
基于整数线性规划的商家属性抽取研究
2017-03-12 08:31孙庆英王中卿朱巧明周国栋
中文信息学报 2017年6期
孙庆英,王中卿,朱巧明,周国栋
(1. 苏州大学 计算机科学与技术学院,江苏 苏州 215006;2. 淮阴师范学院 计算机科学与技术学院,江苏 淮安 223300)
0 引言
随着互联网上用户活动的日益频繁,人们通过在Yelp、大众点评等网站或客户端发表对美食或产品的评论,给其他用户和商家提供决策支持。因此针对用户产生的在线评论进行情感分类[1-2]、评价对象抽取[3-4]、评论星级预测[5-6]、自动推荐[7-8]等成为研究热点。
以往情感分析的研究主要针对文本的情感极性抽取,或者是评价对象抽取等,但是对于商家属性分析却很少。商家属性是指商家本身具备的一些属性,比如是否可用信用卡、是否提供停车位、是否支持外卖等。通常来说,商家属性对用户有很大的帮助,比如说用户开车去就餐,就会关心饭店是否提供停车位;带着孩子就餐,就会考虑这家饭店是否适宜孩子;喜欢清静的人会考虑就餐环境是否安静。本文中,我们从商家评论文本中抽取商家属性,我们具体抽取了如下五种属性: 是否适宜孩子(good for kids)、环境是否安静(noise level)、是否适宜午餐(good for lunch)、是否有打折的欢乐时光(happy hour)、是否有服务员(waiter service)。通常来说,商家属性之间是有关联的,比如说适宜孩子的饭店环境相对安静,开门后削价或免费供应饮料的商家,可能会有服务员提供服务等。因此,在学习预测模型的时候,我们需要考虑商家属性之间的关联,从而进行协同学习。整数线性规划在文本处理和数据挖掘中已经有了广泛的应用[9-11],该方法一般可以将不同类别之间的关联抽象成不同的约束条件,进行协同优化学习。因此,在本文中,我们利用整数线性规划将不同的商家属性进行关联。我们这个模型的流程为,首先基于最大熵分类器抽取评论中不同的商家属性;其次,我们利用整数线性规划模型,通过添加不同属性之间的关联约束条件,对整个模型进行协同优化学习。实验证明了经过整数线性规划优化后的准确率、召回率、F1值都有提高。
以下各节内容组织如下: 第1节介绍情感分类、评价对象抽取等相关工作,第2节介绍本文的研究内容和使用的研究方法,第3节介绍实验设置和相关结果,第4节总结本文内容,展望未来工作。
1 相关工作
针对用户产生的评论文本进行分析研究已经开展多年,主要有情感分类、评价对象抽取、评论星级预测、自动推荐等工作,下面我们主要对与本文相关的情感分类和评价对象抽取的相关工作进行总结。
对用户评论文本的情感分类研究主要为文档级的,主要有两种方法: 有监督和无监督的机器学习方法。已有的有监督的机器学习方法被广泛应用于情感分类,比如贝叶斯、SVM、最大熵[12-14]等。近年来,深度学习的方法被应用于情感分类,取得了很好的效果,比如Tang等提出了一个基于门限循环神经网络模型来进行文档级情感分类的方法,该方法首先用卷积神经网络学习了文档的表示,然后通过门限循环神经网络,将句子的语义及句间的关系编码进文档表示中,在四个大规模的评论数据集上实验,效果有了较大的提升[15]。
