
增值性评价的实践与思考*
——以某寄宿制中学七年级为例
2017-05-16 10:18周颖
中国教育信息化 2017年9期
周颖
(成都七中实验学校现代教育技术中心,四川成都611130)
增值性评价的实践与思考*
——以某寄宿制中学七年级为例
周颖
(成都七中实验学校现代教育技术中心,四川成都611130)
我们常用的原始分数,进行横向比较的成绩分析存在很多弊端,增值性评价是今后评价制度改革的一个重要方向。本文以某寄宿制中学七年级为例,应用经典S-P表评价理论,在同时考虑学生层面和班级层面的基础上,使用目前国际流行的多层线性分析技术,建立了寄宿制中学语文和数学分析模型,并计算出学校和教师对学生成长的实际净增值,为评判学校和教师的教育教学提供科学依据,以实现教育教学评价的科学化、有效化。
增值性评价;经典S-P表;评价理论;多层线性分析
IT(Information Technology)时代指信息技术时代,主要标志是现代信息技术产品,如投影、交互式投影、一体机、实物展台、网络等大规模地使用。DT(Data Technology)时代指数据时代,标志是对用户数据的收集以及分析,可以做到对用户个别化、差异化的服务。在DT时代大数据的背景下,教育也将迎来深度变革,DTE(Data Technology for Education),即教育数据技术应运而生,这标志着以基于教育教学过程产生的数据和数据分析为核心的时代已经来临,可以为教育教学提供更精确的服务,真正做到因人施教。
教育数据挖掘(Education Data Mining)是教育数据技术(DTE)中一个重要应用。它综合运用数理统计、人工智能与机器学习、数据挖掘等技术与方法,对教育原始数据进行分析处理,通过构建数据模型,对学习者的学习结果与学习内容、学习资源和教学行为等变量进行相关关系分析,从而有效地发现学习者学习中存在的问题,为教学管理者、教师和学生提供支持和解决方案,实现高效学习。
