
基于多叉树确定K值的动态K-means聚类算法
2017-06-27 08:14鲍黎明
计算机技术与发展 2017年6期
鲍黎明,黄 刚
(南京邮电大学 计算机学院,江苏 南京 210003)
基于多叉树确定K值的动态K-means聚类算法
鲍黎明,黄 刚
(南京邮电大学 计算机学院,江苏 南京 210003)
K-means聚类算法是基于划分的经典聚类算法之一,因其简洁、高效得到了广泛的应用。K-means算法具有容易实现、时间和空间复杂度较小的优点。但该算法的初始聚类数K通常不能通过有效的手段事先确定,其初始聚类中心往往是随机选取的,易收敛于局部最优解,造成聚类结果的不准确。基于多叉树确定K值的动态K-means聚类算法是对传统算法的改进,力求在迭代过程中动态分裂合并簇来确定最合理的聚类数,并且能在一定程度上解决聚类结果收敛于局部最优解的问题。文中还探索了相应的数据模型以支持所改进算法的研究,并从横向与纵向两方面与二分K-means算法作了对比实验。实验结果表明,改进后的K-means算法不依赖于全局数据集,更适用于分布式平台运算;算法相对效率随着数据集规模的增大,特别是在洪量数据集下具有明显的优势。
K-means;聚类;分裂;合并;多叉树
0 引 言

(1)设定簇内相似度λ和簇间相似度γ两个阈值。
(2)在所选数据集上运行二分K均值聚类算法,得到两个类C1和C2,计算C1和C2的簇内相似度λ',若λ'>λ,则继续运行二分K均值聚类算法,不断迭代以上过程,直到得到所有的簇内相似度都小于λ。
(3)计算所有簇的簇间相似度,将簇间相似度小于γ的簇合并。
(4)得到的聚类个数即为k值。
该算法通过分裂和合并两个过程,得到较为准确的聚类结果,思想较为简单。二分K均值聚类算法是改进K-means算法思想的来源。
基于多叉树确定k值的动态聚类算法是一种不依赖于初始聚类数、在聚类过程中通过分裂与合并动态地确定k值的算法。基于多叉树确定k值的动态聚类算法不同于二分K均值聚类算法的最明显表现是,在迭代开始时可以在2与N之间随机指定初始聚类数,每次迭代可以分裂合并多个类簇。
这样聚类中心数即k值在每次迭代后是动态变化的,随着聚类中心趋于稳定,最终确定的K值即为最终的聚类数目。实验结果表明,基于多叉树确定k值的动态聚类算法确定的聚类数目与实际聚类数目相同,且算法的聚类准确性得到了相应提高。
1 基本思想
传统K-means算法[6]的基本步骤为:
(1)选择k个点作为初始质心。
(2)重复以下过程:将每个点指派到最近的质心,形成k个簇;重新计算每个簇的质心。
(3)直到质心不发生变化,算法结束。
基于多叉树确定k值的动态K-means聚类算法是对传统K-means算法的改进,但也离不开核心的迭代过程。该算法对于初始聚类数和初始质心的选取要求不高,但是合理地选取初始聚类数和初始质心可以降低算法的运行时间,提高效率。初始质心的选取可以采取基于密度的方法[7]来进一步提高聚类效率,然而,为凸显基于多叉树确定k值的动态聚类算法的有效性,利用随机均匀选择初始质心的方法。改进算法的迭代过程是区别于传统聚类算法和二分K均值聚类算法的核心所在。
图1为算法思想的直观阐述。
2 算法的简单性描述
基本定义:
定义1:簇质心的计算公式为:
(1)
其中,ni为簇Ci内数据点的个数;Ii=(ii1,ii2,…,iip)为簇Ci内维度为p的数据对象。

