
基于LDA模型的音频分类方法
2017-08-10 09:52张翔孙伟余璇
现代计算机 2017年17期
张翔,孙伟,余璇
(上海海事大学信息工程学院,上海 201306)
基于LDA模型的音频分类方法
张翔,孙伟,余璇
(上海海事大学信息工程学院,上海 201306)
随着网络的发展海量音频文件涌现,音频分类系统也越来越普及。音频分类,尤其是语音和音乐的分类是提取音频结构和内容语义的重要手段,是基于内容的音频检索和分析的基础。介绍一种基于音频内容根据音频内容间的相似度对音频进行分类的方法。用每个音频的音高集代表该音频文件,以LDA主题模型对音频进行分类。
相似度;音频内容;音高;LDA主题模型
0 引言
随着计算机技术与多媒体技术的发展大量的音频文件进入我们的生活。在这种情况下的音频检索的范围也越来越大检索的准确率也越来越低,且原始音频文件中所包含的数据缺乏语义与结构化的组织很难直到其真实意义这给音频检索带来很大的困难。因此,缩小音频检索的范围提高检索效率变得尤为重要。音频分类技术可以很大程度上缩小检索的范围提高检索的效率。因此,有关音频分类的研究越来越普及。
有关音频分类的研究早期主要有文献[1,2]所示技术,文献[1]介绍了一种将神经元网络直接将声音类别映射到所标注的文本。文献[2]通过使用自组织映射聚类算法将具有相似特征的音频划归为同一类。美国Music Fish公司的Erling Word等人通过分析响度、音高、亮度、谐度实现了真正意义上的基于内容的音频分类,所用数据集包括铃声、音乐等16类样本数据[3]。卢坚、陈毅松、孙正兴、张福炎于2002年12月提出了基于隐马尔可夫模型的音频自动分类[4]。到2005年白亮、老松杨、陈剑赞、吴玲达提出了基于支持向量机的音频分类[5]。语音和音乐是两类比较重要的音频文件是基于内容检索技术的主要区分对象,文献[6,7]采用基于简单决策树的语音/音乐多步层次分类方法,即每一步根据一种或者几种音频特征及其阈值判定音频所属的类别。
1 概述
音频分类属于模式识别领域,涉及到计算机技术、多媒体数据库技术,主要包括两个过程:音频特征提取和音频分类两步。音频特征提取指应用数字信号处理技术和信号系统理论来寻找原始音频信号表达形式,抽取出能代表原始信号的数据,抽取出音频的物理特征。音频分类是指通过音频间的相似度将有相似特征的音频归为一类。音频分类问题是基于内容的音频检索技术必须解决的关键问题。
隐式狄利克雷(LDA)主题模型原本用于文本分类。LDA模型对文本进行分类时假设文本没有任何的词序和语法、句法,也就是说文本中的所有的词都是无序的。LDA模型对文本分类的具体过程为:首先给每篇文本的每一个词随机的赋予一个主题编号;重新扫描语料库对每篇文章的每个词的主题编号进行吉布斯采样;重复上一步直到吉布斯采样公式收敛;根据记录的数据计算出每篇文本对于主题类别的概率分布。
2 基于LDA模型的音频分类
2.1 音频特征提取
音高指各种不同高低的声音,即音的高度。音的高低由振动频率决定的,两种成正比关系。考虑到音乐的音高频率趋向于音高频率表中的振动频率而平常语音的振动频率有高有底数值分布比较广。因此,这里提取音高频率作为音频的特征,并写入文档,作为LDA模型的输入。基于用户输入的分类个数K,LDA模型通过该文档将音频分为指定K类。提取音高频率的算法由python的vamp库提供。运行程序可得每个文件的音高集,去除其中小于等于0的数值得到有效的音高集。音频音高提取关键代码如下所示这里使用Python语言实现。

2.2 LDA模型分类
LDA模型假设每个音频的每个音高之间都是无序的,没有任何的先后关系。因此,如图1所示在LDA模型中每个音频可以表示为三层生成式贝叶斯网络结构,一个音频由若干个隐含的主题构成,而这些主题由若干个音高构成。基于用户输入的分类个数K,LDA模型根据每个音频的相对音高之间的相似度对音频进行分类,最终可得到每个音频对于文件的概率分布P(topick|audio)。
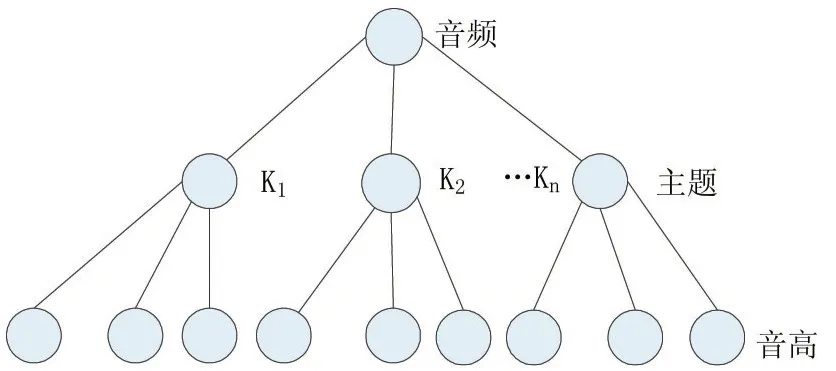
图1 三层生成式贝叶斯网络结构
在生成一个音高时,LDA模型假设每个音高的生成过程如下:首先从若干类别中选择一个类别,再根据该类别生成一个音高。重复以上过程便可生成一个音频。基于以上假设每个音高的生成原理如图2所示。

