
基于最佳一致光滑逼近的孪生支持向量机研究
2017-04-24 10:38:33唐辉军杨志民
计算机应用与软件 2017年4期
唐辉军 白 玲 杨志民
1(宁波大红鹰学院信息工程学院 浙江 宁波 315175)2(浙江工业大学之江学院理学院 浙江 杭州 310023)
基于最佳一致光滑逼近的孪生支持向量机研究
唐辉军1白 玲1杨志民2
1(宁波大红鹰学院信息工程学院 浙江 宁波 315175)2(浙江工业大学之江学院理学院 浙江 杭州 310023)
孪生支持向量机本质为两个二次规划问题,对于其目标函数中约束变量取正号不可微特性,提出一种基于最佳一致逼近的多项式光滑函数构建方法。分别以Bernstain多项式和Chebyshev多项式进行正号函数最佳一致有效光滑逼近。重点突出Chebyshev多项式的最佳一致逼近过程,使用Remez算法构造最佳一致Chebyshev多项式,讨论各阶Chebyshev多项式逼近状况。最后综合最佳一致逼近多项式和样本适应度构建目标优化函数,采用快速Newton-Armijo算法求解目标优化函数,基于UCI数据验证了方法的优越性。
孪生支持向量机 最佳一致逼近 适应度
0 引 言
支持向量机[1](SVM)被认为是能较好地对多角色个体进行有效分类和回归的重要工具。可在不同应用领域针对小样本、非线性模式识别表现出独特的优势[2-3]。不少专家和学者对其进行了深入研究和效率改进,从提高计算速度出发,对分类超平面计算进行效率改进成为该领域一个研究热点。PSVM[4]、GEPSVM[5]等支持向量机新模型被相继提出。2007年Jayadeva等人在上述研究成果的基础上,提出孪生支持向量机(TWSVM)机器学习新方法[6],其本质上表现为构造两个不平行的分类超平面,按照离哪类近就归属哪类的性质,解决两个二次规划问题。由于其计算速度为标准SVM的4倍,TWSVM在图像检测、人工识别[7-8]等众多领域得到了良好应用。并且与一般支持向量分类机、回归机相比,孪生支持向量机无论在正确率计算、计算速度、优化精度等方面都得到了有效提高[9]。以孪生支持向量分类机为例,其标准数学模型构造为:
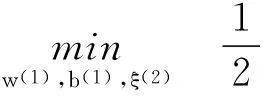
(1)

在线性分类情况下,按照一般支持向量机的求解思路,引入拉格朗日参数,基于KKT条件,对式(1)进行对偶空间内优化求解,计算结果得到形如式(2)所示。其中M=D=[B,e2]T,N =S=[A,e1]T,e1,e2均为值为1的列向量。

(2)
对于拉格朗日参数α和β的寻求,可通过内点法[10]、性能更好的TBSVM[11]等相关算法得到。在非线性分类情况下,依托于SVM中核函数[12]的引入,也可得到相应的数学模型。
式(2)应用了从对偶空间中解决孪生支持向量机的解决问题。但文献[13-14]通过计算分析表明,TWSVM事实上可直接基于原始数值空间求解优化问题,在原始空间内引入正号函数形成光滑孪生支持向量机模型(STWSVM),进而通过对正号函数进行逼近,将原模型进行光滑化,从而达到采用梯度算法快速求解目的。Chen等人[15]采用Sigmoid函数作为光滑函数,对孪生支持向量的目标函数作光滑处理,并采用快速算法求解相应的模型。实验结果都表明了其有效性。文献[16,17] 基于光滑孪生支持向量机的光滑逼近要求,在总结了大量使用方法的基础上,提出了使用多项式光滑逼近方式,并且基于一定的标准数据集计算取得了比Sigmoid函数更好的效率优化结果。
