
基于词包和特征融合的目标识别算法
2017-07-24 17:38周治平李文慧周明珠
数据采集与处理 2017年3期
周治平 李文慧 周明珠
(江南大学物联网工程学院,无锡,214122)
基于词包和特征融合的目标识别算法
周治平 李文慧 周明珠
(江南大学物联网工程学院,无锡,214122)
针对现有词包模型对目标识别性能的不足,对特征提取、图像表示等方面进行改进以提高目标识别的准确率。首先,以密集提取关键点的方式取代SIFT关键点提取,减少了计算时间并最大程度地描述了图像底层信息。然后采用尺度不变特征变换(Scale-invariant feature transform,SIFT)描述符和统一模式的局部二值模式(Local binary pattern,LBP)描述符描述关键点周围的形状特征和纹理特征,引入K-Means聚类算法分别生成视觉词典,然后将局部描述符进行近似局部约束线性编码,并进行最大值特征汇聚。分别采用空间金字塔匹配生成具有空间信息的直方图,最后将金字塔直方图相串联,形成特征的图像级融合,并送入SVM进行分类识别。在公共数据库中进行实验,实验结果表明,本文所提方法能取得较高的目标识别准确率。
词包模型;目标识别;形状特征;纹理特征
引 言
目标识别[1]是计算机视觉领域中的研究热点之一。当运动目标被检测出来后,如何迅速和准确地得到目标属性以及由此识别出目标的物体种类信息是重要的研究方向。而运动目标往往受光照、视角和尺度变化等影响,使得目标识别任务仍然面临种种挑战。传统的目标识别方法是在图像中提取特征,然后直接通过分类器对特征向量进行分类来识别目标。宋丹等[2]针对方向梯度直方图(Histogram of oriented gradient, HOG)特征不具备仿射不变性,提出仿射梯度方向直方图特征与支持向量机(Support vector mochine,SVM)结合,有效抵抗了尺度变化、旋转变化和错切变化。Zhang B等[3]提取分层梯度直方图特征与Gabor特征,采用最近邻分类器、多层感知器、随机树和SVM设计出带有拒绝选项的两级集成分类。近年来,词包模型因其简单、有效的优点而在目标识别领域得到广泛应用。基本的词包模型包括SIFT特征提取、生成视觉词典以及分类器实现等。为了进一步提高词包模型的识别性能,研究者们对词包的实现过程进行了不同的变种和改进[4,5]。文献[6]提取目标的轮廓分段特征,然后编码建立词包进行识别,但此方法只在二值图像上取得较好的效果,在真实图像上因其很难准确提取目标的轮廓信息而识别效果一般。文献[7]与传统的自底向上的词包构建方式不同,提取图像的中层特征,并充分利用图像的局部和全局空间信息,获得比传统的词包模型更强的判别力。文献[8]采用超像素作为分类单元,给目标的每个部件分别建立1个局部分类器,这在一定程度上增加了算法的复杂性。李士进等[9]提出结合相关性及冗余度分析去除视觉码本中不相关或弱相关的视觉单词,减少了计算复杂度。文献[6~9]都是采用图像的单一特征,运动目标常常受到光照、噪声、尺度以及视角变化的影响。因此单一的特征提取往往不能应对图像的多种变化,因此有必要使用多个特征进行相互补充来描述运动目标。因此许多基于特征融合的词包模型方法被提出。如文献[10]将捕捉图像形状信息的尺度不变特征变换(Scale-invariant feature transform, SIFT)特征和描述图像纹理信息的局部二值模式(Local binary pattern,LBP)特征,分别通过网格级和图像级两种方法进行特征融合。刘帅等[11]提出分别提取图像的视觉词袋特征、颜色直方图特征以及Gabor纹理特征,最后采用支持向量机进行分类并进行自适应综合。但文献[10,11]中算子提取兴趣点的方式都是稀疏提取的方式,会丢失掉大量的有用信息。
