
基于改进K-近邻算法的电视剧点播量预测方法
2017-06-29 12:00:35潘栋杨静
计算机应用与软件 2017年5期
潘 栋 杨 静
(华东师范大学计算机科学技术系 上海 200241)
基于改进K-近邻算法的电视剧点播量预测方法
潘 栋 杨 静
(华东师范大学计算机科学技术系 上海 200241)
及时、准确地预测电视剧点播量为商业决策提供很大帮助。传统时间序列预测需要大量历史数据,很难满足及时、准确的预测需求。提出一种基于改进K-近邻算法的电视剧点播量预测方法,改进了K-近邻模型,并融入缩放技术和相关系数,结合百度搜索数据和点播量序列的相关性,以前一周每天的点播量为特征,预测电视剧后一天的点播量。在PPTV和优酷数据集上进行实验,比用K-近邻的方法在MAE和MAPE上分别提高了75.5%、95.3%和71.8%、99.3%。
点播系统 电视剧点播量预测 K-近邻模型 搜索数据 缩放技术 相关系数
0 引 言
近年来, VOD(video on demand)服务成为了目前各大视频服务提供商最为主要的业务,优酷、PPTV、乐视等各大在线点播系统之间的竞争越来越激烈。如果能根据早期的电视剧的播放情况准确地预估电视剧的点播量,提前准备首页推荐,能够获得更好的用户体验。同时,根据艾瑞咨询2013年第三季度到2015年第一季度的数据统计,在中国在线视频市场中,广告所占的市场份额最大,2015年第一季度占了总收入的58.2%[1]。而提早预知视频点播量可以为广告播放次数、广告播放时间做出预先安排计划。这将为各大视频服务提供商的商业决策给予极大的支持。因此,能在电视剧上线后越早预测电视剧的点播量,并准确地预测用户点播电视剧的次数成为了新的研究热点。
在点播系统中,电视剧第一次出现在系统中一般称为上线,用户点播电视剧的次数称为电视剧的点播量。目前已有的研究主要注重对点播量的相关因素进行统计和分析,从而总结出对预测点播量有帮助的性质,还有一些研究针对视频点播量趋势的预测。而关于时间序列预测方面的研究,最大的困难是训练模型时需要大量历史数据,这为早期预测造成很大的困难。但文献[2-3]的研究表明,序列前期的不同趋势会对未来的点播量造成影响,所以当没有足够的序列历史数据时,可以根据早期点播量匹配趋势变化相似的邻居序列来帮助预测点播量。KNN算法是一种邻近算法,可以找出样本中与自身特征相似的邻近点。然而传统的KNN算法,一般使用欧氏距离作为相似度,并不能体现序列的趋势变化的相似,如果通过改进KNN算法,找出序列趋势一致的邻居序列,这样可以更准确地预测点播量。
虽然通过预测模型可以找出趋势相似的邻居序列,但是点播量序列存在不确定性,如果可以通过外部数据预测趋势变化的类别,那将对预测结果有很大帮助。对于外部数据用于预测方面,很多研究通过搜索引擎数据对电影票房和电视剧排名进行预测,取得了较好的成果。这些研究都是利用搜索数据可以体现用户对该电视剧或电影的关注度,从而对票房和热度排名进行预测。然而,由于搜索数据和点播量在数值上存在很大的偏差,直接利用搜索数据进行电视剧点播量的预测变得十分困难。但是,如果能分析出搜索数据与点播量之间的相关性,将对准确地预测电视剧的点播量起到良好的辅助作用。
