
基于时间感知的页面排序算法的改进
2017-03-21 05:10:20,,,,,
中华医学图书情报杂志 2017年1期
,, ,,,
互联网网页的信息大多都具有时效性,而搜索引擎在处理具有时间属性的查询还存在一定的问题[1-3]。比如,2016年10月,在百度中输入“十大电影排名”时,首先出现的是近期上映的电影,然后才出现近年的“十大电影排名”搜索结果,前几条记录均是2015年、2014年发布的消息,2016年发布的消息则排到第6条记录。搜索引擎并不能对用户查询信息时间敏感性的要求对信息进行加工与处理[4],显然结果不能让用户满意。于是利用时间感知对信息搜索结果进行排序的研究显得很有必要。
1 国内外时间感知页面排序算法的研究
有关时间感知的查询,目前已有部分学者进行了相关研究。ShengLin[5]等人提出了一个关于时间感知的页面排序算法,用一个四元的方式来表示文档的时间,通过页面时间与查询时间之间的比较,获得两时间之间的相似度,从而获得基于时间感知的页面排序算法。他们运用了6 455 985组数据进行实验,其中含有显式时间的数据有3 763 923组(占58%),隐式时间的数据有2 692 062组(占42%),实验结果显示,查询的精确度较没有运用此算法之前至多提高了15.13%。在国内,在张乃洲等人[6]也研发出了一种基于时间感知的搜索引擎模型[3]。该模型主要分为页面时间属性抽取器、时间感知查询处理模块、基于时间感知的页面排序模块三大部分,其中运用到时间粒度来对页面与查询间的时间相关度进行计算,最后通过时间感知度因子权衡得出结果页面的排序算法。在页面时间属性抽取部分,对于含显式时间的页面其抽取精度可达0.93,然而对于隐式时间的页面抽取精度仅为0.76。查询结果显示,除了个别查询外,大部分查询的精度值都可得到不同程度的提升,提升幅度与Google原始查询的精度值有关。例如某一查询类型为月的查询从初始的精度值约0.4提高到约0.8,而另一查询类型为日的查询(如汽油价格)初始值已达1.0,改进后仍然为1.0。此外,该实验加入了查询结果序关系对排序结果影响的AP指标,即排序算法对排序结果的作用。
随着互联网信息的不断更新,用户对信息时效性的追求越来越高。在页面的排序算法中融入时间属性可让用户获得更加满意的结果,同时使搜索引擎更加精确、更加智能化,提高用户对搜索引擎的使用率。本文针对目前页面排序算法存在的不足,融入时间属性及个性化服务对排序算法进行改进。
2 改进的时间感知算法
2.1 基本思路
在获得了查询的时间信息后,对页面进行融合了时间属性的查询时,本文将采用公式(1)来对查询结果进行排序:
ST(D,Q)=(1-ω)*S(D,Q)+ω*Stemporal(D,Q) (1)
