
图书信息检索中读者兴趣偏好挖掘模型的建立仿真*
2017-04-19 03:17:58张福泉
沈阳工业大学学报 2017年2期
冯 静, 张福泉
(1.新疆师范大学 图书馆, 乌鲁木齐 830054;2.北京理工大学 软件学院, 北京 100081)
图书信息检索中读者兴趣偏好挖掘模型的建立仿真*
冯 静1, 张福泉2
(1.新疆师范大学 图书馆, 乌鲁木齐 830054;2.北京理工大学 软件学院, 北京 100081)
针对传统挖掘模型对图书信息检索中读者兴趣偏好数据进行挖掘时,存在的挖掘效率低、耗时长等问题,提出基于聚类分析的读者兴趣偏好挖掘模型.采用分类索引分布树法对图书相似度与读者兴趣距离进行计算,通过兴趣因子对兴趣偏好度进行度量,并以此为基础,采用相关反馈模型Rocchio算法对读者兴趣图书检索进行扩展,引入聚类分析法建立图书信息检索中读者兴趣偏好挖掘模型.实验仿真结果表明,采用改进模型时,其挖掘效率、时间及误差均优于传统模型.
图书信息;检索;读者兴趣偏好;挖掘模型;兴趣因子;兴趣距离;图书相似度;扩展
计算机信息网络及通讯技术的飞速发展给人们日常生活带来了极大的便利,各行各业存储了大量关于产品和用户的数据信息,导致数据库技术得到了越来越多的重视[1-3].图书馆也开始利用信息技术来提高自己的软件条件,读者每天都会对图书馆中各种资源加以利用,使得图书馆数据库中积累了大量的数据信息,而这些信息中隐藏了很多值得工作者去深入研究的关系信息[4-5].如读者与借阅图书之间的关联规则,若是掌握好这些规则,则可以对读者进行个性化图书推荐,实现读者兴趣偏好的预估.如何对图书检索中读者兴趣偏好数据进行高效准确地挖掘成为了该领域重点研究的方向,文献[6]提出一种基于多层安全相关属性标定的偏好数据挖掘模型,并使用决策算法得到挖掘数据,所提出的挖掘模型提高了数据的准确性与选择数据的安全性,但其整体挖掘时间较长.文献[7]以男士上衣为例,通过问卷调查得出数据信息,并采用K-means聚类算法,利用专业的数据挖掘软件处理数据,拟合出具有代表性的设计模型.所提出的模型可以有效揭示不同类型消费者的偏爱度,但其建模方法复杂,需要应用专业软件.本文针对上述问题,提出一种基于聚类分析的偏好挖掘模型,无需其他专业软件辅助,提高了挖掘的效率与准确性.
1 兴趣偏好统计与计算
1.1 图书相似度与读者兴趣距离计算
在对读者兴趣偏好进行度量时,首先需要对图书相似度与读者兴趣距离进行计算,本文采用分类索引分布树法对其进行计算[8].两名读者S1、S2所借阅图书之间相似度的计算方法如下:
1) 当两名读者所借阅图书的分类索引号完全相同时,说明读者借阅的是同一本图书或者是两本类似的图书,则计算图书之间的相似度需考虑读者对该图书的借阅时间.将该图书的平均借阅时间与读者借阅所有书籍的平均借阅时间进行比较,计算得到的比值反应出图书的相似度,即
(1)
式中:x、y为两名读者所借阅的具有完全相同分类索引号的图书;T1x、T2y为两名读者S1、S2对图书x、y的借阅时间;m、n分别为两名读者S1、S2借阅图书的行为数;T1j、T2j为两名读者S1、S2对图书j的借阅时间.
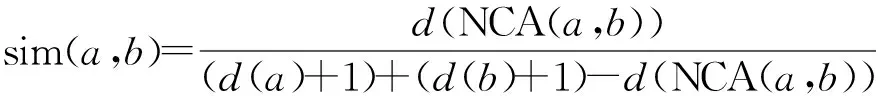
(2)
式中:d(a)、d(b)分别为图书a、b的分类号在图书分类索引分布树中的所属深度;d(NCA(a,b))为最近共同标志在图书分类索引分布树中的所属深度.
