
关联规则挖掘在超市商品销售中的应用研究
2017-09-01 00:53黄子航
赤峰学院学报·自然科学版 2017年16期
黄子航
(华南师范大学 数学科学学院,广东 广州 510641)
关联规则挖掘在超市商品销售中的应用研究
黄子航
(华南师范大学 数学科学学院,广东 广州 510641)
本文对数据挖掘领域中的关联规则进行了阐述,介绍经典算法Apriori,运用关联规则对悉尼一家超市的部分数据进行分析、挖掘,判定发现不同类商品之间的关联度,挖掘出商品中隐藏的实用价值,进而在实际销售运作中有效地避免这类错误,给超市公司提出适当的货架销售建议与货架摆放依据,利于增加超市公司的运营利润.
关联规则;Apriori算法;超市购物交易
1 关联规则与Apriori算法
1.1 背景
关联规则反映一个事物与其他事物之间的相互依存性和关联性,是数据挖掘的一个重要技术,用于从大量数据中挖掘出有价值的数据项之间的相关关系.最著名的例子就是美国沃尔玛超市的“啤酒与尿布”,商家发现部分美国中年男性在买完孩子的尿布后会顺便买自己爱喝的啤酒,因此调整了货架的设置,把啤酒和尿布放在一起销售,从而增加了销售额.同时,关联规则在保险业务、医疗、银行服务等方面也有应用.
1.2 关联规则简介
设I={i1,i2,…,im}是一个项目集合,事务数据库D={t1,t2,…, tn}是由一系列具有唯一标识的事务组成,每个事务ti=(i=1,2,…,n)都对应I上的一个子集,项的集合成为项集,包含k个项的项集称为k-项集,项集的出现频率是包含项集的事务数,简称为项集的频率或计数.关联规则是形如A→B的蕴涵式,其中A⊂I,B⊂I,且A∩B=Ø.规则A→B在事务集D中成立,具有支持度s,其中s是D中事务包含A∪B的百分比,为概率P(A∪B).规则A→B在事务集D中具有置信度c,其中c是D中包含A的事务也包含B的百分比,为条件概率P(B|A).即
Support(A→B)=P(A∪B),Confidence(A→B)=P(B|A),同时满足最小支持度阈值minsup和最小置信度阈值minconf的规则成为强规则,满足最小支持度的项集称为频繁项集,频繁k-项集的集合通常记作Lk.
但有时仅仅依靠支持度和置信度制定的强规则未必是有效的,会出现规则互斥的情况,此时引入提升度L,为含有事务A的条件下,同时含有事务B的概率,与不含事务A的条件下却含有事务B的概率之比,即其中,lift(A→B)=1表示A与B相互独立,即规则A→B无效,此时即使支持度与置信度再高也不能说明该规则有效;在强关联规则中,Lift(A→B)>1表明是有效的强关联规则,Lift(A→B)≤1表明是无效的强关联规则,我们要寻找的是有效的强关联规则.
关联规则挖掘的目标是找出数据集中的所有有效强规则,可分为两个子问题:根据最小支持度找出事务数据库中的所有频繁项集;根据频繁项集和最小置信度产生关联规则,其中要应用到经典算法:Apriori算法.
1.3 Apriori算法
首先找出所有频繁1-项集的集合,记作L1,基于L1寻找所有频繁2-项集的集合,记作L2,基于L2寻找所有频繁3-项集的集合,记作L3,依次进行直至不能找到频繁k-项集.在第k-次循环中,先产生候选k-项集的集合Ck,Ck的每一个项集是对两个只有一个项不同的属于L(k-1)的频繁集做一个(k-2)来连接产生的,最后的频繁集Lk是Ck的一个子集,Ck的每个元素需在交易数据库中进行验证以确定加入Lk的元素.
2 基于超市商品销售的关联规则挖掘
2.1 数据的收集和预处理
本文选取了澳大利亚悉尼的一家超市在2016年9月份的部分购物数据,该超市9月份(共30天)每天上午9点至下午5点每小时若干条顾客购物数据,由于购物数据表中有多个属性,每个属性有多个值,因此先进行数据的可视化处理,对于其中的少数连续型数据,采用少数区间替代的方法将原始数据离散化,通过简化数据使得挖掘结果简介且易于使用,在数据预处理后共得到4800条购物数据,包含127件商品.