关于评价对象抽取,现有的研究主要集中在产品评论的属性抽取,又称为特征抽取。比如: 这幅照片质量非常好,这句评价的对象就是照片的质量。Web上的评论主要有两种形式限制,一种为固定格式的评论,由正方、反方、详细评论三部分组成,正方、反方主要为短语。另一种就是比较自由的形式,一般为比较完整的句子。根据不同的评论形式,分别有不同的特征抽取技术[16-18]。对于第一种评论形式,正方、反方的形式简短,一般为短语或不完整的句子,其中就包含了评价对象,可以采用条件随机场(CRFs),标注提取模式并匹配的方法等[16]。第二种评论通常都是完整的句子,也可以采用前面提到的方法,但效率较差。Hu等提出了一种无监督的学习方法,分为两个步骤,第一步,通过词性标注、词频统计找出常用的名词或名词短语。因人们评论商品特征时,使用的词汇相对集中,很多产品特征都是名词,那些经常被提到的名词往往就是产品特征。第二步,通过识别观点词找到不常用的特征,因同样的观点词可以用来修饰不同的对象特征,可以是常用的特征,也可以是不常用的特征。这样通过识别这些观点词就可以抽取不常用的特征[17]。Popescu等改进了Hu中的步骤一,通过计算识别出的名词和辨别特征词之间的点互信息,去掉了一些可能不是特征的名词[18]。
本文提出的商家属性抽取有别于上面介绍的产品特征抽取。所提出的方法是对商家评论信息进行抽取,商家信息中已经包含了商家的属性信息,这些信息就相当于产品的特征信息,本文从顾客的评论信息中抽取对商家属性信息的判断,比如通过评论信息判断该商家是否提供停车场的属性值。但这些商家属性信息基本都是描述客观事实,不带有情感色彩,有别于基本都带有情感色彩的产品特征。
2 基于整数线性规划的商业属性抽取方法
本文使用的数据来源于饭店评论网站。首先对数据进行预处理,然后针对我们选择的属性,用最大熵分类器对顾客的评论信息进行分类。对于分类结果,我们构建整数线性规划模型进行优化,最后分析比较实验结果,整体研究框架如图1所示,下面详细叙述各个步骤。

图1 整体研究框架
2.1 数据的获取与统计
我们的数据来自于Yelp。Yelp是一个著名的英文商家评论网站,类似于国内的大众点评网。在Yelp提供的数据中包含商家、评论、用户等信息。我们选择了类别与餐饮有关并且包含用户评论的商家信息,一共是30 035个商家及其评论信息。接着对每个商家的评论信息进行合并,选择前20条评论信息,随机选择10 000个商家作为实验数据。这些商家信息中总计包含了37个属性信息,我们统计了每个属性值的分布情况,考虑到部分属性样本数量较少,我们选择了样本数量足够多并且属性之间可能存在关联的五个属性: 是否适宜孩子、环境是否安静、是否适宜午餐、是否有打折的欢乐时光、是否有服务员,作为具体的实验对象。实验数据中这五个属性的正负样本分布情况见表1,商家属性的原始数据表示如图2所示,对于属性值为非布尔类型的数据,我们做了非布尔值到布尔值的处理。
