
协同过滤技术在高校图书馆学术资源个性化推荐服务中的应用研究★
2017-08-27 03:06张立滨
河北科技图苑 2017年4期
张立滨
(辽宁大学图书馆 辽宁沈阳 110036)
协同过滤技术在高校图书馆学术资源个性化推荐服务中的应用研究★
张立滨
(辽宁大学图书馆 辽宁沈阳 110036)
个性化信息服务是未来图书馆信息服务的发展方向。在分析已有的个性化信息服务应用系统基础上,构建了基于协同过滤技术的高校图书馆学术资源个性化推荐系统理论模型,通过对用户信息的表示与获取、邻集的形成及推荐信息的产生等方面介绍了推荐系统的实现。协同过滤技术的应用能够提高高校图书馆学术资源个性化推荐服务的精度和效率。
协同过滤技术;高校图书馆;学术资源;个性化推荐
随着现代信息的多元化和高校图书馆的进一步发展,高校图书馆馆藏资源日益丰富,用户可在其中找到任何自己需要的资源。高校图书馆丰富的馆藏资源满足了广大用户的需要,同时也为进一步提高高校师生的整体素质提供帮助。然而,丰富的馆藏资源会导致信息检索步骤较为繁琐,读者需要输入多个关键词才能确定自己想要检索的信息。目前,一些高校图书馆开通了信息推送功能,图书馆信息服务系统根据用户的点击热点、检索习惯、个人爱好等向用户推送相关信息。信息推送的主要方式有两种,一是系统向用户推荐点击率排在前列的资源。用户在图书馆中的操作会被系统自动记录下来,系统会自动根据资源点击率将图书馆资源进行排列,区分出热门资源和非热门资源。二是系统向用户推荐图书馆最新资源。高校图书馆资源的更新速度日益加快,新的热门资源逐渐被高校图书馆引入。在用户对高校图书馆系统进行访问时,系统会自动将最近更新的资源向用户进行推荐,使得用户能及时掌握图书馆更新的内容。但是,通过对当前高校图书馆管理系统资源推荐方式的分析,发现目前高校图书馆信息服务系统面向用户的资源个性化推荐服务还不完善。针对上述问题,本文建立了一个基于协同过滤技术的高校图书馆学术资源个性化推荐模型,以提高图书馆信息服务系统资源个性化推荐服务效率。
1 个性化推荐服务概述
个性化推荐服务主要是指系统在分析用户喜好、职业、常检索资源类型等的基础上,总结出符合用户需求的信息,将系统中满足该信息的资源向用户进行推荐[1]。个性化推荐服务可以实现用户间经验共享,即对同类型用户需求习惯信息进行融合,以期整理出满足此类用户信息的数据资源。个性化推荐模块的工作原理为:系统对用户访问过的信息资源进行分类总结,建立用户信息资源偏好模型;根据该模型,系统在信息资源库中查找与此匹配的信息资源,根据特定的算法生成信息资源推荐内容;将信息资源推荐内容向用户进行推荐[2]。个性化推荐服务算法主要分为三种:基于关联规则的个性化推荐、基于内容过滤的个性化推荐和基于协同过滤的个性化推荐。
1.1 基于关联规则的个性化推荐
基于关联规则的个性化推荐系统主要是根据用户的使用习惯、人的思维习惯、信息资源的关联性等一般规则,制定出一种通用的信息资源筛选规则[3]。当用户登录系统后,系统将按照该规则对信息资源进行比对,并将比对结果向用户推荐。例如,对于一位正在进行本体知识库技术学习的用户来讲,当他登录系统并开展本体知识库信息检索时,系统会自动向他推荐与本体知识库相关的信息资源,如数据库应用技术、本体知识应用等信息。