图1 算法思想示意
定义2:两个数据对象间的欧氏距离[8]为:
d(Ii,Ij)=
(2)
其中,Ii=(ii1,ii2,…,iip)和Ij=(ij1,ij2,…,ijp)是两个p维的数据对象。
定义3:簇中所有的数据点到簇质心的距离的平均值定义为簇内相似度[9],计算公式为:
inner=
(3)
其中,ni为簇Ci内数据点的个数;I=(i1,i2,…,ip)为簇Ci内的数据元素;Wi=(wi1,wi2,…,wip)为簇Ci的质心。Inner值越小,说明簇间相似性越大;反之,则越小。
定义4:簇质心到其他簇质心的最小距离定义为簇间相似度[9],计算公式为:
ext=min‖Wi-Wj‖=
(4)
其中,Wi=(wi1,wi2,…,wip)与Wj=(wj1,wj2,…,wjp)分别为簇Ci与Cj的质心。ext的值越大说明簇间相似度越小;反之,则越大。
基本步骤为:
(1)确定初始聚类数k并随机选取初始质心(见图1(a))。
(2)将每个点指派到最近的质心,指派的标准为欧氏距离,重新计算每个簇的质心(见图1(b))。
(3)分裂簇(见图1(c))。
(4)重新计算每个簇的质心(见图1(d))。
(5)合并簇(见图1(e))。
(6)再次重新计算每个簇的质心(见图1(f))。
从算法每一次的迭代步骤中会发现除了第六步重新计算质心外,中间还有两次需要计算质心,这是因为簇的分裂和合并所依赖的簇内相似度和簇间相似度都需要明确每个簇的质心,关于分裂与合并簇的标准,下面将会详细讨论。还会发现迭代过程是先分裂簇后合并簇,这是因为,分裂后的簇也许会符合合并簇指标,先分裂后合并会适当减少迭代次数,提高算法效率。还有一个问题是如何避免已分裂的簇在合并阶段又合并在一起的问题,这个问题会让迭代无限执行下去而得不到最终的聚类结果。因此,分裂后所得到的两个簇要做标识,来避免在合并阶段,将分裂的两个簇合并。
分裂标准:算法在分裂阶段如何正确选择该分裂的簇进行分裂是一个难题,因此算法需要一个簇内相似度阈值来判断哪些簇该分裂。
(5)
(6)

图2 正态分布图
分裂算法过程:
输入:簇inner;
输出:分裂的两个簇。
Begin
(2)k=k+1
(3)选择2个点作为初始质心。
repeat
(4)将每个点指派到最近的质心,形成K个簇。
(5)重新计算每个簇的质心
until质心不发生变化
End
分裂算法具体过程其实就是将需分裂的簇视为一个原始样本点,在此簇内运用原始K-means算法进行聚类,唯一不同的是聚类数的取值为2。当然分裂后的两个簇并不能保证它们是纯簇(只包含一类样本点的簇),但是基于多叉树确定k值的动态聚类算法会在迭代过程中不断使簇的元素数据趋于单一。
因为分裂簇后会造成聚类数增加1,因此需要在原来k的基础上加1。
合并标准如下:
两个簇要合并需依次满足三个标准才可进行:所谓依次是指满足了标准一,才可以去看是否满足标准二,进而标准三。
标准一:要合并的两个簇不可以是大簇分裂后形成的两个簇,下文将讨论如何识别两个簇是否为分裂后的小簇。
标准二:满足ext最大的两个簇,满足标准二说明簇间相似度较大,且相邻。

因为合并簇后会造成聚类数减1,因此需要在原来k的基础上减1。
3 基于多叉树的数据结构模型
