
一种在线字典学习的高光谱图像盲解混方法
2017-07-21 10:04宋晓瑞赵忠文
装备学院学报 2017年3期
宋晓瑞, 赵忠文, 于 尧
(1. 装备学院 研究生管理大队, 北京 101416; 2. 装备学院 复杂电子系统仿真实验室, 北京 101416)
一种在线字典学习的高光谱图像盲解混方法
宋晓瑞1, 赵忠文2, 于 尧1
(1. 装备学院 研究生管理大队, 北京 101416; 2. 装备学院 复杂电子系统仿真实验室, 北京 101416)
针对待处理高光谱图像中所含地物光谱未知的情况,将在线字典学习的方法引入高光谱稀疏解混中,提出了一种基于在线字典学习和稀疏编码的高光谱图像盲解混方法。通过在线字典学习以及对稀疏编码的统计,从训练字典中筛选出与未知地物光谱最为接近的原子,作为待处理数据所含地物光谱的估计。仿真结果表明:这种方法的准确提取概率超过66%,有效提取概率超过89%,对地物光谱识别等相关研究有一定借鉴意义;另外,利用训练字典和稀疏编码可较好的重构混合像素光谱向量。
高光谱遥感;在线字典学习;稀疏编码;地物光谱提取;稀疏解混
光学遥感作为现代战场环境感知的重要技术手段,其技术发展进程是光谱分辨率不断提高的过程,历经全色(黑白)(panchronmatic)、彩色摄像(color photography)、多光谱(multispectral)扫描成像,至今已发展到高光谱分辨率遥感(hyperspectral remote sensing)阶段。高光谱分辨率遥感,也称高光谱遥感,是指用很窄(10-2λ)而连续的光谱通道对地物持续遥感成像的技术[1]。高光谱遥感在可见光到短波红外波段的光谱分辨率高达纳米(nm)数量级,通常具有波段多的特点,光谱通道数多达数十甚至数百个以上,且各光谱通道间往往是连续的。因此,高光谱遥感又被称为成像光谱(imagingspectrometry)遥感,其在成像的同时记录下上百个光谱通道数据,且从每个像素均可提取一条连续的光谱曲线。图谱合一、光谱连续的特点,使得高光谱遥感图像在军事伪装探测和战场环境背景探测等方面有重要应用。
高光谱图像的光谱分辨率虽然很高,但每个像素所对应的地物目标空间分辨率却较低。由于空间分辨率不足,以及实际地物分布复杂多样等因素的影响,混合像素普遍存在于高光谱遥感图像中。混合像素的出现严重制约了高光谱图像处理精度的提升,成为阻碍高光谱遥感技术发展的重要因素。针对这一问题提出的混合像素分解技术,已成为高光谱遥感图像处理领域的一大研究热点。
随着压缩感知和稀疏表示理论的不断发展成熟,稀疏表示的思想也被引入到高光谱解混中。2009年,Iordache与Bioucas-Dias等[2]用光谱库代替线性光谱混合模型中的端元集合,提出了基于稀疏表示的线性光谱混合模型。2011年,Bioucas-Dias等[3]1提出了SUnSAL(SparseUnmixingbyvariableSplittingandAugmentedLagrangian)算法,该算法利用交替迭代思想,通过变量分裂和增广拉格朗日乘数法求解l1-范数下丰度系数的稀疏解。在此基础上,又有学者陆续提出了SUnSAL-TV[4]、正交匹配追踪[5](OrthogonalMatchingPursuit,OMP)以及SMP[6](SubspaceMatchingPursuit)等多种稀疏解混算法。文献[7]中提出了一种基于反正切平滑的l0-范数稀疏解混算法,更好地解决了稀疏解混的NP(Non-deterministicPolynomial)难问题。文献[8]提出了一种应用丰度矩阵加权核范数的低秩本地正则化稀疏解混算法,进一步提高了丰度系数的估计精度。