基于关联规则的个性化推荐主要存在两个方面的不足。首先,这种关联规则是无法自动生成的,每次更新都需要系统管理人员手动更新。对于那些过时的关联规则也需要系统管理人员进行手动删除或者修改,管理人员工作量较大,关联的精确度不高[4]。其次,在向用户进行信息资源推荐时所依据的规则是之前管理人员制定好的,不能随着用户每次检索信息内容的调整而变化,这就导致推荐的信息资源不能很好的满足用户的需求,同时不能很好的发现用户潜在的关注点[5]。
1.2 基于内容过滤的个性化推荐
内容过滤技术是信息处理技术中最基本的一种方法,之后被应用于个性化推荐服务中。基于内容过滤的个性化推荐主要是通过机器学习、概率统计等技术实现内容过滤[6]。首先,系统会根据用户的喜好生成一个用户信息需求向量,同时系统会对所有文字资源建立分词标引、词频统计等加权信息,并生成文本资源向量。其次,系统根据用户信息需求向量和文本资源向量的相似度对比结果,将相似度高的文本资源向用户进行推荐。
基于内容过滤的个性化推荐可对文本资源建立向量,而对于多媒体资源,如视频、动画等资源,虽然可以建立简单的资源向量,但是所建立的资源向量所表示的内容和实际资源内容差别较大,不能很好的反映资源的内容。目前,常见的数字资源内容丰富多样,不仅有文本资源,还有动画、视频、音频等资源。由此可知,基于内容过滤的个性化推荐存在一定的局限性,不能很好的实现数字信息资源个性化推荐服务。
1.3 基于协同过滤的个性化推荐
与基于关联规则的个性化推荐和基于内容过滤的个性化推荐两种技术不同,基于协同过滤的个性化推荐是在对资源内容进行分析计算和与用户需求资源进行匹配的基础上为用户进行推荐的一种技术。采用该技术进行个性化推荐的依据是每个用户对所属资源的评分。采用协同过滤技术进行推荐时,首先会对用户的所有特性进行分析,比如用户的关注内容、职业等信息,然后通过特定的相似性算法比较多个用户间的相似性,找出与目标用户相似性比较高的多个用户,最后根据用户对资源的打分情况,将打分最高的多个资源向目标用户进行推荐[7]。
该推荐技术主要有以下三个特点。一是使用范围广。与其他个性化推荐技术的不同之处在于该推荐技术所采用的算法中起决定作用的是用户对资源的评分,而非资源的内容或者资源的形式。这一特点使得该推荐技术不仅对文本资源适用,而多媒体资源,如视频、动画、音频等同样也可以使用。二是有准确的推荐精度。该推荐技术是建立在用户对资源的评分上,如果一种资源得分较高,说明用户对该资源的满意度较高,根据该推荐技术,将评分较高的资源推荐给目标用户,使得推荐结果能更好的被目标用户接受[8]。三是可以将优势资源进行共享。该推荐技术是通过目标用户的相似用户预测评分,这可以使得相似用户之间可以彼此分享资源使用经验,通过资源分享可以发现目标用户潜在的喜好,使得推荐更为有效。因此,协同过滤的个性化推荐能更准确地找到用户的喜好,实现用户间经验共享。
2 学术资源个性化推荐模型
