
应用感知的容器资源调度优化方法①
2017-03-27 09:35陆志刚吴悦文顾泽宇吴启德
计算机系统应用 2017年3期
陆志刚, 吴悦文, 顾泽宇, 吴启德
应用感知的容器资源调度优化方法①
陆志刚1,2,3, 吴悦文1,2, 顾泽宇1,2, 吴启德4
1(中国科学院软件研究所, 北京 100190)2(中国科学院大学, 北京 100049)3(苏州工业园区国有资产控股发展有限公司, 苏州 215028)4(中国科学技术大学计算机科学学院, 合肥 230026)
资源调度作为容器管理的关键技术之一, 已有研究工作或满足公平性目标, 将工作负载平均调度到所有物理节点上, 关注吞吐率指标; 或满足性能目标, 将工作负载关联的多个容器载体调度到相同或相近的物理节点上, 关注响应时间. 提出应用感知的容器资源调度方法, 采用多队列模型兼顾公平性和性能目标. 实验结果显示, 对于典型的大数据处理场景, 本方法和已有公平性调度方法具有相当的吞吐率; 对于典型的事务型应用场景, 本方法相对于已有的公平性调度方法, 事务型应用的延迟最多可减少100%.
应用感知; 容器; 资源调度; 大数据; 事务型
容器是一种新型虚拟化技术, 其核心思想是操作系统复用, 模拟沙箱进程环境, 因而具有接近物理主机性能、资源利用率高的特性[1]. 近年来, 容器已在国内外产业界得到广泛应用, 比如Docker Cloud[2], 羊年春晚微信抢红包[3], 京东618商品秒杀[4]等. 另具Gartner研究报告[5], 全球约70%的应用将于2019年迁移到容器基础设施上. 因此, 容器正逐渐成为应用运行支撑的主流基础设施.
资源调度是大规模容器管理的核心组件之一, 也是学术界和工业界的关注重点, 如Google Kubernetes[7]、Microsoft Apollo[8]、Apache Mesos[9]. 资源调度是指通过合适的调度策略或算法, 将容器合理的分配到不同的物理机器上, 以在满足特定约束条件的情况下提高资源利用率, 节省运营成本.
已有研究考虑公平性因素, 适用大数据处理应用, 其核心思想是将封装大数据处理应用的容器均分到物理服务器上, 优化目标是吞吐率[10,11]. 另有研究关注性能因素, 适合事务类应用, 其核心思想是将封装了事务类应用的容器尽量部署在相同的物理服务器上, 优化目标是延迟[12,13]. 由此可见, 已有研究通常在运行时只能满足单一优化目标, 难以根据应用类型选择最优的调度算法.
本文提出应用感知的容器资源调度方法, 该方法采用多队列模型, 每个队列采用单一调度策略, 并可根据应用类型, 选择合适的调度策略, 从而达到兼顾公平性和性能目标. 实验结果显示, 对于典型的大数据处理场景, 本方法和已有公平性调度方法具有相当的吞吐率; 对于典型的事务型应用场景, 本方法相对于已有的公平性调度方法, 事务型应用的延迟最多可减少100%. 例如文献[12]选取事务型应用TPC-W作为测试基准, 采用延迟优化的调度算法, 在并发500的场景下, 应用平均响应时间从507ms下降到237ms.
1 系统概述
1.1 体系结构
如图1所示, 整个体系结构涉及应用层、资源调度层和物理资源层, 其中资源调度层由应用类型声明器、数据监测器、调度决策器、应用放置器四个部分.