因为基于多叉树确定k值的动态聚类算法涉及到簇的分裂合并,特殊的簇比如分裂后的簇需要标识,来避免在后面合并的部分又让其合并。此外分裂合并会造成聚类数的变化,也就是说k值是不断浮动变化的,因此还需保证k值的实时有效性。综合多方面考虑,数据节点的结构如下:
Static intk;
Class Node{
Int flag=i;i∈(1,2,…,k)
Int *k=k;
Int inner,ext;
Int P_flag=p;p为父节点的标识,根节点p为0
Node *L_child=L;
Node *R_child=R; 当节点本身为叶节点时,即未分裂时L和R为空
}
静态全局变量k为聚类数,这样可以保证k的唯一性与实时性,因为在分裂时k值要加一,合并要减一,并且下一步迭代依赖于k的真实值。Flag为此质心节点的唯一标识。P_flag为父节点的标识,簇分裂后形成的两个小簇的P_flag的值相同,用来避免合并步骤又重新合成。Inner与ext表示本簇的簇内与簇间相似度。
L_child与R_child为指向本簇分裂后所形成的两个小簇的指针,这里根节点有所不同,因为初始聚类数k值并不是2,所以根节点应有初始k个子节点。
4 算法具体分析

变量定义:k为该算法在数据集上输出的聚类数量;n为数据集对象元素个数。在初始化时,从数据集{I1,I2,…,In}随机找出k个{W1,W2,…,Wk},Wi=Ij,i∈{1,2,…,k},j∈{1,2,…,n}作为簇的初始均值或中心,对剩余的每个对象,根据其与各个簇均值(见式(1))的距离(见式(2)),将它指派到最相似的簇,计算每个簇的新均值。执行分裂、确定质心、合并、确定质心、再指派这个过程,不断反复,直到准则函数Ew收敛,或者分裂与合并停止。
基于多叉树确定k值的动态K-means聚类算法的描述如下:
输入:包含n个对象的数据集及簇的数目k;
输出:簇的集合。
Begin
初始化k个簇中心{W1,W2,…,Wk},其中Wi=Ij,i∈{1,2,…,k},使每一个聚类Cj与簇中心Wj相对应
Repeat
For 每一个输入向量Ij,j∈{1,2,…,n} do ①

②For 每一个聚类Ci,i∈{1,2,…,L},do ③
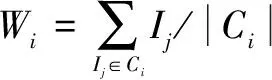
⑤For 每一个分裂后的类Cm,其中m指上一步被分裂的簇产生的小簇 do⑥

⑦当簇满足合并标准时合并簇
⑧For 每一个合并后的类Cb,其中b指上一步被合并的簇产生的合簇 do ⑨
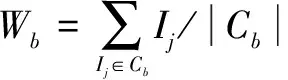
⑩计算目标函数Ew
UntilEw不再明显改变或者聚类的成员不再变化
End
5 实 验
验证在不同的数据集及不同的初始聚类中心选取数目和选取方式因素下,实验算法都能高效地得到准确的聚类结果。
影响实验结果的因素有数据集大小、初始聚类中心选取数目、初始聚类中心选取方式。为了验证算法的有效性,实验选取了数个规模不同的先验数据集,在这些数据集上分别进行了不同初始聚类中心选取数目和方式的基于多叉树确定k值的动态K-means聚类算法(算法A)的实施。为了验证算法的高效性,与基于二分均值聚类的k值决定方法(算法B)进行了对比,通过比较聚类结果以及聚类时间来验证实验的高效性。
实验需要横向比较与纵向比较两大步骤。横向比较是指在同一数据集初始聚类中心选取数目与选取方式的差异所导致的算法的优效比;纵向比较是指在不同规模数据集上的算法优效比。
