
基于主成分分析和运行特征的软件聚类分析*
2017-04-07 01:33皇甫大鹏林曼筠赵现纲
中国教育信息化 2017年6期
陈 平,皇甫大鹏①,林曼筠,赵现纲
(1.北京师范大学信息网络中心,北京100875;2.中国气象局国家卫星气象中心,北京100081)
基于主成分分析和运行特征的软件聚类分析*
陈 平1,皇甫大鹏1①,林曼筠2,赵现纲2
(1.北京师范大学信息网络中心,北京100875;2.中国气象局国家卫星气象中心,北京100081)
随着教育领域的应用软件种类的不断增加,如何为软件提供合理的硬件资源和提高软件的运行效率受到越来越多的关注。本文提出了一套基于软件运行特征的软件分型方法,该方法利用软件运行时资源消耗情况来刻画软件运行特征。首先引用主成分分析方法对软件运行特征数据进行分析;然后采用聚类算法对教育领域软件进行分型;结合主成分分析结果解释各类软件综合运行特征的意义,并将其作为优化软件硬件资源分配和提高软件运行效率的依据。
聚类算法;主成分分析;特征分析
一、引言
随着教育领域系统种类的快速增加和高性能计算软件的需求的不断增长,教育领域软件和系统所依赖的软硬件资源的运行情况成为人们关注的重点工作。尤其是高校在化学、物理、天文、卫星等领域高性能计算的方面的实时、高效方面提出了很大的要求,在无法监控软件内部运行的情况下,如何能够通过软件运行特征分析软件的运行情况,成为研究的热点。
