
基于深层神经网络的多特征关联声学建模方法
2017-05-13 03:51范正光闫红刚张文林
计算机研究与发展 2017年5期
范正光 屈 丹 闫红刚 张文林
(解放军信息工程大学信息系统工程学院 郑州 450002)(fanzg11@163.com)
基于深层神经网络的多特征关联声学建模方法
范正光 屈 丹 闫红刚 张文林
(解放军信息工程大学信息系统工程学院 郑州 450002)(fanzg11@163.com)
针对不同声学特征之间的信息互补性以及声学建模中各任务间的关联性,提出了一种多特征关联的深层神经网络声学建模方法,该方法首先借鉴深层神经网络(deep neural network, DNN)多模态以及多任务学习思想,通过共享DNN部分隐含层为不同特征声学模型间建立关联,从而挖掘不同学习任务间隐含的共同解释性因素,实现知识迁移以及性能的相互促进;其次利用低秩矩阵分解方法减少模型估计参数的数量,加快模型训练速度,并对不同特征的识别结果采用ROVER(recognizer output voting error reduction)融合算法进行融合,进一步提高系统识别性能.基于TIMIT的连续语音识别实验表明,采用关联声学建模方法,不同特征的识别性能均要优于独立建模时的识别性能.在音素错误率(phone error rates, PER)指标上,关联声学建模下的ROVER融合结果要比独立建模下的ROVER融合结果相对降低约4.6%.
语音识别;深层神经网络;声学模型;低秩矩阵分解;融合
在现代连续语音识别(continuous speech recognition, CSR)系统中,声学特征提取是一个必不可少的模块,其性能直接影响系统的识别能力和鲁棒性.理想的声学特征应一方面能表征不同识别基元的声学差异,另一方面又能表征不同样本间相同识别基元的声学相似性信息等[1].然而,要得到一种满足这些特性的声学特征往往是不可能的,因此也就出现了多种差异性的特征,如Mel频率倒谱系数(Mel-frequency cepstral coefficients, MFCC)、感知线性预测系数(perceptual linear predictive coefficients, PLP)等.
不同特征参数表征着不同的声学和物理意义,在识别性能上也存在一定的差别.针对不同特征间的差异性,通过融合方法来有效利用他们之间的互补信息、提高识别精度,已被成功用于语音识别任务中.例如文献[2-4]分别在特征层、声学模型层以及识别结果层对不同特征进行融合从而利用它们之间的互补性来提升识别性能,但这些方法均是基于传统的高斯混合模型(Gaussian mixture model, GMM)框架,性能提升并不明显.
近年来,深层神经网络(deep neural network, DNN)在语音识别领域取得了巨大成功[5-10],通过深层神经网络对声学模型的状态输出概率进行建模已成为主流方法.用于声学建模时,DNN将分类以及对输入特征内在结构的学习结合在一起,其多个隐层可以视为对输入特征的多次非线性变换,从而提取高层特征.利用DNN能够深度整合不同信息源的能力,文献[6-7]提出基于DNN的特征融合方法,该方法将语音信号提取的多种特征进行拼接作为DNN的输入,通过DNN提取“最相关”信息用于音素分类.实验表明融合特征的识别性能要高于使用单一特征时的识别性能.但是采用拼接特征作为DNN的输入时,对特征的选取有较高要求,特征选择不当会对系统性能产生负面影响.
在机器学习和数据挖掘领域,基于DNN的多模态(multimodal)学习以及多任务(multitask)学习表现出优异性能.例如文献[8-9]利用DNN进行两感交叉(cross-modality)特征学习,通过共享中间层增强不同模态数据(音频和视频)特征的鲁棒性和泛化能力;文献[10]则利用DNN多任务学习框架,通过共享隐层实现跨语言声学数据中共有隐藏因素的共享;文献[11]将深度卷积神经网络架构应用到拉丁文和中文的字符识别中,利用中文字符上训练得到的卷积神经网络轻易地识别大写拉丁字母.为了利用不同特征间的互补信息,本文借鉴DNN多模态以及多任务学习思想,提出一种基于多声学特征流共享隐层的DNN声学建模方法.该方法在对不同声学特征进行DNN声学建模时,通过共享部分隐含层,从而建立不同声学特征间的内在关联,实现信息共享.同时通过设置不同的输出层,以实现对不同特征识别任务的区分,并采用ROVER[12]融合方法对不同输出结果融合以进一步提高识别性能.此外,针对联合后的DNN最后一层参数较多、训练较慢问题,采用低秩矩阵分解(low-rank matrix factorization, LRMF)方法减少模型参数,提高模型训练效率.在TIMIT语料库上的实验表明:多特征关联声学建模相比于单特征独立声学建模方法可以获得更好的识别性能.
