
一种基于马尔科夫随机场的蒙古文古籍图像恢复方法
2017-04-24 10:25:01白淑霞鲍玉来
计算机应用与软件 2017年4期
白淑霞 鲍玉来* 敖 权
1(内蒙古大学图书馆 内蒙古 呼和浩特010021)2(内蒙古大学计算机学院 内蒙古 呼和浩特 010021)
一种基于马尔科夫随机场的蒙古文古籍图像恢复方法
白淑霞1鲍玉来1*敖 权2
1(内蒙古大学图书馆 内蒙古 呼和浩特010021)2(内蒙古大学计算机学院 内蒙古 呼和浩特 010021)
针对蒙古文古籍图像检索领域中对同一查询关键词,不同的二值化算法对整体检索性能影响问题,提出一种基于马尔科夫随机场的蒙古文古籍图像二值化方法,从而提高蒙古文古籍图像的检索性能。利用马尔科夫随机场模型在灰度图像和二值图像之间建模,通过训练码本估计隐藏层的先验概率,并分析灰度图像的直方图估计可观察层的概率密度。利用这两种先验知识实现图像二值化。实验数据集为100页蒙古文《甘珠尔经》,为了验证本文所提方法的性能,实验采用R-Precision作为评价指标。实验结果表明,基于马尔科夫随机场的二值化方法不仅可以有效修复受损图像,还可以进一步提高其检索性能。
蒙古文古籍 文档图像检索 图像二值化 马尔科夫随机场
0 引 言
古籍文献资料作为人类的宝贵文化遗产,由于其具有珍贵的历史和文物价值,它们大多被珍藏于博物馆、图书馆,除了少数专家和学者之外,公众很少有机会能翻阅它们。近年来,数字化技术的迅猛发展,进一步推动了古籍文献资料(包括蒙古文古籍文献)向数字图像的转换工作,从而实现对古籍文献资料的长久保存。同时,通过互联网,公众可以便捷地翻阅这些古籍文献的数字图像。然而,古籍文献的数字图像只记录了像素颜色、亮度等底层(图像)信息,并没有描述文献内容的高层(索引)信息,因此无法对其全文检索。
在古籍图像检索领域HDIR(Historical Document Image Retrieval),词定位技术能够通过图像匹配的方式从古籍图像中定位(检索)查询关键词出现的位置,并能够较好地解决古籍图像检索中涉及的相关问题(如图像质量差、文字书写不规范、变形严重等)[1]。在词定位技术中,通常将古籍图像集合表示成单词图像集合,即古籍图像被分割成单词图像。在检索时,依据用户提供的查询关键词的示例图像,计算示例图像与单词图像集合中每个单词图像之间的相似度,并按照相似度降序返回检索结果[2]。
蒙古文古籍图像检索问题中已经有应用词定位技术的先例。在之前的研究工作中,以清代康熙版(1720年印制)蒙古文《甘珠尔经》为对象,通过以下方法实现蒙古文古籍图像的检索[3]:首先,每幅彩色扫描图像先经过预处理(包括灰度化、平滑滤波、二值化),被转换成二值(黑白)图像,再经过版面分割,从中获得相应单词图像[4]。其次,分别从单词图像的每行和每列中提取如下轮廓特征:左轮廓、右轮廓、水平投影、水平方向笔划穿越数、上轮廓、下轮廓、垂直投影和垂直方向笔划穿越数。这样,每个单词图像可被描述成与单词图像宽度相同的四个“行”特征向量和与单词图像高度相同的四个“列”特征向量[5]。然后,将单词图像的每个特征向量分别执行离散傅里叶变换,仅保留频域空间中前10个低频复系数的模,从而可将每个单词图像表示成长度为80维的特征向量[6]。最后,在检索时,通过提出的单词图像生成方法,由相应字形拼接生成所需查询关键词的示例图像;示例图像也经上述过程的处理,转换成长度为80维的特征向量;再通过计算示例图像与其他单词图像特征向量之间的相似度可获得检索(排序)结果[7]。