教育数据挖掘的核心在于数据分析处理,教育数据分析内容很多,其中我们用得最多、最普遍的是成绩分析。但原有的以原始分数进行横向比较的成绩分析评价方式存在很多的弊端,如看不到学生的进步、打击学生学习积极性、班级之间比较没有考虑生源因素、挫伤教师积极性等等。增值性评价是今后评价制度改革的一个重要突破和方向,自上世纪90年代在美国田纳西州广泛运用以来,得到了越来越多的关注。简单地说,增值性评价就是看学生在一段时间教育过程后的成长、进步、转化的幅度,即增值=输出-输入。简单来说就是注重学生纵向比较,淡化横向比较。比如基础差、学习困难的学生,如果经过一段时间学习后,本次考核比原来有了进步,哪怕他的原始分数横向比较仍然很低,都应该褒奖;反之,原来学习优秀的学生,如果没有保持或退步,即使他的原始分数比学习困难的学生多很多,也应该受到批评。换言之,增值性评价正是发展性评价的一种,强调以每个学生的进步幅度来评价教师和学校的工作水平,这与目前所倡导的面向全体学生、促进学生全面发展的思想不谋而合。
同样,增值性评价系统也改变了学校教师评价,不是简单地看最后考试的分数,它能让教师更多地关心学生学业的进步。由于是以学生学业成绩的增值为考评教师的基础,能很好地解决“择生”问题(即目前所谓实验班、火箭班和普通班划分,学校内部人为地将学生区分为三六九等),为教师提供了公平的教学环境。
现在以某中学七年级语文和数学期末考试为例谈谈对增值评价的思考与实践。
一、以期末语文考试原始分排序(见表1)
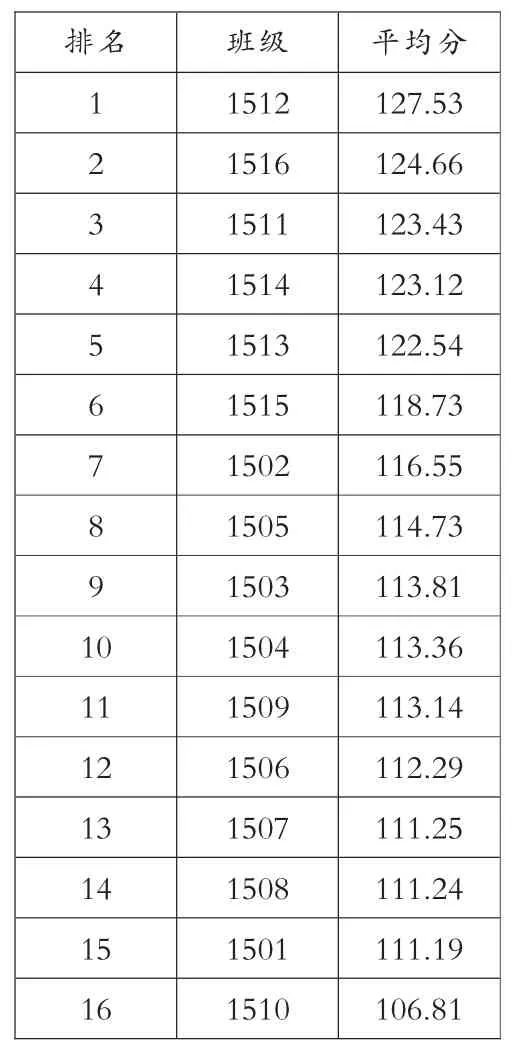
表1
二、用增值比较排序
将入学考试和期末考试成绩折算成标准分,即Z分,再计算增值,用增值来排序。这样不是单纯地以一次考试成绩来评判班级和教师,而是用进步和发展的角度来评价,显然比第一种方法更科学。(见表2)