上述算法的基本思想为求解混合像素在过完备光谱库下的稀疏表示,其特点为均要求过完备光谱库已知。由于自然界地物光谱的复杂多样性,通常存在某些甚至全部地物光谱未知的情况,在这种情况下如何进行混合像素解混以及地物光谱提取,具有十分重要的应用价值。
针对这一实际情况,本文将在线字典学习的方法引入到高光谱图像稀疏解混问题中,提出一种基于在线字典学习与稀疏编码的高光谱遥感图像盲解混算法,其优势在于利用稀疏编码在光谱解混中的优良性能的同时,无须光谱先验知识。该算法以高光谱遥感图像为训练集,通过在线学习的方法得到冗余字典,利用该冗余字典求解混合像素稀疏编码,即丰度系数向量,最后利用统计方法得到未知地物光谱。因此,利用本文所提算法进行高光谱解混,除待处理图像外,不再需要其他输入。
1 基于稀疏表示的线性光谱混合模型
光谱混合从本质上可分为线性光谱混合(LinearSpectralMixtureModel,LSMM)和非线性光谱混合(NonlinearSpectralMixtureModel,NLSMM),多数情况下非线性光谱混合可通过线性化转化为线性光谱混合。因此,线性光谱混合模型目前被大多数光谱解混算法采用。本文中所采用的光谱混合模型为线性光谱混合模型。
基于稀疏表示的混合像素分解算法是通过引入一个有效的过完备光谱库,将混合像素光谱曲线表示成光谱库中某几种地物光谱的线性组合,如图1所示。其模型为[9]
x=Dα+n
(1)
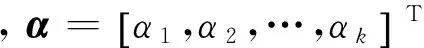
需要强调的是,考虑到模型的物理意义,丰度系数向量α应满足非负及和为1的约束条件,即
(2)
0≤αi≤1
(3)

图1 过完备光谱库下混合像素的线性表示
由于α稀疏,式(1)可等价为l0范数最小化问题,即
(4)
式中,δ为一个极小常量。
基于稀疏表示的高光谱解混算法,基本思想可简单理解为对多维数据的线性分解。因此,目前所研究的稀疏解混问题可等价为在已知过完备光谱库的情况下,寻找方程最简单的解。
2 基于在线字典学习与稀疏编码的盲解混方法
从上一节对基于稀疏表示的线性光谱混合模型的讨论中可知,得到稀疏编码,即丰度系数向量的前提是用于光谱向量系数表示的过完备光谱字典D∈RL×k已知。当遥感图像中存在未知地物光谱时,过完备光谱字典D显然部分或全部未知。因此,需要先求得一个较好的字典,才能够进行稀疏解混,得到各像素中端元丰度系数,并通过统计方法得到未知地物光谱曲线以用于进一步的研究,如地物识别等。
本文将一种适用于大数据集的基于随机近似(stochasticapproximations)的在线字典学习优化算法引入高光谱稀疏解混中,可以使光谱字典学习速度大大提高,并有效地处理大规模训练数据。利用高光谱遥感图像中的部分混合像素光谱向量为训练集,通过本文提出的光谱字典在线学习算法,求得用于稀疏解混的过完备光谱字典D。
利用在线学习得到的过完备光谱字典D,对遥感图像中混合像素进行稀疏解混,得到稀疏编码α。最后通过对稀疏编码α进行统计分析,提取出未知地物光谱。
2.1 光谱字典在线学习算法
在给定混合像素光谱向量集合的条件下,字典学习的目标是找到一个冗余光谱字典,能够运用较少数目的原子表示这些光谱向量。其数学描述如下:
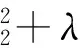
(5)
式中:Np为训练集中混合像素数目;l1-范数项诱导稀疏编码,二次项为误差,二者权值由正则化参数λ(正值)确定。
由于字典D和稀疏解α的联合优化问题属于非凸问题,而当固定式(5)中D和αi的其中一个时,问题将转化为凸问题。解决这个问题较为便捷的方案是轮流固定D和αi,即交互地对D和αi进行最优化求解。
