
DE-ELM在水煤气组分浓度软测量建模中的应用
2017-03-02 05:29黄远红黄清宝
自动化仪表 2017年2期
黄远红,黄清宝
(广西大学电气工程学院,广西 南宁 530004)
DE-ELM在水煤气组分浓度软测量建模中的应用
黄远红,黄清宝
(广西大学电气工程学院,广西 南宁 530004)
水煤气组分(H2、CO、N2、CO2、O2)浓度是合成氨煤制气最关键的工艺参数之一,其与生产过程安全、稳定和成本控制密切相关。由于实时在线测量设备成本极高、维护困难、技术难度大,一般企业仍采用人工分析化验法。针对人工分析化验的方法造成的测量数据准确度差、滞后时间长、人为影响因素大,不利于煤制气生产过程的操控等问题,提出利用差分进化算法优化极限学习机(DE-ELM)神经网络系统,建立水煤气组分浓度的软测量模型,测量水煤气组分各浓度。将改进的方法与逆向神经网络(BP)、广义回归神经网络(GRNN)、极限学习机(ELM)的水煤气组分浓度软测量模型进行对比分析。对比结果显示,基于DE-ELM的水煤气组分浓度软测量模型精度更高、泛化性能更好,所测数据与实际生产数据吻合度更高,能更好地满足合成氨造气炉生产过程的实时调控要求。
安全; 软测量; 神经网络; 模型; 优化控制; 迭代; 极限学习机
0 引言
合成氨工业[1]在国民经济中具有重要的地位。其原料水煤气的主要成分[2]为氢气(H2)、一氧化碳(CO)、氮(N2)、二氧化碳(CO2)、氧气(O2),这些成分的浓度难以实现实时、在线测量。一般企业只能通过人工取样(主要为H2、CO、N2、CO2、O2)手动分析,实现对水煤气组分浓度的检测,但无法保证数据的连续性、实时性、稳定性和准确性。
极限学习机(extreme learning machine ,ELM)[3]神经网络以其学习速度快、泛化性能好的优点被大量应用于软测量建模[4],但由于ELM的连接权值和阈值是随机选取的,隐层神经元节点数较大,导致极限学习机存在结构复杂、仿真时间过长等缺点。为此,引入差分进化算法(differential evolution method,DE),基于种群的全局搜索策略,确定ELM的最优初始权值[5],以改善ELM网络的结构。该方法为差分进化算法优化极限学习机(DE-ELM)。
根据造气炉的生产过程与特点,选取与水煤气组分有极大关系的在线生产数据作为输入变量,手动离线检测数据作为输出变量,采用DE-ELM方法构建水煤气组分浓度的软测量模型,并与BP、GRNN、ELM的软测量结果进行比对分析,证明其在模型精度和泛化能力上的优势。
1 理论基础
1.1 ELM
ELM于2004年由黄广斌提出,是一种简单、易用、有效的单隐层前馈神经网络(single hidden layer feedforward neural network,SLFN)。ELM网络拓扑结构[6]如图1所示,其隐层只有一层节点。

图1 ELM网络拓扑结构图
图1中:输入变量为xi(i=1,2,...,n),中间隐层有i个神经元,输出层有m个神经元;输入层与隐层间的连接权值为ω,隐层与输出层的连接权值为β,隐层神经元阈值为b;网络有Q个样本的训练集,输入矩阵为X,输出矩阵为Y,隐层神经元激励函数为g(x)。