针对上述问题,本文从两方面进行了研究。首先在关键点提取阶段,采用固定步长、固定尺度的密集提取方式代替传统的兴趣点提取,以获取更加丰富的信息。其次,考虑到不同的图像特征描述图像基本信息的方向不一样。复杂的运动目标也使得单一特征无法充分描述其信息,提出在关键点周围提取SIFT和统一模式的LBP特征,分别采用K-means算法进行聚类生成视觉词典。然后将局部描述符进行近似局部约束线性编码,进行最大值特征汇聚并利用金字塔匹配生成带有空间信息的直方图并进行串联,完成形状和纹理特征的图像级融合,最后送入SVM进行分类识别。
1 特征提取和视觉词典生成
1.1 Dense SIFT特征
Dense SIFT[12]特征是SIFT特征的一个变种,一经提出便被许多研究者使用。SIFT算法通常分为特征点提取和特征点描述两个步骤。在特征点提取阶段,其需要构建高斯差分尺度空间等,往往耗时较长,且其提取的关键点比较稀疏,往往丢失掉过多的有用信息。Dense SIFT采用密集提取的方法,采用固定步长,固定尺度提取大量的关键点。这样做虽然有更高的冗余度,但信息也变得丰富,再利用SIFT描述符描述关键点周围的形状特征能得到大量的局部描述特征,其最大程度地对图像底层进行描述,防止丢失过多有用信息。研究表明,将Dense SIFT与词包相结合能获得更好的性能[13]。Dense SIFT提取的具体步骤为:从左到右、从上到下依次遍历整幅图像。每一次都提取当前位置为左上角的固定大小的网格,本文根据Lowe等[14]提出SIFT描述子的原始文献将网格大小设置为16×16。网格中心为关键点,按照一定的步长(本文设为8)向右移动,到达图像右侧后向下移动一个步长,得到整幅图像的关键点,将提取到的关键点利用SIFT描述符进行描述。首先,将以关键点为中心的16×16的网格划分为 4×4个子区域。然后在每个子区域图像小块上计算 8 个方向的梯度方向直方图,绘制每个梯度方向的累加值,即可形成一个种子点。每个种子点梯度的模值和方向分别为
(1)
(2)
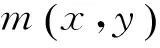
1.2LBP特征
LBP是一种用来描述图像局部纹理特征的算子,它具有旋转不变性和灰度不变性等显著优点。LBP算子是一个固定的3×3矩阵元,对应9个灰度值,将周边的8个像素灰度值与中心像素灰度值比较,大于或等于中心像素值的像素点置为1,否则置为0,按照逆时针或顺时针方向读取8个二进制值作为特征值,此后研究者对LBP算子进行扩充,以中心点为圆心,邻域大小为P,从以该点半径为R的区域提取特征,记作LBPP,R。其特征为
(3)