实验算法的核心是分裂合并两个步骤,因此这两个步骤的迭代次数是算法效率的最直接体现,所以实验选取分裂合并次数和聚类时间作为验证算法优劣的参数。
为了使初始聚类中心选取数目(K0)的选取具有代表性,K0的选取有较少、适量、较多三个层次。因为所选取数据集为先验数据集,K0的适量层次即为准确的聚类数K;较少层次首先需要包括1,其余需要从1-K之间均匀选取三个数值;较多层次需包括最大聚类簇元素数N,以及K-N之间均匀选取三个数值。
初始聚类中心选取方式包括局部分布、均匀分布两种。
横向比较实验结果见表1。

表1 横向比较结果
分析以上结果,可以得到如下结论:
(1)当K0选取过少时,聚类迭代时分裂次数明显增加,聚类所需时间明显增加。
(2)当K0选取过多时,聚类迭代时合并次数有所增加,聚类时间也会相应增加,但聚类花费时间明显小于当初始K值过少时的聚类所花费时间。
(3)当K0选取合适,但初始聚类中心局部分布时,迭代过程中合并次数明显增加,聚类时间明显增加。
(4)当K0选取合适,且均匀分布时,分裂合并次数在正常范围内,聚类时间最短。
以上四种情况,实验聚类算法运行正常,聚类结果正确。
纵向比较实验结果:实验需控制初始聚类中心选取数目及选取方式两个变量。实验初始聚类中心选取数目K0等于最终聚类数K,选取方式为均匀分布。实验结果如图3所示。
图中,横坐标为数据集规模(以最终聚类数为参数),纵坐标为随着数据集规模的增长时分裂次数、合并次数、聚类时间的量化。
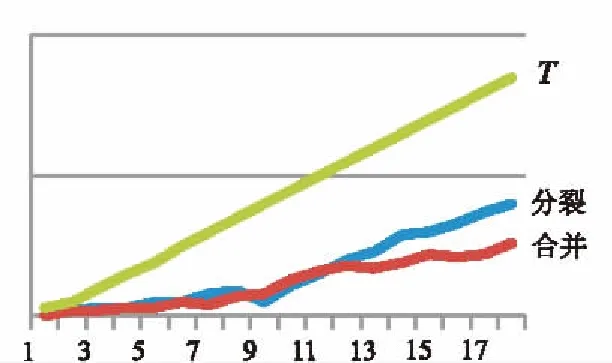
图3 实验结果图
由图3可知,随着聚类规模的递增,分裂次数与合并次数增长趋势平缓,呈现非指数型增长,聚类时间呈线性增长。证明算法在不同规模数据集的时间复杂度在可接受范围内。
最后实验使用外部数据集Wine data和Iris data对算法A与算法B进行了对比,结果见表2。
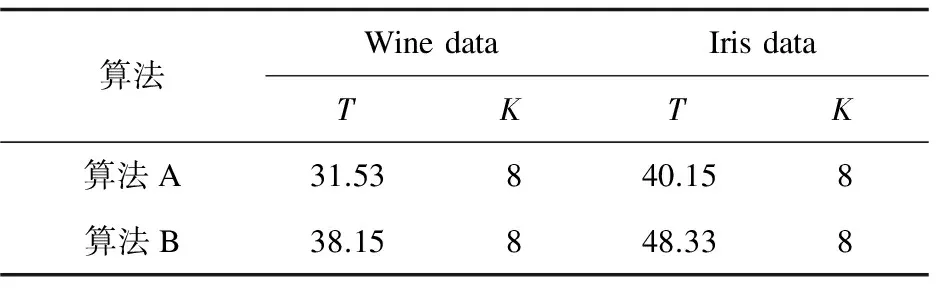
表2 对比实验
实验结果表明,基于多叉树确定k值的动态K-means聚类算法在Wine data和Iris data数据集所用时间分别是基于二分均值聚类的k值决定算法的82.6%和83.1%,说明改进算法相较于基于二分均值聚类的k值决定方法的效率有所提高。
以上实验说明,基于多叉树确定k值的动态K-means聚类算法对于各种不同的初始k值选取、不同的聚类中心选取方式,都能在可控时间范围内,得到正确的聚类结果,并且具有较高的效率。
6 结束语
K-means算法是广泛应用的聚类算法之一,通过研究分析传统K-means算法的局限性,用一种新思路对K-means算法进行适当改进,使改进算法不再严重依赖初始聚类数的选取。实验结果表明,改进算法在聚类准确性和效率上都有适当提升。当然,算法还有进一步改进的可能,比如可在分布式文件系统中实现并行化,如Hadoop平台可使算法效率进一步提高,这是下一步研究的方向。
[1] Han J W,Wen S P.Data mining:concepts and techniques[M].San Francisco:Morgan Kaufmann Publishers,2000.
[2] 杨善林,李永森,胡笑旋,等.K-means算法中的k值优化问题研究[J].系统工程理论与实践,2006,26(2):97-101.
