
基于证据理论组合多分类规则实现大区域植被遥感分类研究*
2017-04-19 08:14:46鞠洪波
林业科学研究 2017年2期
胡 博,鞠洪波,刘 华,郝 泷,刘 海
(中国林业科学研究院资源信息研究所,北京 100091)
基于证据理论组合多分类规则实现大区域植被遥感分类研究*
胡 博,鞠洪波**,刘 华,郝 泷,刘 海
(中国林业科学研究院资源信息研究所,北京 100091)

遥感;大区域;证据理论;植被分类
利用遥感技术对森林、湿地、荒漠等进行调查监测[1-5],提供科学有效的数据支撑具有重要的研究意义。我国的森林资源不仅分布辽阔,还时时处于变化中,利用遥感数据时效性和宏观性的特点,科学、快速、准确地提取大区域植被类型及其变化规律信息是森林资源现代化管理的主要内容之一。
面向国家级或省级的大区域植被遥感分类大多基于中低分辨率遥感影像的像元特征,随着分类研究的发展,研究人员发现单分类算法存在不同程度的错分和误分现象,但不同分类器错分和误分的像素并不集中也没有统一规律,说明不同的分类器之间的性能存在差异。也就是说,分类器间存在互补性,某一分类算法错分或误分的样本在另一分类器中存在正确识别的可能,基于这一发现产生了多分类器组合分类思想[6-9],多分类器组合的新分类方法也得到越来越广泛的实验验证和应用。
证据理论是以A. P. Dempster的研究工作为基础发展起来的,Dempster的研究是用概率范围去模拟事件发生的不确定性,G.Shafer将证据理论推广研究应用于处理不确定性信息,因此证据理论也称为D-S理论。证据理论的主要特征包括:(1)发展了Bayes概率理论,具有表达不确定信息的能力,相比Bayes概率理论,证据理论的先验数据更容易获取,具有灵活性。(2)证据理论是一种可以综合多源信息的融合方法[10-13]。证据理论的合成规则,可以对不同来源的专家知识进行很好的融合,并且对数据格式的限制较低。因此,采用证据理论进行多分类器组合,将不同分类规则得到的同一区域的不同分类结果优势信息进行融合,可以得到一个精度更高的综合分类结果。
本研究基于证据理论原理实现大区域植被遥感分类。已有证据理论分类的研究,大多将多光谱波段作为融合的证据源,或者对多种专题数据进行信息融合,而多光谱遥感数据较难避免云和阴影的影响,专题数据存在时效性不统一的问题。实验数据选取16天合成一期的2001年23期NDVI时序数据,减少云影噪声影响的同时能够反映植被完整的物候周期信息。通过IDL程序将多分类规则处理得到的植被类型特征信息归一化处理为基本概率赋值作为证据源数据,依据证据理论实现多源信息综合,将组合结果依据最大信任度原则确定植被类型。另外,为了避免不同证据源低信任值相近可能导致的“Zadeh”悖论问题,设置了超集假设参与组合。实验过程中尽量减少人为干预,依靠分类算法挖掘实验数据的时间空间特征,实现了大区域植被类型信息客观、快速、高效地提取。
1 实验区域与实验数据
1.1 实验区域概况
本研究选取寒温带针叶林区域作为实验区,该区域位于127°20′ E以西,49°20′ N以北的大兴安岭北部及其支脉伊勒呼里山地,总面积约为211 600 km2。
该区域植被覆盖率高,地带性植被以兴安落叶松(Larixgmelini(Rupr.) Rupr.)林为主,其间有少量灌木分布,是我国重要的木材产地。由于研究区属于寒温带气候,分布着大量的永久冻土层,水分下渗困难,形成零星水体,地表积水使湿地广泛发育,其中草本沼泽分布在海拔900 m以下地带,海拔300 m以下有森林草原带分布。该区域平坦谷地区域有农业分布但农业不发达[14]。
1.2 实验数据