光滑函数的选择是解决这一问题的关键所在,本文在总结光滑孪生支持向量机数学形式的基础上,提出一种基于最佳一致逼近的光滑函数,通过样本数据的重要度设置样本数据适应度,最后基于最佳一致光滑逼近函数和适应函数构建新的目标优化函数。相关数据集的实验验证,证明了最佳一致孪生支持向量机的可行性。
1 光滑孪生支持向量机
按照所采用光滑方法的不同,其一般运算过程为将式(1)中的松弛变量ξ(1)、ξ(2)由1范式改变为2范式。
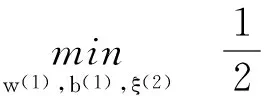
(3)
式(3)中对ξ(1)、ξ(2)具有一定的约束条件,引入正号函数[x]+=max(0,x),根据KTT条件设置ξ(1)、ξ(2)优化取值,进而引入光滑逼近函数p(x),其表示了通过一定的函数转换,把式(3)转变为两个无约束优化问题。
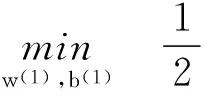
(4)
式(4)变成了可微的目标函数优化问题,可采用具有快速收敛能力的相关算法求解该模型。光滑孪生支持向量机在原始空间更具优势,理论分析和实验验证[15]都表明了其有效性和可行性。
在非线性情况下,基于核函数的孪生支持向量机一对超平面求解目标函数可以表示为:
(5)
基于同样的原理,将式(5)转换成为无约束目标函数为:
(6)
2 最佳一致逼近光滑函数
光滑函数的选择是求解式(4)和式(6)数学模型的关键,文献[16,17]指出,基于多项式插值的光滑函数构建是解决约束不可微问题的重要方法。但对于多项表达式的寻求,目前还没有普遍的方法来构造完成,并且逼近误差达不到计算需求。最佳一致逼近具有逼近速度快、精度误差小等特点,为解决上述问题提供了一个良好方法。

(7)
Bn(f)随着参数n的增大逼近了目标函数f(x),显然,正号函数满足在区间上的连续,基于逼近精度需求,考虑函数在对称区间[-1,1]逼近,通过变量替代变换到计算区间,可得到与其对应Bernstein多项式为:
(8)
表1表示了Bernstain多项式在区间[-1,1]上对正号函数的逼近多项式。可以看到,随着逼近的逐次迭代,计算多项式复杂度也得到了较大的提高。
由表1构造的多项式结合文献[18]对其的精度分析可知,Bernstain多项式对整体的逼近性质要求较好,但收敛速度较慢,提高精度伴随着多项式次数的提高,这对复杂函数下的多项式逼近工作量较大。但由于正号函数并不复杂,构造表1中Bernstain多项式逼近正号函数不失为一种方法。

表1 Bernstain多项式最佳逼近
与Bernstain多项式逼近相比,Chebyshev逼近是构造最佳逼近多项式的一种较为理想的有效方式。其在构建过程中更强调整体精度性且迭代次数计算并不复杂。其表示对于f(x)∈C[a,b],要寻求f(x)的n次最佳一致逼近代数多项式pn(x),问题的关键在于确定具有n+2个点的交错点组{xi},如果点组存在,则满足:
(9)
其中η=Δ(f,pn)或者-Δ(f,pn)。由介值定理可知,f(x)-pn(x)在C[a,b]上至少有n+1个零点,pn(x)就是以这n+1个零点为插值点的n次拉格朗日插值多项式。
式(9)是一个关于n+2个变元a0,a1,…,an,η的n+2阶线性方程组,存在唯一的解,从而求得最佳逼近多项式pn(x)和最佳逼近|η|。由于寻找交错点组并不容易,这里应用Remez最佳一致近似算法[14]来求解。其有以下3步构成:
(1) 在区间[a,b]上选择n+2由小到大的初始点列{x0,x1,…,xn+1}作为交错点组,设置迭代计算精度ε>0。
(2) 计算式(5)中的方程组,得到{a0,a1,…,an},进而构建pn(x),计算最佳逼近|η|。
(3) 若Δ(f,pn)=|f(x)-pn(x)|∞-|η|≤ε,则迭代终止,否则利用单一交换、同时交换等方法计算替换新的交错点组,返回步骤(2)。
依据Remez算法,对光滑孪生支持向量机中的正号函数进行最佳一致Chebyshev多项式逼近。设定初始迭代区间范围[-1,1],应用单一交换方法,计算正号函数多项式逼近取值过程,其二次多项式逼近结果如表2所示。

表2 多项式最佳逼近
同理可分别计算得到最佳一致n次Chebyshev多项式,由于Remez算法为逐次逼近近似求解,其并没有统一的n次多项式表示,表3罗列了n取值不超过5时的Chebyshev多项式及其误差精度。
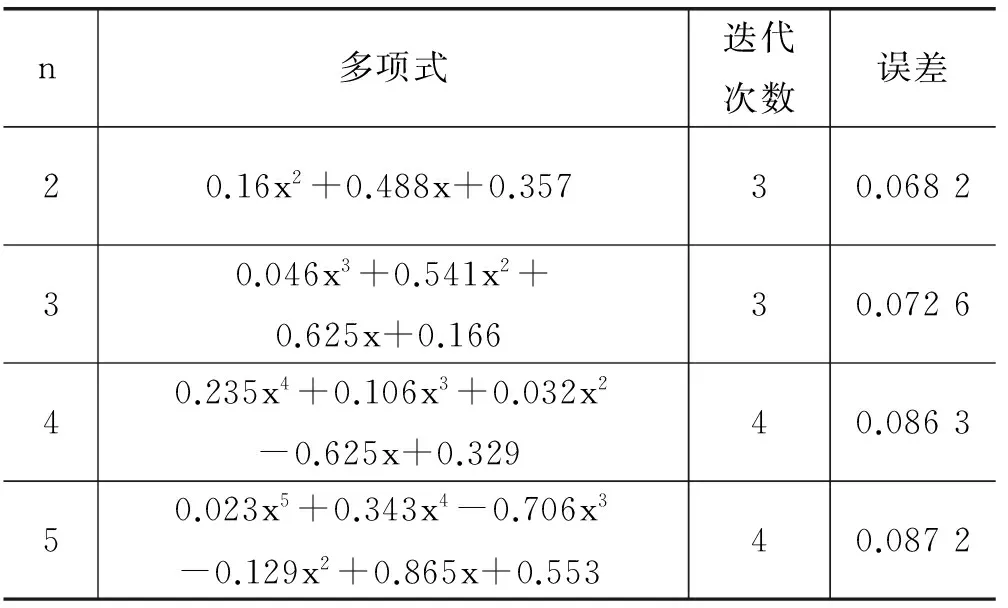
表3 Chebyshev多项式最佳逼近
从表3可以看出,Remez算法的收敛速度相当快,经过3次迭代就可以计算得到结果。图1表示了样条插值多项式(黑线)、最佳一致五次Bernstain多项式(细线)、二次Chebyshev多项式(虚线)正号函数逼近效果,从图形可以知道,最佳一致逼近Chebyshev多项式相比插值多项式、Bernstain多项式取得了良好的逼近效果。
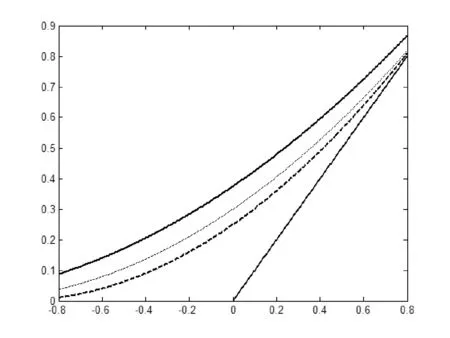
图1 最佳一致逼近光滑函数
为了综合考虑样本离群点对孪生支持向量机的影响,在基于文献[13]的加权系数设计方式上,这里采用基于距离公式建立各个样本点的适应度,为了有效表示中心点,离群点及对分类超平面的影响,依据离群点的位置重要度指标形成一个数值向量g1、g2。其值设置为:
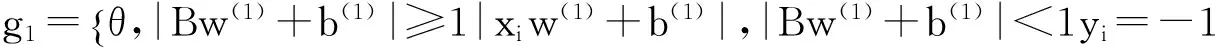
(10)
综合式(4),式(10),在原始空间内对线性孪生支持向量机求值,通过构造最佳一致二次多项式光滑逼近目标函数内的正号函数,得到在区间内的具体优化目标为:
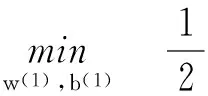
(11)
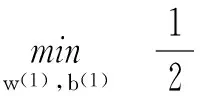