式中:gc为中心像素值;gi为邻域像素点像素值。研究者在LBP的基础上提出了统一模式,实验表明最本质的纹理信息表现出强大的判别能力[15]。统一模式的LBP仅仅考虑U不大于2的情况。其中,U表示统一性度量值,为LBP的二进制特征值被首尾相连为环形时0到1和1到0的跳变次数。共有58种LBP统一模式,但是可以表达将近90%的纹理特征,而其他所有非统一模式为1维特征,这样就可以大大地减少特征的维数。
1.3 特征融合
文献[11]表明SIFT特征和LBP特征相组合对于目标识别的可行性。文献[16]将SIFT算法与LBP算法相结合,用于人脸识别,在一定程度上也提高了识别的精度。所以图像中的目标特性可以由SIFT和LBP算法共同捕获。利用密集提取的方式获得关键点之后,在关键点周围分别利用SIFT和统一模式的LBP描述符描述,并对所得结果进行归一化处理。然后对于形状特征和纹理特征分别采用K-Means算法进行聚类,生成视觉词典,并利用空间金字塔匹配生成带有空间信息的直方图。最后将直方图串联,实现图像级的特征融合,并送入SVM进行分类识别。具体识别过程如图1所示。

图1 优化词包模型的目标识别过程Fig.1 Optimization process of bag of words
1.4 视觉词典生成
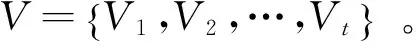
tLBP=ψtSIFT
(4)
式中:ts和tLBP分别为根据SIFT特征和LBP特征学习到的视觉词典大小。
2 特征编码和特征汇聚
在图像中利用密集提取方式获得的大量局部特征含有很多冗余和噪声。为提高特征表示的稳定性,需要将底层特征进行编码,与无监督聚类算法得到的视觉词典相联系,得到更具区分性、更加稳定的特征表达。本文采用现阶段较为优秀的局部线性编码,并利用其近似形式,提高编码速度。具体地,近似局部线性编码的数学表达式为
(5)
式中:X=[xi,x2,…,xN]为局部特征向量集,C=[c1,c2,…,cN]是局部特征向量集X的编码组,大小为t×N,每列代表每个局部特征向量在每个视觉单词上的响应值。将每个局部特征进行编码后,需要将编码后的特征集进行汇聚操作,从而形成图像内容的紧致特征表达。通过汇聚操作后的特征可以获得一定的特征不变性,同时也避免了利用整个编码特征集进行图像表达的高额计算代价。本文采用最大值汇聚方法,其数学表达式为
(6)
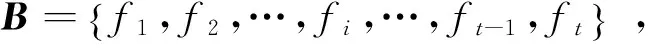
3 空间金子塔匹配
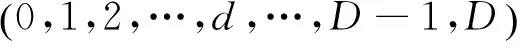
(7)
则在第d层对统计直方图进行匹配,其相似性度量为

图2 金字塔匹配原理Fig.2 Pyramid matching principle
(8)
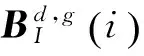
(9)
该核函数证明满足Mercer条件[18],可直接用于SVM分类。
4 实验结果及分析
4.1 实验数据库
本文在图像分类与识别领域中较为经典的数据库Caltech101和Caltech256中进行实验。图3为这两个数据库中的一些图像示例。Caltech101:该数据库中一共包含9 144幅图像,分为101个物体种类和一个背景干扰类。每类中的图像数从31~800幅不等。与其他数据库相比,Caltech101数据库具有较强的颜色与形状差异,目标物体居于图像中心,且占据图像大部分面积,但缺少不同的视角变化。Caltech256:该数据库可以看作Caltech101数据库的扩展,一共包含30 607幅图像,分为256个物体种类和一个背景干扰类。每一类中至少含有80幅图像。此数据库不仅在物体种类和每类的图像数量上大大超过Caltech101数据库,而且类内差距更加明显,类间变化更加复杂,加剧了目标分类和识别的难度。

