
沙棘WRI1转录因子基因的生物信息学分析
2017-04-12 23:38马倩李景滨阮成江李荣荣
湖北农业科学 2016年22期
马倩++李景滨++阮成江++李荣荣

摘要:以构建的沙棘(Hippophae rhamnoides Linn.)不同组织转录组数据库为基础,分离得到1个沙棘WRI1转录因子编码基因,命名为HrWRI1,利用生物信息学方法对其基因结构、理化性质、保守域、信号肽、亚细胞定位、磷酸化位点和高级结构等进行了预测和较为全面的分析。结果表明,该成员含有1 206 bp的完整开放阅读框,编码401个氨基酸组成的不稳定亲水蛋白,无信号肽和跨膜结构域,存在多个磷酸化位点,定位于细胞核中,高级结构以无规则卷曲为主。与不同植物中已报道的同源WRI1转录因子进行多重序列比对后,发现它们在核酸与氨基酸水平均高度同源,并且具有相同的结构域。
关键词:沙棘(Hippophae rhamnoides Linn.);WRI1基因;生物信息学
中图分类号:Q943.2 文献标识码:A 文章编号:0439-8114(2016)22-5972-04
DOI:10.14088/j.cnki.issn0439-8114.2016.22.061
Bioinformatics Analysis of WRI1 Gene in Hippophae rhamnoides
MA Qian,LI Jing-bin,RUAN Cheng-jiang,LI Rong-rong
(Resources and Plant Research Institute/College of Environment and Resources,Dalian Nationalities University,Dalian 116600,Liaoning,China)
Abstract: In the present study,a HrWRI1 gene firstly based on the transcriptome sequencing data from H. rhamnoides was obtained. Then,cDNA and deduced amino acid sequence, physical and chemical characterization,conserved domain,signal peptide,subcellular localization,phosphorylation site molecular modeling were predicted and analyzed. It follows that this predicted cDNA has an open reading frame of 1 206 bp in length,encoding protein of 401 amino acids. It was hydrophilic proteins,no transmembrane