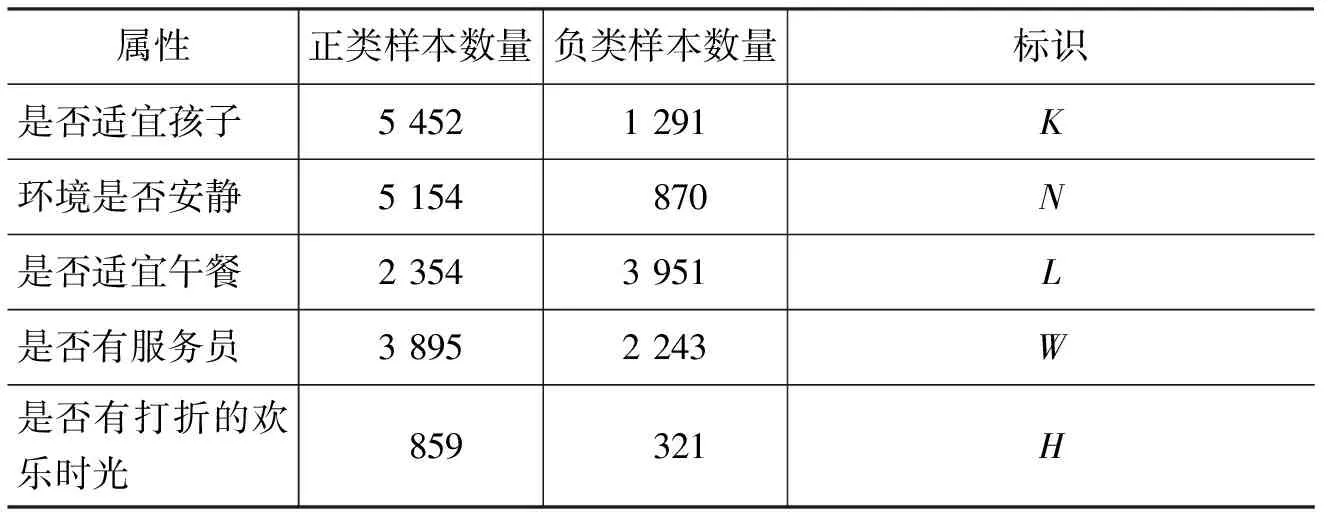
表1 数据集中五个属性的正负样本分布情况

图2 商家属性原始数据表示
2.2 最大熵分类器分类商业属性
最大熵模型在自然语言处理中有很多应用,比如中文分词、词性标注、句法分析、信息抽取、机器翻译等[19-20]。
最大熵模型通过熵的最大化来表示可能性,以达到求解最优解的目的,最大熵模型的优化公式如式(1)所示,其中fi(x,y)为特征集合,wi为每个特征对应的权重,Zw(x)为归一化因子。
本文针对以上提到的五个商家属性,分别构建了一个最大熵分类器。针对每一个商家的评论信息,我们将评论中的每个词作为特征,并赋权重为1,经最大熵模型训练后,可以自动从用户的评论信息中获取商家某个属性的最优分类。
2.3 整数线性规划模型优化分类结果
以上针对每个商家属性独立构造了一个分类器,没有考虑这些属性之间的关联,而这些商家属性通常不是独立的,因此我们构建了一个整数线性规划模型,考虑这些属性之间存在的关联约束,在最大熵分类器的基础上通过协同学习,优化各个属性的分类结果。下面我们从变量定义、目标函数、约束条件几个方面介绍整数线性规划模型。
2.3.1 变量定义
对于不同的商家,可能包含不同的商家属性,每个属性对应的分类是0或1,下面我们定义这样一些变量:
(1)A: 商家属性集合,我们将本文选取的五个商家属性分别用字母标识,具体如表1所示,即{K,N,L,W,H}。
(2)α∈A:A中某一个属性。
(3)B: 商家集合。
(4)b∈B: 某一个商家。
(5)C∈{0,1}: 正负类集合。
(6)c∈C: 正类或负类。
另外,我们定义了如下的整型变量:
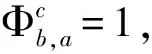
2.3.2 目标函数

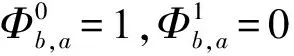
2.3.3 约束条件
我们添加了以下约束条件来确保目标函数获得最大值。


这个约束表达式有个前提条件,就是属性K(是否适宜孩子)对应的分类为正类。
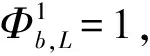
同样,这个约束表达式也有个前提条件,就是属性L(是否适宜午餐)对应的分类为正类。
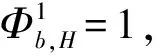
这个约束表达式的前提条件是属性H(是否有打折的欢乐时光)对应的分类为正类。
约束5经统计发现,一般来说同一个商家这五种属性中,至少有一个为正类,我们抽象出如下的约束:
3 实验
3.1 实验设置
本文使用的数据来源于Yelpchallenge官网*http://www.yelp.com/dataset_challenge/。,Yelp提供的数据中包含了商家、用户、评论等实体。商家包含了商家编号、类别、评论数、属性等信息,评论包含了星级、评论文本、商家编号等信息,实验中主要用到了这两类实体。初始数据集包含61 184个商家,我们选择了类别和餐饮有关的30 035个商家样本,随机选择其中10 000个样本,每个商家抽取了不超过20条评论信息。商家的属性包含是否提供酒、环境是否安静、是否适宜孩子、是否允许吸烟等,我们选取了可能存在关联的五个属性: 是否适宜孩子、环境是否安静、是否适宜午餐、是否有打折的欢乐时光、是否有服务员。
