
基于混合核学习支持向量机的主减速器故障诊断
2017-06-29 12:00:34张华伟左旭艳
计算机应用与软件 2017年5期
张华伟 左旭艳 潘 昊
(武汉理工大学计算机科学与技术学院 湖北 武汉 430070)
基于混合核学习支持向量机的主减速器故障诊断
张华伟 左旭艳 潘 昊
(武汉理工大学计算机科学与技术学院 湖北 武汉 430070)
主减速器是汽车的重要零部件,同时也是汽车主要的故障源,据此实现一种基于混合核学习支持向量机的故障诊断方法。利用经验模态分解(EMD)与小波阈值函数,以达到对振动信号降噪。利用核主成分分析(KPCA)进行特征向量的提取,获取特征子集的低维向量。以提取的特征向量作为输入值,以支持向量机(SVM)为分类器,经遗传算法参数优化后获取故障识别率。通过研究混合核函数即单核函数的线性组合,实验结果表明,相比与传统的单核学习故障诊断方法,该方法提高了主减速器故障诊断的精度。
经验模态分解 小波阈值函数 核主成分分析 支持向量机 遗传算法
0 引 言
在复杂的工况中,机械设备的振动信号不可避免地会受到噪声污染,从混有噪声的振动信号中提取出有效的信号信息,是影响后续故障诊断精度的关键点。利用经验模态分解(EMD)与小波阈值函数,以达到对振动信号降噪,经过降噪预处理后的信号减少了对后续诊断的干扰[1]。利用主减速在不同故障状态下所表达的信息量不同及小波正交分解的特点,构造特征空间。但得到的原始特征不可避免地存在信息的冗余,导致故障诊断的精确度下降,因此,需要对原始特征子集进一步的提取特征向量。
随着国内外研究学者对故障诊断展开研究,YU GAO等人利用PCA的特征提取方法与SVM故障检测,在实际中有很好的应用[2];RENPING SHAO等人比较了PCA与KPCA提取特征的有效性,得出使用KPCA的优越性[3];黄宏臣等人通过使用LE算法和传统的降维方法PCA、MDS进行对比,提取低维特征量,再使用模式识别对滚动轴承故障进行分类,验证了拉普拉斯特征映射LE(Laplacian Eigenmaps)的高效性[4]。为了提取有效的特征向量,文中通过KPCA与LE的对比研究,实现振动信号的最优特征提取。
利用SVM进行故障识别时,一般选取的核函数都是单核,LU等人利用单核RBF支持向量机实现实时动力传动系统齿轮箱的故障诊断[5]。然而实际的特征并不是单领域的,为了充分利用不同核函数的特征映射能力,将多个核函数进行线性或非线性组合构成核函数。由于混合核函数能够集成各成员核函数的优点并具有更加优越的性能,因此成为核函数领域研究的热点。魏延等验证了利用线性核函数与RBF核函数的组合优于普通核函数构造的支持向量机[6]。为了有效地进行主减速器的故障诊断,本文将使用遗传算法来实现参数的优化,充分发挥了支持向量机较高泛化能力的优势。
1 基于EMD分解的小波阈值降噪
1.1 经验模态分解获取本征模函数
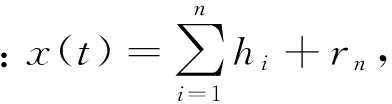