regions and signal peptide,contain multiple phosphorylation sites. A subcellular localization analysis predicted that they may exist in the nucleus. In addition,the secondary structure is mainly based on random coil. In comparison to the other known WRI1 from various species,the overall sequence alignment suggested that they were highly similar at the protein level,especially conserved domain. Our investigation could definitely provide a significant foundation for further research on function analysis of HrWRI1.
Key words: Hippophae rhamnoides Linn.; WRI1 gene; bioinformatics
沙棘屬(Hippophae)系林奈于1753年以沙棘(Hippophae rhamnoides Linn.)为模式建立的。沙棘又名醋柳、酸刺等,为胡颓子科沙棘属落叶灌木或小乔木,是一种新兴的小浆果类树种[1,2]。近年来,植物油脂的需求量越来越多,利用基因工程技术提高油料作物中植物油的含量已经成为最有发展前景的方法之一,培育高含油量的沙棘品种已成为沙棘研究的主攻方向之一[3]。WRINKLED1(WRI1)是第一次在模式植物拟南芥(Arabidopsis thaliana)中发现的1个AP2/EREBP类转录因子,WRI1基因编码蛋白含有两个AP2/EREBP结构域,AP2/EREBP家族转录因子是植物特有的一类转录因子,含有由60~70个氨基酸组成的AP2/ERF结构域,其在控制种子的蔗糖到油的积累过程中起关键作用[4]。研究发现过量表达WRI1基因则提高种子和幼苗中三酯酰甘油,而降低了WRI1基因的表达量致使发育中的种子将蔗糖转化为三酯酰甘油的过程受阻,破坏了糖酵解过程,因而降低了种子的含油量[2]。
本研究以HrWRI1基因序列为目的基因,利用生物信息学方法以及相关软件分析预测该基因编码的蛋白理化性质、结构、功能,为今后开发和利用奠定基础[5]。
1 生物信息学分析
1.1 编码氨基酸的一级结构及理化性质分析
利用在线工具ProtParam程序(http://web.expasy.org/protparam/)分析HrWRI1基因所编码氨基酸的组成以及其基本的理化性质。
1.2 氨基酸保守结构域分析