分别针对这五个商业属性,我们从10 000个样本中抽出包含某个属性的样本,考虑到正负样本平衡问题,我们选取了同样数目的正负类样本,并将数据平均分成五份,做五倍交叉验证,其中80%用来训练,20%用来测试。最大熵分类器使用MALLET机器学习工具包*http://mallet.cs.umass.edu/。实现,整数线性规划使用lp_solve*http://lpsolve.sourceforge.net/。工具实现。在使用过程中,这些工具的所有参数都设置为它们的默认值。
3.2 实验结果与分析
首先将我们提出的方法和一些基准系统进行比较,进而分析不同的约束条件对实验效果的影响。
3.2.1 和基准系统比较
因没有前人做过本文类似的工作,不便于和前人的工作进行比较,所以将我们提出的方法和大家用得较多的基准系统即最大熵分类器的结果进行比较,分别用准确率(P)、召回率(R)、F1值作为评价指标。具体的,我们和以下方法进行了比较:
(1) ME,用最大熵分类器抽取评论中的不同的商家属性,以评论中的词为特征,对商家属性进行分类;
(2) ILP-ME,本文提出的模型,基于整数线性规划,通过添加约束条件优化ME分类结果。
实验结果如表2所示。
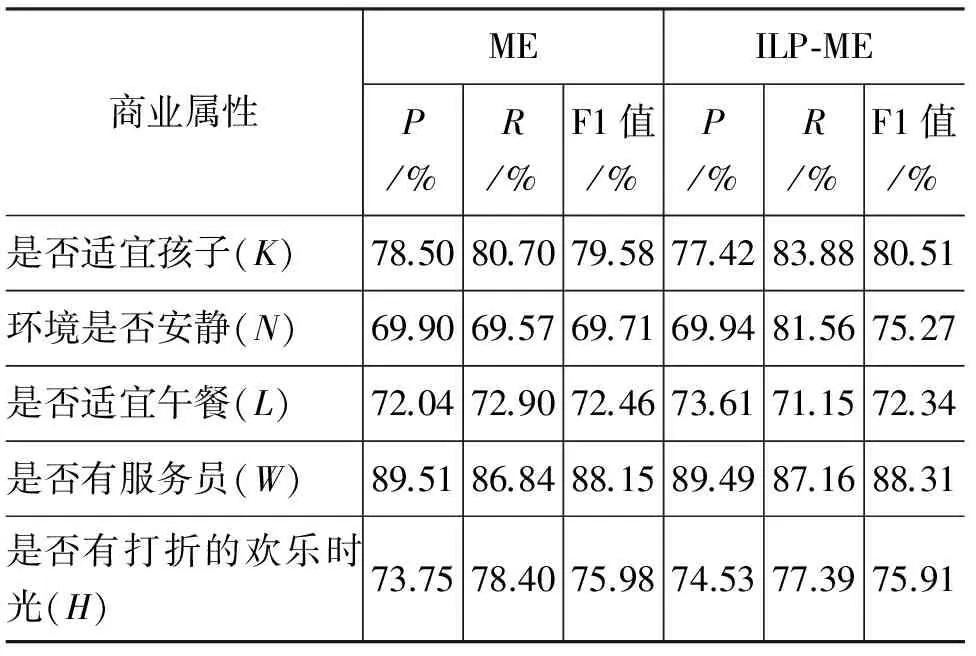
表2 不同模型在商业属性分类任务上的效果
从表2的实验结果可以看出,通过最大熵分类器抽取评论中的商家属性,在准确率、召回率、F1值上都获得了较好的效果,最大熵的结果中环境是否安静(N)属性稍微偏低。本文提出的基于整数线性规划的优化方法,对不同属性在以上几个指标上大部分都有所提高。其中是否适宜孩子(K)属性召回率提高了3.18%,F1值提高了0.93%,环境是否安静(N)属性召回率提高了11.99%, F1值提高了5.56%,是否适宜午餐(L)属性准确率提高了1.57%, 是否有打折的欢乐时光(H)属性 准确率提高了0.78%。总的来说,第一、第二个属性的提升效果较明显,说明在这几个属性上所附加的约束条件在线性规划优化时起到了较好的作用,这几个约束条件考虑了属性之间的关联,比如适合午餐的地方可能更适合孩子,适合孩子的地方环境也可能比较安静,经过这样的约束限制,将错的分类纠正了,从而提高了分类性能。
3.2.2 不同约束条件的贡献分析
在整数线性规划模型中,我们一共加了五个约束条件,为了分析不同的约束条件对哪些商家属性之间的关系抽取有帮助,我们分别设计了一组添加不同约束条件的实验。表3描述了不同的约束条件对ILP-ME模型的贡献情况。具体的,我们对以下方法进行了比较:
(1) ILP-ME(1),只加约束条件(1),(1)是必须加的限制条件,即某个商家的某个属性分类不是正类,就是负类;
(2) ILP-ME(1,2),加约束条件(1,2),约束条件(2): 适合孩子的地方环境比较安静;
