
基于UR-LDA的微博主题挖掘
2017-06-27 08:14赵海博
计算机技术与发展 2017年6期
陈 阳,邵 曦,赵海博
(1.南京邮电大学 通信与信息工程学院,江苏 南京 210003; 2.软通动力信息技术有限公司,浙江 杭州 310000)
基于UR-LDA的微博主题挖掘
陈 阳1,邵 曦1,赵海博2
(1.南京邮电大学 通信与信息工程学院,江苏 南京 210003; 2.软通动力信息技术有限公司,浙江 杭州 310000)
以微博为代表的社交网络已经成为用户发布和获取实时信息的重要手段,然而这些实时信息中很大一部分都是垃圾或者是冗余的信息。通过有效的手段,精准地发现、组织和利用社交网络海量短文本背后隐藏的有价值的信息,对微博中隐含主题的挖掘,具有较高的舆情监控和商业推广价值。尽管概率生成主题模型LDA(Latent Dirichlet Allocation)在主题挖掘方面已经得到了广泛的应用,但由于微博短文本消息语义稀疏以及文本之间相互关联等特点,传统的LDA模型并不能很好地对它进行建模。为此,基于LDA模型,综合考虑微博的文本关联关系和联系人关联关系,提出了适用于处理微博用户关系数据的UR-LDA模型,并采用吉布斯抽样对模型进行推导。真实数据集上的实验结果表明,UR-LDA模型能有效地对微博进行主题挖掘。
微博;主题挖掘;UR-LDA;吉布斯抽样
1 概 述
微博,微型博客(Micro Blog)的简称,是Web2.0时代兴起的一种新型社交网络形式,以其开放性、交互性、自由性和及时性而风靡全球。微博基于用户之间的关联关系,构建了一个海量信息分享、传播和获取的平台。用户可以通过网络,移动设备和其他客户端软件登录微博,进行短文本信息的实时获取或更新。据新浪微博财报显示,新浪微博日活跃用户数(DAU)达到1.06亿,在2016年第一分钟发出去的微博信息高达883 536条。
用户通过微博网站构建的平台可以发布海量信息。但微博用户人群构成多样,文本内容口语化,主题随意性强,语法缺少规范。据统计发现,超过50%的微博内容为情感语录、个人心情等,因此,微博文本噪声占比高。在信息爆炸的时代,通过有效的手段从海量的短文本中挖掘出有效的主题信息就显得尤为重要。优质的主题挖掘对情感分析系统、舆情监控系统以及大数据预警系统的发展具有极大的推动作用。
传统的微博主题挖掘算法按照其输入数据的种类,主要分为以下三类:基于网络关系的微博主题挖掘、基于用户标签或文本内容的微博主题挖掘、结合用户文本内容、网络关系的微博主题挖掘。
