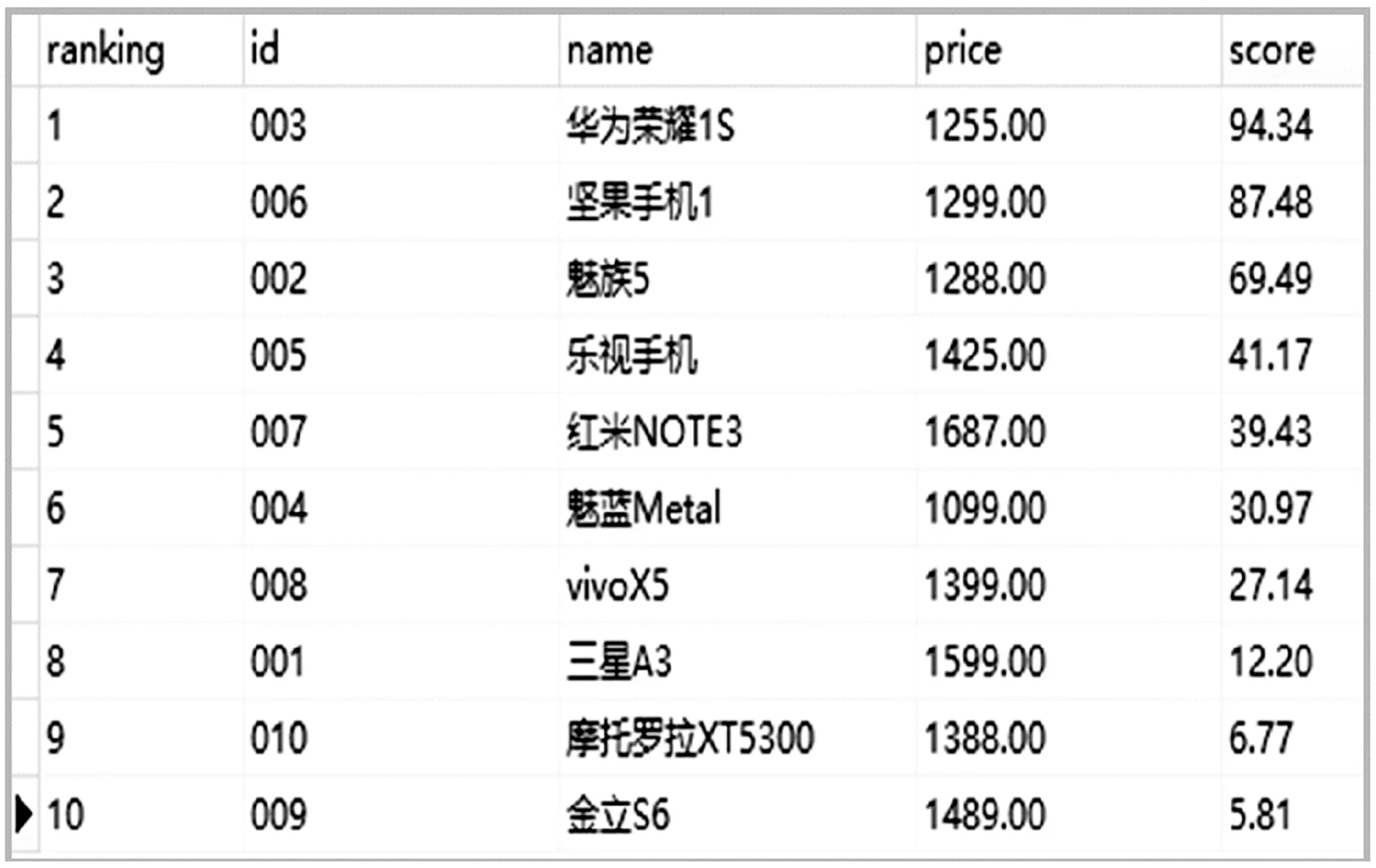
图2 实验结果的商品样本的得分与排序
键词向量.通过关键词向量与特征词的距离计算它们的相似度,从而获得[0,1]之间的相似度数值.以相似度数值作为权重,与好评词库的匹配结果计为正值,与差评词库的匹配结果计为负值从而得出该商品的得分.
图2为本实验所获取的商品评论文本通过上述方法计算的得分与排名情况.从图中可以看出经过构建特征词词库、文本预处理和相似度计算等一系列处理后,对商品的可推荐程度均以具体的得分数值表示,从而根据得分对商品进行排序,将排序顺序靠前的商品推荐给消费者.