为了提高检索的精度,我们尝试寻求更好的二值化方法。尽管蒙古文古籍文档图像的背景和光照强度变化并不剧烈,但是,由于蒙古文古籍风化、破损严重,使得图像本身包含很多破洞和掉色的情况,加之本实验使用的笔划穿越数特征对图像破洞十分敏感,预处理过程中,采用传统的二值化方法很难获得令人满意的检索效果。传统的二值化方法[8-13]通过阈值分割将图像上的每一个像素归类为前景或背景,其中主要包括两大类:全局阈值和局部适应阈值。在全局阈值中,整张图像只选取一个阈值,所有的像素灰度值通过与该阈值比较来确定其属于前景或背景。Otsu算法[8]作为全局阈值的经典算法,通过最大化类间方差来选取最佳的阈值。局部适应阈值则是依据像素的邻域块的灰度分布来确定该像素位置上的二值化阈值,局部适应阈值可以有效缓解光照变化剧烈带来的影响,但容易断笔和伪影等现象。Niblack[11]、Sauvola[13]两种算法是经典的局部阈值算法。最近,马尔科夫随机场理论被用作图像的二值化[14-17]。在文献[16]中,Cao等首先将输入观察图像y和输出二值图像x都分成大小相同且互不重复图像块yi和xi,利用马尔科夫随机场(MRF)模型来模拟相邻图像块之间的条件依赖关系,通过求解最大化后验概率(MAP)来对图像进行二值化处理。
1 马尔科夫随机场模型
本文使用文献[16]中所描述的MRF模型,该MRF模型被定义为G={V,E}的图模型。该模型中,二值图像被分割成不重叠的方块x1,x2,…,xN,并且观察图像也被分割成同样大小y1,y2,…,yN,其中1≤i≤N,二值图像块xi与观察图像块yi相对应,并且xi,yi∈V。二维马尔科夫随机场模型中存在两种不同的边,其中一种边用来连接节点xi和节点xj,xj表示xi水平方向和垂直方向上的四个相邻节点,可以表述为:每一个二值图像块在水平和垂直方向上条件依赖该块的四个相邻块;另一种边用来连接节点xi和yi,表示xi条件依赖yi,用来表达二值图像和灰度图像之间的条件依赖。条件依赖关系可以由下面公式表示:
P(xi|x1,x2,xi-1,xi+1,…,xN,y1,y2,…,yN)=
P(xi|xn1,i,xn2,i,xn3,i,xn4,i) 1≤i≤N
(1)
其中,xn1,i,xn2,i,xn3,i,xn4,i表示xi的四个邻接图像块,观察图像块与二值图像块之间的条件依赖关系可以表示为:
P(yi|x1,x2,…,xN,y1,y2,…,yi-1,yi+1,…,yN)=
P(yi|xi) 1≤i≤N
(2)
二维MRF模型表示如图1所示。
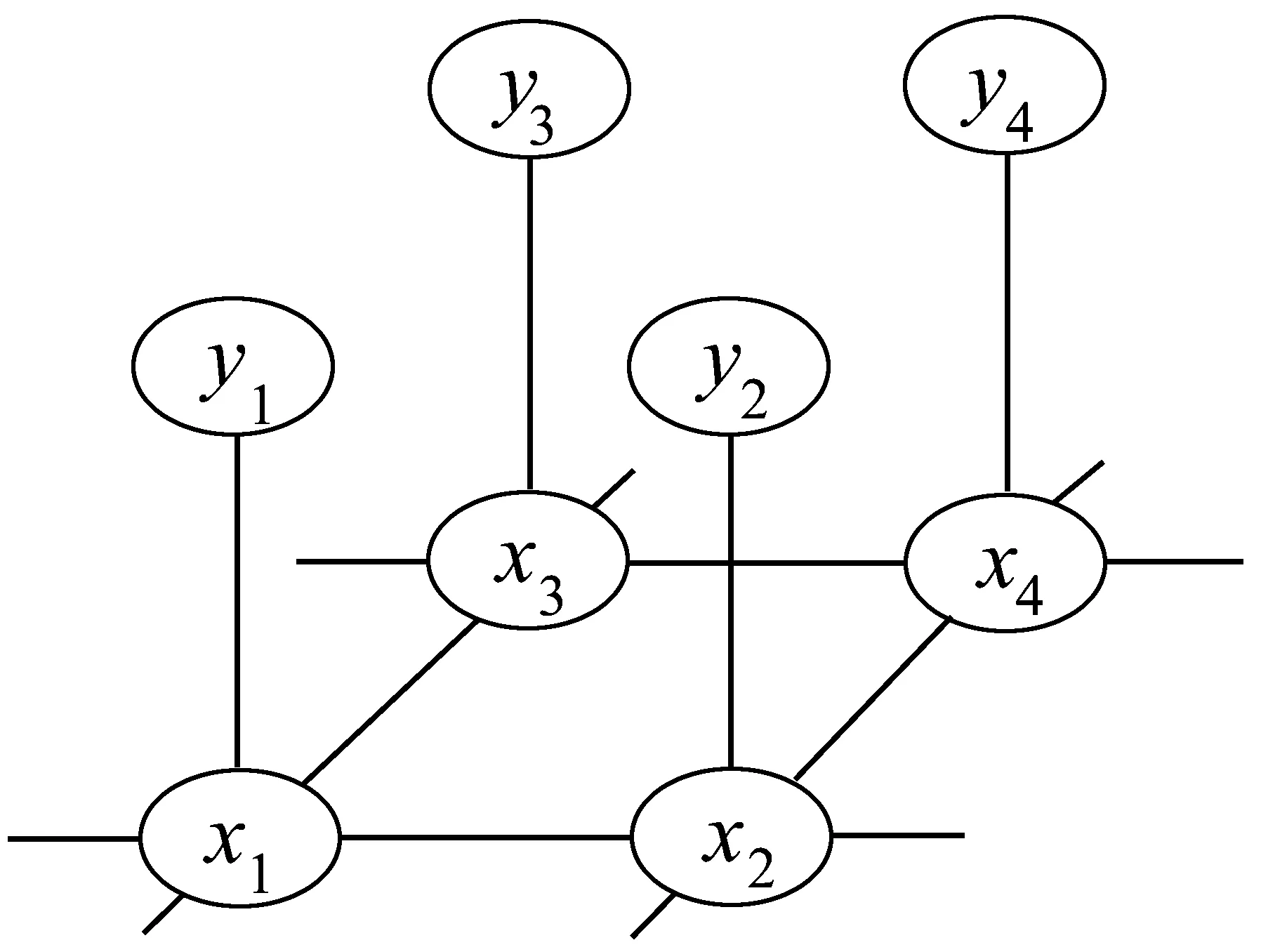
图1 二维马尔科夫随机场模型
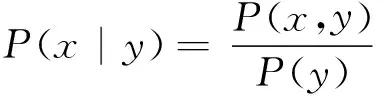
(3)