前文我们对基于协同过滤的个性化推荐算法及工作原理进行了分析,在此基础上建立个性化推荐模型。该模型主要包括:基于协同过滤技术的推荐引擎、基于知识库技术的数据支持和新进资源的推荐等三个模块组成,如图1所示。
2.1 数据支持模块
该模块为整个学术资源个性化推荐服务系统的核心数据部分,它由多个数据库构成,其中包括:用户信息库、学习行为数据库、学术信息资源库及用户评分数据库。
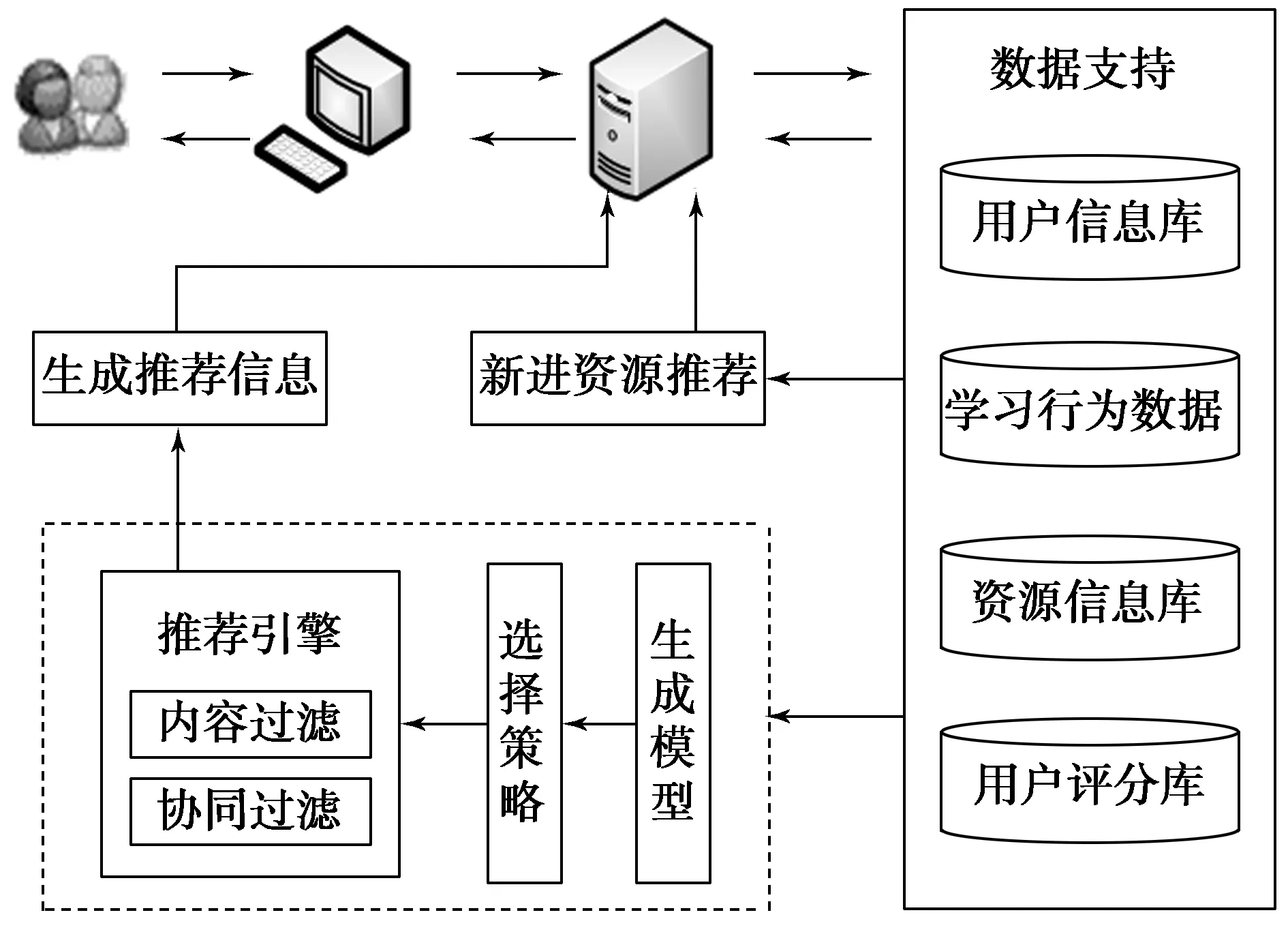
图1 基于协同过滤的学术资源个性化推荐模型
(1)用户信息库。该数据库主要用于存放用户的基本信息和个人喜好信息。基本信息包括用户姓名、密码、账号、电子邮箱、微信号、QQ号等信息;个人喜好信息包括用户检索频率高的词组、用户浏览文献的类别、用户浏览的学科信息等。为了方便系统协同过滤推荐,对用户个人喜好信息掌握的越多越好。
(2)学习行为数据库。该数据库主要用于存放用户的学习行为过程数据。通过对用户在系统中的整个操作过程所产生轨迹信息及缓存信息进行存储,通过数据挖掘对用户的学习行为进行归类总结,得出用户在使用图书馆学术资源数据的偏好,如用户阅读下载学术资源类型、收藏学术资源的学科等。该数据库也是用户评分模块的数据来源。
(3)学术资源信息库。该数据库为整个学术资源的一个仓库,整个学术资源信息均存储在该数据库中,包括期刊信息、硕士博士论文信息、专家学者信息等。
(4)用户评分数据库。该数据库主要用于存储用户对每个资源信息点击浏览、下载的频次,该频次在一定程度上反映出学术资源信息的热门程度。同时,该数据库也为协同过滤算法提供有力支撑。
2.2 协同过滤个性化服务推荐引擎
协同过滤个性化服务推荐引擎是学术资源个性化推荐服务系统的大脑,是实现个性化推荐服务的技术支撑,具体实现流程如图2所示。
2.3 新购买学术资源的推荐
该模块主要根据系统用户的不同喜好,对新购买资源进行分类,在用户访问系统时可以实现新购买的学术资源进行推荐。新购买学术资源由于知道的用户不多,很多资源处于闲置状态,不能真正发挥新进资源的作用,进而造成资源的浪费。该模块根据用户资源评分数据库中的数据进行相似性判断,然后按照特定的规则将新购买的学术资源进行分类推荐,以提高学术资源的利用率。
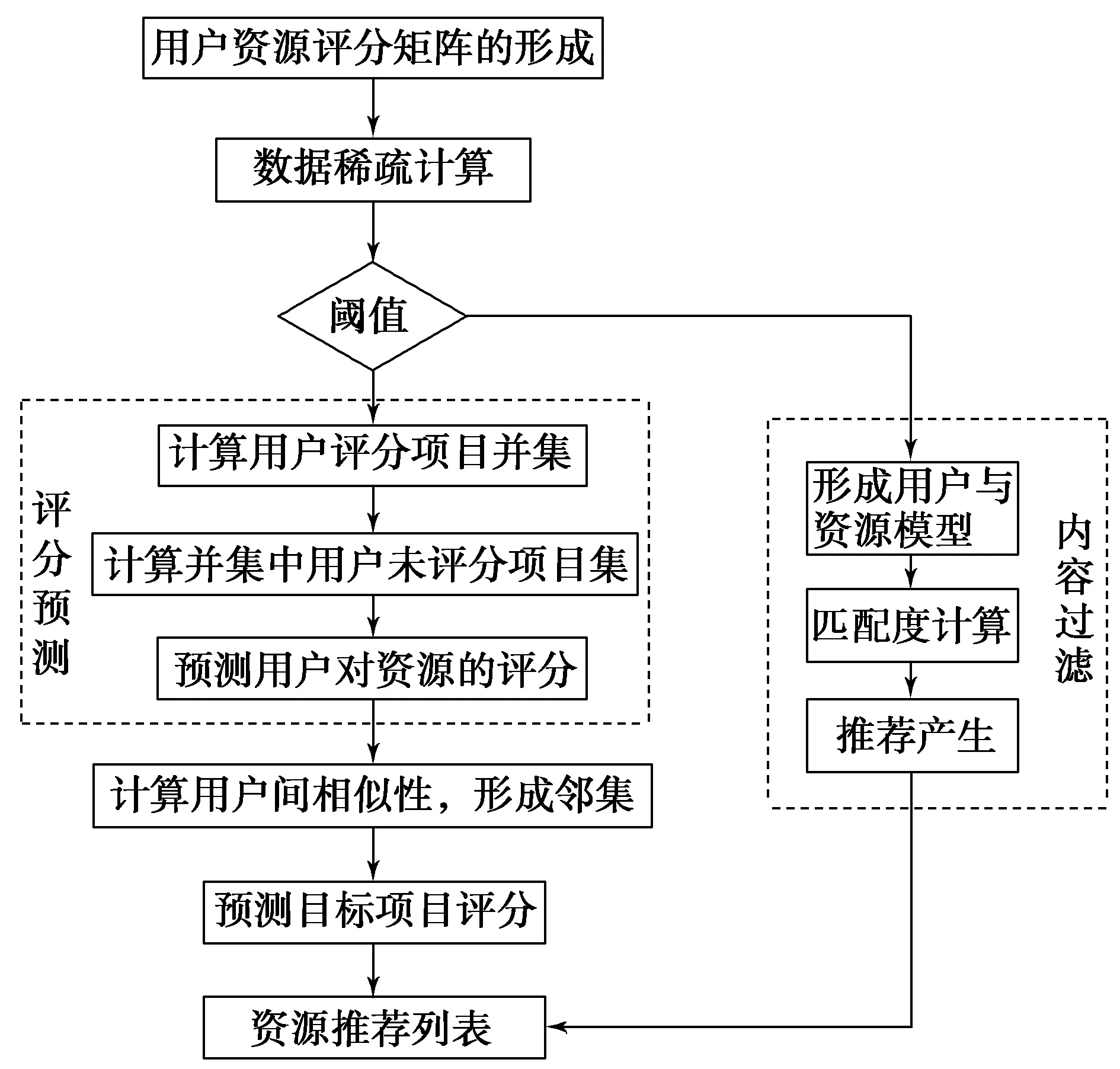
图2 学术资源个性化推荐中推荐引擎的实现流程图
3 学术资源个性化推荐服务系统的实现
3.1 推荐服务系统中用户信息的获取与表示
用户信息数据主要包括:用户注册的基本信息、用户学习数据信息和用户行为数据信息。学术资源个性化推荐服务系统实现的关键环节是用户行为数据的获取,是学术资源个性化推荐的依据。用户行为数据的获取主要有显式获取和隐式获取两种。显式获取主要是指用户通过对学术资源进行打分或者点赞来获取;隐式获取主要是指系统通过对用户学术资源的使用习惯、资源的获取类型等进行数据挖掘,得出用户的需求和偏好。目前,系统常见的获取方式为显式获取。隐式获取需要在系统中植入数据挖掘模块,同时建立该模块与知识库、显式终端的联系来实现。
3.2 协同过滤技术中邻集的形成
