
基于动态时间的个性化推荐模型
2017-06-27 08:10:08谭黎立聂瑞华王进宏
华南师范大学学报(自然科学版) 2017年3期
谭黎立, 聂瑞华*, 梁 军, 王进宏
(1.华南师范大学计算机学院,广州 510631;2. 华南师范大学网络中心,广州 510631;3. 北明软件有限公司,广州 510663)
基于动态时间的个性化推荐模型
谭黎立1, 聂瑞华1*, 梁 军2, 王进宏3
(1.华南师范大学计算机学院,广州 510631;2. 华南师范大学网络中心,广州 510631;3. 北明软件有限公司,广州 510663)
在推荐系统中,往往会存在数据的非实时性、稀疏性和冷启动性等问题,文中通过引入遗忘曲线来跟踪用户对资源偏好程度随时间变化情况,提出一种改进的K-Means聚类算法对用户集进行聚类,根据改进的个性化推荐算法对用户进行推荐,建立了一种基于动态时间的个性化推荐模型. 通过实验验证,该个性化推荐模型能够获取准确的用户偏好信息,并缓解冷启动问题,降低算法计算的时间空间复杂度,提高个性化推荐算法的推荐质量.
个性化; 遗忘曲线;K-Means; 物质扩散; 热传导
个性化推荐技术是在20世纪90年代提出的,一直保持着较高的研究热度[1]. 如人工智能、数据挖掘和大数据等各个研究领域相关技术为其提供相关服务与支持[2]. 个性化推荐技术是为了解决信息过载问题而发展出来的一门科学技术[3],而基于协同过滤推荐技术(Collaborative Filtering Recommendations, 简称CF)是运用最广的个性化推荐技术[4]. 面对“大数据”时代,个性化推荐系统可以在海量的信息中,准确预测出用户的个性化潜在偏好,但也面临着数据的稀疏性[5]、冷启动性[6]和推荐效果不佳等问题.
学者们就这些问题纷纷提出了相应的改进算法,如:概率扩展和热力传导的混合推荐算法,解决了在推荐效果上的准确性和多样性[7];基于顺序的推荐模型,分析用户访问项目的顺序,以发现用户的潜在感兴趣的产品[8];构建特征层次模型,不仅可以通过时间序列分析来预测用户偏好,而且可以很好解决数据冷启动问题[9];根据用户的偏好记录信息构造社会关系网络图,猜想与新用户之间的社会关系信息,并通过计算相似度,预测新用户可能感兴趣的项目,解决偏好矩阵的稀疏性问题[10];利用数据挖掘相关算法来分析用户行为信息,并分类处理,预测用户的行为特征,为用户推荐相关资源[11].
本文就构建动态用户偏好模型、降低数据复杂度和提高推荐算法的推荐效率等方面进行深入研究,提出了一种基于动态时间的个性化推荐模型,旨在应对个性化推荐系统面临的挑战.
1 一种基于动态时间的推荐模型
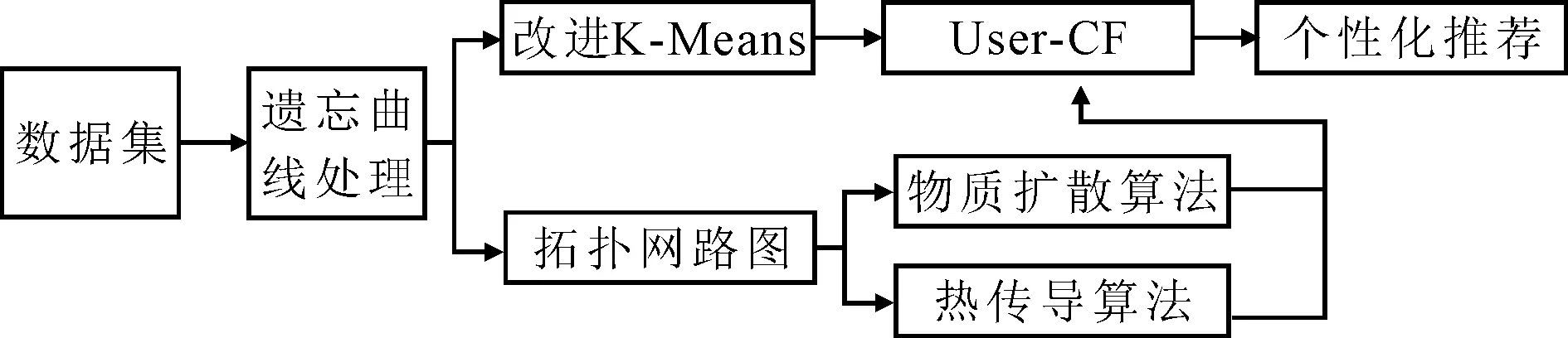
本文提出了一种基于动态时间的个性化推荐模型(HH-CF),能够有效地提高其推荐质量,降低计算的时间复杂度(图1). 主要改进点为引入遗忘曲线对用户偏好进行处理、对用户集进行聚类处理和对预测评分值进行优化调整.