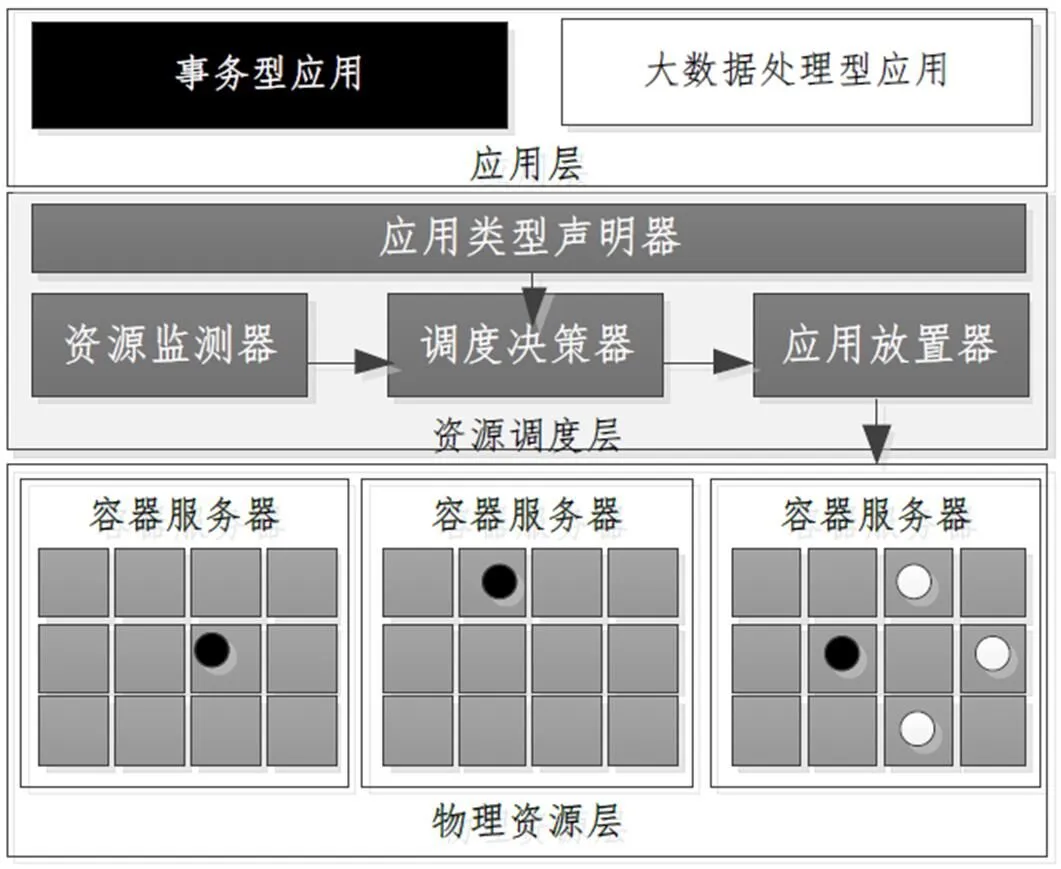
图1 体系结构
应用声明器: 用户在部署应用的时候, 需要显示声明应用的类型是事务型, 还是大数据处理型, 见1.2节;
资源监测器: 用于监测物理资源的使用率, 基于开源监测软件Zabbix实现;
调度决策器: 考虑资源空闲和应用类型两个维度因素, 采用多队列模型进行刻画, 并实现相关的资源调度算法, 见第2节;
应用放置器: 依据调度决策器输出结果, 调用容器暴露API进行应用放置, 构建应用与物理资源的映射关系.
1.2 应用声明器
1.2.1手动设定
本文应用App由向三元组刻画应用
ComponentSet采用有向无环图进行刻画, 用于描述应用组件的规模, 以及各个组件的资源需求. 其中, 点代表应用组件实例, 点的属性包括资源需求, 由二元组

图2 体系结构
1.2.2自动识别
相关研究工作尝试自动识别并挖掘应用构成, 这些方法通常采用代理机制, 适用于离线测试阶段, 其核心思想是将Agent部署在容器中, 监测和记录网络交互信息, 采用PCA等算法过滤噪音数据, 基于图模型分析获取容器(及其应用组件)的关联关系.
2 各模块的算法设计与实现
2.1 基于多队列资源调度机制
如图3所示, 资源调度器由多队列模型组成, 分别实现公平性资源调度算法和延迟敏感调度算法, 以满足公平性或性能目标, 其具体流程:
① 根据应用声明
② 如果应用为事务型, 调用公平性调度算法, 最终通过容器API, 构建应用组件与容器服务器的映射关系, 见2.2节;
③ 如果应用为大数据处理型, 调用延迟敏感调度算法, 最终通过容器API, 构建应用组件与容器服务器的映射关系, 见2.3节.

