
基于因子分析的财务预警模型构建
2017-07-05 13:07:23孟晓俊
杭州电子科技大学学报(社会科学版) 2017年3期
孟晓俊,宋 楠
(1.杭州电子科技大学 会计学院,浙江 杭州 310018;2.杭州电子科技大学 卓越学院,浙江 杭州 310018)
基于因子分析的财务预警模型构建
孟晓俊1,宋 楠2
(1.杭州电子科技大学 会计学院,浙江 杭州 310018;2.杭州电子科技大学 卓越学院,浙江 杭州 310018)
笔者提出了基于因子分析的财务预警建模方法,该种方法不仅实现指标的降维,而且能对公共因子的经济意义进行解释。通过对制造业企业的实证研究,本文构建了财务预警模型,并能够从六个维度对企业财务危机的产生原因进行分析,进而利于企业制定应对措施。此外,对于不同的主体,误拒与误受两类误判的代价差异较大,但大部分研究都忽略了这一点。因此笔者在模型中引入了误判代价,并对误判代价进行稳健性分析,也为进一步的财务预警研究提供新思路。
财务预警;因子分析;指标降维;误判代价
2014年底财政部制定发布了《关于全面推进管理会计体系建设的指导意见》,提出管理会计的建设目标,要求加强管理会计工具方法的研究。财务预警模型就是一种现代化企业管理的重要工具。
目前财务预警模型经过几十年的发展,建模的方法已多达十余种。实际应用较为广泛的模型有单变量模型、多元判定模型、Logistic回归模型、单位概率模型等。大部分建模方法都是以财务指标为基础,因此也受到了一些质疑。这些质疑主要围绕模型无法量化行业环境因素或企业管理者的作用。近年,也有学者试图在模型中加入此类虚拟变量,如张建华(2009)[1]在其模型中引入非财务指标;吴星泽(2011)[2]提出嵌入利益相关者的作用的模型。但实际上大部分无法加入虚拟变量的模型仍有良好的预警能力,反倒是加入虚拟变量的模型会导致模型复杂度提高,参数估计不精确,预警能力也未见提高。两权相害取其轻,预警能力才是核心,不能因为模型不够全面而不计成本地加入虚拟变量。
当然,目前的财务预警模型仍存在一些问题。张友棠(2011)[3]指出预警模型仅能对企业是否会出现财务危机进行预测,却无法诠释引起危机的原因,因而无法帮助企业进行有效应对。陈静(1999)[4]在研究的局限中提到其模型忽略了误判代价,将“误拒”和“误受”两类错误同等看待。但遗憾的是至今大部分研究仍未进行改进,沿用误判概率最小原则而忽略误判代价。此外,建模过程存在一些通病,如指标体系选取不合理,样本选取不严格,大部分研究也未对模型进行稳健性分析。根据以上问题,本文提出了利用因子分析重构财务预警模型的方法,为更深入的财务危机预警研究提供参考。
一、财务预警模型存在的问题及解决方案
财务危机预警模型中主要存在以下四个问题:无法诠释引起财务危机的根源、忽略误判代价、指标体系不合理、建模样本不合理,下文将对这四个问题进行具体的阐述,并提出相应的解决方案。
(一)存在的问题
1.无法诠释引起财务危机的根源
张友棠(2011)在其研究中也指出类似的问题。大部分模型根据统计方法都能够对企业未来的财务状况进行总体上的评价,如多元判别模型会给出企业的总体情况。但在实际应用中,这类模型无法找到财务危机发生的原因,因而不利于企业制定应对措施,这使得财务预警模型的功效大打折扣。
2.忽略误判代价
在模型的判别中会出现两类误判情况:Ⅰ类误判是将“公司一年后会出现财务危机”误判为“公司一年后不出现财务危机”;Ⅱ类误判是将“公司一年后不出现财务危机”误判为“公司一年后会出现财务危机”。陈静(1999)认为针对企业外部的投资者,Ⅰ类误判代价较高,因为他们可能因此遭受投资损失;针对企业来说,Ⅱ类误判代价较高,因为供应商、银行等机构产生不必要的戒备状态而导致企业受损。不同使用主体对误判代价的选择有显著的差异,但至今大部分研究仍忽略误判代价,沿用误判概率最小原则,这也使得财务预警模型的适用范围大大降低。
3.指标体系不合理
