
一种面向大数据的快速自动聚类算法
2017-06-22 14:41于海鹏李宜晨
河南工程学院学报(自然科学版) 2017年2期
于海鹏,李宜晨
(1.河南工程学院 计算机学院,河南 郑州 451191;2.山东大学 软件学院,山东 济南 250101)
一种面向大数据的快速自动聚类算法
于海鹏1,李宜晨2
(1.河南工程学院 计算机学院,河南 郑州 451191;2.山东大学 软件学院,山东 济南 250101)
为了提高大数据的快速处理和识别能力,需要进行数据快速聚类分析.针对传统的模糊C均值聚类算法对初始值敏感且容易陷入局部优化解的问题,提出了一种基于Logistics混沌映射聚类中心小扰动抑制的大数据快速聚类算法.采用非线性时间序列分析方法构建大数据信息流模型,提取大数据信息流的时延尺度特征值,以提取的该特征值为聚类搜索目标函数,用模糊C均值聚类算法计算大数据聚类的最优聚类中心,采用Logistics混沌映射差分进化方法进行聚类中心的小扰动抑制,实现了优化聚类,可避免陷入局部最优解.仿真结果表明,采用该方法进行大数据聚类,能有效提高数据召回率,计算速度较快,实现了大数据的快速自动聚类.
大数据;聚类;模糊C均值;混沌;Logistics映射
大数据信息处理的关键环节就是进行数据聚类,即通过挖掘大数据中具有同类属性的数据特征参量,对数据进行分门别类的分析.在数据聚类的基础上建立专家系统和大数据库,以进行相关的模式识别和诊断分析服务.大数据的优化聚类技术研究在故障诊断、目标识别、云存储数据库模型的构建及情报检索等领域具有较高的应用价值,研究面向大数据的优化聚类方法已受到了人们的重视.
当前,数据聚类算法主要有基于网格技术的数据聚类方法[1]、模糊C均值聚类方法[2]、模糊K均值聚类方法和基于自适应波束形成的聚类算法等[3-5],上述方法均是通过求取大数据信息流属性特征之间的相似度进行分类的.其中,模糊C均值和模糊K均值聚类算法需要反复调整聚类结果来进行聚类优化.随着数据规模的扩大对初始聚类中心有较大敏感性;网格聚类算法没有考虑数据密度和类别距离给聚类中心搜索带来的影响,导致聚类的精度受到了限制;自适应波束形成聚类算法通过波束聚类性进行自动聚类,该方法对数据直接进行处理,计算开销较小,但该方法在受到较大的干扰影响时容易出现误分和漏分[6].对此,相关文献进行了算法的改进设计.文献[7]提出了一种基于全邻模糊聚类的联合概率数据互联挖掘方法,提高了数据块索引的效率,从而提高了聚类的时效性,但该方法在对特征敏感性较强的数据进行聚类处理时,容易出现聚类中心的扰动,导致分类出错;文献[8]提出了一种基于面板数据的接近性和相似性关联度分析的大数据自动聚类方法,把数据的分割转化为对空间的分割,采用模糊C均值聚类算法实现数据聚类,但该方法的缺陷是对初始值聚类中心和噪声数据敏感,容易陷入局部优化解的问题.为了解决上述问题,本课题提出了一种基于Logistics混沌映射聚类中心小扰动抑制的大数据快速聚类算法.基于模糊C均值聚类算法计算大数据聚类的最优聚类中心,采用Logistics混沌映射差分进化方法进行聚类中心的小扰动抑制,以实现大数据的优化.改进的算法利用Logistics混沌映射的均匀遍历特性和高效的全局搜索能力,使数据聚类中心能有效克服小扰动的影响导致的计算偏差,避免陷入聚类中心的局部收敛,实现聚类中心解向量的全局寻优,弥补了模糊C均值算法的缺陷.