利用NCBI数据库中的BLASTP(http://blast.ncbi.nlm.nih.gov/),进行保守结构域的分析预测。
1.3 编码氨基酸的亲水性/疏水性以及跨膜结构分析[6]
对该基因编码的氨基酸序列的亲水性/疏水性预测利用ProtScale程序(http://web.expasy.org/cgi-bin/protscale/protscale.pl),蛋白跨膜结构分析的预测应用TMHMM程序(http://www.cbs.dtu.dk/services/TMHMM-2.0/)。
1.4 编码蛋白的亚细胞定位、核定位信号及信号肽分析[6]
使用ProtComp v.9.0 Predict the sub-cellular localization for Plant proteins(http://linux1.softberry.com/berry.phtml)对该蛋白进行亚细胞定位预测。对编码蛋白的核定位信号利用NLS mapper program(http://nls-mapper.iab.keio.ac.jp)。利用在线工具SignalP程序(http;//www.cbs.dtu.dk/services/SignalP/)对该蛋白序列进行信号肽预测。
1.5 磷酸化位点分析
利用在线工具NetPhos2.0 Serve(http://www.cbs.dtu.dk/services/NetPhos/)对序列进行潜在磷酸化位点预测分析。
1.6 HrWRI1基因的功能预测
利用ProtFun 2.2 Server程序(http://www.cbs.dtu.dk/services/ProtFun/),对HrWRI1基因进行功能的分析预测[5]。
1.7 编码蛋白的二级结构和三级结构预测分析
蛋白质二级结构分析利用HNN Methods(https://npsa-prabi.ibcp.fr);蛋白质的三维结构利用ExPASy服务器的SWISS-MODEL工具进行预测(http://swissmodel.expasy.org/),通过Discovery studio viewerpro软件进行查看[7]。
1.8 蛋白序列比对及进化树分析
首先通过NCBI数据库中的Blastp对HrWRI1基因编码的氨基酸进行同源性分析。利用ClustalX、BioEdit、GeneDOC和MEGA 4软件进行多重序列比对并构建系统进化树。
2 结果与分析
2.1 开放阅读框的获取及编码的氨基酸分析
在沙棘轉录组数据库中获得一个全长为1 251 bp的cDNA序列,通过BioXM 2.6软件分析得到一个全长为1 206 bp的开放阅读框,编码401个氨基酸,如图1所示。
2.2 保守结构域的分析
通过NCBI中BLASTP分析开放阅读框所编码的氨基酸序列的保守结构域。结果(图2)表明,所编码的氨基酸序列中共包含两个保守结构域,属于AP2/EREBP家族,该序列可能是AP2/EREBP类转录因子家族中的一员。
2.3 HrWRI1蛋白的理化性质分析