网络输出T为:
T=[t1,t2,...,tQ]m×Q
(1)
式中:j=1,2,...,Q;ωi=[ωi1,ωi2,...,ωin];xj=[x1j,x2j,...,xnj]T。
式(1)又可表示为:
Hβ=T′
(2)
式中:T′为矩阵T的转置。
当激活函数g(x)无限可微时,ELM的参数无需全部调整(ω和b可以随机选择,且恒定),可通过求解以下方程组的最小二乘解获得:
(3)
其解为:
β=H+T′
(4)
式中:H+为隐含层输出矩阵H的Moore-Penrose广义逆。
1.2 差分演化算法
差分演化算法[7-8]是1995年由Storn等人提出的一种基于群体进化的算法。该算法具有种群内信息共享和记忆个体最优解全局收敛能力、鲁棒性较强的特点。算法流程如下。
①种群初始化:随机选择个体p(满足约束条件),并组成大小为NP的种群。
pi={pi1,pi2,...,pij}
(5)
式中:i=1,2,...,NP;j=1,2,…,D,D为自变量个数。
(6)

②变异操作:从种群中随机选择三个个体(pr1,g、pr2,g、pr3,g),且互不相等。
vr,g+1=pr1,g+Fg(pr2,g-pr3,g)
(7)
式中:vr,g+1为新构造的向量;F为缩放因子;g为代数。
式(7)只表示其中一种变异策略,不同的要求可设定不一样的策略(公式)。
③交叉操作:新个体vr,g+1(变异操作)与xi(父代)离散交叉得到更新的个体ui。
(8)
式中:交叉概率CR∈[0,1];rand(i)为第i个向量产生的[1,D]间随机整数。
④选择操作:新生代与上代变量的适应值比较,值小者进入下一代,否则保留。
(9)
2 合成造气流程简介
2.1 生产流程
固定床间歇气化法采用交替吹风和制气的方式生产水煤气,完成一次吹风和制气的过程称为一个工作循环。一个循环包括5个阶段:吹风、一次上吹、下吹、二次上吹、空气吹净。
2.2 工艺条件
合成造气流程工艺条件包括温度、吹风速度、水蒸气用量(上吹、下吹)和其他辅助及安全监控参数[9]。
①温度:造气炉的温度主要是指气化层温度,但由于气化层温度难以测量,操作工一般参考造气炉的其他相关温度(上、下气道和炉条)测量值进行操作;炉温越高,水煤气产量越高,一氧化碳、氢气的含量浓度就越高;但炉温也不能超过煤的灰熔点,以避免炉内结疤。
②吹风速度:一般换算成吹风量(一次加氮)计算;吹风速度越快,炉温提升越迅速,但风速过大也会破坏正常气化条件。
③水蒸气用量(上吹、下吹):水蒸气用量直接关系到水煤气的产量与质量。用量大则产气量大,但水煤气质量差;用量小则产气量少。
④其他辅助及安全监控参数:炉条电流、炉条转速、炉上/下压力等。
3 DE-ELM软测量建模
3.1 模型描述
受控于造气炉运行参数的水煤气各组分浓度,对于液氨的生产、成本控制以及安全环保等各方面极为重要,但连续在线测量极为困难;而软测量技术[10-11]能够采用相对容易获得的过程变量(辅助变量)数据,通过计算机的数学运算,与难以测量的待测变量(主导变量)建立数学关系(软测量模型),以软测量模型实现水煤气组分浓度的实时检测并进行相关研究。
3.2 模型形式的确定
DE-ELM神经网络算法的主要流程为:ELM网络确定、差分进化算法优化相关参数、最优参数的DE-ELM训练和仿真。该算法具体流程如图2所示。