指标体系的不合理表现在两方面,一是指标选择的主观成分较大,二是指标数量过多。大部分的指标体系要么是依据专家评判法构建的,要么是主观地改进Beaver(1966)[5]与Altman(1968)等[6]学者率先引入的财务预警指标体系。以上这两种方法均存在较大的主观成分。此外,为了使得预警体系全面,模型会尽可能多地添加相关指标。但是大量的指标不仅有可能会导致多重共线性问题,而且会增加财务预警体系的复杂度。如秦志敏(2012)[7]在研究中选择了30个指标对企业进行全方位的评价,但同时也牺牲了模型的简洁性。并且其指标体系中同时包括了流动比率、速动比率、现金比率这三个指标,实际上对于同行业的企业来说,这三个指标极有可能呈强相关关系,这最终可能会导致模型参数估计不准,进而影响预警精度。
4.建模样本不合理
在建模过程中样本起到基础作用,所以样本的选择至关重要。大部分研究都以ST(或*ST)样本代表出现财务危机的公司,以非ST样本代表财务状况良好的公司。
但被实施风险警示处理能代表公司出现财务危机吗?《深圳证券交易所股票上市规则(2014年修订)》(以下简称《上市规则》)13.2.1条中列示的实行风险警示处理的情形主要包括以下六类原因:连续两年亏损、财务破产、由于追溯重述造成的连续两年亏损或期末净资产为负、审计否定、信息披露违规、重大会计差错或虚假记载。《上市规则》中第三类原因涉及公司过度粉饰财务报表,后三类原因则涉及到了违规与造假。此类公司财务数据极不可靠,也并非由财务危机引起公司被实行风险警示处理。若加入此类样本,势必严重扭曲模型。
此外,非ST样本对经营良好公司的代表性也不强。由于监管体系存在漏洞,许多非ST企业通过盈余管理进行利润的操纵,从而避免被挂牌ST。如鞍钢股份(股票代码:000898)在2011年和2012年分别巨亏21亿元和42亿元,因而被挂牌ST。然而,2013年在其营业收入下滑、钢材市场低迷的情况下,鞍钢居然实现了净利润7.7亿元,从而将ST的帽子摘除。A股市场中类似的案例并不少见,此类公司的财务数据极不可靠,如果在样本中没有进行剔除,则可能扭曲模型。
(二)解决方案
章之旺(2004)[8]、廖斐(2014)等[9]学者的研究都证明了第T-1年的数据对公司第T年财务危机的预测效果显著好于T-2或T-3年,因此本文直接以T-1年的数据进行建模。以下三条是针对上述问题的解决方案。
1.利用因子分析进行建模
因子分析是一种挖掘数据特征的统计方法,它能够从大量指标中提取出共性因子,并对其经济意义进行解释。这样我们不仅能评价公司是否发生财务危机,而且能够对公司各方面的能力进行评价,从而找出引发财务危机的导火索。此外,因子分析更加地客观,减少了人为构建指标体系存在的主观因素,起到了良好的降维作用。
2.在模型中加入误判代价
本文在制定判别准则时,设定Ⅰ类误判代价为Ⅱ类误判代价的n倍(1/10≤n≤10)。以总误判代价最小为原则,制定出相应的判别规则。其实大部分研究所采用的“误判概率最小原则”是误判代价相等的特殊情况。本文通过对参数n的10 000次模拟取值,计算出对应的预警界限,从而进行稳健性检验,以提高模型的适用性。
3.提高训练样本的筛选标准
为了保证财务报表数据的可靠性,本文提高了筛选样本的标准,以免出现财务造假或过度粉饰的样本。Hill(1996)[10]证实了审计意见与财务危机发生率这两个变量之间有极强的相关性。往往经营状况不佳的公司有掩盖财务危机的动机,因此本文仅保留了取样公司前5年的审计意见类型均为标准无保留意见的样本,且对于上市未满5年的样本进行剔除。对于非ST公司样本,本文要求其连续2年盈利,以避免公司的利润操纵嫌疑。
二、基于因子分析的预警模型构建
本文参考了证监会2012年修订的《上市公司行业分类指引》,选取了全部A股市场中的制造业企业进行建模分析,并对模型结果进行了稳健性检验与精度检验。
(一)指标的选取
本文从以往的财务预警模型中选取了衡量企业5个维度的20个指标,并将详细的指标与符号列示如下:
•盈利能力:资产报酬率(X1)、总资产净利率(X2)、净资产收益率(X3)、营业成本率(X4)、营业净利率(X5)、现金与利润总额比(X6)