图3 Caltech 101和Caltech 256数据库中的图像示例Fig.3 Image examples in Caltech 101 and Caltech 256
4.2 实验结果与分析
实验硬件采用I5-3210M,主频2.5GHz的处理器,8GB内存。软件平台使用Windows7操作系统,开发平台为MatlabR2012a。为了验证本文所提算法的有效性,分别在Caltech101和Caltech256两个数据库中进行验证。为了使实验具有说服性,分别从这两个数据库中随机选取10类来进行实验。这10类图像数据分别为:Caltech101:Airplanes,Car_Side,Ceiling_fan,Dragonfly,Euphonium,Motorbikes,Nautilus,Watch,Wheelchair,Windsor_chair。Caltech256:Bowling-ball,Canoe,Dog,Dolphin,Flashlight,Golf-ball,School-bus,Treadmill,Yo-yo,Zebra。为了验证识别准确率与单特征SIFT的视觉词典大小tS的关系,分别在上述Caltech101和Caltech256随机选取10类进行实验,利用15幅图像用于训练,30幅图像用于测试,假设将图像进行3层级的空间金字塔匹配。得到10类图像的平均识别率和视觉词典大小tS的关系,如图4所示。在图4中可以看出,上述分别在Caltech101和Caltech256随机选取的10类图像,它们的识别性能都有相似的变化趋势,即当视觉词典大小t开始增加时,平均识别率迅速增加,但当增加到一定值后继续增加,平均识别率就没有明显提高。这是因为当词典尺寸较小时,生成的视觉单词区分性不强,会导致不相似的特征映射到同一个视觉单词中。但当视觉词典大到某一数值以后继续增加,视觉单词的区分性变强了,但相似的特征可能会被映射至不同的视觉单词,使识别率上升不高甚至降低识别率。因此,视觉词典的设置并不是越大越好。从图4,5中还可以看出,从Caltech101随机选取的10类图像中,其词典大小上升至100后,其平均识别率就上升不明显或有所下降,而在Caltech256随机选取的10类图像中,其词典大小上升至200后,其平均识别率才上升不明显或有所下降,这是因为Caltech256比Caltech101数据库类内差距更加明显,类间变化更加复杂,因此需要比Caltech101设置更大的词典大小。所以,合适的视觉词典大小需要根据实验来决定,其与所要分类的图片的种类数、图片的类内类间差距等因素息息相关。根据图4,5中的结果,对于上述随机选取的10类图像中,Caltech101设置tS为100,Caltech 256设置tS为200。
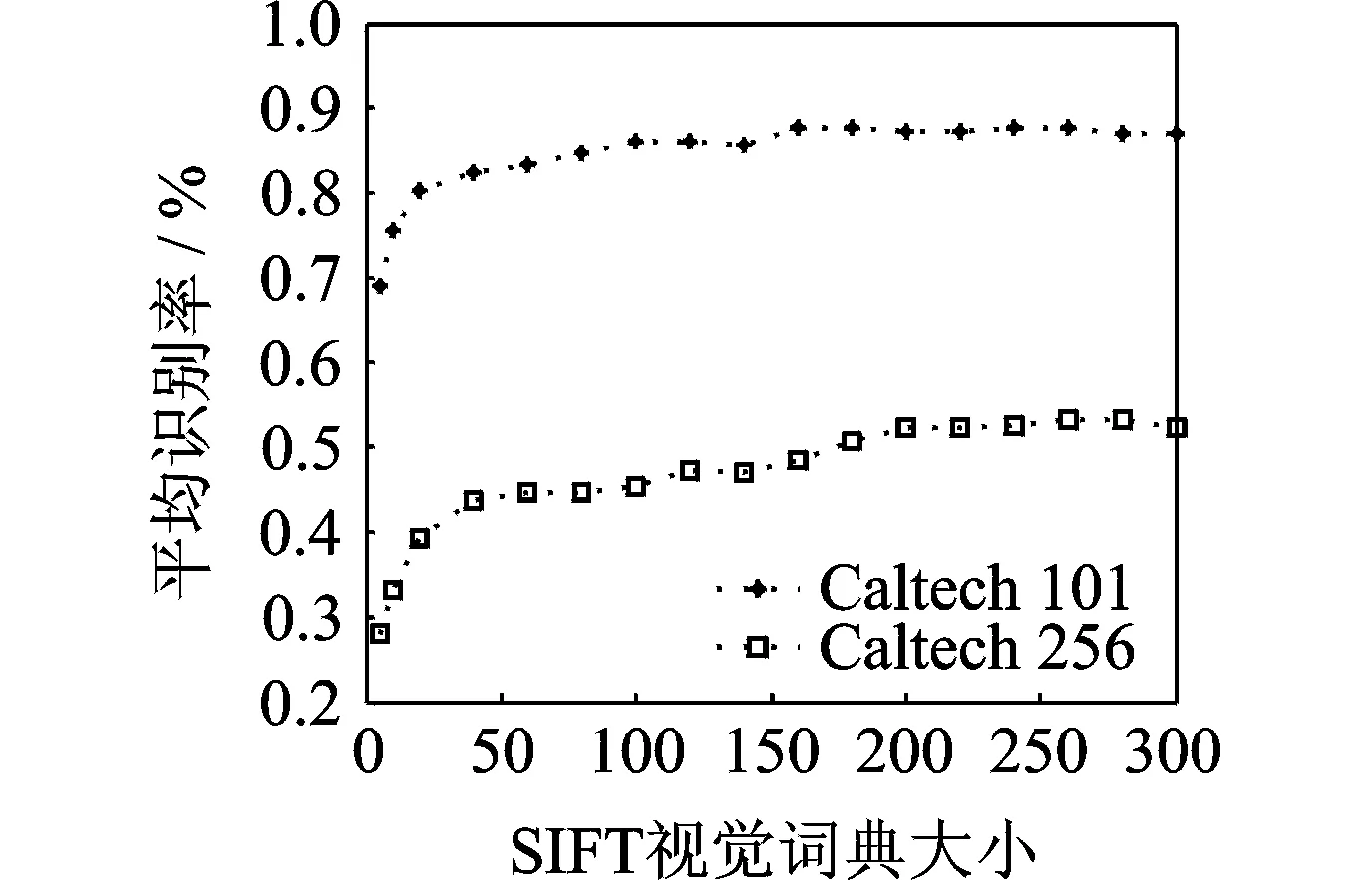
