
传感器网络中语义事件区域查询处理
2017-05-13 03:43李英龙朱艺华吕明琪
计算机研究与发展 2017年5期
李英龙 朱艺华 吕明琪
(浙江工业大学计算机科学与技术学院 杭州 310023)(liyinglong@zjut.edu.cn)
传感器网络中语义事件区域查询处理
李英龙 朱艺华 吕明琪
(浙江工业大学计算机科学与技术学院 杭州 310023)(liyinglong@zjut.edu.cn)
传感器网络可以看成是一个资源受限的无线分布式数据库系统,如何设计低功耗高可靠的数据处理方法,从分布式的感知数据中获取用户感兴趣的信息是一个挑战性工作.现有的事件(区域)检测方法大都基于原始的感知数据,处理大规模的原始感知数据的通信和时间开销很大,然而这些原始数据由于本身的不精确性和不确定性,难以保证得到精确的处理结果.大多数情况,用户并不关心这些原始感知数据或者网内过滤/融合时的数据形态,而是想得到类似自然语言的“有多严重?” 、“可信吗?”等语义事件信息.此外,现有的事件区域检测方法主要是利用邻居协作来提高检测的准确性,而邻居协作需要大规模的网内数据交换,非常耗时耗能.鉴于上述问题,提出一种新的基于模糊方法的语义事件区域查询处理方法,语义事件信息代替原始的感知数据用于网内过滤和融合,并设计了基于模糊方法的分布式语义事件信息表示、过滤和融合算法.基于真实数据集的仿真实验表明了该方法在兼顾节能和可靠性方面有良好的表现.
语义事件信息;模糊方法;能量有效性;可靠性;传感器网络
传感器节点计算、存储、通信能力十分有限,尤其是能量供应受限,在很多应用中更换电池或者充电是难于做到的,因此无线传感器网络可以看成是一个资源受限(尤其能量有限)的无线分布式数据库系统.如何设计节能而可靠的数据处理算法,从分布式的感知数据中获取用户感兴趣的信息是一个挑战性工作.由于传感器网络的通信开销主要是用于数据传输,因此在满足用户精度要求下降低网络数据传输量是一个有效的解决方法.此外,减少数据传输量还可以提高处理的响应速度,以及减少无线通信中的信号干扰.
事件(区域)检测是传感器网络/物联网应用中的一类非常重要的任务[1-15],尽早地发现潜在事件并及时处理,可有效地减少灾害损失.获取事件信息可分为用户主动查询监控区域内的潜在事件信息,以及感知节点自发检测并上报事件信息.目前这类研究主要包括基于单个节点的简单事件检测[5,11-12]和基于邻居协作的复杂事件检测[6,8,10],这些方法在兼顾节能性、实时性和可靠性方面仍存在不少问题.
1) 单节点事件检测.事件定义往往取决于具体的应用问题,也影响着事件检测的效率.在感知节点稀疏部署(单个节点覆盖区域内的冗余节点较少)且节点稳定可靠的情况下,单个节点就可以完成局部事件检测.这种方法的最大优点是网内数据传输量少,处理也非常及时,但是结果的准确性难以保证,特别是对于用户想查询k个最严重事件区域的情况,往往不大适用.例如在煤矿安全监控系统中,感知节点用于监测瓦斯浓度,如图1所示,标注有瓦斯浓度(%)数据的节点是值得关注的潜在事件节点.在单节点事件检测方法中,top-3事件查询的结果是{S1,S2,S3},这些结果均来自同一个区域,而用户的本意可能是查询以S2,S8,S12为中心的事件区域.另一方面,单节点事件检测由于缺少空间相关性信息分析,容易造成事件误报,如图1所示,孤立事件节点S16可能是一个误报.
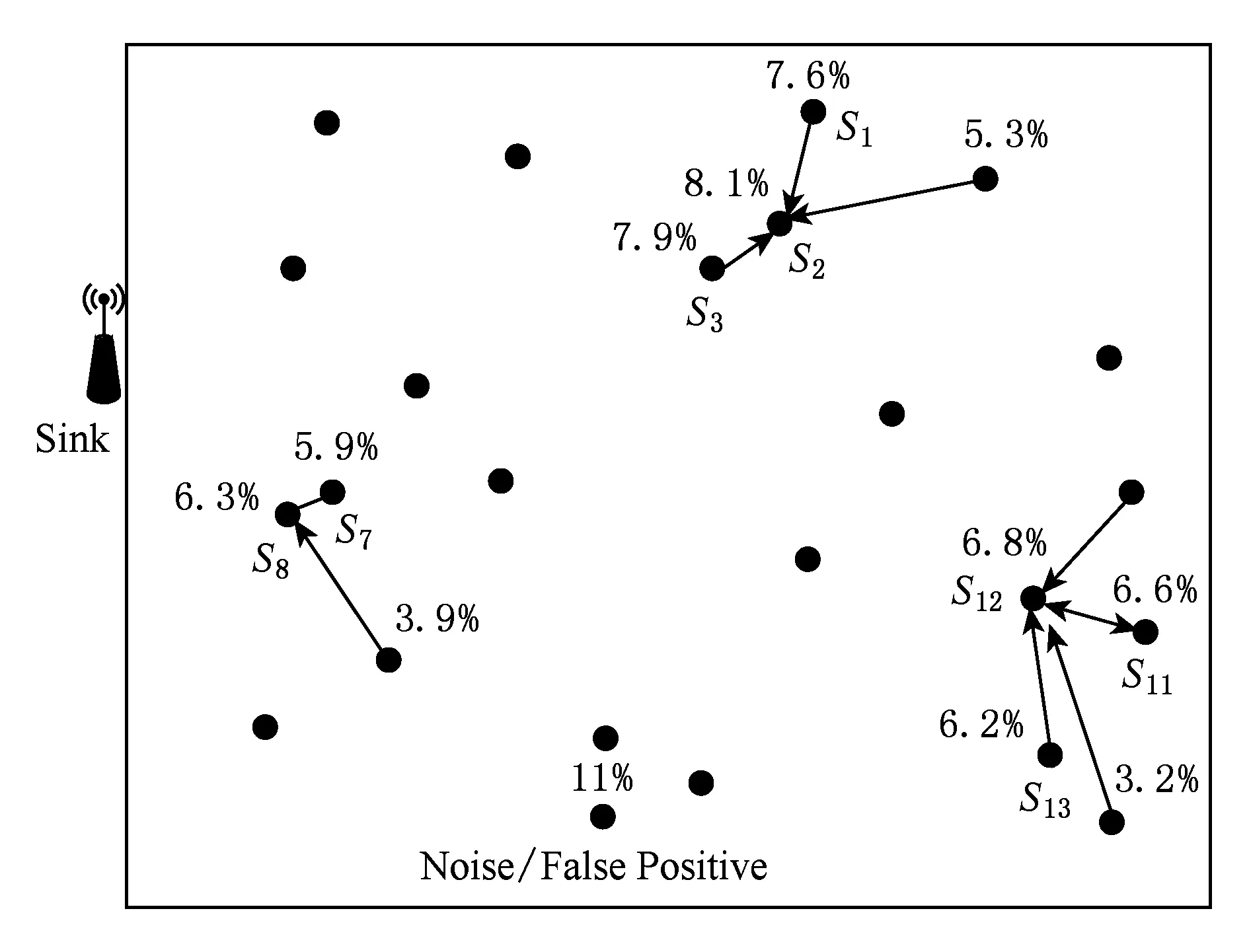
Fig. 1 Example of coal mine gas concentration monitoring图1 煤矿瓦斯浓度监测示例
2) 邻居协作事件检测.在实际应用中,感知节点的部署会较为稠密,即有一定的冗余,这样可以利用空间相邻节点交换感知数据来提高事件检测的准确性,这类代表性研究就是基于权重的“投票(voting)技术”[6-7].该方法的好处是可以减少单个异常节点的误报以及事件区域的漏报,从而提高事件检测的可靠性.例如图1中,基于邻居协作的top-3事件区域查询能正确找出S2,S8,S12为代表的3个事件区域.然而此类事件检测方法,需要大量相邻节点之间的信息交换,对于实时性和节能性来说,代价非常高.