本文提出的算法从电视剧上线一周后开始每天预测其后一天的点播量,预测出具体的点播量数值,算法借助了百度搜索数据并改进了KNN模型。本文的主要工作有以下三个方面:
(1) 改进KNN模型,融入了缩放技术,并以曲线的相关系数代替传统的欧氏距离,效果好于传统的KNN预测方法。
(2) 发现百度搜索数据的趋势变化与电视剧点播量的趋势变化有明显的一致性,并有一定的提前量。利用百度搜索数据的变化趋势,融入到改进的KNN模型中,进行预测点播量,效果明显好于只用改进KNN模型的方法。
(3) 有效解决传统方法需要大量历史数据,在后期才能开始预测的问题,本方法能在电视剧上线一周后开始预测点播量的具体数值。
1 相关工作
对于视频点播模式下的研究工作大致可以分为两类:分析类和预测类。前者的研究主要注重于对点播量的相关因素进行分析和统计,从而总结出一些对预测点播量有帮助的性质;而后者给出具体的预测模型,主要对点播的趋势进行分析预测。
(1) 分析类:文献[4]通过研究PPTV的点播日志数据,分别分析了用户行为、视频热度、视频点播平台等因素。再通过计算皮尔森相关系数,提出了视频在上线后的前面几个小时的点播量与最终的点播量有很强的相关性。而文献[5]分析了视频的生命周期,指出节目的点播量集中在视频的早期。文献[6]分析并对比各种视频类型的趋势变化,认为电视剧和电影每日的点播量存在一定规律。
(2) 预测类:文献[2]利用基于HMM的峰值预测方法对视频信息数据和点播量序列数据进行预测,说明了视频前期的点播趋势和后期的点播趋势具有一定的相关性。文献[7]对序列数据的趋势类型进行聚类,得到趋势类型的种类。再训练分类器,预测新序列的趋势类型。文献[8]认为序列在不同的时间所表现的趋势类别应该是不一样的。所以,作者用窗口对序列进行切分,最后对切分序列进行聚类操作。文献[3]对前K天的点播量总和采用线性回归和对数线性回归的方法,预测前N天的点播量总和。文献[9]以早期序列作为特征,用KNN预测视频的播放量峰值来对视频进行热度排名。文献[10]利用早期的点播序列与后期点播变化的相关性利用KNN在早期预测了点播序列。
对于借助外部数据对点播量预测的研究,文献[11]中,作者通过研究电影上映的周票房,分析了电影的票房数和电影的搜索次数,发现两者的相关性。再用前4周发布的电影名相关搜索次数等相关因素预测了票房。文献[12]作者利用微博社交数据和百度搜索数据作为特征,利用线性回归的方法,对电视剧进行热度排名,取得了很好的效果。文献[13]利用社交网络数据对视频的热度实时的进行排名预测。
针对上述的情况,本文试图结合搜索数据来进行点播系统中的电视剧点播量的预测,通过分析搜索数据与点播序列的相关性,利用改进的预测模型对新上线的电视剧点播量进行预测。
2 方 法
本文提出的方法由两步组成,如图1所示。第一步,训练集处理。将作为训练集的电视剧点播序列进行窗口划分,并对曲线趋势进行分类;第二步,点播量预测。根据百度搜索数据的变化趋势,利用改进KNN模型预测电视剧点播量。本文中所使用到的符号,如表1所示。

图1 方法总体框架

