
一种针对句法树的混合神经网络模型
2017-03-12 08:30霍欢,张薇,刘亮,李洋
中文信息学报 2017年6期
霍 欢,张 薇,刘 亮,李 洋
(1. 上海理工大学 光电信息与计算机工程学院,上海 200093;2. 复旦大学 上海市数据科学重点实验室,上海 201203)
0 引言
文本处理模型大致可以归为三类: BOW(bag-of-words)模型、序列化模型和基于句法树的模型。相对于BOW模型[1-2]词与词间的独立性假设,序列化模型[3-4]考虑了词序信息,并因其突出性能被广泛使用。但前两种模型都忽略了文本自身存在的句法结构,而句法结构对获取文本语义特征相当重要。因此,TreeLSTMs模型[5]是一种针对句法树的LSTMs模型,该模型将顺序处理的LSTM cells按句法树递归排布,使原本o(n)的操作变成o(log(n)),缩短了反向传播的路径,在一定程度上缓解了梯度消失的问题,使模型能够更准确地学习长序列的空间关联性。其中句法树是将句子借助于树形图来说明句中词与词、词组与词组之间的句法、语义和逻辑关系。目前树形结构分为两种: 支持树(Constituency tree)和依存树(Dependency tree),分别如图1(a)和图1(b)所示。其中,图1(a)中加粗箭头表示组合,图1(b)中加粗箭头表示卷积操作。
但TreeLSTMs的缺点也显而易见: 在图1(a)中,为了计算父节点O1的隐藏状态h1和细胞状态c1,首先要获得它两个子节点O2和O3的隐藏状态和细胞状态,然后再加以组合。这种对空间关联性的计算完全限制了TreeLSTMs的并行能力,在需要训练大型数据集的场景下,计算效率成为这一模型首要考虑的问题。

图1 TreeLSTMs和TBCNNs模型示例
相对于TreeLSTMs,TBCNNs[6-7]是一种针对句法树的CNN模型,它的树卷积方法能实现在句法树上的并行化特征提取,训练效率比TreeLSTMs有很大提升。但由于池化操作的空间不变性假设,模型无法在节点间对特征进行组合(故在图1(b)中,h1、h2和h3间无任何箭头连接),导致模型未能充分利用输入序列的结构信息。
由于TreeLSTMs和TBCNNs两种模型存在着互补特性, 本文提出一种针对句法树的混合神经网络模型。该模型以TreeLSTMs为改进对象,借助TBCNNs的树卷积和池化方法实现了类似TreeLSTMs的计算,故将此模型命名为Quasi-TreeLSTMs。模型包含卷积模块和池化模块两个子模块,前者完成非线性变换层和门状态的计算,后者完成剩余的空间关联性的计算。由于池化模块的计算不存在任何参数,因此该模块的计算耗时可忽略不计。两模块一个为模型带来了并行性,另一个则保证了它仍然拥有和TreeLSTMs一样的记忆和组合特征的能力。本文将在情感分类和语义相似性两种自然语言处理任务上对模型进行测试,实验结果表明: Quasi-TreeLSTMs的表现普遍优于TreeLSTMs。
本文其他部分内容如下: 第一节概述TreeLSTMs模型;第二节介绍本文提出的两种Quasi-TreeLSTMs模型,Dependency Quasi-TreeLSTMs和Constituency Quasi-TreeLSTMs;第三节对实验结果进行讨论和分析;第四节介绍相关工作;第五节总结全文。
1 背景知识
考虑到本文的改进对象是TreeLSTMs,本节将对此模型进行概述。图2展示了将Fruit flies like a banana进行解析后的两种句法树。
1.1 针对依存树建模的Dependency TreeLSTMs
针对依存树建模的TreeLSTMs模型,称为Dependency TreeLSTMs。依存树是按照词与词间的句法关系将各个词节点相互连接的句法树,如图2(a)中flies和Fruit由nsubj(主谓关系)标签连接,flies和banana则由nmod(复合名词修饰关系)标签连接。考虑到依存树中每个节点包含的子节点的数量各不相同(有时甚至差异巨大);同时,各个子节点间也不存在任何顺序,因此,Dependency TreeLSTMs在组合各子节点的隐藏状态时采用的方式是全部求和。对某个节点j,该模型通过如下公式计算它的隐藏状态hj。
其中C(j)是节点j所有子节点的集合。
式(2)~(5)分别代表输入门(input gate)、遗忘门(forget gate)、输出门(output gate)和非线性变换层,其中遗忘门需要区分各个子节点k。 它们各自有一组(W,U,b)共享变量,可通过训练进行学习获得。如前文所述,节点j的门状态和线性变换层的计算都依赖式(1)组合其所有子节点的隐藏状态,这种空间的关联性计算正是TreeLSTMs模型难以并行处理数据的根本所在。