直接通过式(3)计算xj是不太现实的,因为随着节点个数的增加,计算量会呈指数形式增长。利用置信传播(BP)[16]迭代的方式来近似MAP估计为本文提供了一种解决方法,该方法的计算量随节点个数增加呈线性增长。
为了通过MRF模型得到优化的二值化图像,需要按照图2所示的流程,即:将MRF模型定义为二维图模型,然后通过计算MAP来估计最终的二值图像。其中,计算MAP,首先利用置信传播(BP)迭代计算,再进行二值块先验概率估计,最后估算观察模型。

图2 马尔科夫随机场(MRF)模型
1.1 置信传播(BP)

(4)
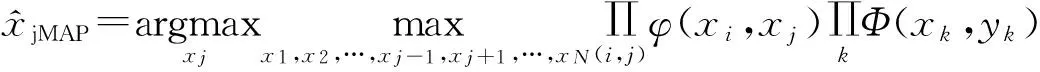
(5)
(6)
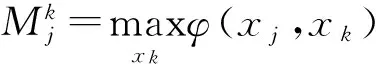
(7)
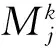
(8)
并且使用联合概率表示Φ,公式如下:
Φ(xk,yk)=P(xk,yk)
(9)
将式(8)、式(9)代入到式(6)、式(7)中,可以得到:
(10)
(11)
为了防止算数溢出,将式(10)、式(11)函数取对数:
(12)
(13)
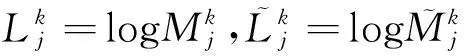
置信传播算法的参考代码如下:
Function reco_image=belief_propagation(test_image,patch)
% 文中1.1节算法实现
% 置信传播(belief_propagation)算法,通过迭代的方式回复出二值图像
% 输入参数:test_image待恢复图像,patch为码本(对应本文图3)
% 输出参数:reco_image恢复后图像
patch_size=size(patch,1);
patch_num=size(patch,3);
%采用文献[8]的方法估计前景和背景的均值与方差,并
%将灰度图进行二值化
[bina_image,fore_mean,fore_std,back_mean,back_std]=Binarization(test_image);
hor_num=size(test_image,1)/patch_size;
ver_num=size(test_image,2)/patch_size;
bina_patch=reshape(bina_image,[patch_size,patch_size,hor_num,ver_num]);
gray_patch=reshape(test_image,[patch_size,patch_size,hor_num,ver_num]);
% 计算式(13)中的条件概率P(yk|xk);
for i=1:hor_num
for j=1:ver_num
for k=1:patch_num
log_pr_yk_xk(i,j,k)=observe_model(gray_patch(:,:,i,j),bina_patch(:,:,k),…back_mean,back_std,fore_mean,fore_std);
end
end
end
L_jk=zeros(patch_num,hor_num,ver_num,4);
while 1
% 调用式(13)