本实验参考2001年1:100万中国植被图矢量数据中寒温带针叶林区域的植被分布信息以及2000年中国土地覆盖1 km栅格数据(简称WESTDC)中实验区域的非植被分布信息[15-16]。
根据实验区域宏观大范围特点,选取空间分辨率250 m的MODIS影像作为实验数据。为降低云、影的影响,选择MODIS的L3级科学数据集中陆地专题产品MODIS13Q1中的归一化植被指数(NDVI)时序数据文件[17],该产品每期间隔为16天。减少云影影响的同时,利用2001年23期NDVI影像数据体现的各类植被的生长物候周期信息,参考已有资料数据实现该区域植被遥感分类。
以上矢量、栅格数据均具有空间坐标信息,且进行过影像配准,精度限制在一个像元内。
2 研究方法
组合多分类规则的证据理论大区域植被遥感分类总体思路,如图1所示。

图1 D-S理论多分类器组合分类技术路线Fig.1 Methodological framework of classifier combined by multiple classifiers with D-S theory
2.1 分类系统设计和样本快速采集
2.1.1 辨识框架和分类系统设计 寒温带针叶林区域的植被类型包括乔木、灌木、草地、湿地、农田。同时,该区域内还存在零星水体和建筑等非植被地类,非植被地类参考WESTDC中实验区的水体和建筑分布掩膜,不参与分类。
本实验参考证据理论中辨识框架的概念设计分类系统。假定辨识框架中包括3个基本假设:{A, B, C},辨识框架的假设结构将接受包括所有假设组合的证据,即[A]、[B]、[C]、[A,B]、[A,C]、[B,C]、[A,B,C]。前3个假设每个假设包括1个基本要素,称为单体假设。其余为非单体假设。含有辨识框架中全部基本要素的非单体假设,称为超集,如{A, B, C}的超集为假设[A,B,C]。
本实验辨识框架设计为Ω={乔木,灌木,草地,湿地,农田},可能出现的假设为32个,包括空集(Φ)和超集(θ)。由于遥感影像像素值唯一且认为每一像素唯一对应一类,因此不考虑非单体假设,仅保留[乔木]、[灌木]、[草地]、[湿地]、[农田]假设,即分类系统中的植被类型。
2.1.2 大区域植被样本快速采集 本实验参考1:100万植被图、WESTDC中国土地覆盖图,结合实验区域2001年MODIS时序NDVI影像的非监督分类结果,利用矢、栅数据的空间特征,将实验影像非监督分类的类型信息关联为随机样点属性,依据该属性中包含的非监督分类类型数和各类型的样点比例,对比类别间样本可分离性指标、标准差变化,实现样本纯化。经实验验证,纯化后的植被样本与WESTDC中植被空间分布基本一致,主要植被类型空间分布精确程度为84.82%,该采样方法适用于宏观大区域植被遥感监督分类。
中国植被图表明实验区植被覆盖以乔木、草地和湿地为主。植被覆盖率为乔木67.40%、草地18.04%和湿地12.48%。灌木0.97%,农田1.08%两类植被在实验区域较少分布。依据快速采样方法得到的各类样本中样点数为乔木3 489个,草地409个,湿地212个,灌木31个,农田31个。
2.2 证据理论组合多分类规则
2.2.1 多证据源的基本概率赋值 基本概率赋值(BPA),也称作概率分配函数。表示证据对假设组合的支持,并不表示其子集的概率。通常用字母“m”来表示。
定义1:设函数m:2Ω->[0,1],且满足
存在2Ω上的基本概率赋值m,m(A)表示当前环境下辨识框架中元素A的精确信任程度,m(A)称为A的基本概率赋值,也称作概率分配函数。基本概率赋值不是概率,m是2Ω上而非Ω上的基本概率。辨识框架中各元素基本概率赋值的和为1。对于给定假设的BPA值可以通过主观判断或经验数据来得到。
