
私有云环境下基于虚拟集群的资源共享方法*
2017-08-16 11:10刘沛东钟业弘曹东刚
计算机与生活 2017年8期
刘沛东,安 博,钟业弘,王 虎,曹东刚+
1.北京大学 高可信软件技术教育部重点实验室,北京 100871
2.北京大学(天津滨海)新一代信息技术研究院,天津 300450
私有云环境下基于虚拟集群的资源共享方法*
刘沛东1,2,安 博1,2,钟业弘1,2,王 虎1,2,曹东刚1,2+
1.北京大学 高可信软件技术教育部重点实验室,北京 100871
2.北京大学(天津滨海)新一代信息技术研究院,天津 300450
随着云计算与大数据处理的飞速发展,越来越多的应用框架开始使用“云”的方式运行,这对企业私有云平台提出了一些重要挑战:如何让私有云环境有限的物理资源支持多个应用框架和多个用户,不仅能保证绝大多数现有的异构应用同时运行,还能为新应用提供扩展性与弹性支持。提出了一种新的服务模型ClaaS(cluster as a service),用一种简单而易于实现的方式为中小规模的数据中心解决了上述问题。ClaaS的主要思路是将虚拟化的单位扩展为集群,为分布式的应用框架直接提供虚拟的集群环境。这样,大部分的分布式应用就可以在无需任何修改的条件下直接运行在虚拟的集群环境中。为了验证ClaaS的可行性,基于现有的轻量化容器技术和软件定义网络技术等实现了一个开源轻量级私有云系统Docklet,能够支持用户按需共享资源,支持Spark、MPI等各种计算框架,及Python、R、Java等语言,并在真实教学科研环境中提供、部署服务。最后描述了系统的设计与实现,并进行了实验与评估。
云计算;虚拟机群;ClaaS;软件定义
1 引言
如今,伴随数据规模的膨胀与数据使用方式的增加,在许多企业内部,需要运行的计算框架越来越多[1]。同时,应用框架本身的多样性也随着云计算和大数据处理技术的发展而快速上升。在当今的环境下 Hadoop(http://hadoop.apache.org)、Spark(http://spark.apache.org)、Storm(http://storm.apache.org)这样的分布式应用框架占据主流地位,而MPI(http://www.mpi-forum.org/docs)和OpenMP(http://openmp.org/wp/)这样的传统分布式或并行应用框架也扮演着相当重要的角色。分析这些使用计算资源的方式,不难发现它们的一些共性,其中最为重要的就是它们都需要依托集群资源来使得计算效率最大化。然而,许多中小型的企业和组织只拥有有限的计算资源,对他们而言,为每一个需要运行的应用框架单独配置集群花销巨大且浪费资源,几乎不可能实现。因此,他们迫切需要一种简单而高效的方法来在各种应用框架之间共享计算资源,解决资源共享率低和资源浪费的问题[2],在满足运算需求的前提下减少在计算资源方面的开销。此外,同一个机构下的不同用户出于各种原因也会需要同一个计算框架的不同副本。例如,A用户在运行版本1的Spark的同时,另一个用户B需要同时运行版本2的Spark,这就需要为计算资源提供多用户和多实例的支持。
目前,在同一个物理集群中为不同框架提供计算资源方面已经有了一些解决方案[3]。Mesos[4]是其中有代表性的一种,它通过合理地封装、调度资源,提供了一套可行的共享资源方法。然而,Mesos对于不包括在它支持列表里的计算框架而言不够灵活,甚至需要使用者编写新的调度代码来使得这些框架运行在Mesos上。例如,在Mesos上运行MPI程序就需要用户额外编写一个调度脚本,这对不够精通Mesos的使用者而言是一个相当大的负担。而且在Mesos中,用户通常共享同一框架的同一个实例,让不同用户出于各种原因(比如安全性)运行同一框架的不同实例有时是非常困难的。而Borg[5]、Apollo[6]、Omega[7]这样的系统又过于专有化,需要巨量的计算资源与定制化的应用,难以在中小型私有云中进行使用。
为了解决上述私有云环境下的资源共享问题,本文提出了ClaaS(cluster as a service)的概念。ClaaS的目标是构建一个可扩展的高效而易于使用的系统,这一系统可以向私有云中可信的用户提供虚拟集群服务,能够支持用户按需共享资源。用户可以方便地仅通过Web接口在线创建虚拟集群,在集群中运行Spark和MPI这样的应用,而无需掌握有关新系统的复杂知识。与以往的解决方案最重大的不同是,ClaaS提供“虚拟集群即服务”,包括若干虚拟单位(虚拟机或容器)和网络设施,而非单个的虚拟单位,作为一个单元。