本文采用的数据是北京师范大学用于教育和科研高性能计算等方面的软件或系统的运行特征数据,首先,对采集原始软件运行特征数据进行特征提取和加工,使其更好的表达软件的特征;其次,使用主成分分析方法对采集的运行特征进行分析,计算主成分提取其特征,并分析其实际意义;然后使用加工后的软件特征数据进行 K-means算法进行[4-6]聚类分析;最后结合主成分分析结果,描述每类软件的特点。
二、软件运行特征提取与处理
1.软件和硬件环境概述
本文的研究对象是用于教育软件和科研高性能计算方面的软件和硬件资源的运行特征,软件资源包括188个教育软件;硬件资源包括3台浪潮小型机和50台普通服务器,详细的配置见表1。
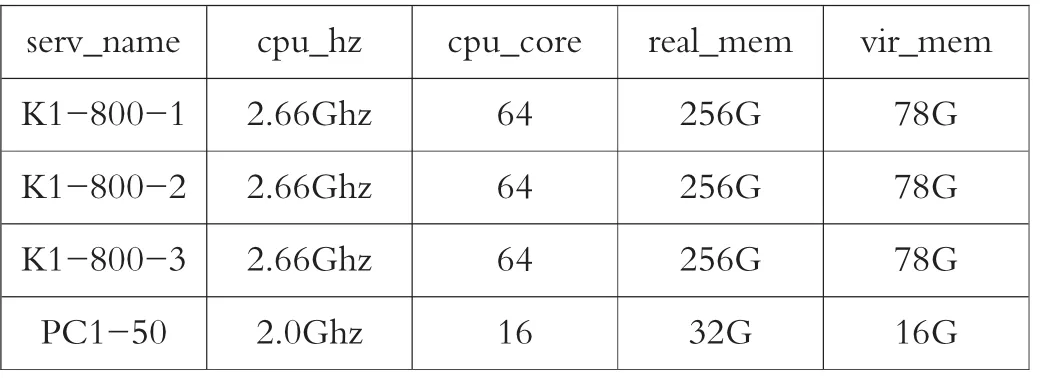
表1 硬件配置
2.软件运行特征数据采集
软件运行特征数据采集范围包含188个应用软件,软件运行数据的采集方式:是通过定期调用linux命令和接口。软件运行特征数据采集类型包括CPU级、系统级、进程级和作业级数据。
3.运行特征数据刻画
软件特征分析还需将软件的运行特征尽量完整的表达,并将每个软件的运行特征通过一个向量来表达。刻画软件运行特征需要从两个方面来考虑:(1)软件运行的时间序列特征;(2)消除平台间差异和系统本身的资源消耗。
4.特征数据归一化
原始数据中每个运行特征的单位都不一样,数据之间的大小差异很大,为了减少特征数据之间的差异,首先对数据进行归一化处理。本文选用Min-max标准化方法是对原始数据进行线性变换。设minA和maxA分别为属性A的最小值和最大值,将A的一个原始值x通过Min-max标准化映射成在区间[0,1]中的值x',其公式为:
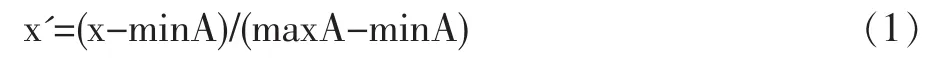
