
基于人工免疫的链路层协议帧同步字识别
2017-03-29 07:30:04李歆昊
电子与信息学报 2017年3期
李歆昊 张 旻
基于人工免疫的链路层协议帧同步字识别
李歆昊*张 旻
(电子工程学院 合肥 230037) (安徽省电子制约技术重点实验室 合肥 230037)
该文提出一种基于人工免疫的同步字识别算法,解决了无线网络链路层协议帧同步字的识别问题。算法在定义相关概念的基础上,通过对已知协议类型文件集脱氧核苷酸(ODN)浓度的计算,得到了相关协议的同步字脱氧核苷酸库;然后,利用得到的同步字脱氧核苷酸库与相关文件集进行连续一致匹配,生成同步字检测基因库;最后,利用得到的同步字脱氧核苷酸库和同步字检测基因库,通过连续一致匹配和基因相似度值的计算,实现了同步字的准确识别。仿真实验验证了算法的有效性,与已有的模式串匹配算法相比,所提算法的鲁棒性较好,具有一定的工程应用价值。
帧结构;同步字;人工免疫;阴性选择;相似度值
1 引言
随着社会的飞速发展,无线通信和智能通信在人们的生活中扮演着越来越重要的角色,而通信协议分析是上述通信过程中实现同步的关键[1]。此外,在非合作的军事对抗领域,协议分析是获取敌方通信信息和进行有效干扰的前提[2]。因此,针对通信协议识别的研究受到了国内外学者的广泛关注。链路层协议是通信协议的重要组成部分,但是由于链路层协议种类繁多且帧结构各不相同,要实现有效分帧并最终完成协议的解析,首先需要解决同步字的识别问题[3]。因此,研究一种有效的同步字识别方法具有重要的意义。
人工免疫系统是受生物免疫系统的免疫现象和生物医学理论启发而设计的计算机系统,利用已有的生物免疫学说,人工免疫系统对应提出了阴性选择算法、免疫遗传算法、克隆选择算法、基于疫苗的免疫算法和基于免疫网络的免疫算法等[16,17]。在链路层协议构成的比特流序列中,用于确定每帧起止位的同步字要求具有特异性,而人工免疫系统具有优良的区分“自体”和“异体”的能力,这与同步字的识别有相似之处。因此,本文提出了基于人工免疫的链路层协议帧同步字识别算法。算法在定义相关概念的基础上,通过对已知协议类型文件集脱氧核苷酸浓度的计算,得到了相关协议的同步字脱氧核苷酸库;然后,利用得到的同步字脱氧核苷酸库与相关文件集进行连续一致匹配,生成同步字检测基因库;最后,利用得到的同步字脱氧核苷酸库和同步字检测基因库,通过连续一致匹配和基因相似度值的计算,在误码率一定的条件下实现了同步字的准确识别。
2 数据帧的基础知识
数据链路层的协议虽然有许多种,但为了保证数据传输的准确性和可靠性,各种协议的比特流在链路层都要封装成帧并且进行透明传输。
封装成帧就是在一段数据的前后分别添加首部和尾部,这样就构成了一个完整帧,图1表示用帧首部和帧尾部封装成帧的一般概念[18]。
由于帧开始和结束的标记是使用特定指明的控制字符,因此在传输的数据中,任何8 bit的组合绝对不能与用作帧定界的控制字符的比特编码相同,满足以上编码条件的传输被称为透明传输。

图1 帧封装
在完成了帧封装且满足透明传输条件后,待传输数据无缝连接形成比特流进行传输。此时,帧首部与帧尾部形成具有同步功能的字段,称之为同步字;两两同步字之间包含的数据部分称之为信息段。因此,对于链路层传输的比特流形式的协议帧,其结构如图2所示。

图2 链路层帧结构
3 同步字的识别
3.1 同步字脱氧核苷酸库
DNA是存储生物体遗传信息的主要介质,但只有DNA中的基因才是具有上述遗传效应的片段,而基因又由若干的脱氧核苷酸(ODN)构成。上述三者之间的关系如图3所示。
结合链路层帧结构,我们给出了DNA,基因和ODN的定义。
(1)DNA:整个链路层的比特流数据;
(2)基因:同步字的检测器,DNA的片段,同步字检测的比较单元;
(3)脱氧核苷酸:每4 bit作为一个脱氧核苷酸,记做ODN,若干个脱氧核苷酸构成了基因。
我们将整个链路层的比特流数据对应为生物体的DNA;比特流中的同步字被认为是基因,这些基因由同步字的ODNs组成。多个ODN的有序连接表示比特流中的一个或多个同步字。利用已知浓度信息统计每个ODN趋向于代表同步字的程度,浓度的相关定义及计算公式如下:是单个包含同步字的训练集文件中的ODN总数;是单个不包含同步字的训练集文件中的ODN总数;是训练集中ODN在包含同步字的文件中出现的次数;是训练集中ODN在不包含同步字的文件中出现的次数;是训练集中包含同步字的文件数目;是训练集中不包含同步字的文件数目;浓度的计算公式如式(1):