ClaaS有如下的能力和优势:其一,提供简单可靠的资源管理与作业管理技术;其二,不同进程可以通过虚拟集群提供的可靠通信方法形成一个整体;其三,ClaaS系统会按需为每个计算框架构建一个虚拟的私有子网;最后,由于每个应用的负载在实际应用中不尽相同,ClaaS的虚拟集群提供可伸缩性以实现更高的资源利用率。
基于ClaaS的理念,开发了一个轻量的可扩展的云系统Docklet。为了减少中间过程的性能损耗,Docklet使用了Linux容器LXC(http://lxc.sourceforge.net/lxc.html)。LXC目前集成在Linux内核中,拥有封装和隔离资源的功能[8]。相较于其他资源封装手段,该项技术对于ClaaS而言更高效,更加适合私有云环境。同时,在Docklet中使用了软件定义技术来帮助管理和虚拟化集群资源。对于多用途的应用,Docklet提供了简单的Restful接口。Docklet可方便地支持Spark、Storm、MPI、Hadoop、MapReduce、HDFS、Akka、Erlang、RabbitMQ和Jupyter等应用,所有这些应用都可以简单地通过浏览器访问而无需额外部署软件环境,这对于企业用户而言是十分易于使用的。Docklet已经在多个教育科研环境进行了部署,提供教学实验环境、大数据分析等服务,代码在github开源(https://github.com/unias/docklet)。
本文组织结构如下:第2章叙述了相关工作;第3章描述了ClaaS模型和虚拟集群的概念;第4章描述了基于ClaaS模型的Docklet系统设计;第5章给出了一些实例和实验;最后给出了一些结论,同时描述了未来的工作。
2 相关工作
Mesos[4]是一个支持多框架共享物理资源的开源资源调度引擎,得到了广泛的应用。但Mesos的一个问题是,并非所有应用都能简单地代入Mesos中运行,让Mesos支持新的框架是一件困难的工作,程序员需要编写许多额外的代码来完成这一目标。在最坏的情况下,程序员甚至需要调整应用框架的源代码,使其适应Mesos。此外,Mesos还缺乏多用户的隔离支持,比起提供ClaaS,它更专注于资源调度。在ClaaS中,通过使用软件定义技术,新的应用框架可以很容易得到支持,同时ClaaS也提供多用户支持。
ClaaS使用了Linux容器技术LXC。Felter等人[9]对比了传统虚拟机和Linux容器间的性能差异,列出了二者性能损耗的细节。其实验结果指出,几乎在所有情况下,Linux容器在性能上等同于或超过传统虚拟机。基于该实验的结果,为了提升整体性能表现,本文在虚拟化方面放弃虚拟机而使用容器。Docker是另一种容器技术的封装,本文没有采用Docker而采用LXC技术的原因是Docker技术更复杂,而LXC更轻量简单,适合本文面向的私有云环境。
Doelitzscher等人[10]描述了一个用于为私有云中的研究项目与机器学习任务按需提供高性能计算资源的云解决方案,该方案可以在需要时使用亚马逊的公有云作为扩展资源池。Brock等人[11]也提出了在云设施中提供整个集群作为服务的概念。与以上工作不同的是,本文更专注于为任意不同的应用框架构建一个高效易用的ClaaS平台,并支持灵活的资源调度。
OpenStack[12]是一个按节点分配资源、部署系统环境的开源私有云平台,它在不改变程序源代码和操作方式的条件下就能在同一集群里运行各种不同的应用框架。和ClaaS不同之处在于,它其实是使用虚拟机的方法隔离了资源,依旧是一次提供单个虚拟资源的模式,对于许多分布式的弹性的应用框架而言缺乏效率与扩展性。OpenStack工作在基础设施即服务(infrastructure as a service,IaaS)层面,因此对于应用框架本身并不友好。使用类似OpenStack的工具构建、管理、使用一个虚拟云平台是一件十分繁重而复杂的工作。
3 ClaaS与Vcluster模型
ClaaS不仅不同于提供单节点服务的IaaS,与对程序提供应用接口的平台即服务(platform as a service,PaaS)也有很大的区别。它通过直接提供集群作为服务单元,描述了一种通用的定义不同应用的方法,同时为私有云环境下的应用实现了高兼容性、高效性与高扩展性支持。
3.1 Vcluster与它的优势