M.E.J.Newman等[1]提出的算法是基于网络关系的社交网络主题挖掘方法的典型代表。该算法认为移除不同主题之间的连接边就能较好地将社交网络分割成不同的主题[1]。
文献[2]提取用户标签,将各个用户兴趣特征向量化,最后对用户兴趣特征向量聚类进行主题挖掘。在该算法中,用户标签不完整及口语化会严重影响最终的聚类效果。
文献[3]利用一种正规化框架,结合用户关系和用户文本内容进行社交网络主题挖掘。
Blei等[4]提出了概率主题模型LDA,即“文档—主题—词”三层贝叶斯模型,为社交网络主题挖掘提供了新的思路。
汪进祥[5]利用LDA主题模型与中文标注相结合进行微博话题挖掘。
但是未经修改,LDA主题模型一般适用于新闻等经过初次加工的语料,而微博是短文本(字数通常小于140),语义信息稀疏,噪声大,文本语言口语化,极大地增加了对其主题挖掘的难度[6];另一方面,转发型微博文本和对话型微博文本从形式上说明微博文本之间是相互关联的,与传统LDA模型假设文本之间相互独立是矛盾的。以上特性说明微博主题挖掘不能简单套用传统的LDA模型。基于LDA,结合微博文本的特性,提出了一种适合中文微博主题挖掘模型UR-LDA。
2 文本生成模型LDA
2.1 LDA模型
LDA主题模型继承自LSA[7]和PLSA[8]方法,在文档—单词引入“主题”的概念,形成了“文档—主题—词”的三层贝叶斯模型[9]。在LDA模型中,文本m可以表示成多个主题的联合分布,记为P(z),每个主题又是词汇表中所有单词上的概率分布,记为P(w|z)。因此,文本中每个单词的概率分布为:
(1)
其中,K为主题个数;i∈[1,Nm],Nm为数据集中所有单词的个数。
同时,LDA模型是一个完备的主题模型,词语符合“词袋模式”,即在文档的生成过程中,不同词语之间相互独立,顺序无关,模型引入Dirichlet分布,只需要分别设置超参数α和β就可以表示文档m与主题的关系θm以及主题k与词语的关系φk,实现文档—主题和主题—词语之间参数的精简。LDA模型的文本生成模型如图1所示。
(1)根据先验参数为α的Dirichlet分布,随机抽取每篇文档的混合主题概率θm。
(2)根据先验参数为β的Dirichlet分布,随机抽取各个词语在主题k下出现的概率φk。
(3)针对每篇文档m中的每一个待生成的词wm,n:
①根据θm抽取当前单词所代表的主题zm,n。
②根据p(wm,n|φk,zm,n)抽取具体的单词wm,n。