1 基于深层神经网络的声学模型
深度神经网络DNN是具有多隐含层的神经网络,比传统的高斯混合模型GMM具有更强的声学建模能力.DNN与隐Markov模型(hidden Markov model, HMM)结合的方法已经成为语音识别领域的主流框架.图1为一个DNN-HMM模型结构,该模型共有L-1个隐含层,每个隐含层的输出为
yi=σ(xi)=σ(Wiyi-1+bi),1≤i≤L-1,
其中,Wi和bi分别为i层和i-1层之间的权重矩阵和偏移矢量;σ(·)为Sigmoid激活函数,定义为σ(x)=1(1+exp(-x)).输出层为Softmax层,实现对三音子绑定状态(senones)后验概率的估计,定义为
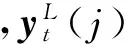
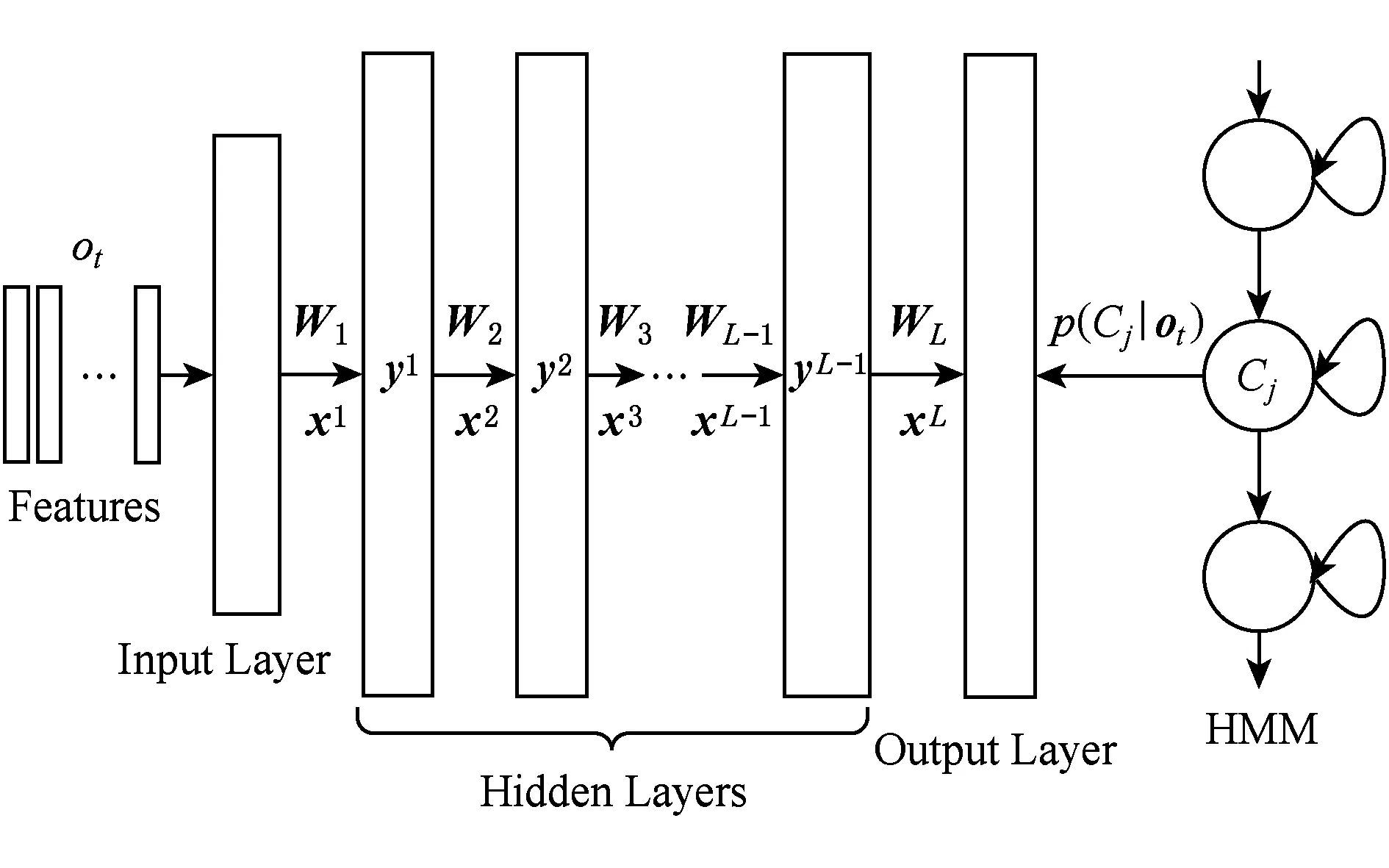
Fig. 1 DNN-HMM structure diagram图1 DNN-HMM结构示意图
对DNN直接使用误差反向传播(back propa-gation, BP)算法进行训练容易使得DNN的参数陷入局部最优解,所以实际中往往是先通过无监督训练的方法预先训练一个深置信网络(deep belief networks, DBN),再利用DBN初始化DNN.完成DNN初始化后,借助BP算法对DNN进行训练,其基本思想是将DNN的训练过程视为一个误差反向传播的过程,在这过程中采用随机梯度下降(stochastic gradient descent, SGD)对网络参数进行更新:
其中,ε为学习速率(learning rate),由于SGD对学习速率比较敏感,因此ε一般设置成一个非常小的数值,以保证DNN的训练收敛;D为代价函数,常用DNN计算得到的预估概率分布与类别的真实概率分布之间的交叉熵(cross entropy, CE)作为代价函数,定义为
其中,dt(j)分别为输入οt对应的第j个senone的目标值.给定代价函数的具体形式后,DNN会在最小化交叉熵准则的指导下完成参数的训练.