图3 基于多队列资源调度机制
2.2公平调度算法SAF
公平性资源调度算法的核心思想是均衡, 将容器服务器根据资源的空闲状态进行排序, 将应用中每个组件依次进行调度, 每次调度将应用组件部署在资源空闲的容器服务器上.

算法1. 公平调度算法SAF 输入:A set of physical machine PMSet; A specified application App.输出:The relationship between componenets and PMSet f(componenet,PMSet),, where componeneti∈App.1. For componeneti in App 2. PMSet=DescendingSort(PMSet)3. PMj = PMSet.remove(0)4. PM = PM − Attr(componeneti)5. PMSet.add(PMj)6. Add f(componeneti,PMj)7. End For
算法1为公平调度算法SAF(Scheduling algorithm based on fairness)实现, 遍历应用包含的所有组件componenet, 然后根据容器物理主机的资源空闲进行降序排列, 则第一个元素即为最为空闲的容器主机(第1行-2行). 将应用组件调度到资源最后空闲的容器主机上, 同时更新该容器主机的空闲资源状态, 并记录下此时应用组件和容器服务器的关联关系(第3行-6行).
2.3公平调度算法SAL
公平调度算法SAL(Scheduling algorithm based on latency-aware)是一种延迟敏感的资源调度算法, 其核心思想是优先将应用组件调度到相同的容器物理机上, 即最大资源利用率每台容器物理服务器.
算法2为公平调度算法SAL实现. 首先根据容器物理主机的资源空闲进行降序排列, 则第一个元素即为最为空闲的容器主机(第1行-2行). 遍历应用包含的所有组件, 优先调度到相同的容器物理服务器上, 直到该容器服务器资源饱和, 此过程中记录下应用组件和容器服务器的关联关系(第3行-5行, 第9行). 如果容器服务器资源饱和, 且此时还有应用组件未被调度(6行-8行), 则重新根据容器物理主机的资源空闲进行降序排列, 选择空闲的容器服务器接着调度, 直到应用组件全部调度完成为止.

算法2. 公平调度算法SAL 输入:A set of physical machine PMSet; A specified application App.输出:The relationship between componenets and PMSet f(componenet,PMSet),where componeneti∈App.1. PMSet =DescendingSort(PMSet)2. PMj = PMSet.remove(0)3. While PMj > 04. For componeneti in App 5. PM = PM − Attr(componeneti)6. If(PMj<0)7. PM = PM + Attr(componeneti)8. Break;9. Add f(componeneti,PMj)10. End For11. PMSet.add(PMj)12. PMSet =DescendingSort(PMSet)13. PMj = PMSet.remove(0)14. End While
3 实验与验证
实验包括三个部分, 首先是实验环境的介绍, 接着对比SAF和SAL算法在事务型应用场景下, 性能的差异性; 最后对比两种算法在大数据处理应用场景下, 吞吐率的差异性. 从而验证本方法的有效性. 其中SAF算法本质是公平调度, 可反映Kubernetes、Omage等系统的资源调度效果; SAL算法本质为延迟敏感, 可反映Apollo、Nomad和DelaySchedule的资源调度效果.
4.1 实验环境与负载
如图4所示, 实验环境由21台刀片机组成, 每台刀片的配置都是16 cores, 2.4GHz Intel Xeon CPU和24G内存: 其中10台刀片作为HDFS服务器; 10台刀片安装容器软件, 用于部署容器, 1台刀片作为负载发生器, 模拟用户进行压力测试, 1台刀片安装本文所述应用敏感的资源调度器. 所有刀片设备之间通过千兆交换机互联.

图4 实验环境
事务型应用采用TPC-W基准测试, 前端Web服务器组件选用HttpServer 2.0, 中间应用服务器组件tomcat 8.0, 后端数据库服务器组件选用Mysql 5.6, 数据库采用默认设置, 即10 000件商品和1 440 000个用户. 上述应用组件均部署在2CPU和2GB内存的容器中. 其中, 工作负载来源于1998年法国世界杯网站, 分别模拟50、175、250和325并发用户, 图5所示.

图5 事物型负载
大数据处理应用采用WordCount和Sort两类基准测试, 数据存在HDFS中, 前者数据总大小为10GB, 后者数据总大小为1GB, 且应用组件均部署在2CPU和2GB内存的容器中. 表1给出了相关的配置.