通过ProtParam程序对HrWRI1蛋白的理化性质进行了分析,HrWRI1分子式为C1958H3038N562O661S9,分子质量为45.315 5 ku,理论等电点为5.35,为酸性蛋白;该蛋白含Ser最多,占12.0%;总的带正电残基精氨酸(Arg)+赖氨酸(Lys)为46,负电残基天冬氨酸(Asp)+谷氨酸(Glu)为58;不稳定系数为57.74,表明HrWRI1是一个不稳定蛋白(不稳定系数小于40时为稳定蛋白)。
2.4 HrWRI1基因编码的氨基酸的亲水性/疏水性和跨膜结构分析
蛋白质的折叠主要由氨基酸的亲、疏水性驱动,是每种氨基酸固有的特性。蛋白质在折叠时形成疏水的内核和亲水的表面,同时潜在跨膜区会出现高疏水性结构域,通过对亲疏水性分析可以反映蛋白质表面氨基酸的分布和跨膜结构域[8]。
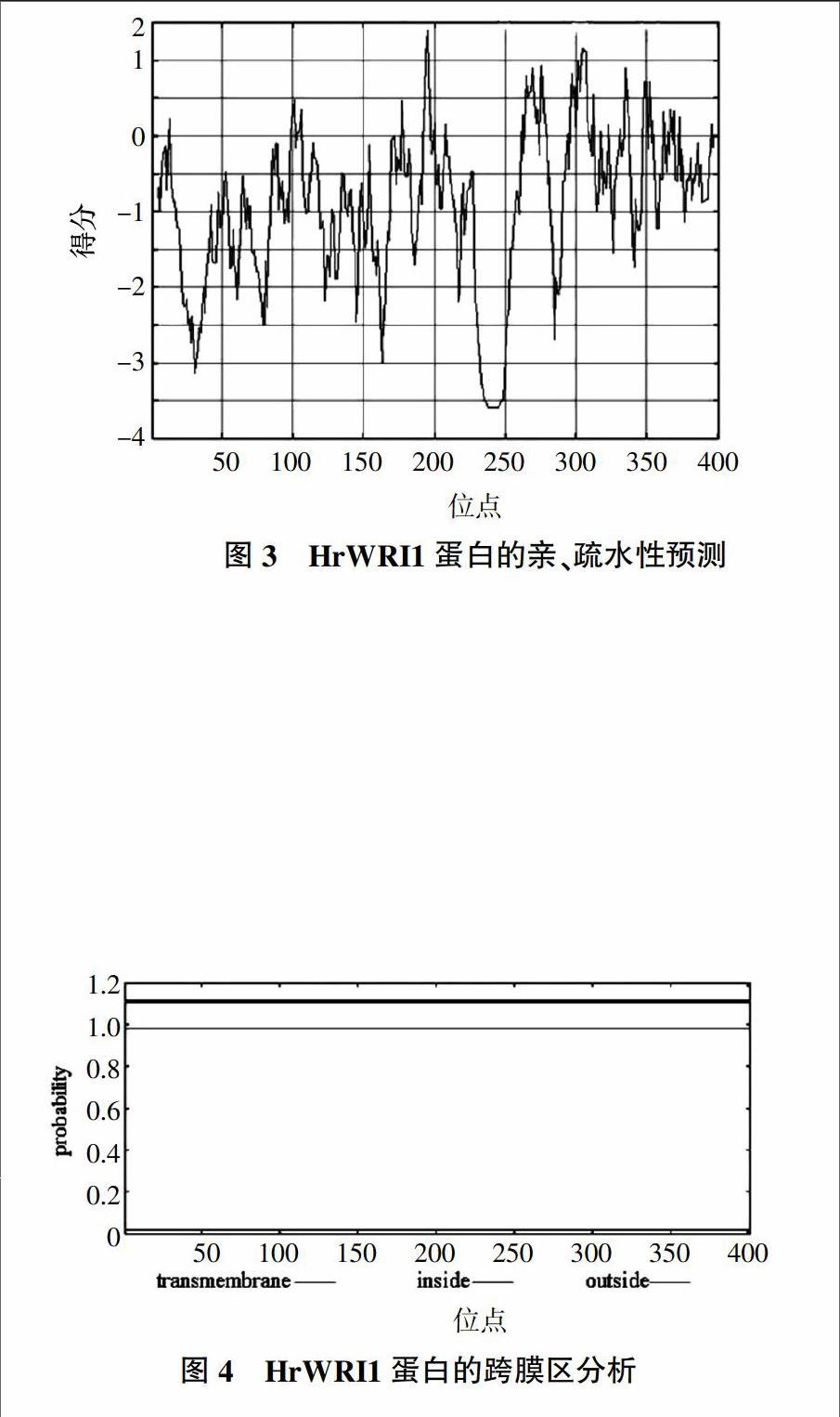
通过ProtScale程序分析,预测HrWRI1氨基酸序列的亲水性/疏水性,结果如图3所示。多肽链的第195位具有最大值1.389,疏水性最强;第238位至245位存在最小值-3.589,均为亲水性氨基酸。平均疏水性通过理化性质分析显示为-0.914,在整条肽链中,亲水氨基酸数量较多,表明整条多肽链表现为亲水性[9]。
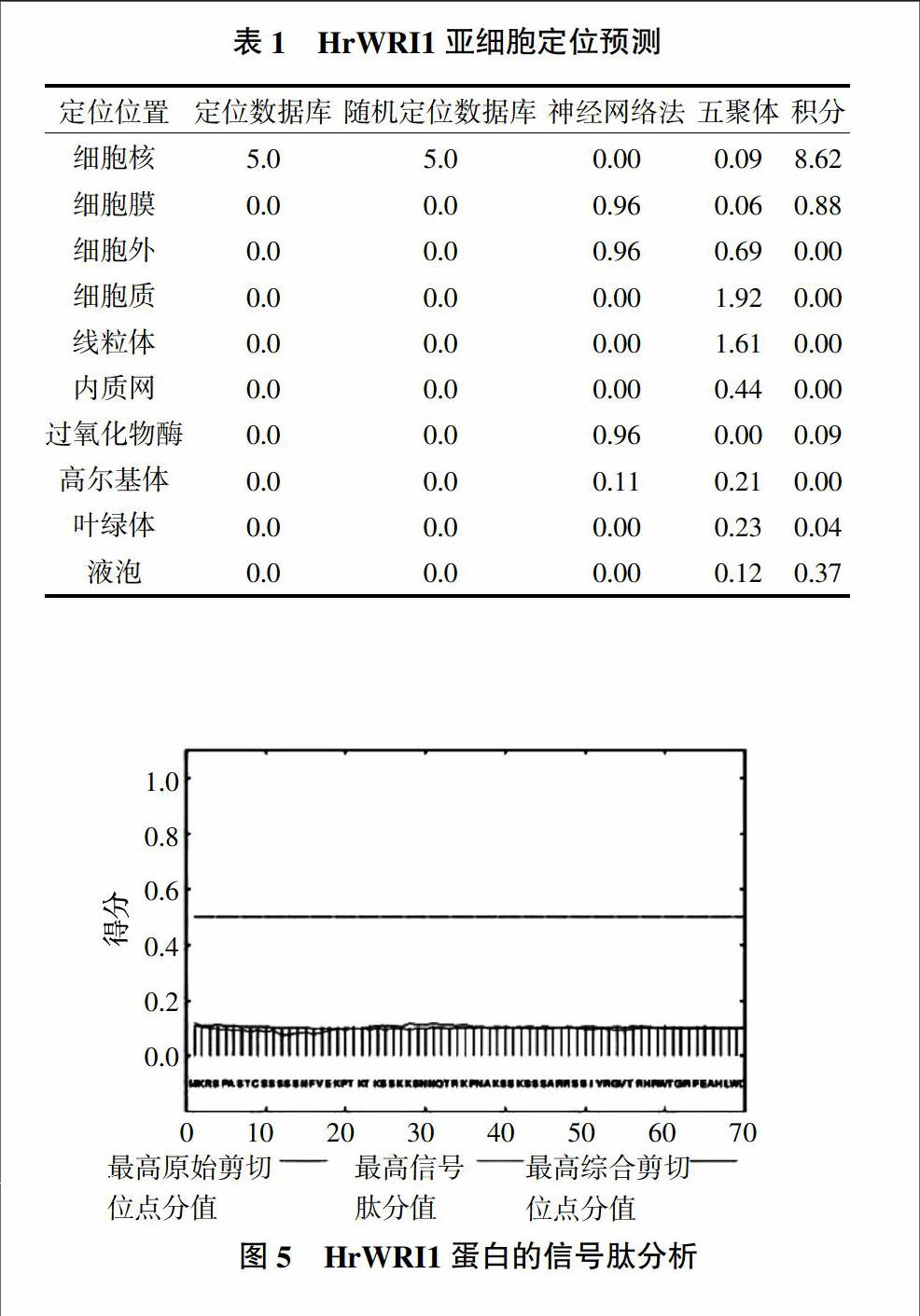
跨膜区必须由强疏水的氨基酸组成才能使膜蛋白穿过膜的磷脂双分子层。通过蛋白亲、疏水性分析发现,HrWRI1为亲水性蛋白,推测不存在跨膜区。进一步利用TMHMM程序对HrWRI1蛋白跨膜区进行了分析,结果如图4所示。表明确实不存在跨膜区,这与亲水性的分析的结果是一致的。
2.5 HrWRI1蛋白的亚细胞定位及信号肽分析
核定位信号是一段特殊的短肽氨基酸序列,其能引导整个蛋白质进入细胞核。亚细胞定位和核定位信号分析发现,HrWRI1蛋白定位于细胞核上,结果见表1,同时发现它在2~29位氨基酸处存在潜在的核定位信号。
信号肽是引导前体蛋白质通过细胞膜分泌到胞外的一段序列,对其预测和分析有助于了解蛋白质的细胞定位并区分蛋白质的功能域。信号肽预测结果如图5所示,HrWRI1蛋白最高原始剪切位点分值(C)、最高信号肽分值(S)以及最高综合剪切位点分值(Y)分别为0.109、0.120、0.106。通常可能的信号肽剪切位点由最高Y值来推测,为具有最高C值的点同时又是S值由高变低是陡峭的位置。HrWRI1蛋白不存在信号肽,为非分泌蛋白。
2.6 HrWRI1蛋白的磷酸化位点分析
磷酸化是蛋白质最常见、最重要的一种翻译后修饰方式之一,该过程能够参与调节细胞生长、细胞分化和信号转导等多种生命活动。蛋白质磷酸化位点主要在丝氨酸(Ser)、苏氨酸(Thr)和酪氨酸(Tyr)残基上,通常基因功能与多肽链中氨基酸潜在磷酸化位点的多少有很大相关性。利用NetPhos程序对HrWRI1蛋白磷酸化位点的数量进行预测,若Poential值大于Threshold值,那么存在磷酸化位点,相反则不存在。结果(图6)表明,HrWRI1蛋白有29个Ser、9个Thr、1个Tyr可能成为磷酸化位点。