符号含义n窗口大小TS电视剧点播量序列集合Tsi集合TS中的第i个序列Tsi(t)序列Tsi中的第t个元素S划分好的序列集合sti序列Tsi从的第t个元素开始划分的子序列sti(k)sti的第k个元素trendtisti的趋势类别s[i:j]序列s从i到j的子序列snew新的电视剧序列sbaidu百度搜索数据序列sneighbour邻居序列Daypre百度搜索数据变化趋势较点播量变化趋势的提前天数
2.1 训练集处理
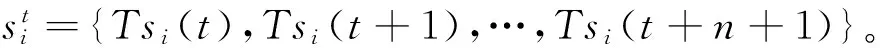
2.2 百度指数分析
为了分析百度搜索数据与电视剧点播量之间的相关性,作者从PPTV中获取了2014年10月到2015年7月新上线的100部电视剧的点播数据,并从百度指数中抓取了这些电视剧的历史搜索数据。对于百度指数的分析,本文主要关注两个问题:
(1) 百度搜索数据的趋势变化是否提前于电视剧点播量的趋势变化;
(2) 电视剧点播量的趋势变化与百度搜索数据的趋势变化是否具有一致性。
2.2.1 百度搜索次数的趋势变化提前量分析
根据电视剧播出的情况,首播前制片商会在各个渠道对电视剧进行大量的宣传活动,然后播出预告片,最后才会进行正式首播。用户往往在点播电视剧前,在搜索引擎上搜索电视剧名,了解电视剧的相关内容简介。同时,对于新的电视剧,网上更新往往比在电视上播放要晚一天,会在第二天凌晨放出片源。这些原因都有可能造成搜索数据的趋势变化提前于点播量的趋势变化。所以,根据相关系数公式(式(1))分别计算了电视剧从首播开始30天的点播量s[0:29](设首播日在各个序列中的下标为0)与百度搜索数据首播前四天sbaidu[-4,25]、首播前三天sbaidu[-3,26]、首播前两天sbaidu[-2,27]、首播前一天sbaidu[-1,28]、首播当天sbaidu[0,29]、首播后一天sbaidu[1,30]、首播后两天sbaidu[2,31]的相关系数,取其中相关系数最大的为电视剧的提前量,并统计电视剧数,如图2所示。
(1)
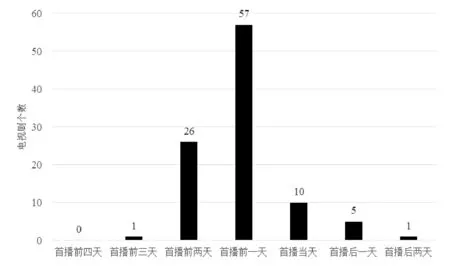
图2 百度搜索数据提前量分析
从图2中可以看出在100部电视剧中,26部电视剧的提前量为首播前两天,57部电视剧的提前量为首播前一天。占了84%的电视剧搜索数据的趋势变化提前于电视剧点量的趋势变化。这也说明了绝大多数电视剧的百度搜索数据的趋势变化先于电视剧的点播量的趋势变化。
2.2.2 百度搜索次数与点播量趋势变化的一致性分析
往往搜索量越多的电视剧,说明受到的关注越多,从而点播数量相对较多。对于变化趋势一致性的分析,我们根据式(1)计算在图2分析中趋势变化提前于点播量序列的84部电视剧的点播量与其首播前三天、首播前两天、首播前一天百度搜索数据的相关系数,取其中最大的相关系数,作为该电视剧百度搜索数据与点播量的相关系数,分别统计相关系数0.9-1、0.8-0.9、0.7-0.8、0.6-0.7、0.5-0.6和0-0.5的电视剧个数,如图3所示。
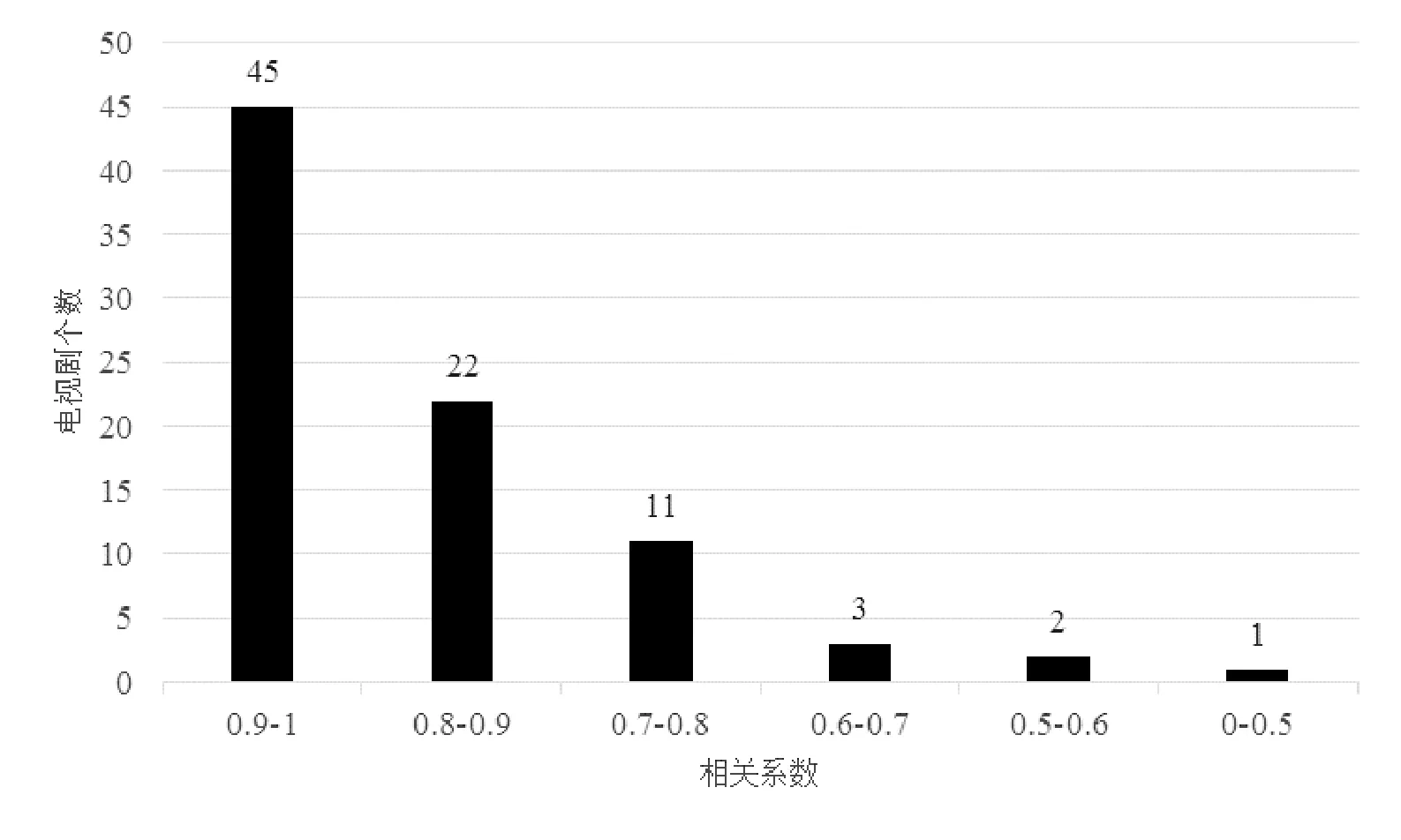