L_jk=max_xk(hor_num,ver_num,patch,L_jk,log_hor_xk_xj,log_ver_xk,xj,log_x);
% 调用式(12)
reco_patch=argmax(hor_num,ver_num,patch,L_jk,log_x,log_pr_yk_xk);
if isequal(reco_patch,bina_patch)
break;
else
bina_patch=reco_patch;
end
end
%得到最终恢复图像
reco_image=reshape(bina_patch,[hor_num,ver_num])&bina_image;
end
1.2 二值块先验概率
为了求解P(xj)和P(xk|xj),首先想到能否直接统计xj出现的每一种情况的概率,显然这样是不行的。假设选用的图像块的大小为b×b,那么xj所有可能的情况会有2b2种,当b=15时,xj所有可能出现的情况有2225种,这样大的计算量远远超出了实验室计算机的计算能力。由于所用图像之间及内部存在大量的相似的图像块(patch),训练码本为本实验提供了一种可行的解决思路:利用码本中少量的码字来近似表达图像块所有可能出现的情况,将码字作为训练集中图像块{pi}的代表,从而使得计算变得可行。
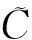
(14)
(15)
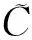

图3 233个码字组成的码本
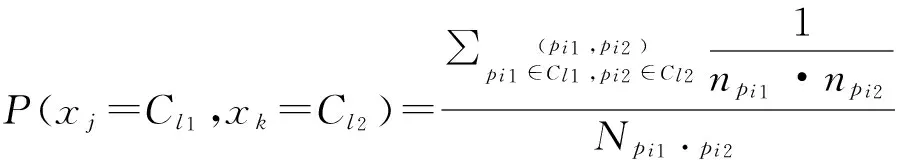
(16)
其中l1,l2=1,2,…,M。以水平方向为例,(pi1,pi2)表示训练样本中相邻的两个图像块,并且pi1在pi2的左边,Npi1·pi2表示水平相邻块的总对数。
1.3 观察模型
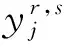
(17)
可以证明:
(18)
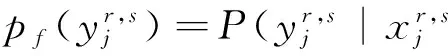
(19)
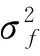
观察模型的参考代码如下所示:
% 文中1.3节算法实现,用以计算原始图像每个patch与码本
%的条件概率,即,式(19)
% 输入参数:gray_patch原始图像的patch,bina_patch为第k个
%码本
function log_pr=observe_model(gray_patch,bina_patch,back_mean,back_std,fore_mean,fore_std)
log_pr=0;
for i=1:patch_size
for j=1:patch_size
if bina_patch(i,j)==0
log_pr=log_pr+log(normpdf(gray_patch(i,j),fore_mean,fore_std));
else
log_pr=log_pr+log(normpdf(gray_patch(i,j),back_mean,back_std));
end
end