图3 DNA,基因,ODN关系图
3.2 同步字检测基因库
在得到同步字ODN库后,需要产生同步字检测基因库,而同步字检测基因库的生成需要首先得到同步字候选基因库和类同步字基因库,具体步骤如下所示。
3.2.1 相关基因库生成 利用得到的同步字ODN库,采用连续一致匹配的方法匹配包含同步字比特流的DNA,生成同步字候选基因库。连续一致匹配是指从第1位发生匹配的位置开始,利用滑动窗口的方法向后进行匹配比较,匹配一直进行到发生间断为止。此时,统计从开始匹配到匹配结束共有多少同步字ODN库中的ODN参与匹配,如果ODN数目不小于阈值,将同步字DNA的这个片段作为同步字基因,反之不是同步字基因。由于链路层数据在实际应用中常以字节为单位进行传输,且同步字的长度一般大于等于3个字节。因此,本文规定阈值的取值为6。
由于训练样本中包含有不同种类的协议数据,因此得到的同步字候选基因库中的基因存在与不包含同步字比特流序列基因匹配的可能性。通过采用上述生成同步字候选基因库相同的方法,利用ODN库与训练集中所有不包含同步字比特流序列进行匹配,可以得到类同步字基因库。
3.2.2 同步字检测基因库 将类同步字基因库中的基因看做“自体”,同步字候选基因库中的基因看做“异体”,采用连续一致匹配的方法,进行阴性选择。如果同步字候选基因库中的基因与类同步字基因库中的任一基因匹配成功,就删除该同步字候选基因。重复上述过程,直到同步字候选基因库中所有与类同步字基因库发生匹配的基因被完全删除为止。此时,同步字候选基因库就升级为同步字检测基因库。
3.2.3 待识别序列类同步字基因库 采用与生成同步字候选基因库相同的方法,通过ODN库与待识别序列的匹配,我们能够很容易地得到待识别序列的类同步字基因库并实现待识别序列的同步字识别。
3.3 浓度阈值的选取
经过阴性选择后的同步字检测基因库与不包含同步字数据的相似度值为0,与大部分包含同步字数据的相似度值不为0,此时算法具有较好的识别效果。但实际情况下,训练集包含的协议类型有限,产生的同步字检测基因库仅对训练集协议类型数据具有较好的识别效果。当训练集的组成改变时,算法的识别准确性和推广泛化能力降低。因此,实际应用中选取最优浓度阈值没有意义。
本文针对选取的训练集,使用1维搜索的方法,对训练集中的已知协议数据进行同步字识别。每种浓度下进行50次识别,并计算出平均的识别正确率。随着浓度值的增加,同步字识别正确率达到理想值而不能再提高。选取识别正确率最大值所对应的最小浓度取值为浓度阈值,在此浓度阈值下产生的同步字检测基因库将对检测集中的同步字达到完美识别。
3.4 基因的相似度计算
为了提高本文算法的识别准确性,定义两个基因之间的匹配程度为相似度值。因此,对于彼此之间不匹配的基因,它们的相似度值为0;对于两两匹配的基因,它们应该满足如下的条件,即若,其中,则两基因位ODN匹配时的相似度值要大于两基因位和位ODN匹配时的相似度值之和。如果定义是位ODN匹配时的相似度值,则有,利用数学归纳法我们可以得到式(2):

根据上述分析,可以得到相似度值的计算公式为
(3)
将待识别序列类同步字基因库中的一个基因与同步字检测基因库中的每个基因进行匹配比较,利用式(3)计算得到此基因与同步字检测基因库中各基因的相似度值,并将最大的相似度值作为该基因与同步字检测基因库的相似度值;重复上述过程,直到得到类同步字基因库中每个基因与同步字检测基因库的相似度值;最后将这些相似度值中最大的作为类同步字基因库与同步字检测基因库的相似度值,与其对应的同步字检测基因库中的基因即被判定为待识别序列的同步字。
4 算法流程
本文算法的具体流程主要包括两部分:即有向导地生成同步字检测基因库的训练部分、在连续一致匹配和相似度值计算基础上实现同步字准确识别的检测部分,具体步骤如下所示。
步骤1 选取若干组包含同步字和不包含同步字的比特流数据组成训练集,初始化,,,,,为0, ODN 长度bit;
步骤4 利用得到的同步字候选基因库和类同步字基因库,采用连续一致匹配的方法,在连续匹配ODN数目阈值bit的条件下进行阴性选择,得到同步字检测基因库;
步骤6 利用式(3),计算待识别序列类同步字基因库与同步字检测基因库的相似度值,与其对应的同步字检测基因库中的基因即被判定为待识别序列的同步字。
5 仿真实验
实验选取CCSDS空间链路层协议中的TC协议帧、TM协议帧、Proximity-1协议帧和局域网链路层802.3协议帧,各协议帧的相关参数如表1所示。