1.2 阈值函数的小波降噪
阈值降噪的基本原理就是对小波信号能量进行处理,设置一个门限值为λ,把大于门限值λ的小波系数作为信号的主要成分,小于λ的小波系数认为是噪声,然后重构新的小波系数得到图像。
一般阈值降噪的方法有2种,硬阈值和软阈值。
(1) 硬阈值定义为:
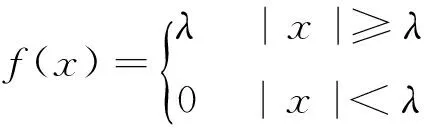
(1)
(2) 软阈值定义为:
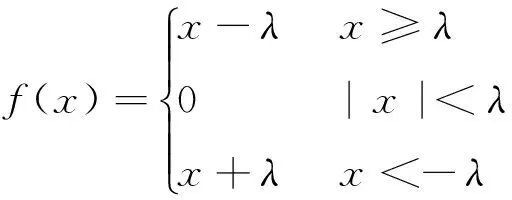
(2)
其中,f(x)为含噪信号,λ为门限值。由于硬阈值函数存在间断点,而软阈值在小波系数绝对值较大的区域引起高频信息损失。因此本文利用一种新的阈值函数进行降噪处理[8]。新阈值函数定义如下:
(3)
其中,x为小波分解的系数,通过调节a的大小使得函数f(x)收敛于软硬阈值函数的程度,克服了硬阈值函数存在间断点的问题。
在降噪的过程中,通常认为大量的信息在低频部分,一般不作处理,只对剩余的高通部分进行处理。在对信号进行EMD分解后,得到不同频率的IMF分量,对高频IMF分量进行小波降噪处理,重构得到的信号即为去噪的信号。其过程原理如图1所示。
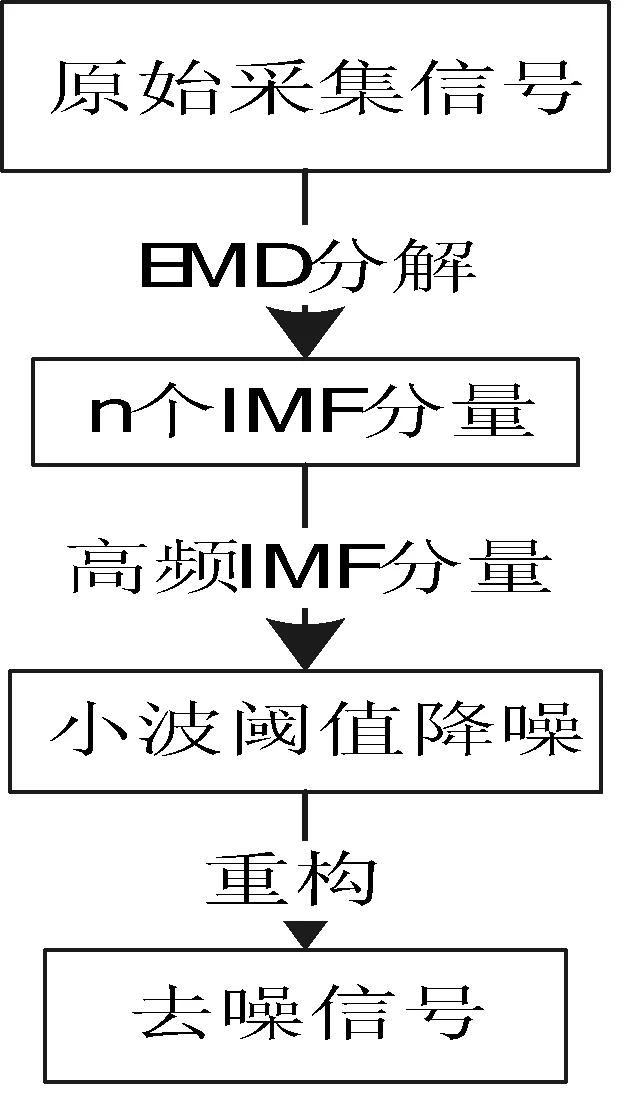
图1 去噪过程原理图
2 基于核主成分分析的故障特征提取
2.1 构造特征空间
基于主减速器在不同故障状态下所表达的信息量不同的特点,在时域和频域特征中选择特征量。在时域特征中选用均方根植、方根幅值、歪度、峭度、峰值指标、波形指标、脉冲指标、裕度指标作为维度指标。由于小波包分解采用正交基对信号进行重构,不存在信号丢失的现象的特点,选用db4小波包函数进行3层小波包分解,得到8个子频带的滤波信号,将每个频带的相对能量比作为频域统计特征参数,归一化处理之后得到一个16维的特征向量。16种特征量如表1所示。
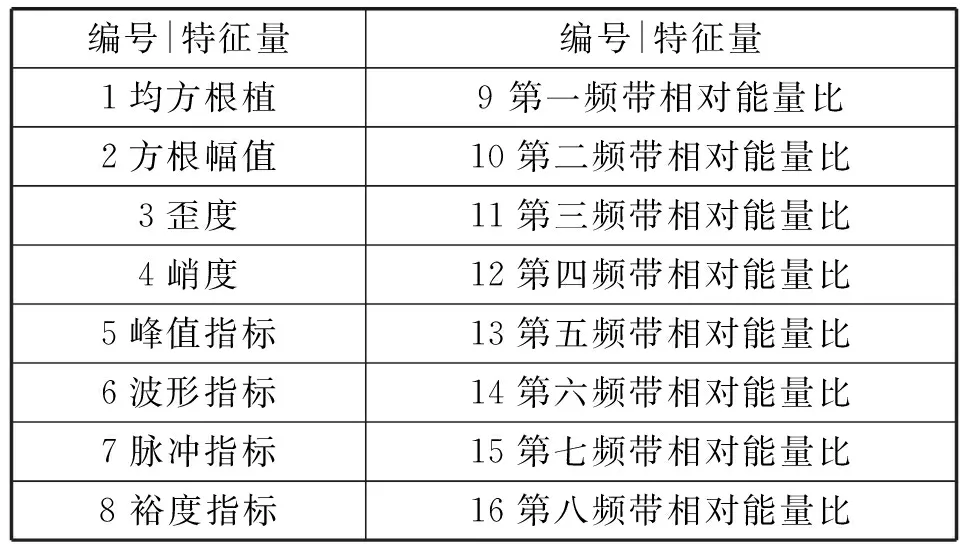
表1 16个特征量
2.2 核主成分分析(KPCA)
核主成分分析[9]是一种非线性的特征提取方法,通过核函数的引入将数据从输入空间映射到特征空间。对于给定的数据集XT={x1,x2,…,xl}∈Rn×l,n表示系统变量数目,l表示系统样本数目,输入空间Rn到特征空间F的映射为φ,J(w)的目标是在特征空间寻找一个投影向量w,使得投影后的yi=(φ(xi))Tw保留原始数据的大部分信息,其中,i=1,2,…,l。核主成分分析的目标函数J(w)可以表示为:
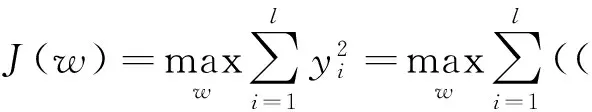
(4)
式中,wTw=1。
投影后的特征空间由映射值φ(x1),φ(x2),…,φ(xl)组成,所以投影向量w必定在特征点φ(xi)展开方向上,即存在一个向量满足:
(5)
将式(5)代入式(4),目标函数转化为如式(6)所示:

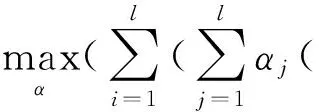
(6)

(7)