图3 百度搜索次数变化趋势和点播量变化趋势各个相关系数段的电视剧个数
在84部电视剧中,相关系数大于0.7有78部 ,而大于0.8的也有67部,这说明了百度搜索次数的变化趋势与点播量的播放的变化趋势有显著的线性相关性,也可以说明它们的变化趋势有显著的一致性。
2.3 电视剧点播量数值预测
本文主要改进了KNN算法的相似度计算,不再使用传统的欧氏距离,使用融入了缩放技术的相关系数作为相似度,利用前期的点播量找出训练集中与其变化趋势相似的邻居序列,并通过相似的邻居序列进行预测具体的点播量数值。
2.3.1 融入缩放技术与相关系数的相似度计算
由于不同的序列的数量级各不相同,要预测出精确的数值,数量级的不同会影响到预测数值的精度,为了消除相似度计算由于序列自身数量级而造成的影响,本文使用了文献[14]中所提出的缩放技术。同时,考虑到传统的KNN使用欧氏距离作为相似度,而欧氏距离主要体现的是空间距离,对于时间序列欧氏距离只能表现出两条序列之间值的差距大小,并不能体现出序列之间趋势变化的相似程度。而相关系数主要体现两条序列的线性相关程度,可以有效地衡量两条曲线的趋势变化是否相似。因此本文利用序列的相关系数作为相似度,可以更好地找出趋势变化一致的邻近点。融入了缩放技术的相关系数相似度计算式表示为:
sim(sa,sb)=r(sa,αsb)
(2)

2.3.2 点播量数值预测方法
由于根据图2分析,电视剧的提前量主要集中在首播前两天和首播前一天,所以根据式(2)计算预测序列snew[0:n](假设首播日在各个序列中的下标为0)与该电视剧百度指数中首播前一天序列sbaidu[-1:n-1]、首播前两天sbaidu[-2:n-2]的相似度,相似度高的作为该电视剧搜索指数提前于点播序列的天数Daypre。
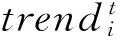
(3)
3 实 验
3.1 实验数据集
本文在两个数据集上进行了实验,数据集来自两个国内主流在线点播服务提供商——PPTV和优酷。PPTV数据集取样自PPTV的日志文件,从PPTV中收集了2014年10月1日到2015年6月30日新上线,并且首播日期和真实首播日期一致的138部电视剧的点播序列作为测试集,选取524部电视剧的点播序列作为训练集;优酷数据集抓取了中国网络视频指数中优酷的点播量,选取了2014年10月1日到2015年6月30日新上线,并且首播日期和真实首播日期一致的101部电视剧的点播量作为测试集,选取556部电视剧的点播序列作为训练集。本文还用到了外部数据——百度搜索数据,从百度指数中抓取了电视剧在百度中每天的搜索次数。
3.2 实验设置
在实现本文的方法时,对于处理训练集,在设置窗口大小n时,考虑到训练集序列不能过短或过长,过短不能体现序列的变化趋势,过长会推迟预测时间,根据文献[9]设置窗口大小为一周左右最为合适。对于训练集序列分类规则中设置的5个阈值分别为0.5、0.1、0、-0.1、-0.5,0用来区分趋势的升降;区分趋势类别中的“快速上升”和“快速下降”,取中间值0.5和-0.5作为阈值;区分趋势类别中的“缓慢上升”和“缓慢下降”,取小一点的数0.1与-0.1作为阈值。