end
end
2 实 验
2.1 实验数据集
本实验采用的数据集是从内蒙古大学图书馆获取的100页蒙古文《甘珠尔经》的彩色扫描图像,扫描分辨率为600 DPI。每幅彩色扫描图像均经过文献[4]提出的预处理方法,被转换为灰度图像,并通过版面分析共获得24 827个单词(灰度)图像。本实验将对这些单词(灰度)图像使用本文提出的MRF算法进行二值化。
为了便于统计相关性能指标,数据集的每一页扫描图像都采用Unicode编码进行了文本标注。该实验数据集已被用于统计文献[3]中检索系统的性能。在本研究中,继续沿用文献[3]使用的查询关键词(一个“查询关键词”相当于文本信息检索中的一个“Topic(主题)”),共计20个。这些查询关键词是对100页扫描图像的文本标注统计词频之后随机挑选出来的。挑选标准是词频(出现次数)不少于20次,且具有实际意义的单词(如名词、动词等),如表1所示。
表1 查询关键词列表

2.2 实验直观结果对比
在蒙古文古籍图像检索以前的研究中,《甘珠尔经》曾被尝试多种方法二值化,例如Otsu算法[8]、Kittler算法[9]和FCM算法[10],但二值化结果都不太理想。在先前的图像检索中,本文使用Otsu、Kittler和FCM三种算法的综合结果,即三种算法投票的方式,若两种或三种算法将某一像素归类为前景或背景,则该像素为前景或背景。实验结果对比如图4所示,(a)、(d)为原始破损灰度图像,(b)、(e)为采用FCM、Kittler和Otsu投票二值化之后的二值图像,(c)、(f)为采用MRF算法二值化之后的二值图像。

图4 二值化效果对比
2.3 评价指标
本文采用的性能评价指标是信息检索中常用的R-Precision。R-Precision的定义如下[19]:
(20)
其中,Rel是表示与与查询关键词相关的单词个数,r表示在是前Rel个检索结果中出现的相关单词的个数。如果相关单词出现在前Rel个检索结果中的数目越多,则R-Precision的值越高,其最大值为1(前Rel个检索结果中全部为相关单词),最小值为0(前Rel个检索结果中无相关单词)。对每个查询关键词,可按上述公式由其检索结果计算各自的R-Precision。
2.4 实验过程、结果与分析
在实验中,对每个查询关键词都执行以下过程:首先利用本文中所述的方法来对图像进行二值化;第二步,在二值图像的基础上提取本实验所需要的80维轮廓特征;接下来,将该特征放到特征库匹配,按相似度降序形成的检索结果(单词图像列表);最后统计结果中的R-Precision指标(如图5所示)。
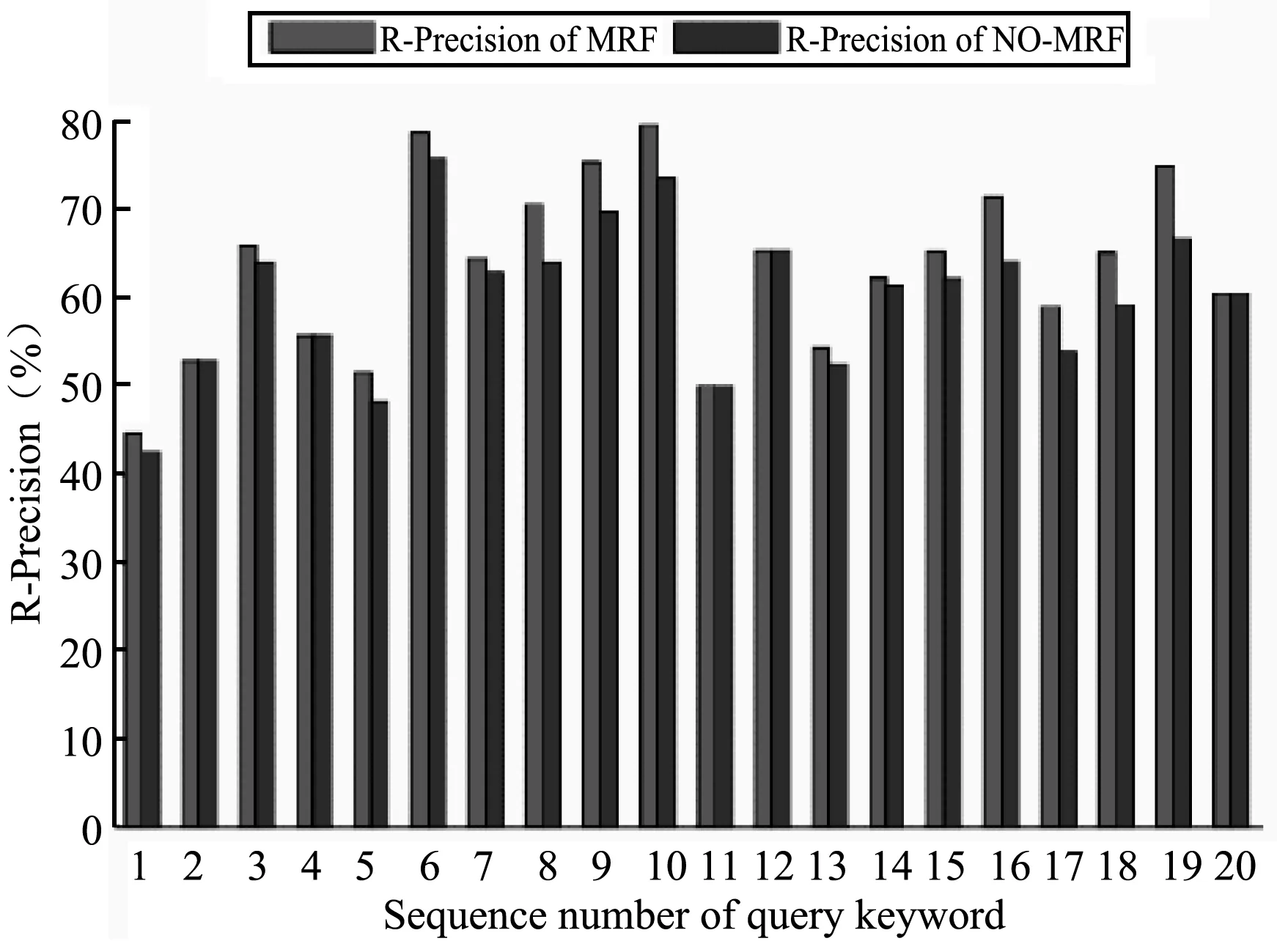
图5 每个关键字的R-Precision
从图5可以看出,使用MRF之后大部分查询关键词的检索性能都有所提高,部分查询关键词的检索性能未发生变化。
3 结 语
本文采用了一种更加适合蒙古文古籍文档检索中预处理的二值化算法。该方法能够缓解低质量古籍文档中的因为破损、掉色造成的图像信息损失,不仅在视觉上获得了比较好的结果,而且也提高了检索性能。从整体来看,不使用MRF的平均R-Precision为57.76%,MRF处理之后的平均R-Precision为59.73%,检索性能提高了近2%。在后续的研究中,我们将致力于选择检索精度更高、维度更少的特征来描述单词图像,以提高检索精度和性能。
