
基于Hadoop的IPTV大数据解决方案
2017-04-28 01:19姚俊伍江苏省广播电视总台新媒体事业部
视听界(广播电视技术) 2017年2期
姚俊伍 江苏省广播电视总台新媒体事业部
基于Hadoop的IPTV大数据解决方案
姚俊伍 江苏省广播电视总台新媒体事业部
Hapdoop是目前大数据领域最为通用的技术平台。本文对Hadoop的技术架构和特点进行了综述,重点介绍了HDFS和MapReduce实现原理,并结合工作实际,提出了一种基于Hadoop的IPTV大数据的解决方案。
大数据 Hadoop HDFS MapReduce 解决方案
一、引言
据统计,2016年全国IPTV用户已达到7800万户左右,2017年将有可能突破一亿户,IPTV成为了近年来广电发展最为迅速的业务之一。在业务迅速发展的背后,大数据起到了不可忽视的作用。通过大数据分析,能够主动性的适应用户收视的要求,摸准用户的使用习惯,挖掘用户潜在需求,尽可能的提升业务的ARPU值,推动IPTV业务的持续发展。
IPTV的大数据分析,主要是对IPTV用户行为进行分析。每个用户每天有近几十次的行为发生,在这些行为中包括直播、点播、时移、回看等相关的行为,每天有近60%的用户在线,每天用户行为的发生主要密集在晚间时段,在用户行为的高峰期有近千万的用户行为在线。在这样的用户行为的背景下,以300万IPTV用户规模来说,每天有近三千万条的用户行为数据记录,产生近3G的log行为数据日志。
对于这么大的数据进行统计与分析,在用户可接收的时间内反馈结果,对于系统的计算、存储和查询提出了前所未有的要求,传统方式的系统结构和数据处理方式已不能满足需求。
二、Hadoop简介
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。Hadoop基于Java开发,为应用程序提供一组稳定可靠的API接口,它具有高可用性、高容错性和高可扩展性等优点。用户可以在完全不了解底层实现细节的情形下,开发适合自身应用的分布式程序。
Hadoop由HDFS、MapReduce、HBase、Hive和ZooKeeper等组成,其中HDFS(Hadoop Distributed File System)和MapReduce引擎为最基础、最重要的两个组成元素,
Hadoop比较适合解决大数据问题,很大程度上也是依赖HDFS和MapReduce引擎。
(1)分布式文件系统(HDFS)
分布式文件系统(HDFS)为底层用于存储集群中所有存储节点文件的文件系统,它可以构建从几台到几千台由常规服务器组成的集群,并提供高聚合输入输出的文件读写访问。
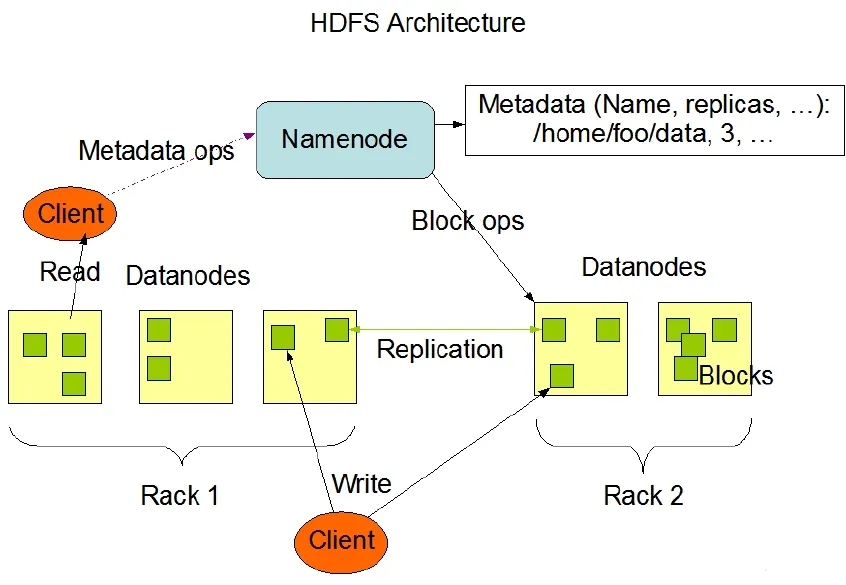
图1 分布式文件系统体系架构图
如图1所示,Namenode是一个中心服务器,负责管理文件系统的namespace和客户端对文件的访问;Datanode在集群中会有多个,一般是一个节点存在一个,负责管理其自身节点上它们附带的存储。在内部,一个大文件分成一个或多个block,这些block存储在Datanode集合里。Namenode执行文件系统的namespace相关操作,例如打开、关闭、重命名文件和目录,同时决定了block 到具体 Datanode 节点的映射 。 Datanode 在Na-menode的指挥下进行block的创建、删除和复制。单一节点的Namenode大大简化了系统的架构。Namenode负责保管和管理所有的HDFS元数据,因而在请求Namenode得到文件的位置后就不需要通过Namenode参与而直接从Datanode进行。为了提高Namenode的性能,所有文件的names-pace数据都在内存中维护,所以就天生存在了由于内存大小的限制导致一个HDFS集群的提供服务的文件数量的上限。