对αi求最优化是一个BPDN(BasisPursuitDe-Noising)问题,文献[10]中利用最小角度回归算法(LeastAngleRegression,LARS)求解。但由于αi的物理意义中要求满足非负与和为1的约束条件,本文利用文献[3]3提出的变量分解和增广拉格朗日稀疏回归方法(SUnSAL)解决该BPDN的最优化问题。
对字典D进行最优化求解,相当于最小化下面的问题。
(6)

图2 光谱字典在线学习算法流程图
式中:t为当前迭代次数;xj为从原始训练集中随机获取的j个混合像素光谱向量组成的当前训练集合。本文中对式(6)进行最小化时,采用投影块坐标下降算法对字典进行列更新。
通过对在线字典学习原理的分析,可以得到光谱字典在线学习算法流程,如图2所示。首先,从原始遥感图像中选取若干个混合像素光谱向量作为原始训练集;然后,从原始训练集中随机选取一系列混合像素光谱向量作为当前循环中所使用的训练集,并按照一定顺序根据该当前训练集进行字典学习。对于当前训练集中的每一个新元素,先通过求解BPDN问题计算稀疏编码,然后对字典进行更新。
值得注意的是,该算法对初始化字典并不过分依赖,通常选取原始训练集中k个混合像素光谱向量作为初始化字典。
2.2 稀疏解混算法
通过2.1节中在线字典学习的方法训练得到过完备光谱字典后,可以对遥感图像混合像素光谱向量进行稀疏编码。由于训练得到的字典D是冗余的,且各类干扰的存在使得式(4)中δ>0。此时,式(4)所描述的最优化问题是NP难问题[11],不能够直接求解。为解决这一问题,可将l0-范数进行松弛化处理,利用l1-范数进行近似。因为J(x)=‖x‖1是凸的,所以可求得最优解[12]。近似后的问题被称为LASSO(LeastAbsoluteShrinkageandSelectionOperator)问题[13],与BPDN问题是等价的。
由于稀疏编码α的物理意义为丰度系数,需满足非负与和为1的约束条件,且其求解问题与BPDN问题等价,因此,可同样应用SUnSAL算法求解。需要特别强调的是,虽然在线字典学习与求解稀疏编码中均应用了这一算法,但2次应用中算法关键参数,如正则化参数λ等,在设置上有很大不同,必须根据问题的不同设置合适的参数。
2.3 地物光谱提取
得到遥感图像混合像素光谱向量的稀疏编码α之后,通过对其进行统计分析,可在训练得到的过完备光谱字典D中提取到遥感图像中未知地物光谱曲线。其原理是:由于α的稀疏性,其大多数元素为0,不为0元素的坐标是所选择的用线性表示混合像素光谱曲线的最优原子。当α的样本足够大时,统计被选择次数最多的若干个字典原子,可认为这些原子所代表的是遥感图像中未知地物光谱曲线。

(7)
式中:τi为被选择次数第i多的原子的被选择次数;φ为设定的阈值。阈值的选取通常与待处理高光谱遥感图像有关。
需要说明的是,采用这种统计算法提取得到的地物光谱曲线并不一定与真实地物光谱完全一致,其误差大小很大程度上取决于字典训练的“好坏”程度。
3 仿真实验
为验证算法性能,仿真实验中所使用的待处理数据为人工生成的模拟混合像素光谱向量,设为x。由于仅涉及光谱数据处理,因此模拟数据中不考虑空间维情况。
首先,从USGS(UnitedStatesGeologicalSurvey)矿物光谱库中任意选取9种物质的光谱(光谱波段数L=224),作为生成模拟数据的真实地物光谱,如表1所示。

表1 模拟数据所选取的地物
假设每个混合像素均由2个真实地物光谱以任意丰度系数混合而成,丰度系数满足非负且和为1的约束条件。模拟数据x中共包含10 000个混合像素光谱向量。
3.1 在线字典学习与稀疏解混
采用模拟数据x中的Np个数据作为原始训练集,将光谱字典在线学习算法的参数设置如表2所示。
另外,光谱字典在线学习算法停止条件为:迭代次数达到200次。