2 基于深层神经网络的多特征关联声学模型
2.1 声学特征的提取与处理
本文对Mel频率倒谱系数MFCC、感知线性预测系数PLP以及基于Gammatone的倒谱系数[13](Gammatone frequency cepstral coefficients, GFCC)三种不同的倒谱声学特征进行研究.所有的特征参数采用13维的原始特征及其一阶、二阶差分,总矢量维数为39维.为了增强声学特征的区分性,或降低声学特征的维度以降低声学模型复杂度,原始声学特征在输入DNN前往往需要进行特征变换、特征降维等.图2为本文的声学特征处理流程,首先通过基于说话人的倒谱均值方差规整[14](cepstral mean and variance normalization, CMVN)对倒谱特征的一阶矩和二阶矩(即均值和方差)进行规整,以减小训练数据和测试数据倒谱特征的概率密度函数间的差异,补偿识别中特征参数不匹配造成的影响.规整后的特征与相邻帧(左右5帧)进行拼接得到高维特征矢量,这样每帧特征就含有更多的长时信息.线性判别分析(linear discriminant analysis, LDA)用于对拼接后的超矢量进行降维,从而降低声学模型复杂度提高训练效率.最后,采用特征空间最大似然线性回归(feature-space maximum likelihood linear regression, fMLLR)实现特征参数自适应,以消除测试语音声学特征与声学模型参数间的不匹配.经过上述处理后的特征作为DNN的输入,用于声学模型训练.
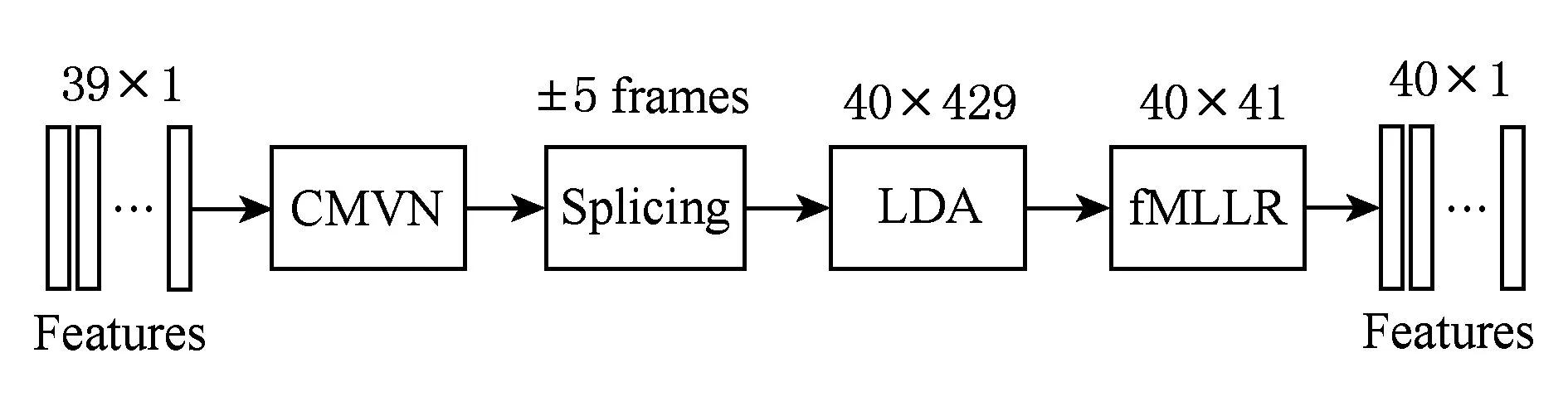
Fig. 2 Processing of acoustic features图2 声学特征处理
2.2 多特征关联声学建模
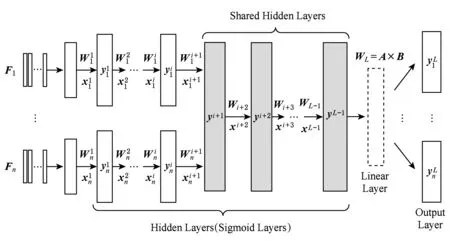
Fig. 3 Acoustic model of multi-features based on DNN图3 基于DNN的多特征关联声学模型
在机器学习中,通过对多个相关任务联合学习来提高各子任务性能的方法称为多任务学习(multi-task learning, MTL)方法.利用该思想,文献[15]采用多语言识别任务共享同一个DNN隐层,实现了不同语言识别任务间的优势互补,从而增强了DNN的泛化能力提升了各语言的识别性能.文献[8]中的多模态DNN特征提取也可以看作多任务学习的一种,即通过不同任务间共享DNN部分隐层实现各特征间的关联,从而增强特征的鲁棒性.采用不同特征进行DNN声学建模时各任务间同样具有很强的联系性,如都是表示的同一组音频数据的信息,具有相近的识别性能以及采用相同的神经网络结构等.综合上述,本文提出多特征流共享隐层(shared hidden layer, SHL)的DNN声学建模方法,如图3所示.利用不同特征进行DNN声学建模时,通过共享部分隐含层,从而为不同特征间建立关联,实现性能的相互促进.这与文献[15]中的MTL-DNN不同,文献[15]中针对不同语言采用相同的输入特征并且隐含层全部共享,而本文针对同一种语言采用不同的输入特征并进行部分隐层共享.进行DNN声学建模时,不同特征并不是直接输入共享隐层,而是首先经过独立隐层的非线性变换,这些变换可以认为是将不同特征向同一特征空间的映射(实验部分将会说明),同时,后端保留各自的输出层以区分不同任务.
2.3 多特征关联DNN的训练
联合后的DNN相比于单任务下的DNN模型参数增多,训练数据增大,这会导致DNN的训练速度变慢.为了加快DNN训练速度,在训练算法方面,除了设置变步长的学习速率外,针对误差曲面“平坦区(plateau)”导致的学习变慢,通过在随机梯度下降(SGD)算法中嵌入“冲量(momentum)” 项,减少总体梯度方向的偏离,从而加快学习速度.令Δθ(i)为第i轮训练参数更新值,则带有冲量项的参数更新公式为
(Wi+1,bi+1)←(Wi,bi)+(1-α)×
ε×η×Δθ(i)+αΔθ(i-1),
其中,ε为学习速率,η为衰减因子,引入“冲量”项后,将随机反向传播中的学习规则修改为包含了以前权值更新量的α倍,“平均化”了随机学习过程中权值的随机更新,增加了稳定性.