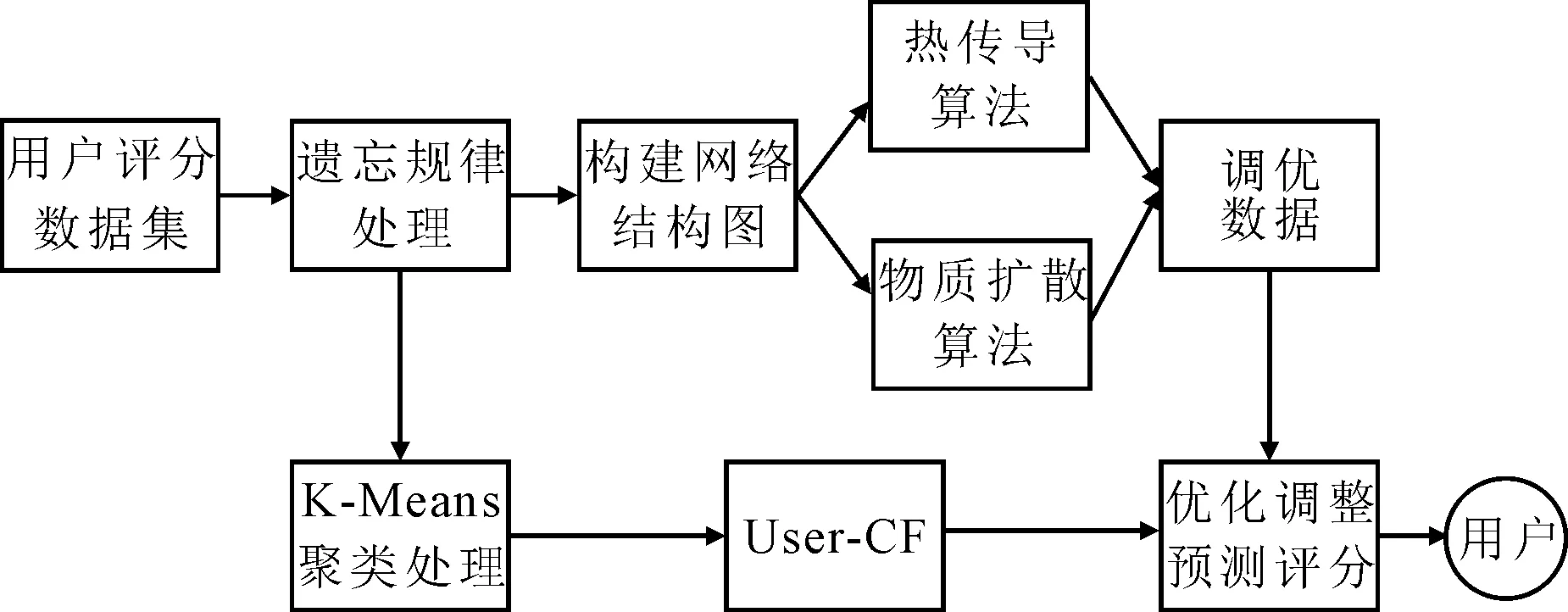
图1 基于动态时间的个性化推荐模型
Figure 1 The personalized recommendation model based on dynamic time
1.1 基于遗忘规律的改进
用户在不同时间段有不同需求,在传统推荐系统中,很难获取用户当前准确的潜在偏好信息,因此,本文引入遗忘曲线调整用户偏好信息. 人的记忆变化情况是:记忆量随时间呈非均匀的减少,下降速率逐渐减少[12]. 通过大量实验对遗忘曲线进行拟合计算,得到如下公式:
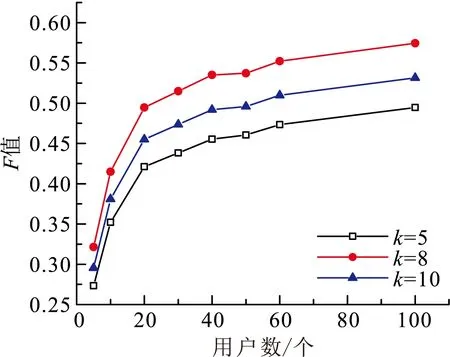
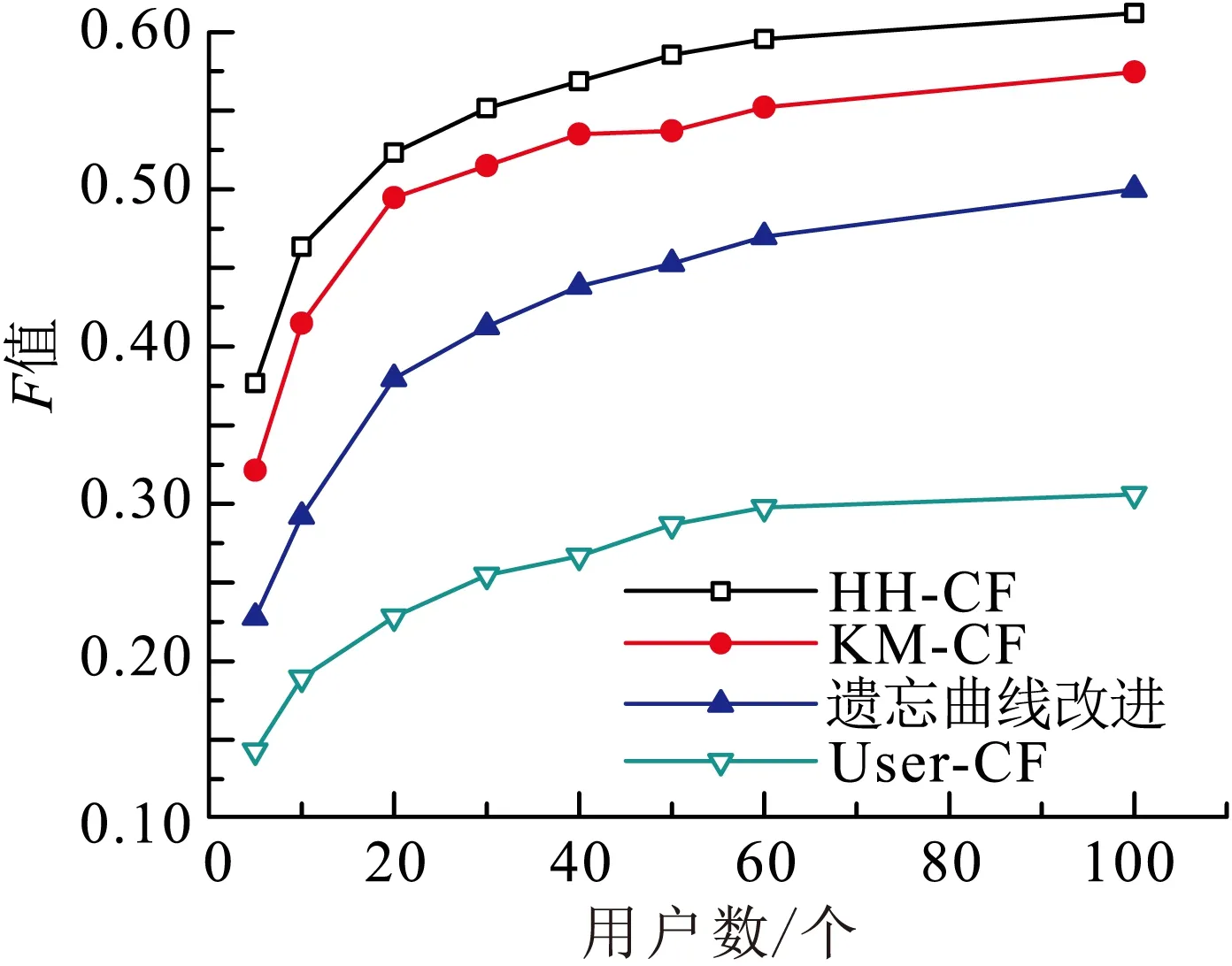
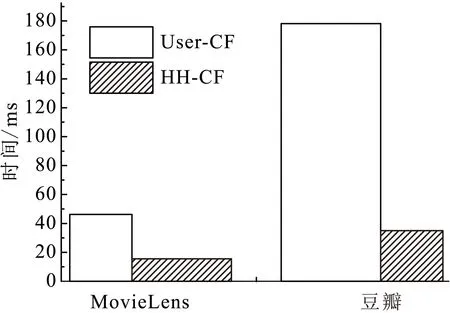
ri,j=r0+r1e(t-t0 (1) 其中,t表示当前时间,ri,j表示在t时第i用户ui对第i资源resj的偏好值(当由式(1)计算ri,j>5时,我们默认ri,j5),r0表示ui在t的最小偏好值,r1表示在t0时ui对resj的偏好值,表示ui对resj的遗忘因子,T表示该计算公式的有效时间. 最小偏好r0用于调整用户对资源的偏好. 例如,当该资源刚上线,或当前为热销时期,系统把其设置为更大值. 动态调整r0,可以解决资源的冷启动性问题. 本文采用一维向量的方式来表示:r0=[r1,r2,r3,…,rn]. 1.2 基于聚类算法的改进 本文提出了一种改进的K-Means算法来缓解数据稀疏性和高维度问题. 通过减少干扰用户量,降低数据维度和缓解数据稀疏性. 用户集合U={u1,u2,…,um},其中ui=(ri1,ri2,…,rin),K-Means主要把数据集分解为k个相似用户簇(k K-Means计算流程: 步骤1:在U中选出k个用户作为簇中心,表示为C={C1,C2,…,Ck},其中Cj=(cj1,cj2,…,cjn). 步骤2:遍历U,利用欧式距离计算用户与簇中心的距离: 将每个用户划分到最近簇内. 步骤3:计算簇的均值点,把其替换成新的簇中心. 例如,簇Si={u1,u2,…,ua},ui=(ri1,ri2,…,rin),求取簇新中心Cj: 步骤4:重复步骤2、3,直到聚类结果不再变化. 判定目标函数是否不再变化作为结束标志. 目标函数定义为: 由K-Means算法计算可以得到k个用户簇,每个簇表示具有相似偏好的用户集合. 改进的K-Means算法的具体计算流程如下: (1)对U={u1,u2,…,um},随机选取一个用户作为初始簇中心C1,加入C={C1}; (2)以C1为起点,分别计算得出离C1距离最大的用户,得到C2,加入C={C1,C2}; (3)以C1、C2为目标点,计算得到C3距离两点最大,C={C1,C2,C3}; (4)循环K次,以C={C1,C2,…,Cj}为目标点,计算得到Cj+1距离C集合最大,加入C={C1,C2,…,Cj+1}. 计算距离最大值公式为: (2) 其中, 式(2)使用了乘积计算方式,可以有效解决中心点集和其他簇中心相邻近的干扰问题. 如使用加法方式计算,特殊情况时则不能保证簇中心是分离的状态. 1.3 基于推荐算法的改进 考虑到推荐算法推荐效率不佳与多样性等问题,提出了改进的推荐模型,如图2所示. 图2 HH-CF模型Figure 2 HH-CF model 1.3.1 引入算法 基于用户协同推荐算法User-CF的计算流程[13-15]如下: (1)根据系统中已有的用户信息、资源信息和用户历史偏好信息等数据,生成用户偏好矩阵; (2)根据用户偏好矩阵计算用户间的相似度,查找出与目标用户相似的用户集; (3)根据相似用户的偏好,利用推荐算法计算用户对未评分资源进行预测评分,向用户推送top-N个资源. 