本文设置3个方法用来与提出的方法进行比较:(1)KNN:利用KNN模型,以传统的欧氏距离作为相似度,根据式(3)计算出点播量变化的归一化值sreslut_temp,反归一化后加上snew(t)预测电视剧的点播量;(2)KNN+:用融入了缩放技术的相关系数作为相似度的KNN模型,根据式(3)计算出点播量变化的归一化值sreslut_temp,反归一化后加上snew(t)预测电视剧点播量;(3) 百度指数:在得到提前天数Daypre后,直接使用百度搜索数据变化比例作为点播量的变化比例β,以snew(t)=(1+β)×snew(t-1)预测电视剧的点播量。
对于实验结果评测,本文使用平均绝对误差[15](MAE)和平均绝对百分误差[15](MAPE)作为实验的评价指标。MAE:所有单个预测值与真值之间偏差的绝对值的平均值,不会出现正负抵消的情况,更好地反映预测值误差的实际情况;MAPE:所有单个观测值与真值偏差百分比的平均值,可以避免由于真值数量级不同造成的影响,体现预测的绝对误差。
3.3 实验结果与分析
本文根据设置的4个方法,预测了测试集中电视剧每天的具体点播量,评测结果如表2所示。在四个方法中本文提出的方法在两个数据集上的效果都好于其他三个方法。在两个数据集上,KNN+的方法预测准确率高于KNN预测的结果,分别在PPTV和优酷两个数据集上提升了40%、56%以及45%、60%。KNN+的方法在效果上显著高于KNN,一方面说明KNN+模型的有效性,传统的欧氏距离只能计算序列之间的空间距离,并没有体现出序列的变化趋势。而KNN+算法,通过修改相似度的计算,很好地体现了序列之间趋势变化的相似程度,能够根据需要预测的点播序列从训练集中找到与其趋势变化相似的点播序列。另一方面也从侧面说明了电视剧的点播量与其前期点播量的趋势变化有密切的相关性。

表2 实验结果
而本文提出的方法是四个方法中效果最好的,在各个评测指标上都显著好于KNN+的结果。在PPTV和优酷两个数据集上,MAE和MAPE分别提高了59.0%、39.1%和49.1%、38.9%,在准确性上有很大的提升。说明了百度搜索数据的趋势变化确实和电视剧点播量的趋势变化趋于一致,并有一定的提前量,具有显著的相关性。所以,百度搜索数据能够对准确地预测电视剧点播量起到很好的辅助作用,帮助预测点播量的趋势变化;同时,本文提出的方法比较百度指数的方法在两个指标上超出:(1)PPTV:23%、8.4%;(2) 优酷:15%、1.6%。说明了KNN+在这个方法中的有效性,可以通过KNN+的方法找出趋势变化相似的邻居序列,用相似的邻居序列对电视剧点播量进行预测。
对于两个数据集的比较,由于MAE会受到数据集本身数据的影响,所以主要从MAPE这个指标进行分析。从MAPE上可以看出,四种方法在PPTV上的效果好于优酷数据。这个原因可能由两个数据集的数据来源不同而导致,PPTV的数据来源于日志文件,处理数据时,点播量主要统计了正片每天的点播量;而优酷数据,是从中国网络视频指数中抓取获得,点播量由预告片和正片的点播量组成,这个原因可能导致方法在优酷数据集上的结果要略差于PPTV。