(3) ILP-ME(1,3),加约束条件(1,3),约束条件(3): 适合午餐的地方更适合孩子;
(4) ILP-ME(1,4),加约束条件(1,4),约束条件(4): 如果商家提供打折优惠等欢乐时光,一般都需要服务员给顾客提供服务;
(5) ILP-ME(1-4),加约束条件(1,2,3,4);
(6) ILP-ME(1,5),加约束条件(1,5),约束条件(5): 同一个商家这五种属性中,至少有一个为正类;
(7) ILP-ME,加上约束条件(1,2,3,4,5),即本文提出的方案。
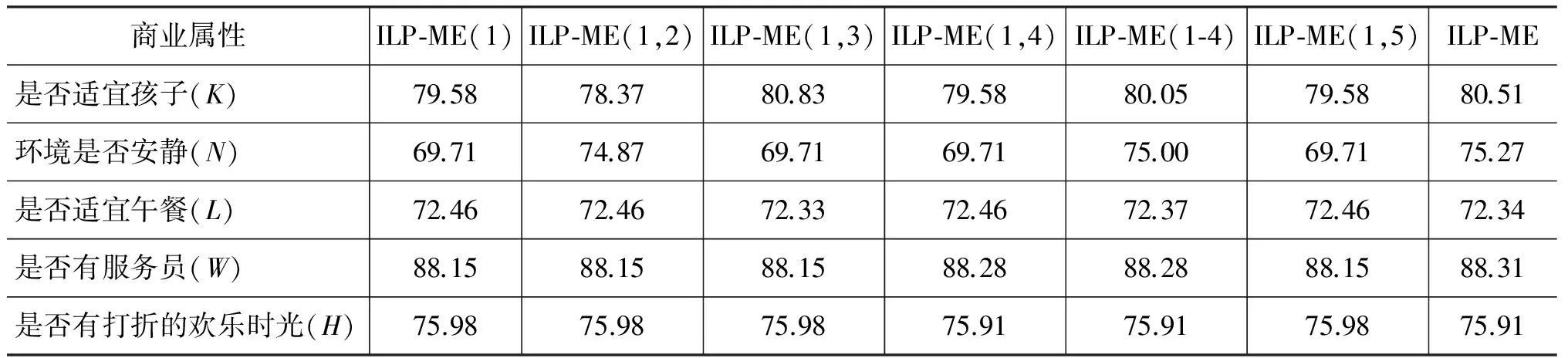
表3 不同约束条件的F1/%值比较
从表3我们可以看出:
(1) 只加约束条件(1)和最大熵的结果是一样的,说明整数线性规划的模型是正确的。
(2) 约束条件(2)、(3)、(4)分别对环境是否安静(N)、是否适宜孩子(K)、是否有服务员(W)属性的分类效果有提升。
(3) 加上所有约束条件后要比单独加每个约束条件效果有所提升。约束条件(2)、(3)合并一起的效果为: 适宜午餐的地方(L)→适宜孩子(K)→环境安静(N),这样形成了一个约束链条,如果属性适宜午餐的地方分类正确,则会提升适宜孩子属性的分类结果,进一步提升环境是否安静属性分类的结果,形成了一个连锁反应,因属性适宜午餐的地方处于链条的顶端,所以提升效果不明显。
(4) 约束条件(4)对属性是否有服务员(W)和是否有打折的欢乐时光(H)提升效果都不明显,说明原本的约束条件“如果饭店有打折的欢乐时光,一般需要有服务员提供服务”的假设并不是普遍现象,对最大熵结果的纠错并没有起到太大的作用。
(5) 单独加约束条件(5)和最大熵的结果是一样的,但不加约束条件(5),加上其他所有约束条件(即方案ILP-ME(1-4))的效果不如所有条件都加上(即方案ILP-ME)的效果,说明约束条件(5)在多个条件约束的前提下起到的效果较好,这时五个属性中至少有一个为正类的可能性更大。
4 结论
本文首次提出基于整数线性规划的商家属性抽取模型,基于最大熵分类器的结果考虑了不同商家属性之间的关联,通过添加关联约束条件,优化了商家属性分类结果。实验结果表明: 添加约束条件后的整体效果要比最大熵模型有所提升,其中是否适宜孩子(K)、环境是否安静(N)、是否适宜午餐(L)三个属性之间构成了一个约束链,提升效果较明显。是否有服务员(W)属性和是否有打折的欢乐时光(H)属性提升效果不明显。下一步计划选取不同的属性组、加入情感信息、寻找其他的约束条件等研究,进一步提升现有模型的性能。
[1] Pang B, Lee L, Vaithyanathan S. Thumbs up?: Sentiment classification using machine learning techniques[C]//Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing. Philadelphia, 2002: 79-86.