2.2 Apriori算法的实现
根据Apriori算法,设定minsup=0.01,minconf=0.3,限定提升度大于1,得到128条有效的强规则,其中的支持度、置信度、提升度三者关系如下图1,2所示,
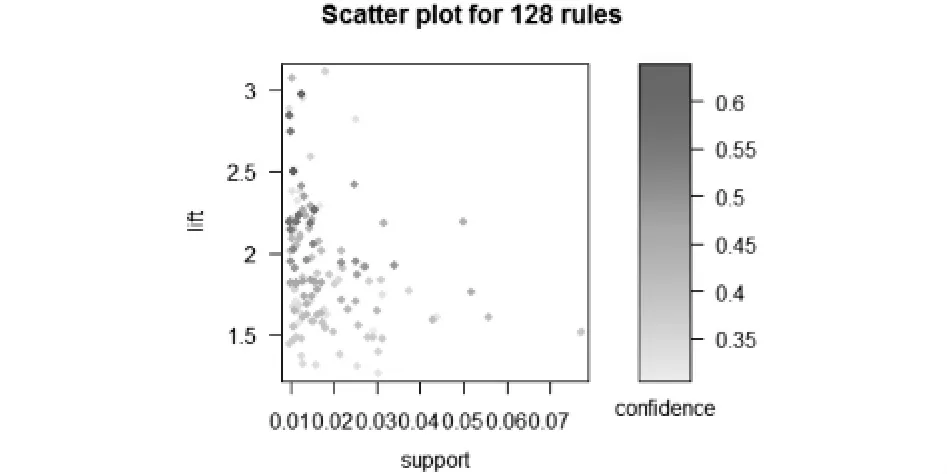
图1 支持度与提升度关系图
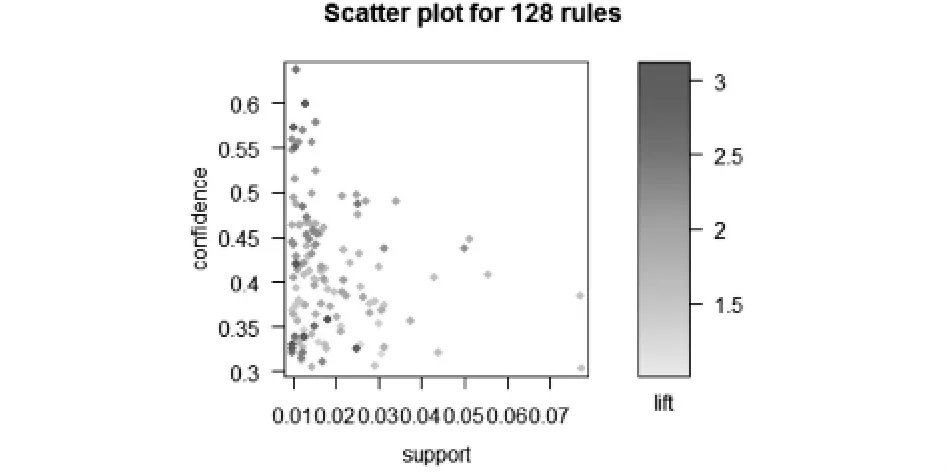
图2 支持度与置信度关系图
从上图中看出,置信度与提升度高的规则,支持度都偏低,呈现负相关关系,我们选出在提升度大于1的情况下置信度与支持度高的规则,并列出三项指标:支持度、置信度、提升度最高的10条强关联规则如表1,2,3所示.
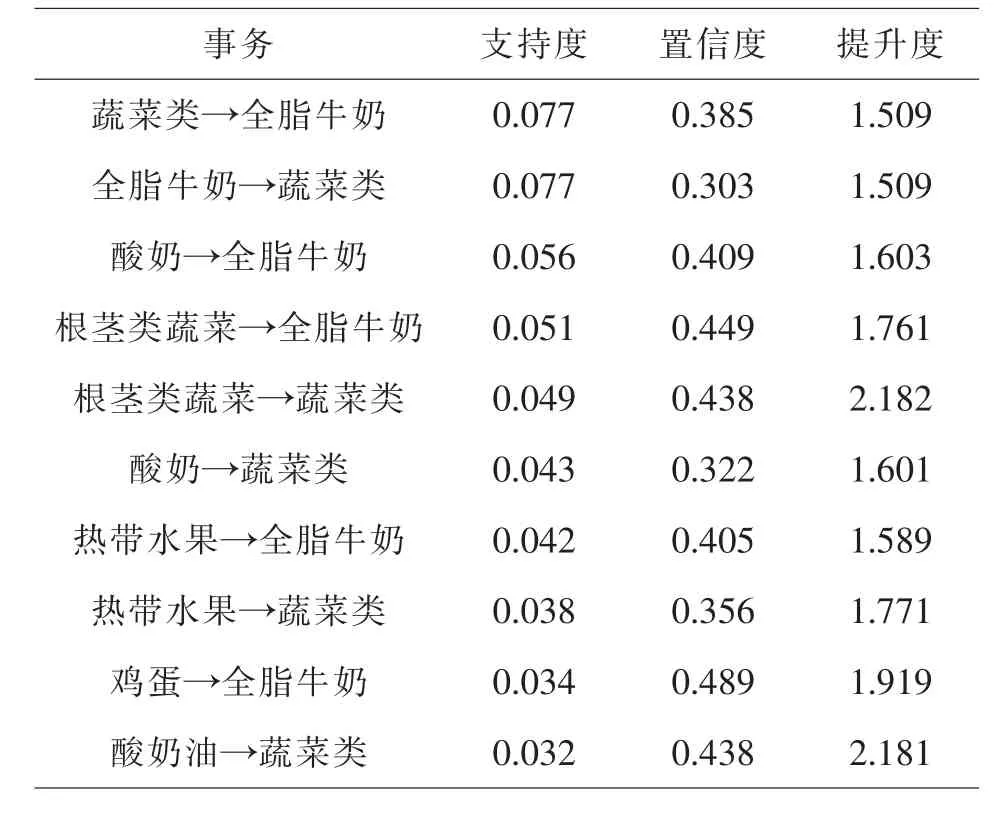
表1 支持度最高的10条规则
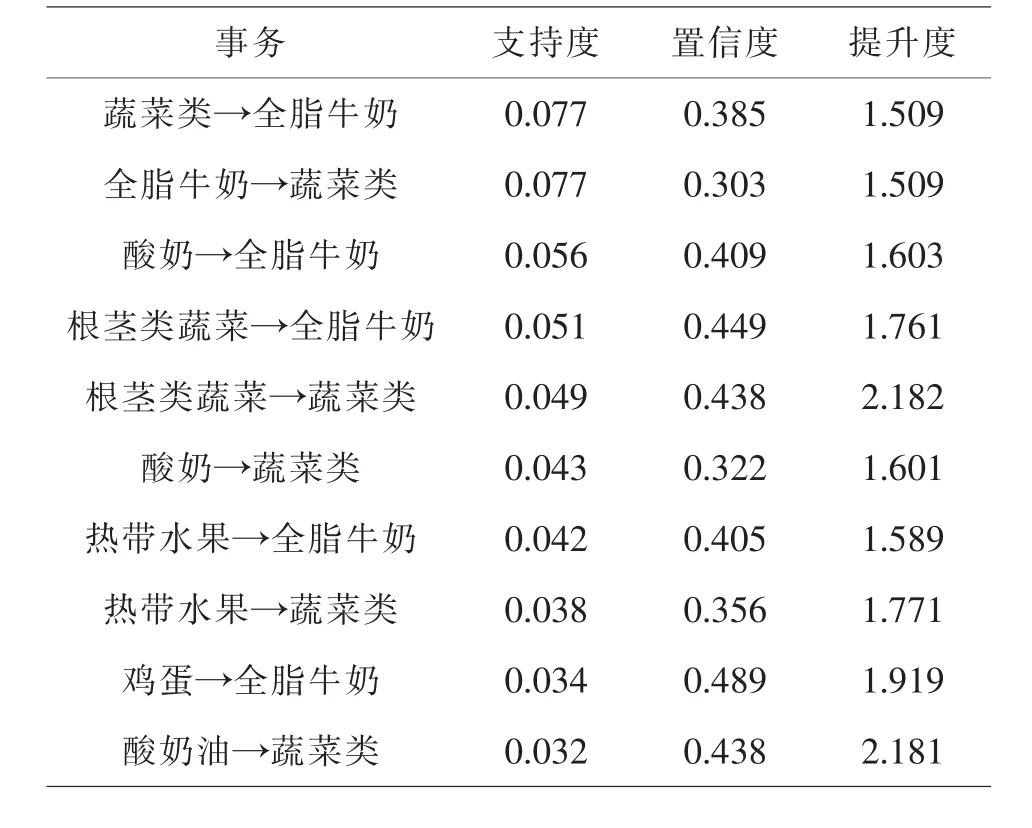
表2 置信度度最高的10条规则
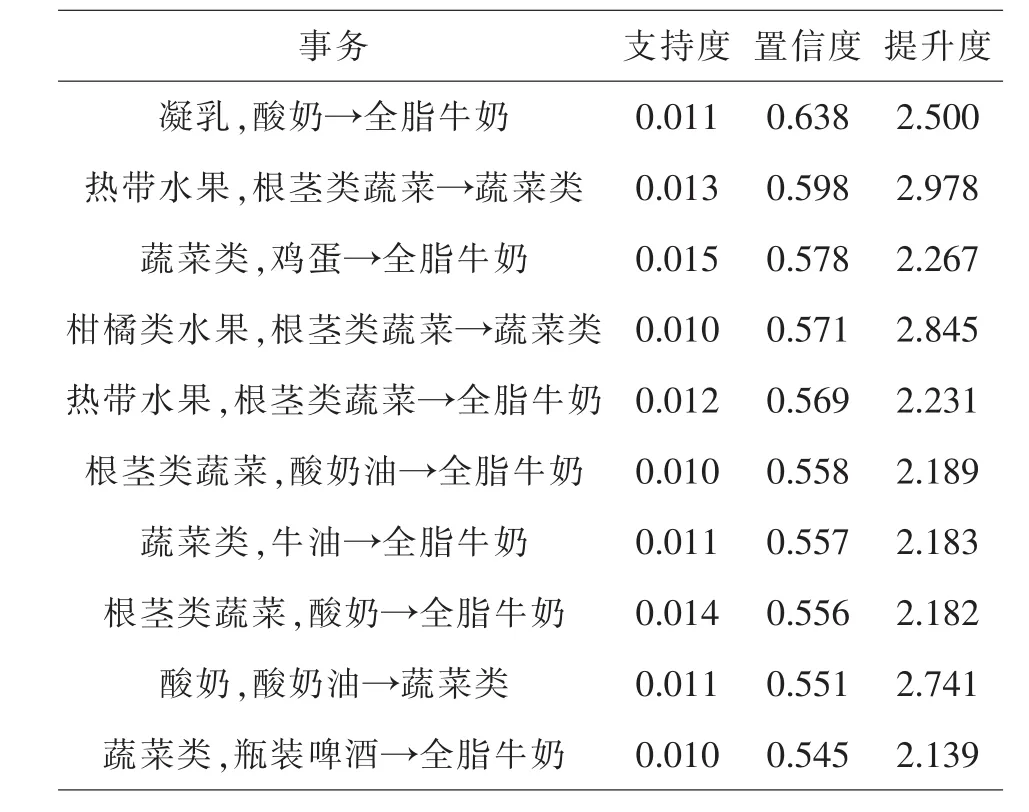
表3 提升度最高的10条规则
2.3 结果的分析与评价