根据式(1)和(2)可以得到图书相似度与读者兴趣间的距离为
(3)
式中,l为读者所借阅图书间相似度的个数.通过采用分类索引分布树法对图书相似度与读者兴趣距离进行计算,可为图书信息检索中读者兴趣偏好数据聚类提供基础依据.
1.2 读者兴趣偏好的度量
在对图书相似度与读者兴趣距离进行计算的基础上,利用一种兴趣因子来衡量关联规则的兴趣偏好程度,其被定义为两个变量的联合概率密度除以两个变量期望概率的乘积.
TF-IDF(term frequency-inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术,在图书信息检索中可用其来衡量读者的感兴趣程度.TF值越大,表明兴趣偏好程度越高,如果一个图书信息在读者兴趣偏好中出现的频率很低,则这本图书易于区分和识别.TF-IDF权值计算表达式为
(4)
式中:fij为读者感兴趣图书ui使用标签tj在图书信息检索中出现的次数;N为训练集中读者感兴趣的总图书数量;ni为训练集中出现的特征项的图书数量;Di为读者感兴趣图书ui的标签结合.
读者兴趣偏好可以利用读者感兴趣的图书集合来度量.图书标签映射的项目数为图书被读者选取次数,利用TF-IDF方法计算读者喜欢图书ui标签tj的权重,即
(5)
式中,n0为图书检索中标签tj的读者数量.
假设两本图书分类号为A和B,则读者兴趣偏好关联度可表示为
(6)
该因子为一个非负实数,在等于1的时候,表示两个变量相互独立.读者兴趣偏好支持度域值可以较好地去掉那些负相关及不相关的读者信息,因此,如果读者兴趣偏好的度量中含有支持度,则可以更为准确地定义一个读者信息兴趣偏好程度.读者兴趣偏好表达式为
(7)
IS(A1,A2,…,Ak⟹Ak+1,Ak+2,…,An)=
(8)
式(7)与(8)仅适合于比较由同一个项集所产生的读者兴趣偏好度.支持度域值可以用于裁剪那些负相关或不相关的读者兴趣偏好信息,而读者兴趣的信任度则说明了该偏好度的统计重要性,因此一个较为理想的判别模型应该同时体现这两者的作用.假设r、r′分别为原始读者兴趣偏好及待比较读者兴趣偏好,则图书对于读者的兴趣偏好度可表示为
(9)
式中:c、c′、s、s′分别为原始读者与待比较读者对图书的支持度和信任度;w1、w2为分配权值,w1+w2=1.由式(9)可知,如果一个读者的兴趣偏好Ics值大于1,则说明该图书更受读者喜欢,且该值越大,表明兴趣偏好程度越高.
2 信息检索扩展与挖掘模型建立
在对图书信息检索中读者兴趣偏好进行度量的基础上,采用数据聚类分析法建立图书信息检索中读者兴趣偏好挖掘模型.
2.1 读者兴趣图书检索扩展
采用相关反馈模型Rocchio算法,根据相关图书和不相关图书进行修正检索,检索量表达式为
(10)
式中:qm为修正的检索量;q0为初始检索量;α、β、γ为调整参数,取值为1;Dr为相关图书检索深度集合;Dnr为不相关图书检索深度集合;dj为检索深度.检索扩展词在与检索相关的类别图书中进行特征提取,然后计算检索与该类特征词的相似度,相似度高的加入检索扩展词库.该检索扩展的特点是相关图书类别是通过模型系统计算得出的,不需要读者判别,减轻检索负担,提高读者兴趣偏好的挖掘效果.
但是一些相关度小的图书信息的加入对系统来讲是噪声信息,有研究学者提出了扩展噪声对查询性能的影响,当扩展查询达到25个时,检索精度下降,所以本文加入20个扩展词进行读者兴趣偏好挖掘.