物质扩散算法、热传导算法分别根据下式计算得出: (3) (4) 其中,k(resc)为网络拓扑图中resc的度,k(ui)为网络拓扑图中ui的度,eijE,r(resc)表示resc的初始值,W(resi)表示resi的权重值,R(resi)表示resi的权重值,通过排名对资源进行推送. 由式(3)可知,资源节点度越大,其值越大,因此,物质扩散算法更偏向推荐热门的资源对象;由式(4)可知资源节点度越小,其值越大,因此,热传导算法更偏向推荐冷门资源对象. 1.3.2 改进的推荐模型 改进的推荐模型(图3)加入MD算法和HS算法,可以增加用户推荐流行和冷门资源对象的概率,提高推荐效率和多样性. 具体流程如下: 步骤1:根据数据集构造网络拓扑结构图,用二分图来表示,并设置初始的资源评分集合R向量. 步骤2:根据物质扩散和热传导算法计算对应的权重值W(i)和R(i),计算资源的调优权重值S(i). S(i)=, (5) 步骤3:根据步骤2得到的调优权重值来优化调整推荐算法得到的预测值: (6) 其中,KMCF(u,i)表示引入K-Means算法改进的User-CF算法进行计算得到的用户评分预测值,δ为权重因子,实验不断拟合计算,找到使算法推荐效果最优的δ. 步骤4:对预测值R(u,i)进行排序,为用户推送top-N个资源集合. 本节主要介绍实验数据集、实验评价标准和实验设计过程,最后给出对比实验、分析实验结果、得出实验结论. 2.1 数据集与评价标准 2.1.1 实验数据集 本实验采用标准的电影评分数据集MovieLens和豆瓣电影评分大规模数据集,数据集划分70%为训练集、30%为测试集,衡量推荐精度的指标采用F评价指标. 数据集详细介绍见表1. 表1 数据集Table1 Data sets 2.1.2 评价标准 本实验采用F值为评价标准. 评价标准精准率(precision)、召回率(recall)和F值计算公式如下: 其中,A表示有效的推荐结果,B表示未被推荐的相关文档,C表示无效的推荐结果. 2.2 算法推荐效果比较 该实验数据集采用0.1 K规模大小的MovieLens数据集. 通过借助基于用户的协同过滤推荐算法(User-CF)进行以下4组有效实验,分别验证本文提出的改进模型的有效性,算法模型中的其他参数值均设置为使算法模型达到效果最优时的相应值. 图3 遗忘因子比较Figure 3 Comparison of forgetting factor 实验2:分别设置聚类簇个数k=5、k=8和k=10,比较通过K-Means聚类后进行User-CF算法的推荐效果,实验结果见图4. 图4 聚类簇数比较Figure 4 Comparison of cluster number 实验3:分别设置权重因子δ=0.7、δ=0.8和δ=0.9,比较HH-CF算法推荐效果,实验结果见图5. 图5 权重因子比较Figure 5 Comparison of weight factor 实验4:实验参数设置最优时,比较HH-CF与User-CF算法的推荐效果,实验结果见图6. 图6 算法效果比较Figure 6 Comparison of algorithm performance 从实验结果可以得到以下结论: (1)最近邻用户越多,算法的推荐效率越好. (3)在设置参数使算法效果最佳时,该模型得到的推荐效率优于传统推荐算法. 