1 大数据非线性时间序列分析模型及特征参量的提取
1.1 大数据非线性时间序列分析模型
通过对大数据信息流的前期统计和采样,构建了大数据时间序列的单变量时间序列{xn},数据样本长度为N.在数据的采样时间段内,数据分布是标量时间序列,设X和Y为数据流的聚类特征属性类别,采用相空间重构分析方法进行大数据的非线性映射处理,选择最小嵌入维数m与最佳时延τ,当数据特征的平均测度ε满足2-λt<ε(λ>0)时,大数据时间序列的信息流模型如下:
xn=x(t0+nΔt)=h[z(t0+nΔt)]+ωn,
(1)
式中:h(·)为大数据时间序列的每个样本中包含的相似性特征量.通过计算关联度来表达大数据非线性时间序列的高维几何属性[9],通过相空间重构,可得到大数据非线性时间序列的特征空间分布轨迹表达式:
X=[x(t0),x(t0+Δt),…,x(t0+(K-1)Δt)]=
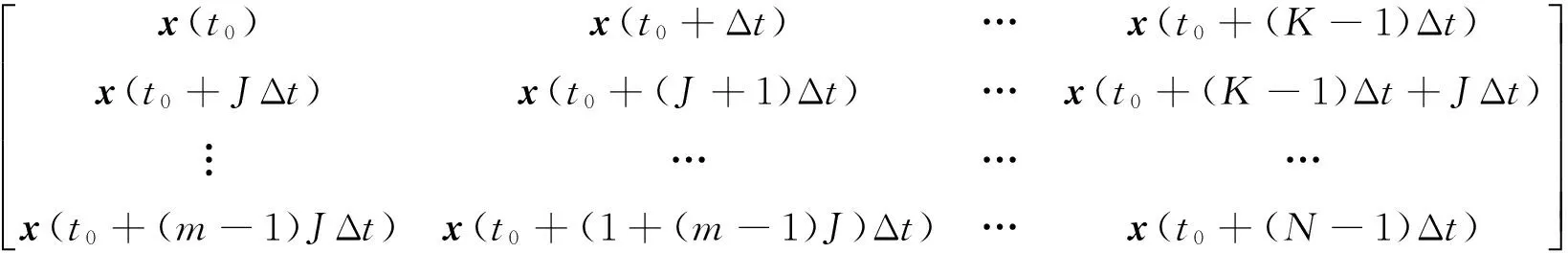
(2)
式中:x(t)表示面板数据的采样时间序列;J是相似性关联系数;m是嵌入维数;Δt是抽样时间间隔;K=N-(m-1)J.为了最大限度地反映前期统计测量的大数据时间序列的分类属性,采用指标数据投射方法得到大数据的特征非线性时间序列标量模型为{x(t0+iΔt)},i=0,1,…,N-1,其特征空间高维映射矢量为
X=[s1,s2,…,sK]n=(xn,xn-τ,…,xn-(m-1)τ),
(3)
式中:K=N-(m-1)τ,表示大数据时间序列的接近性关联系数;τ为对大数据时间序列采样的时间延迟.
1.2 大数据信息流时延尺度特征参量的提取
以上述构建的大数据信息流为输入进行时延尺度特征的提取,以提取的特征值为基础建立聚类搜索目标函数,用Ru,v表示大数据属性集的模糊集合自相关量,为数据特征向量之间的互相关函数,则大数据属性集的交叉分布模型可表示为
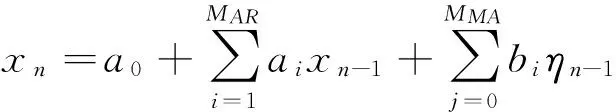
(4)
式中:a0为初始大数据时间序列的采样幅值;xn-1为具有相同均值和方差的大数据标量时间序列;bj为大数据的最优分裂属性.对于大数据的标量时间序列为x(t),t=0,1,…,n-1,采用非线性自回归滑动时间窗口构建多层空间模糊聚类中心[10],采用模糊C均值聚类算法进行初始聚类中心搜索,假设有限数据集向量
X={x1,x2,…,xn}⊂Rs,
(5)
通过属性集分类,可得到数据集合中含有n个样本.其中,样本xi(i=1,2,…,n)的信息增益矢量为
xi=(xi1,xi2,…,xis)T.