此外,现有的事件检测方法大都基于原始的感知数据,处理大规模的原始感知数据的通信和时间开销很大,而且这些原始数据由于本身的不精确性和不确定性,难以保证得到精确的结果.然而在实际应用中,用户并不关心这些原始感知数据或者网内过滤/融合时的数据形态,而是想知道类似自然语言的“严重性” 、“可信度”等语义事件信息.
本文提出一种低功耗可靠的语义事件区域查询处理方法.提出语义事件信息代替原始感知数据用于网内融合和传输,可明显降低数据传输量.给出基于模糊方法的事件可信度测量方法和非均匀离散化的语义事件信息表示方法,并设计基于模糊方法的语义事件信息过滤和网内融合算法,最后从节能和可靠性等方面,基于真实数据的仿真实验验证了此方法的有效性.
1 模型与问题定义
1.1 网络模型
在事件监测系统中,感知节点部署到监控区域内自组织形成一个连通的网络.感知节点部署通常包括随机部署、规则部署和按需部署3种方法,每种部署方法都有各自的适用场景.其中规则部署和按需部署由于人工干预,通常能保证一定的网络连通性,而随机部署则需要关注网络的连通性,通常的做法是引入泊松点过程(Poisson point process)假设[16].泊松点过程是广泛存在的,例如建模一个确定空间的星星数量或者描述皮氏培养皿中的细菌数等.本文网络部署引入泊松点过程是因为它符合多数人对于“随机部署”的直觉概念.
此外我们将监控区域基于地理位置逻辑划分成若干网格,每个格内选择一个格管理(grid manager,GM)节点,用于收集局部事件信息和管理局部网络拓扑结构,被选中的GM可以更高的通信频率形成一个以Sink节点为根的TAG[17]树形路由结构GM-Tree,如图2所示:
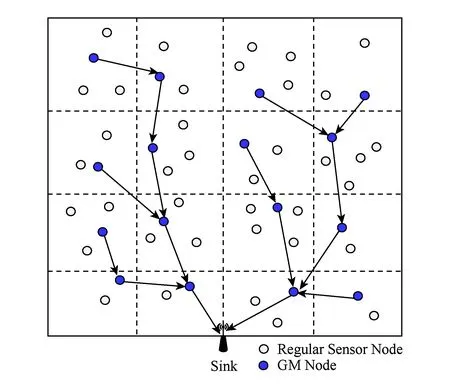
Fig. 2 Grid network model based on uniform Poisson point process—GM-Tree图2 基于均匀泊松点过程的格网络模型——GM-Tree
值得注意的是,我们的网格划分是基于地理位置的逻辑划分,不需要像分簇网络[18]那样需要专门的簇结构管理算法.网格的大小可以根据节点的通信半径和监控区域的大小而定,基本原则是每个网格覆盖较多的节点,以保证一定数量的空间相关性节点用于事件区域检测.GM的选择方法也很多,比如可以离格中心最近的节点作为GM,这样可使得GM收集本地事件信息的总能耗少;或者选择剩余能量最大的节点为GM,这样有利于网络能量均衡.可以根据实际情况选择GM.
此外,基于地理位置的网络模型具有良好的鲁棒性和可扩展性.当一个节点移动或增加到某一个网格中时,节点可以根据其地理坐标(GPS定位装置)计算得到其所属的网格.当一个GM失效或者移动到另一个网格时,它周围的节点能够发现它的移动并且按一定方法选择新的GM.
1.2 问题定义
定义1. 语义事件区域查询(semantic event region query,SERQ).SERQ查询监控区域内k最有可能发生的潜在事件区域位置及其语义信息,可形式化为一个四元组:
SERQ=(Γ,n,k,QType),
其中,Γ为查询覆盖节点的集合,一般为监控区域的所有的节点;n为查询的最近的采样周期数,与采样周期间隔长短有关,采样周期间隔越长,n越小;k为返回查询结果的个数,在事件监控系统中,由于人力物力限制,往往只能同时处理k个潜在事件,如果没有这个限制,则返回所有可能的潜在事件区域位置;QType是事件类型,事件类型决定了事件定义模型.
值得注意的是,一个事件监测系统通常有默认的事件类型,比如煤矿安全监控系统中通过监测瓦斯浓度发现潜在瓦斯爆炸事件、森林安全监控系统中查询潜在火灾事件、现代精细化农业管理中温度和湿度感知节点常用于查找需要浇灌的事件等.节点在部署前一般被嵌入默认的事件可信度模型或事件概率模型,如果要更改查询的事件类型,那么需要基站广播新的事件模型给每个节点,以更新原来默认的事件模型.
定义2.SERQ的查询结果rst也可用一个三元组形式化表示:
rst=(nodeID,sev,serc),
其中,nodeID是相同或相似事件区域的代表性节点的位置,这个代表性位置监控区域内最接近真实潜在事件的位置;sev为语义事件变量(semantic event variable),sev使用接近人类自然语言来描述一类严重程度的潜在事件语义信息,详见2.3节中的语义事件信息表示方法;serc为语义事件区域可信度(semantic event region confidence),用于表示潜在事件区域是否存在的可信度.
总体来说,在SERQ中,用户不关心具体的感知数据,也不关心网内融合的数据格式,只关心最严重k个潜在事件的语义信息及其最可能的发生位置.
2 语义事件信息表示
2.1 感知数据清洗
事件检测应该消除错误感知数据对事件分析的影响.错误数据通常有2个主要来源:1)失效节点;2)正常节点的噪音数据.一般来说,实时事件监测系统中采样周期都相对较短,那么可以基于最近n(n≥1)次采样周期内的感知数据来进行实时事件检测分析.现有噪声数据检测方法,大都利用时空相关性分析来发现和消除错误感知数据,其中空间相关性分析需要大量的相邻节点信息交换[14,19],非常耗时耗能,因此我们只利用节点局部的时间相关性分析来消除错误数据.尽管这不能消除所有的错误数据,但可以消除大部分错误数据,而且几乎没有通信代价,非常适用于低功耗的实时事件检测.
对于失效节点,它的大部分数据会明显偏离正常的取值范围,因为传感器网络应用中,感知节点常用于感知物理环境,正常情况下物理环境值通常在一个合乎常理的取值范围R之内,比如说在精细化农业管理中,土壤盐碱度的取值范围通常为[0,80%],如果某个盐碱度感知节点的大部分采样值超过100%,甚至是负值,那么该节点极有可能就是一个失效节点.此外,失效节点的感知数据通常不具备时间相关性或者标准差难以接受.对于失效节点的感知数据,应该被提前过滤,以免事件误报.
对于正常工作的节点,其采集的大部分感知数据符合一个正常模式V,少部分采样周期内的感知数据明显偏离正常取值范围R或者均值λ,这部分感知数据称为噪声数据.我们之前的研究[8]提出一种识别和消除噪音数据的方法(improved smoothing factor, ISF),ISF方法可以根据精度需要,通过设定标准值阈值,消除那些明显偏离均值的噪声数据,可以有效提高事件区域检测的可靠性.