[2] 廖健, 王素格, 李德玉, 等. 基于观点袋模型的汽车评论情感极性分类[J]. 中文信息学报, 2015, 29(3): 113-120.
[3] 戴敏, 王荣洋, 李寿山, 等. 基于句法特征的评价对象抽取方法研究[J]. 中文信息学报, 2014, 28(4): 92-97.
[4] Ramesh A, Kumar S H, Foulds J, et al. Weakly supervised models of aspect-sentiment for online course discussion forums[C]//Proceedings of the 2015 Annual Meeting of the Association for Computational Linguistics. Beijing, 2015: 74-83.
[5] Qu L, Ifrim G, Weikum G. The bag-of-opinions method for review rating prediction from sparse text patterns[C]//Proceedings of the 2010 International Conference on Computational Linguistics. Beijing, 2010: 913-921.
[6] Kamath R, Ochi M, Matsuo Y. Understanding rating behaviour and predicting ratings by identifying representative users[C]//2015 Pacific Asia Conference on Language, Information and Computation. Shanghai, 2015: 522 -528.
[7] Kang J S, Kuznetsova P, Luca M, et al. Where not to eat?: Improving public policy by predicting hygiene inspections using online reviews[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Seattle, Washington, 2013: 1443-1448.
[8] 褚晓敏, 王中卿, 朱巧明, 等. 基于简介和评论的标签推荐方法研究[J]. 中文信息学报, 2015, 29(6): 179-184.
[9] 吴龑, 张奇, 黄萱菁. 基于整数线性规划的查询扩展[J]. 计算机研究与发展, 2013, 50(8): 1737-1743.
[10] Li P F, Zhu Q M, Zhou G D. Argument inference from relevant event mentions in chinese argument extraction[C]//Proceedings of the 2013 Annual Meeting of the Association for Computational Linguistics. Sofia, Bulgaria, 2013: 1477-1487.
[11] Kong F, Ng H T, Zhou G D. A constituent-based approach to argument labeling with joint inference in discourse parsing[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha, Qatar, 2014: 68-77.
[12] Blitzer J, Dredze M, Pereira F. Biographies, bollywood, boom-boxes and blenders: domain adaptation for sentiment classification[C]//Proceedings of the 2007 Annual Meeting of the Association for Computational Linguistics. Prague, Czech Republic, 2007: 440-447.
[13] 李本阳, 关毅, 董喜双, 等. 基于单层标注级联模型的篇章情感倾向分析[J]. 中文信息学报, 2012, 26(4): 3-9.
[14] Yang M, Tu W, Lu Z, et al. LCCT: A semi-supervised model for sentiment classification[C]//Proceedings of the Human Language Technologies: The 2015
Annual Conference of the North American Chapter of the ACL. Denver, Colorado, 2015: 546-555.
[15] Tang D Y, Qin B, Liu T. Document modeling with gated recurrent neural network for sentiment classification[C]//Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon, Portugal, 2015: 1422-1432.
[16] Liu B, Hu M, Cheng J. Opinion observer: Analyzing and comparing opinions on the Web[C]//Proceedings of the 2005 International World Wide Web Conference. Chiba, Japan, 2005:342-351.
[17] Hu M Q, Liu B. Mining and summarizing customer reviews[C]//Proceedings of the 2004 ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Seattle, Washington, 2004: 168-177.
[18] Popescu A M, Etzioni O. Extracting product features and opinions from reviews[C]//Proceedings of the 2005 Human Language Technology Conference and the Conference on Empirical Methods in Natural Language Processing. Vancouver, 2005:339-346.
[19] 谷晶晶, 周国栋. 汉语冒号标注与自动识别方法研究[J]. 中文信息学报, 2016, 30(3): 16-22.
[20] Zheng Z G, Meng Y, Yu H. Maximum entropy based lexical reordering model for hierarchical phrase-based machine translation[C]//25th Pacific Asia Conference on Language, Information and Computation. Singapore, 2011: 216-225.
猜你喜欢
电机与控制应用(2022年4期)2022-06-27
计算机系统应用(2021年2期)2021-02-23
电子技术与软件工程(2019年18期)2019-11-18
中等数学(2018年12期)2018-02-16
电子技术与软件工程(2017年14期)2017-09-08
北京航空航天大学学报(2016年6期)2016-11-16
航天返回与遥感(2014年5期)2014-07-31
小朋友·快乐手工(2009年5期)2009-06-11
初中生·作文(2004年9期)2004-09-18