在模型结构方面,联合DNN的输出层包含了多个单任务的输出层,因此最后一层的参数数量要远远多于单任务DNN.这也限制了联合DNN的训练速度,并且参数过多在训练时也会占用更多的内存.为了降低DNN的计算和空间复杂度,文献[16]提出了一种低秩矩阵分解LRMF的方法.令最后一层的权重矩阵为A,其维数为m×n.若A的秩为r,则存在满秩分解A=B×C,其中B为m×r的满秩矩阵,C为r×n的满秩矩阵.因此可以考虑将最后一层的权重矩阵A,用具有较少元素(即参数)的矩阵B和C代替.具体实现上,该方法即在输出层与最后一个隐含层之间引入了一个节点为r的线性层,如图3所示,其中r的大小可以通过实验确定.该线性层实为一个线性的瓶颈(bottleneck, BN)层,它的引入一方面减少了最后一层的模型参数,另一方面通过限制最优化目标函数时的搜索空间提高了模型训练效率.
联合DNN的训练采用“预训练+参数调优(fine-tuning)”方式.预训练阶段,在单任务(非共享隐层)DNN结构基础上,利用无监督逐层训练方法(即散度对比方法)完成初始参数估计,在此阶段中训练数据采用所有特征数据.参数调优阶段,网络隐含层分为共享层和非共享层,首先利用预训练阶段得到的权重参数完成初始化,此时非共享隐层的初始参数相同,然后通过基于Mini-Batch的随机梯度下降(SGD)算法[17]实现最终参数估计.具体流程如算法1所示:
算法1. 联合DNN参数训练算法.
输入:特征数据(x1,x2,…,xN)l,l={1,2,3};
输出:DNN权重参数θ=(W,b).
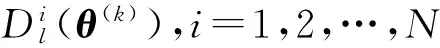
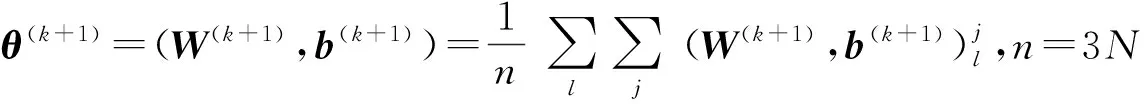
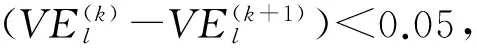
2.4 基于ROVER的系统融合
不同特征的输出结果可以采用融合方法以进一步降低错误率.本文采用ROVER实现不同特征系统间的融合.ROVER通过“投票”机制来利用不同系统间的互补性从而得到更好的识别结果,该系统主要包括2个模块:词对齐(word alignment)和投票(voting).通过词对齐实现不同系统线性输出结果的强制对齐并得到词转移网络(word transition network, WTN).对词转移网络进行重打分,从而得到更好的识别结果,重打分计算为
其中,N(wi)为词w在WTN的第i个对齐位置出现的次数,C(wi)是词置信度得分,α为权重.置信度得分有2种选择:最大置信度得分和平均置信度得分,即分别对各系统输出的置信度取最大值或平均值作为重估后的置信度打分.本文将在实验中对2种置信度得分进行讨论.
3 实验结果及分析
3.1 实验数据及设置
为了验证本文方法的有效性,本节针对一个典型的连续语音识别系统进行实验.实验数据采用TIMIT语料库[18],训练集(TEST)包含462个说话人,共3 696句话,约为3.14 h的数据;开发集(DEV)共有50个说话人、400句话、总时长约为0.34 h;测试集包含24个说话人、192句话、总时长约为0.2 h.实验主要基于开源工具包Kaldi以及Pdnn*http://www.cs.cmu.edu/~ymiao/kaldipdnn.html搭建.所有声学特征为13维的原始特征及一阶和二阶差分系数,总的特征矢量维数为39,帧长为25ms,帧移为10ms.HMM-GMM模型采用最大似然估计(maximum likelihood estimate, MLE)方法得到,其中HMM模型为包含3个发射状态的、自左向右无跨越的三音素模型.对MFCC,PLP,GFCC特征分别采用决策树进行状态聚类后,系统最终包含2 024,2 035,2 037个不同的上下文相关状态.用GMM对各状态建模,特征不同,各状态GMM的混元数也不同.最终,3种特征的声学模型中分别包含15 021(MFCC),15 015(PLP),15 018(GFCC)个高斯混元.实验中所有的DNN模型设置4个隐含层,每层包含1 024个节点.输入为2.1节所述特征矢量,输出节点与聚类状态数一致.预训练过程中,mini-Batch设置为128,对于底层的高斯-伯努利以及其余4个伯努利-伯努利均采用5个epoch训练.高斯-伯努利RBM(restricted Boltzmann machine)的学习速率为0.005,伯努利-伯努利RBMs的学习速率为0.08.在精细调整过程中,采用BP算法进行参数更新,学习速率初始设为0.08,并根据校验集的性能改善,进行折半调整.实验平台为4核Intel Core i7-3770@3.40 GHz CPU.所有实验采用音素错误率(phones error rates, PER)作为评价指标.