ClaaS提供给用户的是虚拟集群Vcluster(virtual cluster),每个Vcluster包括一系列分布式的同构的节点与连接它们的网络设施,对于用户而言Vcluster可以看成是物理集群环境,从而可以安装运行自己所需要的分布式计算框架。在ClaaS中,使用者可以将不同的应用框架部署在不同的Vcluster中,这样的设计有如下的优点:
(1)灵活性。Vcluster中的每个节点都提供和传统虚拟机相似的环境,任何应用框架都可以简单地移植到Vcluster中,通过创建新的Vcluster来支持和扩展。
(2)可扩展性。同一Vcluster中的不同节点可以透明地在不同物理机器上运行,由此使得单个应用框架可以利用不同位置的物理资源。
(3)伸缩性。每个Vcluster都允许内部的应用方便地控制工作节点的生存周期,这对应用自身通过调度实现弹性有着极大帮助。
(4)可定义性。Vcluster可以通过软件定义技术描述和重建,用户可以自定义分布式结构、迁移策略、运行脚本及其他特征,这使得Vcluster的使用十分灵活。同时,该特性独立于硬件结构。
如图1所示,ClaaS提供的这种服务模型使得它比在IaaS层面操作更有优势,而且它在部署分布式框架时也能做到和PaaS模式类似。
3.2 ClaaS中的软件定义技术
在虚拟化过程中,使用了软件定义技术,利用灵活的软件协议来代替固定的硬件设备。例如,软件定义网络、软件定义存储等。在Vcluster层面,同样使用了这一类技术,本文称之为软件定义虚拟集群。软件定义的虚拟集群需要用户提供构建逻辑集群,处理集群状态变化和执行内部应用的一些关键参数。
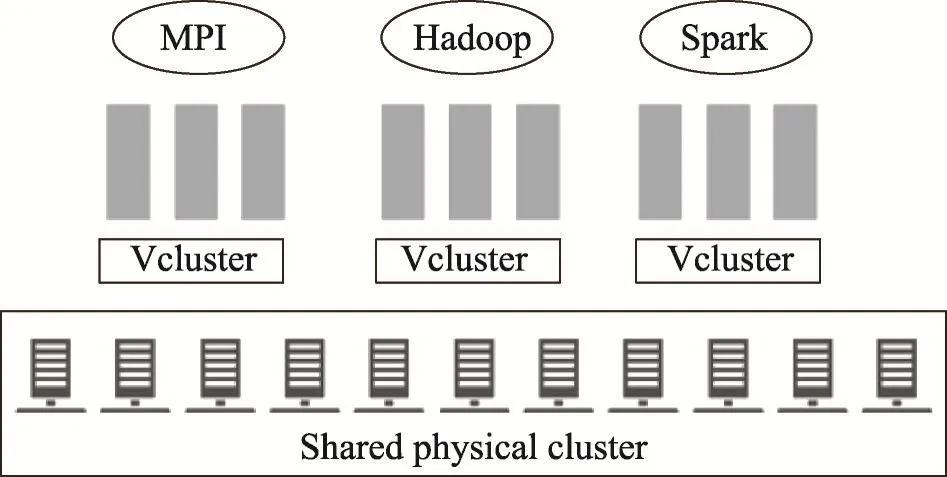
Fig.1 Multiple Vcluster for multiple tenants图1 多租户条件下的多个Vcluster
软件定义虚拟集群有如下两方面的优势:
(1)简化集群部署的复杂度。ClaaS的用户无需单独配置每一个节点,只需要提供一些简单的策略来处理集群伸缩、节点恢复与节点迁移这样的事件。
(2)简化分布式设备的管理。Vcluster与其内部的应用可以随时被方便、快捷而安全地共享或重现,这无疑同时减轻了管理员和用户的学习与使用成本。
4 ClaaS支持系统Docklet的设计与实现
Docklet是设计用来支持ClaaS的平台系统,它是一个开源项目(https://github.com/unias/docklet)。
Docklet是为拥有中小型数据中心的企业或科研机构设计的轻量级私有云平台,使员工能方便地共享使用有限的计算资源。这些用户通常有很多在物理机或虚拟机上工作的经验,且不太愿意接受很高的时间花费去学习一套新系统的使用方法。人们希望Docklet提供的虚拟集群可以像用户熟悉的传统物理机或虚拟机一样使用。同时,Docklet引入了一些方便用户使用的新特性。例如,提供一份软件定义的文档,就可以迅速构建并重现一个特定的Vcluster,并在它启动时自动运行指定的应用框架或服务。同时,还希望它可以在占用尽量少的物理资源的情况下表现良好。
除此之外,Docklet还要求Vcluster拥有弹性,以便使用Hadoop和Spark这样的分布式程序或框架。在Docklet的设计中,用户和Vcluster内部的程序都可以方便地控制Vcluster的规模。为了让Docklet对扩展和外部监督更加开放,应该提供一套简单易用的接口。在目前版本中,使用了HTTP协议下REST-ful风格的接口,以保证只需要浏览器就可以使用Docklet提供的服务。
4.1 结构设计
Docklet的用户视图见图2。用户通过工作空间(workspace)来访问自己的资源,workspace就是包含用户应用与数据的工作空间,在这个空间里,用户可以进行运行应用、分析数据等操作。每个workspace在底层通过一个对应的Vcluster来支持,而Vcluster是Docklet进行资源管理的一个单元。一个Vcluster由一系列节点与连接它们的私有子网构成。用户可以在浏览器中创建、删除、重启、扩展与收缩Vcluster来管理自己的资源。与此同时,每个workspace为用户提供了一个Portal来访问和操作Vcluster中的节点。每个节点之间是分开的,只有同一个Vcluster中的节点可以通过网络互相访问,即不同Vcluster的节点无法彼此影响。在实现细节上,每个虚拟节点都是一个LXC容器。
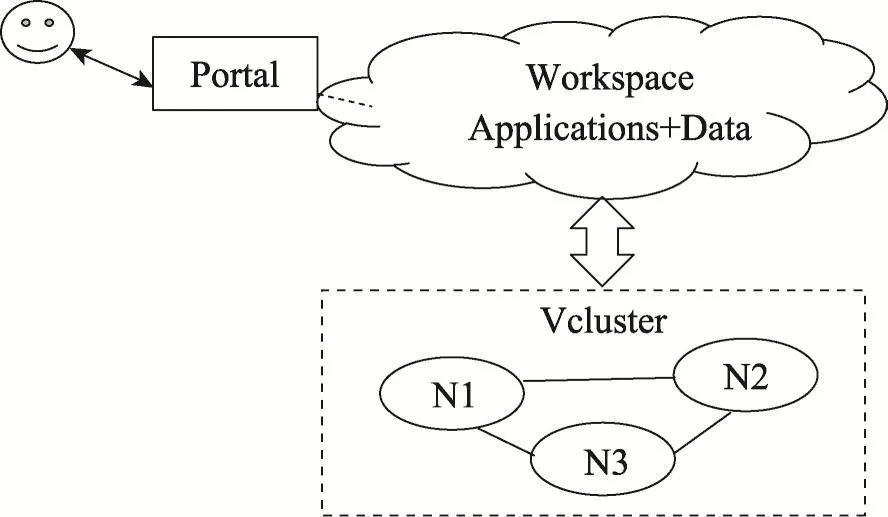
Fig.2 User's perspective of Vcluster and workspace图2 Vcluster和worksapce的用户视角