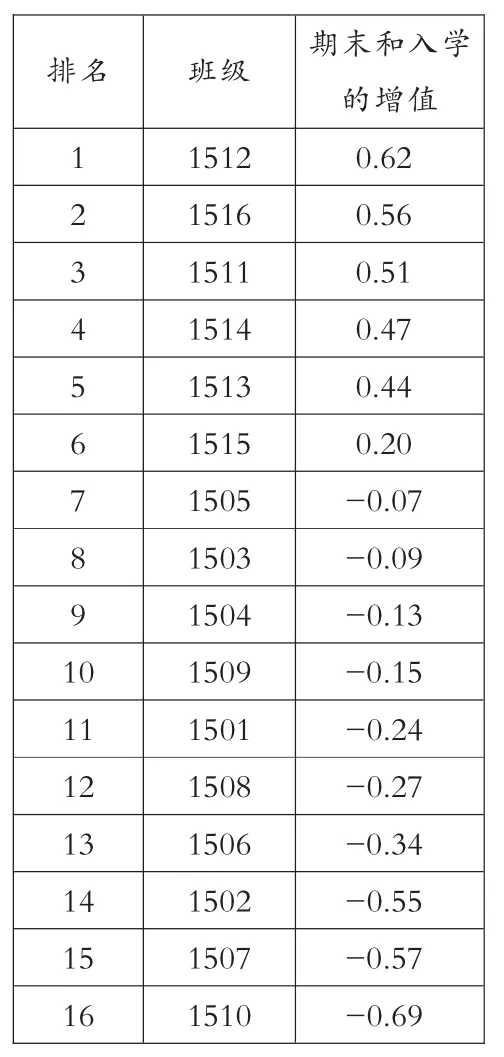
表2
三、多层线性分析
在教学实践中我们可以发现,学生的成绩不仅受到学生自身因素的影响,也受到很多外部因素的影响,不仅受到学校的影响,也受到家庭、社会的影响。比如学生的基础,学生的学习态度、学习方法习惯、家庭出身等,都与学生的成绩有关系。如果忽视这些学校不能控制的因素,只是简单地进行入和出的比较,将学生成绩全部归因于教师的教学,对很多普通学校和班级来说显然是不公平的。
故目前大家都普遍认为,学生个体不是生活在真空里的,对学生学习的评价必须考虑到学生个体自身影响和生活在其中的外部环境影响。在寄宿制学校中,因学生绝大部分时间都在学校,故我们暂时忽略家庭的影响,先考虑班级对学生的影响。我们常常可以发现,班级内部学生的差异明显小于不同班级间学生的差异,所以我们在对全校各班做分析时不能只考虑学生个体因素,忽略班级因素;或只考虑班级因素,忽略学生个体因素,而要把这两者结合起来。那么传统的基于普通最小二乘法(OLS)的回归模型就很难做到,所以这次笔者引入了多层线性分析来进行。
本次分析的对象是某寄宿制中学七年级751名学生,分成16个班。通过调查问卷等形式,得到影响学生成绩的因素,分为学生层面和班级层面两层。在学生层面,大家比较认同和关心的是学生的基础、学习方法、学习态度、学习习惯等,我们可以把学习方法、学习态度、学习习惯等合称为学生的学力;班级层面有基础平均分和学力平均分。使用软件为SPASS和HLM。
1.学生基础
按照入学考试成绩,将其折算成标准分。
2.学生学力
使用经典S-P表评价理论,根据入学成绩将学生学力分为六个等级,从A-C',如图1所示。
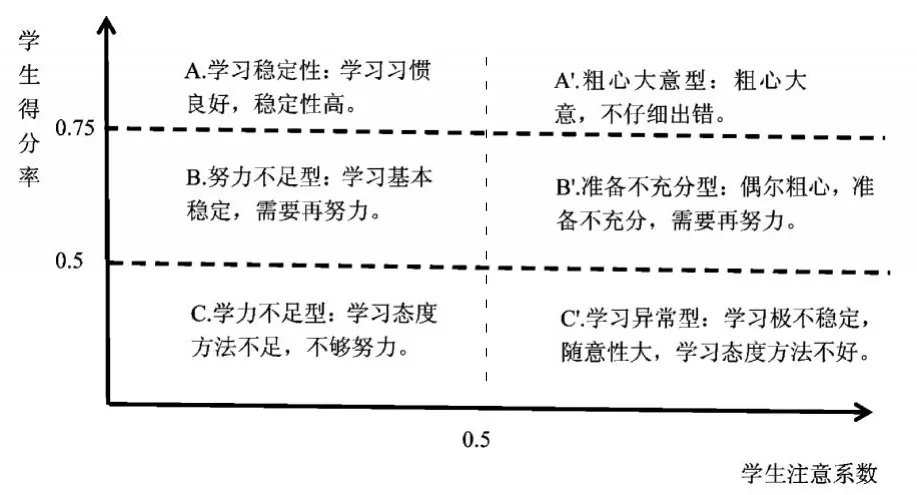
图1
对六个学力等级分别赋值1-6。
分析过程如下:
第一阶段:零模型
建立方程如下:
LEVEL1:Dij=β0j+γij