3.2 实验结果与分析
1) 基于LDA拼接特征的性能对比实验
表1给出了不同特征下的识别性能对比,其中,前3行采用单特征,后4行为采用基于LDA降维的拼接特征(降维后的特征矢量为60维).从实验结果来看,3种声学特征因特性存在差异故而具有不同的识别性能.当声学模型采用GMM模型时,拼接特征并没有带来识别性能上的改善,但是当采用基于DNN进行声学建模时,可以得到略优于单特征的识别性能,这与文献[13]中的结果基本一致.利用GMM模型进行声学建模时,协方差矩阵一般采用对角阵,因此特征矢量各维分量间的相关性越小则估计得到的协方差矩阵越准确.拼接特征虽然含有更多的信息,但是由于不同特征间可能存在一定的相关性,这会造成对角矩阵的假设不合理,并且也会对LDA投影矩阵的估计造成一定影响(文献[2]中也指出了这个问题),从而降低识别性能.DNN对输入特征维数以及各分量间的相关性并不敏感,拼接特征含有更多的信息,就会更有利于提取准确的高层抽象特征,从而获得性能的提升,但从实验结果来看拼接特征对系统性能的提升有限.
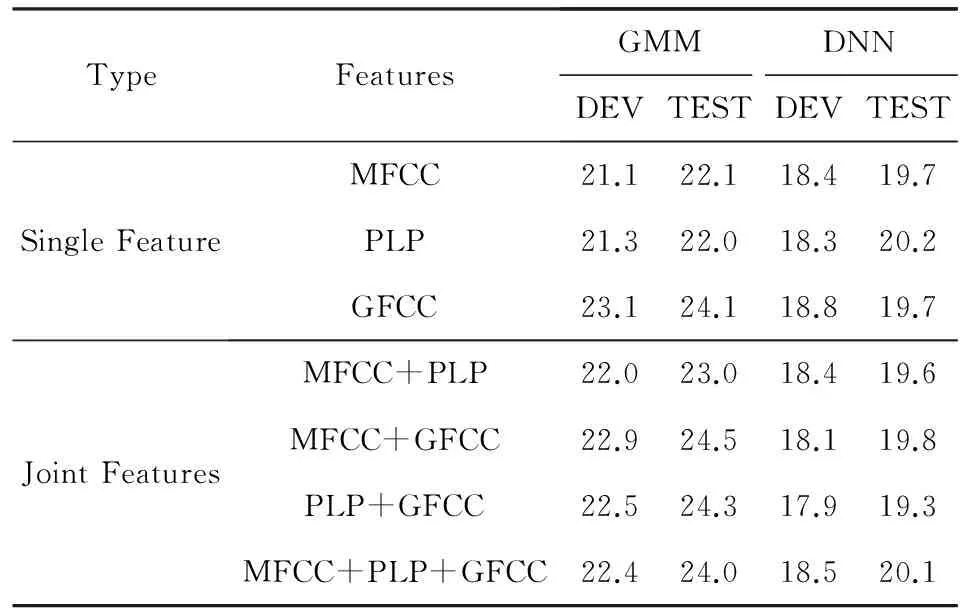
Table 1 PER of Different Acoustic Features表1 不同特征下的音素识别错误率 %
2) 共享隐层下的各特征性能对比实验
为了探讨共享隐含层数的多少对系统性能的影响,我们采用MFCC特征以及PLP特征进行声学模型训练,表2给出了共享隐含层数分别为1(表示仅最后一层共享,以此类推),2,3,4下的2种特征的识别性能.可以看出,系统的识别性能确实受到共享隐层数的影响,共享隐含层数少则可能无法有效学习到各特征间的关联性,而共享隐含层数多则对于某种特征,其优势可能受其他特征影响而掩盖.通过比较MFCC与PLP这2种特征在不同隐含层数下识别性能可知,通过共享部分隐层,除PLP特征在共享隐层数为4时测试集性能略微下降外,其余情况下2种特征的识别性能都要优于非共享隐层时的最佳识别性能(开发集最低PER为18.3%,测试集最低PER为19.7%),这证明了所提方法的有效性.如表2所示,当共享隐层数为2时,2种特征均取得了较好的识别性能,因此我们采用共享隐含层数为2进行其他特征的共享隐层实验.
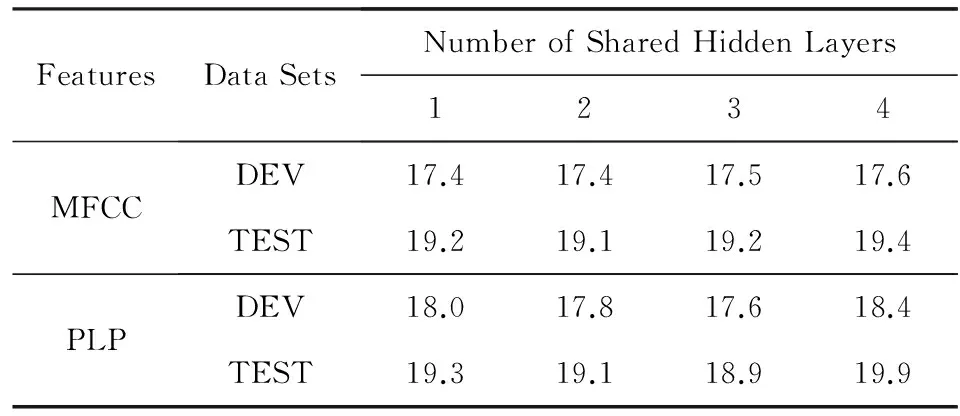
Table 2 PER of Different Number of Shared Hidden Layers表2 不同共享隐层数下的音素识别错误率 %
表3为当共享隐含层数为2时不同特征的识别性能对比.从实验结果可以看出,通过共享隐层,各声学特征的识别性能普遍优于单任务下的识别性能.其中,MFCC,PLP特征的性能提升更为明显.PLP特征与GFCC特征共享隐层时,采用PLP特征测试集得到最低的错误率(18.8%),性能提升约7%(相比于单任务下的20.2%).值得注意的是,根据表1,这2种特征拼接也具有最佳识别性能,说明GFCC特征可以为PLP特征提供更有效的互补信息.3种特征共享隐层,可以看到PLP特征的识别性能有所降低,说明进行关联建模时并不是采用特征越多,对所有特征的性能改善就越好.在何种情况下能够得到最佳识别性能要根据实际情况通过实验来确定.