(12)其中R为求得的最佳一致多项式系数。式(11)、式(12)表示了无约束条件下的二次规划求值,可采用Newton-Armijo算法求解优化模型。其一般计算流程为:
(1) 设定初始点(w(0),γ0),设置算法精度ε,设置循环计算的初始值k=1。
(2) 计算关于当前迭代点的偏导函数g(k)的值,判断是否满足终止条件‖g(k)<ε‖,否则转(3)。
(3) 求新的迭代点的(w(k),γk)值,根据迭代公式求搜索方向d(k)。
(4) 基于步骤(3)中的寻求目标d(k),依据全局搜索策略步长ak。
(5) 基于上述步骤,迭代公式(w(k+1),γk+1)= (w(k),γk)+d(k)ak,转(2)。
3 实 验
为验证模型有效性,以BUTWSVCM表示最佳一致二次Chebyshev多项式光滑逼近孪生支持向量分类机,以DUTWSVCM表示对偶空间内的孪生支持向量机分类机,BETWSVCM表示Bernstein五次多项式逼近分类机。所有实验在都在Intel(R)Core(TM)i5-2450MCPU,4GB内存和MATLABr2011b的环境中进行 应用Newton-Armijo算法求解优化模型。设置Remez算法精度ε=1.0E-3,线性算法对数据集的测试结果对比见表4所示。采用一般高斯径向基函数作为核函数,从UCI数据集中各取100条数据作为测试数据,非线性算法下的训练和测试结果见表5所示。

表4 线性算法计算结果

表5 非线性算法计算结果 %
从表4、表5中可以看到, BUTWSVM取得了更好的计算速度和精度。采用最佳一致光滑逼近函数求解孪生支持向量机可以得到满意的结果。
依据表1、表3的多项式表达方式,选取同一UCI数据集,对n(n<6)次最佳一致多项式逼近效果和准确率开展计算分析,计算结果如表6所表示。其表明,相比较于其他同类多项式,Bernstein五次多项式、Chebyshev二次多项式取得了良好效果。也间接验证了表4、表5的结果最佳性。
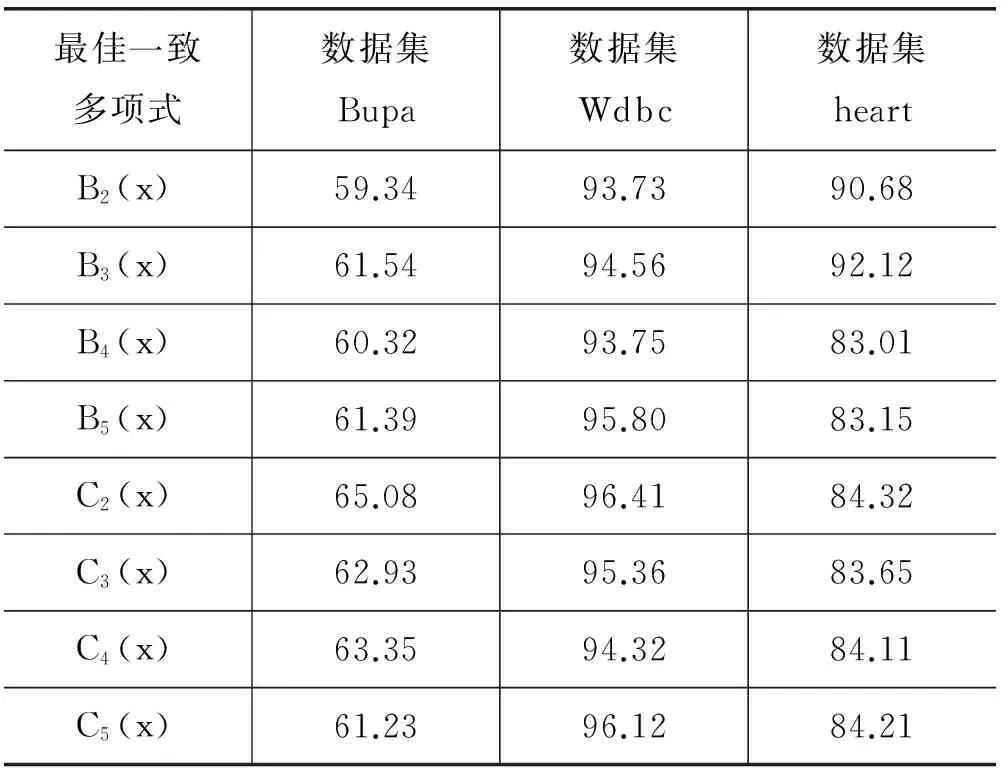
表6 最佳一致多项式分类准确率 %
4 结 语
孪生支持向量机与一般支持向量机相比,在计算效率方面得到了有效提升。本文针对孪生支持向量机原始空间优化求值的需求,构建最佳一致光滑逼近方法孪生支持向量机计算模型。给出了最佳一致二次多项式的推导和计算过程,定义了孪生支持向量机光滑数学模型,基于样本位置计算了个体适应度。通过实验仿真可以得到最佳一致光滑多项式能够有效地逼近原始空间内的正号函数,计算准确率和速度都达到了优化要求。最佳一致光滑逼近函数的建立,对于优化孪生支持向量机计算过程进而达到快速求解目的,提高计算分析准确率具有重要的作用。
[1] Vapnik V N.The Nature of Statistical Learning Theory[M].Springer-Verlag,New York,1995.
[2] Shawe-Taylor J,Sun S.A review of optimization meth- odologies in support vector machines[J].Neurocomputing,2011,74:3609-3618.