Vcluster中的节点需要通过镜像创建,Docklet使用的镜像和虚拟机镜像或Docker镜像很相似。Docklet采用了一种简单却有效的技术来构建、分享和使用适用于不同条件的镜像。如果需要向Docklet中添加对一种新框架的支持,用户可以简单地在一个节点中搭建好对应的软件环境,然后将这个节点的快照保存为镜像。用户还可以在Docklet的所有用户间共享这个镜像,一旦一个镜像被设置为共享,所有用户都可以访问并使用它。对于之后的用户而言,共享镜像使得应用的部署被大大简化了。
图3展示了Docklet的主要组成构件。Docklet使用了一个Web服务器来为用户展示图形界面,一个http服务器来处理发来的各种请求。图中的Core指的是Docklet的核心,它包含一个master进程,若干个运行在每一台物理机上处理具体工作的worker进程,搭建网络基础设施的网络构件,以及远程过程调用(remote procedure call,RPC)构件。在系统的更底层,ETCD(https://coreos.com/etcd/docs)被用来存储系统运行中产生的信息,分布式文件系统被用于存储用户的磁盘数据。
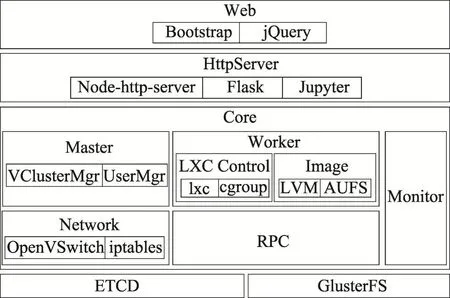
Fig.3 Architecture of Docklet图3 Docklet的结构
在物理层面上,Docklet服务器分为计算服务器和存储服务器,计算服务器提供处理器、内存等计算资源和一小部分存储资源(通常被软件运行环境占用),而存储服务器提供绝大多数的存储资源。这样计算和存储分离的设计适合中小规模的集群,可以使得Docklet具有较好的弹性伸缩能力和较灵活的系统扩展能力。与此同时,存储对于用户而言是透明的,用户无需关心计算节点中数据的存储位置。目前,本文使用GlusterFS(http://www.gluster.org)作为底层的分布式文件系统,其他能达到同样功能的文件系统(如Ceph)也可以用于Docklet中。
当master进程接收到创建Vcluster请求时,会根据物理资源的状态和已有Vcluster的负载决定新的Vcluster的部署位置。当Docklet已准备好创建一个Vcluster后,它会将创建容器的参数传递给合适的worker,然后开始构造该Vcluster的网络结构,Docklet的网络构件会保障该Vcluster容器间的正常通信。镜像的保存则使用了逻辑卷管理(logical volume manager,LVM)和AUFS(advanced multi-layered unification filesystem,以UNIONFS[13]为原理),以便容器可以被方便地保存和在用户间共享、重现,而monitor模块主要负责展示物理资源和虚拟集群的运行状况。
在Docklet中,用户可以在浏览器中创建一个弹性的、动态的、无需额外配置就可以开始运行所需任务的虚拟集群(例如,创建集群之后直接运行Spark作业)。该集群可以随时停止或重启,也可以被分享给系统内的其他用户。当作业运行时,用户通过一个网页了解到集群的各种状态。作业完成后,逻辑集群就可以被删除并释放所占用的资源。
对每个workspace而言,Docklet提供一个门户来让用户可以从外部网络直接访问Vcluster的内部节点。在目前版本中,使用了一个开源项目Jupyter来实现在浏览器中远程操作节点的功能。
4.2 Docklet的特点
Docklet有如下特点:
(1)隔离性。Docklet采取了很多措施,防止单个节点出现问题时可能影响到其他节点和外部环境的情况出现,这些措施包括CGroup、Capacity Drop、Namespace、NetFilter、Apparmor、Filesystem Quota等。
(2)高效性。单台物理机可以被多个用户的Vcluster中的节点共享,这有利于在资源有限的情况下高效利用计算资源。
(3)简单性。对用户而言在Docklet上部署基于集群的应用是十分快捷的,因为Docklet将其中许多复杂单调的工作,例如子网配置、数据共享空间、SSH公私钥配置,简化或自动完成了。
(4)透明性。无论虚拟节点在哪一台物理机上,有没有被迁移,从外部来看,该节点的IP地址、根文件系统和共享数据等参数都不会发生变化。
4.3 接口设计