LEVEL2:β0j=γ00+μ0j
水平1中因变量Dij表示第j个班级第i个学生的增值,β0j是第j个班级的平均值,γij是第j个班级第i个学生残差;水平2中γ00是总体结果的总平均数,μ0j是与第j个班级相联系的随机效应。并做如下假定:①γij为独立并且服从以0为平均数、σ2为方差的正态分布,表示为γij~N(0,σ2)。②μ0j为独立并且服从以0为平均数、τ00为方差的正态分布,表示为μ0j~N(0,τ00)。③γij与μ0j相互独立。
零模型是多层分析的起点,它是最简单最基本的多层模型,水平1和水平2都不存在自变量。它用来估计因变量的差异有多少归因于第一层和第二层,即我们的学生层和班级层。如果班级层占了总体方差的较大部分,就有必要使用多层分析;如果班级层占据因变量的差异没有达到显著水平,则只需要使用单层分析技术,即简单回归即可。计算公式如下:
班级间差异,也就是方差Var(μ0j)=τ00
班级内学生差异,也即方差Var(γij)=σ2
所以ρ=τ00/(τ00+σ2)
一般来说,ρ值大于0.059,则有必要进行多层分析。检验结果如表3所示:
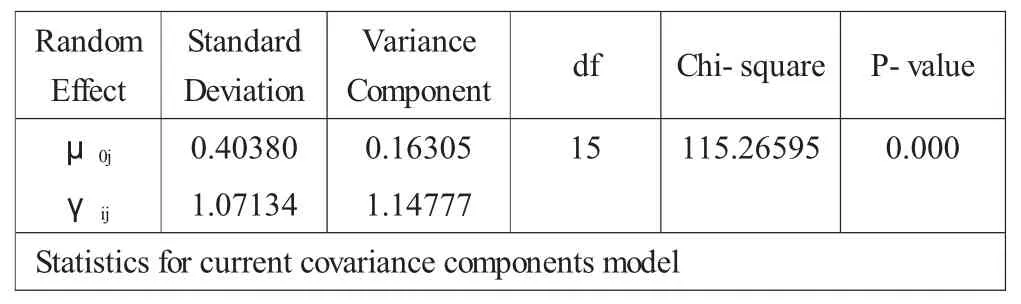
表3 Final estimation of variance components:
ρ=τ00/(τ00+σ2)=0.16305/(0.16305+1.14777)≈0.1244,并且p-value=0.000,达到了显著性水平,这表明学生成绩增值在班级层存在显著差异,在学生成绩增值的总变异中有12.44%归因于班级之间差异,其余87.56%归因于学生个体。故我们下结论有必要进行多层分析。
第二阶段:随机效应模型
在这个模型中,我们只在水平1中加入预测变量,通过对水平1中各预测变量在水平2的班级间差异是否显著进行检验,从而判断是否以该水平1中预测变量的斜率为因变量在水平2中建立方程。