[3] Wu J X.Efficient HIK SVM learning for Image Classification[J].IEEE Transactions on Image Processing,2012,21(10):4442-4453.
[4] Fung G,Mangasarian O L.Proximal Support Vector Machine Classifiers[C]//Proc 7thACM SIFKDD Intl Conference on Knowledge Discovery and Data Mining,2001:77-86.
[5] Mangasarian O L,Wild Edward W.Multi-surface proximal support vector machine classification via generalized eigenvalues[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2006,28(1):69-74.
[6] Jayadeva K R,Suresh C.Twin support vector machines for pattern classification[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2007,29(5):905-910.
[7] Kumar M A,Gopal M.Application of smoothing technique on twin support vector machines[J].Pattern Recognition Letters,2008,29(13):1842-1848.
[8] Khemehandani R,Jadeva S Chajndra.Optimal kernel selection in twin support vector machines[J].Optimization Letter,2009,3:77-88.
[9] Cong H H,Yang C F,Pu X R.Efficient Speaker Recognition based on Multi-class Twin Support Vector Machines and GMMs[C]//2008 IEEE Conference on Robotics,Automation and Mechatronics,2008:348-352.
[10] 袁玉萍,钟萍,邹艳华.基于预测-校正原对偶内点法的多分类支持向量机学习算法[J].南京大学学报,2009,45(4):494-498.
[11] Shao Y H,Zhang C H,Wang X B,et al.Improvements on twin support vector machines[J].IEEE Transactions on Neural Networks,2011,22(6):962-968.
[12] Jayadeva R K.Optimal kernel selection in twin support vector machines[J].Optimal Letter,2009,3:77-88.
[13] Wang Z,Shao Y H,Wu T R.A GA-based model selection for smooth twin parametric-margin support vector machine[J].Pattern Recognition,2013,46:2267-2277.
[14] 黄华娟.孪生支持向量机关键问题的研究[D].中国矿业大学,2014.
[15] Chen X B,Yang J,Liang J,et al.Smooth twin support vector regression[J].NeuralComputing & Applications,2012,21:505-513.
[16] 熊金志,胡金莲,袁华强,等.一类光滑支持向量机新函数的研究[J].电子学报,2007(2):8-10.
[17] 陈卫东,范艳峰.基于三次样条插值的支持向量机研究[J].计算机工程与设计,2009,30(7):1722-1725.
[18] 蒋尔雄.数值逼近[M].上海:复旦大学出版社,2007.
RESEARCH ON TWIN SUPPORT VECTOR MACHINES BASED ON BEST UNIFORM SMOOTHING APPROXIMATION
Tang Huijun1Bai Ling1Yang Zhimin2
1(CollegeofInformationEngineering,NingboDahongyingUniversity,Ningbo315175,Zhejiang,China)2(CollegeofZhijiang,ZhejiangUniversityofTechnology,Hangzhou310023,Zhejiang,China)
The essence of twin support vector machines(TWSVM) is to optimise two quadratic programming problems. As the positive constrained variable of objective function was not differentiable, this paper presented a constructing method of polynomial smoothing function based on best uniform approximation. Bernstein and Chebyshev polynomial were established to effectively achieve the best uniform smoothing approximation of the positive function. The best uniform approximation of Chebyshev polynomial is emphasized. The best uniform Chebyshev polynomial was established by applying the Remez algorithm, and each order of the Chebyshev polynomial approximation was discussed. Finally, the objective optimal function based on best uniform approximation polynomial and the degree of sample adaption could be got, and the fast Newton-Armijo algorithm was used for solving the objective optimal function. On the basis of UCI data, we validated the advantages of the method.
Twin support vector machines Best uniform approximation Degree of adaption
2015-12-07。国家自然科学基金项目(10926198);浙江省公益技术应用研究计划项目(2016C33G2620016);宁波市自然科学基金项目(2015A610135)。唐辉军,讲师,主研领域:数据挖掘,计算机仿真。白玲,硕士生。杨志民,教授。
TP18
A
10.3969/j.issn.1000-386x.2017.04.030
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
西南石油大学学报(自然科学版)(2019年1期)2019-01-28 09:33:52
电子制作(2018年11期)2018-08-04 03:25:38
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
测绘科学与工程(2016年5期)2016-04-17 06:51:15
电测与仪表(2016年10期)2016-04-12 00:26:24
电测与仪表(2016年14期)2016-04-11 12:32:48
新高考·高二数学(2015年11期)2015-12-23 18:17:44
电子设计工程(2015年3期)2015-02-27 12:03:45