一个文本中所有单词与其所属主题的联合概率分布,如式(2)所示:
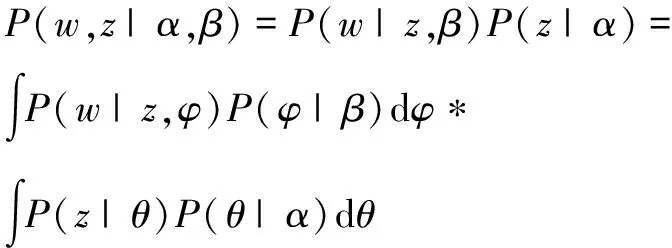
(2)
2.2 吉布斯抽样法
吉布斯抽样法是一种简单的蒙特卡洛算法实现,经常用来进行LDA模型概率推导。该方法的思想是[10]:对于已知概率分布π(x),x=(x1,x2,…,xn)(通常称为目标分布),如果π太过复杂以致不能直接从它抽样,可以通过构造一个非周期且不可约的马尔可夫链来间接获取样本。由于模拟的数值可以被视作是来自目标分布的独立样本,当马尔可夫链足够长时,就可以用其稳态分布来推断π的重要特征。具体过程如下:
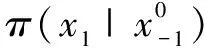
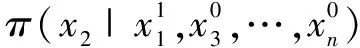

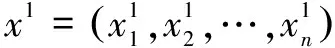
3 微博主题挖掘
3.1 微博生成模型UR-LDA
从微博消息的发布形式可以看出,微博不同于一般文本,本身带有表征文本之间关联关系的信息,如:转发型微博中含有“//@”,对话型微博含有“@”。其中,转发型微博的文本内容由当前用户和其他用户发布原创微博共同组成,往往用于当前用户对转发部分的评论,可以通过“//@”把原创部分和转发部分隔离开来。例如,“好样的!//@陈阳:林说会以马努为榜样,说会无视交易流言,已经习惯了”。其中“//@”之前的是原创内容,“//@”之后的转发内容,“@陈阳”表示转发部分的作者是陈阳。转发型微博的主题主要取决转发部分而不取决于微博发布者,而且当微博发布者原创部分的内容不包含能够表征任何有意义主题的词时,可以将其忽略。对话型微博含有特定的提醒或者发送对象,如“@JeremyLin林书豪一直被你的精神鼓舞着,前进着!”,“@JeremyLin林书豪”表示该条微博所要发送的对象是JeremyLin林书豪。这种类型的微博体现了微博文本联系人之间的关联关系。
UR-LDA是在研究LDA的基础上,综合考虑微博文本关联关系和联系人关联关系以及微博短文本特性,形成适合中文微博主题挖掘的模型。在UR-LDA模型中,一条微博如果是转发微博,其主题由当前用户原创部分和转发部分共同确定;如果是对话型微博,其主题由该条微博发送对象中所有与当前微博相关的微博共同确定。其中发送对象中的相关微博是指,发送对象发布的,含有当前微博关键字的微博。