实验1识别数据生成
由图4可知,当浓度值增大到0.5时,正确识别同步字的概率为1,且随着浓度值的增大,识别概率不变。因此,我们选取浓度阈值对训练集中的ODN进行筛选。
(2)同步字检测基因库生成:仿真产生长度为240000 bit的上述4种协议帧和其信息段各10组,分别构成训练集中的包含同步字比特流文件集和不包含同步字比特流文件集。设置同步字ODN长度bit、浓度阈值,利用仿真产生的训练集数据,统计各ODN对应十进制数的浓度值分布如图5所示。
由图5可知,16种ODN的浓度值都大于0.4,其中浓度值大于浓度阈值的ODN有7种,它们对应的二进制取值0101, 0111, 1010, 1011, 1101, 1110, 1111构成同步字ODN库。
表1 协议帧特征统计

协议帧同步字帧长(bit) TC11000101110001011100010111000101110001011100010111000101011110011110101110010000256n (n=1,2,3) TM00011010110011111111110000011101128n (n=1,2,3) Pro-1111110101111001100100000128n (n=1,2,3) 802.31010101010101010101010101010101010101010101010101010101010101011256n (n=1,2,3)
图4浓度值
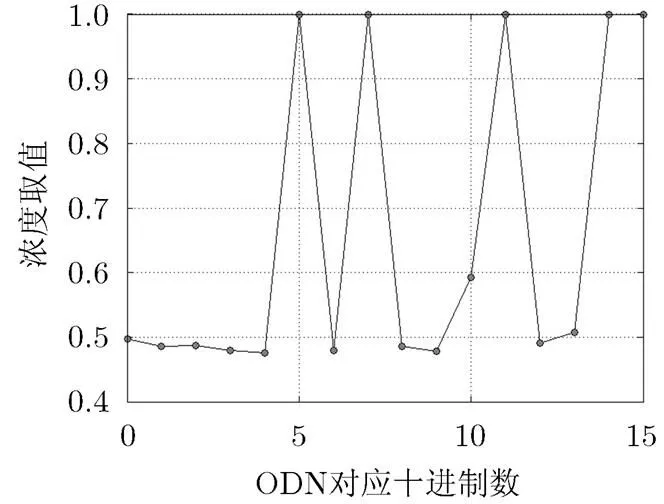
图5 浓度值分布
由表2可知,生成的同步字检测基因库由30个检测基因组成,每个基因的长度为24 bit。利用上述得到的同步字检测基因库,我们就可以对待识别序列的同步字进行检测识别。
实验2 同步字识别
(1)无误码识别: 在无误码且起始位正确的条件下,分别仿真产生长度为640000 bit的上述4种协议帧进行同步字识别。设置ODN匹配数目,得到的类同步字基因库如表3所示。
计算得到的类同步字基因库中每个基因与同步字检测基因库的相似度值如图6所示。由图6可知,Proximity-1协议帧的相似度值是384210526, TC协议帧的相似度值是245029240, TM协议帧的相似度值是86964912, 802.3协议帧的相似度值是1107017544。它们对应的同步字检测基因库中的基因即为识别的该协议的同步字,结果如表4所示。
我们将得到的各协议的同步字识别结果与正确同步字进行比较,对比结果如表5所示。
表5中第1行是正确的同步字,第2行是识别的同步字。由表5可知,在上述4种协议的识别结果中,TC协议帧、Proximity-1协议帧和802.3协议帧的识别结果能够完全匹配正确的同步字,TM协议帧与正确同步字的匹配只相差3位,也达到了较好的识别准确性。
(2)有误码识别: 在误码率为0.5%且起始位错误的条件下,分别仿真产生长度为640000 bit的上述4种协议帧,计算各协议的类同步字基因库中的每个基因与同步字检测基因库的相似度值如图7所示。
由图7可知,Proximity-1协议帧的相似度值是358672560, TC协议帧的相似度值是234314514, TM协议帧的相似度值是87391461, 802.3协议帧的相似度值是1078453616。它们对应的同步字检测基因库中的基因如表6所示。
如表6所示,识别结果与不存在误码且起始位正确时的完全相同,表明本文算法具有较好的抗误码性能。
实验3 误码性能对比
仿真产生长度为640000 bit的TC协议帧,分别利用本文的人工免疫算法和已有的模式串匹配算法,在不同误码率条件下各进行100次的蒙特卡洛同步字识别仿真实验,验证两种算法的抗误码性能,实验结果如图8所示。
表2 同步字检测基因库