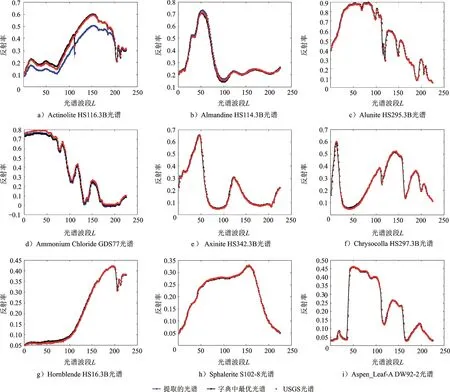
图4 提取地物光谱曲线、字典最优原子与真实光谱曲线的比较
完成参数设置及停止条件设置后,将原始训练集作为算法输入,按照本文所提出的光谱字典在线学习算法求解训练字典,其算法流程如图2所示。

求得稀疏编码α后,可利用训练字典D和稀疏编码α重构模拟混合像素光谱向量,其与原数据之间的误差如图3所示。

图3 重构混合像素光谱向量与模拟数据误差示意图
从图3中可看出,重构的模拟混合像素光谱向量与原数据之间误差较小,验证了在线字典学习与稀疏解混算法的正确有效。
3.2 地物光谱提取
设阈值φ=1/3,通过式(7)解得Na=9,与生成模拟数据时所使用的矿物光谱数一致,验证了统计算法的有效。将被选择次数最多的9个字典原子,即提取到的地物光谱曲线,与真实光谱曲线进行比较,如图4所示。
从图4可看到,9个提取到的地物光谱中有6个和字典中最接近USGS真实光谱的原子完全重合,这说明了2个问题:(1)通过在线学习得到的字典D中包含与未知地物光谱近似一致(如图4i))的原子;(2)通过2.3节中地物光谱提取方法可有效提取到字典中的最优原子。图4a)、4b)、4e)中,提取到的地物光谱与USGS真实光谱之间存在不同程度的偏差,其原因是:训练得到的字典D中无法找到与上述3个真实光谱近似一致的原子,导致稀疏编码在选择原子时无法找到字典中最优原子光谱,因此无法通过统计方法有效提取到真实光谱对应的字典中最优原子。即便如此,图4a)、4b)、4e)中,提取到的地物光谱在光谱特征上与USGS真实光谱之间仍高度相似,对地物识别等相关研究也有一定帮助。
为定量评价待处理高光谱数据中地物光谱提取效果,计算字典中最优原子光谱和提取地物光谱与USGS真实光谱之间的均方根误差,分别为Eatom和Esta,如表3所示。

表3 最优原子光谱和提取光谱与真实光谱之间的均方根误差
从表3中可看到,图4所示完全重合的6条光谱的2个均方根误差值相同,进一步说明通过本文算法提取到了真实光谱所对应字典中的最优原子,且其均方根误差值均小于0.01,与真实光谱近似一致。而图3所示存在偏差的3条光谱,其Esta均大于Eatom,说明未能提取到真实光谱所对应字典中的最优原子,而较大的Eatom值则说明了训练得到的字典中难以找到与真实光谱近似一致的原子。虽然如此,3条光谱的Esta值仍较小,也与图3中光谱特征高度一致的特点相对应。
综上所述,从仿真实验结果看:在线字典学习可得到较好的字典,其中包含与真实地物光谱近似一致及特征高度相像的原子;提取得到的未知地物光谱与真实光谱之间误差较小,其中准确提取的概率可超过66%,有效提取的概率达到89%,验证了本文算法的正确性和有效性。
4 结 束 语
本文提出了一种基于在线字典学习和稀疏编码的高光谱图像盲解混方法,在待处理高光谱图像中所含地物光谱未知的情况下,无须其他先验知识,利用待处理图像作为训练集,通过在线学习得到较好的光谱字典,进而有效估计了未知地物光谱曲线,并得到较好的稀疏解混效果,为地物光谱识别等相关研究提供帮助。但如何实现已知部分地物光谱条件下效果更优的地物光谱提取及稀疏解混等问题,仍有待进一步解决。
References)
[1]童庆禧,张兵,郑兰芬.高光谱遥感:原理、技术与应用[M].北京:高等教育出版社,2006:38-39.
[2]IORDACHE M D,BIOUCAS-DIAS J M,PLAZA A.Sparse unmixing of hyperspectral data[J].IEEE Transactions on Geoscience & Remote Sensing,2011,49(6):2014-2039.