•盈利质量:净利润现金净含量(X7)、营业收入现金净含量(X8)、营业利润现金净含量(X9)
•营运能力:应收账款周转率(X10)、存货周转率(X11)、总资产周转率(X12)
•增长能力:净利润增长率(X13)、营业利润增长率(X14)、可持续增长率(X15)
•偿债能力:流动比率(X16)、速动比率(X17)、现金比率(X18)、资产负债率(X19)、长期资本负债率(X20)
(二)样本的选取
本文将样本分为“非ST公司样本组”与“ST公司样本组”,样本的筛选标准如下所示。
1.非ST公司样本组
由于非ST公司有为避免被挂牌ST而进行利润操纵的嫌疑,因此本文提高了筛选标准,具体筛选标准见以下六条:
•样本范围:全部A股市场中的制造业企业,并剔除当年被挂牌ST的企业。
•样本时间:本文采集T-1年的指标,其中T为2011-2015。
•数据口径:财务指标值由合并财务报表年报中的数据计算得到。
•样本规模:取样前的销售收入在10亿元到150亿元之间。
•要求样本取样前连续5年年报的审计意见类型为“标准无保留意见”。
•要求样本取样前连续2年盈利(即年报的净利润大于零)。
2.ST公司样本组
《上市规则》中实施风险警示处理的后四类情况涉及公司粉饰报表、违规、造假等原因,而并非由财务危机导致公司被挂牌ST。因此我们必须对由这四类原因引起的样本进行剔除,本文ST公司样本组的筛选标准见以下五条:
•样本范围:全部A股市场的制造业企业中首次被指定为ST(或*ST)的企业。
•样本时间:本文采集T-1年的指标,其中T为2011-2015。
•数据口径:财务指标值由合并财务报表年报中的数据计算得到。
•样本规模:取样前的销售收入在10亿元到150亿元之间。
•剔除由于追溯重述造成的连续两年亏损或期末净资产为负、审计否定、信息披露违规、重大会计差错或虚假记载等原因而被挂牌ST(或*ST)的样本。
根据以上的样本筛选标准,本文能够建立一个合理假设:本文所选样本的财务数据能有效反映公司的财务状况、经营成果、现金流量等情况,“非ST公司样本组”与“ST公司样本组”分别对未出现财务危机的公司与出现财务危机的公司有良好的代表性。
最终本文将按照以上条件筛选出来的样本分为建模样本、判别样本、检验样本。建模样本是指用来进行因子分析提取公共因子的样本。由于“ST公司样本”的个别指标会与总体有较大偏离,如果将其加入建模样本进行因子分析会扭曲模型,因此建模样本中仅选取了200个“非ST公司样本”。判别样本是指用来制定判别规则的样本,在判别样本中本文选取了“ST公司样本”与“非ST公司样本”各50个,根据误判代价最小的原则划出了预警的界限。检验样本是指用来检验财务预警模型精度的样本。检验样本同样也选取了“ST公司样本”与“非ST公司样本”各50个进行精度检验。
(三)数据的预处理
根据以上所选取的指标我们从国泰安数据库中检索了相关数据。但是由于原始数据存在量纲上的差异,为了避免大数吃小数的现象本文先对原始数据进行标准化处理,计算方法见公式(1):
(1)
其中Z-score表示标准化后的数据,X表示原始数据,μ表示指标的样本均值,δ表示指标的样本方差。
(四)因子分析的适度性检验
在利用因子分析提取公因子之前,先要对筛选出来的数据进行因子分析的适度性检验,以确定数据适合进行因子分析。本文的因子分析适度性检验主要采用了KMO和Bartlett两种方法,检验结果见表1:

表1 KMO和Bartlett的检验
由表1可以看出KMO=0.740,大于0.7,说明我们的数据较适宜用因子分析。此外,Bartlett的球形度检验的概率P值为0.000,在显著性水平取1%的条件下通过了检验。由此,我们可以认为我们的原始数据存在较大的相关性,适宜用因子分析。
(五)财务预警模型的构建
根据标准化的数据,我们利用主成分方法对公共因子进行提取,并且最终提取了6个特征值大于1的公共因子。并且这6个因子的累计方差贡献率达到了84.77%,说明了这6个公共因子能够代表20个原始变量中84.77%的信息量。不仅实现了良好的降维,而且保证了较高的信息提取量。