同步字检测基因库 010101010101010101010101 010101010101010101101000 010101010101010101101001 010101010101010101101100010101010101010101101101 010101010101010101110000 010101010101010101110001 010101010101010110100010010101010101010110100011 010101010101010110100100 010101010101010110110010 010101010101010110110011010101010101010110110100 010101010101010111000010 010101010101010111000011 010101010101010111000100010101111001111010111001 011111010111100110010000 011111111110000011101010 011111111110000011101011011111111110000011101100 101010101010101010101010 101010101010101101100110 101010101010101110000100110101010101010101010101 110111110101111001100100 111110101111001100100000 101010101010101101000110101010101010101110000110 101010101010101110001000
表3 待测序列类同步字基因库

协议帧类同步字基因库 TC010101111001111010111001 010110110001011100010111 TM011111111110000011101010 011111111110000011101011 011111111110000011101100 Pro-1010110111110101111001100 111110101111001100100000 110111110101111001100100 802.3010101010101010101010101 010101010101010101101000 010101010101010101101001 010101010101010101101100010101010101010101101101 010101010101010101110000 010101010101010101110001 010101010101010110100010010101010101010110100011 010101010101010110100100 010101010101010110110010 010101010101010110110011010101010101010110110100 010101010101010111000010 010101010101010111000011 010101010101010111000100010110101010101010101010 101010101010101010101010 101010101010101010101101 110101010101010101010101
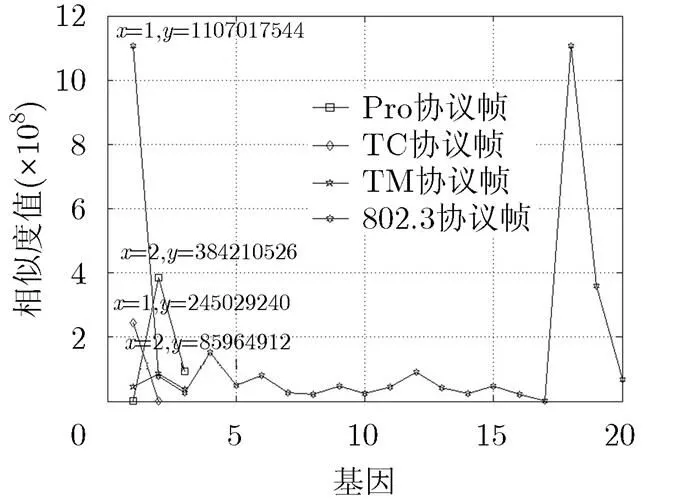
图6 无误码条件下的相似度值分布
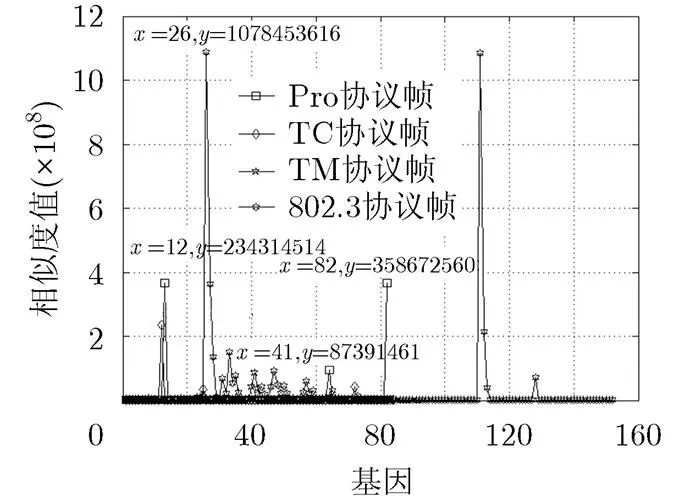
图7 有误码条件下的相似度值分布
图8 抗误码性能对比
表4 同步字识别结果

协议帧同步字识别结果 TC010101111001111010111001 TM011111111110000011101011 Pro-1111110101111001100100000 802.3010101010101010101010101 101010101010101010101010
表5 识别结果对比
表6 同步字识别结果

协议帧同步字识别结果 TC010101111001111010111001 TM011111111110000011101011 Pro-1111110101111001100100000 802.3010101010101010101010101
由图8可知,在误码率达到2.5%时,模式串匹配算法的识别概率在40%左右,而本文的人工免疫算法保持在75%左右;当误码率继续升高到3.5%时,模式串匹配算法的识别概率只有5%左右,而人工免疫算法仍然保持在50%以上,可见本文算法比已有的模式串匹配算法具有更好的抗误码性能。
6 结论
