
天基数据混合推荐方法研究
2017-04-25 01:14:01彭会湘王长力
无线电工程 2017年5期
杜 楚,彭会湘,李 峰,王长力
(1.中国电子科技集团公司第五十四研究所,河北 石家庄 050081; 2.中国人民解放军91635部队,北京 102249)
天基数据混合推荐方法研究
杜 楚1,彭会湘1,李 峰1,王长力2
(1.中国电子科技集团公司第五十四研究所,河北 石家庄 050081; 2.中国人民解放军91635部队,北京 102249)
数据推荐技术能够主动地满足用户对数据的需求,提高用户对数据的获取效率,该技术已经在电商系统中得到了广泛应用。然而,现有的数据推荐算法无法很好地适应天基数据的特点。新提出的天基数据混合推荐方法基于模式挖掘、兴趣关系图和相似度聚类技术实现,能够使推荐的天基数据在内容上主动匹配用户的潜在需求,从而提高用户使用天基数据的效率。
天基数据;推荐算法;天基数据混合推荐;模式挖掘;相似度聚类
0 引言
随着天基信息探测装备的不断发展和广泛使用,我国已形成了一个在陆地、海洋、天空和太空全方位部署的较为完整的信息感知网络,信息获取能力特别是天基数据获取能力得到了很大提高,已经积累了海量的卫星遥感数据、导航定位信息和全球地理数据等天基数据,各类数据信息以文字、图像和声像等多种形式存储管理。目前受到分析方法的限制,无法对大规模多源异构的天基数据进行有效地挖掘分析,单一的数据库检索手段已不能满足天基数据推荐所需的深度分析能力,无法达到天基数据高效利用的目的。因此,需要对天基数据的推荐方法进行研究,实现向用户推荐的天基数据在内容上主动满足用户潜在的需求。
1 数据推荐方法的研究与应用现状
用户在使用数据时,可以根据明确程度将用户的需求分为3类:用户明确已知的需求A、用户基于本身的知识可以明确的潜在需求B和用户基于本身的知识无法直接明确的潜在需求C。数据推荐的核心思想在于:在用户提出需求A后,推荐算法可以根据使用记录与兴趣关系,计算出用户的潜在需求B与潜在需求C,从而提升用户对数据的使用效率,实现在内容上主动满足用户潜在的需求,这种思想已经广泛应用于互联网电商系统中。
电商根据用户的购买行为和兴趣特点,向用户推荐用户即将需要和感兴趣的信息和产品,在增加顾客满意度的同时又增加订单量,为电商创造了可观的利润增值[1]。目前,大型电商平台如京东、亚马逊和天猫等都采用了个性化推荐算法。目前常见的个性化推荐算法包括:基于内容的推荐、协同过滤的推荐、基于知识的推荐和基于规则的推荐。
1.1 基于内容的推荐
基于内容的推荐过程主要依赖用户间、物品间或用户与物品间的相似性,不需要用户对推荐物品的评价意见,而是根据用户所选择的物品特征,把其他类似属性的物品作为推荐结果反馈给用户[2]。这样即使没有用户的评分数据,也能通过衡量用户或物品内容特征的相似度来对用户给出推荐信息。基于内容的推荐算法的核心思想是:先把推荐物品的内容特征抽取出来,然后从用户以往选择物品的内容特征去学习用户的偏好兴趣,最后与用户偏好兴趣匹配度较高的物品将被推荐给用户[3]。
1.2 基于协同过滤的推荐
基于协同过滤的推荐系统先根据已有的历史数据(如评分数据),计算出用户(或物品)之间的相似度,再根据相似度找到用户(或物品)的最近邻居集合,最后根据最近邻居集合中的评分情况得出预测评分,并将评分按大小排序,选择几个预测评分靠前的作为推荐列表返回给用户[4]。协同过滤的推荐算法目前主要分为基于内容的协同过滤和基于模型的协同过滤[5]这2类。
1.3 基于知识的推荐
基于知识的推荐算法利用用户知识和物品知识,通过推理来为用户推荐物品,在一定程度上也被视为一种推理技术[6]。它并不依赖于用户评分等关于用户偏好的历史数据,故其不存在冷启动方面的问题。其基本思想是:在统一的语义互联环境中获取用户知识和物品知识,通过功能知识的推理或语义匹配向用户做出推荐,能够根据推荐系统所处的具体环境选择相应的推荐策略,在必要的时候调用传统的推荐技术,结合传统推荐技术的优点采用混合推荐技术向用户做出推荐以获取最佳的推荐质量[7]。基于知识的推荐系统能够实时响应用户需求,当用户偏好发生变化时不需要任何训练。
1.4 基于规则的推荐