[1] Manmatha R, Han C, Riseman E M, et al., Indexing Handwriting Using Word Matching [C]// Fox E A, Marchionini G. Proceedings of the First ACM International Conference on Digital Libraries.
[2] Rath M T, Manmatha R. Word spotting for historical documents[J]. International Journal on Document Analysis and Recognition, 2007, 9(2-4): 139-152.
[3] Wei H X, Gao G L. A keyword Retrieval System for Historical Mongolian Document images[J]. International Journal on Document Analysis and Recognition, 2014, 17(1): 33-45.
[4] Wei H X, Gao G L, Bao Y L, et al. An Efficient Binarization Method for Ancient Mongolian Document images [C]// Proceedings of the Third International Conference on Advanced Computer Theory and Engineering. Washington DC: IEEE Computer Society, 2010: 43-46.
[5] 魏宏喜, 高光来. 基于Word Spotting 技术的蒙古文古籍图像检索中的特征选择[J].计算机应用, 2011, 31(11):3038-3041.
[6] Wei H X, Gao G L, Zhang X L. Indexing for Mongolian Kanjur Images in Word Spotting[J]. Journal of Computational Information Systems, 2013, 9(4):1501-1508.
[7] Wei H X, Gao G L. Word Spotting Application in Historical Mongolian Document Images[C]// Huang D S, Bevilacqua V, Figueroa J C, et al. Proceedings of the Ninth International Conference on Intelligent Computing. Berlin Heidelberg: Springer-Verlag, 2013: 256-274.