三、特征分析法原理
主成分分析方法[1](Principal Component Analysis,PCA)是一种统计方法。通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分。主成分分析的结果好坏,主要取决于指标之间的相关性,如果相关性很强则主成分分析的结果会很好,反之则较差[2]。特征分析法的计算方法与步骤如下。
(1)根据原始数据矩阵计算相关矩阵
原始数据矩阵每行表示1个软件的运行特征,每列表示软件1个运行特征的值,通过SPSS软件分析结果见表2。该矩阵反映了任意两个软件的运行特征之间的相关性。
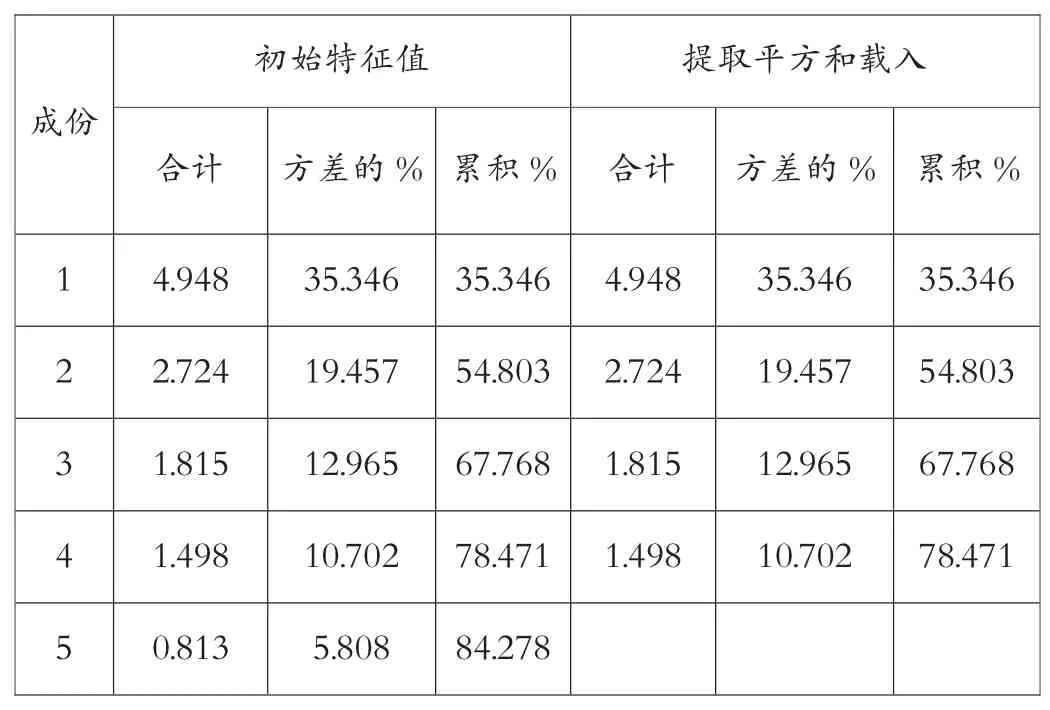
表3 解释的总方差
通过表3和表4分析发现,可以用1、2、3和4四个主成分代表原始矩阵的主要因素。在运行过程中,表达式中的变量已经不是原始变量,而是标准化变量,以第一主成分为例,可被其他标准化变量表示为:

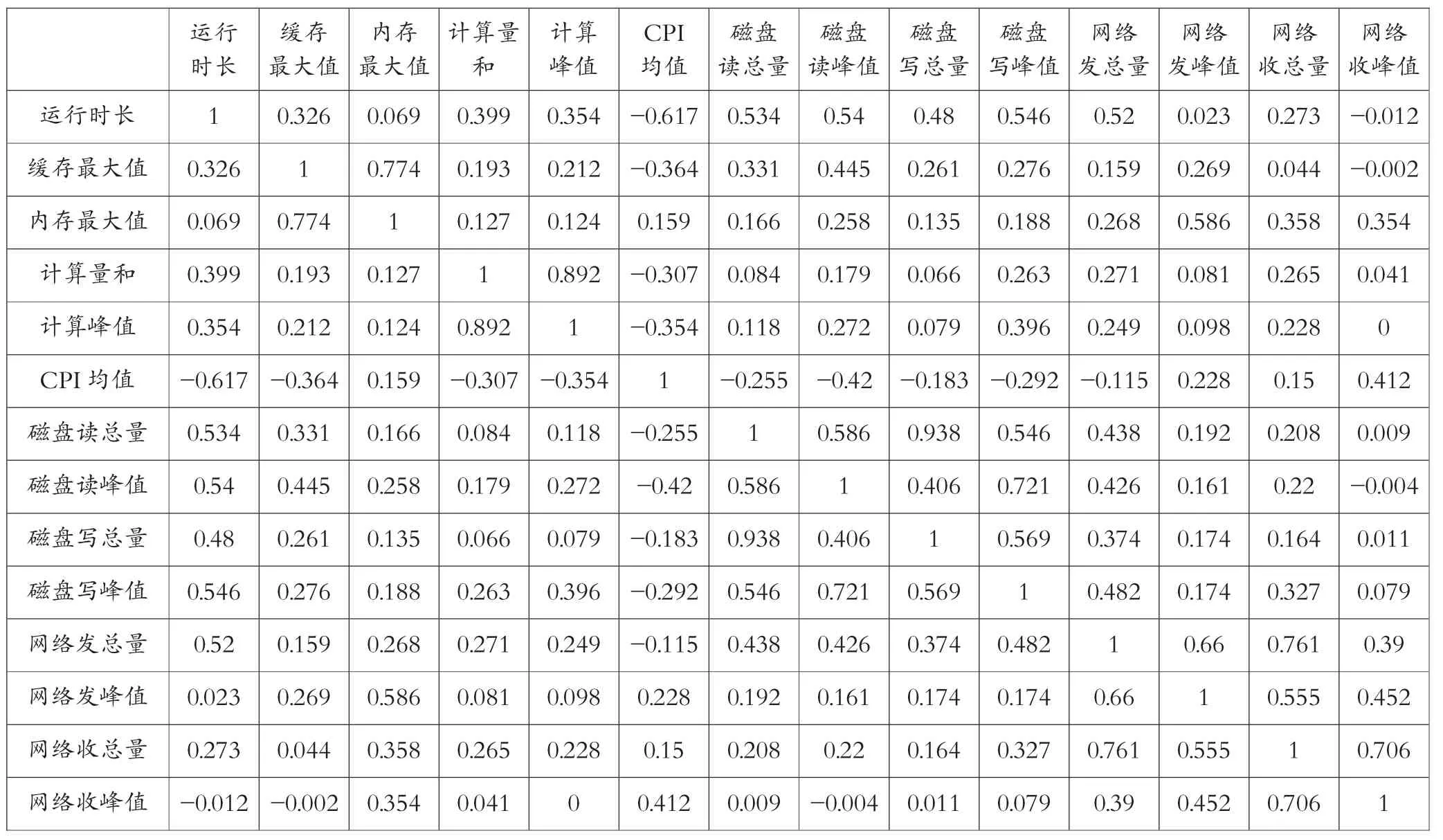
表2 相关矩阵
(2)通过总方差提出主成分
根据文献[2],当ρ(累加%)≥0.8~0.9时,就可以选用前面4-6个主分量代替原来的14个运行特征,并且保留了原来14个运行特征所包含的主要信息,这前4-6个主分量称为公共影响因子。
(3)计算软件主体成分
通过分析表4中的四个主成分系数,选取相关性系数较大的运行特征作为分析的因素。表5中可以发现第一类主成分中主要与运行时长和磁盘读写资源相关;第二类主成分主要跟网络资源和CPI有关;第三类主成分主要与计算资源相关;第四类主成分与内存和缓存有关。