[3] Wang Aijie,Chai Xuguang.Easy and efficient algorithm todetermine number of clusters[J].Computer Engineering and Applications,2009,45(15):166-168.
[4] Lai J Z C,Huang T J.Fast global k-means clustering using cluster membership and inequality[J].Pattern Recognition,2010,43(5):1954-1963.
[5] Zhang Zhongping,Steinbach M,Karypis G,et al.A comparison of document clustering techniques[R].USA:University of Minnesota,2000.
[6] 冯 超.K-means聚类算法的研究[D].大连:大连理工大学,2007.
[7] 谢娟英,郭文娟,谢维信,等.基于样本空间分布密度的初始聚类中心优化k-均值算法[J].计算机应用研究,2012,29(3):888-892.
[8] 宋宇辰,张玉英,孟海东.一种基于加权欧氏距离聚类方法的研究[J].计算机工程与应用,2007,43(4):179-180.
[9] 元昌安.数据挖掘原理与SPSS Clementine应用宝典[M].北京:电子工业出版社,2009.
[10] 陆声链,林士敏.基于距离的孤立点检测研究[J].计算机工程与应用,2004,40(33):73-75.
[11] 苏锦旗,薛惠锋,詹海亮.基于划分的K-均值初始聚类中心优化算法[J].微电子学与计算机,2009,26(1):8-11.
[12] 步媛媛,关忠仁.基于K-means聚类算法的研究[J].西南民族大学学报:自然科学版,2009,35(1):198-200.
[13] 马 帅,王腾蛟,唐世渭,等.一种基于参考点和密度的快速聚类算法[J].软件学报,2003,14(6):1089-1095.
[14] 孙吉贵,刘 杰,赵连宇.聚类算法研究[J].软件学报,2008,19(1):48-61.
A Dynamic Clustering Algorithm ofK-means Based on Multi-branches Tree forK-values
BAO Li-ming,HUANG Gang
(School of Computer,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
K-means algorithm is the one of most classical clustering algorithms with repartition and has been widely used because it’s really concise and efficient.What’s more,it has advantages such as being easy to be implemented and low cost of complexity in running time and storing space.However,it’s normally initial number calledK-value which cannot be precisely predicted by effective method.The initial clustering center used to be chosen randomly,so that the result usually converges to local optimal solution,which makes the latest clustering results inaccurate.The dynamic clustering algorithm ofK-means based on multi-branches tree to determine theK-value is an improved one.The improved algorithm has been designed to determine the most reasonableK-value by dynamically dividing and merging cluster during the iterative process and partly solved the problem that clustering result converges to local optimal solution.Furthermore,exploration for corresponding data structure model has also been conducted to the investigation of the algorithm mentioned.Horizontal and vertical comparison with the binaryK-means algorithm has been achieved.The comparison and analysis results show that the improvedK-means algorithm is independent of improved global data sets,which makes it more suitable for distributed computing platform and that relative efficiency has been increased with increase of the size of the data set,especially in magnanimity data set.Therefore the improvedK-means algorithm has promoted the clustering performance and can lead to a more stable clustering result.
K-means;clustering;dividing;merging;multi-branches tree
2016-05-13
2016-09-14 网络出版时间:2017-03-13
国家自然科学基金资助项目(61171053);南京邮电大学基金(SG1107)
鲍黎明(1990-),男,研究方向为云计算与大数据应用;黄 刚,教授,研究方向为计算机软件理论及应用。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170313.1545.008.html
TP301.6
A
1673-629X(2017)06-0041-05
10.3969/j.issn.1673-629X.2017.06.009
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
北京航空航天大学学报(2021年4期)2021-11-24
商用汽车(2021年4期)2021-10-13
作文周刊·小学一年级版(2021年36期)2021-01-14
阅读与作文(小学高年级版)(2020年8期)2020-09-12
中学生数理化·教与学(2019年5期)2019-06-06
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
数学大世界(2018年35期)2018-02-22
汽车实用技术(2017年20期)2017-10-24