[8] Ohtsu N. A Threshold Selection Method from Gray-Level Histograms[J]. IEEE Transactions on Systems Man & Cybernetics, 1979, 9(1):62-66.
[9] Kittler J, Illingworth J. Minimum error thresholding[J]. Pattern Recognition, 1986, 19(1):41-47.
[10] Duda R, Hart P, David G. Pattern Classification[M]. 2nd ed.Wiley, New York, 2001:528-530.
[11] Niblack W. An Introduction to Digital Image Processing[M]. Prentice Hall, Englewood Cliffs, 1986:1251-1255.
[12] Yang Y, Yan H. An adaptive logical method for binarization of degraded document images[J]. Pattern Recognition, 2000, 33(5):787-807.
[13] Sauvola J,Seppanen T,Haapakoski S,et al.Adaptive Document Binarization[C]// Proceedings of 4th Internationl Conference on Document Analysis and Recogntion,1997:147-152.
[14] Gupa M D, Rajaram S, Petrotic N, et al. Restoration and Recognition in a Loop[C]// Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2005.
[15] Wolf C, Doermann D. Binarization of Low Quality Text Using a Markov Random Field Model[C]// International Conference on Pattern Recognition, 2002. Proceedings. IEEE, 2002,3:160-163.
[16] Cao H, Govindaraju V. Preprocessing of Low-Quality Handwritten Documents Using Markov Random Fields[J]. Pattern Analysis & Machine Intelligence IEEE Transactions on, 2009, 31(7):1184-1194.
[17] Su B, Lu S, Tan C L. A learning framework for degraded document image binarization using Markov Random Field[C]// Pattern Recognition (ICPR), 2012 21st International Conference on. IEEE, 2012:3200-3203.
[18] Freeman W T, Pasztor E C, Carmicheal O T. Learning Low-level Vision[J]. International Journal of Computer Vision, 2000, 40(1):25-47.
[19] Manning C D, Raghavan P, Schutze H. Introduction to Information Retrieval [M].Cambridge: Cambridge University Press, 2009: 158-164.
AN IMAGE RETRIEVAL METHOD OF HISTORICAL MONGOLIAN DOCUMENT BASED ON MARKOV RANDOM FIELD
Bai Shuxia1Bao Yulai1*Ao Quan2
1(Library,InnerMongoliaUniversity,Hohhot010021,InnerMongolia,China)2(SchoolofComputerScience,InnerMongoliaUniversity,Hohhot010021,InnerMongolia,China)
Aiming at the problem of the influence of the same query keyword and different binarization algorithms on the overall retrieval performance in historical Mongolian document images retrieval, this paper presents an image binarization method of historical Mongolian document based on Markov random field to improve the retrieval performance of historical Mongolian documents. The MRF model is used to model the gray level image and the binary image. The prior probability of the hidden-layer is estimated by the training codebook, and the probability density of the observable-layer is estimated by analyzing the histogram of the gray image. The two kinds of prior knowledge are used to realize image binarization. The experimental data set is 100-page Mongolian Kanjur. In order to verify the performance of the proposed method, R-Precision is used as the evaluation index. Experimental results show that the binarization method based on Markov random field can not only effectively repair the damaged image, but also can improve its retrieval performance.
Historical Mongolian document Document image retrieval Image binarization Markov random field
2016-10-24。国家自然科学基金项目(71163029)。白淑霞,馆员,主研领域:蒙古文信息检索。鲍玉来,副研究馆员。敖权,本科。
TP319.3
A
10.3969/j.issn.1000-386x.2017.04.035
猜你喜欢
黑龙江大学自然科学学报(2021年4期)2021-11-19 07:05:10
有色金属(矿山部分)(2021年4期)2021-08-30 06:10:34
高技术通讯(2021年2期)2021-04-13 01:09:46
资源导刊(信息化测绘)(2020年5期)2020-06-22 08:37:00
测控技术(2018年10期)2018-11-25 09:35:28
卫拉特研究(2018年0期)2018-07-22 05:47:46
读写算·基础教育研究(2017年17期)2017-12-31 00:00:00
西部蒙古论坛(2016年4期)2017-01-16 12:12:47
卫拉特研究(2016年0期)2016-12-06 09:11:56
湖北师范大学学报(自然科学版)(2015年1期)2016-01-10 08:41:30