(6)
在数据集中选择K个实例,求得聚类目标函数的极值:
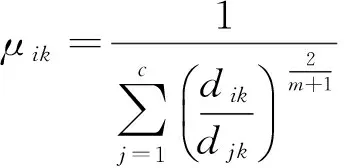
(7)
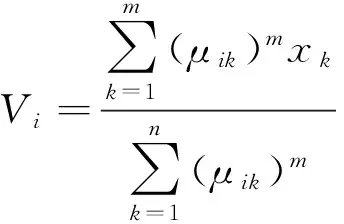
(8)
在上述构建了大数据聚类目标函数的基础上,通过对大数据最优聚类中心的搜索,进行数据聚类算法的改进设计.
2 数据快速自动聚类算法的改进
2.1 聚类中心的小扰动抑制
采用Logistics混沌映射差分进化方法进行聚类中心的小扰动抑制,避免聚类中心对初始值敏感而陷入局部优化解.根据混沌理论,定义Logistic混沌映射表达式[11]为
xn+1=μxn(1-xn),
(9)
式中:x∈[0,1];μ∈[0,4];n=1,2,3,….
以此为训练函数进行大数据模糊聚类中心的尺度调整,在聚类中心检索t和t+τ时刻的时延尺度:
V={vij|i=1,2,…,c,j=1,2,…,s},
(10)
式中:Vi为邻近数据点对聚类中心的扰动权重.对于大数据时间序列的第i个聚类中心矢量,采用Logistics混沌映射进行差分扰动,将每个数据点作为一个可能的聚类中心,得到聚类中心稳定的周期解:
U={μik|i=1,2,…,c,k=1,2,…,n},
(11)
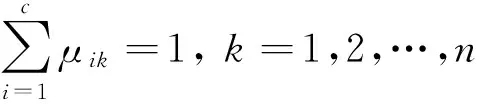
(12)
结合大数据聚类目标函数,在聚类中心初始值已经给定的情况下进行聚类中心的小扰动抑制,抑制过程如下:
(1)当式(9)中的0≤μ≤1时,大数据聚类中心的最优解只有x=0这样一个稳定的周期点;
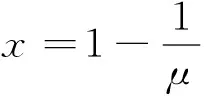
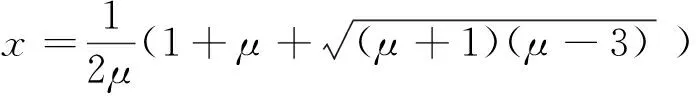
(13)
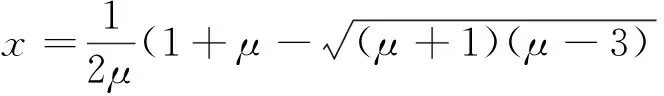
(14)
通过Logistics混沌映射进行周期解的差分进化,排除邻近数据点的扰动,得到两个稳定的2周期点;
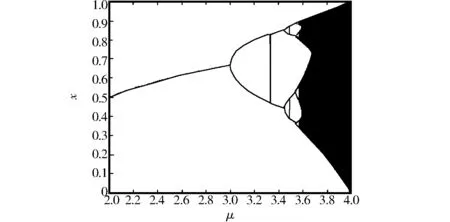
图1 Logistics混沌映射差分进化的聚类中心小扰动抑制Fig.1 Logistics chaotic mapping differential evolution of cluster centers with small disturbance rejection
(4)当3.449≤μ≤3.544时,2周期点变得不稳定,此时出现了4个稳定的4周期点;当参数μ继续变大,μ>3.544,Logistics混沌映射采用差分进化方法,通过倍周期分岔通向最优值[12],实现了对大数据快速聚类中心的小扰动抑制,如图1所示.
2.2 聚类算法构建实现的具体步骤
通过上述分析,基于模糊C均值聚类算法计算大数据聚类的最优聚类中心,采用Logistics混沌映射差分进化方法进行聚类中心的小扰动抑制,实现了面向大数据的快速自动聚类算法的改进设计,步骤描述如下:
(1)定义模糊聚类中心矩阵,首先选择一个C值,确定大数据分类属性的总数.若数据集为m,令Aj(L)为聚类中心,j=1,2,…,k,构建数据聚类目标函数.
(2)提取数据信息流的时延尺度特征,在数据集中选择K个实例,采用替代数据法进行大数据时间序列的归一化幅值的随机化处理,初始化数据聚类中心F(xi,Aj(L)),i=1,2,…,m,j=1,2,…,k.