从以上的实验结果分析来看,本文提出的基于改进K-近邻并结合了百度搜索数据与点播量的相关性预测新上线电视剧点播量的方法在评测结果上要优于其他方法。
4 结 语
本文通过百度搜索引擎利用改进的KNN模型对新上线的电视剧进行了点播量预测。我们通过对PPTV中新上线的100部电视剧进行了相关系数分析,发现了百度搜索数据和电视剧点播序列的趋势一致性,以及百度搜索数据的趋势变化提前于电视剧点播量的趋势变化。最后利用本文提出的方法在PPTV和优酷两个数据集上进行了测试,都表现出了更好的预测效果,对比KNN的方法,在MAE和MAPE上分别高出75.5%、95.3%和71.8%、99.3%。
对于未来工作,我们在处理训练集时,在划分序列的同时可以考虑序列所处的位置,将序列的位置信息加入到预测工作中。
[1] 艾瑞咨询.艾瑞:2015Q1中国在线视频移动广告占比迅速攀升[DB/OL].(2015-5-11).http://www.iresearch.com.cn/view/249731.html.
[2]CraneR,SornetteD.Viral,Quality,andJunkVideosonYouTube:SeparatingContentfromNoiseinanInformation-RichEnvironment[C]//AAAISpringSymposium.California.USA:SocialInformationProcessing.2008:18-20.
[3]SzaboG,HubermanBA.Predictingthepopularityofonlinecontent[J].CommunicationsoftheACM,2010,53(8):80-88.
[4]LiZ,LinJ,AkodjenouMI,etal.Watchingvideosfromeverywhere:astudyofthePPTVmobileVoDsystem[C]//Proceedingsofthe2012ACMconferenceonInternetmeasurementconference.Boston.USA:ACM,2012:185-198.
[5]FigueiredoF,BenevenutoF,AlmeidaJM.Thetubeovertime:characterizingpopularitygrowthofyoutubevideos[C]//ProceedingsofthefourthACMinternationalconferenceonWebsearchanddatamining.HongKong.China:ACM,2011:745-754.
[6]AbrahamssonH,NordmarkM.ProgramPopularityandViewerBehaviorinaLargeTV-on-DemandSystem[C]//Proceedingsofthe2012ACMconferenceonInternetmeasurementconference.NewYork.USA:ACM,2012:199-210.