2.2 读者兴趣偏好挖掘模型建立
在对图书检索进行扩展的基础上,采用聚类分析法建立读者兴趣偏好挖掘模型,详细步骤如下:
1) 建立读者注册信息向量.读者注册信息包括姓名、年龄、性别、身份证号,此时可用一个集合(姓名、年龄、性别、身份证号)表示读者基本信息,转换为表达式形式为Y=(y1,y2,y3,y4).
2) 基于K-MEANS算法的读者信息聚类.针对读者的基本信息,采用K-MEANS算法将读者信息聚类为K类稳定信息集合.假设数据点的集合P=(Y1,Y2,…,Ym),其中Yi=(yi1,yi2,yi3,yi4),i=1,2,…,m.把数据点集合划分为K个分组,即G1,G2,…,GK.
3) 聚类获取读者的兴趣偏好.利用步骤2)的K-MEANS算法把读者信息样本聚为K类,每类兴趣采用集合<类别,关键字,权值>的形式来表示,以此表达每一类读者的总体特征,进而得出K类读者的共同偏好,即
NL={〈e1,f1,w11〉,〈e2,f2,w22〉,〈e2,f3,w23〉,
…,〈e2,fg,w2g〉,…,〈ei,fj,wij〉}
(11)
式中:g、j为聚类获取的每一类读者偏好的关键字个数;i=1,2,…,K为偏好类别.
4) 构建读者兴趣偏好挖掘模型.读者兴趣偏好受到短期检索图书兴趣和长期检索图书兴趣两方面的影响,因此读者的兴趣偏好可表示为
H={M,N}
(12)
式中:M为短期检索图书兴趣;N为长期检索图书兴趣.由于读者兴趣的多样性,可将M和N分别表示为
(13)
为了更详细地区分读者兴趣程度,兴趣向量应该蕴涵大量的资源信息.针对每一个Oi、Lj(i=1,2,…,m;j=1,2,…,n)来说,应引进类别属性变量Ei、Ej与权重属性变量Fi、Fj,则Oi、Lj可进一步表示为
Oi=〈Oi,Fi,Ei〉 (i=1,2,…,m)
(14)
Lj=〈Lj,Fj,Ej〉 (j=1,2,…,n)
(15)
则读者兴趣偏好挖掘模型可以表示为
(16)
式中:Om、Ln分别为短期检索图书兴趣与长期检索图书兴趣的某个属性值;Em+n为读者兴趣对应的图书属性类别;Fm+n为属性值的兴趣权重,表示读者对某类图书的感兴趣程度.至此实现了图书信息检索中读者兴趣偏好挖掘模型的建立.
3 实验结果与分析
为了验证改进模型在偏好挖掘中的效果,实验数据采用了某学校图书馆数据库的汽车、IT、体育、旅游、教育及军事等6类文本,每类3 000本图书,总计18 000本,其中12 000本用来训练,6 000本用来测试.读者搜索历史表示检索和浏览相关图书,假设读者平均每天检索6本,并跟踪了30天的搜索历史记录.通过读者兴趣偏好模型挖掘读者兴趣,构建读者文档和检索特征矩阵、图书和类别特征矩阵、检索和类别特征矩阵,最后对读者兴趣度进行排序,类别兴趣度越高,读者对该类图书越感兴趣.
为了验证改进模型的查准率,将改进模型与文献[6]、文献[7]模型进行了查准率方面的对比,对比结果如图1所示.
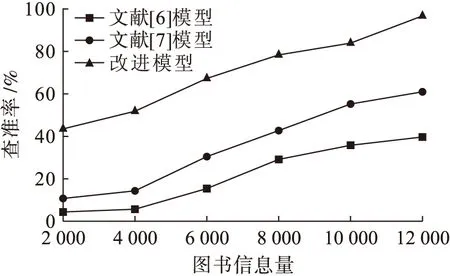
图1 不同模型下的查准率对比Fig.1 Comparison in precision ratio with different models
由图1可知,图书信息量为10 000时,采用文献[6]模型查准率约为35.4%,随着图书信息量的增加,读者兴趣偏好查准率也随之增加;文献[7]模型查准率约为55.1%,相比文献[6]模型查准率提高了约19.7%;采用改进模型时,其查准率约为80.2%,且随着图书信息量的增加,读者兴趣偏好查准率也随之增加,最高时达到了97.6%,相比文献[6]与[7]模型的查准率分别提高了44.8%和25.1%,在查准率方面具备一定的优势.