将实验数据与快速采样得到的植被样本,通过最小距离非参数分类规则、最大似然参数分类规则和利用植被时序特征的波谱角分类3个分类规则计算,得到3个规则下的植被类型特征数据,共15幅影像。
依据归一化公式通过IDL程序读取各规则的植被类型特征影像,实现归一化处理[18]得到三个证据源的植被类型的概率赋值信息(mBpa),表达不同证据源信息对各植被类型的支持程度。
其中,i为植被类型,m为基本概率赋值,X为分类规则,Xi为各分类规则得到某一植被类型的特征值。
2.2.2 证据理论组合多证据源数据 对于相同的事件,证据源的不同会得到不同的基本概率赋值,不同证据源的基本概率赋值可以通过正交规则进行合并。合并规则是证据理论的核心,概括为公式表达:
设m1和m2是两个不同的基本概率赋值,则其正交和m=m1⊕m2满足
其中,K=1-∑x∩y=Φm1(x)×m2(y)或者K=∑x∩y≠Φm1(x)×m2(y)
如果K≠0,则正交和m也是一个基本概率赋值;如果K=0,则不存在正交和m,称m1与m2矛盾。
证据理论组合不同证据源数据过程中,考虑不同证据源低信任值相近可能导致“Zadeh悖论”现象产生,因此,通过在证据源中设置超集假设,即超集θ=[乔木,灌木,草地,湿地,农田]的值来避免影响。本研究中超集的基本概率赋值设置为最大的植被特征像元BPA的0.01,最大的植被特征像元BPA为原值的0.99。
将最大似然、最小距离和时序SAM分类规则得到的类型特征影像归一化为基本概率赋值,作为证据源数据。多证据源数据依据证据理论的正交合并规则进行组合,得到多证据源下各类型的组合BPA。
依据证据理论中信任函数定义,可以得到各类型的信任函数数据。通过最大信任度原则(CBV),将信任值最大的类型,作为该像素可能体现的类型信息。即CBVk=max{Belief(Xi)},像素对应的植被类型为k。
3 结果与分析
3.1 证据累积过程分析
本实验辨识框架为{乔木、灌木、草地、湿地、农田},超集假设Θ=[乔木、灌木、草地、湿地、农田]。以影像行列定位为(1000,1000)的像素P的类型确定过程为例。
实验区域时序NDVI影像结合快速采集的样本数据,通过最小距离、最大似然和时序SAM规则生成的类型特征影像,经过归一化处理得到多证据源的基本概率赋值。P点处的3个证据源的基本概率赋值,如表1所示:
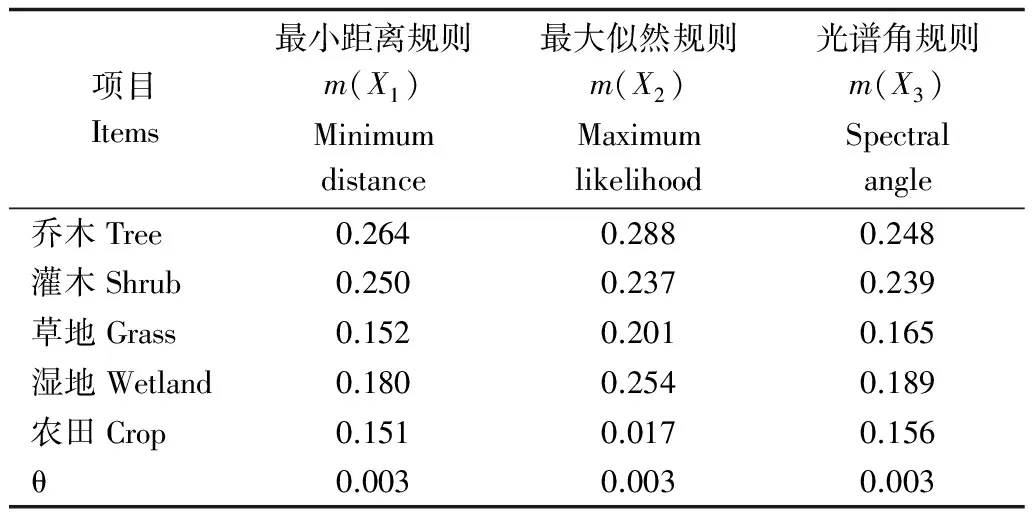
表1 3个证据源基本概率赋值
将归一化处理得到的三组证据源数据,依据证据理论合并原理进行两两规则证据源组合和3个规则证据源的组合。P点处的组合证据源的基本概率赋值,如表2所示:
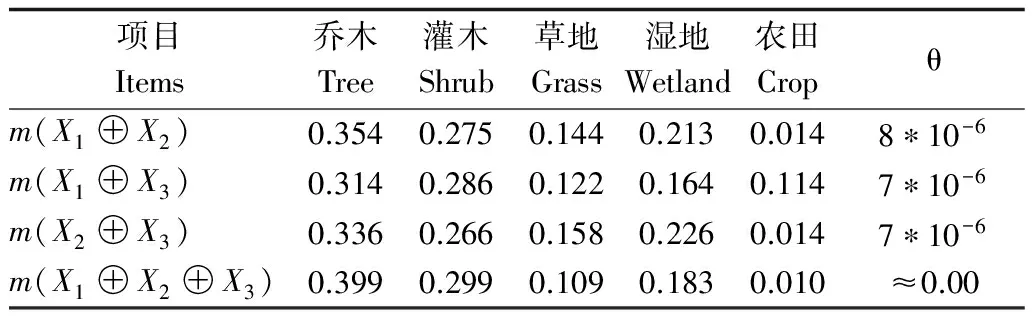
表2 证据理论组合分类器像素值
依据信任函数原理,单一元素假设的信任函数即为该元素的基本概率赋值。因此,实验中各类型的信任函数值与各类型的基本概率赋值相等,即Belief(i)=mBpa(i),其中i为对应的类型。
最后,由最大信任度原则确定实验影像中P点处乔木类的基本概率赋值最大,因此P为乔木类。
表2中组合证据源的基本概率赋值表明,P点处乔木和灌木分别是第一优势类和第二优势类。两两规则证据源组合的mBpa(乔木)与mBpa(灌木)的差值分别为0.079、0.048、0.07,3个规则证据源组合的mBpa(乔木)与mBpa(灌木)的差值为0.1,差值增大。乔木类型特征随着合成次数的增加而增大,与非乔木类型的特征差异更为显著。
因此,通过证据理论合成规则,合成证据源越多合成次数越多,优势类的基本概率赋值与其他类的差值越大,类型特征优势越明显。