上述各表反映了不同类商品对销售情况的影响,从表1和表2来看,蔬菜类、根茎类蔬菜、全脂牛奶的支持度和置信度最高,分别达0.07、0.38左右,说明这三者有密切的联系,热带水果、酸奶、鸡蛋、酸奶油等商品的支持度和置信度也分别高达0.05、0.32左右,相关性较强,热带水果、酸奶、鸡蛋、酸奶油等商品的销售量十分可观,是超市销售盈利的主要来源,表3可看出凝乳、柑橘类水果、酸奶等商品的提升度普遍在2.1-2.9之间,说明这几类商品对于蔬菜类、根茎类蔬菜、全脂牛奶三者的销售有着明显的促进作用.
通过关联规则挖掘,该超市应将蔬菜类、根茎类蔬菜、全脂牛奶等蔬菜类与奶制品的商品放在临近的售货架上,并适当增加蔬菜类商品和营养类商品的入销量,则超市的运营利润会有大幅度的提升,同时加大水果类商品的销售力度,使得其余蔬菜类、奶制品等的销售位置相近,有利于增加蔬菜类商品的销售量.
关联规则的数据挖掘在超市货物营销方面有着突出的应用,由以上结论发现,超市运营部可根据不同商品实际情况的需要,在关联规则上设置相应的输入和输出字段,并通过minsup和minconf的设置,判定发现不同类商品之间的关联度,挖掘出商品中更多的实用价值,同时也能发现商品货物销售间的一些由于未全面考虑提升度而出现的矛盾现象,进而在实际销售运作中有效的避免这类错误,也反映了数据挖掘的科学性.
〔1〕David Hand,Heikki Mannila,Padhraic Smyth.数据挖掘原理[M].北京:机械工业出版社,2006.2-7.
〔2〕乔克满,欧阳为民,孙卫.关联规则挖掘技术在体质指标分析中的应用研究[J].天津体育学院学报,2010,25(2):453-455.
TP311.13
A
1673-260X(2017)08-0011-02
2017-05-20
本论文属于华南师范大学数学科学学院科研项目《电影推荐算法的实证研究》阶段性研究成果;本论文属于华南师范大学数学科学学院科研项目《政行思教专业两岸培养模式的研究》阶段性研究成果
猜你喜欢
中国交通信息化(2022年10期)2022-11-17
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
河南水利年鉴(2020年0期)2020-06-09
天津科技大学学报(2018年4期)2018-08-22
计算机应用(2018年5期)2018-07-25
华中师范大学学报(自然科学版)(2017年6期)2017-12-26
轴承(2015年2期)2015-07-25
中南民族大学学报(自然科学版)(2011年2期)2011-02-07
网络安全与数据管理(2010年1期)2010-05-18