之后,本文通过最大方差法对因子进行旋转,使因子的经济意义更好解释。观察旋转后的载荷矩阵,我们将高载荷指标归为一类,客观地建立了新的指标体系,见表2。与原始指标体系相比,通过因子分析后“可持续增长率”这一指标被归类到了盈利能力(F1)这个维度,说明该指标实际上与盈利能力相关性较高。此外,系统又将原始指标体系中的“偿债能力”拆分成了短期偿债能力(F5)和长期偿债能力(F6)两个维度。

表2 公因子及其含义
注:指标值来源于国泰安数据库,因子的提取方法为主成分方法,旋转方法为最大方差法。
根据成分得分系数矩阵,本文确定企业在六个维度各自的标准化得分模型F1至F6,见公式(2)至(7),其中X表示指标经过标准化处理后的数值。
F1=0.202X1+0.180X2+0.224X3-0.167X4+0.180X5-0.014X6-0.019X7+0.068X8-0.014X9-0.003X10-0.078X11-0.019X12-0.003X13-0.028X14+0.216X15-0.061X16-0.060X17-0.066X18+0.042X19+0.063X20
(2)
F2=0.005X1+0.003X2-0.015X3-0.020X4+0.010X5+0.286X6+0.290X7+0.236X8+0.265X9+0.062X10-0.028X11-0.033X12+0.010X13+0.041X14-0.024X15-0.019X16-0.024X17-0.019X18-0.034X19+0.005X20
(3)
F3=-0.052X1-0.032X2-0.071X3-0.006X4-0.002X5-0.016X6-0.015X7-0.005X8-0.011X9-0.034X10+0.115X11+0.012X12+0.019X13+0.019X14-0.057X15+0.336X16+0.355X17+0.365X18-0.058X19+0.131X20
(4)
F4=0.032X1+0.024X2+0.035X3+0.202X4-0.144X5-0.003X6-0.001X7-0.043X8-0.001X9+0.216X10+0.473X11+0.456X12+0.002X13+0.015X14+0.036X15+0.036X16+0.067X17+0.066X18+0.008X19-0.042X20
(5)
F5=-0.007X1-0.004X2-0.006X3+0.054X4+0.009X5+0.013X6+0.059X7+0.019X8-0.011X9-0.071X10+0.045X11+0.014X12+0.532X13+0.552X14-0.001X15+0.020X16+0.017X17+0.020X18-0.001X19-0.035X20
(6)
F6=0.002X1-0.069X2+0.087X3-0.046X4-0.011X5-0.008X6-0.011X7-0.047X8+0.016X9-0.151X10+0.091X11-0.048X12+0.010X13-0.061X14+0.134X15+0.066X16+0.108X17+0.163X18+0.441X19+0.706X20
(7)
若某个企业的第i项因子得分Fi<0,则表示该企业在经营规模类似的制造业中处于行业平均水平之下。且Fi越小,则该企业在i方面表现得越差,说明企业需要及时地在对应方面进行调整,以免出现财务危机。反之说明企业在该方面的表现良好。
由于各个因子的方差贡献率代表了其在指标体系中的重要程度,所以我们可以将方差贡献率作为因子的权重构造综合得分模型,见公式(8)。根据总误判代价最小的原则(本文设定I类误判代价为Ⅱ类误判代价的n倍,此处计算中取n=1),计算出预警界限为-0.503,由此构造的判别规则见公式(9):
Z=(0.24930F1+0.17017F2+0.16713F3+0.09823F4+0.08512F5+0.07771F6)/0.84765
(8)

(9)