图2 句法树示例
1.2 针对N元支持树建模的Constituency TreeLSTMs
针对N元支持树(下面统称为支持树)建模的TreeLSTMs模型,称为Constituency TreeLSTMs。与依存树不同,支持树的叶子节点有序地表示输入序列中的词,而非叶子节点代表的是短语,连接各节点的边上也没有关系标签。如图2(b)中第二层的非叶子节点NP(名词性短语)指的是a banana,第三层PP(介词性短语)再加入叶子节点like,代表like a banana。直觉上,支持树似乎更加符合人们由下至上组合语义的要求。考虑到支持树各个非叶子节点包含的子节点数目都不超过N个,且各子节点间存在着词序,例如,图2(b)表示一个binary constituency tree,即二叉支持树,图中NP代表的是a banana而非banana a。因此Constituency TreeLSTMs在组合子节点的隐藏状态时采用的方式是线性加权。对某个节点j,该模型通过如下公式计算它的隐藏状态hj。
2 混合神经网络模型(Quasi-TreeLSTMs)
受混合神经网络[8-9]的启发,本文提出一种针对句法树的Quasi-TreeLSTMs模型,借助TBCNNs的思想,将影响TreeLSTMs效率的空间关联性计算任务进行拆分,并设计两个子模块——卷积模块和池化模块分别处理。
2.1 卷积模块
本文中卷积模块的任务不是直接提取特征,而是对TreeLSTMs的非线性变换层和门状态进行计算。首先,本文使用Stanford Neural Network Dependency Parser[10]和Stanford PCFG Parser[11]分别将序列解析成依存树或支持树,两种树结构对应Quasi-TreeLSTMs的两个变体Dependency Quasi-TreeLSTMs和Constituency Quasi-TreeLSTMs,分别如图3(a)和图3(b)所示。

图3 Quasi-TreeLSTMs的两个变体
接着,设计一个深度固定为h(本文h=2)且包含m个卷积核(kernels)的卷积窗口,让它在整棵树上滑动,算法过程中对窗口内的子树进行计算。假设现在窗口内的子树上有t个节点,每个节点被赋予一个向量xk∈n。如果是依存树,向量指的是节点词的词向量;如果是支持树,考虑到非叶子节点上没有对应的词,在实验中将为每个非叶子节点初始化一个n维正态分布的随机向量。此时,卷积窗口的输出如下:
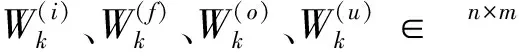
依存树每个节点包含的子节点数目不固定,因此Dependency Quasi-TreeLSTMs可以像TreeLSTMs一样对全部子节点的词向量求和[式(1)],也可以利用TBCNNs的方法,根据父子节点间的句法关系标签[如图2(a)中的nsubj和nmod等]为子节点分配权值矩阵,本文将选择前者。假设此时窗口内子树的根节点为xj,它的子节点数为C(j),具体卷积计算过程如下:
上述计算与式(1)~(5)十分相似,训练参数的个数也相同,但由于获取xk不需任何前期计算,打破了原本的空间关联性限制,使这部分计算得以并行化处理。
类似地,针对支持树的Constituency Quasi-TreeLSTMs的卷积计算过程如下:
当卷积窗口在树上完成一次遍历后,会得到一棵特征树,上面的每个节点保存了卷积获得的非线性变换层和门状态向量。但对于遗忘门,即式(20)和式(24),fjk是保存在它的各个子节点k上的。虽然卷积操作在一定程度上增加了空间复杂度,但只要按批训练时batch大小设置合适,一般不会对训练产生任何影响。
2.2 池化模块
在通过卷积模块获得的特征树上,池化模块要完成空间关联性计算任务。可以看到,式(6)~(7)和式(12)~(13)的计算虽然依赖前一层的计算结果,但过程中不存在任何需要训练的参数,对现在大多数的CPUs/GPUs来说计算任务不大。与TBCNNs中提到的Dynamic Pooling[12]不同,本文将采用一个和卷积窗口类似的池化窗口(深度为2)。因为深度固定可保证计算只在特征树的父子节点间完成,而不会在层级间跳跃破坏空间关联性。计算过程同式(6)~(7)和式(12)~(13),故此处不再赘述。
2.3 目标函数构造

其中m是训练样本中节点数目,λ是L2正则化项超参。