图2为3种模型在不同兴趣偏好数据条件下挖掘时间的对比示意图.由图2可知,文献[6]模型平均挖掘时间约为5.4 s,且随着读者兴趣偏好数据量的增加,读者兴趣偏好挖掘时间也随之降低;文献[7]模型平均挖掘时间约为6.8 s,相比文献[6]模型的挖掘时间增加了约1.4 s;采用改进模型时,其平均挖掘时间约为3.8 s,且随着读者兴趣偏好数据量的增加,读者兴趣偏好挖掘时间也随之降低,最低时达到了2 s.
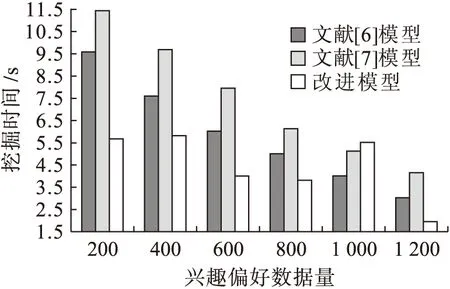
图2 不同模型下挖掘时间对比Fig.2 Comparison in mining time with different models
图3为3种模型在不同兴趣偏好数据条件下挖掘准确率的对比示意图.由图3可以看出,采用文献[6]模型时,准确率随着兴趣偏好数量的增加出现先增加后降低的情况,数据量在1 000之后降到最低;采用文献[7]模型时,出现了建模准确率不稳定的情况;而采用改进模型时,其建模准确率大大提高,且准确率随着数据量的增加而增加.
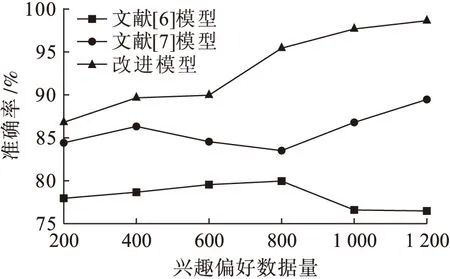
图3 不同建模方法的准确率对比Fig.3 Comparison in accuracy for different modeling methods
4 结 论
针对传统挖掘模型对图书信息检索中读者兴趣偏好数据挖掘时存在的挖掘效率低、耗时长的问题,提出基于聚类分析的读者兴趣偏好挖掘模型建立方法.在对读者兴趣偏好进行度量时,首先需要计算图书相似度与读者兴趣的距离,并以此为基础采用相关反馈模型Rocchio算法,根据相关图书和不相关图书进行修正检索,对读者兴趣图书检索进行扩展,构建读者兴趣偏好挖掘模型.实验结果表明,采用改进模型时,查准率较高,挖掘时间更短且误差较小.
[1]王晓艳,林昌意.基于查询意图的中文信息类网页分类研究 [J].图书情报工作,2015,59(1):113-118.
(WANG Xiao-yan,LIN Chang-yi.Research on Chinese informational webpage classification based on query intention [J].Library and Information Service,2015,59(1):113-118.)
[2]王元卓,贾岩涛,刘大伟,等.基于开放网络知识的信息检索与数据挖掘 [J].计算机研究与发展,2015,52(2):456-474.
(WANG Yuan-zhuo,JIA Yan-tao,LIU Da-wei,et al.Open web knowledge aided information search and data mining [J].Journal of Computer Research and Development,2015,52(2):456-474.)
[3]谭亮,陈燕,楚存坤.基于研究性学习的信息检索课教学效果实证研究 [J].大学图书馆学报,2014,32(2):72-75.