图4 目标平均识别率与单特征SIFT视觉词典大小的关系Fig.4 Relationship between object average recognition rate and size of visual dictionary of single feature SIFT
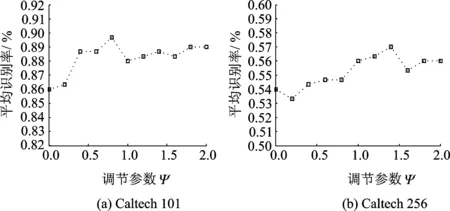
图5 目标平均识别率与调节参数ψ的关系Fig.5 Relationship between object average recognition rate and adjustable parameters
为了验证SIFT和LBP特征不同的组合方式对平均识别率的影响,在上述随机选取的图像中,设置不同的调节参数ψ,得到LBP特征不同的视觉词典大小,将图像中利用两个特征分别得到的3层级划分的金子塔匹配直方图进行串联。依旧利用15幅图像训练,30幅图像测试,假设将图像进行3层级的空间金字塔匹配。得到平均识别率与不同调节参数ψ的关系,如图5所示。 在图5中可以看出,通过选取不同的调节参数ψ可以调整融合特征中SIFT特征和LBP特征各自所占的比例,并且获得不同的平均识别率。通过实验,在上述随机选取的10类图像中,对于Caltech101,当ψ=0.8时,平均识别率最高,此时SIFT特征的平均识别率为86%,LBP特征的平均识别率为71.33%,融合SIFT特征和LBP特征得到的平均识别率为89.67%,比最高的单特征SIFT高出了3.67%。对于Caltech256,当ψ=1.4时,平均识别率最高,此时SIFT特征的平均识别率为54%,LBP特征的平均识别准确率为38.33%,融合SIFT特征和LBP特征得到的平均识别率为57%,比最高的单特征SIFT高出了3%。为了考察金子塔匹配原理对于图像级特征融合词包模型识别性能的影响,以及划分层数如何确定。在上述随机选取的子数据库中进行实验。训练图像数设为15,测试图像数设为30。当D=0时代表无金子塔划分。实验结果如表1所示。
表1 基于金字塔匹配原理的平均识别率
Tab.1 Average recognition rate based on pyramid matching
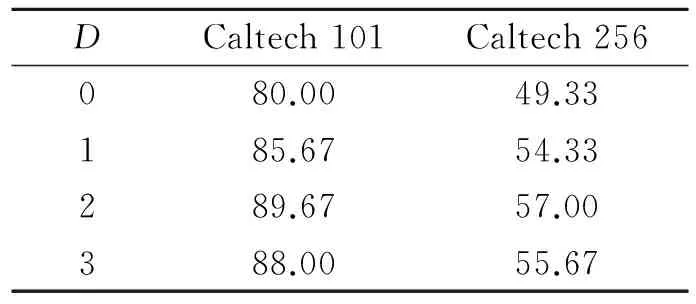
DCaltech101Caltech256080.0049.33185.6754.33289.6757.00388.0055.67
从表1中可以看出,当D=2即进行3层级划分时,Caltech101库和Caltech256库的平均识别率均达到最佳,相比较无金子塔划分,平均识别率分别提高了9.67%和7.67%,这充分说明了利用空间金子塔引入空间信息的必要性,同时金子塔划分的层数并非越多越好,过多的金子塔划分反而会使特征失去描述能力,降低识别率。为了验证本文所提算法的优越性,将整个数据库的实验结果与其他现有算法进行比较。根据多次实验,在整个Caltech101数据库中,将tS设置为1 050,tLBP设为840较为合适。将每一类的训练图像数分别设为15和30,然后利用训练好的模型预测剩下的图像。在整个Caltech 256数据库中,将tS设置为2 100,tLBP设为2 940较为合适,将每一类的训练图像数分别设为30和60,然后利用训练好的模型预测剩下的图像。对比结果如表2所示。