3.2实验结果及分析
本次实验采用Java编程语言在Windows7下开发了商品推荐系统,并以Mysql5.6为数据库保存特征词词库、关键词向量和最终的匹配结果等.系统采用开放式结构,词库等体系能比较容易地进行扩充,对商品评论的挖掘有一定的精准度,能基本满足电子商务领域的特定需求.在对本章实验的实验结果进行分析时,对比了天猫购物网站该样本商品的综合得分,如表3所示.
表3实验结果与网站商品评分对比

排名商品名称得分1得分21华为荣耀1S94.344.92坚果手机187.484.93魅族569.494.74乐视手机41.174.85红米NOTE339.434.96魅蓝Metal30.974.87VivoX527.144.68三星A312.204.69摩托罗拉XT53006.774.610金立S65.814.5
表3中得分1指本文评价方法的商品得分,得分2是网站对商品的评价得分.通过实验结果与实际购物网站中商品的评分的比较可知本系统对商品的推荐有一定的可参考性,对样本商品的可推荐程度排名与“天猫”网站的实际评分排序比较接近.但是由于样本文本的数量有限,以及特征词词库的完整性还有不足,与实际商品的可推荐程度会有所差异,需要后续的完善.
4 结 语
本文利用商品评论文本挖掘有用信息,并将其用于商品推荐系统.针对电子商务网站文本的特性采用词频-逆文档频率的方法构建了反映评论褒贬倾向的特征词词库,通过预处理提取关键词得到关键词向量.结合实际情况研究了词语相似度的计算方法,以基于同义词的词语相似度计算为主对文本进行了相似度匹配计算,得出匹配结果并计算商品的可推荐程度.最后,实现了商品推荐系统进行了商品推荐的模拟实验及实验结果分析.在文本预处理部分由于汉语语言的特殊性,分词工具的分词效果不能完全满足电子商务网站评论文本的特定需要,小部分词需要人工校对才能达到文本处理的需求,后续还需完善.在构建特征词词库的过程中,由于加入了词频-逆文档频率的特征词提取方法,相比单一的对文本进行特征词统计更具代表性,能更加明确的凸显该评论特征词与其他特征词的特性区分,推荐效果更好.
[1] 项 亮. 推荐系统实践[M]. 北京: 人民邮电出版社, 2012.
[2] COOLEY R. Web usage mining: discovery and applicaton of interesting patterns from web data [D]. Minneapolis: University of Minnesota. 2013. 356-360.
[3] 赵晓煜, 丁延玲. 基于顾客交易数据的电子商务推荐方法研究[J]. 现代管理科学2006, 3: 93-94.
[4] THORLEUCHTER D. Mining ideas from information [J]. Expert Systems with Application, 2014,37: 7182-7188.
[5] 李本阳. 句子和篇章文本倾向分析[D]. 哈尔滨: 哈尔滨工业大学, 2010.
Recommendingcommoditiesbasedontextmining
ZHANG Jun-wei1, YANG Liu2, WANG Shuo-ning2, WANG Zhong-jian1
(1. School of Computer and Information Engineering, Harbin University of Commerce, Harbin 150028, China; 2. Faculty of Basic Science, Heilongjiang Institute of Tourism, Harbin 150086, China)
By dealt with the user comment text of the electronic commerce website, such as word segmentation, removing stop words and word frequency statistics, the character-words were extracted. Then TF-IDF was applied to improve word feature category distinguishing ability. After a large number of electronic commerce comment text of website were collected, characteristic word corpus was constructed. The word similarity calculation based thesaurus was used for similarity calculation of keyword vector and character-words. According to the results of the similarity calculation of the user comments with characteristic word, rank of the purchase products and recommendation were carried out. Finally, the commodity recommendation system was designed and implemented, the experiment was carried out and the experimental results were investigated and analyzed.
character-words; similarity calculation; commodity recommendation
2016-11-19.
黑龙江省教育厅科学研究项目(12511127)
张俊伟(1989-),男,硕士,研究方向:文本挖掘、自然语言处理.
TP319
:A
1672-0946(2017)04-0463-06
猜你喜欢
园林科技(2021年3期)2022-01-19 03:17:48
计算机技术与发展(2018年8期)2018-08-21 02:08:14
中国机械工程(2017年22期)2017-12-02 01:52:34
英语知识(2016年1期)2016-11-11 07:07:54
读者·校园版(2015年7期)2015-05-14 13:11:40
中文信息学报(2015年4期)2015-04-21 08:29:12
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
电脑迷(2014年14期)2014-04-29 00:44:03
图书馆论坛(2014年8期)2014-03-11 18:47:59
电脑迷(2012年15期)2012-04-29 17:09:47