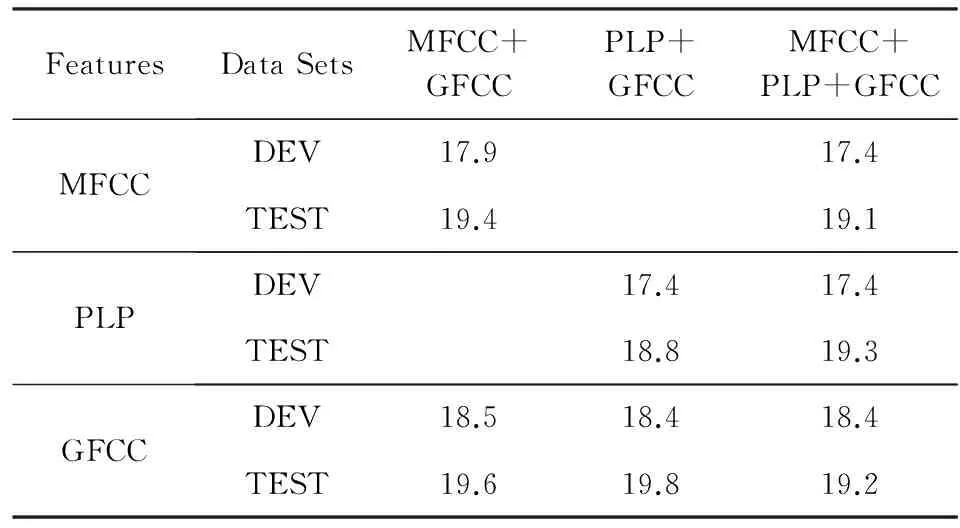
Table 3 PER of Different Features When Sharing the Hidden Layers
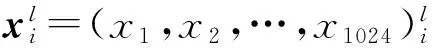
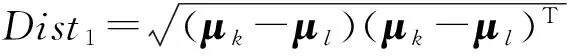
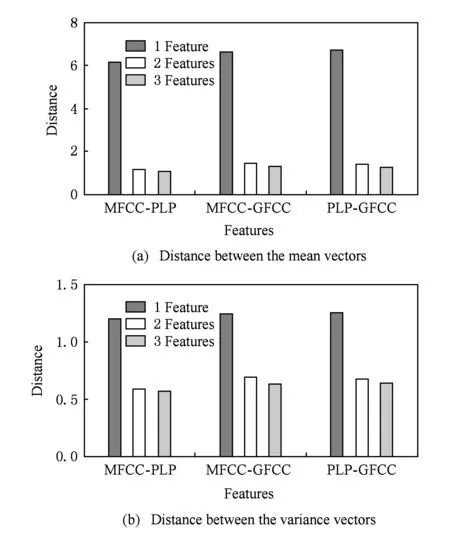
Fig. 4 Distance between the mean and variance vectors of the outputs at the 2nd hidden layers of different features图4 特征矢量在第2隐含层输出均值和方差间的距离
采用LRMF进行DNN加速训练时,需要确定最后一层权重矩阵秩r的大小,即确定线性层的节点数量.表4给出了采用3种声学特征进行共享隐层DNN训练时,r在不同取值下的各特征的识别性能以及训练时间.可以看出,通过在输出层前引入节点数较少的线性层,模型训练时间大大缩短,r越小则训练速度越快.当节点数为128时,系统的识别性能已与不采用LRMF时的系统性能相当,但是训练时间缩短了16 h左右.增加节点数,系统性能有略微的提升,但是训练时间也会增大.在模型参数上,不引入线性层时隐含层与输出层间共有1 024×(2 024+2 035+2 037)=6 242 304个参数,约占系统总参数的55%.引入节点数为128的线性层后隐含层与输出层间的参数变为1 024×128+128×(2 024+2 035+2 037)=911 360,参数总规模减少约47%.因此通过采用LRMF在不降低系统性能的前提下,大大提高了模型的训练速度并减少了参数规模.