关联规则作为数据挖掘领域内的一项重要技术,已经被广泛应用于电子商务推荐系统中。关联规则的挖掘工作可以分成2步:① 从交易数据集合中发现所有满足用户给定的最小支持度的频繁项目集;② 在频繁项目集的基础上生成所有满足用户给定的最小可信度的关联规则[8]。基于规则的推荐算法的基本思想是:通过挖掘用户数据来产生用户的行为模式,然后结合用户的历史行为记录,产生对目标用户的推荐列表[9]。
2 天基数据混合推荐方法设计思路
上述各类推荐算法在无使用记录时的冷启动问题[10]、推荐数据要求以及响应数据变化等方面都有着各自的优势与劣势,然而在实际工程应用中需要采用不同推荐算法的组合才能达到扬长避短的目的,从而产生更符合用户需求的推荐,文献[11-12]也论述了混合策略在准确性上优于单一的推荐策略。理论上可以有很多种的推荐组合方法,目前研究和应用较多的混合推荐是把基于内容的推荐和协同过滤的推荐混合在一起[13]。然而天基数据与商品数据不同,具有组合使用性强、用户专业性强和时空约束的特点,将现有的数据混合推荐方法进行套用并不能满足天基数据推荐工作的要求,因此需要从以下3个方面对天基数据的混合推荐方法进行设计。
2.1 使用记录的频繁子集合与子序列模式
单一的天基数据(如一张遥感图像)并不具有使用价值,而需要一定的处理流程的加工(与图层、底图和坐标系统的叠加等)才能产生使用价值。因此,用户对天基数据的使用往往都处于某个流程之中,使得用户的使用记录对天基数据的推荐具有较高的参考价值。对所有用户的天基数据使用记录进行模式挖掘,发现其中的频繁子集合与子序列模式[14],找到所有用户在使用该数据时的潜在工作流程。在推荐天基数据时,考虑数据在流程或功能上的互补性、兼容性,为用户推荐工作流程后续需要用到的数据,帮助用户完成整个工作流程,从而提升推荐数据的可用性。
2.2 用户子兴趣区域相似性
天基数据的用户具有较强的专业性,同一用户往往集中使用某几种天基数据,因此实现天基数据与用户需求之间的匹配需要对用户的兴趣进行分析。用户兴趣区域通常包含多个子兴趣区域,每个子兴趣区域对应特定的天基数据属性,例如行政区域、卫星代号和分辨率要求等。用户子兴趣是用户对部分数据感兴趣并构成的一个子图,不同用户子兴趣可能存在重合,可能在某一领域重合部分较多,而在另一领域重合部分较少。研究分析用户子兴趣之间的关联,比研究分析所有用户兴趣关联更有价值,更能准确地预测用户行为。它克服了协同过滤算法无法对某一领域用户子兴趣的相似性进行特殊分析和处理的弊端,因此在推荐时可以根据用户的专业进行精确推荐。
2.3 天基数据时空相关性
天基数据通常在时间和空间属性上具有相关性,同时这些数据在时间和空间范围及尺度上也存在差异性。单一的天基数据不能完全满足用户的需求,在推荐天基数据时,需要推荐在时空相关性方面匹配的天基数据组合,避免出现时空范围及尺度上差异性较大从而不可组合的场景,促进天基数据的最优组合推荐[15]。
3 天基数据混合推荐方法
依据上述的设计思路,本文提出针对天基数据的混合推荐方法,其计算过程如图1所示。

图1 天基数据混合推荐方法计算过程
首先,对用户使用记录进行模式挖掘得到用户对数据使用的频繁子集合与子序列模式、进行计算构建得到用户的兴趣关系图;对天基数据进行相似度聚类,将相似度高的天基数据聚合到同一类中,得到聚类结果;进而根据用户的选择进行混合推荐;将混合推荐得到的结果集进行时空相关性筛选形成最终的推荐集合。
3.1 使用记录的模式挖掘
通过对用户的使用记录进行模式挖掘找到用户使用数据的频繁子集合与子序列模式是本推荐方法的难点和重点。模式挖掘工作分为3步:
① 将用户的使用记录表示为一个图:
G=(D,E:ω)
式中,节点D为被用户使用的数据或实体;节点之间的边E为数据或实体之间的连接或调用关系;边上的权值ω为连接的强弱或调用的次数。本文使用BIT-ProcessLibrary-Release2009数据集中的匿名用户服务调用记录作为模式挖掘方法的验证数据,构建的使用记录图如图2(a)所示;
② 在得到用户的使用记录图后,使用基于图结构的聚类算法(Graph-skeleton-based Clustering)[16]对该图进行分解,得到如图2(b)所示的结果,共得到编号1~4的4个主要核心功能子图,即数据的频繁子集合,其中编号5的子图中的节点为其他节点之间的连接节点,不是核心功能子图;