本文提出了一种基于人工免疫的链路层协议帧同步字识别算法。在得到同步字脱氧核苷酸库和同步字检测基因库的基础上,通过计算待识别序列的类同步字基因库与同步字检测基因库的相似度值,达到识别同步字的目的。由于误码对相似度值的计算和判断影响较小,且最终的同步字识别以同步字检测基因库为准,因此与已有模式串匹配算法相比,本文算法具有较好的鲁棒性。
[1] 张永光, 娄才义. 信道编码及其识别分析[M]. 北京: 电子工业出版社, 2010: 1-2.
ZHANG Yongguang and LOU Caiyi. Channel Coding and Recognition Analysis[M]. Beijing: Publishing House of Electronics Industry, 2010: 1-2.
[2] 李相迎. CCSDS数据链路层协议识别关键技术研究[D]. [博士论文],中国科学院大学, 2011.
LI Xiangying. Key technologies of protocol identification for CCSDS data link layer[D]. [Ph.D. dissertation], University ofChineseAcademyofSciences, 2011.
[3] HUANG S, HE J, ZENG X,. Accurate frame synchronization for IEEE 802.16d system[C]. WCSP 2009. International Conference on IEEE, Nanjing, China, 2009: 1-3. doi: 10.1109/WCSP.2009.5371458.
[4] 金凌. 面向比特流的未知帧头识别技术研究[D]. [硕士论文], 上海交通大学, 2011.
JIN Ling. Study on bit stream oriented unknown frame head identification[D]. [Master dissertation], Shanghai Jiao Tong University, 2011.
[5] 白彧, 杨晓静, 王懋. 基于相关滤波和哈达玛变换的帧同步码识别[J]. 探测与控制学报, 2011, 33(3): 69-72.
BAI Yu, YANG Xiaojing, and WANG Mao. Recognition method of frame synchronization codes based on relativity filter and Hadamard transformation algorithm[J].&, 2011, 33(3): 69-72.
[6] 陆凯, 张旻, 李歆昊. 一种有效的等帧长帧同步盲识别方法[J]. 火力与指挥控制, 2015, 40(9): 68-71.
LU Kai, ZHANG Min, and LIXinhao. A blind recognition method of fixed frame length frame synchronization[J].&, 2015, 40(9): 68-71.
[7] 郭凯丰, 王萌. 基于等帧长信号的帧头检测方法研究[J]. 信号与信息处理, 2014, 44(6): 33-36.
GUO Kaifeng and WANG Meng. Research on detection of frame head on fixed frame length[J]., 2014, 44(6): 33-36.
[8] 张玉, 杨晓静. 集中插入式帧同步识别方法[J]. 兵工学报, 2013, 34(5): 554-560.
ZHANG Yu and YANG Xiaojing. Recognition method of concentratively inserted frame synchronization[J]., 2013, 34(5): 554-560.
[9] IMAD R, SICOT G, and HOUCKE S. Blind frame synchronization for error correcting codes having a sparse parity check matrix[J]., 2009, 57(6): 1574-1577. doi: 10.1109/ TCOMM.2009.06.070445.