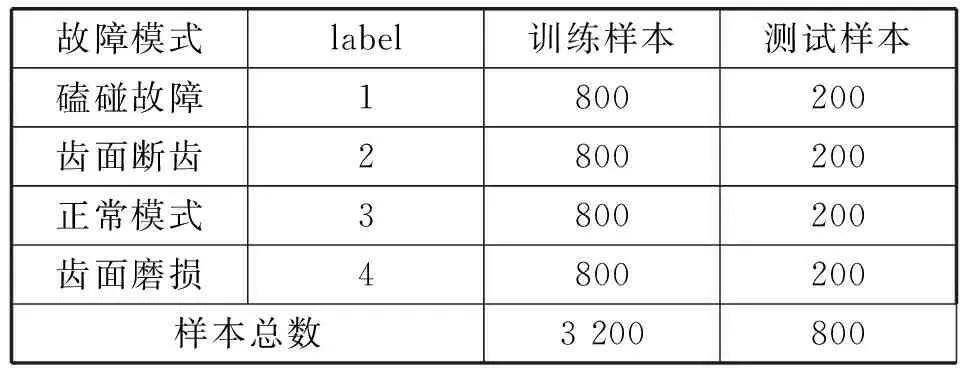
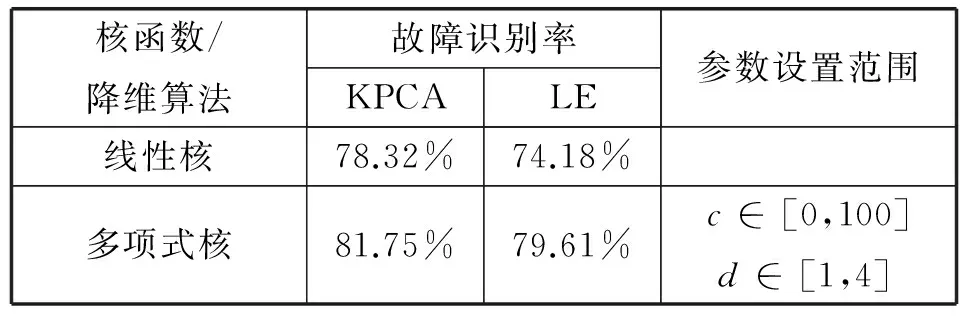
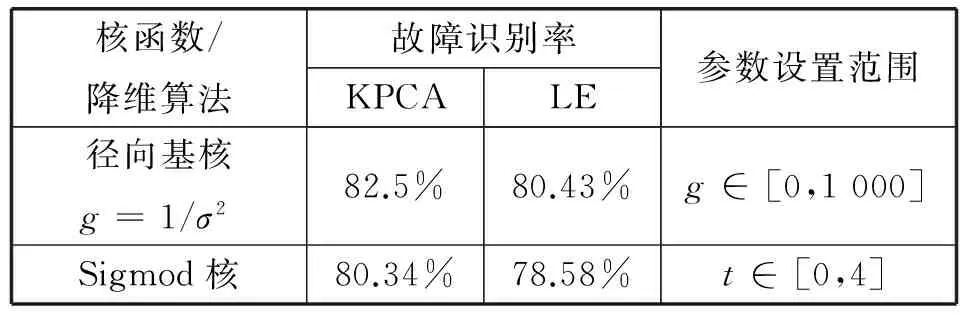
对于核函数的选取,常用的核函数[10]如下:
(1) 线性核函数
K(xi,xj)=(xi·xj)
(8)
(2) 多项式(poly)核函数
K(xi,xj)=[(xi·xj)+c]d
(9)
(3) 径向基(RBF)核函数
(10)
(4)Sigmod核函数
K(xi,xj)=tanh(v(xi·xj)+t
(11)
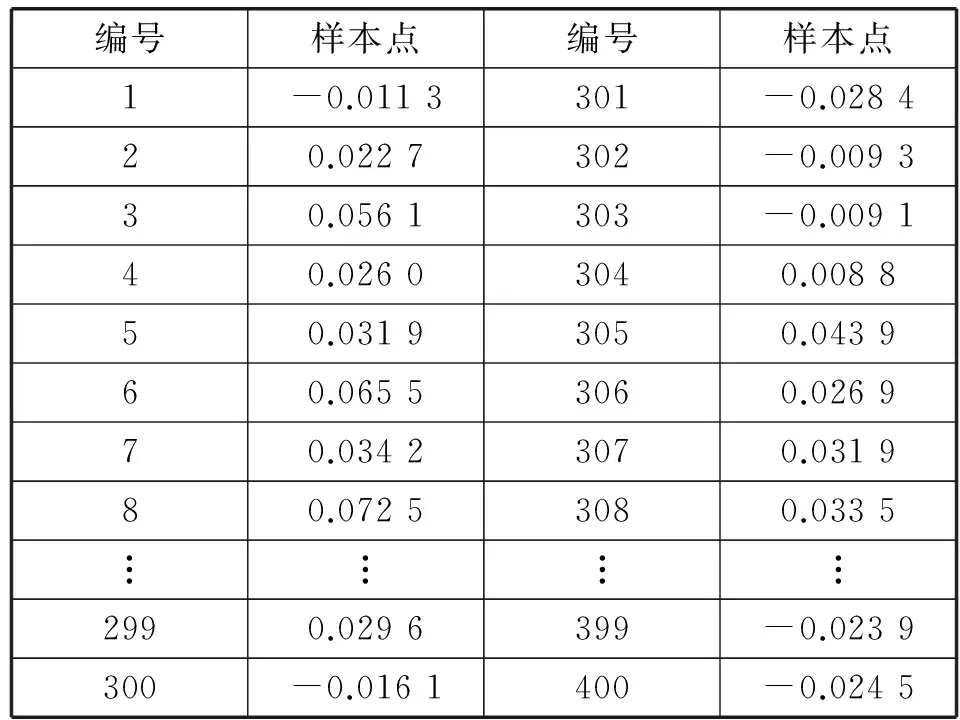
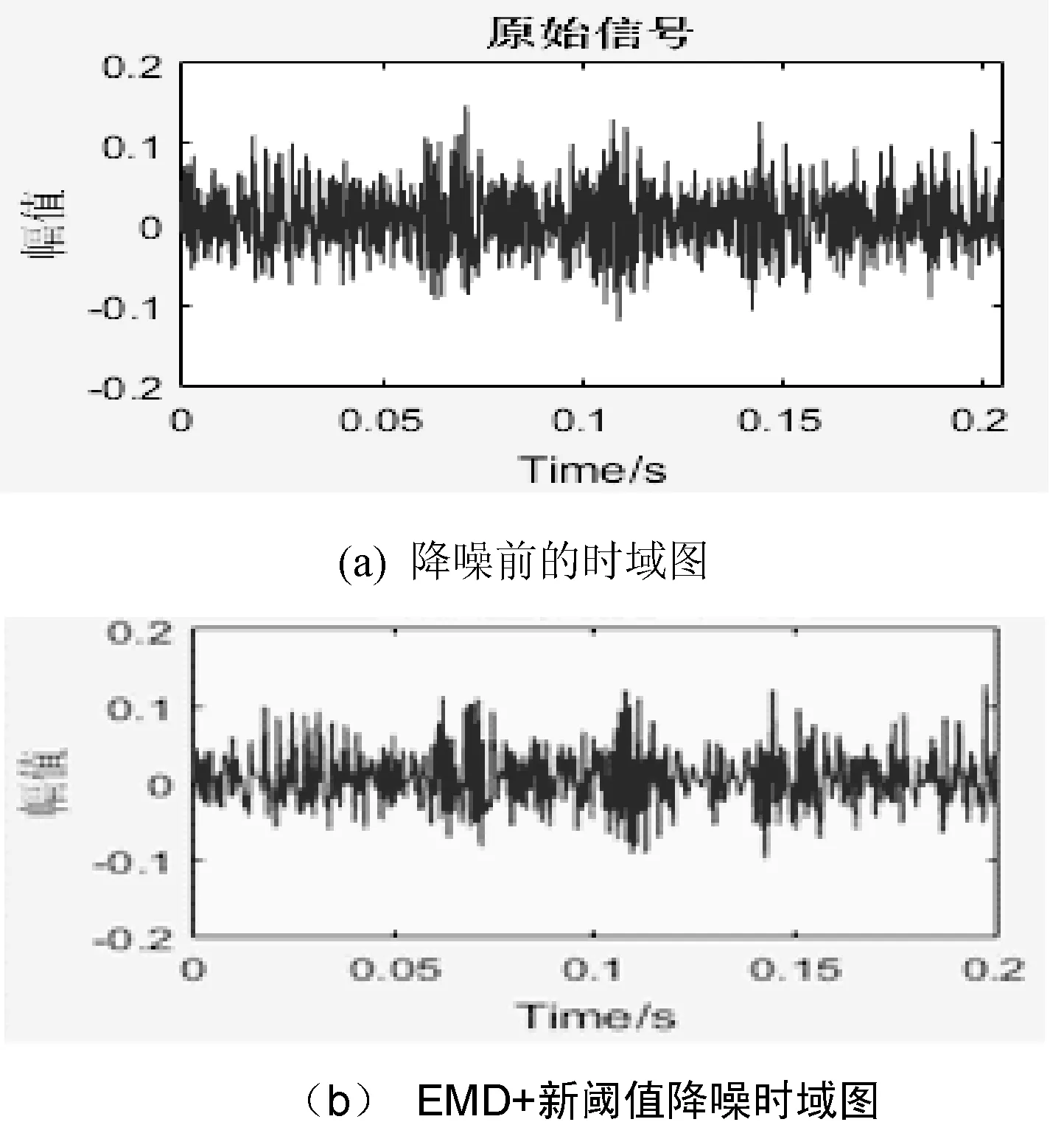
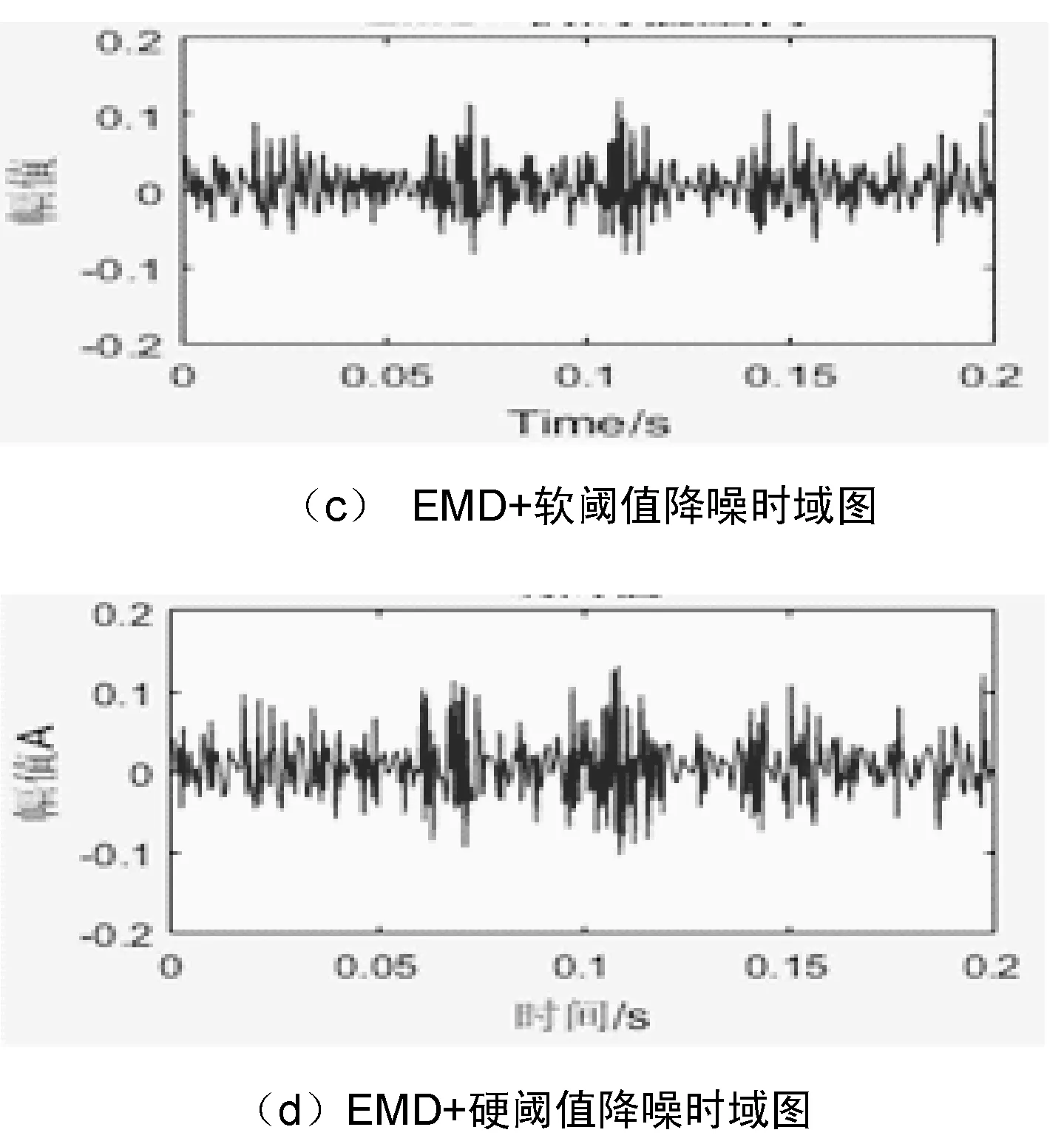
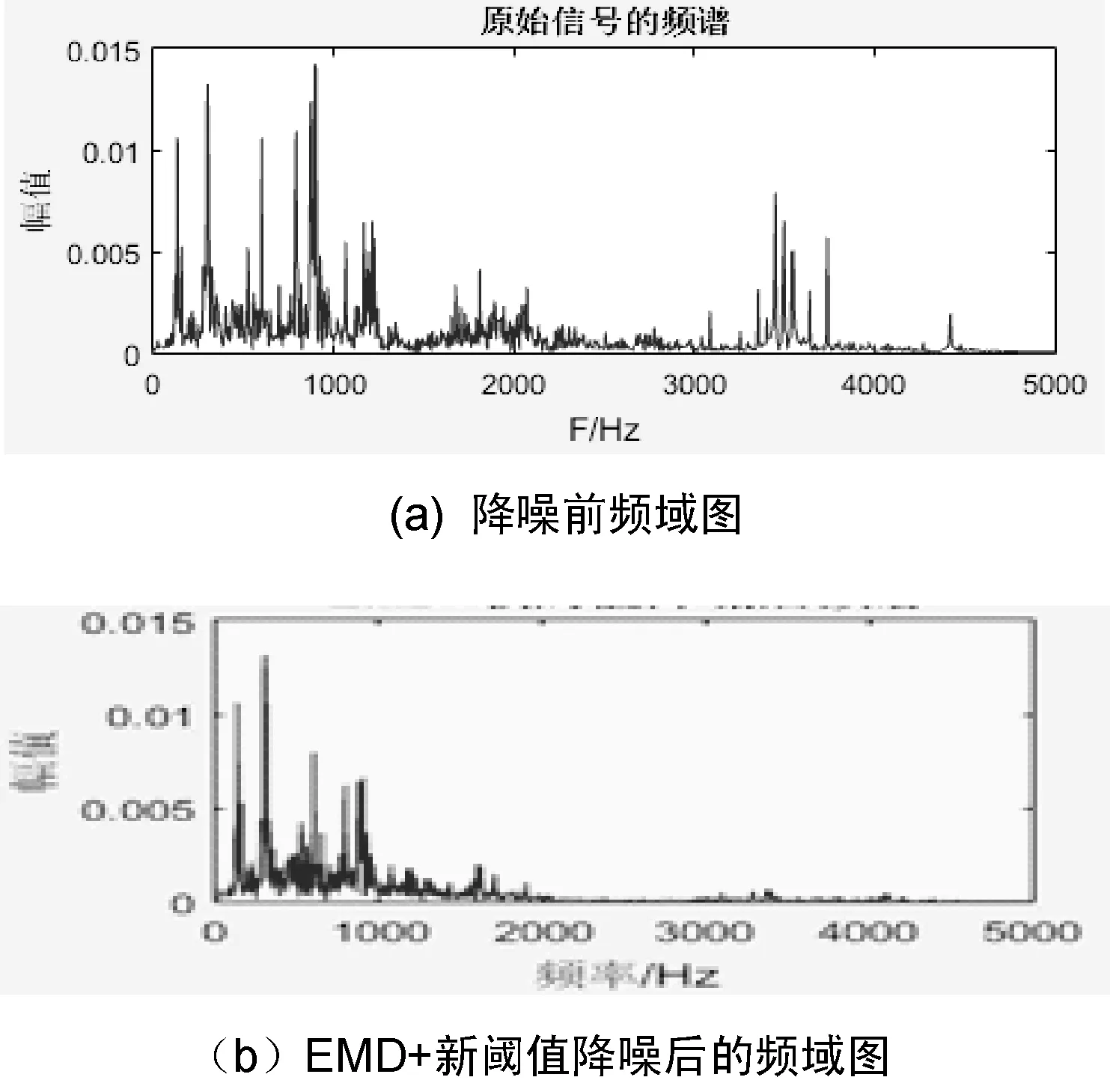
2.3 拉普拉斯特征映射
拉普拉斯特征映射LE是通过Beltrami算子来构造相应空间嵌入目标函数,实现高维数据在低维空间的嵌入[11]。给定Rm中的N个数据点X={x1,x2,…,xN},寻找低维空间Rd(d< (1) 确定每个xi∈Rm的近邻点,构建邻域关系图G,可使用K近邻或ε近邻。 (2) 确定邻接权矩阵,可选择热核方式或简单连接方式: 热核方式表示为: 简单方式表示为: (3) 构建Lapacian矩阵,计算数据的低维嵌入,广义特征向量求解:Ly=λDy,其中D是对角矩阵,满足Dii=∑jWji,L=D-W是对称的半正定矩阵为拉普拉斯矩阵。经特征分解后,得到的第2到第d+1项的非零特征值对应的特征向量作为降维后的d维输出。 LE算法的本质是从邻域关系图G到低维空间Rd中一组像点Y={y1,y2,…,yN}的映射,使得近邻的点尽可能地邻近,由LE算法的描述可知,邻域选取很重要。LE算法不需要迭代,因此计算时间大大减少。 3.1 支持向量机 支持向量机SVM是一种基于结构风险最小化的机器学习方法。SVM的主要思想在样本空间里建立一个最大间隔超平面,对应的模型f(x)=wTx+b,其中w和b是模型参数,并使两个类最近点之间的距离最大,这个距离叫做间隔w,边缘上的点叫作支持向量[12]。 对于非线性可训练空间xi∈Rd,在d维特征空间上通过引入松弛变量ξi最大化几何间隔得到常用的SVM优化模型如下: (12) s.t.yi(wTxi+b)≥1-ξiξi≥0i=1,2,…,m (13) 其中:C为代价参数,ξi为松弛因子。通过拉格朗日乘子法得到其对偶问题: (14) 对于线性不可分的情况,将原特征向量映射到高维,引入核函数,决策函数为: (15) 其中K(xi,xj)=<φ(xi),φ(xj)>为核函数。核函数是支持向量机的基础,常用的核函数在KPCA中已提到,不同的核函数会导致支持向量机的学习性能和预测精度不同。