其中,D代表文档,Q代表用户的查询,Stemporal(D,Q)代表查询时间和页面内容时间之间的相关性强度,用公式进行表示:Stemporal(D,Q),其中Sk是常数,需根据查询词条所涉及的时间粒度来决定;Tq代表当前查询词条所包含的时间;Td则代表数据库所含页面的内容所表达的时间。S(D,Q)是由排序算法获得的D和Q之间的相关程度,为了使它的取值介于0和1之间需对两者的相关度进行标准化处理。张乃洲等学者[3]在此处运用PageRank算法得出S(D,Q),但是PageRank算法存在同类网页间连接较少和对用户没有区分(无法感知不同的网页对不同用户的重要性的不同)等不足。
本次基于时间感知排序算法的改进从此处着手,运用改进后的PageRank算法得出S(Q,Q)。对原始的PageRank算法加入用户投票计算“P_VRank”,加入用户模型向量计算“P_URank”值,使改进后基于时间感知的页面排序算法实现个性化服务,更好地满足用户的需求。ω是一个用来表示时间感知度的大小的因子,它的取值与用户键入的查询有关——如果用户键入的查询具有对时间的要求,则ω的取值较大,如果用户键入的查询对时间要求较低,则 的取值较少。
本次改进算法的基本思想是在原有算法的基础上,通过加入“用户投票计算”(P_VRank)和“用户模型向量计算”(P_URank),为用户实现查询的个性化服务,使查询结果的排序更加地贴切不同用户的需要,提高用户对搜索引擎的满意程度。本改进算法的主要工作原理是通过一个时间感知度因子ω来控制查询与页面之间相关度S(D,Q )和查询与页面内容之间的时间相关度S(Q,D )两者间的比重。对于基于时间感知的查询,Stemporal(D,Q)的值较大,ω所占到的比重较大;对于基于非时间感知的查询而言,ω则取值较小,S(D,Q )占到的比重较Stemporal(D,Q)大。
2.2 改进方法
关于基于时间感知页面排序算法的改进针对部分的获取主要分为2个步骤:一是参照PageRank算法的原有思想,形成一个投票分值加入到影响Rank值得计算当中去,得到被修改后的Rank值即P_VRank值;二是将网页的页面质量与用户兴趣模型数据相互结合获得P_URank值。
2.2.1 获得P_VRank值
超链接是PageRank算法的核心,通过网页之间的链接,获得质量较高的网页来反馈给用户。这仅仅是从商家的角度进行链接分析,不仅不利于同类网页之间的公平竞争,而且没有顾及到用户的反馈,缺乏全面性。因此引入字段Vote来表示用户对网页的投票,把用户对网页的反馈添加到网页的质量评估当中去。用户对该网页表示满意好评的,该网页的Vote值对应地加1;用户对该网页不满意表示差评的,则该网页的Vote值相应地扣掉1。一个月结束时对各网页的Vote值进行统计,最后与原有的PageRank算法融合获得P_VRank值。这一步的数据计算量较大,计算结果表现的是从商家和用户两个方面反映出来的页面质量,得出的页面质量评估结果更为精准。具体的过程如下:
一是通过PageRank算法获得网页的质量排名(PageRank),计算公式如下:
PRi=(1-d)/N+d(PR(T1)/C(T1)+PR(Tn)/C(Tn)) (2)
二是获得网页的投票排名(VoteRank),计算过程分为两步:
首先,计算出某一网页(i)的Vote值(得票数)在全体的Vote值总和当中所占的比例,用WRi表示,见公式(3)。
然后,比较前一步得出的VRi的获得最大值VRmax,利用步骤(1)中获得的PR值对VR值得权重进行评估,从而VR拥有与PR相同的比重,见公式(4)。
三是融合PR值和VR值,形成获得一个新的Rank值,用P_VRank表示,计算公式如下:
P-VRank=z·VR+PR(5)
i为阻尼系数,目的是将用户投票对排序结果产生的影响控制在一定的范围之内,以避免PR和VR出现某一方面决定排序结果的情况。暂且对i取值为0.6,这一数值还需通过后续的大量实验进行考证。
通过上述三大步骤获得的结合用户和商家两者反馈的页面质量排序结果较单独的PageRank算法获得的排序结果更为科学精确,但这个结果对于每一个用户来说都是一样的,没有体现出个性化服务。
2.2.2 获得P_URank值
在获得P_URank值的这一步骤的计算中,虽然是计算量较小的计算,但是在用户发出请求后进行,需牺牲程序的运行效率来进行处理。通过使不同用户间即使在查询栏键入相同的查询词,不同的用户间所得到的查询结果也是不一样的,使用户在前几页就能获得满意的结果。
此处需要运用到“用户兴趣向量”,此向量经过一段时间的获取、统计、计算后可以挖掘、反映出某一用户的兴趣所指。通过这一向量,系统获得了某一用户对某一类别页面的兴趣程度,再把页面的内容与用户的兴趣向量进行相似度比较(相似程度较高且页面质量较高的网页的P_URank值较高,相似程度低且页面质量较低的网页的P_URank值较低),最后根据P_URank值对结果页面进行排序,获得的排序结果中,用户感兴趣的、最需要的页面排名在前,给用户提供的个性化的结果排序。初步获得的计算过程(见公式6)如下:
IFnQ==niη=1ELSEη=0
上述公式中,ηi和ηq分别表示页面 和用户兴趣分类 的分类号。如果两者相等,表明该页面符合用户的兴趣类型,则用公式(6)计算。tq表示该用户对于某一类别页面的认可程度大小,用数值表示,用户对页面表示认可则 值加1,反之则减1;N是页面分类的总和。计算时,先获得用户对某一类页面的感兴趣程度,再与P_VRank进行乘积运算,最终得出关于这个页面的一个可以体现用户个性化需求的P_URank值。