[10] ZHANG Y, CHEN X, FAN W,Robust and reliable frame synchronization method for DVB-S2 system[C]. Wireless Telecommunications Symposium(WTS), Tampa, Florida, USA , 2010: 1-5. doi: 10.1109/WTS.2010.5479625.
[11] QIN J, HUANG Z, LIU C,Novel blind recognition algorithm of frame synchronization words based on soft-decision in digital communication systems[J]., 2015, 10(7): e0132114. doi: 10.1371/journal.pone.0132114.
[12] HOUCKE S and SICOT G. Blind frame synchronization for block code[C]. European Signal Processing Conference, Florence, Italy, 2006: 1-4.
[13] WANG Y, ZHANG C, PENG Q,Learning to Detect Frame Synchronization[M]. Berlin, Germany, Neural Information Processing, Springer Berlin Heidelberg, 2013: 570-578. doi: 10.1007/978-3-642-42042-9_71.
[14] 王和洲. 面向比特流的链路协议识别与分析技术[D]. [硕士论文], 中国科学技术大学, 2014.
WANG Hezhou. Research on bit-stream oriented link protocol identification and analysis techniques[D]. [Master dissertation], University of Science and Technology of China, 2014.
[15] 张一嘉. 局域网链路层数据帧识别算法的设计与实现[J]. 通信对抗, 2007, 99(4): 41-44.
ZHANG Yijia. Design and implementation of algorithm for LAN data frame recognition[J].2007, 99(4): 41-44.
[16] WANG W, ZHANG P, TAN Y,. An immune local concentration based virus detection approach[J].2011, 12(6): 443-454. doi: 10.1631/jzus.C1000445.
[17] 龚涛, 蔡自兴. 基于正常模型的人工免疫系统及其应用[M]. 北京: 清华大学出版社, 2011.
GONG Tao and CAI Zixing. Artificial Immune System Based on Normal Model and Its Applications[M]. Beijing: Tsinghua University Press, 2011.
[18] 谢希仁. 计算机网络[M]. 北京: 电子工业出版社, 2008: 66-67.
XIE Xiren. Computer Network[M]. Beijing: Publishing House of Electronics Industry, 2008: 66-67.
Frame Synchronization Word Identification of Link Layer Protocol Based on Artificial Immune
LI Xinhao ZHANG Min
(,230037,)(,230037,)
Inspired by biologic immune system, a novel frame synchronization word identification algorithm based on artificial immune is proposed. Firstly, due to the calculation of ODN concentration of known protocol type file set, ODN library of synchronization word in corresponding protocol is constructed. Then, through uniform continuity matching between ODN library of synchronization word and relevant file set, the detecting synchronization word gene library is constructed. At last, through calculating similarity value and uniform continuity matching by using ODN library of synchronization word and detecting gene library, synchronization word can be identified exactly. The new method, which has higher accurate recognition than pattern matching algorithm suggested by simulation results, has significant potential in engineering application.
Frame structure; Synchronization word; Artificial immune; Negative selection; Similarity value
TN911.22
A
1009-5896(2017)03-0561-07
10.11999/JEIT160476
2016-05-10;改回日期:2016-09-09;
2016-11-14
李歆昊 lixinhao1989616@126.com
国家自然科学基金(61171170),安徽省自然科学基金(1408085QF115)
The National Natural Science Foundation of China (61171170), The Natural Science Foundation of Anhui Province (1408085QF115)
李歆昊: 男,1989年生,博士,主要研究方向为信道编码识别.
张 旻: 男,1966年生,教授,博士,主要研究方向为通信信号处理、智能计算.
猜你喜欢
阅读(高年级)(2022年9期)2022-10-08 01:20:08
今日农业(2021年1期)2021-11-26 07:00:56
宁夏师范学院学报(2021年7期)2021-09-27 12:35:00
国际种业前沿动态(2020年18期)2020-12-23 06:59:17
生物学教学(2018年1期)2018-08-07 09:06:16
科学24小时(2016年11期)2016-11-08 11:42:55
长春工业大学学报(2016年1期)2016-05-07 01:50:03
结核与肺部疾病杂志(2015年1期)2015-07-18 11:09:24
电子设计工程(2015年6期)2015-02-27 12:05:02
广西教育·D版(2014年12期)2015-01-21 23:28:19