(3)使用Logistics混沌差分进化方法进行聚类中心的扰动抑制,如满足
D(xi,Aj(L))=min{D(xi,Aj(L))},
(15)
那么xi∈ωk,此时的聚类中心取得最优解.
(4)把混沌扰动量引入进化分类簇的实例中,计算初始隶属度矩阵,以平均值作为新的聚类属性特征向量的平均值:
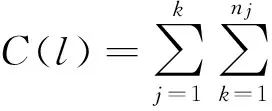
(16)
3 仿真实验与结果分析
为了验证本算法在实现大数据快速自动聚类中的性能,进行仿真实验.实验建立在Matlab仿真软件的基础上,使用的计算机主频为3 G、内存为2 G.用Microsoft .NET Framework 4.0开发工具建立数据聚类分析软件,实验数据来自2个大数据集:KDDP201大型网络数据库模拟数据集(包括2个规模为22.4 MB的分区)和CSLOGS实际数据集(含规模为6.45 MB的分区).在测试数据集中进行大数据样本选取,大数据采集的时间间隔为0.43 s,采样频率fs=4f0=20 kHz,在不同的采集时间段内得到了6组大数据采样样本,其时域波形如图2所示.
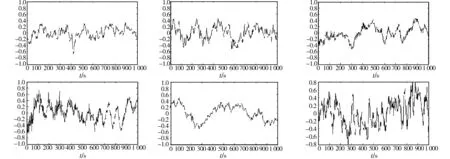
图2 大数据聚类实验测试样本的时域波形Fig.2 Time domain waveform of large data clustering experiment test sample
根据仿真环境和实验样本的设定,以上述数据样本为研究对象进行数据聚类分析.通过特征提取和聚类中心搜索,以其中一组样本为例,得到了大数据聚类的最优聚类中心搜索轨迹,如图3所示.