(2)MapReduce引擎
MapReduce引擎是一个软件框架,基于该框架能够容易地编写应用程序,这些应用程序能够运行在由上千个商用机器组成的大集群上,并以一种可靠的、具有容错能力的方式并行地处理上TB级别的海量数据集。
MapReduce采用“分而治之”的思想对大数据进行分析。Mapper负责“分”,即把复杂的任务分解为若干个“简单的任务”来处理。“简单的任务”包含三层含义:一是数据或计算的规模相对原任务要大大缩小;二是就近计算原则,即任务会分配到存放着所需数据的节点上进行计算;三是这些小任务可以并行计算,彼此间几乎没有依赖关系。Reducer负责对Map阶段的结果进行汇总。
MapReduce的整个工作流程主要分为四个步骤,首先由客户端来提交MapReduce作业;接下来通过jobtracker来协调作业的运行;然后由tasktracker来处理作业划分后的任务;最后通过HDFS在其它实体间共享作业文件。
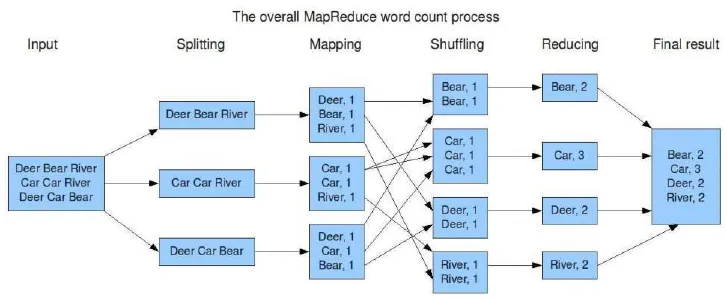
图2 MapReduce调用实例
如图2所示,是MapReduce的一个过程,实例任务是计算某个文件中指定单词出现的次数,从图中我们可以看出这个任务被分裂成三个子任务后映射到集群中JobTracker指定的TaskTracker上运行子任务,每个子任务都可以在指定的TaskTracker上运行,把运行的结果保存在当地,然后Reduce程序被调用。最后进行的是结果的整合,整合完毕后得到最终的结果。
三、Hadoop技术特点
(1)MPP并行关系型方案
多个独立的关系数据库服务器,访问共享的存储资源池。
优势:采用多个关系数据库服务器、多个存储,与原有的架构相比扩展了存储和计算的能力。
劣势:计算与存储分离,数据访问存在竞争和带宽瓶颈;支持的关系数据库服务器数量有限;只能向上扩展不能横向扩展。
(2)Hadoop分布式方案
有大量独立的服务器通过网络互连形成集群,每台服务器有独立的存储。
优势:计算与存储融合,支持横向扩展,有更好的扩展性;
劣势:解决数据冲突时,需要节点间协作。MPP与Hadoop的方案对比如下表所示:

表1 软件架构(扩展性)

表2 数据模型

表3 分析方式
四、实际应用
根据Hadoop的特点,采用“分层设计”的思想,设计了一种IPTV大数据系统的软件逻辑架构。如图3所示,从下到上为数据源接口层、计算层、存储查询层和产品层。
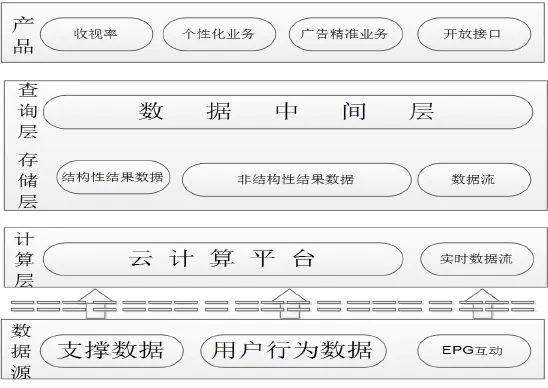
图3 IPTV大数据系统的软件逻辑架构
(1)数据源接口层 获取采集系统收集的数据,对数据进行清理,并对数据进行任务分担,分给不同的计算服务设备。
(2)计算层 完成计算任务,形成结果,存储系统的中间过程数据,系统支持新增设备的平滑增加和任务的负载均衡。
(3)存储层和查询层 负责存储计算层形成的结果数据,并响应产品层的查询请求。无论是结构化数据还是非结构化数据以及数据流形式的数据都会存储在此层。