图2 音高生成原理图
生成过程如下:

Dirichlet先验分布+多项分布数据→Dirichlet后验分布

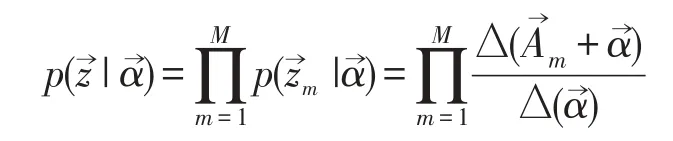

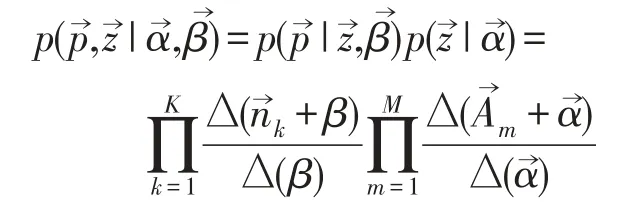
已知生成所有相对音高的联合分布是M+K个狄利克雷共轭分布,可以根据狄利克雷共轭来推导吉布斯采样公式。这里是已知数据,是隐含变量所以需要采样的分布是,音高库中第i个音高对应的topic记为zi,其中i=(m,n)是一个二维下标,对应第m个音频中第n个音高,用表示去除下标为i的音高。按照Gibbs Samping算法的要求,求得任意坐标i所对应的条件分布为。假设已经观测到的音高pi=t,根据贝叶斯法则可得:

由于zi=k,pi=t只涉及到两个共轭结构,而其他的共轭结构和zi=k,pi=t是独立的所以的后验分布依然是狄利克雷分布分别为:
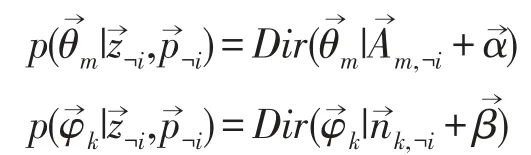
由此可得LDA主题模型的Gibbs Samping公式为:
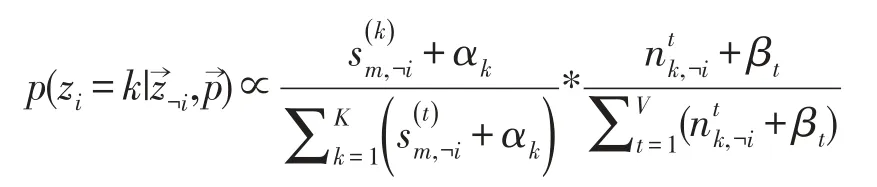
根据吉布斯采样公式可以计算出每个音高的主题编号由当前的主题编号转移至其他主题编号的转移概率,转移原理如图3所示。

图3 吉布斯采样主题编号转移原理图
基于LDA模型音频分类具体流程如图4所示。

图4 基于LDA模型音频分类流程
LDA主题模型对音频进行分类时首先给每个音频的每个音高随机赋予一个主题编号,并记录主题编号与每个音频以及每个音高的相关数量关系数据用于后期计算音频所属类别(这里的编号最大值为用户输入的K);根据吉布斯采样公式计算出当前主题编号转移至各主题编号的概率,并根据转移概率完成主题编号的转移更新相关记录数据;重复迭代上一步骤直到吉布斯采样公式收敛;根据记录的数据计算出每个音频所属于每一类的概率,以及每个音高所属于每一类的概率。在整个过程中吉布斯采样过程为整个分类关键部分其关键代码如下。