通过上述实验结果验证,在本文实验环境下,基于动态时间的个性化推荐模型(HH-CF)优于传统推荐算法. 2.3 算法性能比较 该实验主要用于比较本文提出的算法模型计算时间性能的大小. 利用2组大小规模不同的数据集,比较HH-CF和User-CF算法为用户进行推荐需要的平均时间. 由图7可知基于动态时间的个性化推荐模型(HH-CF)比传统User-CF算法时间性能更好,极大地降低计算复杂度,进行推荐计算时,可以减少计算花费的时间. 在大规模的数据集中,能够更加明显地减少推荐算法计算的时间,极大地解决用户个性化体验问题. 图7 不同数据集的时间效率比较Figure 7 Comparison of time efficiency of different data sets 2.4 实验总结 本文实验对HH-CF算法模型进行有效地验证,分别比较参数为何值时,HH-CF算法的推荐质量最好. 并在不同数据集下比较算法的时间性能,验证了HH-CF算法的有效性. 因此,本文提出的基于动态时间的个性化推荐模型能够有效地减少计算的复杂度、降低数据维度和提高推荐算法的质量. 本文深入研究了个性化推荐算法,提出一种基于动态时间的个性化推荐模型,并通过实验证明其推荐效果明显优于传统推荐算法. 该模型是通过引入遗忘曲线来获取准确的用户偏好信息,然后利用改进的K-Means对用户聚类,降低推荐算法计算的空间维度,最后根据改进的推荐算法来实现个性化推荐. 但是,面对当前时代的要求,其个性化推荐系统还有一些需要亟待解决的问题: (1)实时有效推荐. 在大数据时代,需要处理海量化的数据,需要准确快捷地为用户提供服务. (2)多样化推荐. 由于用户的潜在需求越来越大,推荐系统需要提供更多用户可能感兴趣的资源集合,才能满足用户的需求. [1] CHEN L. Personality in recommender systems[C]∥Proceedings of the 3rd Workshop on Emotions and Personality in Personalized Systems. New Yord:ACM,2015:16-20. [2] NUNES M A S N,HU R. Personality-based recommender systems:an overview[C]∥Proceedings of the Sixth ACM Conference on Recommender Systems. New York:ACM,2012:5-6. [3] 于洪,李俊华. 一种解决新项目冷启动问题的推荐算法[J]. 软件学报,2015,26(6):1395-1408. YU H,LI J H. Algorithm to solve the cold-start problem in new item recommendations[J]. Journal of Software,2015,26(6):1395-1408. [4] KOREN Y. Collaborative filtering with temporal dynamics[C]∥Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New Yord:ACM,2009:447-456. [5] JONNALAGEDDA N,GAUCH S. Personalized news re-commendation using twitter[C]∥Proceedings of the 2013 IEEE/WIC/ACM International Joint Conferences on