将各个因子带入计算综合得分,若Z>-0.503则判别为该公司一年后不出现财务危机;反之,则判为该公司一年后出现财务危机。此外,本文中没有加入判别的灰色区域,是因为在实际应用中,灰色区域会不利于企业进行判别。若企业想进行保守估计,则可以自行调整预警界限或是误判代价等参数。
(六)模型的稳健性检验
上文中参数n=1是误判代价相等的特例,但大多情况下n≠1。本文将n在区间[1/10,10]进行取值,计算对应的预警界限,以使模型更加稳健。经过10 000次模拟n的取值,最终得到了不同的预警界限,见图1:

图1 预警界限Z的稳健性检验图
由图1可以看出,不同的误判代价会造成预警界限Z的不同。对于企业外部投资者(即n>1)与企业自身(即n<1)预警界限的差异十分显著。甚至即使外部投资者对误判代价的不同认知,预警界限Z也有相当大的差异。所以加入误判代价后的模型更加稳健,其适用性亦有了明显的提高。
(七)模型的精度检验
根据以上财务预警模型(8),我们带入检验样本进行模型的精度检验,检验结果(包括判别样本与检验样本)见表3:

表3 财务预警模型的误判率及误判代价
注:Ⅰ类误判率=Ⅰ类误判个数/实际财务危机个数,Ⅱ类误判率=Ⅱ类误判个数/实际无财务危机个数,总误判率=误判个数/总样本数;其中Ⅰ类误判代价为Ⅱ类误判代价的n倍,n取1。
由表3可以看出,判别样本的总误判率仅为13%。而100个检验样本总的误判个数为12个,总体误判率仅12%。由此可以认为该模型有较高的预警精度。
三、财务预警模型的应用
精伦电子(股票代码:600355)在2010年被上海证券交易所实行了“退市风险警示处理”,股票简称变更为*ST精伦。本文以该公司为例进行分析,对公司各个维度的能力进行评价,找出该公司存在的问题。
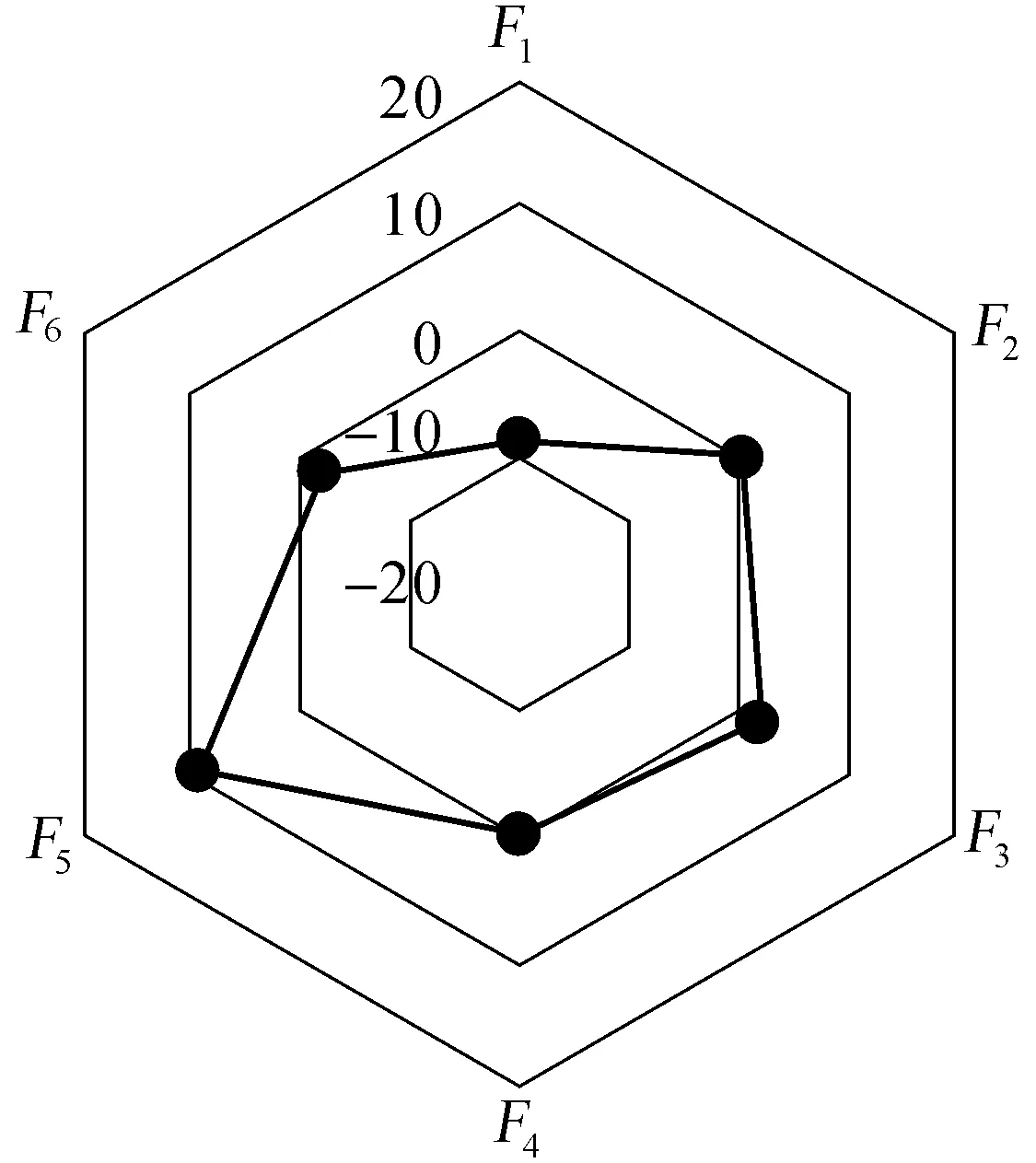
图2 因子得分雷达图
将该公司2009年的财务指标带入公式(8)中计算得Z=-1.30<-0.503,说明根据模型该公司一年后极有可能出现财务危机。为了找出危机产生的原因,我们依据因子得分公式(2)至(7)分别计算6项因子得分,见图2:
由图2可以看出,公司F1(盈利能力)与F6(长期偿债能力)两项因子小于0,说明公司在盈利能力和长期偿债能力这两方面低于同行业的其他公司。且F1显著小于0,说明该公司的盈利能力出现严重的问题。公司可以结合F1所对应的指标(根据表2)与张友棠(2011)所构建的企业风险传导模型寻找出问题根源,制定应对措施。
本文所建立的模型较以往有了一些突破,但仍然存在一定的局限性,它只能起到辅助决策的作用,仍不能取代管理层对企业的认知与经验。
[1]张建华.引入非财务指标的企业财务危机预警模型研究[D].北京:首都经济贸易大学,2009.
[2]吴星泽.财务危机预警研究:存在问题与框架重构[J].会计研究,2011(2):59-65.
[3]张友棠,黄阳.基于行业环境风险识别的企业财务预警控制系统研究[J].会计研究,2011(3):41-48.
[4]陈静.上市公司财务恶化预测的实证分析[J].会计研究,1999(4):32-39.
[5]Beaver W H. Financial Ratios as Predictors of Failure[J]. Journal of Accounting Research, 1966(4):71-111.
[6]Edward I Altman. Financial Ratios Discriminant Analysis and the Prediction of Bankruptcy[J]. Journal of Finance,1968(9):589-609.
[7]秦志敏.我国上市公司财务预警变量选择研究[D].大连:东北财经大学,2012.
[8]章之旺.现金流量在财务困境预测中的信息含量实证研究——来自2003-2004年度ST公司的新证据[J].中国管理科学,2004(6):24-29.
[9]廖斐,贾炜.基于现金流量的上市公司财务危机预警研究[J].商业会计,2014(4):80-82.