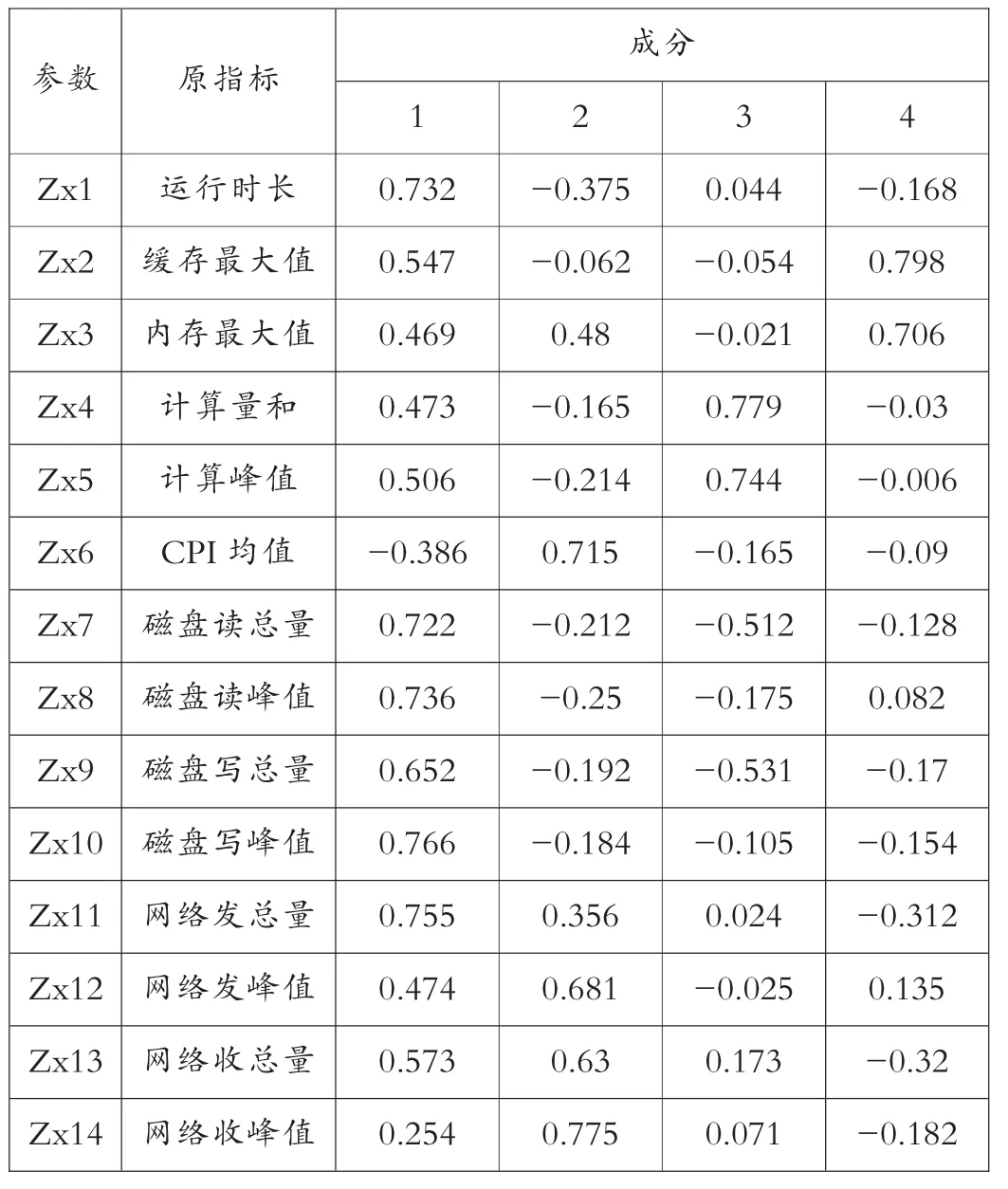
表4 成分矩阵
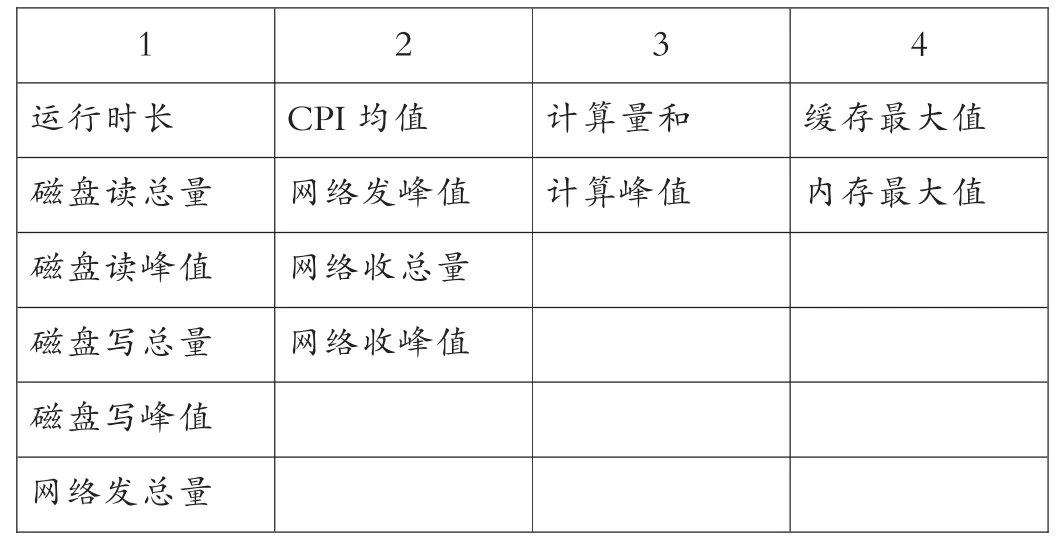
表5 主成分
通过表4和表5,提取新的主成分公式如下:
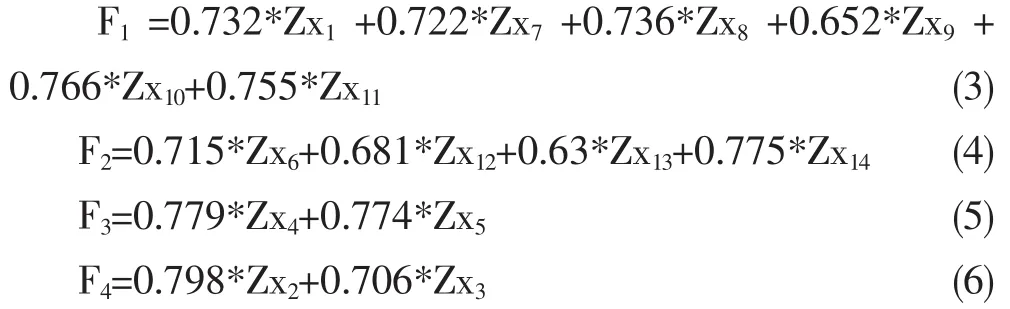
四、聚类分析结果
本文采用改进K-means算法进行聚类,聚类结果如下图所示,共得出了三种类型:
结合主成分分析结果和聚类结果,容易得出以下结果:第一类中第四主成分值较高,其他值都较低,该类软件对内存和缓存的要求比较高,为内存密集型软件;第二类中4个主成分都很高,该类软件属于综合密集型,对CPU、内存、磁盘和网络的需求量都比较大;第三类中4个主成分都比较低,属于小规模资源密集型,该类软件运行时间比较短,对各种资源的需求量整体偏低。
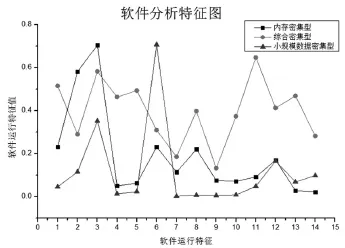
图1 软件分型特征图
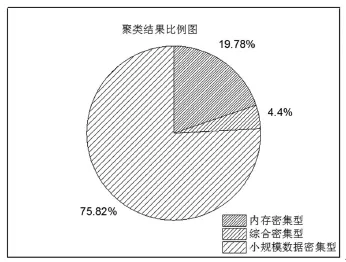
图2 软件分型结果图
通过上述两幅图表可以发现,CPU的整体使用率偏低,可以降低CPU的配置或者在此服务器上增加应用软件。内存使用比较密集且集中,可以增加内存的容量以提升运行速度。软件对磁盘的读写速度要求比较高,突发性流量加大,建议磁盘配备转速较高或者增加多级缓存资源,以降低磁盘读写对软件计算的影响。经调研和实验验证,上述结果与实际情况相符,可以作为软硬件资源优化的依据。