2.7 HrWRI1基因的功能预测
通过在线工具ProtFun 2.2 Server进行了功能的预测分析,结果如表2所示。由表2可知,HrWRI1基因的主要功能是调控。
2.8 HrWRI1蛋白的二级结构与三级结构预测分析
蛋白的二级结构只要是指蛋白质多肽链本身的折叠和盘绕方式,是其空间结构预测的基础。通过HNN Methods对沙棘WRI1蛋白二级结构进行预测,结果如图7所示,发现该蛋白中存在248个无规则卷曲(Random coil)占61.85%、97个α-螺旋(Alpha helix)占24.19%、56个伸展链(Extended strand)占13.97%。将氨基酸序列提交SWISS-MODEL,得到蛋白质的三维结构,如图8所示。
2.9 HrWRI1同源蛋白序列比对及进化树分析
对HrWRI1进行BLASTP同源序列搜索,发现其与陆地棉(Gossypium hirsutum)、胡杨(Populus euphratica)、蓖麻(Ricinus communis)、麻风树(Jatropha curcas)、山杏(Prunus sibirica)具有很高的同源性。多重序列比对结果如图9所示,氨基酸序列存在一定范围的相对保守的重叠区,重叠区主要集中在2个保守的AP2/EREBP结构域区域,并且两个结构域之间的序列也相对保守。
根据氨基酸的多序列比对,构建系统发育树(图10)。发育树分为两丛,沙棘的cDNA编码的蛋白质与同为蔷薇目的山杏(Prunus sibirica) 的亲缘关系最近,说明可能具有类似的功能,而与无油樟(Amborella trichopoda)、亚麻荠(Camelina sativa)和欧洲油菜(Brassica napus)的亲缘关系比较远。同时,同为大戟科的麻风树和蓖麻聚到了一组,这与植物分类学上的分类是一致的。
3 讨论
随着生物信息学和分子生物学不断的深入研究,通过基因工程的方法来改变种子的代谢途径已成为可能。目前,在拟南芥[10],油菜[11],大豆[12]等植物中已经有关于WRI1基因的相关报道,发现WRI1是AP2/EREBP类转录因子家族中的一员,转录因子WRI1的靶基因主要参与脂肪酸合成和糖酵解,因而其对植物的胚胎發育、种子油脂积累及相关代谢活动具有调节作用。另外,在水稻、蓖麻、杨树、葡萄等植物中也发现了WRI1类似基因,所以WRI1基因有可能成为一种新的改良种子含油量的目标基因[4],但对于沙棘来说,相关的研究报道比较少。目前对沙棘油的报道中,主要集中在对沙棘油的萃取方法、生化成分的分析以及其药用价值等方面,所以在建立沙棘转录组数据库的前提下,选取HrWRI1基因作为目标基因通过生物信息学知识进行了分析预测,这与传统的实验室生物学研究相比,具有低成本、高效率的优点。但是为了获取更准确的研究结果,就必须在一定程度上进行实验室克隆验证,因此关于HrWRI1基因的分子克隆和功能鉴定有待于进一步的试验和研究。