为了方便内部修改与外部扩展,Docklet的应用程序编程接口(application programming interface,API)是按照RESTful风格设计的,以下列出了一些重要的API。对于这些API来说,返回类型都是“application/json”。


4.4 虚拟网络
Docklet的虚拟集群Vcluster各个节点要求是能在一个虚拟网络子网中,彼此互相联通,从而像物理集群一样可安装运行分布式应用。Docklet的虚拟网络功能大部分建立在OpenVSwitch(http://openvswitch.org/support/dist-docs/)与iptables的基础上,OpenVSwitch是OpenFlow[14]技术的开源实现,在Docklet中主要被用来建立虚拟子网。网络模块给同一个Vcluster中的节点提供一个透明的虚拟子网,让它们看起来出于同一个真正的局域网中。Docklet的网络结构如图4所示,各个宿主机间建立了连接容器的GRE(generic routing encapsulation)通道,这些通道无需额外的网络设备支持。当一个Vcluster准备被创建时,Docklet会建立一个子网,该Vcluster中的容器会在这个子网下生成,同时Docklet会配置好SSH公钥和私钥,使得容器间可以彼此免密码登录。
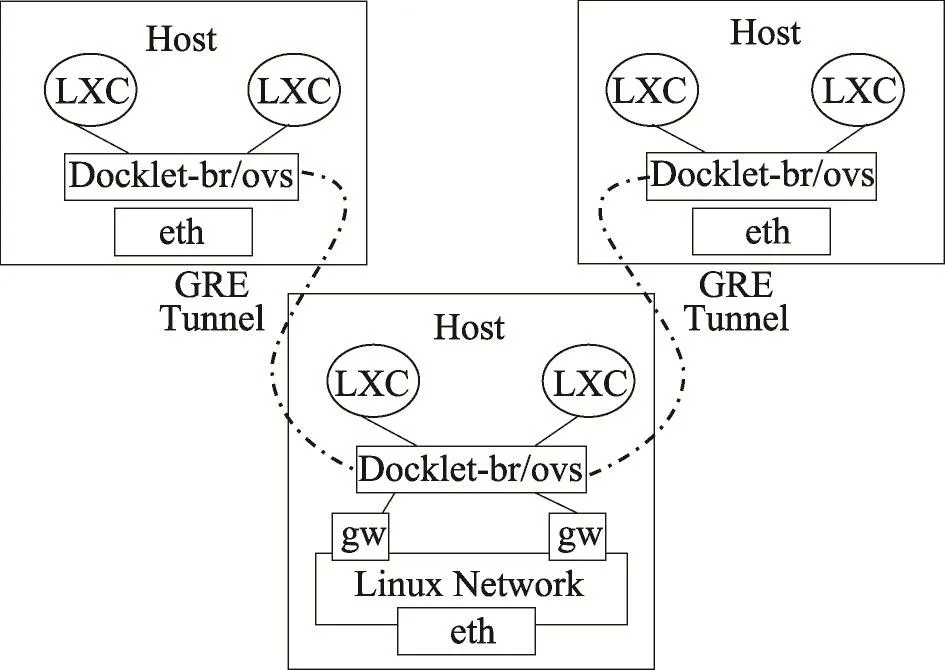
Fig.4 Docklet network on multi-hosts图4 多宿主机网络结构
5 实验与评估
为了展示Docklet的特性和使用效果,本文在真实环境的物理机下进行了一些实验。以下的实验与评估都基于3台拥有400 GB物理内存,32核CPU(Xeon E5-2670 2.60 GHz)的装有Docklet的物理机。Docklet配置每个容器使用1个CPU和4 GB的内存。此外,该物理集群中还包括额外的3台用作全局NFS存储的机器,每台机器拥有3 TB的RAID5磁盘阵列(redundant arrays of independent disks,RAID)。
5.1 样例:Spark作业
该实例展示了在Docklet上部署Spark的过程,如图5所示。登录Docklet后,创建新的workspace,此时该workspace里默认有1个节点。之后,将该workspace扩展到3个节点,其中的Vcluster含有3个节点,它们的名字分别是系统默认的host-0、host-1、host-2。使用Jupyter进入host-0之后,执行如下的脚本。Spark的运行状态可以从Docklet提供的代理链接中查看。
Start scripts for Spark
root@host-0:~#cd/home/spark
root@host-0:/home/spark#./sbin/start-master.sh
root@host-0:/home/spark#ssh root@host-1/home/spark/sbin/start-slave.sh spark://host-0:7077
root@host-0:/home/spark#ssh root@host-2/home/spark/sbin/start-slave.sh spark://host-0:7077
root@host-0:/home/spark#./bin/spark-submit--master spark://host-0:7077 examples/src/main/python/pi.py 10
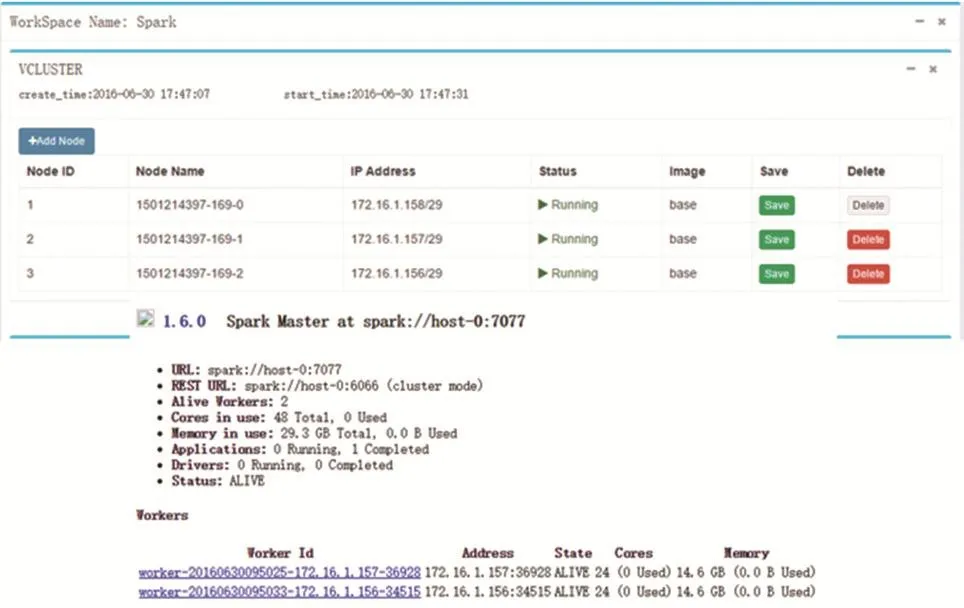
Fig.5 Spark example图5 Spark样例
5.2 样例:MPI作业
MPI也可以在Docklet上方便地运行,集群的配置方法同Spark的例子,在host-0中执行如下脚本就可以开始MPI作业(假设MPI程序是program.cpp)。
Start scripts for MPI
root@host-0:~#cd/nfs
root@host-0:/nfs#mpic++./program.cpp-o mpi.bin
root@host-0:/nfs#mpiexec-hosts host-0,host-1,host-2-n 6./mpi.bin〉/nfs/result.out
5.3 评估:I/O密集型作业