从表2可以看出,所有方法在Caltech256数据库中所获得的识别性能远远小于Caltech101数据库中的整体识别率,这是因为后者目标的类内变化,视角变化等更剧烈,使识别任务的实现变得更加困难。对于这两个分类难度具有差异的数据库,本文所提的方法都具有一定的优势,在文献[4,5]中都只利用了形状特征,在文献[11]中虽然使用了SIFT和LBP特征,但是没有引入空间金字塔匹配原理,在一定程度上没有使得识别率达到最优。本文所提方法在Caltech101数据库中当训练图像数为30时,整体识别率最高能达到77.33%,对于在Caltech256数据库中,当训练图像数为60时,整体识别率达到50.98%。由此可见,本文方法达到了较为理想的识别效果。为了进一步验证本文所提方法的有效性,在Graz-02数据库,MSRcv2物体数据集,PASCAL2007数据集上进行对比实验,分别得到其整体识别率。实验结果如表3所示。从表3可以看出,由于各数据集分类识别难度不同,因此获得的整体识别率也存在较大差异。但是本文算法相比较其他算法都取得了最优性能。
表2 本文方法与现有方法整体识别率的比较
Tab.2 Overall recognition rate comparison of proposed method with existing methods
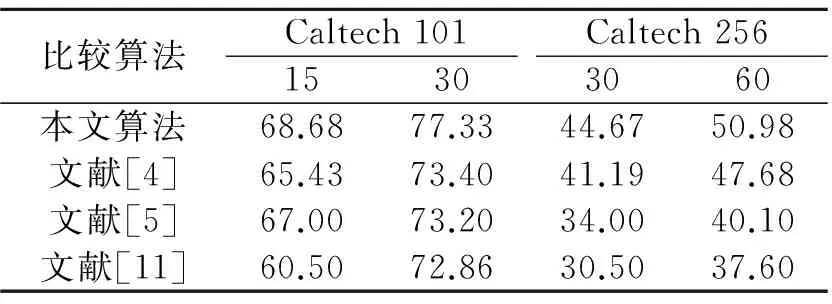
%
表3 算法性能比较
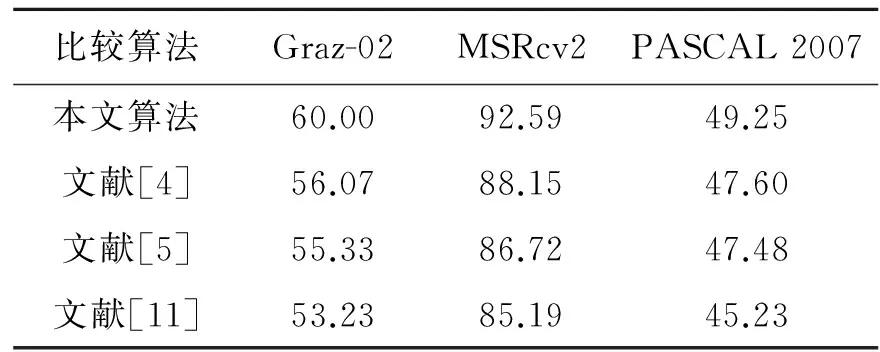
Tab.3 Performances comparison of algorithms %
5 结束语
本文分析了影响词包模型识别性能的主要因素,在特征提取与图像表示等方面对传统的词包模型进行优化。利用密集提取关键点的方式获得丰富的图像信息,并且利用形状特征和纹理特征分别描述目标的不同特性。引入K-Means聚类算法分别生成视觉词典,然后将局部描述符进行近似局部约束线性编码,并进行最大值特征汇聚,采用空间金字塔匹配生成带有空间信息的直方图最后送入SVM分类。与当前的几种流行算法比较,此方法在Caltech,MSRcv2等多个数据集上都表现出了良好的性能,比单一特征获得了更好的分类精度,将更好地应用在智能视频监控、车辆辅助驾驶等领域。近年来,目标识别技术越来越多地应用在实际生活中,在提高识别精度的同时减少算法的运行时间是今后研究的方向之一。
[1] Andreopoulos A, Tsotsos J K. 50 years of object recognition: Directions forward[J]. Computer Vision and Image Understanding,2013,117(8):827-891.
[2] 宋丹, 唐林波, 赵保军. 基于仿射梯度方向直方图特征的目标识别算法[J]. 电子与信息学报,2013,35(6):1428-1434.
Song Dan, Tang Linbo, Zhao Baojun. The object recognition algorithm based on affine histogram of oriented gradient[J]. Journal of Electronics & Information Technology, 2013, 35(6): 1428-1434.