语义相似性任务是两个句子的匹配问题,需要构建两棵树并分别用一个Quasi-TreeLSTMs进行编码。实验中将两树在根节点上的特征向量对(hL,hR),hL,R∈m进行如下组合,获得一个匹配向量hs∈4m, 如式(28)所示。
3 实验分析
实验选择以下两个自然语言处理任务来测试本文提出的Quasi Tree-LSTMs模型的性能: ①情感分类,分析上万条带标签的电影评论的情感倾向;②语义关系,根据语义关系判断句子对是否相似。
3.1 情感分类
数据集介绍本实验使用Stanford Sentiment Treebank数据集[13],该数据集包含一万多条电影评论,所有评论都带有一个人工标记的情感标签,分别如下: 强积极(++)、积极(+)、中立(neutral)、消极(-)、强消极(--)。本文在五分类和二分类两种设置上进行实验: 对五分类任务,按8 544/1 101/2 210的比例将数据集划分成训练集/验证集/测试集;对二分类任务,实验中不考虑标记为中立的样本,将强积极和积极归为一类(+),消极和强消极为另一类(-),最后训练集/验证集/测试集的比例是6 920/872/1 821。
训练参数电脑配置Intel/Xeon E5-2683V3 14核28线程,NVIDIA GTX1080显卡,32GB内存,并使用Tensorflow 深度学习框架实现。
本文的模型初始化和TBCNNs的设置相同,并在验证集上对模型进行超参调优,最后得到如下的训练参数: 模型使用带有300个卷积核且深度为2的卷积窗口和在Wikipedia 2014和Gigaword 5上训练获得的300维(d=300)的Glove词向量[14]来初始化词向量,若遇到未包含的词则赋予300维正态分布的随机向量。采用AdaGrad[15]随机梯度下降算法,初始学习率0.05,batch size 25,本文对Embedding也进行训练,初始学习率0.02。L2正则化系数为0.000 1,同时将Embedding层和output层使用的dropout(keep probability)分别设置为0.6和0.8。为了不让训练样本波动过大,本文预先按句子长度对数据集进行排序。
实验结果由于无法得到一些重要训练参数,尽管经过细致的调优过程,本文对TreeLSTMs和TBCNNs两个模型的实现在准确度上仍低于文献[5]和文献[6]中给出的结果。因此,参照本文对TreeLSTMs模型和TBCNNs模型的实验获得的结果来评估模型性能,与本文提出的Quasi-TreeLSTMs模型进行比较。表1展示了模型在五分类和二分类两个情感分类任务上分别训练十个epochs后的结果。

表1 Stanford Sentiment Treebank测试结果

续表
由表1可知,相较于其他模型,Dependency TreeLSTMs在两个分类任务上的准确度明显较低,而Constituency TreeLSTMs却并不受影响,原因是支持树更能满足TreeLSTMs层级间组合信息的需求,在处理数据的过程中细粒度在不断增大,这对特征信息的提取非常有利,但在依存树上缺少这一特性。TreeLSTMs模型基于依存树训练得到的准确度不高是因为依存树结构中能训练的带标签的节点要比支持树中少了将近一半(150k:319k),因此能获得的信息就更少。依存树结构要比支持树结构更加紧凑,这对TBCNNs的卷积和池化操作都更加有利,因此它能在已有标签的节点上提取更多的信息。
在情感分类的两个任务上,Dependency TBCNNs的准确度都比Constituency TBCNNs高了近1%, TBCNNs在依存树上处理叶子节点融合问题时,根据引入的15个高频句法标签为子节点分配权值,由于TreeLSTMs中并未这样处理,因此本文实现Dependency TBCNNs模型时并未加入句法标签权重。虽然不考虑句法标签信息的Dependency TBCNNs的准确度在两个任务上分别下降了0.9%和0.8%,但仍高于Constituency TBCNNs的准确度,这一实验结果也表明TBCNNs在处理依存树结构的数据上有一定的优势。
本文提出的Constituency Quasi-TreeLSTMs在两个任务上的准确度都高于Dependency Quasi-TreeLSTMs,这和TreeLSTMs的结果一样,不同的是本文的两个模型差距却不大,说明Quasi-TreeLSTMs作为一种混合模型,缓解了已有的模型对树结构存在的敏感性,特别是有效避免了TreeLSTMs在依存树上无法有效提取信息的问题。