Web Intelligence. Washington,DC:IEEE,2013:21-25. [6] KRESTEL R. Recommendation on the social web:diversification and personalization[C]∥Proceedings of the 2011 International Workshop on DETecting and Exploiting Cultural DiversiTy on the Social Web. New York:ACM,2011:1-2. [7] GUAN Y,ZHAO D,ZENG A,et al. Preference of online users and personalized recommendations[J]. Physica A: Statistical Mechanics & Its Applications,2013,392(16):3417-3423. [8] SALEHI M,KAMALABADI I N. Hybrid recommendation approach for learning material based on sequential pattern of the accessed material and the learner’s preference tree[J]. Knowledge-Based Systems,2013,48:57-69. [9] ZHANG Y F. Daily-aware personalized recommendation based on feature-level time series analysis[C]∥Proceedings of the 24th International Conference on World Wide Web. Florence,Italy:[s.n.],2015:1373-1383. [10]NAYAK R,ZHANG M,CHEN L. A social matching system for an online dating network:a preliminary study[C]∥Proceedings of the 2010 IEEE International Conference on Data Mining Workshops. Washington,DC:IEEE,2010:352-357. [11]WANG T,LIU H,HE J,et al. Predicting new user’s behavior in online dating systems[M]∥Advanced Data Mi-ning and Applications. Berlin:Springer,2011:266-277. [12]AVERELL L,HEATHCOTE A. The form of the forgetting curve and the fate of memories[J]. Journal of Mathematical Psychology,2011,55(1):25-35. [13]GARCIN F,ZHOU K,FALTINGS B,et al. Personalized news recommendation based on collaborative filtering[C]∥Proceedings of the 2012 IEEE/WIC/ACM International Joint Conferences on Web Intelligence and Intelligent Agent Technology. Washington,DC:IEEE,2012:164-173. [14] 丁浩,戴牡红. 