2.2 事件可信度测量
模糊方法[20]是扎德(Lotfi Zadeh)教授在1965年创立的,它以相对的、鲁棒的和易于理解的方式分析处理复杂系统中的不精确和不确定数据.语言变量代替数值变量用于描述系统的行为,这为人们处理不确定性问题和近似问题提供了一种新的解决方法[21].
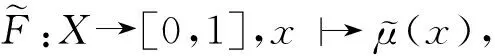
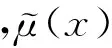
其中,xi(i=1,2,…,m)是节点的感知数据,m为感知数据的维数,avg(xi)是每维感知数据的平均值.在2.1节中,数据清洗消除了大部分错误数据,我们可以用最近几个采样周期内的感知数据的平均值来定义事件点的可信度.ωi(i=1,2,…,m)是可调因子,用于调节各属性对于事件概率的影响程度,ω1+ω2+…+ωm=1.fun和fi可在领域专家指导下设定.
其中,α是一个0~1之间的指定值,即α∈[0,1].通常α=0.5,表示最大不确定性的临界值.
定义5. 事件的0.5-截集内的所有事件点称为值得关注的的事件节点(noteworthy event node, NEN).
上述定义是为了提早过滤那些可信度较低的事件节点,即过滤那些安全的感知数据,以减少网内通信开销.
2.3 语义事件信息表示
非均匀的事件可信度离散化方法:把NEN可信度ec的取值范围[α,1)划分成若干区间大小不等的子范围Rsub,这种非均匀的划分可以基于某种数学模型(如等差数列),也可以在领域专家指导下设定,遵循的原则是ec越大,其所处的子范围区间越小.
例1. NEN可信度ec的取值范围为[0.5,1),它被划分为6个不均匀的子区间,如表1中第4列所示.事件可信度取值越靠近1的Rsub,其区间间隔大小越小(0.03),越靠近α的子范围区间间隔越大(0.16).这样划分的好处是可用较多的语言变量(表1中第1列)来描述较严重的语义事件信息,有助于事件信息网内融合时提高事件检测的可靠性.
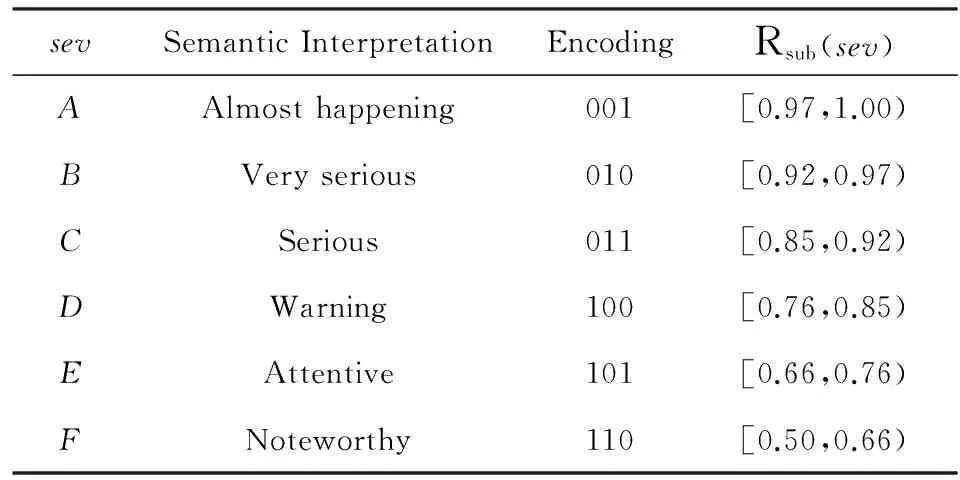
Table 1 Example of Semantic Event Information Description表1 语义事件信息表示示例
语义事件信息表示方法:根据非均匀的事件可信度离散化方法,可以得到若干个区间大小不等的子范围,我们定义相同数量的语义事件变量sev.每个子范围对应着一个语义事件信息变量及其语义解释,如表1中第1列、第2列所示.每个sev描述同一类严重程度的事件信息,区间间隔越小的子范围对应的sev描述越严重的事件信息.在实际应用系统设计时,GM节点还可以对语义事件变量进行二进制编码,如表1中第3列所示,以进一步降低网内通信开销.
例2. 在表1中,6个子范围对应着6个sev,每个sev的语义解释如表1中第2列所示,这些语义解释可以帮助用户容易地理解返回的结果信息,而不需要领域专家的指导.4个sev用于描述较为严重的事件信息,只有2个sev用来描述不重要的(事件可信度低于0.76)事件信息,这有利于提高事件信息表示的准确性.
3 语义事件区域信息查询处理
3.1 格内语义事件区域信息处理
格内语义事件信息过滤和存储的过程为:每个节点根据2.2节式(2)计算本地语义事件的可信度;再根据定义6过滤0.5-截集内的所有事件点,即非NEN被过滤;然后根据2.3节语义事件信息表示方法得到本地语义事件变量sev,并发送其nodeID和sev到本格GM,GM有一张列表List,存储每个接收到的nodeID及其对应sev.
定义6. 语义事件区域可信度serc描述局部事件区域存在的可信度,这种可信度和格内NEN数量有直接的关系,本文提出一种几乎没有额外通信代价的基于格内NEN数量的serc计算方法:
其中,List.size为格内NEN数量.当某格内NEN数为零时,表明潜在事件和事件区域都不存在;当只有1个NEN时,表明是孤立的NEN,误报的可能性比较大,这时serc=0.5;当格内有2个以上的NEN时,那么潜在事件事件区域的可信度非常高,这时跃阶函数serc的基数设为0.9,并随着NEN数增加而增加;当空间相关的NEN数量为4或以上时,那么潜在事件事件区域的必然存在,serc=1.从理论分析和实际应用角度上看,跃阶函数serc的设计是比较可行的.
根据上述格内语义事件信息过滤和存储过程描述,我们可以设计格内语义事件区域信息处理分布式算法如下:
算法1. Inner-GM_SERQ_Process.
输入:SERQ查询消息;
输出:List(nodeID,sev),sercofGM.
步骤1. 每个节点根据2.2节式(2)计算本地事件点可信度;
步骤2. 根据定义6过滤0.5-截集内的所有事件点,即非NEN被过滤.
步骤3. 每个NEN根据2.3节语义事件信息表示方法得到本地语义事件变量sev,并发送其nodeID和sev到本格GM;
步骤4.GM内的List存储每个接收到的nodeID及其对应sev,并根据定义7中式(3)计算该格serc值.
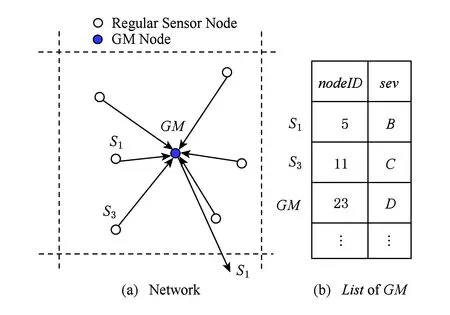
Fig. 3 Example of inner-grid semantic event information processing图3 格内语义事件信息处理的例子
例3. 算法1的一个运行例子如图3所示,在某个格GM内,GM收集所有的NEN,在图3中NEN为S1,S3,GM本身,这些NEN的语义事件点信息存储在GM的List中.算法1根据定义6式(3)计算该格内存在事件区域的可信度为0.98.由于S1的语义信息最严重,因此它将作为该事件区域代表被发送给GM的父GM节点.