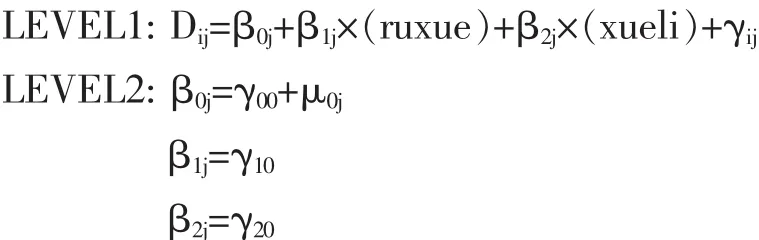
其中,Dij解释同第一阶段。预测变量ruxue是学生入学成绩,预测变量xueli是学生入学时学力。为了研究能尽可能量化,假定班级水平与学生水平变量之间的交互作用在各个班级之间没有显著差异,所以水平1中除了截距外,其它回归系数都限定为在不同班级间固定不变,这样对于每个班级而言,水平2中β0j包括两个部分:γ00(固定截距,所有班级都一样)与μ0j(随机截距,每个班级不一样),这样μ0j就为一个班级除了其他因素外实际增量。
检验结果如表4所示。
从固定效应中可以看到,学生入学成绩(学习基础)是一个显著的负向影响,其值为:γ10=-0.770459,T=-14.501,P<0.05,这个数据表明基础好的学生,经历了近一年学习,其语文成绩提高不如基础差的学生。这个问题很多专家也进行过研究,如美国学者Sanders在美国田纳西州的增值性研究表明,进步较快的学生,是原来水平比较低的学生,因为其原来掌握的知识比较少,因此他们有更大的增值空间。(参见The Tennessee Value-Added Assessment System中相关论述)
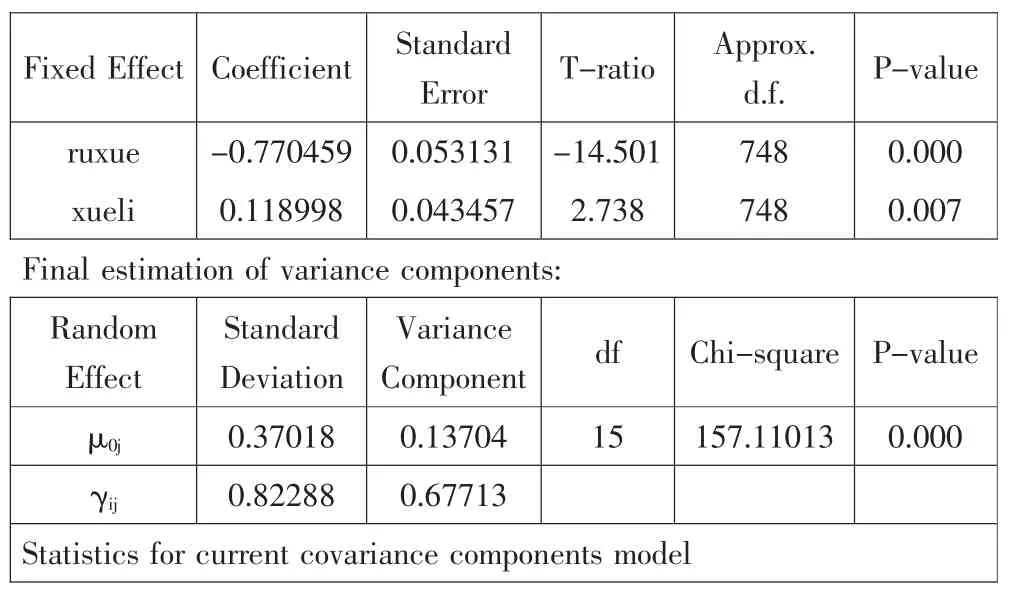
表4 Final estimation of fixed effects(with robust standard errors)
学生的学力(学习态度、学习方法等)是一个显著正向影响,其值为:γ20=0.118998,T=2.738,P<0.05,这个数据表明学生学力越高,其语文学习成绩进步越大。
此外,班级内学生差异,也即方差σ2,从模型1的1.14777降到现在的0.67713,其减少幅度为:(1.14777-0.67713)/1.14777≈0.41,降低幅度为41%,换言之,我们在水平1中加入了学生基础和学生学力两个预测变量后,解释了学生水平变异的41%,效果还是比较显著。