RBF核函数因其具有极好地学习能力和分类的高效性,被认为是实际应用中最好的选择,其公式如式(11)。 3.2 混合核学习 若k1和k2为核函数,对于任意整数γ1和γ2,其线性组合也是核函数γ1·k1+γ2·k2,核函数的直积也是核函数k1⊗k2(x,z)=k1(x,z)k2(x,z),对于任意函数g(x),k(x,z)=g(x)k1(x,z)g(z)也是核函数。混合核学习中的合成核可以定义为: (16) (17) 本文采用单核函数线性组合的方法构造混合核函数,确定不同的核函数,可通过权值的调整来找到更适合的核函数,比单核具有更强的鲁棒性。 惩罚参数C和核函数参数σ的选择,对于SVM诊断的准确率影响很大。只有正确选择参数,才可以使SVM的分类得到比较好的效果。避免参数选择的盲目性,文中使用遗传算法来实现SVM中的参数优化。 3.3 遗传算法(GA) 在SVM参数优化的方法中,遗传算法[13]GA的应用较广泛,并取得了较好的实践成果。其实现的一般步骤如下: (1) 进行个体编码,产生初始群体。 (2) 评估每条染色体所对应个体的适应度,用于衡量个体被遗传到下一代的几率,适应度值越大则有可能进入下次迭代。 (3) 选择操作是按照适应度越高选择概率越大的原则,从种群中选择父代将基因信息遗传到下一代。 (4) 交叉操作是将种群内的个体随机搭配成对,再随机交换其中一个或几个位于同一位置的编码来产生子代。 (5) 变异操作是在种群内随机选择个体,按照二进制变异的方式进行二进制串中的某位的翻转,进而产生新的个体。 (6) 重复步骤(3)、(4)、(5),直至得到预设的分类识别率或到达最大迭代数。 4.1 信号降噪 本文的实验数据取自广西某汽车公司车桥厂生产的主减速器振动数据集,采样频率为10kHz。在800r/min的转速下模拟主减速器最常见的几种故障类型,包括磕碰、断齿故障、齿面磨损以及正常模式,一共4种状态。实验环境:Inter(R)Core(TM)CPU2.3GHz/4GB内存,软件环境:Windows7/MATLAB2015a。 采集磕碰故障2 048个数据点作为样本数据集,列举了磕碰故障的400个数据点如表2所示。 表2 磕碰故障400个数据集 现对采集的故障模式进行EMD分解得到IMF分量,对含噪声的高频信号进行软阈值、硬阈值和改进阈值函数小波降噪,选取具有正交、对称性的db类小波,分解层数为3层,低频部分不做处理,然后将信号重构,可以大大降低信息的噪声成分。降噪前后的时域与频域图对比如图2、图3所示。 图2 降噪前后时域图 图3 降噪后的频域图 使用信噪比SNR和均方根误差RMSE来衡量降噪效果,SNR参数越大,RMSE参数越小处理效果越好。由表3可得使用改进的阈值方法对故障信号降噪效果比较好。SNR定义为: (18) RMSE定义为: (19) 由此可知EMD和新改进的阈值降噪方法得到的降噪效果比较好。使用改进阈值的降噪方法对采集的振动信号进行降噪实验。 4.2 特征提取 在正常模式及几种故障模式下,经降噪后信号的每个特征量的幅值如图4所示。 