③ 使用图的结构抽取算法(Graph Skeleton Extraction Algorithm)[17]对每个核心功能子图进行抽取得到子图的核心结构,图2(c)所示的核心结构是对图2(b)中编号1的核心功能子图进行抽取得到。这一结构代表了用户对某些数据的核心使用流程,即数据使用流程的子序列模式。

图2 用户使用记录模式挖掘
在进行天基数据推荐时,当用户选择了某个数据时,找到该数据所在的子序列模式,将模式中与该数据有流程逻辑关系的数据推荐给用户,完成基于频繁数据集合和子序列模式的数据推荐。
3.2 用户兴趣关系图构建
用户的兴趣关系定义为一个图:
G=(U,E:(c,ω))。
式中,节点U为用户;节点之间的一条边E为用户之间相似的子兴趣;边上的属性c为该子兴趣所述的类型;边上的属性ω为该子兴趣的强弱。用户的兴趣关系图的构建是一个计算统计的过程,在使用记录中,如果2个用户都对同一类型的数据重复使用,说明他们对该类型的天基数据具有一个相同的子兴趣,在其节点之间建立一条边,边上的属性c为数据的类型,边上的属性ω为同时使用这一类型数据的次数,ω越大表示该子兴趣越相似。
在对某一用户进行数据推荐时,推荐工作面向具有相似子兴趣区域的用户进行,将与该用户子兴趣相似的用户选择过的数据推荐给用户,完成基于用户兴趣关系图的推荐。
3.3 天基数据相似度聚类
天基数据的相似度聚类体现了数据在内容上的相似程度,是解决数据推荐在无使用记录情况下“冷启动”的基础,为了得到天基数据的相似度聚类,需要进行3步:
① 建立一个元组对天基数据的元数据进行表示,元组的定义为:
D= {ID,class,filed,source,date,target,
scope,resolution,format}。
式中,D为天基数据的元数据元组;ID为数据的编号;class为数据的种类,如遥感数据、多光谱数据和电子侦察数据等;filed为数据所属的领域,如SAR遥感数据、气象数据和高程数据等;source为数据的来源;date为数据时间属性,体现数据的时效性;target为中心点经纬度;resolution为数据的分辨率;format为数据的文件格式。由于元组各项的值域确定,因此总能找到一个向量表示上述的元组。
② 计算2个元组之间的向量距离作为2个天基数据之间的相似度,计算方法使用余弦相似度。余弦相似度表示的是2个向量之间的夹角关系,夹角越小表示这2个向量越相似,余弦相似度Sim1,2为:
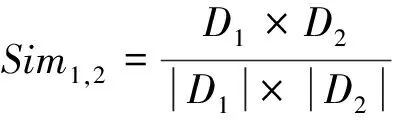
③ 利用谱聚类[18]方法对天基数据进行聚类。谱聚类算法建立在谱图理论基础上,其核心思想是对聚类对象在拉普拉斯空间上进行K-means运算,其计算空间由直接进行K-means运算的N*N维空间降维到N*k维空间上(N为聚类对象的个数,k为聚类的个数),由此带来巨大的计算节省,与K-means、Meanshift等传统算法相比,特别适合于大规模海量数据的聚类计算。K-means算法固有的聚类初始点随机选择不当造成聚类结果不理想的问题,在针对天基信息数据进行计算时,能够通过人工指定平均相似度最大的天基数据作为初始节点的方式进行改善。
在得到的聚类结果中,内容相似的天基数据被聚在同一类中。数据推荐时,把与用户选择的数据相似的数据推荐给用户,完成基于相似度聚类的天基数据推荐。最终将上述基于频繁数据集合和子序列模式、基于用户兴趣关系图、基于相似度聚类的推荐结果依据用户的设定与偏好进行组合,经过时空相关性筛选后,作为最终的结果推荐给用户。
4 结束语
通过对现有数据推荐方法的研究与应用现状的分析,结合天基数据组合使用性强、用户专业性强以及时空约束的特点,设计出了天基数据的混合推荐方法并对方法的实现过程进行了详细论述。本文的推荐方法相对于传统方法应用效果更好,能够较好地反映用户的专业兴趣特点,且随着用户使用记录的积累,方法能够从使用记录蕴含的工作流程中找到合适的推荐数据,满足用户的潜在需求,提高用户使用数据的效率。
[1] 马瑞敏,卞艺杰.基于Hadoop的电子商务个性化推荐算法—以电影推荐为例[J].计算机系统应用,2015,24(5):111-117.