3.3 模型评价指标
均方根误差(RMSE)可用来衡量仿真值与真值之间的偏差。
(10)
式中:i为样本个体;n为样本总数;yi为仿真输出值;y为样本输出量。
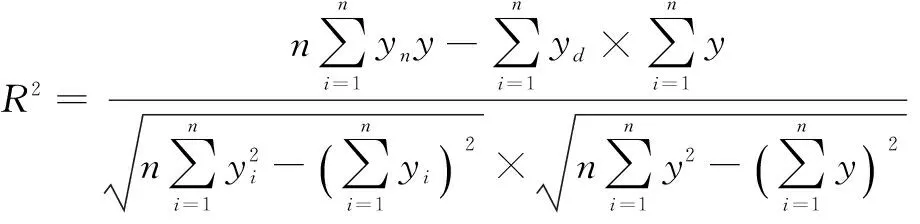
(11)
软测量模型训练时间以仿真运行时间长短作为判断网络优劣的依据之一。
4 DE-ELM软测量模型的仿真与分析
4.1 样本数据的预处理
4.1.1 建模样本数据的选取
为了真实地反映水煤气组分浓度,即主导变量,共收集了与组分浓度密切相关的11类在线实时数据,作为测量模型的输入变量(即辅助变量,各变量具体作用见2.2节);选取2015年的2 784组主导/辅助变量数据作为样本。辅助变量部分样本数据如表1所示。
4.1.2 样本数据的预处理
建模数据直接采集生产中仪表测量的真实数据(2 784组),数据离散性、突变和误差相对较大。对此,先采用小波降噪和一维中值滤波对数据进行预处理;然后对样本数据进行归一化处理,使数值分布在[-1,1],便于数据的处理。
4.1.3 样本数据的功能划分
因数据量大,考虑到生产过程的复杂性和工艺操作习惯、生产时段的差异,从样本数据交叉等距抽取3/4数据(2 088组)作为训练样本,另外等距的1/4数据(696组)为测试样本。
4.2 DE-ELM相关参数的确定
ELM网络结构采用11个辅助变量、5个主导变量,对于隐层神经元节点数(hiddennum)的选择尚无很好的确认最佳值方法(以下通过不同节点数试验确定较好的节点数),激励函数采用常见的“Sigmoid”函数,而输入-隐层的连接权值和阈值通过DE算法寻找最优组合值。

表1 辅助变量部分样本数据(在线测量)
DE需考虑的参数较多,有种群规模、最大迭代次数、搜索上/下限、缩放因子、交叉概率、测试方程索引、变异策略等。本模型主要考虑种群规模(population size)和最大迭代次数(max interation)对测量的影响。
4.3 软测量模型仿真及验证分析
应用Matlab7.0软件平台对DE-ELM软测量模型进行仿真,选择5个主导变量之一的H2浓度(最重要的组分)作为仿真分析的依据。
4.3.1 隐层神经元节点数对模型的影响
采用不同的隐层神经元节点数对DE-ELM网络进行仿真,结果如表2所示。
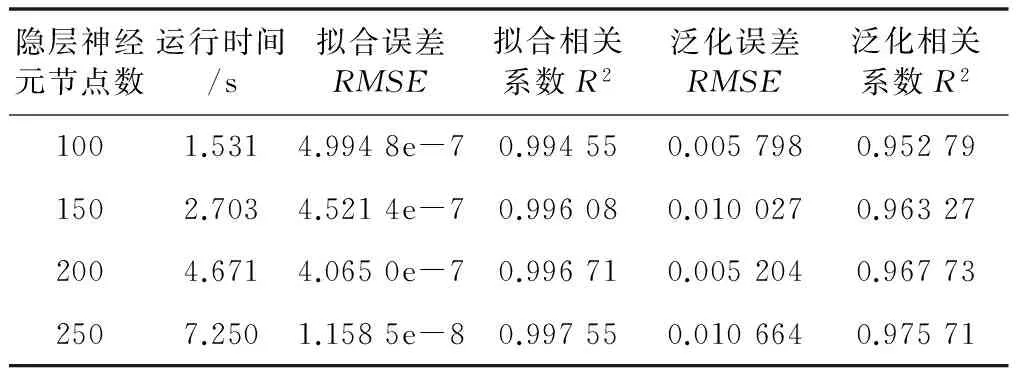
表2 隐层神经元节点数的性能评价对比
从表2的数据来看:不同隐层神经元节点对仿真影响差别不大:神经元节点数越多,拟合误差越小、相关系数越大,但是重要的是泛化误差并没有规律,而且运行时间变得很长;神经元节点数的增加,对测量模型的误差和相关系数影响不是特别明显,但是时间却是成倍的增长。从整个运行效果来看,隐层神经元节点数可适当取小一点,在对精度没有特别要求的前提下,模型能够快速运行。
4.3.2 种群规模对软测量模型的影响
采用不同的种群规模对DE-ELM网络进行仿真,结果如表3所示。
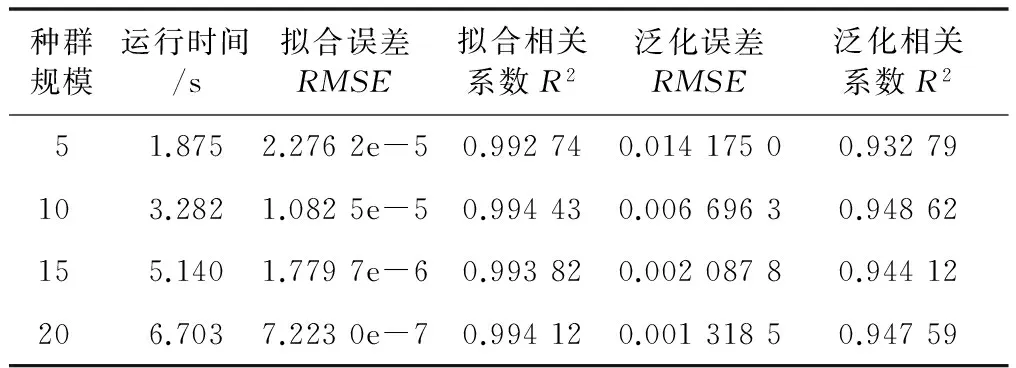
表3 种群规模的性能评价对比