算法1时间复杂度分析如下:算法1中各NEN发送消息包时是分布式的,GM接收多个NEN事件消息包时是串行通信的.假设格内最大节点数为h,不考虑计算时间开销,算法1的时间复杂度为Tt+h×Tr,其中Tt为传感器节点发送一个消息包的时间,Tr为GM接收一个事件消息包的时间.
3.2 网内语义事件区域信息融合
这里说的网内是指GM-Tree格与格之间,包括叶子GM语义事件区域信息过滤传输,以及非叶子GM语义事件区域信息融合.
在给出网内语义事件区域信息融合算法之前,我们基于模糊方法中的t-余模运算[20]定义语义事件变量比较操作符,用于选举格内代表性事件点.
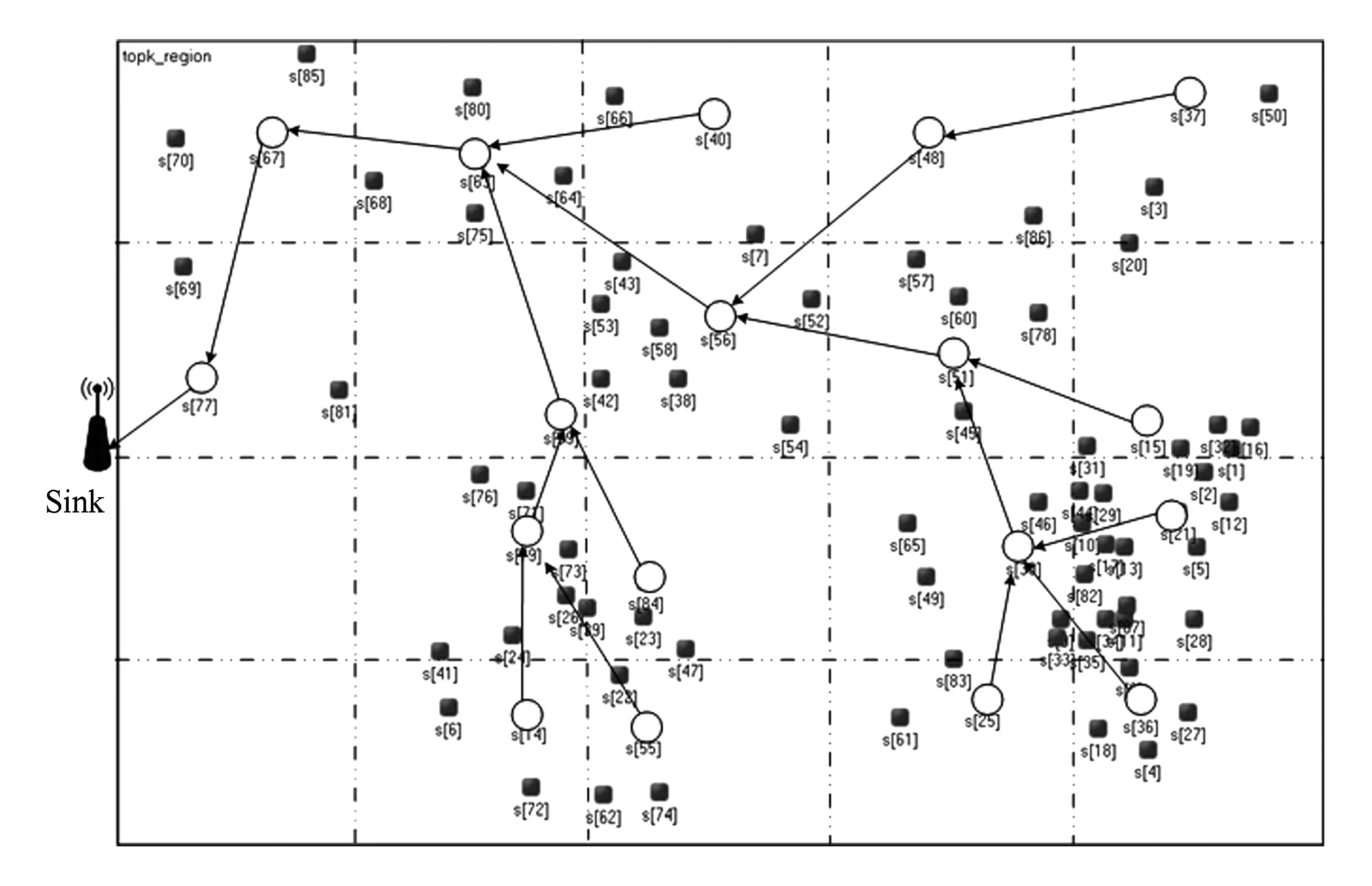
定义7. 设U和V为2个事件语言变量,对于任意的可信度值x∈Rsub(U)和y∈Rsub(V),如果x 例如,在表1中,Rsub(A) 定义8. 设U和V为2个语言变量,它们的可信度子范围分别为Rsub(U)和Rsub(V),如果Rsub(U) Θ即为格内语义事件变量比较操作符. 引理1. 比较操作符Θ是t-余模运算. 证明. 对任意的语言变量sev(如A,B,C,D)且Rsub(sev)⊂[0,1],函数Θ:sev×sev→sev,对于任意的语义事件变量A,B,C,D满足4个条件: 1) 交换律Θ(A,B)=Θ(B,A); 2) 结合律Θ(Θ(A,B),C)=Θ(A,Θ(B,C)); 3) 单调性A≤B,C≤D⟹Θ(A,C)≤Θ(B,D); 4) 边界条件Θ(A,0)=A. 由模糊方法[20],可得Θ即为t-余模运算. 证毕. 此外,我们还要定义一个综合排序函数,用于格间语义事件区域信息top-k融合. 定义9. 定义格间语义事件区域信息融合排序函数score(sev,serc),score综合考虑事件代表点可信度ec和事件区域可信度serc,一个score函数例子为 其中,ec(sev)计算sev对应可信度区间的中间值.根据表1可知:ec(A)=0.985,ec(B)=0.945,ec(C)=0.885等,ω用于调节ec和serc对于score的影响程度,一般来说,事件区域存在可信度较大的时候,用户往往对sev更大的事件区域代表点感兴趣,因此本文实验设置ω=0.7. 网内语义事件区域信息融合过程可用算法2描述. 算法2. Inter-GM_SERQ_Process. 输入:SERQ查询消息; 输出:topknodeID,sev,serc. 步骤1. ① for each叶子GM(i)*GM-Tree的叶子GM* ② ifGM(i).Listis null then*List为空* ③ break; ④ else ⑤ 利用定义8中的Θ操作符查找最大sev对应的List(j).nodeID;*最大sev的NEN为事件区域代表点* ⑦ endif 步骤2. ⑨ do{ ⑩ for each非叶子GM(i)*收集完子GM语义信息消息包* 例4. 算法2的一个运行例子如图4所示.叶子GM节点GM(1),GM(2),GM(3),GM(7) 把其语义事件区域信息(nodeID,sev,serc)发送给非叶子GM(8)节点,这些信息存储在GM(8) 的Listp中.GM(8)根据定义10中式(4)计算Listp中的语义事件区域信息的综合得分,然后根据SERQ中的k值,返回查询结果,k=1,2,3时的查询结果分别为{(5,B,0.94)},{(5,B,0.94),(11,C,0.98)}和{(5,B,0.94),(11,C,0.98),(37,D,1.0)}. Fig. 4 Example of inter-grid semantic event region information fusion图4 格间语义事件区域信息融合的例子 1)SERQ时间复杂度分析.SERQ时间复杂度即为算法2和算法1总的时间复杂度,设GM-Tree的最大度数为q,GM-Tree的层数为p.不考虑计算时间开销,之前我们得到算法1的时间复杂度为Tt+h×Tr,其中h为格内最大节点数.同理,我们考虑分布式发送和串行接收的情况,SERQ的时间复杂度为 (Tt+h×Tr)+(Tt+q×Tr)×(p-1),即为p×Tt+((p-1)×q+h)×Tr.由于h,p,q的值都比较小,因此SERQ的时间开销非常低. 2)SERQ结果可靠性分析.我们没有考虑所有的空间相关性,比如格与格边界节点的空间相关性,也不做严格的事件区域边界检测,因此,SERQ的结果不是精确的,但是由于在SERQ的GM-Tree中,我们定义了格大小设置原则,即保证格内有一定数量的节点,使得格内节点的空间相关性足够判断一个事件区域是否存在,也即SERQ考虑了网内NEN的主要空间相关性,因此结果的可靠性比较高.如果我们考察所有的空间相关性以及做严格的事件区域边界检测,那么网内信息交换通信开销很大[1,6],将退化成现有的类似投票方法. 4.1 实验设置 仿真实验平台为OMNET++[22],它是国际认可度很高的开源多协议网络仿真软件.实验数据来自部分真实数据LUCE[23],我们已经下载了该真实数据集,包括88个有效节点的位置数据和感知数据(节点号、温度、湿度、光照、风向等),节点分布在450 m×300 m的感知区域,感知节点和GM的通信半径分别为50 m和80 m时的一个基于GM-Tree的网络如图5所示.我们主要使用其中的温度T(temperature)和湿度H(humidity)来描述潜在火灾事件.另外,为了更好地模拟事件的时空相关性,以及考察网络中不同NEN比例对于算法的影响,我们基于Intel Lab Data[24]合成了部分数据. 其中,Tn和Hn是最近n个采用周期内的温度和湿度值.实验时n=5,avg(Tn) 和avg(Hn)分别表示最近n个采样周期内的平均温度值和平均湿度值,Tig和Hig是火灾事件的临界值,本实验设置Tig和Hig分别为100°C和10%. 据我们检索传感器网络/物联网相关文献,并没有发现可以进行比较的同类方法,因此我们选择2类代表性的事件处理方法进行比较评估,其中集中式查询可以得到精确的事件信息结果,而基于投票的方法是目前事件检测最常用的一种空间相关技术.为公平起见,下述2种方法中,非值得关注的事件节点同样被提前过滤. 1) 集中式查询(central)方法.在集中式查询处理中,所有值得关注的潜在事件节点将最近5个周期的感知数据的平均值传输到Sink,然后Sink利用全局的拓扑信息来计算得到相对精确的潜在事件区域信息. Fig. 5 Real-world network with 4.4 nodes per gird图5 真实网络—每个格平均覆盖节点4.4个 2) 投票方法(voting).