基于用户评分和遗传算法的协同过滤推荐算法[J/OL]. 计算机工程与应用,2015:6pp. (2015-08-31)[2016-02-25]. http:∥d.g.wanfangdata.com.cn/Periodical_pre_c6cf658e-83f1-498f-8bd3-230dbb8cb6e8.aspx. DING H,DAI M H. Collaborative filtering recommendation algorithm based on user ratings and genetic algorithm[J]. Computer Engineering and Applications,2015:6pp. (2015-08-31)[2016-02-25]. http:∥d.g.wanfangdata.com.cn/Periodical_pre_c6cf658e-83f1-498f-8bd3-230dbb8cb6e8.aspx. [15]CACHEDA F,CARNEIRO V,FERNNDEZ D,et al. Comparison of collaborative filtering algorithms:limitations of current techniques and proposals for scalable,high-performance recommender systems[J]. ACM Transactions on the Web,2011,5(1):161-171. [16] ZHANG Y C,MEDO M,REN J,et al. Recommendation model based on opinion diffusion[J]. Europhysics Letters,2007,80(6):417-429. [17] ZHANG Y C,BLATTNER M,YU Y K. Heat conduction process on community networks as a recommendation model[J]. Physical Review Letters,2008,99(15):12505-12508. 【中文责编:庄晓琼 英文编校:肖菁】 PersonalizedRecommendationModelBasedonDynamicTime TAN Lili1, NIE Ruihua1*, LIANG Jun2, WANG Jinhong3 (1. School of Computer Science, South China Normal University, Guangzhou 510631, China;2. Network Center, South China Normal University, Guangzhou 510631, China; 3. Bei Ming Software Co., Ltd., Guangzhou 510663, China) In the recommendation systems, it often exists some problems of non-real-time data, sparse data and cold start. First, the forgetting