[2] 江周峰,杨 俊.结合社会化标签的基于内容的推荐算法[J].软件,2015,36(1):1-5.
[3] 姜书浩,薛福亮.一种利用协同过滤预测和模糊相似性改进的基于内容的推荐方法[J].现代图书情报技术,2014,243(2):41-47.
[4] 冷亚军,陆 青.协同过滤推荐技术综述[J].模式识别与人工智能,2014,27(8):720-734.
[5] 陈洁敏,汤 庸.个性化推荐算法研究[J].华南师范大学学报,2014,46(5):8-15.
[6] 艾 磊,赵 辉.基于知识的推荐系统用户交互模型研究[J].软件导刊,2015,14(3):15-17.
[7] JANNACH D,FELFERMIG A,FRIEDRICH G,et al.推荐系统[M].蒋 凡,译.北京:人民邮电出版社,2013.
[8] 郭文月,刘海砚.非指定时间约束的社会安全事件关联规则挖掘[J].地理与地理信息科学,2016,32(3):14-18.
[9] 陈江平,黄炳坚.数据空间自相关性对关联规则的挖掘与实验分析[J].地球信息科学学报,2011,13(1):109-117.
[10] 孙冬婷.协同过滤推荐系统中的冷启动问题研究[D].长沙:国防科学技术大学,2011.
[11] 刘建国,周 涛,汪秉宏.个性化推荐系统的研究进展[J].自然科学进展,2009,19(1):1-21.
[12] 许海玲,吴 潇,李晓东.互联网推荐系统比较研究[J].软件学报,2009,20(2):350-362.
[13] 陈洪涛,肖如良.融合推荐潜力的个性化趋势预测的混合推荐模型[J].计算机应用,2014,34(1):218-221.
[14] 王 芳,王培群.基于频繁序列挖掘的预取算法研究与实现[J].计算机研究与发展,2016,53(2):443-448.
[15] 李惠松,王小铭.一种基于帧间差分与时空相关性分析的运动目标检测算法[J].计算机与数字工程,2007,12(35):32-35.
[16] HUANG J,SUN H,SONG Qin-bao,et al.Revealing Density-based Clustering Structure from the Core-connected Tree of a Network[J].IEEE Transactions on Knowledge and Data Engineering,2013,25(8):1 876-1 889.
[17] LIU Wen ping,JIANG Hong bo,BAI X,et al.Distance Transform-based Skeleton Extraction and Its Applications in Sensor Networks[J].IEEE Transactions on Parallel and Distributed Systems,2013,24(9):1 763-1 772.
[18] LUXBURG U V.A Tutorial on Spectral Clustering[J].Statistics and Computing,2007,17(4):395-416.
杜 楚 男,(1987—),博士,工程师。主要研究方向:航天地面应用。
彭会湘 男,(1973—),研究员。主要研究方向:航天地面应用。
The Research on Space-based Data Hybrid Recommendation Algorithm
DU Chu1,PENG Hui-xiang1,LI Feng1,WANG Chang-li2
(1.The54thResearchInstituteofCETC,ShijiazhuangHebei050081,China; 2.Unit91635,PLA,Beijing102249,China)
The data recommendation could enhance the efficiency of data acquisition and it is already widely used in the electronic business system.However,existing recommendation algorithms could not match with the space-based data.A new space-based hybrid recommendation method has been proposed in this paper.This method is implemented based on pattern mining,interest relation graph and similarity clustering.The contents of recommendation results could meet user’s potential demand and enhance the efficiency of space-based acquisition.
space-based data;recommendation algorithm;space-based data hybrid recommendation;pattern mining;similarity clustering
10.3969/j.issn.1003-3106.2017.05.04
杜 楚,彭会湘,李 峰,等.天基数据混合推荐方法研究[J].无线电工程,2017,47(5):15-18.[DU Chu,PENG Huixiang,LI Feng,et al.The Research on Space-based Data Hybrid Recommendation Algorithm[J].Radio Engineering,2017,47(5):15-18.]
2017-02-10
中国博士后科学基金资助项目(2016M600197)。
V55
A
1003-3106(2017)05-0015-04
猜你喜欢
现代装饰(2022年5期)2022-10-13 08:47:36
国际太空(2022年1期)2022-03-09 06:04:40
空间科学学报(2021年2期)2021-07-21 08:43:40
数学小灵通(1-2年级)(2020年4期)2020-06-24 05:47:08
航天电子对抗(2019年4期)2019-06-02 08:22:50
电子测试(2017年15期)2017-12-18 07:19:27
作文周刊·小学一年级版(2016年23期)2017-06-05 23:27:03
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
中国卫生(2014年12期)2014-11-12 13:12:32