事件发生具有空间相关性,投票技术的核心就是相邻节点相互交换信息来验证事件的发生和事件区域的可信度;然后进行网内融合,返回k个最严重的事件区域.在投票方法中,通常需要距离因素确定投票权重,所以节点的地理位置信息也被传输.同样为公平起见,非值得关注事件节点不参与到相邻信息交换过程中. 评估指标有2个: 1) 数据传输量 在无线通信中,数据传输耗能占总通信耗能开销的大部分,此外数据传输量对实时性也有很大影响,因此我们把数据传输量作为一个重要评估指标. 本实验中,nodeID设为8位整数(INTERGER),sev为8位字符(CHAR),温度T、湿度H、地理位置坐标数据、serc等都是32位实数(因为是32位的实验平台).我们不考虑消息包中的包头、校验码等占位信息. 2) 准确性 我们定义SERQ查询结果的准确性acc(accuracy): 4.2 数据传输量 我们考察图5中4种不同NEN比例(10%,20%,30%,50%)的网络情况对于SERQ,voting,central的节能性能影响.对于相同NEN比例的网络情况,调整NEN节点的分布,重复做实验10次,分别计算得到它们平均数据传输量.上述4种不同NEN比例的网络情况下,SERQ,voting,central三种方法的平均数据传输量如图6所示. 现象1. 上述4种NEN比例的网络环境下,SERQ的平均数据传输量都是最少的,central最大,voting介于它们之间.在30%NEN网络中,SERQ的平均数据传输量大概是voting的43.5%,以及约是central的14.9%;在50%NEN网站中,SERQ的平均数据传输量大概是voting的39.6%,以及约是central的10.4%.在4种NEN比例的网络环境下,SERQ的平均数据传输量大概是voting的44.7%,以及约是central的18.7%. 解释.在实验对比时,为尽可能地公平,我们都使用GM-Tree作为主干路由结构.在central方法中,没有要求传输原始感知数据,而是同样经节点处理后的节点事件概率值,此外还假设Sink或基站有全局的网络拓扑信息,而不用传输地理位置信息;在voting方法中,没有要求考察所有的邻居空间相关性,比如网格边界节点的邻居协作就没有进行处理,严格意义上说本文的对比方法voting是一种改良版,相比传统voting方法的数据传输量更少.在这些设置下,我们的SERQ方法仍然具有数据传输量上的较大优势,这主要:得益于采用了网内语义事件信息表示、过滤和融合的方法,这种方法可以减少原始感知数据直接或间接地参与到网内融合,有效地减少了数据传输量,此外,通过设置GM,在格内语义事件信息收集和融合时,不用传递地理位置信息. 现象2. 在每个不同NEN比例的网络中,SERQ和voting的数据传输量都随着k值的增加而较为缓慢地增长,而central始终保持不变. Fig. 6 Data transmission comparison of three methods in 20 girds based network图6 20个网格划分下3种方法的数据传输量比较 解释.显而易见,central方法和k无关,因此它的数据传输量保持不变;而SERQ和voting方法中,k值的大小直接影响了网内融合时过滤的程度,而且k越小,过滤的事件区域信息越多,相应地总数据传输量越小,k增加时网内信息融合过程中需要保护的信息较多,因而网内数据传输量会增加. 现象3. 随着NEN比例的增加,SERQ,voting,central的平均数据传输量都有相应的增加. 解释. NEN比例增加,参与传输和融合的事件节点和事件区域都在增长,最容易理解的就是在central方法中,需要传输数据的节点增加,转发跳数也在增加,这必然导致整个网络数据传输量的增加.同理,在SERQ和voting中,增加的NEN可能出现在网络的任何位置,显而易见,增加的NEN信息需要参与传输和融合,这会增加数据传输量;此外如果增加的NEN位置远离Sink或基站,网内传输的总跳数也会增加. 此外,我们还考察了每个格覆盖节点数量对SERQ性能的影响,对于图5,每个格平均覆盖节点数为4.4;当GM通信半径增加到100 m时,图5可划分成12个网格,这时每个网格平均覆盖节点数为7.3,与图5中20网格网络实验的设置和方法一样,我们考察图5中12个网格网络中SERQ,voting,central方法的节能性.同样4种NEN比例的网络环境下,上述3种方法的数据传输量对比结果和20个网格网络大致相同,在4种NEN比例的网络环境下,SERQ的平均数据传输量约是voting的38.7%,以及central的17.7%左右,如图7所示.其中原因和现象1的解释相似,不再重复. Fig. 7 Average data transmission comparison of 10%,20%,30% and 50% NENs in 12 girds based network图7 12格网络中4种NEN比例下平均数据传输量对比 4.3 准确度 同样地,我们考察图5网络中3种不同NEN比例(10%,30%,50%)的网络情况对于SERQ查询结果准确性的影响.相同NEN比例的情况,重复做实验10次,计算得到误报数、漏报数和准确度的平均值. 这里说的误报(false positive)有2种情况:1)孤立节点被当成事件区域;2)原本是1个事件区域,由于所处的格不同而被当成2个事件区域.漏报(false negative)是指由于SERQ算法的原因,那些原本属于查询结果的事件区域,没有出现在结果集中,值得注意的是,如果SERQ中用户指定的k值比实际事件区域数量小,而造成的漏报,我们不计入SERQ漏报性能评估,因为用户不需要那么多查询结果,这与SERQ算法无关. 在上述3种NEN比例情况下的事件区域误报数和漏报数如表2~4所示: Table 2 Average Number of False Positive and False Negative with 10% NEN Table 3 Average Number of False Positive and False Negative with 30% NEN Table 4 Average Number of False Positive and False Negative with 50% NEN 现象4. 