3 实验结果分析
本次实验所使用的音频为歌曲、有声小说(语音)、以及歌曲和有声小说的混合音。数量分别有500个。实验PC机为Thinkpad A6-3400M,主频为1.4GHz。音频下载自酷我音乐,下载的文件为mp3文件,转换成wav文件。通过python2.7 vamp库配合melodia插件可取出音频文件的基频序列并写入文本作为LDA模型的输入。
本次实验主要以分类结果的准确性作为评价基于LDA模型的音频分类方法的的指标。根据LDA模型对音频数据分类的结果数据,最终可计算出每个音频属于每个类别的概率以及每个音高频率属于每一类别的概率,选择其中所属概率最大值的类别作为该音频的所属类别。
通过多次实验,修改不同的迭代次数之后分类的结果也趋于稳定。500首歌曲中有440首左右歌曲被归为同一类,即准确率0.88,该类音频中贡献最高的是音高频率表中几个常用的频率。500个有声小说音频中有445个左右的音频被归为同一类,即准确率为0.89,该类音频中对分类贡献比较高的是几个不在音高频率表中的音高频率。有声小说和歌曲混合部分有400个左右音频被归为同一类,即准确率为0.80该类音频中对分类贡献比较高的音高频率有部分来自于音高频率表。平均准确率为0.856左右。歌曲和有声小说的准确率都很不错,但混合音的准确率下降较多。造成这一现象的原因可能是本来音高频率表中的音高频率和无规则的音高频率对于分类贡献相近,但实际试验中却肯定有部分数据偏向于某一方从而导致该类音频被划归到歌曲或者有声小说。文献[6]分类结果为语音准确率0.81、音乐准确率0.70,平均准确率为0.75。文献[7]分类结果为语音准确率为0.75、语音准确率0.89,平均准确率为0.82。基于LDA模型的音频分类方法效果明显好于文献[6]和文献[7]所提方法。
4 结语
本文使用音高频率为每个音频的标志数据,完成了一个基于LDA模型的分类方法。该方法根据音频的音高之间的相似度对音频进行分类。相信用音高标志音频这一方法将会得到更多的应用,LDA模型的作用也将得到巨大的拓展。音频的分类还可以进一步的划分,例如歌曲按照一定的风格划分。音高标志音频是将来关于音频分类的重要研究方向。
[1]Feiten B,Frank R,Ungvary T.Organization of Sounds with Neural Nets.In:Proceedings of the 1991 International Computer Music Conference,International Computer Music Association.San Francisco,1991:441-444.
[2]Feiten B,Gunzel S.Automatic Indexing of a Sound Database Using Self-organizing Neural Nets.Computer Music Journal,1994,18(3):53-65.
[3]Wold E,Blum T,Keislar D,et al.Content-Based Classification,Search,and Retrieval of Audio.IEEE Multimedia Magazine,1996,3(3):27-36.
[4]卢坚,陈毅松,孙正兴,张福炎.基于隐马尔科夫模型的音频自动分类[J].软件学报,2002,13(8):1594-1597.
[5]白亮,老松杨,陈剑赟,吴玲达.基于支持向量机的音频分类与分割[J].计算机科学,2005,4:87-90.
[6]Srinivasan S,Petkovic D,Ponceleon D.Towards Robust Features for Classifying Audio in the Cudevideo System.In:Proceedings of the 7th ACM International Conference on Multimedia.Orlando:ACM Press,1999:393-400.
[7]Lu Guo-jun,Templar H.A Technique Towards Automatic Audio Classification and Retrieval.In:Proceedings of the 4th International Conference on Signal Processing,ICSP,Vol 2,1998:1142-1145.
[8]CHEN Qiu-xing,YAO Li-xiu,YANG Jie.Short Text Classification Based on Lda Topic Model.ICALIP,2016:749-752.
Audio Classification Based on LDA Model
ZHANG Xiang,SUN Wei,YU Xuan
(College of Information Engineering of Shanghai Maritime University,Shanghai 201306)
With the development of the network mass audio files come to the fore,audio classification system is becoming more and more popular.Au⁃dio classification,especially classification between pronunciation and music is an important means of extract audio structure and content se⁃mantics.It is the foundation of audio retrieval and analysis based on content.Introduces a method which classifies audio based on audio contents.And the method classifies audio according to degree of similarity between audio content.In this method,pitch set of every song be⁃halves the song and audio is classification by LDA model.
张翔(1991-),男,江苏淮安人,硕士,研究方向为机器学习
2017-03-28
2017-06-10
1007-1423(2017)17-0016-05
10.3969/j.issn.1007-1423.2017.17.003
孙伟(1978-),男,山东莱州人,副教授,研究方向为机器学习
余璇(1994-),女,河南郑州人,硕士,研究方向为机器学习、自然语言处理
Degree of Similarity;Audio Content;Pitch;LDA Model
猜你喜欢
陶瓷学报(2021年4期)2021-10-14
黄河之声(2021年10期)2021-09-18
乐府新声(2021年1期)2021-05-21
家庭影院技术(2021年1期)2021-03-19
少儿画王(3-6岁)(2020年4期)2020-09-13
天津音乐学院学报(2020年4期)2020-02-01
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
计算机应用(2018年8期)2018-10-16
人间(2015年8期)2016-01-09