[7]FigueiredoF.Onthepredictionofpopularityoftrendsandhitsforusergeneratedvideos[C]//ProceedingsofthesixthACMinternationalconferenceonWebsearchanddatamining.Rome.Italy:ACM,2013:741-746.
[8]AhmedM,SpagnaS,HuiciF,etal.Apeekintothefuture:Predictingtheevolutionofpopularityinusergeneratedcontent[C]//ProceedingsofthesixthACMinternationalconferenceonWebsearchanddatamining.Rome.Italy:ACM,2013:607-616.
[9] 李仑,王洪波.基于K近邻的网络视频播放量峰值预测模型[EB/OL].(2015-12-02).http://www.paper.edu.cn/releasepaper/content/201512-122.
[10]ChenH,HuQ,HeL.Clairvoyant:AnEarlyPredictionSystemForVideoHits[C]//Proceedingsofthe23rdACMInternationalConferenceonConferenceonInformationandKnowledgeManagement.Shanghai.China:ACM,2014:2054-2056.
[11]PanaliganR.QuantifyingMovieMagicwithGoogleSearch[EB/OL].(2013-05-18).http://www.tuicool.com/articals/mei2Qf.
[12] 徐晓枫,贺樑,杨静.融合社交与搜索数据的电视剧点播排名预测研究[J].计算机工程,2015,41(8):6-12,17.
[13]XuJ,VandSM,LiuJ,etal.Timelyvideopopularityforecastingbasedonsocialnetworks[C]//Chengdu.China:ComputerCommunications.IEEE,2015.
[14]ChuKKW,WongMH.Fasttime-seriessearchingwithscalingandshifting[C]//ProceedingsoftheeighteenthACMSIGMOD-SIGACT-SIGARTsymposiumonPrinciplesofdatabasesystems.Philadelphia.USA:ACM,1999:237-248.
[15]HyndmanRJ,KoehlerAB.Anotherlookatmeasuresofforecastaccuracy[J].InternationalJournalofForecasting,2005,22(4):679-688.
A PREDICTION METHOD OF TV ON DEMAND BASED ON IMPROVED KNN ALGORITHM
Pan Dong Yang Jing
(DepartmentofComputerScienceandTechnology,EastChinaNormalUniversity,Shanghai200241,China)
Timely and accurate prediction of TV on demand provides a great help for commercial decision. Traditional time series prediction requires a lot of historical data, and it is difficult to meet the timely and accurate prediction needs. In this paper, an improved KNN algorithm is proposed to improve the prediction of TV on demand. The KNN model is improved, and the scaling technology and correlation index are integrated. Combining the correlation between Baidu search data and the demand quantity sequence, it is characterized by daily demand of the previous week to predict the day after the TV drama demand. Experiments on the PPTV and Youku data sets show an increase of 75.5%, 95.3%, 71.8% and 99.3% on the MAE and MAPE, respectively, compared with the KNN algorithm.
On-demand system TV on demand prediction KNN model Search data Scaling technology Correlation index
2016-05-20。国家科技支撑项目(2015BAH01F02);上海市科学技术委员会科研计划项目(16511102702)。潘栋,硕士生,主研领域:数据挖掘,复杂信息处理与数据库。杨静,副教授。
TP3
A
10.3969/j.issn.1000-386x.2017.05.042
猜你喜欢
第一财经(2021年6期)2021-06-10 13:19:08
学生天地(2020年14期)2020-08-25 09:20:58
Defence Technology(2020年4期)2020-07-02 03:16:58
特别文摘(2018年3期)2018-08-08 11:19:42
青年与社会(2018年2期)2018-01-25 15:37:06
Coco薇(2017年9期)2017-09-07 21:23:49
纺织服装流行趋势展望(2016年2期)2016-05-04 03:47:15
IT时代周刊(2015年8期)2015-11-11 05:50:22
诗选刊(2015年6期)2015-10-26 09:47:11
汽车科技(2015年1期)2015-02-28 12:14:44