(TAN Liang,CHEN Yan,CHU Cun-kun.Information retrieval course’s problem-based learning practice research [J].Journal of Academic Libraries,2014,32(2):72-75.)
[4]李亚琴,孙建军,杨月全,等.基于信息检索用户的相关性行为研究进展 [J].情报科学,2014,32(5):157-160.
(LI Ya-qin,SUN Jian-jun,YANG Yue-quan,et al.A study of the information retrieval user-oriented beha-vior of relevance [J].Information Science,2014,32(5):157-160.)
[5]卜质琼,郑波尽.基于 LDA 模型的 Ad hoc 信息检索方法研究 [J].计算机应用研究,2015,32(5):1369-1372.
(BU Zhi-qiong,ZHENG Bo-jin.Ad hoc information retrieval method based on LDA [J].Application Research of Computers,2015,32(5):1369-1372.)
[6]王琰.一种多层安全相关属性标定偏好数据挖掘模型 [J].科技通报,2015,31(12):176-178.
(WANG Yan.A multi-layer safety related attribute cali-bration preference data mining model [J].Bulletin of Science and Technology,2015,31(12):176-178.)
[7]吕佳,陈东生.基于聚类算法的服装感性数据挖掘方法 [J].纺织学报,2014,35(5):108-112.
(LÜ Jia,CHEN Dong-sheng.Fashion perceptual data mining based on clustering algorithm [J].Journal of Textile Research,2014,35(5):108-112.)
[8]单冬红,史玉珍.数据挖掘技术在互联网信息检索中的应用研究 [J].科技通报,2014,30(3):161-164.
(SHAN Dong-hong,SHI Yu-zhen.Application research of data mining technology in the internet information retrieval [J].Bulletin of Science and Technology,2014,30(3):161-164.)
[9]Sotudeh H,Mazarei Z,Mirzabeigi M.Bookmarks are correlated to citations at journal and author levels in library and information science [J].Scientometrics,2015,105(3):2237-2248.
(责任编辑:景 勇 英文审校:尹淑英)
Establishment and simulation of mining model for interest preference of readers in book information retrieval
FENG Jing1,ZHANG Fu-quan2
(1.Library,Xinjiang Normal University,Urumqi 830054,China;2.School of Software,Beijing Institute of Technology,Beijing 100081,China)
Aiming at the problem that such detects as low mining efficiency and large error always exist when the traditional mining model is used to mine the interest preference data of readers in the book information retrieval,a mining model for the interest preference of readers was proposed.The distance between the book similarity and reader interest was calculated with the classification index distribution tree method.In addition,the interest preference level was measured through interest factor.On this basis,the interest book retrieval for readers was extended with the relevance feedback model Rocchio algorithm,and the mining model for interest preference of readers in the book information retrieval was established with the clustering analysis method.The results show that the mining efficiency,time and error of the improved model are superior to those of the traditional models.
book information;retrieval;interest preference of readers;mining model;interest factor;interest in distance;book similarity;extension
2016-09-26.
国家教育部博士点基金项目(20121101110037).
冯 静(1978-),女,山东临清人,讲师,硕士,主要从事图书信息检索、图像情报及计算机仿真等方面的研究.
02 17∶28在中国知网优先数字出版.
http:∥www.cnki.net/kcms/detail/21.1189.T.20170302.1728.012.html
10.7688/j.issn.1000-1646.2017.02.13
TP 250.7
A
1000-1646(2017)02-0188-05
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
现代电子技术(2017年23期)2017-12-20 13:23:31
电力与能源(2017年6期)2017-05-14 06:19:37
计算机应用(2016年10期)2017-05-12 11:02:20
新闻传播(2016年18期)2016-07-19 10:12:06
现代计算机(2016年11期)2016-02-28 18:35:15
信息通信技术(2015年6期)2015-12-26 01:16:46
河南科技(2014年11期)2014-02-27 14:10:19
电子设计工程(2014年18期)2014-02-27 12:00:13
计算机光盘软件与应用(2013年6期)2013-08-08 08:26:50