通过使用协同过滤技术向系统登录用户进行学术资源个性化推荐时,一个很重要的步骤就是建立用户个性需求邻集。邻集指的是与目标用户有相同或者相似个人爱好的用户群。在邻集的形成过程中需要系统根据目标用户的数据输入,按照特定的规则自动分析数据库中存有类似数据的数据集,然后进行数据调用。目前常用的数据相似性分析方法有余弦相似性分析法、相关相似性分析法等,每个方法都有优势和劣势。本系统在上述两种方法分析的基础上,将余弦相似性分析法和相关相似性分析法进行了有机结合,在邻集的形成过程中发挥这两种方法的优势,规避其劣势,保证邻集形成的准确性。
3.3 学术资源个性化推荐的产生
学术资源个性化推荐的产生是整个协同过滤技术的最后一个步骤。个性化推荐数据是在邻集形成基础上,通过比对相似性而得出的。不同的相似性有不同的得分,不同的得分体现学术资源的推荐质量的优劣。相似性高的邻集会使预测结果更为准确,相似性低的邻集使得整个预测准确性降低,甚至不符合用户的需求。由此可知,在整个协同过滤技术的实现中,如何选择邻集是整个协同过滤结果的关键,需要精确设定比对规则,然后选择合适的相似性分析方法。
4 结语
协同过滤技术最早产生于电子商务领域,一经问世便取得了很大的成功。本文将协同过滤技术引入到高校图书馆学术资源个性化推荐服务领域,使其能更好地为图书馆用户提供便捷、高效的服务。但是系统仍存在不足之处,主要体现在:用户学习兴趣爱好是动态变化的,这将对协同过滤技术中规则的制定提出了挑战;用户评分信息的显示获取给用户的操作带来不便,采用何种方式可以在避免用户操作的同时又可直接获取用户评分信息值得深入研究。
[1]杨焱,孙铁利,邱春艳.个性化推荐技术的研究[J].信息工程大学学报,2005,6(2):84-87.
[2]赵艳霞.基于关联规则的推荐系统再电子商务中的应用[J].价值工程,2006,25(5):88-91.
[3]杨焱.基于项目聚类的协同过滤推荐算法的研究[D].长春:东北师范大学,2005:19-32.
[4]曾艳,麦永浩.基于用户评分的关联规则挖掘协同推荐[J].计算机工程,2005,31(15):87-89.
[5]邓先箴.基于关联规则的推荐算法研究与应用[D].上海:华东师范大学,2009:13-45.
[6]王艳,景韶光,李雪耀,等.基于分类方法的内容过滤推荐技术[J].情报技术,2005,(8):59-62.
[7]曾春,邢春晓,周立柱.基于内容过滤的个性化搜索算法[J].软件学报,2003,14(5):999-1004.
[8]白丽君.基于内容和协作的科技文献过滤方法研究[D].太原:山西大学,2003:27-39.
Research on the Application of Collaborative Filtering Technology in the Personalized Recommendation Service for Academic Resources of University Libraries
Zhang Li-bin