从图3可知,采用本方法引入Logistics混沌映射进行聚类中心的扰动抑制,使搜索轨迹具有较好的正则规律性,提高了数据聚类的准确性,可避免陷入局部最优解.为了定量地刻画某算法进行数据聚类的准确性和时效性,以上述样本为测试集,采用不同方法进行数据的聚类性能测试,通过1 000次实验并取平均值,得到了数据聚类的准确召回率对比结果,如图4所示.
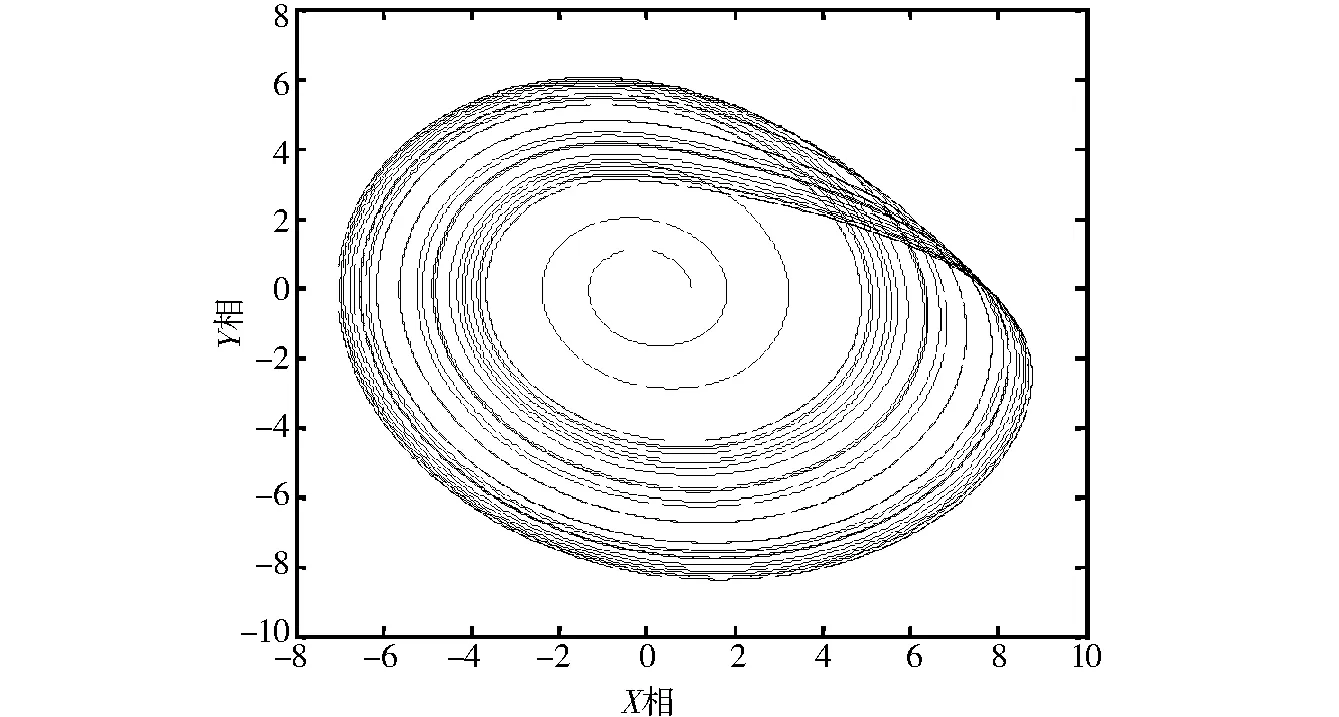
图3 聚类中心搜索轨迹Fig.3 Cluster center search trajectory
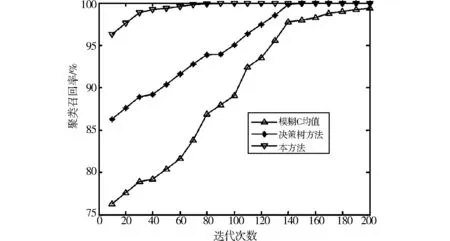
图4 数据聚类的准确性对比Fig.4 Accuracy comparison of data clustering
由图4得知,采用本方法进行数据聚类,对数据的准确召回性能较好,误分率较低,数据聚类的精准度较高.表1给出了采用不同方法进行数据聚类时不同数据规模下的平均时间开销,分析得知本方法的时间开销最小,这是因为本方法进行了数据特征的压缩和降维处理,并进行了扰动抑制,避免了冗余数据的干扰,从而降低了运算量.
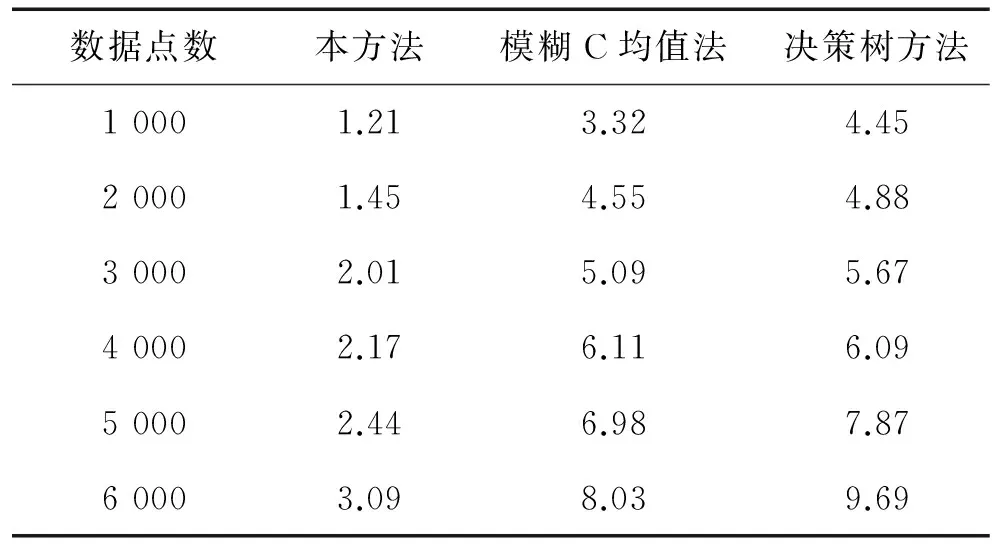
表1 时间开销对比Tab.1 Time overhead comparison s
4 结语
为研究大数据的优化聚类分析问题,本课题提出了一种基于Logistics混沌映射聚类中心小扰动抑制的大数据快速聚类算法,采用Logistics混沌映射差分进化方法进行聚类中心的小扰动抑制,实现了大数据优化聚类,避免陷入局部最优解.分析得出,采用本方法进行大数据聚类,聚类中心搜索较为准确,数据的召回性较好,计算速度较快,具有较好的应用价值.