虽然实验中的三类模型没有绝对的最优,除Dependency TreeLSTMs外,其他模型在五分类任务上的准确度最高和最低间相差仅0.8%,在二分类上相差1.0%,表现最好的是Constituency TreeLSTMs,其次是本文提出的Constituency Quasi-TreeLSTMs,这两个模型在两个任务上相差了0.3%,主要原因是本文提出的模型所使用的池化模块不能像TreeLSTMs模型那样很好地适应支持树;Dependency Quasi-TreeLSTMs的准确度高于Constituency TBCNNs,说明虽然同样是在不适合的树结构上使用模型,但Quasi-TreeLSTMs的混合特性,能弱化这种结构和需求的不对称性。
图4给出了模型在情感分类的两个任务训练上每个epoch的平均消耗时间。TreeLSTMs和TBCNNs模型实现的训练速度差异很大, 且与针对的树结构相关。表2列举了TreeLSTMs针对支持树结构在三种实现方法中平均每秒解析树的个数。

图4 在两个任务上训练epoch的平均消耗时间
表2TreeLSTMs基于支持树的三种实现平均每秒解析树的个数

动态图静态图mini⁃batchmini⁃batch+meta⁃tree1.5933420
由于Tensorflow本身不支持动态图模型的构建,导致模型无法进行batch训练,因此动态图和静态图的解析比较慢。在三种实现中,动态图使用后序遍历操作,静态图将树以列表形式存储,并使用Tensorflow的while loop操作。mini-batch方法[16]基于广度优先遍历搜索变量,类似于树的层次遍历,而mini-batch with meta-tree方法[17]在mini-batch基础上将batch中各棵树上的节点按照结构排序并融合到一棵meta-tree上,然后一层一层地处理。mini-batch meta-tree方法的时间复杂度由O(M×N)缩减到O(log(N)),训练速度非常快(这种方法同Google提出的dynamic batching算法[18]类似)。本文基于支持树的模型都是按照mini-batch meta-tree的方式实现。对于依存树,由于每个节点的子节点数目各不相同,很难构建一棵meta-tree,因此只能以mini-batch的方式实现该模型,因此在图4中,针对依存树建模的模型在训练速度上明显低于针对支持树生成的模型。
如图4所示,本文提出的Quasi-TreeLSTMs是混合模型,它的训练耗时在TBCNNs和TreeLSTMs之间。但由于实现方式的相对高效,使得针对支持树的模型的速度差异小于针对依存树的模型的差异。在两个任务上,Constituency Quasi-TreeLSTMs的训练速度仅比Constituency TreeLSTMs快3.2s ,这一现象说明除了优化模型本身来提升性能外,使用一个高效的方法实现模型也能在一定程度上削弱模型间特性的差异。
由于实现方式相对低效,针对依存树的模型间的特性差异将在训练过程中不断体现。TBCNNs模型最适应依存树结构,且没有空间关联性关系的计算,使得它的训练速度相对较快。而本文提出的Quasi TreeLSTMs模型在TBCNNs基础上融入了部分空间关联性计算,但这部分任务是无训练参数的,因此训练耗时在两个任务上平均只多30s左右。但和TreeLSTMs相比,Quasi TreeLSTMs模型在两个任务上分别快了61.9s和48.3s,说明本文的模型在训练时有较大的速度提升。虽然Quasi-TreeLSTMs模型的准确度不及TreeLSTMs,但在多数情境下,快速训练迭代并获得较好的结果才是任务的需求。
3.2 语义相关性
数据集介绍本实验使用包含9 927个句子对的SICK(sentences involving compositional knowledge)数据集[19],每个句子对被人工标记了ENTAILMENT(蕴含)、NEUTRAL(无明显关系)和CONTRADICTION(矛盾)三类中的一类。本实验按4 500/500/4 927将数据集划分为训练集/验证集/测试集。
训练参数同情感分类实验。
实验结果表3展示了所有对比模型在SICK数据集上训练30个epochs的准确度,及训练一个epoch的平均消耗时间。