五、结束语
本文使用主成分分析法和聚类算法对教育和科研软件进行了特征分析,为软件提供了特征图和资源需求情况。该结论可进一步用于分析软件调度算法提高硬件利用率和降低软件等待时间。
参考文献:
[1]马金龙,景新幸,杨海燕.主成分分析和K-means聚类在说话人识别中的应用 [J].计算机应用,2015,35( S1):127-129.
[2]李柞泳,丁晶,彭莉红著.环境质量评价原理与方法[M].化学工业出版社,2004.
[3]尹成祥,张宏军,张睿,綦秀利,王彬.一种改进的K-Means算法[J].计算机技术与发展,2014,24(10):30-33.
[4]HUANGFU Dapeng,LIN Qianhui,ZHOU Jingmin,et al.An Improved Similarity Algorithm for Personalized Recommendation,Computer Science-Technology and Applications 2009,54-57.
[5]杨文波.信息资源个性化服务技术的研究与实现[D].北京:北京航空航天大学,2006.
[6]孟洋,赵方.基于信息熵理论的动态规划特征选取算法[J].计算机工程与设计,2010,31(17):3879-3881.
[7]原福永,张晓彩,罗思标.基于信息熵的精确属性赋权 K-means聚类算法 [J].计算机应用,2011,31(6): 1675-1678.
[8]汪中,刘贵全,陈恩红.一种优化初始中心点的K-means算法[J].模式识别与人工智能,2009,22(2):299-304.
[9]李永森,杨善林,马溪骏.空间聚类算法中的K值优化问题研究[J].系统仿真学报,2006,18(3):573-576.
[10]Mac Queen J.Some methods for classification and analysis of multivariate observations[C].Proceeding of the Berkeley symposium on mathematical statistics and probability.[s.1.][s.n.]1967:281-297.
(编辑:郭桂真)
TP391
:A
:1673-8454(2017)06-0078-04
①皇甫大鹏为本文通讯作者
*本文得到国家气象局卫星气象中心项目支持(CNS部件级测试环境模拟软件研究项目,项目号:ZQC-H14187)
猜你喜欢
英语文摘(2021年10期)2021-11-22
铁道通信信号(2019年6期)2019-10-08
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
摄影之友(影像视觉)(2019年3期)2019-03-30
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
CHIP新电脑(2015年10期)2015-10-15
电脑爱好者(2015年21期)2015-09-10