UR-LDA模型的参数介绍见表1。

表1 模型符号定义说明
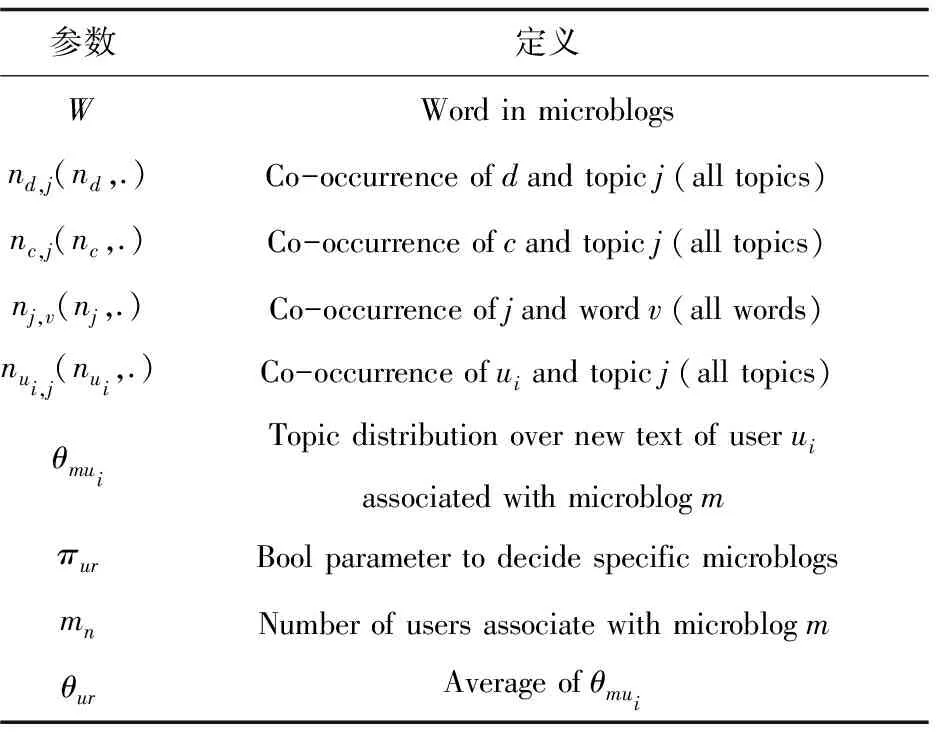
续表1
UR-LDA模型的贝叶斯网络图如图2所示。
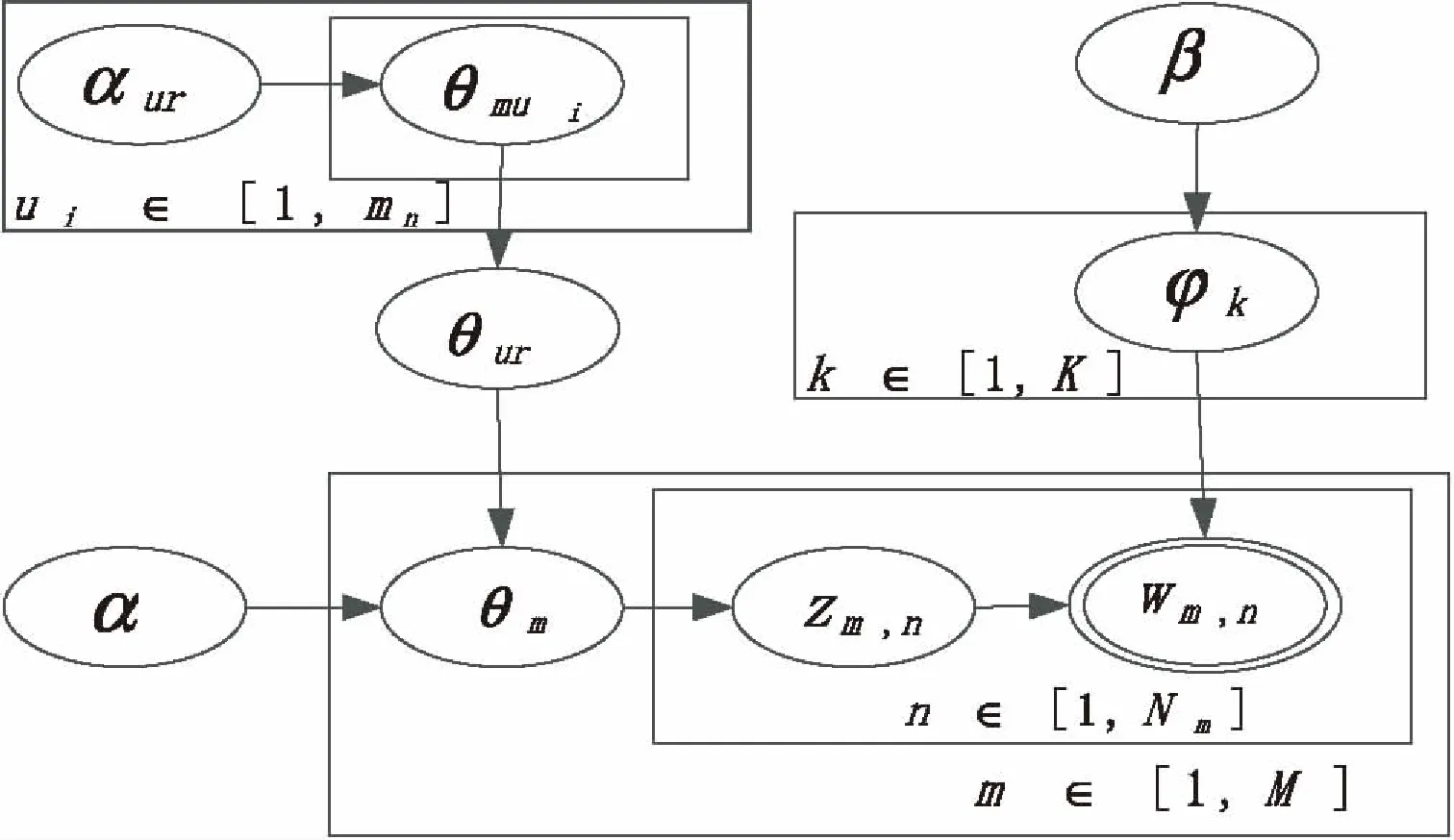
图2 UR-LDA模型
(1)UR-LDA从参数为β的Dirichlet分布中抽取主题k与单词的关系φk。
(2)通过正则表达式[//\s*?@.*?:]过滤掉微博文本中与转发相关的特殊字符,仅保留用户原创部分和转发部分。
(3)针对包含“@”文本:
①通过正则表达式[@(.+?)\s+]找出该文本所有与“@对话对象名”相匹配的字符串,提取相应的对话对象名并利用中科院的ICTCLAS提取当前文本的关键字。
②遍历①中所有的对话对象,找出每个对象发布的含有①中提取的关键字的微博。为降低微博短文本语义稀疏对主题挖掘效果的影响,将同一会话对象中找到的相关微博存入到一个文件中,作为一个新的文本。
③利用传统的LDA模型,根据先验参数为αur的Dirichlet分布,随机抽取②中各个会话对象的新文本的混合主题概率θmui,并对其求均值,记为θur,置πur为1(πur初始值为0)。θur的计算公式为:
(3)
其中,N为①中得到对话对象的总数;θur为每个会话对象生成的新文本在各个主题上的概率分布。
(4)判断πur的取值,若πur=1,则将求得的θur赋给微博m与各个主题之间的关系θm;否则直接从参数为α的Dirichlet分布中抽取该微博m与各个主题之间的关系θm。整个微博集中,θm的概率分布为:
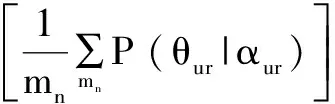
(4)
一条微博中,所有单词与其所属主题的联合概率分布为:
P(w,z|θm,β)=P(z|θm)P(w|z,β)
(5)
3.2 模型推导
用Gibbs Sampling对UR-LDA模型进行推导,其过程如下:
(1)利用欧拉公式对式(2)进行展开:

(6)

(7)
(2)对式(7)反复迭代,并对所有主题进行抽样,最终达到抽样结果稳定。由于抽取单词和抽取主题都满足多项式分布,θm和φk的结果分别如下:
(8)
(9)
类似的,可以得到θmui:
(10)
对θmui求均值,得到θur:
(11)
至此,UR-LDA模型通过吉布斯抽样求解出微博文本在各个主题上的概率分布θm以及每个主题在单词上的概率分布φk。对整个微博集进行分析,通过概率计算,就可以挖掘出单个微博文本最有可能属于哪个主题,每个主题最具代表性的单词。