本实验中,在Docklet上测试了I/O密集型的Map-Reduce任务,一个处理GlusterFS中14 GB/37 GB数据的并行word count程序。GlusterFS和Docklet节点间的数据交换完全通过TCP/IP网络进行。表1展示了该实验在I/O任务中产生的结果。可以看出,Docklet实现了应有的并行效果。

Table1 Speedup of I/O jobs with scalable working nodes表1 可伸缩工作节点进行I/O工作的加速比
5.4 评估:弹性测试
本实验中,通过一个Spark PageRank作业来测试Docklet的弹性表现。由于每个super-step的计算复杂度基本都是相等且稳定的,每个super-step花费的时间基本随工作节点数量的上升而下降,Docklet的弹性管理器(在集群扩展或收缩的时候被调用)会在固定的时间改变集群的工作节点数量。图6展示了该作业的运行效率与Vcluster中节点数量的关系。值得注意的是,新加入的Spark slave需要花10s左右的时间来初始化并准备运行作业,而释放节点会立即降低Spark的运算效率。由此可知,Docklet实现了基本的弹性控制。
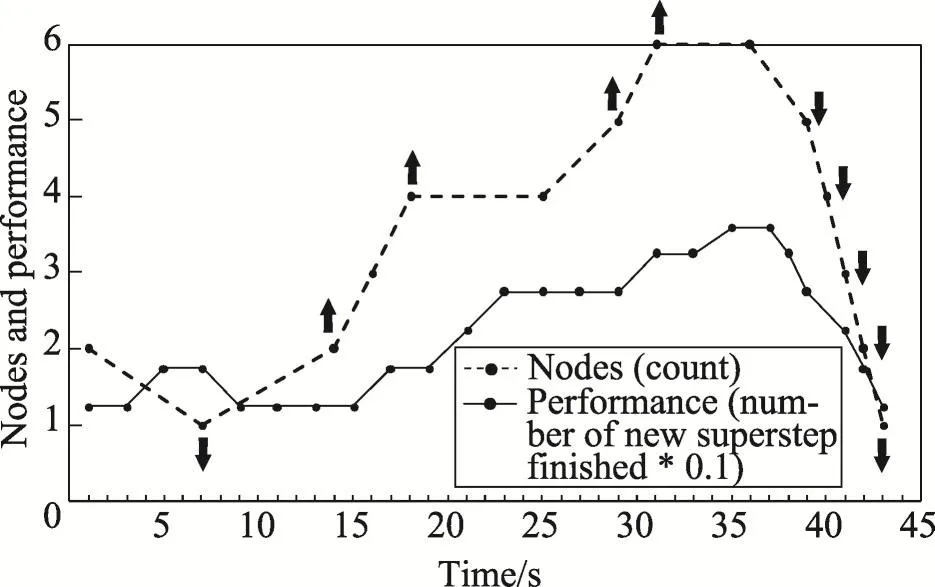
Fig.6 Correlation of Vcluster size and performance图6 虚拟集群规模与运算性能的关系
5.5 评估:网络性能测试
本测试中,测试结果均基于传统的路由器和交换机,并未使用额外的高级硬件,网络结构如图7所示,测量了物理机与物理机,物理机与容器,容器与容器之间的网络吞吐量。此外,容器间的网桥采用OpenVSwitch(v2.4.0)GRE通道(图中的ovs-bridge),OpenVSwitch设备的MTU值被设置为1 420。
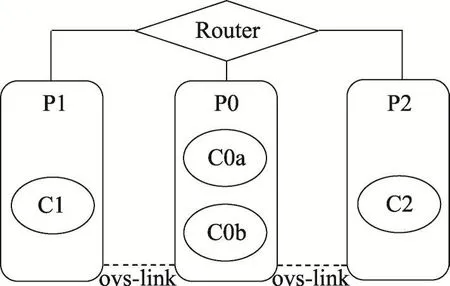
Fig.7 Topology of testing environment图7 网络测试环境结构
P0、P1、P2代表物理机(physical host),C0a、C0b、C1、C2代表容器(container)。表2展示了网络吞吐量和网络传输过程中的ovs-bridge之间的关系。实验证明,当前版本基于传统硬件OpenVSwitch,效率并不高,之后可以用VLAN或SDN[15]优化的芯片来提升效率。
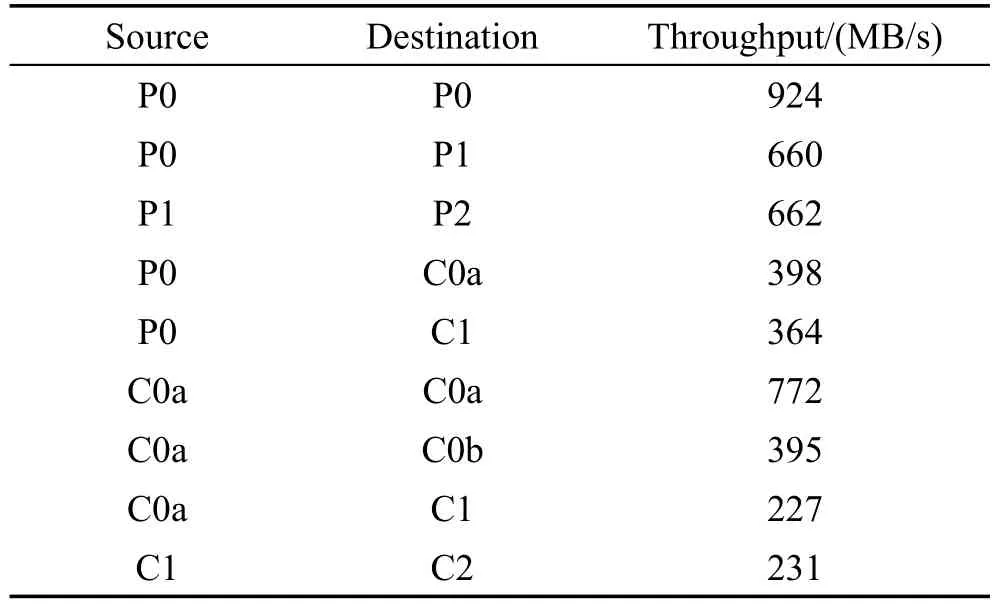
Table2 Data transmission throughput between nodes表2 各节点间网络吞吐量
6 结束语
本文提出了一种私有云环境下基于虚拟集群的资源共享方法ClaaS,介绍了支持ClaaS的Docklet系统及其实现,该系统兼有OpenStack与Mesos这两种方法的优点,为应用框架提供了可扩展性、兼容性以及软件定义的方法。
ClaaS是一种方便易用的在不同应用框架之间共享集群的方法,它大大简化了部署和配置各种应用,特别是分布式应用的过程,还提供了多用户支持与随时重建应用所需环境的功能。Docklet平台可以生成独立于硬件结构的虚拟集群,并利用设计好的特殊机制让其中的容器更好地工作。
未来的工作包括两点:一是更加智能的负载均衡算法,可以使得Docklet根据物理资源的当前状态及历史状态找出资源使用率变化的规律,从而更好地调整容器分布,提高资源利用率;二是更加高效的弹性伸缩,在获取全局状态的前提下对纵向和横向的弹性伸缩进行更好的支持,从而优化整个物理集群的状态。
[1]Cheng Xueqi,Jin Xiaolong,Wang Yuanzhuo,et al.Survey on big data system and analytic technology[J].Journal of Software,2014,25(9):1889-1908.
[2]Lu Xicheng,Wang Huaimin,Wang Ji.Internet virtual computing environment-iVCE:concept and architecture[J].Science in China:Series E Information Sciences,2006,36(10):1081-1099.
[3]Zhan Hanglong,Cao Donggang,Xie Bing.Graph processing framework supporting elastic scalability in distributed shared environment[J].Journal of Frontiers of Computer Science and Technology,2016,10(7):901-914.