参考文献:
[1] 齐虹凌,于泽源,李兴国.沙棘研究概述[J].沙棘,2005,6(2):37-41.
[2] 丁 霄,杨淑巧,许 琦,等.转录因子WRI1在主要作物中的研究进展[J].分子植物育种,2015,13(3):697-701.
[3] 阮成江,李代琼.不同品种沙棘含油量及生化成份研究概况[J].陕西林业科技,1999(1):59-63.
[4] 鲁亚萍,刘风珍,万勇善.花生转录因子WRI1基因特征的in silico分析[J].分子植物育种,2012(3):363-370.
[5] 李旭娟,刘洪博,林秀琴,等.甘蔗KNOX基因(Sckn1)的电子克隆及生物信息学分析[J].基因组学与应用生物学,2015(1):136-142.
[6] 秦丹丹,许甫超,董 静,等.大麦MBF1基因的电子克隆与生物信息学分析[J].湖北农业科学,2014,53(21):5276-5281.
[7] 丁 帅,熊 勇,李正涛,等.菊花rbcL基因电子克隆及生物信息学、适应性进化分析[J].种子,2015,34(10):24-30.
[8] LI JB,LUAN YS.Molecular cloning and characterization of a pathogen-inuced WRKY transcription factor gene from late blight resistant tomato varieties Solanum pimpinellifolium L3708[J].Physiological and Molecular Plant Pathology,2014,87:25-31.
[9] 谭 琳,康由发,郑晓燕,等.香蕉MYB转录因子基因的电子克隆及生物信息学分析[J].广东农业科学,2015(4):123-128.
[10] 吴晓梅,吴雄熊,陈明训.拟南芥WRI1基因的克隆及其植物反义载体的构建[J].江苏农业科学,2010(3):68-69,79.
[11] 施春霖,刘 聪,肖旦望,等.甘蓝型油菜WRI1基因cDNA的克隆与序列分析[J].湖南农业大学学报,2013,39(3):247-252.
[12] 王志坤,常健敏,李丹丹,等.大豆GmWRI1a基因克隆及生物信息学分析[J].东北农业大学学报,2013,44(7):11-16.
猜你喜欢
今日农业(2022年13期)2022-09-15
中国水土保持(2022年3期)2022-03-24
西藏农业科技(2019年1期)2019-07-25
知识经济·中国直销(2018年11期)2018-11-26
知识经济·中国直销(2018年11期)2018-11-26
知识经济·中国直销(2017年8期)2017-09-05
中国校外教育(下旬)(2016年11期)2016-12-27
中国教育信息化·基础教育(2016年10期)2016-12-20
今传媒(2016年11期)2016-12-19