4 主题挖掘实验
4.1 数据准备
4.1.1 新浪微博数据采集
微博数据采集是微博主题挖掘的基础。目前微博数据的获取主要有两种方式,即网络爬虫技术和新浪微博提供API接口获取数据,但这两种方式都存在一定的问题。
目前许多网页都采用了Ajax[11]技术,利用JavaScript动态生成网页,爬虫技术很难爬取到完整的网页数据。由于微博平台的不开放性,新浪对API的调用有诸多限制,使用微博开放的API接口的方式并不能满足大规模数据需求的情况。因此,在实验过程中,可以将两者结合,在多台机器上进行采集,获取大量完整的微博数据。最后将获取到的微博数据进行格式化,保存为json格式或者保存到关系型数据库中。
将网络爬虫技术和新浪微博API接口获取数据方式进行结合,共获取1 894个新浪微博用户214 870条微博数据,将这些数据存入MySQL数据库作为实验数据,利用UR-LDA模型对其建模。
4.1.2 数据预处理
在获得原始数据后,通常需要进行数据预处理,提高数据的可靠性。实验室针对中文微博的主题挖掘,通过以下步骤优化数据源。
(1)去掉微博文本中不能体现任何有意义主题的文本,如不包含任何汉字的文本。
(2)通过正则表达式[//\s*?@.*?:]过滤掉微博文本中与转发相关的特殊字符。
(3)对微博文本长度小于10的微博进行删除。
(4)通过正则表达式[@(.+?)\s+]取出微博文本所有会话联系人,以“@[会话联系人1,会话联系人2,…,会话联系人n]”的形式写在当前微博文本的前面,并以空格将两者隔开。
(5)设置白名单词典、用户词典及停用词表。
白名单词典[12]是为了防止一些有意义的词被当成噪声而设置的,如:KTV。
用户词典是为了防止一些人名和固定词被无意义分割而设计的,如“成龙”。
停用词是指没有实际主题含义的词,如“十分”、“非常”、“特别”等。设计停用词表,主要是为了去除微博文本中的停用词。
(6)通过ICTCLAS[13]进行分词处理,过滤掉微博中不属于白名单词典的所有单个汉字,非汉字词语,停用词,地点以及特殊字符等影响主题挖掘实验的词。
4.1.3 实验环境
实验环境为Intel(R) Pentium(R)4 3.00 GHz 的CPU,4 G内存,160 GB硬盘的PC机,操作系统为Win8,实验工具为JetBrains PyCharm 2016.1.2。
4.2 UR-LDA模型参数