图4 四种模式的特征量 从图4可以看出,通过时域特征分析以及小波包分解得到的指标特征互不相同,具有一定的可分性,说明使用上述时域频域信息作为故障特征是可行的。列举20个齿轮断齿故障的故障样本在经过降噪处理后,得到16个归一化的特征指标,如表4所示。 表4 断齿故障归一化的16个特征量 如图5所示是4种模式的时域信号图。 图5 四种信号的时域图 原始的振动信号在经过去噪、时域信息提取、小波包分解计算频带能量这些预处理后,输入的原始维度为R16,可以视为一个高维度空间,不可避免地存在信息冗余,这些信息会隐藏故障特征,降低诊断的精确度。因此,需要对预处理的数据进行降维,提取能反映出故障特征的信息。考虑到特征向量维度对计算时间成本的影响以及数据分布的可观性,选取降维维数为故障类型数减1即R3。列举四种模式分别用KPCA和LE进行维数约简处理后得到的3维特征量,如表5所示。 表5 四种模式的3维特征量 经维数约简后的特征量需用分类器对降维的数据进行分类,通过得到的故障识别率来衡量维度算法的优良。维数约简后的样本作为分类器的输入特征向量,经SVM的模型训练,以进行故障的分类识别。 4.3 模式识别及参数优化 对采集的振动信号进行预处理之后,其中每组信号包含1 024 000个点,将其划分为1 000份生成1 000个样本,因此每个样本有1 024个点。每组数据集中选取800个样本作为训练数据集训练SVM分类模型,200个作为测试集。其数据集分配如表6所示。 表6 数据集分配 先采用常见的四种核函数进行单核SVM分类,经遗传算法参数优化过程如下: (1) 采用二进制编码形式产生初始个体,创建一个种群最大数量为50,个体长度为20的种群。设定惩罚参数C的取值范围为[0,100]。 (2) 计算个体的适应度:以支持向量机的分类确率作为衡量个体适应度的标准。分类正确率R的计算公式如下: (18) 其中,m表示分类正确的样本数,n表示样本总数。 (3) 采用随机遍历抽样选择法选择适应度高的个体。 (4) 采用两点交叉法即在两个个体编码串中随机设置两个交叉点,交换两个交叉点之间的部分基因进行交叉操作。为了得到更好的对比效果,交叉概率取值为0.4。 (5) 采用二进制变异中的离散变异法进行变异操作。本文将变异概率取值为0.01。 (6) 设定终止条件,将迭代次数T取值100~500,当迭代次数达到500时,或故障识别率达到92.75%时,终止运算。 根据上述参数优化过程,对于单核函数的参数设置范围如下,进行实验,得出的最优故障识别率如表7所示。 表7 四种核函数的故障识别率 续表7 由表7的故障识别率可知,高维数据经过传统的流形学习算法降维后,造成了有效信息的丢失,因而其识别率低于使用核主成分分析进行分类的识别率。因此在使用混合核函数时,本文选取KPCA对归一化的四种模式特征量进行特征提取。 