从表3数据来看,种群规模对软测量模型的影响较大。种群规模越大,则差分选择优质个体的几率相对较大,拟合误差、相关系数或泛化的效果越好,误差减少的幅度较大。但与此同时,运行时间也会随种群的增大而相应增加。
4.3.3 最大迭代次数对软测量模型的影响
采用不同的最大迭代次数对DE-ELM网络进行仿真,结果如表4所示。
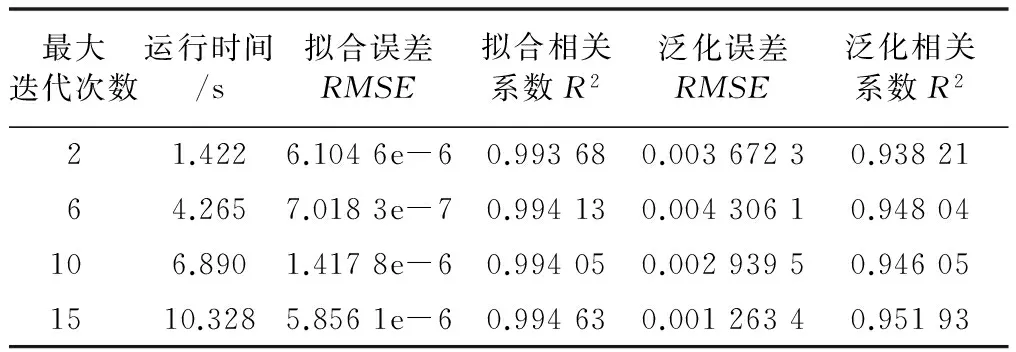
表4 最大迭代次数的性能评价对比
从表4数据来看,最大迭代次数对软测量模型影响较大。但从仿真的结果来看,它对模型的影响并不表现出单纯的正比关系,这是由于模型仿真的隐层神经元节点数、种群规模及最大迭代数较小,极易受缩放因子、交叉概率、变异策略等影响,导致出现局部极小值问题。
4.3.4 不同算法的软测量模型的对比
分别采用DE-ELM、BP、GRNN、ELM等神经网络对软测量模型效果进行对比,结果如表5所示。

表5 不同算法的性能评价对比
从表5数据来看,利用DE-ELM软测量模型的效果非常显著:①由于需用ELM计算个体的适应度值,其运行时间比单纯的ELM算法长,但仍比BP算法速度提高了十几倍;②四种算法得到的仿真误差、相关系数都比较接近,说明这四种模型均能很好进行仿真;③DE-ELM的拟合能力与GRNN接近,比BP、ELM精度更高,其泛化性能优于其他三个模型,说明其有更强的泛化能力。
真实数据、DE-ELM和ELM对H2浓度的泛化曲线对比如图3所示。

图3 泛化曲线对比图
4.3.5 分析结果
综合以上的分析,DE-ELM软测量模型在鲁棒性、泛化能力以及运行时间上比其他三种流行算法模型更具综合优势。利用最优参数给出的DE-ELM软测量模型性能评价指标如表6所示。
表6 DE-ELM软测量模型性能评价指标表
Tab.6 Performance evaluation indexes of soft-sensing modeling based on DE-ELM
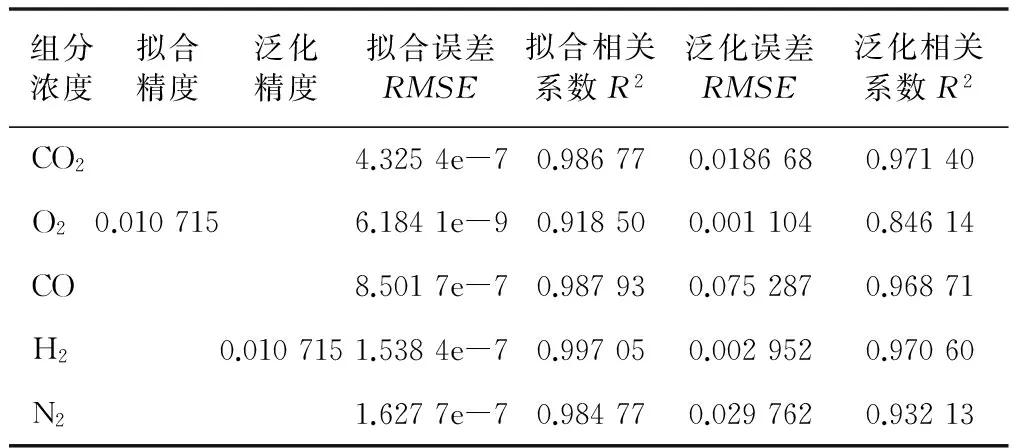
组分浓度拟合精度泛化精度拟合误差RMSE拟合相关系数R2泛化误差RMSE泛化相关系数R2CO24.3254e-70.986770.0186680.97140O20.0107156.1841e-90.918500.0011040.84614CO8.5017e-70.987930.0752870.96871H20.0107151.5384e-70.997050.0029520.97060N21.6277e-70.984770.0297620.93213
5 结束语
差分进化算法优化极限学习机(DE-ELM)的水煤气软测量模型,具有精度高、用时短、鲁棒性强和泛化性能好等优点,克服了人工取样、手工化验的延迟性,消除了人为因素的影响;同时,由于辅助变量取自制气工艺的关键参数,对生产过程的调控也有非常重要的指导作用。本文既对影响DE-ELM模型的关键参数进行仿真分析,又与当前流行的BP、GRNN、ELM算法软测量模型进行比对分析。对比分析结果表明,DE-ELM软测量模型的仿真时间更短、精度更高、泛化性能更好。因此,该软测量模型在实际生产过程中有较高的应用价值。
[1] 崔恩选.化学工艺学[M].北京:高等教育出版社,1990:163-164.