最后,偏离度统计,从模型1的2268.931062减少到1885.231843,有明显减少。
以上数据表明,我们在水平1中加入的两个预测变量是有效的。
第三阶段:完整模型
经过了第一阶段和第二阶段的两个模型分析后,现在我们在水平2中加入两个预测变量,以探究建立七年级语文增值性评价的完整模型。建立方程如下:
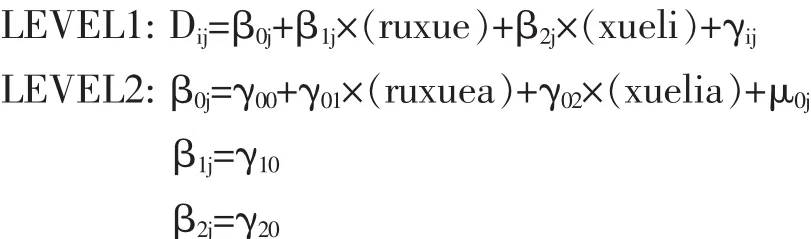
水平2中预测变量ruxuea是班级平均基础分,预测变量xuelia是班级平均学力,其它解释同第二阶段。
检验结果如表5所示。
从固定效应中可以看出,班级平均基础是一个正向影响,班级平均基础好的班级,其增值更大,但是没有统计意义(P>0.05)。班级平均学力是一个显著的正向影响,其值为:γ02=0.673979,T=9.123,P<0.05,这个数据表明班级学生平均学力越高,其语文学习成绩进步越大,也就是说学生之间由于学习习惯、学习态度、学习方法等构成的学习氛围对彼此间有显著的正向影响。
结合以上叙述,我们去掉水平2里没有统计学意义的预测变量——班级平均基础,将相关参数带入,得到如下方程:
LEVEL1:Dij=β0j-0.746931×(ruxue)+0.080888×(xueli)+γij
LEVEL2:β0j=0.003092+0.673979×(xuelia)+μ0j
将每个学生的数据带入后,可以求得每个学生实际的增值,再对各个班级进行平均,得到各个班级关于七年级语文期末相对入学实际增值,计算结果如表6所示。
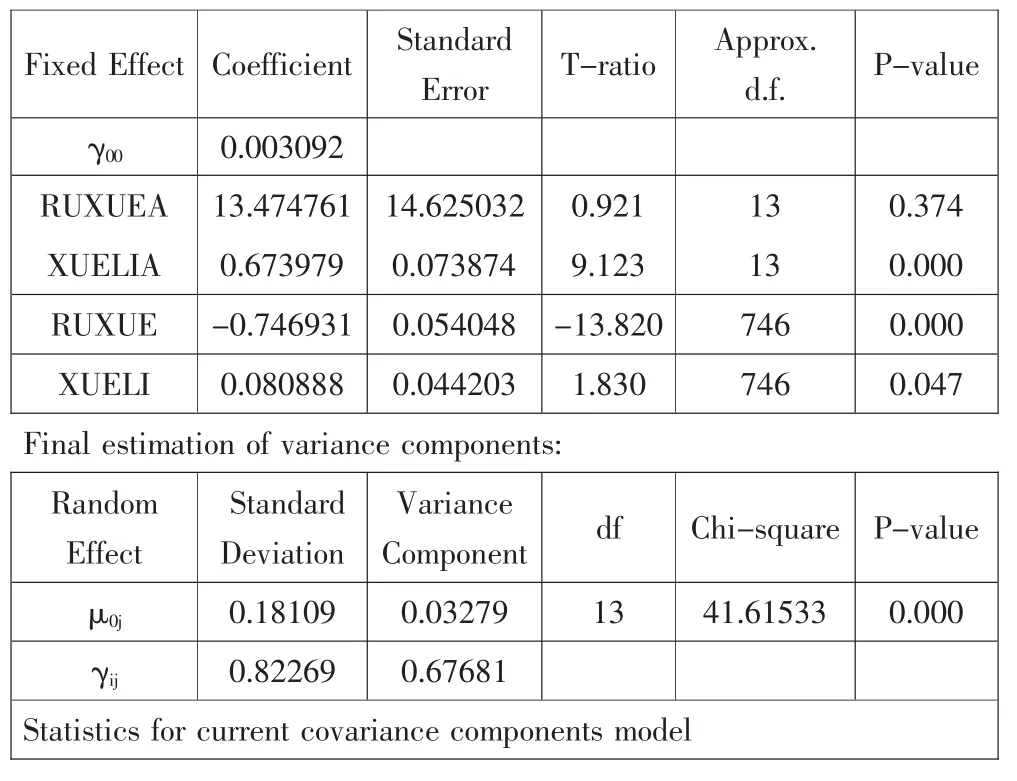
表5 Final estimation of fixed effects(with robust standard errors)
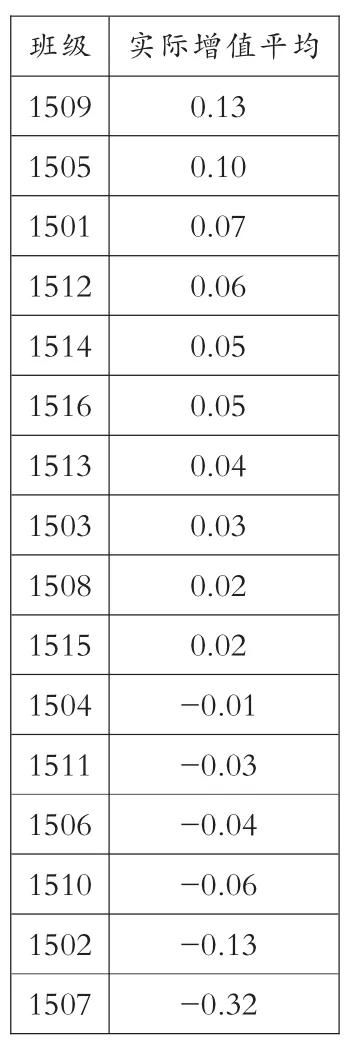