[4]HindmanB,KonwinskiA,Zaharia M,et al.Mesos:a platform for fine-grained resource sharing in the data center[C]//Proceedings of the 8th USENIX Conference on Networked Systems Design and Implementation,Boston,USA,Mar 30-Apr 1,2011.Berkeley,USA:USENIX Association,2011:295-308.
[5]VermaA,Pedrosa L,Korupolu M,et al.Large-scale cluster management at Google with Borg[C]//Proceedings of the 10th European Conference on Computer Systems,Bordeaux,France,Apr 21-24,2015.New York:ACM,2015:18.
[6]Boutin E,Ekanayake J,Lin Wei,et al.Apollo:scalable and coordinated scheduling for cloud-scale computing[C]//Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation,Broomfield,USA,Oct 6-8,2014.Berkeley,USA:USENIX Association,2014:285-300.
[7]Schwarzkopf M,KonwinskiA,Abd-El-Malek M,et al.Omega:flexible,scalable schedulers for large compute clusters[C]//Proceedings of the 8th ACM European Conference on Computer Systems,Prague,Czech Republic,Apr 14-17,2013.New York:ACM,2013:351-364.
[8]Bernstein D.Containers and cloud:from LXC to Docker to Kubernetes[J].IEEE Cloud Computing,2014,1(3):81-84.
[9]Felter W,FerreiraA,RajamonyR,et al.An updated performance comparison of virtual machines and Linux containers[J].Technology,2014,25482:171-172.
[10]Dölitzscher F,Held M,Reich C,et al.ViteraaS:virtual cluster as a service[C]//Proceedings of the 3rd International Conference on Cloud Computing Technology and Science,Athens,Greece,Nov 29-Dec 1,2011.Washington:IEEE Computer Society,2011:652-657.
[11]Brock M,GoscinskiA.Atechnology to expose a cluster asa service in a cloud[C]//Proceedings of the 8th Australasian Symposium on Parallel and Distributed Computing,Brisbane,Australia,Jan 1,2010.Darlinghurst,Australia:Australian Computer Society,Inc,2010:3-12.
[12]OpenStack,NASA and Rackspace[EB/OL].[2016-07-23].http://docs.openstack.org.