由表7可得采用RBF核函数分类所得的故障识别率最高,因局部性核函数(RBF核函数)的学习能力强,泛化性能力较弱,而全局性核函数(多项式核函数)泛化性能力强、学习能力较弱,因此把两类核函数组合起来,可进一步提高核函数支持向量机分类器的性能。 构建混合核矩阵K=kij,选取多项式与RBF作为多核函数的线性组合,核矩阵中的元素为: kij=kmulti(xi,xj)=mkpoly(xi,xj)+(1-m)krbf (21) 其中m为权值,m∈(0,1)。根据经验取值,交叉概率为0.8,变异概率为0.01,经遗传算法优化后的实验结果参数取值及混合核函数经SVM分类所得的故障识别率如表8所示。 表8 混合核函数的故障识别率 经过多次的实验比较,由表8和表7的所得结果可知,使用组合核函数的支持向量机分类器的性能得到了进一步的提高。 针对主减速器故障诊断的研究,本文基于混合核学习支持向量机的故障诊断方法,进行了振动信号采集降噪、构造特征空间、提取故障特征以及故障识别分类等一系列研究。通过KPCA和LE的比较,利用非线性映射核函数将原始空间投影到高维特征空间的方法,保留了原始数据的大部分信息。由于混合核函数的引入,支持向量机分类利用多项式核函数、RBF核函数的线性组合得到的混合核函数,经遗传算法参数调优,得到的故障识别率比仅仅利用单核函数RBF得到的故障识别率高了7%。 [1]MertA,AkanA.Detrendedfluctuationthresholdingforempiricalmodedecompositionbaseddenoising[J].DigitalSignalProcessing,2014,32(2):48-56. [2]GaoY,YangT,XingN,etal.Faultdetectionanddiagnosisforspacecraftusingprincipalcomponentanalysisandsupportvectormachines[C]//2012IEEE7thInternationalConferenceonIndustrialElectronicsandApplications(ICIEA),2012:1984-1988. [3]ShaoR,HuW,WangY,etal.Thefaultfeatureextractionandclassificationofgearusingprincipalcomponentanalysisandkernelprincipalcomponentanalysisbasedonthewaveletpackettransform[J].Measurement,2014,54:118-132. [4] 黄宏臣,张倩倩,韩振南,等.拉普拉斯特征映射算法在滚动轴承故障识别中的应用[J].中国测试,2015,41(5):94-98. [5]LuD,QiaoW.AdaptivefeatureextractionandSVMclassificationforreal-timefaultdiagnosisofdrivetraingearboxes[C]//2013IEEEEnergyConversionCongressandExposition(ECCE),2013:3934-3940. [6] 邬啸,魏延,吴瑕.