表2~4没有出现事件区域漏报,而出现少量的误报.表2中的误报主要是孤立NEN引起的误报,10%的NEN,在k=2时,10组实验有1个误报;k=3时,10组实验共有3个误报;k=4时,10组实验共有10个误报;k=5时,10组实验共有16个误报.表4中,50% NEN的情况,这时的误报是原本属于1个事件区域被误报成2个或更多的事件区域,如在k=3,4,5时,10组实验分别有4,6,11个误报. 解释. 只要SERQ查询中k值够大,那么SERQ不会漏报潜在事件区域,也就是说除非用户在SERQ查询中设置较小k值,这会漏报一些潜在事件,但这种漏报和SERQ方法无关. SERQ可能会有误报,那些serc=0.5的事件区域内只有1个NEN,因此可能是一个误报.如表2中,10%的NEN的情况,整个网络中NEN数量较少,存在孤立NEN的概率较高,因此SERQ算法在k较大时,误报的可能性增加.NEN的比例为50%时,网络中有一半的NEN,这时的空间相关性比较复杂,事件区域往往横跨几个网格,尤其是本实验的20网格,网格区域较小,事件区域更容易包含在几个网格中,在SERQ中,由于不做严格的事件边界检测,而是以网格划分事件区域(节能考虑),因此在表4中,这种误报出现的次数增加. 总体来说,SERQ结果的准确度很高,随着k的增加和NEN比例的增加,准确度有所下降. NEN比例不大的情况下,k值越小,SERQ会优先选择那些serc大且事件区域代表点可信度高的事件区域,那些孤立的NEN由于serc小,几乎没有机会成为SERQ的结果.就像现象4中解释的一样,NEN比例较大时,事件区域可能会横跨几个网格,会造成一些误报,从而降低了SERQ的准确度,但是从多组实验看来,除非NEN分布完全没有空间性规律(这也是不符合实际的),否则SERQ的总体准确度还是非常高的. 本文探讨了传感器网络中如何节能而可靠地获取事件信息的问题,提出一种低功耗可靠的语义事件区域查询处理方法.我们没有利用全部的空间相关性进行事件信息确认,也不进行严格的事件区域边界检测,因为这些操作追求高可靠性而付出的时间和能耗代价非常高.本文借鉴了模糊方法中关于处理不精确性问题的思想,语义事件信息代替原始的感知数据用于网内事件信息的融合,并设计了基于模糊理论的分布式语义事件信息表示、过滤和融合算法.基于真实数据的仿真实验验证了所提出的方法在节能和可靠性方面的预期效果. 如何在可靠性、实时性和节能性之间取得最佳平衡以及本文所涉及的一些函数和参数在实际应用系统的设计等问题都值得进一步研究. [1]Wu Tao, Cheng Qi. Online dynamic event region detection using distributed sensor networks[J]. IEEE Trans on Aerospace and Electronic Systems, 2014, 50(1): 393-405 [2]Dziengel N, Seiffert M, Ziegert M, et al. Deployment and evaluation of a fully applicable distributed event detection system in wireless sensor networks[J]. Ad Hoc Networks, 2016, 37(1): 160-182 [3]Xue Wenwei, Luo Qiong, Pung H K. Modeling and detecting events for sensor networks[J]. Information Fusion, 2011, 12(1): 176-186 [4]Amato G, Chessa S, Gennaroa C, et al. Querying moving events in wireless sensor networks[J]. Pervasive and Mobile Computing, 2015, 16(1): 51-75 [5]Ding Lei, Guo Ge. Distributed event-triggered H consensus filtering in sensor networks[J]. Signal Processing, 2015, 108(1): 365-375 [6]Brass P, Na H S, Shin C S. Local event boundary detection with unreliable sensors: Analysis of the majority vote scheme[J]. Theoretical Computer Science, 2015, 607(1): 96-112 [7]Ding Min, Cheng Xiuzhen. Robust event boundary detection in sensor networks—A mixture model approach[C] //Proc of the 28th IEEE Int Conf on Computer Communications. Piscataway, NJ: IEEE, 2009: 2991-2995 [8]Li Yinglong, Chen Hong, Zhao Suyun, et al. Efficient event prewarning for sensor networks with multi microenvironments[C] //Proc of the 19th European Conf on Parallel Processing. Berlin: Springer, 2013: 382-393 [9]Iqbal A, Murshed M. A hybrid wireless sensor network framework for range-free event localization[J]. Ad Hoc Networks, 2015, 27(1): 81-98 [10]Masud M, Christopher L, Shanika K. An adaptive elliptical anomaly detection model for wireless sensor networks[J]. Computer Networks, 2014, 64(1): 195-207 [11]Yang H, Chung C W, Kim