模型参数参考文献[14]中的方法进行设置。取经验值α=αur=50/K,β=0.01,K=60,其中K是整个数据集上的主题总数。
4.3 实验结果
4.3.1 整体效果
选取UR-LDA模型的主题挖掘前4个主题社区的结果,如图3所示。
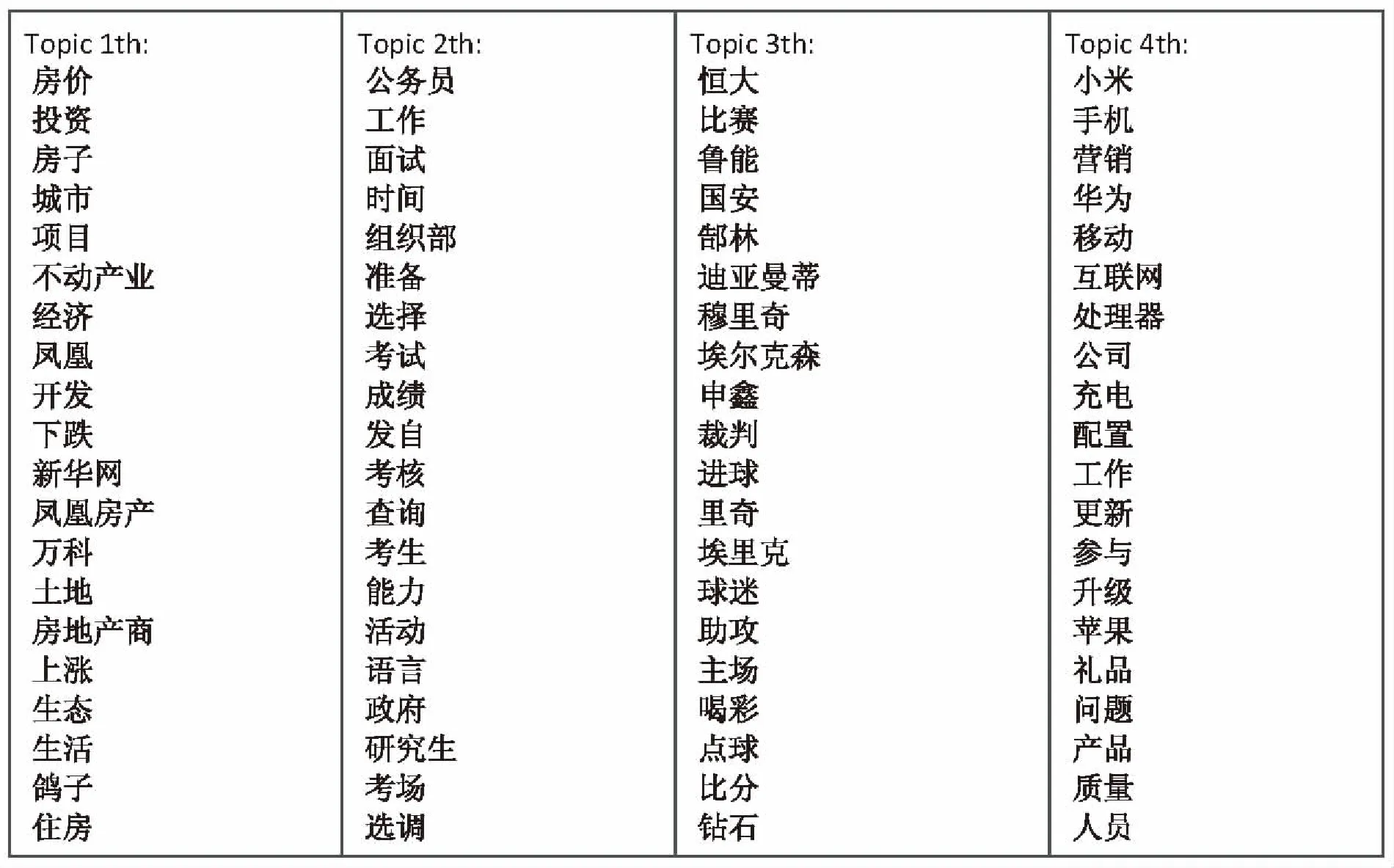
图3 UR-LDA模型部分效果图
图中,每个主题选择了20个关键词进行表征,关键词是按照其在主题下的分布概率由高到低显示。
根据各个主题相对应的关键词可以发现Topic 1是与房价相关的主题,Topic 2是与公务员相关的主题,Topic 3是与足球相关的主题,Topic 4是与手机产品相关的主题。不同主题的关键词都能有效表征当前主题,说明主题的关键词分类合理,主题之间的独立性比较高。
4.3.2 对比实验
在研究主题模型时,可以使用困惑度(perplexity)指标对模型进行评估。perplexity是度量概率图模型性能的常用指标[14],它表示了预测数据时的不确定度,该值越小,模型建模效果越好[15]。计算公式[16-17]如下:
(12)
其中,w为微博数据集;wm为在数据集中出现的单词;Nm为测试集中出现的词语总数。
在相同参数下,分别计算传统LDA模型和UR-LDA模型的perplexity,结果如图4所示。
从图中可以看出,随着迭代次数的增加,直到模型趋于收敛,UR-LDA模型的perplexity都要小于传统的LDA模型,说明UR-LDA模型在测试数据上具有更好的建模效果。
5 结束语
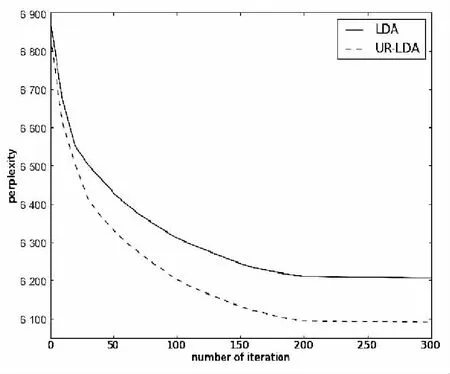
图4 模型困惑度对比图
针对新浪微博短文本语义稀疏以及文本之间相互关联的特点,提出了一种适合处理微博用户关系数据的UR-LDA模型,并采用吉布斯抽样对模型进行推导。在真实的数据集上进行实验,结果证明UR-LDA较传统的LDA主题模型有更好的主题挖掘效果。
虽然UR-LDA模型能够较有效地对微博进行主题挖掘,但也有一定的局限性[18]。通过新浪微博,也可以发布音乐、视频、图片等多媒体信息,而不再是单纯的文字信息。今后的研究工作主要集中在处理微博中的多媒体数据,增强主题模型挖掘能力等方面。
[1] Girvan M,Newman M E J.Community structure in social and biological networks[J].PNAS,2002,99(12):7821-7826.
[2] Li Xin,Guo Lei,Zhao Yihong.Tag-based social interest discovery[C]//Proceedings of the 17th international conference on world wide web.[s.l.]:[s.n.],2008:675-684.
[3] Mei Qiaozhu,Cai Deng,Zhang Duo,et al.Topic modeling with network regularization[C]//Proceedings of the 17th international conference on world wide web.[s.l.]:[s.n.],2008:101-110.
[4] Blei D M,Ng A Y,Jordan M I.Latent Dirichlet allocation[J].Journal of Machine Learning Research,2003,3:993-1022.
[5] 汪进祥.基于主题模型的微博话题挖掘[D].北京:北京邮电大学,2015.
[6] Kang J H,Lerman K,Plangprasopchok A.Analyzing Microblogs with affinity propagation[C]//Proceedings of the KDD workshop on social media analytics.New York:ACM,2010:67-70.
[7] Deerwester S,Dumais S,Landauer T,et al.Indexing by latent semantic analysis[J].Journal of the American Society of Information Science,1990,41(6):391-407.
[8] Hofmann T.Probabilistic latent semantic indexing[C]//Proceedings of the 22nd annual international ACM SIGIR conference on research and development in information retrieval.New York:ACM,1999:50-57.