[3] Zhang B. Reliable classification of vehicle types based on cascade classifier ensembles[J]. Intelligent Transportation Systems, IEEE Transactions on, 2013, 14(1): 322-332.
[4] Wang J, Yang J, Yu K, et al. Locality-constrained linear coding for image classification [C] //Proceedings of the 23rd International Conference on Computer Vision and Pattern Recognition. San Francisco, USA:IEEE Computer Society,2010: 3360-3367.
[5] Yang J, Yu K, Gong Y, et al. Linear spatial pyramid matching using sparse coding for image classification [C] // Proceedings of the International Conference on Computer Vision and Pattern Recognition. Miami, USA: IEEE Computer Society, 2009:1794-1801.
[6] Wang X, Feng B, Bai X, et al. Bag of contour fragments for robust shape classification[J]. Pattern Recognition,2014,47(6):2116-2125.
[7] Fernando B, Fromont E, Tuytelaars T. Mining mid-level features for image classification[J]. International Journal of Computer Vision,2014,108(3):186-203.
[8] Lu H, Feng X, Li X, et al. Superpixel level object recognition under local learning framework [J]. Neurocomputing,2013,120:203-213.
[9] 李士进,仇建斌,於慧. 基于视觉单词选择的高分辨率遥感图像飞机目标检测[J]. 数据采集与处理,2014,29(1):60-65.
Li Shijin, Qiu Jianbin, Yu Hui. Aircraft detection in high resolution remote sensing imagery based on visual words selection[J].Journal of Data Acquisition and Processing, 2014,29(1):60-65.