在3.1节中已经介绍,由于支持树的特性,TreeLSTMs模型处理支持树的数据更有优势。而依存树按照词与词间的句法关系将各个节点连接组合而成,并带有词与词之间的语法关系,使得TBCNNs模型的卷积层和池化操作在处理依存树结构的数据上更有利。由表3可知,Constituency TreeLSTMs(87.5%)模型和Dependency TBCNNs(87.0%)模型的准确度都较高。本文提出的Constituency Quasi-TreeLSTMs(87.2%)模型准确度高于Dependency Quasi-TreeLSTMs(86.7%),鉴于Quasi-TreeLSTMs的混合模型特征,两者表现差距不大。同情感分类任务,本文的模型缓解了已有模型对树结构类型的敏感性,避免了TreeLSTMs模型在依存树上无法有效提取信息的问题,也解决了TBCNNs模型无法利用支持树的层级关系的缺陷。
另一方面,在训练上每个epoch的平均消耗时间TBCNNs的训练速度相对较快,Quasi TreeLSTMs模型在TBCNNs模型的基础上引入了池化模块计算序列中词序关系,但在该模型的池化模块中无训练参数,因此该模型的速度和TBCNNs模型的速度相差不大。Quasi TreeLSTMs模型在速度上相对于TreeLSTMs模型有很大提升。因此,对于综合模型在两种树结构上效果的平衡关系和训练速度两个衡量指标,本文提出的Quasi TreeLSTMs模型最值得考虑。

表3 SICK数据集测试结果
4 相关工作
目前,针对树结构建模的模型大致分为两类: 基于循环神经网络(RNN)在树结构上建模[5,20]和基于卷积神经网络(CNN)在树结构上建模[6,21]。
基于循环神经网络在树上构建的模型,除了Tree-LSTM模型外,Dependency RNN[18]模型在依存树上建模,并通过结合句子的句法依赖性来提高循环神经网络模型的性能。Dependency RNN模型在解析树的所有路径(即从当前节点到根节点的展开)上都相互独立地获取所需要的依赖结构,同时保存每个节点出现在路径中的频率,并将其倒数和学习率结合,以防某一节点出现在多个路径中造成过度训练。此外,文献[18]在模型中加入语法标签,提出Labelled Dependency RNN模型。但该模型除了本文重点强调的效率问题,RNN模型在处理长序列上记忆状态衰减这一特点也是Dependency RNN模型要面临的一个难题。
和TBCNNs模型相同的DBCNNs[19],该模型基于CNN在依存树上建模,提取每个词特征时,将从该词到根节点的路径上的所有节点加入计算。该做法可以提取序列中长距离信息。虽然都是通过CNN模型基于树结构建模,但TBCNNs和DBCNNs卷积窗口的工作方式不同,且两个模型都没考虑输入序列的原始顺序信息。
目前存在很多将CNN模型结合RNN模型生成的混合模型。运用CNN卷积操作接收长度固定的短语进行学习的混合神经网络模型[22]将生成的特征表示用于LSTM模型,进一步学习输入文本的依赖关系。文献[23]将卷积层与双向LSTM结合生成一个新的模型,通过对输入信息使用卷积层来处理文本,并通过池化函数,以减小序列的长度,然后将生成的特征提供给双向LSTM模型用于后续处理。Quasi-RNN模型[9]是一种将CNN卷积操作和RNN的循环操作相结合的新的自然语言处理模型,卷积操作并行计算输入门、遗忘门和输出门信息,在循环层递归地计算输入序列中每个时间步的细胞状态和隐藏状态,有效地解决了RNN时效性问题。但上面的三种模型都是基于顺序处理输入序列,计算得到的最终表示只包含了序列的顺序信息。
5 结论
本文提出一种针对句法树的混合神经网络模型Quasi- TreeLSTMs,该模型结合传统的TreeLSTMs和TBCNNs模型,将影响TreeLSTMs效率的空间关联性计算任务进行拆分,用TBCNNs的卷积操作来完成最主要也是最耗时的三个控制门状态的计算,剩余的少量空间关联性任务因为完全无参,恰好适合用TBCNNs的池化操作进行计算。本文用TBCNNs实现了类似TreeLSTMs的操作,在保持后者记忆能力的前提下,又为其增添了并行性。从在情感分类和语义关系两种自然语言处理任务上的测试结果可以看出,本文提出的Quasi-TreeLSTMs在保持和已有模型相近的分类准确度的同时,在训练速度这一评价指标上有显著的性能提升。
[1] Peter W F, Walter K, Thomas K L. The measurement of textual coherence with latent semantic analysis[J]. Discourse Processes, 1998, 25(2-3):285-307.