表1 Hadoop基础测试配置表
4.2 事务型应用场景下本方法有效性
本方法调度事务型应用时会采用SAL算法, 而Kubernetes、Omage等系统会默认采用SAF算法. 因此, 本方法与Kubernetes、Omage等系统资源调度算法对比本质可转换为事务型应用在两种调度算法下的性能(响应时间刻画)差异如图6所示.

图6 SAL和SAF算法下事务型用性能对比
随着并发用户的增加, 事务型应用在SAF算法和SAL算法下的响应时间的比例差异越大, 最大可达到近3倍. 这是因为响应时间度量指标是指用户请求经过TPC-W测试基准Web服务器、应用服务器、数据 库服务器处理, 最终返回用户的总延迟时间总和. 采用SAL算法, 由于应用组件调度在相同容器物理服务上, 其延迟时间仅仅为SAF算法跨主机的网络延迟是少1/4.
4.3 大数据处理应用场景下本方法有效性
本方法调度事务型应用时会采用SAF算法, 而DelaySchedule等系统会默认采用SAL算法. 因此, 本方法与DelaySchedule等系统资源调度算法对比本质可转换为事务型应用在两种调度算法下的性能(吞吐率刻画)差异如图7所示.
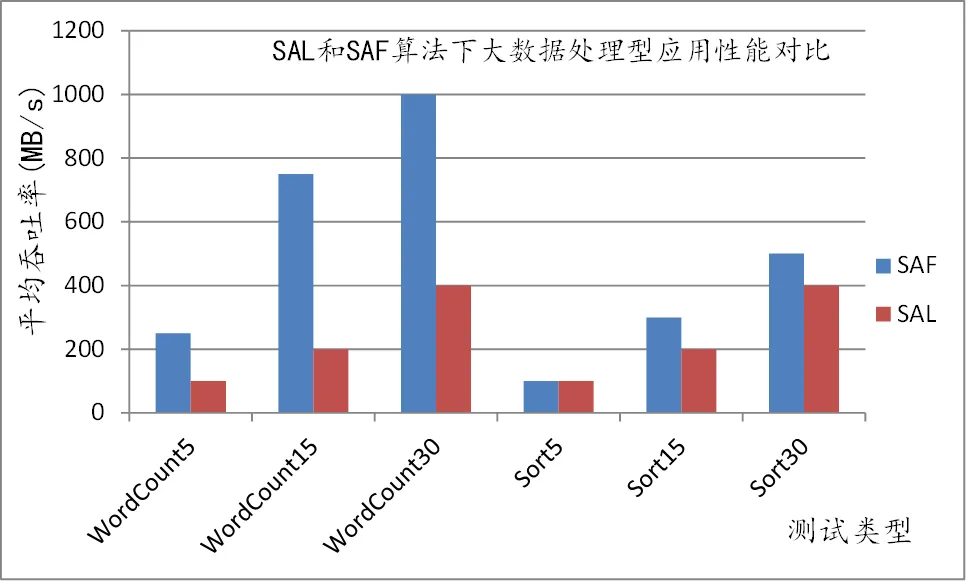
图7 SAL和SAF算法下事务型应用性能对比
无论是WordCount测试基准, 还时Sort测试基准, 随着Map实例数增加, Map阶段在SAF算法和SAL算法下的吞吐率的比例差异越大, 其中WordCount非常明显, 最差可相差2.5倍. 这是因为实验环境全部是千兆网络, SAL算法会将应用组件优先调度到相同容器物理服务器上, 而单台容器服务器理论网络吞吐率上限为125MB/s, 会Hadoop应用实例会因为网络资源竞争而成为瓶颈. 仔细分析实验数据, 单个WordCount的Map阶段吞吐率约为50MB/s, Sort约为20MB/s. 在SAL算法下, 由于Hadoop应用每个实例的资源配置为2CPU和2GB内存, 即每台容器服务器可部署7个WordCount实例和Sort实例, 故导致资源瓶颈.
4 结语
资源调度作为容器管理的关键技术之一, 已有研究工作难以同时适用大数据处理应用和事务型应用场景. 本文提出应用感知的容器资源调度方法, 其核心思想是采用多队列模型, 兼顾两种场景. 实验结果显示本方法具有有效性. 本文下一步工作拟开展基于学习的应用类型自动识别技术, 进一步提高本方法的实用性.