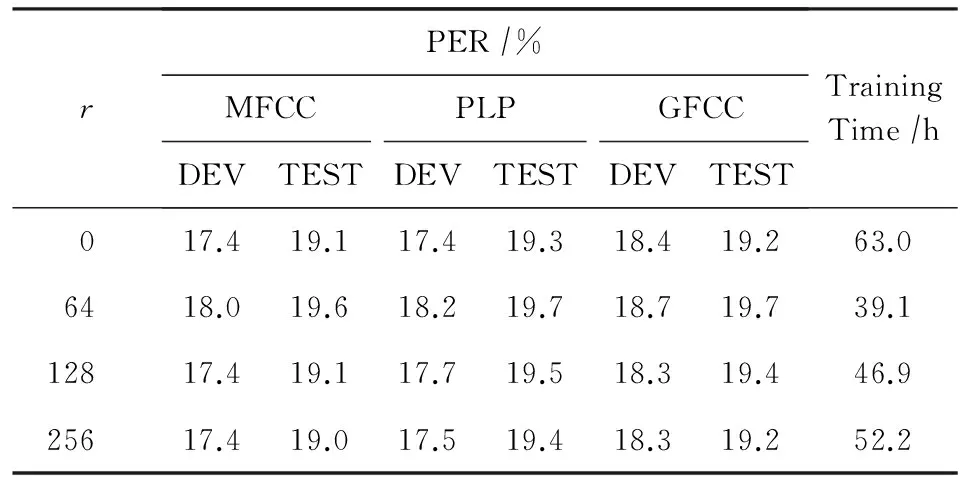
Table 4 Performance of Recognition and Training Time by Using Different Linear Layer Nodes表4 线性层节点数对识别性能以及训练时间的影响
3) 基于ROVER的融合实验
3种不同声学特征系统融合的实验结果如表5所示.表5中给出了基于GMM声学模型、基于单任务(single-task,STL) DNN声学模型以及基于3种特征共享隐层DNN声学模型的测试集融合实验结果.实验采用开发集PER作为指标,利用格点搜索方法确定重打分公式中的权重α.表5中分别列举了2种不同的置信度融合策略: 最大置信度准则(max confidence standard, MCS)和平均置信度准则(average confidence standard, ACS)对系统性能的影响.显然,通过系统融合各系统性能进一步提升,共享隐层DNN改进最为显著,其融合最优结果为18.5%,相比于单任务DNN融合结果(19.4%),提高约4.6%.就置信度融合方法来讲,2种融合准则性能相近,ACS方式略优于MCS,其原因可能在于MCS选择用最大置信度得分,当某一错误识别结果置信度过大时,采用MCS无法避免该错误,而ACS通过将多个系统输出结果的置信度进行平均,可以在一定程度上降低这种错误,从而降低系统错误率.
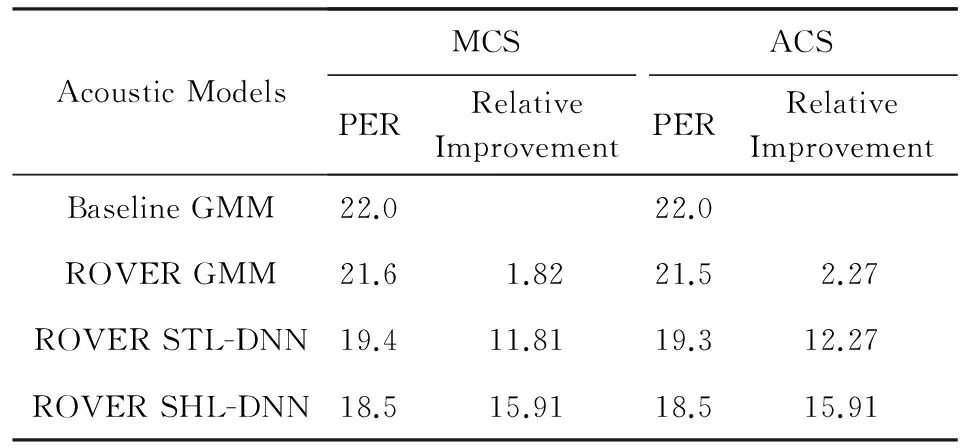
Table 5 PER of the Test Data Sets by Using ROVER Combination
4 结束语
本文提出了一种基于深层神经网络的多特征关联声学建模方法.新方法在利用不同的声学特征进行DNN声学建模过程中,通过共享部分隐层,建立不同模型间的关联关系,实现不同特征间的信息传递.采用ROVER算法对不同特征识别结果进行融合以进一步提高识别性能,同时针对联合后的DNN网络参数过多、训练较慢问题,在最后一层采用低秩矩阵分解方法,减少参数规模,提高运算效率.实验证明,新方法的识别性能要优于原采用单特征进行DNN声学建模时的识别性能.在未来研究中,可进一步考虑更深层网络结构的隐层共享、中间隐层共享以及对噪声情况下的识别影响等问题.