3.2 分类结果精度评价与分析
在实验区域随机布设2 000个样点,将中国植被图与WESTDC土地覆盖图中同一类型重叠的区域视为真实地类分布,落于真实地类分布区域内的样点作为实验的验证样本。
单分类器得到的分类结果的生产精度、用户精度和总体精度,以及3个单分类器的各平均精度,如表3所示:
两两规则组合分类得到的分类结果的生产精度、用户精度和总体精度,以及组合分类器的各平均精度,如表4所示:

表3 单分类器分类结果精度分析

表4 两两组合分类器分类结果精度分析
表3中最大似然分类器的精度最高,总精度为69.88%,最小距离分类器次之,总精度为66.60%,时序SAM分类器的总精度最小为62.77%,单分类器的平均总精度为66.42%。
表4中最大似然与最小距离规则组合的分类结果精度最高,其总精度为78.14%,时序SAM与最小距离规则组合的分类结果精度最低,其总精度为72.56%,两两规则组合分类结果的平均总精度为75.63%,大于单分类器的平均总精度。对比单分类规则和两两规则组合分类结果中各类植被的平均生产精度和平均用户精度,两两规则组合分类结果的各平均精度都有提高。
可见证据理论组合分类规则的方法对分类总精度、各类型生产精度和用户精度均有不同程度的提高;并且参与组合的单分类规则精度越高,越能有效提高组合分类的精度。
生产精度、用户精度和总体精度与单分类器、两两规则组合分类器的平均精度对比分析,如表5所示:

表5 分类结果精度分析
表5中单分类器分类结果的平均总精度为66.42%,两两规则组合分类结果的平均总精度为75.63%,3个规则组合分类结果的总精度最高为80.84%。对比单分类规则、两两规则组合、3个规则组合分类结果中各类植被的平均生产精度和平均用户精度,3个规则组合分类结果的各精度最高。因此,证据理论可以实现多分类算法的组合,并且证据源越多,越能提高分类精度。
4 结论
(1)本研究针对大区域植被遥感分类,基于证据理论组合多分类规则实现了寒温带针叶林区域的植被遥感分类研究。比较分析了组合分类器与单分类器的分类精度,认为证据理论组合分类算法相比单分类算法,实现了分类总精度、各类型生产精度和用户精度的提高。
(2)实验表明基于证据理论实现多分类规则组合的过程中,参与组合的证据源越多,分类结果的可信程度越高,分类结果的精度越高;参与组合的证据源对实验区描述越准确,对分类结果精度的提高越显著。因此,开展更多单分类算法的比较研究,探索更适合参与组合的单分类算法,以实现更好的分类效果作为进一步的研究内容。
(3)本研究利用多种单分类算法挖掘时序数据信息,通过证据理论对来自于不同分类规则的证据源信息进行融合,综合了多分类算法的优势特征。相比多光谱数据的合成分类,减少云影影响的同时结合了植被物候信息;相比专题资料数据的合成结果,能够更客观的体现遥感影像的时间空间特点,更好的反映实验区域植被分布的时效性信息。该方法人为干预较少,能够快速、高效地实现大区域植被类型信息的提取。
[1] Darren Pouliot, RasimLatifovic, Natalie Zabcic,etal.Development and assessement of a 250 m spatial resolution MODIS annual land cover time series(2000-2011) for the forest region of Canada derived from change-based updating [J]. Remote Sensing of Environment,2014,140:731-743.