curve is used to track the changed of user’s interests with time, and then an improved K-Means clustering algorithm is put forward to cluster users, and finally uses the improved personalized re-commendation algorithm. A model of personalized recommendation based on dynamic time is built. The experimental results show that the proposed personalized recommendation model can get more accurate recommendation perfor-mance and alleviate the cold start problem. It also can reduce the computing time and space complexity, and improve the quality of the recommendation of personalized recommendation algorithm. personalization; forgetting curve; K-Means; material diffusion; heat conduction 2016-03-15 《华南师范大学学报(自然科学版)》网址:http://journal.scnu.edu.cn/n 教育部-中移动基金项目(MCM20130651);广州市科技和信息化局基金项目(2014Y2-00006) TP A 1000-5463(2017)03-0123-06 *通讯作者:聂瑞华,教授,Email:nrh@scnu.edu.cn.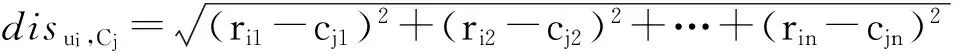
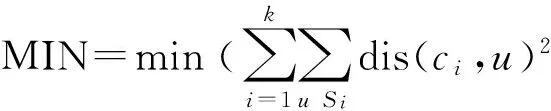
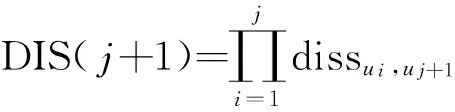
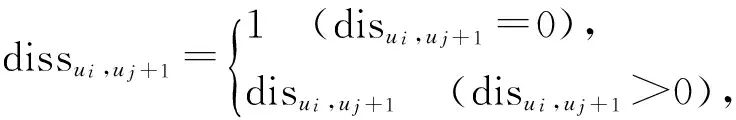

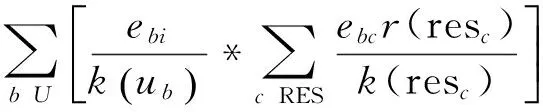

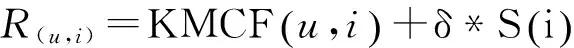
2 算法验证与结果分析

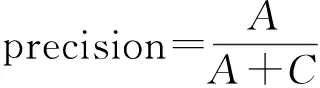
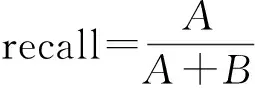


3 总结
猜你喜欢
卫星应用(2022年7期)2022-09-05 02:36:02卫星应用(2022年3期)2022-05-23 13:44:30卫星应用(2022年1期)2022-03-09 06:22:20文苑(2020年4期)2020-05-30 12:35:12环球慈善(2019年6期)2019-09-25 09:06:24新闻传播(2018年12期)2018-09-19 06:27:10电子测试(2017年15期)2017-12-18 07:19:27汽车与新动力(2016年6期)2017-01-04 10:50:48智能系统学报(2015年4期)2015-12-27 09:38:39电子设计工程(2015年6期)2015-02-27 12:04:53