[2] Landauer T K, Dumais S T. A solution to Plato’s problem: The latent semantic analysis theory of acquisition, induction, and representation of knowledge[J]. Psychological Review, 1997, 104(2):211-240.
[3] Elman J L. Finding structure in time[J]. Cognitive Science, 1990, 14(2):179-211.
[4] Mikolov T. Statistical language models based on neural networks[J]. Presentation at Google, Mountain View, 2nd April, 2012.
[5] Tai K S, Socher R, Manning C D. Improved semantic representations from tree-structured long short-term memory networks[J]. Computer Science, 2015, 5(1): 36.
[6] Mou L, Peng H, Li G, et al. Discriminative Neural Sentence Modeling by Tree-Based Convolution[C]//Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, 2015:2315-2325.
[7] Mou L, Yan R, Li G, et al. Backward and forward language modeling for constrained sentence generation[J]. Computer Science, 2016, 4(6):473-482.
[8] Balduzzi D, Ghifary M. Strongly-Typed Recurrent Neural Networks[C]//Proceedings of the 33rd International Conference on Machine Learning, 2016:1292-1300.
[9] Bradbury J, Merity S, Xiong C, et al. Quasi-recurrent neural networks[J]. arXiv preprint arXiv:1611.01576, 2016.
[10] Chen D, Manning C. A fast and accurate dependency parser using neural networks[C]//Proceedings of Conference on Empirical Methods in Natural Language Processing, 2014:740-750.
[11] Klein D, Manning C D. Accurate unlexicalized parsing[C]//Proceedings of Meeting on Association for Computational Linguistics. Association for Computational Linguistics, 2003:423-430.
[12] Socher R, Huang E H, Pennington J, et al. Dynamic pooling and unfolding recursive autoencoders for paraphrase detection[J]. Advances in Neural Information Processing Systems, 2011(24):801-809.
[13] Socher R, Perelygin A, Wu J Y, et al. Recursive deep models for semantic compositionality over a sentiment treebank[C]//Proceedings of the conference on empirical methods in natural language processing (EMNLP), 2013: 1631-1642.
[14] Pennington J, Socher R, Manning C D. Glove: global vectors for word representation[C]//Proceedings of the EMNLP, 2014(14): 1532-1543.
[15] Duchi J, Hazan E, Singer Y. Adaptive subgradient methods for online learning and stochastic optimization[J]. Journal of Machine Learning Research, 2011, 12(7):2121-2159.
[16] Dekel O, Ran G B, Shamir O, et al. Optimal distributed online prediction using mini-batches[J]. Journal of Machine Learning Research, 2012, 13(1):165-202.
[17] Stulp F, Sigaud O. Many regression algorithms, one unified model: A review[J]. Neural Networks, 2015(69):60-79.
[18] Looks M, Herreshoff M, Hutchins D L, et al. Deep learning with dynamic computation graphs[J]. arXiv preprint arXiv:1702.02181, 2017.
[19] Marelli M, Bentivogli L, Baroni M, et al. Sem-Eval-2014 task 1: Evaluation of compositional distributional semantic models on full sentences through semantic relatedness and textual entailment[C]//Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval2014), 2014:1-8.
[20] Mirowski P, Vlachos A. Dependency recurrent neural language models for sentence completion[J]. Computer Science, 2015, 17(15): 30-35.
[21] Ma M, Huang L, Xiang B, et al. Dependency-based Convolutional Neural Networks for Sentence Embedding[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics, 2015:174-179.
[22] Zhou C, Sun C, Liu Z, et al. A C-LSTM neural network for text classification[J]. Computer Science, 2015, 1(4):39-44.
[23] Xiao Y, Cho K. Efficient character-level document classification by combining convolution and recurrent layers[J]. arXiv preprint arXiv:1602.00367, 2016.
猜你喜欢
计算机应用(2022年9期)2022-09-25
科海故事博览·下旬刊(2022年4期)2022-05-07
软件导刊(2022年3期)2022-03-25
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
计算机技术与发展(2019年1期)2019-01-21
智能计算机与应用(2018年2期)2018-05-23
北京航空航天大学学报(2018年1期)2018-04-20