(4)产品层 根据用户需要对相关数据结果进行综合呈现,提供可视化实时的结果进行业务关联。
这种分层的结构,从功能对业务进行了分块,同时对每一块功能的要求进行了分摊,以满足当前各种业务的需要。为保证对于海量用户行为数据的处理能力的要求,和根据多年数据分析挖掘的经验,我们在基础平台引入了云数据处理平台。
根据系统的逻辑分构,系统的业务流程如图4所示。在业务层面上,系统分为应用层、计算层和接口任务层。系统数据的存储分布在计算服务器中,以满足系统对海量数据处理的要求。
(1)系统从网络获得原始数据,通过系统接口存入Hadoop的Master服务器中。
(2)Hadoop平台通过Mapreduce等操作来对数据进行处理,Hadoop由HDFS、MapReduce、HBase、Hive和ZooKeeper等成员组成,其中最基础最重要的两种组成元素为底层用于存储集群中所有存储节点文件的文件系统HDFS(Hadoop Distributed File System)和上层用来执行MapReduce程序的MapReduce引擎。
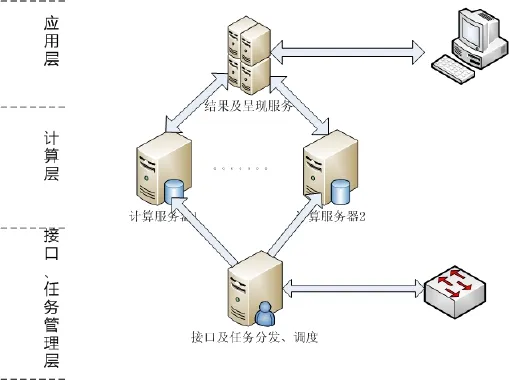
图4 IPTV大数据系统业务流程
(3)Hadoop将运算结果输出到结果呈现平台,在Oracle数据库中存储结果数据,并向外提供查询接口。
(4)WEB展示页面负责数据的呈现与结果查询
江苏广电总台IPTV大数据系统根据以上设计思路得以实现。该系统应用Hadoop分布式架构,能够对大量数据进行分布式处理,并能维护多个工作数据副本,确保能针对失败的节点重新分布处理;能通过并行的方式工作,加快处理速度,处理PB级数据;能够自动检测和补偿任何服务器上出现的硬件或系统问题,可以随时添加或删除平台群集中的计算服务器;采用HDFS分布式存储,运用了shell文本计算方式,可根据系统运行经验和清洗规则的变化对系统算法作出方便、灵活的修改;它本身是没有License限制的,能以较低成本实现硬件扩充。该大数据系统目前运行稳定,实现了对江苏地区IPTV用户行为数据的统计分析,可以按照直播、点播、回看、订购等多个纬度进行系统性分析,按周、月等自动生成报表,为节目采购、编排,市场运营提供了科学的指导。
五、展望
经快速发展,Hadoop成为了目前大数据分析领域中应用最广泛的一种分布式架构。Hadoop提供了强大的计算能力,覆盖各行各业,几乎任何垂直领域。
从行业整体的发展来看,目前只是刚刚意识到了大数据的重要性,聚焦点还在于数据的统计和分析,而大数据更大的价值在于预测。伴随着需求的进一步升级,大数据解决所依赖的Hadoop技术的发展和完善将是刚刚开始,未来仍旧不可估量。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
汽车工程(2021年12期)2021-03-08
铁道通信信号(2019年9期)2019-11-25
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年11期)2018-08-04
计算机测量与控制(2017年6期)2017-07-01
中国交通信息化(2017年3期)2017-06-08
网络安全和信息化(2017年10期)2017-03-08
知识就是力量(2017年2期)2017-01-21
知识产权(2016年8期)2016-12-01