表6
全年级学生增值数据中,最低-7.73,最高1.71,平均0.001581,标准方差0.97,总体上实现了正增值,但是学生之间差异较大。全年级原始分排名和实际增值排名变化如表7所示。(箭头朝上代表名次增加,箭头朝下代表名次下降)
四、对数学期末考试和入学考试分析结果
对数学分析基本同语文,第一步,ρ=τ00/(τ00+σ2)=0.28002/(0.28002+ 0.62271)≈0.3102,并且p-value= 0.000,故对理科而言,多层分析更有必要。
第二步,学生基础是一个负向因子,学生学力是一个正向因子,而且都是显著相关的。
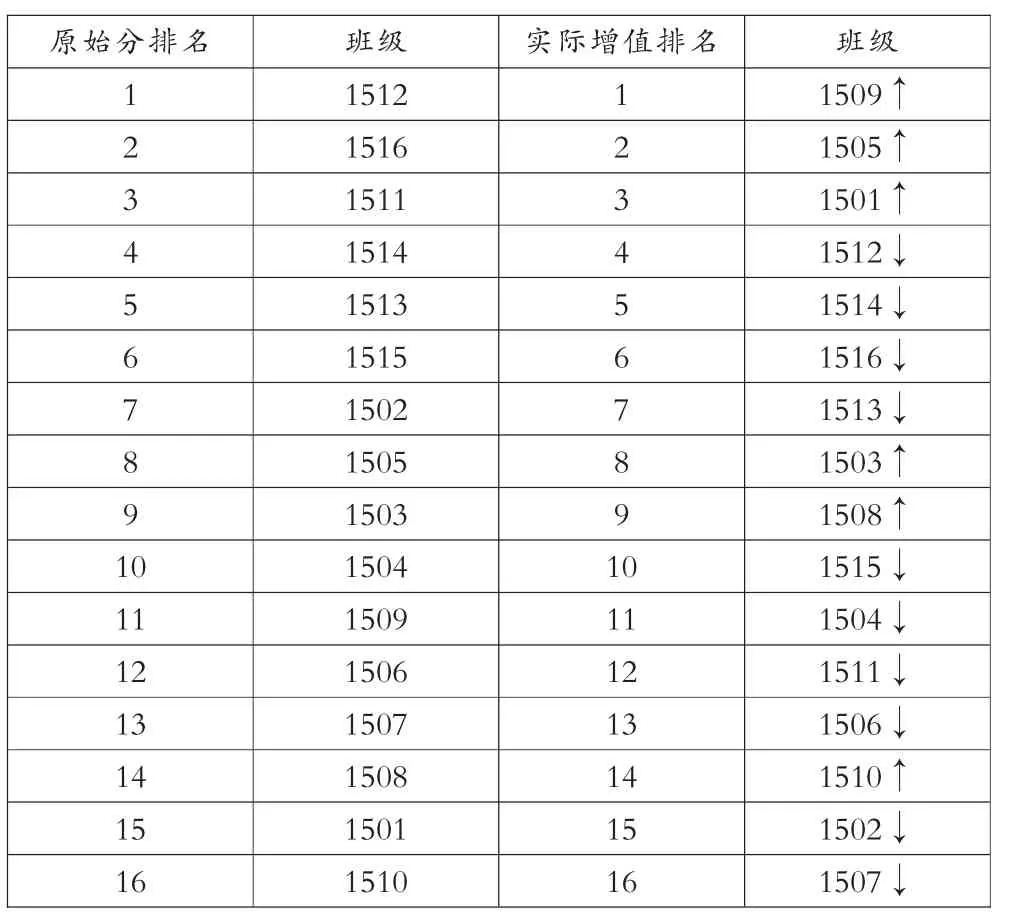
表7
第三步,班级平均基础没有统计意义,班级平均学力是一个显著的正向影响,其值为:γ02=1.114304,T= 9.402,P<0.05。另外γ10=-0.488918,γ20=0.052447。
最后方程如下:
LEVEL1:Dij=β0j-0.488918×(ruxue)+0.052447×(xueli)+γij
LEVEL2:β0j=-0.000037+1.114304×(xuelia)+μ0j
对结果进行统计,全年级学生增值数据中最高3.01,最低-3.54,平均-0.00022,标准方差0.6648,总体是微弱负增长,学生之间差异比较大。全年级原始分排名和实际增值排名变化如表8所示:(箭头朝上代表名次增加,箭头朝下代表名次下降,“-”表示名次没有变化)
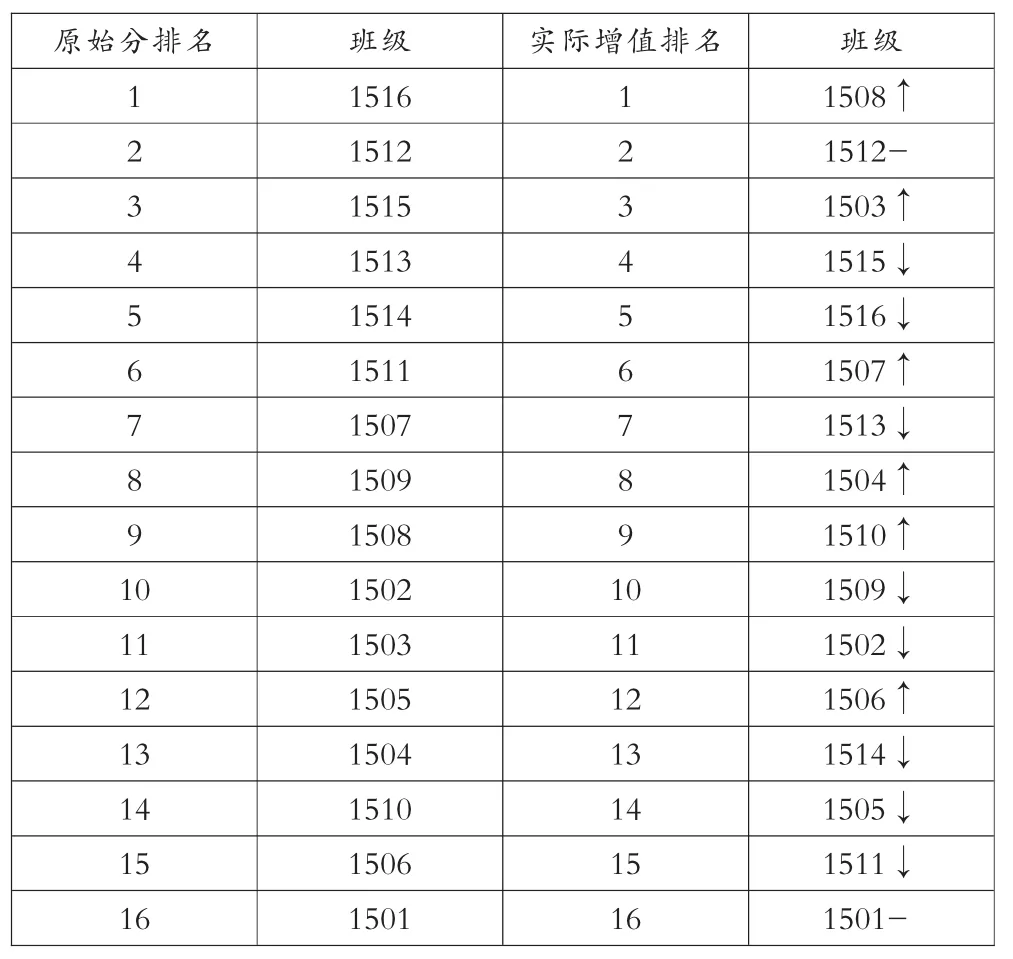
表8
五、结束语