然而,因为上述算法中带有IF语句,在算法的编写过程中,若先出现IF、ELSE、SWITCH等语句,将会大大地降低算法的运行效率。为了减少这些语句的出现,需对上述计算过程进行优化,优化后的计算过程如下:
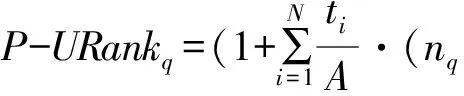
为了避免在后续计算中频繁重复地计算该用户对所有类别认可程度之和,先对该值进行统一的运算并记为A。用nq与ni之间的同或来代替IF语句的使用,提高了算法的运行效率。通过优化后的计算,大大地提高了每个页面对应的P_URank值的获取效率,最后根据获得的每个页面的P_URank值进行页面排序使排序结果更加符合用户的需求。
3 实验分析
3.1 实验方案
整个实验系统主要分为两大模块,第一大模块是根据用户的查询词对数据文档提取形成候选文档数据库,第二大模块则是按照不同的算法对候选文档数据库当中的文档进行重新排序并把结果反馈给用户。具体实验系统框架如图1所示。
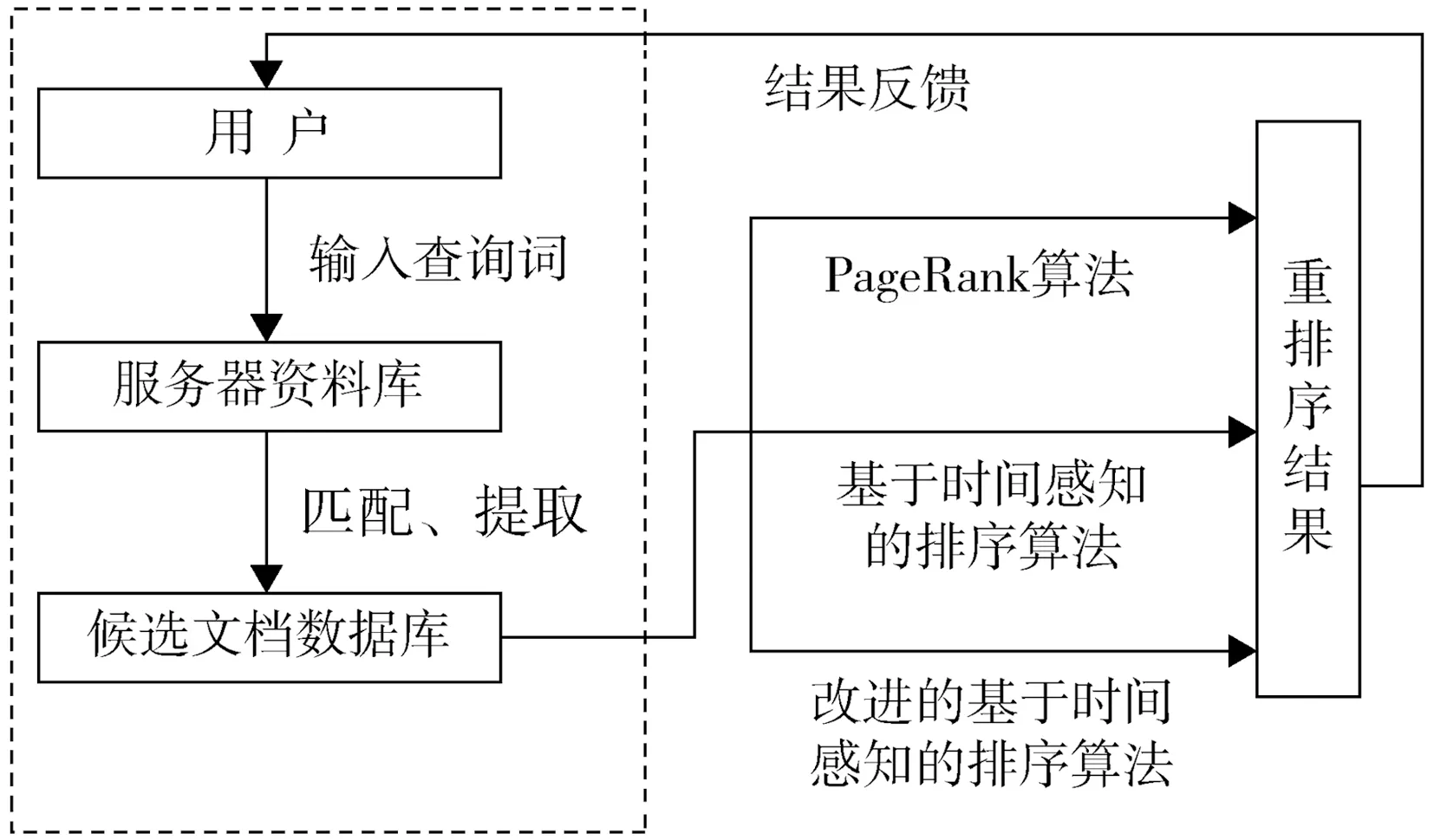
图1 实验系统整体框架
如实验系统整体框架图所示,用户键入查询词后,系统将从服务器资料库中检索与查询词相匹配的文档,并将该文档存入到候选文档数据库中,然后根据不同排序算法的不同排序规则对候选文档数据库当中的文档进行重新排序的工作,最终把重新排序后的文档排序结果反馈给用户。
3.2 实验结果
下面分析针对“麦当劳”这一查询词3种算法的搜索结果中排名前40%的文档,从文档内容时间、文档类型、文档质量等3个方面对3种排序算法进行综合评价。
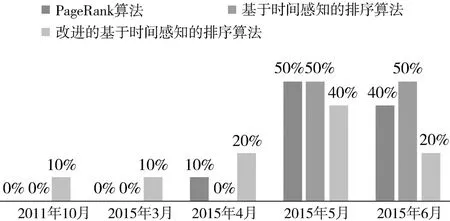
图2 文档时间分布比例
如图2所示,PageRank算法获得的文档内容时间集中分布在最近的两个月,然而也有10%的文档内容时间为2015年4月。其中时间为2015年5月的文档数最多;基于时间感知的排序算法获得的文档内容时间分布中,时间为2015年6月出现的比例为50%,是3种算法中比例最高的,剩余的50%也分布在较近的时间2015年5月,时间距今较近。改进后的算法获得的文档时间分布范围较广,整体数据呈负偏态分布,文档整体的平均时间较前两种算法低,但文档出现的高峰在2015年5月,众数值较前两者变化不大。总的来说,在文档时间分布方面,基于时间感知的排序算法表现较好,改进后的算法表现也不差,虽然分布范围较广,但文档的时间分布仍集中在较新的时间。
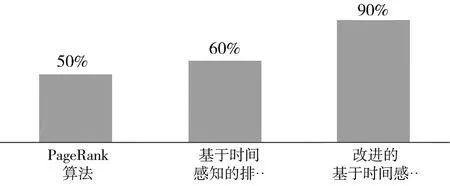
图3 符合用户兴趣类型的文档比例