[1]Bao Yebo. Deep neural network based acoustic feature extraction for LVCSR systems[D]. Hefei: University of Science and Technology of China, 2014 (in Chinese)(包叶波. 基于深层神经网络的声学特征提取及其在LVCSR系统中的应用[D]. 合肥: 中国科学技术大学, 2014)
[2]Schluter R, Zolnay A, Ney H. Feature combination using linear discriminant analysis and its pitfalls[C] //Proc of the 7th Annual Conf of the Int Speech Communication Association. Grenoble, France: ISCA, 2006: 345-348
[3]Andras Z, Ralf S, Hermann N. Acoustic feature combination for robust speech recognition[C] //Proc of Int Conf on Acoustics, Speech, and Signal Processing. Piscataway, NJ: IEEE, 2005: 457-460
[4]Kumar M, Aggarwal K, Leekha G. Ensemble feature extraction modules for improved Hindi speech recognition [J]. International Journal of Computer Science Issues, 2012, 9(3): 175-181
[5]Yu Dong, Deng Li. Automatic Speech Recognition: A Deep Learning Approach[M]. Berlin: Springer, 2015: 57-77
[6]Tuske Z, Golik P, Nolden D, et al. Data augmentation, feature combination, and multilingual neural networks to improve ASR and KWS performance for low-resource languages[C] //Proc of the 15th Annual Conf of the Int Speech Communication Association. Grenoble, France: ISCA, 2014: 1420-1424
[7]Andros T, Sakriani S, Graham N, et al. Combination of two-dimensional cochleogram and spectrogram features for deep learning-based ASR[C] //Proc of the 40th IEEE Int Conf on Acoustics, Speech, and Signal Processing. Piscataway, NJ: IEEE, 2015: 4525-4529
[8]Ngiam J, Khosla A, Kim M. Multimodal deep learning[C] //Proc of the 22nd Int Conf on Machine Learning. New York: ACM, 2011: 689-696
[9]Ngiam J, Chen Z, Koh P. Learning deep energy models[C] //Proc of the 22nd Int Conf on Machine Learning. New York: ACM, 2011: 1105-1112
[10]Chen D, Brian M, Leung C C. Joint acoustic modeling of triphones and trigraphemes by multi-task learning deep neural networks for low-resource speech recognition[C] //Proc of the 39th IEEE Int Conf on Acoustics, Speech, and Signal Processing. Piscataway, NJ: IEEE, 2014: 5629-5633
[11]Ciresan D C, Huval B, Wang T, et al. Transfer learning for Latin and Chinese characters with deep neural networks[C] //Proc of the 2012 Int Joint Conf on Neural Networks. Piscataway, NJ: IEEE, 2012: 1-6
[12]Fiscus J G. A post-processing system to yield reduced word error rates: Recognizer output voting error reduction (ROVER)[C] //Proc of IEEE Automatic Speech Recognition and Understanding Workshop. Piscataway, NJ: IEEE, 1997: 347-354
[13]Plahl C, Schluter R, Ney H. Improved acoustic feature combination for LVCSR by neural networks[C] //Proc of the 12th Annual Conf of the Int Speech Communication Association. Grenoble, France: ISCA, 2011: 1237-1240
[14]Prasad N V, Umesh S. Improved cepstral mean and variance normalization using bayesian framework[C] //Proc of Automatic Speech Recognition and Understanding Workshop. Piscataway, NJ: IEEE, 2013: 156-161
[15]Mohan A, Rose R. Multi-lingual speech recognition with low-rank multi-task deep neural networks[C] //Proc of the 40th IEEE Int Conf on Acoustics, Speech, and Signal Processing. Piscataway, NJ: IEEE, 2015: 4994-4998
[16]Sainath T N, Kingsbury B, Sindhwani V, et al. Low-rank matrix factorization for deep neural network training with high-dimensional output targets[C] //Proc of the 38th IEEE Int Conf on Acoustics, Speech, and Signal Processing. Piscataway, NJ: IEEE, 2013: 6655-6659
[17]Li Muli, Zhang Tong, Chen Yuqiang, et al. Efficient mini-batch training for stochastic optimization[C] //Proc of the 20th ACM Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2014: 661-670
[18]Zue V, Seneff S, Glass J. Speech database development at MIT: TIMIT and beyond[J]. Speech Communication 1990, 9(1): 351-356
Joint Acoustic Modeling of Multi-Features Based on Deep Neural Networks
Fan Zhengguang, Qu Dan, Yan Honggang, and Zhang Wenlin
(Institute of Information System Engineering, PLA Information Engineering University, Zhengzhou 450002)
In view of the complementary information and the relevance when training acoustic modes of different acoustic features, a joint acoustic modeling method of multi-features based on deep neural networks is proposed. In this method, similar to DNN multimodal and multitask learning, part of the DNN hidden layers are shared to make the association among the DNN acoustic models built with different features. Through training the acoustic models together, the common hidden explanatory factors are exploited among different learning tasks. Such exploitation allows the possibility of knowledge transferring across different learning tasks. Moreover, the number of the model parameters is decreased by using the low-rank matrix factorization method to reduce the training time. Lastly, the recognition results from different acoustic features are combined by using recognizer output voting error reduction (ROVER) algorithm to further improve the performance. Experimental results of continuous speech recognition on TIMIT database show that the joint acoustic modeling method performs better than modeling independently with different features. In terms of phone error rates (PER), the result combined by ROVER based on the joint acoustic models yields a relative gain of 4.6% over the result based on the independent acoustic models.
speech recognition; deep neural network (DNN); acoustic models; low-rank matrix factorization; fusion

Fan Zhengguang, born in 1990. Postgraduate of PLA Information Engineering University. His research interests include pattern recognition and speech recognition.

Qu Dan, born in 1974. PhD. Associate professor of PLA Information Engineering University. Her main research interests include machine learning, intelligent information processing and speech recognition (qudanqudan@sina.com).

Yan Honggang, born in 1975. Master, assistant professor. His main research interests include communication signals processing and signal analysis (yanhonggang@gmail.com).

Zhang Wenlin, born in 1982. Received his PhD degree from PLA Information Engineering University. His main research interest include machine learning, intelligent information processing and speech recognition (zwlin_2004@163.com).
2016-01-18;
2016-07-05
国家自然科学基金项目(61175017,61403415,61302107) This work was supported by the National Natural Science Foundation of China (61175017, 61403415, 61302107).
TP391.4; TN912.3
猜你喜欢
计算机工程与应用(2022年15期)2022-08-09
浙江大学学报(理学版)(2022年4期)2022-07-25
复旦学报(自然科学版)(2022年1期)2022-06-16
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
家庭影院技术(2020年6期)2020-07-27
人民珠江(2019年4期)2019-04-20
家庭影院技术(2019年1期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年10期)2018-11-02