[13]Quigley D,Sipek J,Wright C P,et al.Unionfs:user-and community-oriented development of a unification filesystem[C]//Proceedings of the 2006 Ottawa Linux Symposium,2006,2:349-362.
[14]McKeown N,Anderson T,Balakrishnan H,et al.OpenFlow:enabling innovation in campus networks[J].ACM SIGCOMM Computer Communication Review,2008,38(2):69-74.
[15]Software-defined networking:the new norm for networks.Open Networking Foundation,2012.
附中文参考文献:
[1]程学旗,靳小龙,王元卓,等.大数据系统和分析技术综述[J].软件学报,2014,25(9):1889-1908.
[2]卢锡城,王怀民,王戟.虚拟计算环境iVCE:概念与体系结构[J].中国科学:E辑信息科学,2006,36(10):1081-1099.
[3]詹杭龙,曹东刚,谢冰.分布共享环境下支持弹性伸缩的图处理框架[J].计算机科学与探索,2016,10(7):901-914.
Virtual Cluster Based Resource SharingApproach for Private Cloud Environment*
LIU Peidong1,2,AN Bo1,2,ZHONG Yehong1,2,WANG Hu1,2,CAO Donggang1,2+
1.Key Lab of High Confidence Software Technologies(Peking University),Ministry of Education,Beijing 100871,China
2.Peking University Information Technology Institute(Tianjin Binhai),Tianjin 300450,China
+Corresponding author:E-mail:caodg@pku.edu.cn
LIU Peidong,AN Bo,ZHONG Yehong,et al.Virtual cluster based resource sharing approach for private cloud environment.Journal of Frontiers of Computer Science and Technology,2017,11(8):1204-1213.
With the rapid development of cloud computing and big data processing,an increasing number of application frameworks are being considered to run in a“cloud way”.This development brings about several challenges to the enterprise private cloud computing platform,e.g.,sharing limited cluster resources effectively among different frameworks and users,being able to run most existing heterogeneous applications,as well as providing scalability and elasticity support for newly emerged frameworks.This paper proposes a new service model,namely,cluster as a service(ClaaS),which is suitable for medium and small-sized data centers to solve these problems in a relatively easy and general way.The idea behind this model is to virtualize the cluster environment for distributed application frameworks.Most applications can directly run in the virtual cluster environment without any modification,which is a great advantage.Based on lightweight containers and software-defined network,this paper implements an opensource system of ClaaS named Docklet to prove the feasibility of this service model.Docklet is able to distribute resources to users according to their needs,support frameworks like Spark,MPI,and languages like Python,R andJava.Moreover,Docklet is now used to provide and deploy services in real scenarios of teaching and researching.Finally,this paper describes the design and implementation of this system,then presents several examples and evaluates the entire system.
cloud computing;virtual cluster;ClaaS;software definition
ang was born in 1975.He
the Ph.D.degree from School of Electronics Engineering and Computer Science,Peking University in 2004.Now he is an associate professor at Software Engineering Institute,School of Electronics Engineering and Computer Science,Peking University,and the senior member of CCF.His research interests include system software,parallel and distributed computing,etc. 曹东刚(1975—),男,山东威海人,2004年于北京大学信息科学技术学院获得博士学位,现为北京大学软件工程研究所副教授,CCF高级会员,主要研究领域为系统软件,并行计算与分布式计算等。

LIU Peidong was born in 1995.He is an M.S.candidate at Software Engineering Institute,Peking University.His research interests include big data,system software,parallel and distributed computing,etc.刘沛东(1995—),男,江西新余人,北京大学硕士研究生,主要研究领域为大数据,系统软件,并行计算与分布式计算等。

AN Bo was born in 1992.He is a Ph.D.candidate at Software Engineering Institute,Peking University.His research interests include cloud computing,system software and distributed computing,etc.安博(1992—),男,陕西榆林人,北京大学博士研究生,主要研究领域为云计算,系统软件,分布式计算等。

ZHONG Yehong was born in 1994.He is an M.S.candidate at Software Engineering Institute,Peking University.His research interests include operating system,big data,distributed computing and cloud computing,etc.钟业弘(1994—),男,海南文昌人,北京大学硕士研究生,主要研究领域为操作系统,大数据,分布式计算与云计算等。

WANG Hu was born in 1989.He is an M.S.candidate at Software Engineering Institute,Peking University.His research interests include big data,system software,parallel and distributed computing,etc.王虎(1989—),男,河南南阳人,北京大学硕士研究生,主要研究领域为大数据,系统软件,并行计算与分布式计算等。
A
:TP391
*The National Natural Science Foundation of China under Grant Nos.61272154,61421091(国家自然科学基金);the National Science and Technology Major Project of China under Grant No.2016YFB1000105(国家重点研发计划).
Received 2016-09,Accepted 2016-11.
CNKI网络优先出版:2016-11-11,http://www.cnki.net/kcms/detail/11.5602.TP.20161111.1627.004.html
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology 1673-9418/2017/11(08)-1204-10
10.3778/j.issn.1673-9418.1609030
E-mail:fcst@vip.163.com
http://www.ceaj.org
Tel:+86-10-89056056
猜你喜欢
中学生数理化·八年级物理人教版(2022年4期)2022-04-26
科学技术创新(2021年18期)2021-06-23
读者·校园版(2019年24期)2019-12-10
微型电脑应用(2019年10期)2019-10-23
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年11期)2018-08-04
计算机测量与控制(2017年12期)2018-01-05
计算机技术与发展(2017年12期)2017-12-20
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