M H. An efficient top-kquery processing framework in mobile sensor networks[J]. Data & Knowledge Engineering, 2016, 102(1): 78-95 [12]Li Yinglong, Yang Lianghuai, Lü Mingqi. Event-driven approximate top-kqueries in sensor networks with multi microenvironments[J]. Chinese Journal of Electronics, 2015, 24(2): 373-378 [13]Saleh O, Sattler A. Distributed complex event processing in sensor networks[C] //Proc of the 14th IEEE Int Conf on Mobile Data Management. Piscataway, NJ: IEEE, 2013: 23-26 [14]Xu Xiaolong, Geng Weijian, Yang Geng, et al. An efficient fault-tolerant event and event boundary detection algorithm for wireless sensor networks[J]. Journal of Computer Research and Development, 2014, 51(5): 997-1008 (in Chinese)(徐小龙, 耿卫建, 杨庚, 等. 高效容错的无线传感器网事件及其边界检测算法[J]. 计算机研究与发展, 2014, 51(5): 997-1008) [15]Shi Shengfei, Zhang Wei, Li Jianzhong. A complex event detection algorithm based on correlation analysis[J]. Journal of Computer Research and Development, 2014, 51(8): 1871-1879 (in Chinese)(石胜飞, 张伟, 李建忠. 一种基于模式匹配与相关性分析的事件检测算法[J]. 计算机研究与发展, 2014, 51(8): 1871-1879) [16]Streit R L. Poisson Point Processes: Imaging, Tracking, and Sensing[M]. Berlin: Springer, 2010: 1-78 [17]Madden S, Franlin M J, Hellerstein J M, et al. TAG: A tiny aggregation service for ad-hoc sensor networks[C] //Proc of the 5th Symp on Operating Systems Design and Implementation. New York: ACM, 2002: 131-146 [18]Zhu Jiang, Lung C H, Srivastava V. A hybrid clustering technique using quantitative and qualitative[J]. Ad Hoc Networks, 2015, 25(1): 38-53 [19]Zhang Yang, Meratnia N, Havinga P. Outlier detection techniques for wireless sensor networks: A survey[J]. IEEE Communications Surveys & Tutorials, 2010, 12(1): 159-170 [20]Galindo J. Handbook of Research on Fuzzy Information Processing in Databases[M]. Hershey, Pennsylvania: IGI Global, 2008 [21]Kapitanova K, Son S H, Kang K D. Using fuzzy logic for robust event detection in wireless sensor networks[J]. Ad Hoc Networks, 2012, 10(1): 709-722 [22]OpenSim Ltd.. Discrete event simulator[EB/OL]. [2011-03-27]. http://www.omnetpp.org [23]Martin V. Sensorscope: Sensor networks for environmental[DB/OL]. [2011-04-17]. http://sensorscope.epfl.ch/index.php/Environmental_Data [24]Samuel M. Intel Lab Data[DB/OL]. [2011-05-18]. http://db.csail.mit.edu/labdata/labdata.html Semantic Event Region Query Processing in Sensor Networks Li Yinglong, Zhu Yihua, and Lü Mingqi (College of Computer Science & Technology, Zhejiang University of Technology, Hangzhou 310023) Sensor networks can be viewed as resources constrained distributed database systems, of which a significant challenge is to develop reliable, energy-efficient methods to extract useful information from distributed sensor data. Most of the existing event (region) detection