Personalized information service is the development direction of future library information service. On the basis of the analysis of the existing application system of personalized information service, a theoretical model of the personalized recommendation system for academic resources of university libraries based on collaborative filtering technology is constructed. This paper introduces the implementation of recommendation system from aspects of the representation and acquisition of user information, the formation of neighbors and the generation of recommendation information. The application of collaborative filtering technology can improve the accuracy and efficiency of the personalized recommendation service of academic resources in university libraries.
Collaborative Filtering Technology;University Libraries;Academic Resources;Personalized Recommendation
本文系2016年度辽宁经济社会发展立项课题“基于数据挖掘技术的图书馆管理系统功能完善研究”项目(2016lslktzitsg-03)、2017年辽宁省高等学校图书情报工作委员会基金“图书馆电子资源统计指标及绩效评价研究”项目(LTB201702)的研究成果。
G250.7
A
10.13897j.cnki.hbkjty.2017.0080
张立滨(1982-),女,辽宁大学图书馆馆员,研究方向:参考咨询、云计算、阅读推广。
2017-03-26 责任编辑:张静茹)
猜你喜欢
新班主任(2022年4期)2022-04-27
社会科学(2021年5期)2021-10-27
科学大众(2020年23期)2021-01-18
文苑(2020年4期)2020-05-30
中国博物馆(2019年2期)2019-12-07
汽车观察(2019年2期)2019-03-15
商周刊(2019年2期)2019-02-20
新闻传播(2018年12期)2018-09-19
汽车与新动力(2016年6期)2017-01-04
中国卫生(2016年5期)2016-11-12