[9] Nallapati R M, Ahmed A, Xing E P,et al.Joint latent topicmodels for text and critations[C]//Proceedings of the 14th ACM SIGKDD international conference on knowledge discovery and data mining.[s.l.]:ACM,2008:542-550.
[10] 李 明,王占宏,鲁 明.基于J2EE框架的混合模式治安管理信息系统研究与应用[J].计算机工程,2003,29(1):252-252.
[11] Garrett J J.Ajax:a new approach to web applications[EB/OL].(2005-02-18)[2011-02-18].http://www.adaptivepath.com/publications/essays/archives/000385.php.
[12] 郭剑飞.基于LDA多模型中文短文本主题分类体系构建与分类[D].哈尔滨:哈尔滨工业大学,2014.
[13] Thomas H.Probabilistic latent semantic indexing[C]//Proceedings of SIGIR.Berkeley,CA,USA:[s.n.],1999:50-57.
[14] Griffiths T,Steyvers M.Probabilistic topic models[M]//Latent semantic analysis:a road to meaning.Hillsdale,NJ:Laurence Erlbaum,2006.
[15] Philp R,Eric H.Gibbs sampling for the uninitiated[R].[s.l.]:[s.n.],2010.
[16] 张晨逸,孙建伶,丁轶群.基于MB-LDA模型的微博主题挖掘[J].计算机研究与发展,2011,48(10):1795-1802.
[17] 胡吉明,陈 果.基于动态LDA主题模型的内容主题挖掘与演化[J].图书情报工作,2014,58(2):138-142.
[18] Ma D,Rao Lan,Wang Ting.An empirical study of SLDA for information retrieval[J].Information Retrieval Technology,2011(1):84-92.
Microblog Topic Mining Based on UR-LDA
CHEN Yang1,SHAO Xi1,ZHAO Hai-bo2
(1.College of Communication & Information Engineering,Nanjing University of Posts and Telecommunications,Nanjing 210003,China; 2.Isoftstone Information Technology (Group) Co.,Ltd.,Hangzhou 310000,China)
Social network in particular microblog has become a significant way for users to propagate and retrieve information.However,a large proportion of the real time information is junk or redundant.So the discovery of latent topics in social networks through finding,organizing and using valuable information behind the mass passage with effective ways carries high value in public option monitoring and commercial promotion.Although probabilistic generative topic model (Latent Dirichlet Allocation,LDA) has been widely applied in the field of topics mining,it cannot work well on microblog,which contains little information and has connection with others.A novel probabilistic generative model based on LDA,called UR-LDA,has been proposed which is suitable for modeling the micro-blog data and taking the document relation and user relation into consideration to help mining in micro-blog.A Gibbs sampling implementation for inference the UR-LDA model has been also presented.Experimental results used with actual dataset show that UR-LDA can offer an effective solution to topic mining for microblog.
microblog;topic mining;UR-LDA;Gibbs sampling
2016-05-23
2016-09-14 网络出版时间:2017-03-13
国家自然科学基金青年基金(60902065)
陈 阳(1992-),女,硕士研究生,研究方向为社交网络主题挖掘;邵 曦,博士,副教授,研究生导师,研究方向为多媒体信息处理系统。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170313.1545.016.html
TP31
A
1673-629X(2017)06-0173-05
10.3969/j.issn.1673-629X.2017.06.036
猜你喜欢
作文大王·低年级(2022年3期)2022-03-19
魅力中国(2020年23期)2020-07-19
时代英语·高二(2018年7期)2018-12-03
时代英语·高二(2018年3期)2018-06-06
电机与控制学报(2018年9期)2018-05-14
小学生作文·小学低年级适用(2018年12期)2018-04-11
科技视界(2016年19期)2017-05-18
科学家(2016年3期)2016-12-30
校园英语·下旬(2016年2期)2016-03-18
阅读与作文(英语高中版)(2013年12期)2013-12-11