approaches rely on using raw sensory data, which results in a large amount of data transmission as well as is time-consuming. However, it is difficult to ensure accurate results due to the imprecision and uncertainty of the raw sensor data. In many cases, users neither care about these raw sensory data nor pay attention to the data format during in-network filtering or fusion, but want to get natural language-like semantic event information, such as “how serious it is”, “is it credible?” Moreover, the main technique of the existing event detection is neighboring cooperation, which requires great data exchange between neighboring nodes. It is costly in terms of energy and time. This paper proposes a novel fuzzy methodology based semantic event region query processing approach. Semantic event information instead of raw sensor data is used for in-network fusion, and fuzzy method based distributed semantic event information description, filtering and fusion approaches are devised. The experimental evaluation based on real data set show that the proposed approach has good performance in terms of energy efficiency and reliability. semantic event information; fuzzy methodology; energy efficiency; reliability; sensor network Li Yinglong, born in 1981. PhD and lecturer. Member of CCF. His main research interests include data processing and mobile computing in sensor networks. Zhu Yihua, born in 1961. PhD and professor. Senior member of CCF. His main research interests include the Internet of things (IoT), wireless networks, and network coding. Lü Mingqi, born in 1981. PhD and lecturer. Member of CCF. His main research interests include ubiquitous computing, data mining. 2016-08-15; 2016-12-20 国家自然科学基金项目(61502421,61432015);浙江省自然科学基金项目(LY15F020026,LY15F020025) This work was supported by the National Natural Science Foundation of China (61502421, 61432015) and the Natural Science Foundation of Zhejiang Province of China (LY15F020026, LY15F020025). 朱艺华(yhzhu@zjut.edu.cn) TP391; TP393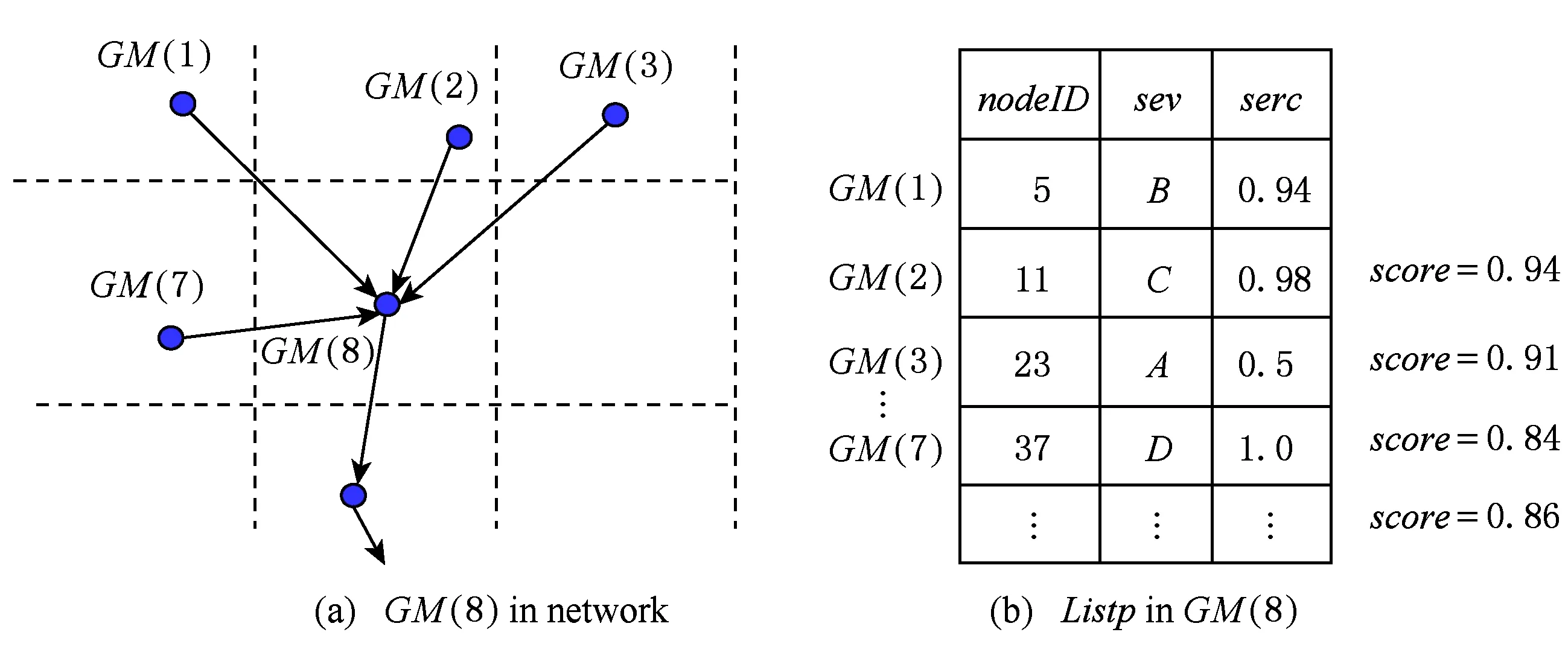
4 实验结果与分析

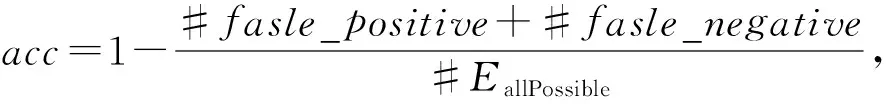
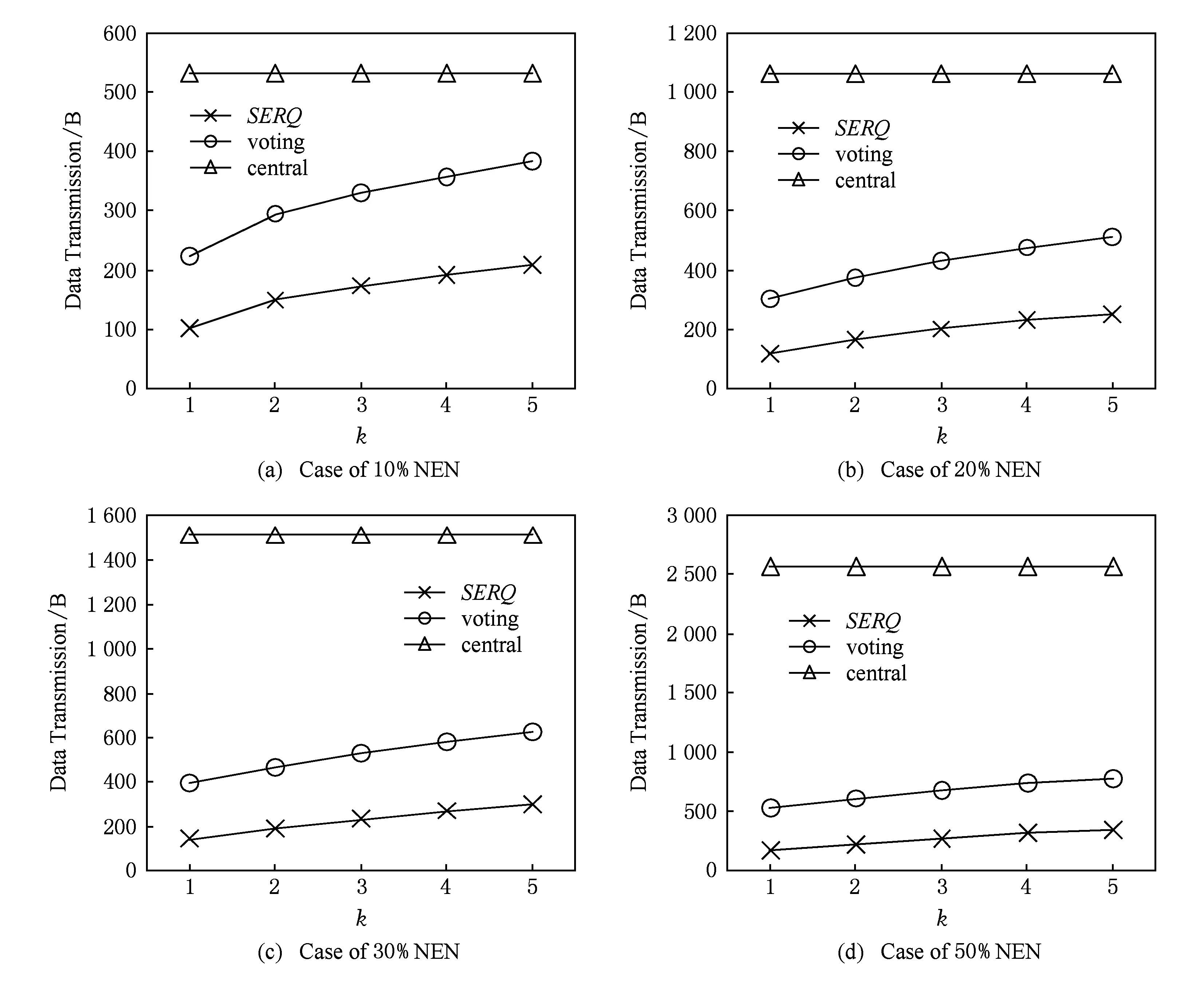
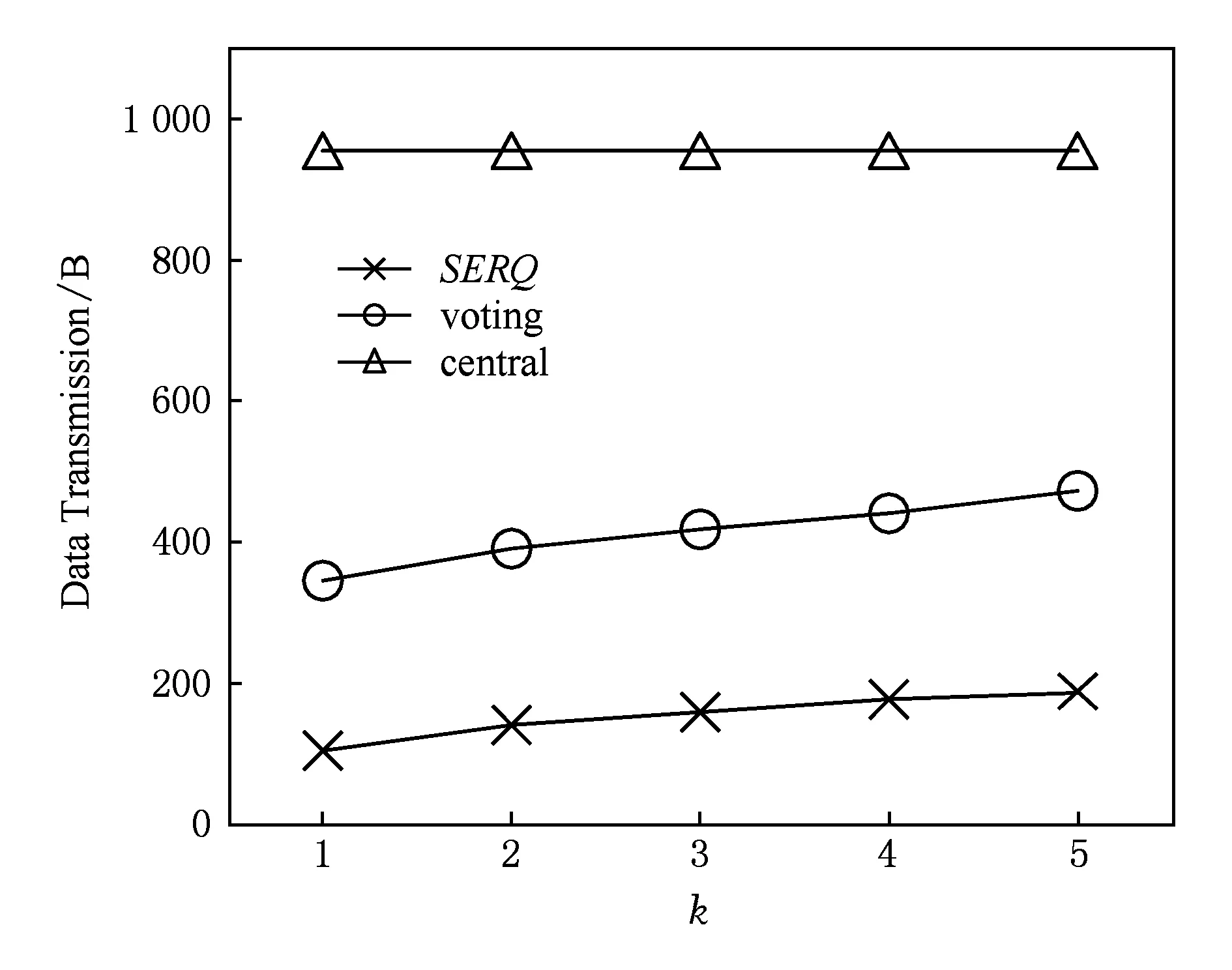



5 总 结


 猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12煤气与热力(2021年6期)2021-07-28装备制造技术(2020年2期)2020-12-14河南科技学院学报(自然科学版)(2020年2期)2020-05-22开放教育研究(2020年2期)2020-03-31中国水运(2016年3期)2017-05-13中国科技纵横(2017年3期)2017-03-29山东工业技术(2017年4期)2017-03-28中国修辞(2017年0期)2017-01-31中国社会历史评论(2016年2期)2016-06-27
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12煤气与热力(2021年6期)2021-07-28装备制造技术(2020年2期)2020-12-14河南科技学院学报(自然科学版)(2020年2期)2020-05-22开放教育研究(2020年2期)2020-03-31中国水运(2016年3期)2017-05-13中国科技纵横(2017年3期)2017-03-29山东工业技术(2017年4期)2017-03-28中国修辞(2017年0期)2017-01-31中国社会历史评论(2016年2期)2016-06-27