[2] 陈 巧,陈永富,鞠洪波.基于3S技术的天保区植被变化监测方法研究[J]. 林业科学研究,2013,26(6):736-743.
[3] 刘 华, 鞠洪波, 邹文涛,等.长江源典型区湿地对区域气候变化的响应[J].林业科学研究, 2013,26(4):406-413.
[4] 姚爱东,车腾腾,姜丽娜,等.甘肃民勤县荒漠化区未利用地的遥感分类研究[J]. 林业科学研究,2014,27(2):195-200
[5] 刘 华,陈永富,鞠洪波,等.美国森林资源监测技术对我过森林资源一体化监测体系建设的启示[J].世界林业研究, 2012,25(6):64-68.
[6] Doan H T, Foody G M.Increaseing soft classification accuracy through the use of an ensamble of classifiers[J].International Journal of Remote Sensing,2007,28(20):4606-4623.
[7] 柏延臣,王劲峰.结合多分类器的遥感数据专题分类方法研究[J].遥感学报,2005,9(5):555-563.
[8] 夏俊士,杜培军,张 伟.遥感影像多分类器集成的关键技术与系统实现[J].科技导报,2011,29(25):22-26
[9] 张智超,范文义,孙舒婷.基于多种分类器组合的森林类型信息提取技术研究[J].森林工程, 2015,31(3):75-80.
[10] Koki I, Kenlo N, Tsuguki K,etal. Creation of new globalland cover map with map integration[J]. Journal of Geographic Information System,2011,03(3):160-165.
[11] Hoyosa A P, García-Haroa F J, San-Miguel-Ayanz J. Amethodology to generate a synergetic land-cover map byfusion of different land-cover products[J]. International Journal of Applied Earth Observation and Geoinformation, 2012,19(10): 72-87.
[12] 陈 博.遥感图像融合及应用研究[M].北京:中国科学技术大学, 2009.
[13] 王 欣.多传感器数据融合问题的研究[D].吉林:吉林大学,2006.
[14] 韩 杰,温瑞勇,迟占颖.浅谈大小兴安岭森林植被分布[J].内蒙古科技与经济,2004,(16):111-113.
[15] 李俊祥,达良俊,王玉洁,等.基于NOAA-AVHRR数据的中国东部地区植被遥感分类研究[J].植物生态学报,2005,29(3):436-443.
[16] 冉有华,李 新,卢 玲.基于多源数据融合方法的中国1km土地覆盖分类制图[J].地球科学进展,2009,24(2):192-203.
[17] 廖 靖,覃先林,周汝良.利用2种植被指数监测中国6种典型森林生长期的比较研究[J].西南林业大学学报,2014,34(3):57-61.
[18] 李华朋,张树清,孙 妍,等.集成多时相ETM+影像的证据推理湿地遥感分类[J].吉林大学学报:地球科学版, 2011,41(4):1246-1252.
(责任编辑:彭南轩)
Combining Multiple Classifiers Based on Evidence Theory for Large Scale Vegetation Types Classification by Remote Sensing Images
HUBo,JUHong-bo,LIUHua,HAOShuang,LIUHai
(Research Institute of Forestry Resource Information Techniques, Chinese Academy of Forestry, Beijing 100091, China)

remote sensing; large area; evidence theory; vegetation classification
2016-05-20 基金项目: 国家863计划课题(2012AA102001)。 作者简介: 胡 博(1985—),女,河北人,博士研究生,主要从事森林资源监测技术研究. * 感谢国家自然科学基金委员会“中国西部环境与生态科学数据中心”提供WESTDC数据。 ** 通讯作者:鞠洪波(1956—),男,黑龙江人,研究员,博士生导师,林业信息技术.
10.13275/j.cnki.lykxyj.2017.02.002
S771.8
A
1001-1498(2017)02-0194-06
猜你喜欢
四川大学学报(自然科学版)(2023年1期)2023-04-29 00:44:03
河北地质(2022年2期)2022-08-22 06:24:04
榆林学院学报(2022年4期)2022-08-02 14:30:42
计算机与生活(2018年8期)2018-08-15 08:24:34
电子测试(2018年1期)2018-04-18 11:52:35
现代园艺(2017年23期)2018-01-18 06:58:12
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
理科考试研究·高中(2016年9期)2016-05-14 00:12:18
应用海洋学学报(2015年2期)2015-11-22 07:36:28