[10]Yu J, Qin Z, Wan T, et al. Feature integration analysis of bag-of-features model for image retrieval[J]. Neurocomputing, 2013,120(23):355-364.
[11]刘帅,李士进,冯钧. 多特征融合的遥感图像分类[J]. 数据采集与处理,2014,29(1):108-115.
Liu Shuai, Li Shijin, Feng Jun. Remote sensing image classification based on adaptive fusion of multiple features[J]. Journal of Data Acquisition and Processing, 2014,29(1):108-115.
[12]Li F F, Pietro P. A bayesian hierarchical model for learning natural scene categories[C]// Proceedings of the International Conference on Computer Vision and Pattern Recognition.[S.l.]:IEEE,2005:524-531.
[13]赵理君, 唐娉, 霍连志, 等. 图像场景分类中视觉词包模型方法综述[J]. 中国图象图形学报,2014,19(3):333-343.
Zhao Lijun, Tang Ping, Huo Lianzhi, et al. Review of the bag-of-visual-words models in image scene classification[J].Journal of Image and Graphics,2014,19(3):333-343.
[14]Lowe D G. Object recognition from local scale-invariant features[C]// Proceedings of the Seventh International Conference on Computer Vision.Kerkyra:IEEE,1999:1150-1157.
[15]Ojala T, Pietikainen M, Maenpaa T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2002,24(7):971-987.
[16]Yang H M, Sun J G. An improved face recognition algorithm based on SIFT and LBP[J]. Applied Mechanics and Materials,2013,427:1999-2004.
[17]赵春晖, 王莹. 一种基于词袋模型的图像优化分类方法[J]. 电子与信息学报,2012,34(9):2064-2070.
Zhao Chunhui, Wang Ying. An optimized method for image classification based on bag of words model[J]. Journal of Electronics & Information Technology,2012,34(9):2064-2070.
[18]Grauman K, Darrell T. The pyramid match kernel:Discriminative classification with sets of image features [C]//Proceedings of the International Conference on Computer Vision.Beijing, China: IEEE, 2005:1458-1465.
For the deficiency of the existing words bag in object recognition. We improve the feature extraction and image representation etc to enhance the accuracy. Firstly, a fixed step size is used and scale-intensive is fixed to extract key points, and then the scale-invariant feature transform (SIFT) and local binry pattern(LBP) around the key points in the grids are extracted to describe the shape features and texture features. K-Means clustering algorithm is introduced to generate a visual dictionary and the local descriptors are encoded by approximated locality constrained linear coding, and max pooling and a histograms are generated using spatial pyramid matching. Both the spatial pyramid histograms are connected,therefore, the feature fusion in the image level is implemented under the words bag. Finally the fusion result is sent to the SVM for classification. Experimental result in public datasets shows that the proposed method can achieve higher recognition accuracy.
bag of words; object recognition; shape features; texture features
江苏省自然科学基金(BK20131107)资助项目。
2015-05-19;
2015-06-11
TP391
A

周治平(1962-),男,博士,教授,研究方向:智能检测、自动化装置和信息安全等,E-mail:zzp@jiangnan.edu.cn。

李文慧(1990-),女,硕士研究生,研究方向:视频与图像信号分析处理。

周明珠(1988-),女,硕士研究生,研究方向:检测技术与自动化装置。
Object Recognition Algorithm Based on Bag of Words and Feature Fusion
Zhou Zhiping, Li Wenhui, Zhou Mingzhu
(School of Internet of Things Engineering, Jiangnan University, Wuxi, 214122, China)
猜你喜欢
湘潭大学自然科学学报(2022年2期)2022-07-28
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
摄影之友(影像视觉)(2018年12期)2019-01-28
中国交通信息化(2018年3期)2018-06-13
初中生世界·八年级(2017年3期)2017-03-24
中国交通信息化(2016年2期)2016-06-06
潍坊学院学报(2016年6期)2016-04-18