[10]Hill N T, Perry S E. Evaluating Firms in Financial Distress: An Event History Analysis[J]. Journal of Applied Business Research, 1996(3):60-71.
On Model of Financial Distress Prediction Based on Factor Analysis
MENG Xiao-jun1, SONG Nan2
(1.SchoolofAccounting,HangzhouDianziUniversity,HangzhouZhejiang310018,China;2.SchoolofZhuoyue,HangzhouDianziUniversity,HangzhouZhejiang310018,China)
This paper presents a model of financial distress prediction based on the factor analysis, which can not only reduce the dimensionality of indexes, but also can interpret the economic significance of common factors. Based on the empirical study of the manufacturing enterprises, the model has been constructed, which can analyze the reasons why the financial distress occurs from the six dimensions so as to help enterprises make solutions to it. Besides, the cost of the false rejection and the false acceptation are quite different for the different subjects, while most of the studies have neglected it. Thus, the cost of the misjudgment is introduced into the model and a robust analysis has been carried out, thus proving a new idea for further researches on it.
financial distress prediction;factor analysis;index dimensionality reduction; cost of misjudgment
10.13954/j.cnki.hduss.2017.03.002
2016-05-10
孟晓俊(1964-),女,安徽合肥人,教授,会计学.
F275
B
1001-9146(2017)03-0009-07
猜你喜欢
今日农业(2019年12期)2019-08-13 00:50:02
安顺学院学报(2019年2期)2019-07-04 00:41:44
海峡姐妹(2017年12期)2018-01-31 02:12:22
现代园艺(2017年22期)2018-01-19 05:07:01
商周刊(2017年6期)2017-08-22 03:42:49
作文与考试·初中版(2017年12期)2017-04-19 20:24:45
统计与决策(2017年2期)2017-03-20 15:25:24
通化师范学院学报(2016年11期)2017-01-15 14:02:46
火控雷达技术(2016年3期)2016-02-06 02:30:27
中学生(2015年12期)2015-03-01 03:43:53