[3]BIOUCAS-DIAS J M,FIGUEIREDO M A T.Alternating direction algorithms for constrained sparse regression: Application to hyperspectral unmixing[C]//Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS),2010 2nd Workshop on.IEEE.Reykjavik:IEEE,2010: 1-4.
[4]IORDACHE M D,BIOUCAS-DIAS J M,PLAZA A.Total variation spatial regularization for sparse hyperspectral unmixing[J].IEEE Transactions on Geoscience & Remote Sensing,2012,50(11):4484-4502.
[5]BRO R,DE JONG S.A fast non‐negativity‐constrained least squares algorithm[J].Journal of Chemometrics,1997,11(5):393-401.
[6]SHI Z,TANG W,DUREN Z,et al.Subspace matching pursuit for sparse unmixing of hyperspectral data[J].IEEE Transactions on Geoscience & Remote Sensing,2014,52(6):3256-3274.
[7]SALEHANI Y E,GAZOR S,KIM I M,et al.l0-norm sparse hyperspectral unmixing using arctan smoothing[J].Remote Sensing,2016,8(3):187.
[8]RIZKINIA M,OKUDA M.Local abundance regularization for hyperspectral sparse unmixing[C]// Signal and Information Processing Association Summit and Conference.Jeju:IEEE,2017:1-6.
[9]赵春晖,王立国,齐滨.高光谱遥感图像处理方法及应用[M].北京:电子工业出版社,2016:83-91.
[10]MAIRAL J,BACH F,PONCE J,et al.Online dictionary learning for sparse coding[C]// International Conference on Machine Learning,ICML 2009.Montreal:DBLP,2009:689-696.
[11]NATARAJAN K.Sparse approximate solutions to linear systems[J].SIAM Journal on Computing,1995(24):227-234.
[12]ELAD M.Sparse and redundant representations: from theory to applications in signal and image processing[M].New York:Springer Publishing Company,Incorporated,2010:16-19.
[13]郝红星.基于干涉相位图像构建数字高程模型的关键技术研究[D].长沙:国防科学技术大学,2014:69-70.
(编辑:李江涛)
Blind Unmixing of Hyperspectral Images Based on Online Dictionary Learning
SONG Xiaorui1, ZHAO Zhongwen2, YU Yao1
(1. Department of Graduate Management, Equipment Academy, Beijing 101416, China; 2. Science and Technology on Complex Electronic System Simulation Laboratory, Equipment Academy, Beijing 101416, China)
In view of the unknown condition of the surface feature spectra in the hyperspectral images to be processed, with the introduction of an online dictionary learning into the hyperspectral sparse unmixing, this paper proposes a method of blind hyperspectral unmixing based on online dictionary learning and sparse coding. Atoms which are closest to the unknown surface feature spectra are selected from the training dictionary via the online dictionary learning and sparse coding statistics. They are used to estimate the surface feature spectra in the data to be processed. The simulation results show that the accurate extraction probability of this method is more than 66%, and the effective extraction probability is more than 89%. It can be used for reference in the research of spectral identification of ground objects. In addition, the training dictionary and sparse coding can be used to reconstruct the mixed pixel spectral vectors. Therefore, this method also works well in sparse unmixing.
hyperspectral remote sensing; online dictionary learning; sparse coding; surface feature spectrum extraction; sparse unmixing
2017-04-17
部委级资助项目
宋晓瑞(1990—),女,博士研究生,主要研究方向为高光谱遥感。sxrjmx@163.com
TP751
2095-3828(2017)03-0021-06
A DOI 10.3783/j.issn.2095-3828.2017.03.004
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
黑龙江大学自然科学学报(2022年1期)2022-03-29
小学生学习指导(中年级)(2021年12期)2021-12-30
空间科学学报(2021年1期)2021-05-22
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
小学阅读指南·低年级版(2019年11期)2019-07-01
疯狂英语·新读写(2018年3期)2018-11-29
小天使·一年级语数英综合(2017年11期)2017-12-05
读者(2016年14期)2016-06-29