基于成绩分析的增值评估是评价学校、教师的一种重要手段,因为学生不是生活在真空里,也不是只受到学校教师的影响,所以我们努力在科学研究、合理预测的基础上,尽量排除其它因素,计算出学校和教师对学生成长的实际净增值,为政府管理机构、教学研究机构以及社会各界评判学校和教师的教育教学提供科学依据,以达到调动各方面积极性的目的,实现教育教学评价科学化、有效化。本文在这方面做了一些有益的尝试,下面还将更深入探讨寄宿制学校中影响学生成绩的各个因素,以使我们的评价更科学有效。
[1]张雷,雷雳,郭伯良.多层线性模型应用[M].北京:教育科学出版社,2003.
[2]温福星,邱皓政.多层次模式方法论:阶层线性模式的关键问题与试解[M].北京:经济管理出版社.
[3]彭湃,胡咏梅,埃克哈德·克里默.学校增值的一致性与稳定性——基于多水平追踪数据的实证研究[J].教育研究,2015(7).
[4]杜屏,杨中超.农村初级中学学校效能的增值性评价——基于我国西部五省调研数据的实证分析[J].北京师范大学学报(社会科学版),2011(6).
[5]周颖.《应用翻转课堂实施智慧教学的研究》开题报告书[R].四川省教育厅四川省教育信息化应用与发展研究中心,课题编号:JYXX15-013.
(编辑:王天鹏)
G40-058.1
A
1673-8454(2017)09-0027-05
*本文系四川省教育厅四川省教育信息化应用与发展研究中心研究课题“应用翻转课堂实施智慧教学的研究”(课题编号:JYXX15-013)阶段性成果之一。
猜你喜欢
美与时代·美术学刊(2022年3期)2022-04-27
小读者(2021年4期)2021-11-24
读与写(2021年11期)2021-05-20
小读者(2021年2期)2021-03-29
甘肃教育(2020年22期)2020-04-13
火花(2019年12期)2019-12-26
人大建设(2019年12期)2019-05-21
广东教学报·初中语文(2018年12期)2018-08-04
中学语文·教师版(2017年10期)2017-11-13
中国火炬(2013年5期)2013-07-25