基于混合核函数的支持向量机[J].重庆理工大学学报(自然科学版),2011,25(10):66-70. [7] 徐明林.基于小波降噪和经验模态分解的滚动轴承故障诊断[D].哈尔滨:哈尔滨工业大学,2013. [8] 彭洪江,陈盛双,曾延安.基于改进阈值函数的小波降噪算法与仿真分析[J].计算机应用与软件,2015,32(10):188-191. [9]SchölkopfB,SmolaAJ,MüllerKR.Kernelprincipalcomponentanalysis[C]//Proceedingsofthe7thInternationalConferenceonArtificalNeuralNetworks,1997:583-588. [10]KungSY.Kernelmethodsandmachinelearning[M].Cambridge,UK:CambridgeUniversityPress,2014:77-140. [11]ChenC,ZhangL,BuJ,etal.ConstrainedLaplacianeigenmapfordimensionalreduction[J].Neurocomputing,2010,73(4-6):951-958. [10] 周志华.机器学习[M].北京:清华大学出版社,2016. [13] 李凌剑.基于遗传算法与支持向量机的接地网故障诊断[D].长沙:湖南大学,2014. FAULT DIAGNOSIS OF MAIN REDUCER BASED ON MIXED KERNEL LEARNING SVM Zhang Huawei Zuo Xuyan Pan Hao (SchoolofComputerScienceandTechnology,WuhanUniversityofTechnology,Wuhan430070,Hubei,China) The main reducer is an important part of the automobile, and it is also the main fault source of the automobile, so a fault diagnosis method based on mixed kernel learning SVM is realized. The empirical mode decomposition (EMD) and the wavelet threshold function are used to denoise the vibration signal. The kernel principal component analysis (KPCA) is used to extract the feature vectors, and