[1] 梁聪刚,王鸿章.微分进化算法的优化研究及其在聚类分析中的应用[J].现代电子技术,2016,39(13):103-107.
[2] 李牧东,赵辉,翁兴伟,等.基于最优高斯随机游走和个体筛选策略的差分进化算法[J].控制与决策,2016,31(8):1379-1386.
[3] PATEL V M,NGUYEN H V,VIDAL R.Latent space sparse and low-rank subspace clustering[J].IEEE Journal of Selected Topics in Signal Processing,2015,9(4):691-701.
[4] 孙力娟,陈小东,韩崇,等.一种新的数据流模糊聚类方法[J].电子与信息学报,2015,37(7):1620-1625.
[5] 邢长征,刘剑.基于近邻传播与密度相融合的进化数据流聚类算法[J].计算机应用,2015,35(7):1927-1932.
[6] 毕安琪,王士同.基于Kullback-Leiber距离的迁移仿射聚类算法[J].电子与信息学报,2016,38(8):2076-2084.
[7] 刘俊,刘瑜,何友,等.杂波环境下基于全邻模糊聚类的联合概率数据互联算法[J].电子与信息学报,2016,38(6):1438-1445.
[8] 吴鸿华,穆勇,屈忠锋,等.基于面板数据的接近性和相似性关联度模型[J].控制与决策,2016,31(3):555-558.
[9] 胡光波,梁红,徐骞.舰船辐射噪声混沌特征提取方法研究[J].计算机仿真,2011,28(2):22-24.
[10]MAHMOUD E E.Complex complete synchronization of two nonidentical hyperchaotic complex nonlinear systems[J].Mathematical Methods in the Applied Sciences,2014,37(3):321-328.
[11]PALOMARES I,MARTINEZ L,HERRERA F.A consensus model to detect and manage non-cooperative behaviors in large scale group decision making[J].IEEE Trans on Fuzzy System,2014,22(3):516-530.
[12]MAREY M,DOBRE O A,LIAO B.Classification of STBC system over frequency-selective channels[J].IEEE Transactions on Vehicular Technology,2015,64(5):2159-2164.
A fast and automatic clustering algorithm for large data
YU Haipeng1,LI Yichen2
(1.CollegeofComputerScience,HenanUniversityofEngineering,Zhengzhou451191,China;2.SoftwareCollege,ShandongUniversity,Jinan250101,China)
In order to improve the recognition and rapid processing of large data capacity, the need for rapid data clustering analysis, according to the conventional fuzzy C means clustering algorithm is sensitive and easy to fall into local optimal solution to the initial problem, we propose a fast clustering algorithm for large data suppression of small disturbance Logistics chaotic map based on clustering center. By using the nonlinear time series analysis method to construct data flow model, time scale characteristic parameters extraction of large data flow of information, in order to extract the eigenvalue searching objective function for clustering, the optimal clustering center calculation data clustering and fuzzy C means clustering algorithm based on Logistics chaotic map, using the differential evolution method of clustering center small disturbance inhibition of large data clustering, to avoid falling into local optimal solution. The simulation results show that the method can effectively improve the recall rate of data, calculate cost is less, and the anti-interference ability is stronger.
large data; clustering; fuzzy C mean; chaos; Logistics map
2017-01-04
河南省高等学校重点科研项目(16A520004)
于海鹏(1979-),男,河南鲁山人,副教授,主要研究方向为图像处理与计算机应用.
TP391
A
1674-330X(2017)02-0062-05
猜你喜欢
数学杂志(2022年5期)2022-12-02
数学物理学报(2022年4期)2022-08-22
数学物理学报(2021年4期)2021-08-30
北京航空航天大学学报(2021年7期)2021-08-13
新世纪智能(数学备考)(2021年5期)2021-07-28
数学物理学报(2019年4期)2019-10-10
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
信息安全研究(2015年3期)2015-02-28