如图3所示,由PageRank算法获得的结果文档的前40%的文档中,符合用户兴趣类型的文档所占比例达到50%,单独来看,该值处于中等水平;基于时间感知的排序算法获得的前40%结果中,符合用户兴趣类型的文档达60%,较前一算法有10%的提高,差距不大。改进后的算法给出的前40%文档中,符合用户兴趣类型的文档高达90%,与PageRank算法的结果相差40%,与基于时间感知的排序算法的结果相差30%,改进后的算法在用户兴趣类型匹配上有了很大的提高。在文档类型与用户兴趣类型匹配,改进后的算法表现最好,与其他两种算法都拉开了较大的差距。
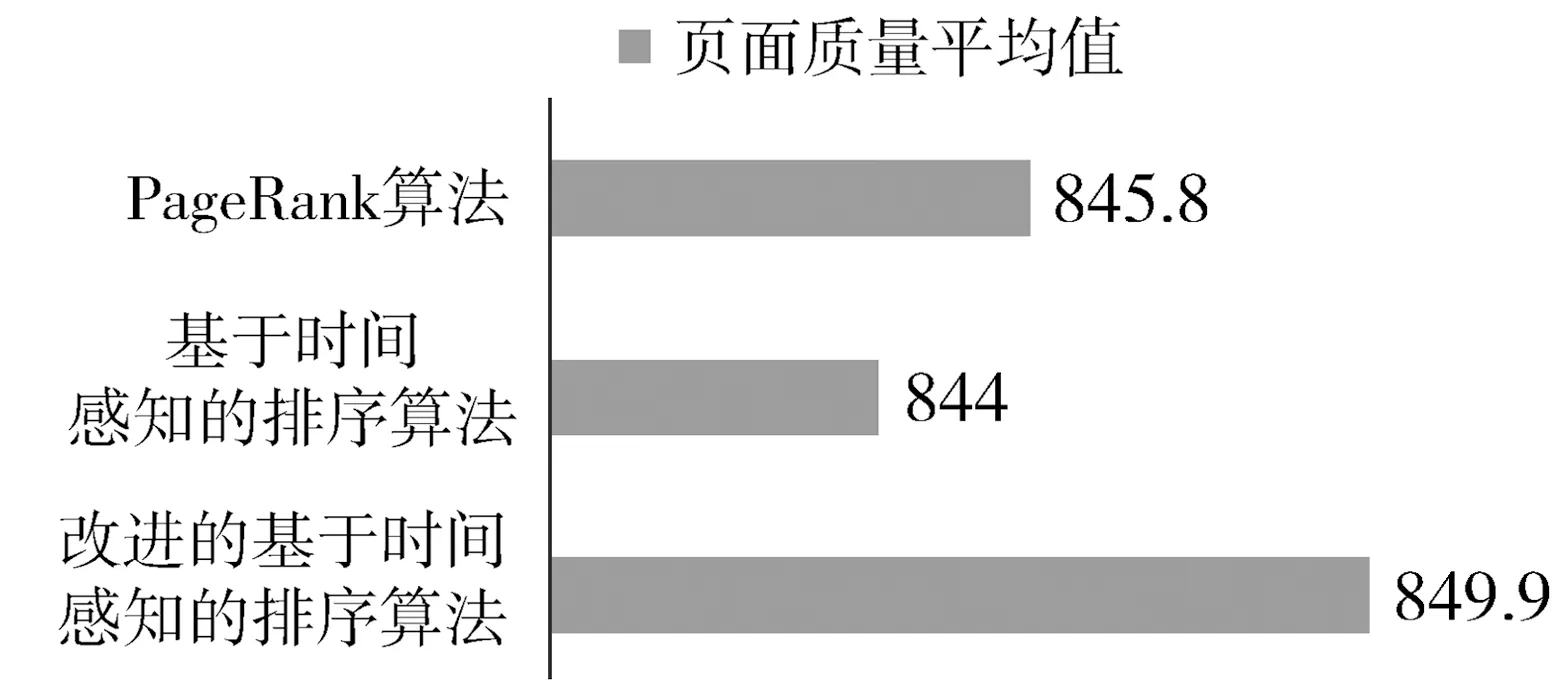
图4 页面质量均值图
由图4可以看出,在获得的前40%结果文档中,3种算法得出的文档的页面质量均值整体水平较高,三者之间相差不大。其中由基于时间感知的排序算法获得页面质量均值稍低为844;PageRank算法获得的均值较基于时间感知的排序算法获得的均值高出1.8,两者之间没有太大差距;改进后的算法获得的页面质量均值是849.9,比PageRank算法高出了4.1,与基于时间感知的排序算法相比高出了5.9,相比之下有较大的提高。在页面质量这一方面,改进后的算法表现较好,与其他两个算法之间的差距相对较大。
通过以上3个方面对3种算法结果的分析,可以看出,改进后的算法在文档内容时间与前两者相差不大的情况下,在文档类型与用户兴趣类型匹配、文档页面质量这两方面都有较大的提升。
4 结语
通过对页面排序算法的改进,使页面排序算法在时效性和个性化服务方面有了一定的提高,但仍然存在不足。如改进算法中只是把查询时间和页面的内容时间的相关度进行比对研究,未考虑页面的更新时间。为了进一步加强算法,全方位地提高搜索引擎的性能,应将重点放在以下方面:如何把页面的更新时间和内容时间结合在一起为查询结果排序提供参考,就算法的运行效率方面进行反复的思考优化,以缩短算法的响应时间,提高搜索引擎的查询效率。
猜你喜欢
保健医苑(2022年1期)2022-08-30 08:39:14
中国新闻周刊(2021年26期)2021-07-27 04:02:12
电子制作(2018年10期)2018-08-04 03:24:38
电子制作(2017年2期)2017-05-17 03:54:56
信息安全研究(2016年4期)2016-12-01 06:06:54
电子测试(2015年18期)2016-01-14 01:22:58
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
计算机与网络(2014年7期)2014-03-25 10:57:07
电脑迷(2012年4期)2012-04-29 06:12:13
电脑爱好者(2011年11期)2011-06-22 08:20:18