1 Abraham L, Allen J, Barykin O, et al. Scuba: Diving into data at facebook. Proc. of the Vldb Endowment, 2013, 6(11): 1057–1067.
2 Ananthanarayanan G, Agarwal S, Kandula S, et al. Scarlett: Coping with skewed content popularity in MapReduce clusters. In EuroSys, 2011: 287–300.
3 Akidau T, Balikov A, Bekiro, et al. MillWheel: Fault-tolerant stream processing at internet scale. Proc. of the Vldb Endowment, 2013, 6(11): 1033–1044.
4 Andersen DG, Franklin J, Kaminsky M, et al. FAWN: A fast array of wimpy nodes. Communications of the ACM, 2011, 54(7): 101–109.
5 Petrucci V, Laurenzano M, Doherty J, et al. Octopus-man: QoS-driven task management for heterogeneous multicores in warehouse-scale computers. 2015 IEEE 21st International Symposium on High Performance Computer Architecture (HPCA). IEEE Computer Society. 2015. 246–258.
6 Aksanli B, Venkatesh J, Zhang L, et al. Utilizing green energy prediction to schedule mixed batch and service jobs in data centers. Association for Computing Machinery, 2011: 53–57.
7 Marchukov M, Song YJ, Bronson N, et al. TAO: Facebook’s distributed data store for the social graph. Proc. of the 2013 USENIX Conference on Annual Technical Conference. USENIX Association. 2013. 49–60.
8 Baker J, Bond C, Corbett J, et al. Megastore: Providing scalable, highly available storage for interactive services. 5th Biennial Conference on Innovative Data Systems Research (CIDR ’11). Asilomar, California, USA. 2011. 223–234.
9 Baumann A, Barham P, Dagand PE, et al. The multikernel: A new OS architecture for scalable multicore systems. ACM Sigops, Symposium on Operating Systems Principles. ACM. 2009. 29–44.
10 Belay A, Bittau A, Mashtizadeh A, et al. Dune: Safe user-level access to privileged CPU features. Symposium on Operating Systems Design & Implementation (OSDI). 2012. 335–348.
11 Schwarzkopf M, Konwinski A, Abd-El-Malek M, et al. Omega: Flexible, scalable schedulers for large compute clusters. ACM European Conference on Computer Systems. ACM. 2013. 351–364.
12 Tune E. Large-scale cluster management at Google with Borg. Proc. of the 10th European Conference on Computer Systems. ACM. 2015. 18.
Application-Aware Container-Oriented Resource Scheduling Optimized Approach
LU Zhi-Gang1,2,3, WU Yue-Wen1,2, GU Ze-Yu1,2, WU Qi-De4
1(Institute of Software, Chinese Academy of Sciences, Beijing 100190, China)2(University of Chinese Academy of Sciences, Beijing 100049, China)3(SIP State Property Holding Co. Ltd., Suzhou 215028, China)4(University of Science and Technology of China, Hefei 230026, China)
Resource scheduling is a key technique for container management. Prior work or meets the goal of fairness, the work load average is scheduled to all physical nodes, pays attention to the throughput indicator; or to meets performance targets, multiple carrier scheduling the workload related to physical nodes in the same or similar, pay attention to the response time. In this paper, it presents an application-aware resource scheduling approach, and employs a multi-queue model to meet both fairness and performance targets. Experimental results show that the approach has equal throughput for typical big data processing scenarios, and can reduce latency by up to 100% for typical transactional application scenarios.
application-aware; container; resource scheduling; big data; transaction-based web
2016-06-16;
2016-07-19
[10.15888/j.cnki.csa.005621]
猜你喜欢
节能与环保(2022年7期)2022-11-09
读者·校园版(2019年24期)2019-12-10
计算机技术与发展(2019年11期)2019-11-18
福建基础教育研究(2019年6期)2019-05-28
外语教学理论与实践(2019年1期)2019-03-11
计算技术与自动化(2017年3期)2017-10-26
计算机应用(2016年10期)2017-05-12
科技创新与应用(2017年3期)2017-02-18
考试周刊(2016年82期)2016-11-01
小朋友·聪明学堂(2015年8期)2015-11-30