[2] 施湛青.氮肥工业与生产操作[M].北京:全国化工技术培训教材编委会,1987:7-8,11-20.
[3] HUANG G B,ZHU Q Y,SIEW C K.Extreme learning machine:theory and applications[J].Neurocomputing,2006,70(1-3):489-501.
[4] 潘立登,李大宇,马俊英.软测量技术原理与应用[M].北京:中国电力出版社,2009.
[5] ZHU Q Y,QIN A K,SUGANTHAN P N,et al.Evolutionary extreme learning machine[J].Pattern Recognition,2005,38(10):1759-1763.
[6] 孙鑫.极限学习机结构优化及其应用研究[D].南宁:广西大学,2014.
[7] 刘明广.差异演化算法及其改进[J].系统工程,2005,23(2):108-111.
[8] 赵斌.基于改进差分进化算法的火电厂负荷分配问题研究[D].武汉:武汉理工大,2013.
[9] 陈志伟.影响造气炉运行的几个重要条件[C]//第二十二届全国造气技术年会,2014:51-52.
[l0]林盛,梁强,高树奎.软测量技术在石化过程中的应用[J].当代化工,2009,38(2):182-184.
[11]梁玉明,王雁芬.软测量技术在化工生产中的应用[J].云南化工,2012,39(6):57-59.
Application of DE-ELM in Soft-Sensing Modeling for Component Concentration of Water Gas
HUANG Yuanhong,HUANG Qingbao
(School of Electrical Engineering,Guangxi University ,Nanning,530004,China)
The concentration of components (H2、CO、N2、CO2、O2) in watergas is one of the most important process parameters in the synthesis ammonia gas production,and it is closely related to safety,stability,and cost control of the production process.For the real-time online measurement equipment is extremely high in cost,difficult in maintenance and hard in technology,the methods used in general enterprises are mostly based on manual analysis in laboratory and feature many disadvantages,such as low accuracy,long time delay,and with various human factors that are not conductive to gas production.Aiming at these problems,to measure the concentration of each component,the soft-sensing model is set up by using differential evolution extreme learning machine (DE-ELM) neural network system.The soft-sensing model is analyzed and compared with back propagation (BP) neural network,generalized regression neural network (GRNN),and extreme learning machine (ELM).The results show that soft-sensing modeling based on DE-ELM has higher accuracy and better generalization performance,the measured data are more consistent with the actual production data,and it can better satisfy the needs of real time regulation and control of the actual production process of synthesis ammonia gas-making furnace.
Safety; Soft-sensing; Neural network; Model; Optimal control ; Iteration; Extreme learning machine
minβ‖Hβ-T′‖
黄远红(1969—),男,在读硕士研究生,工程师,主要从事工业过程自动化方向的研究。E-mail:hyhlh@126.com。 黄清宝(通信作者),男,硕士,副教授,主要从事过程控制、智能控制方向的研究。E-mail:3177151@qq.com。
TH81;TP391.9
A
10.16086/j.cnki.issn 1000-0380.201702020
修改稿收到日期:2016-09-05
猜你喜欢
浙江大学学报(理学版)(2022年4期)2022-07-25
复旦学报(自然科学版)(2022年1期)2022-06-16
煤气与热力(2021年12期)2022-01-19
环境卫生工程(2021年3期)2021-07-21
电子产品世界(2021年8期)2021-01-16
计算机应用与软件(2020年9期)2020-09-09
当代化工(2019年3期)2019-12-12
人民珠江(2019年4期)2019-04-20
现代装饰(2018年5期)2018-05-26
创新时代(2016年8期)2016-10-21