obtain the low dimensional vectors of the feature subsets. Extracted feature vectors as input values and SVM as classifier, the genetic algorithm parameters are optimized to obtain the fault recognition rate. By studying the mixed kernel function, the linear combination of single kernel function, the experimental results show that compared with the traditional single-core learning fault diagnosis method, the method improves the accuracy of fault diagnosis of the main reducer. Empirical mode decomposition Wavelet threshold function Kernel principal component analysis SVM Genetic algorithm 2016-03-25。湖北省武汉市武汉理工大学面上项目(21376185)。张华伟,副教授,主研领域:数据挖掘,大数据,人工智能。左旭艳,硕士生。潘昊,教授。 TP306+.3 A 10.3969/j.issn.1000-386x.2017.05.0163 基于混合核学习的支持向量机的故障诊断

4 仿真实验
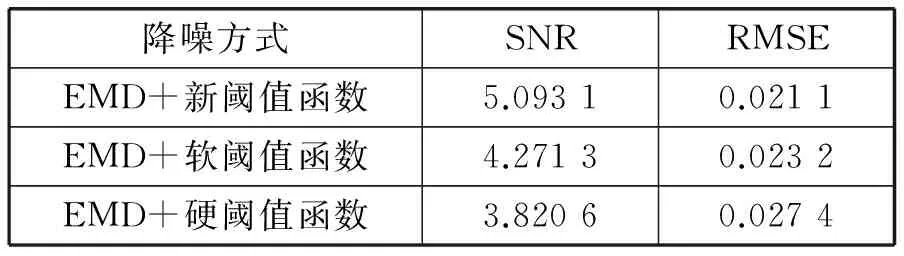
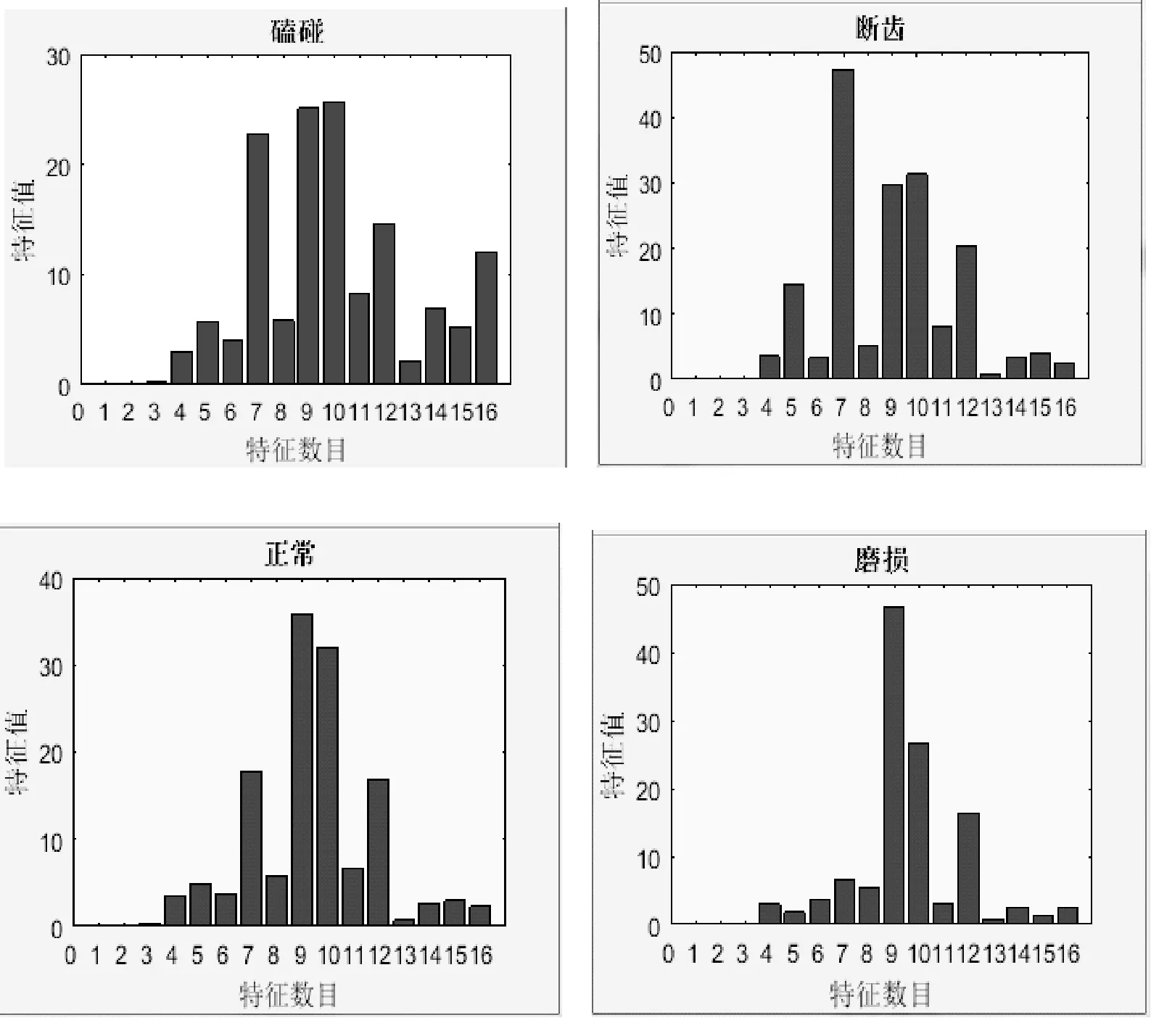

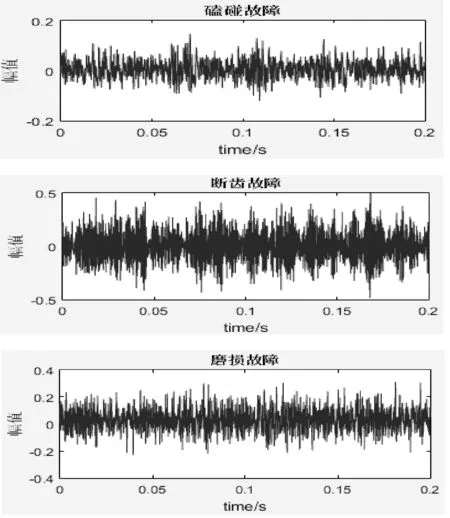
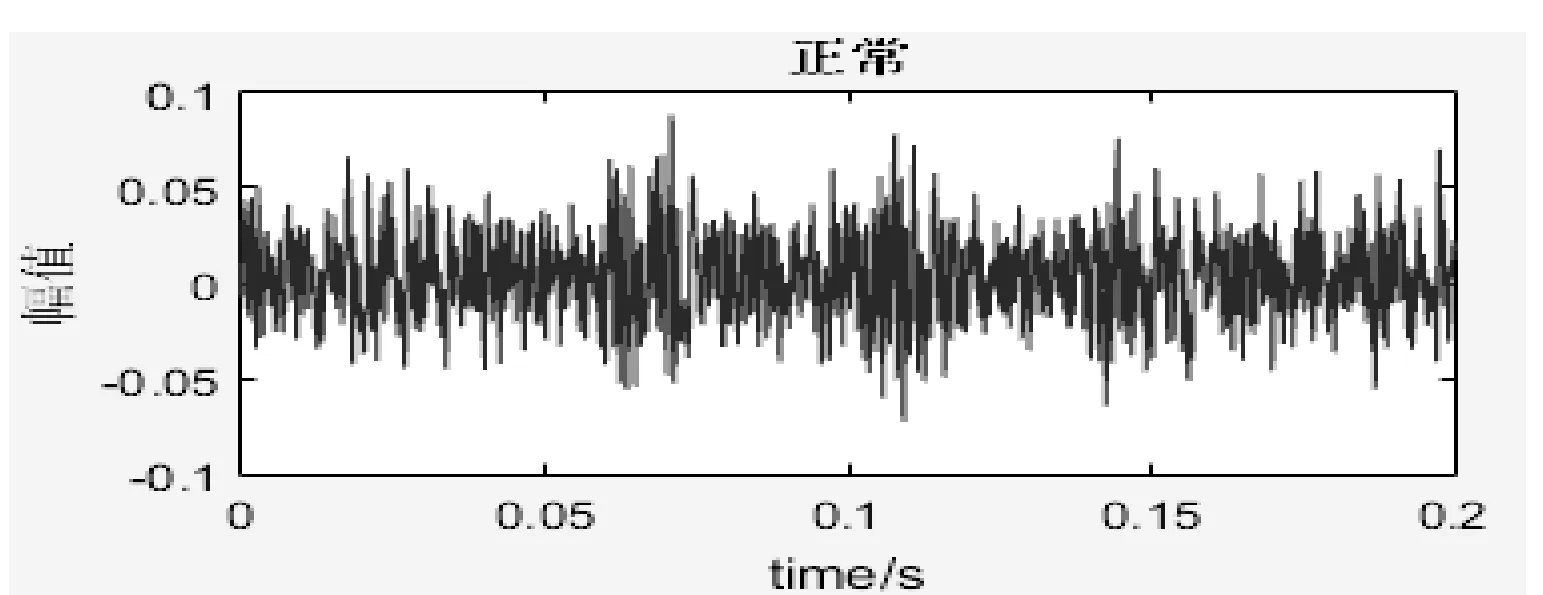


5 结 语
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
科技风(2021年19期)2021-09-07 14:04:29
计算机工程(2020年3期)2020-03-19 12:24:50
电子制作(2019年13期)2020-01-14 03:15:32
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
中国交通信息化(2018年3期)2018-06-13 03:27:58
许昌学院学报(2018年4期)2018-05-02 12:27:37
制造技术与机床(2017年10期)2017-11-28 05:20:43
中华建设(2017年1期)2017-06-07 02:56:14
