
基于关键帧轮廓特征提取的人体动作识别方法
2017-02-24 10:10:45王刘涛廖梦怡王建玺
重庆邮电大学学报(自然科学版) 2017年1期
王刘涛,廖梦怡,王建玺,马 飞
(1.平顶山学院 软件学院,河南 平顶山 467000; 2.武汉大学 计算机学院,武汉 430072)

基于关键帧轮廓特征提取的人体动作识别方法
王刘涛1,廖梦怡1,王建玺1,马 飞2
(1.平顶山学院 软件学院,河南 平顶山 467000; 2.武汉大学 计算机学院,武汉 430072)
为了在人体动作识别中获得更加准确的前景分割和防止关键信息的几何丢失,提出一种利用关键帧提取关键姿势特征的人体动作识别方法。由于背景建模和差分获得的前景不准确,利用基于纹理的灰度共生矩阵提取动作轮廓,并对原图像帧进行分割;然后计算人体Blob的能量,选取最大信息内容的帧作为关键帧,关键帧的获取使得特征提取对时间的变化具有一定鲁棒性;在特征分类识别阶段,为了提高分类的准确性,提出使用支持向量机-K最近邻(support vector machine-k nearest neighbor, SVM-KNN)混合分类器完成分类。在Weizmann,KTH,Ballet和TUM 4个公开数据集上实验验证了该方法的有效性。相比于局部特征方法、全局特征方法和关键点方法等,该方法获得了更高的识别率。此外,实验结果表明,该方法在KTH和Weizmann数据集上的早期识别效果优于Ballet数据集。
人体动作识别;前景分割;轮廓特征;灰度共生矩阵;关键帧
0 引 言
基于视觉的人体动作识别[1](human action recognition, HAR)是在一个视频序列中检测和分析人体的行为/动作,近些年,HAR已经成为计算机视觉中一个重要的研究方向,HAR的应用十分广泛,如监控[2]、辅助健康保健[3]、机器人和恐怖活动预警[4],因此,这类研究具有很高的应用价值和现实意义。
影响HAR方法性能的因素很多,如身体姿势、执行速率、光线条件、遮挡、视角和杂乱的背景。一个优秀的HAR方法能够对这些因素的变化具有鲁棒性,能高效识别。已经有大量关于人体动作和行为识别的研究成果,这些方法依赖于局部特征[5]、全局特征[6-7]、关键点[8]、时空特征[9]、文字包[10]等。
为了克服特征袋模型的时空位置关系缺点,文献[5]中提出了一种基于局部特征的局部时空编码方法,引入了一个时间Gabor滤波器和一个空间高斯滤波器,虽然,这些基于局部特征的描述符对于噪声、亮度的变化以及背景的运动具有一定鲁棒性,但是,这些描述符对于复杂的动作模型缺乏有效性[5]。
文献[6-7]提出了一种依赖于人体轮廓序列的整体人体动作识别方法。在基于轮廓点方法中,利用背景分割法提取出前景,然后从轮廓中提取出特征。如文献[6]中提出了一种基于轮廓的方法,该方法利用快速傅里叶变换和边缘小波描述子相结合,给出多段定向距离轮廓描述矩阵实现人体轮廓特征的提取。文献[7]利用最优化参数,将人体轮廓作为基本实体进行特征评估,利用进化计算对最优化参数进行评估。由于基于人体轮廓方法[6-7]大多是利用背景建模和背景差分的方法进行前景分割,而背景建模的不够精确会使后续识别性能下降。
文献[8]提出了基于流形学习的动作识别方法,利用深度图像的关键点识别深度图像中的人体动作,降维操作通过流形学习在训练集中完成,匹配过程通过改进的Hausdorff距离对低维空间下测试序列和训练运动集的相似度进行度量。
为了在达到识别率的同时,降低传感器节点的能耗,文献[9]引入压缩传感和稀疏表示理论用于解决人体活动监测,其中,类动作识别在传感器节点利用随机投影对传感数据进行压缩,中心节点利用稀疏表示进行分类与识别。
文献[10]中提出了一种改进版的文字包模型,即校正姿势包,这种模型利用了全局和局部特征的优势,处理视觉文字表示包中丢失的几何信息,一般情况下采用的方法是k-means聚类算法。但是,局部特征与全局特征的结合会导致描述符具有较高的维度[11],为了进行有效的识别需要进行维度消减。
现存的人体动作识别一般存在以下问题:①一般情况下,利用背景建模和背景差分进行前景分割,会使得获取的前景不一定准确,为此,本文中采用一种基于纹理的分割方法,从人体行为识别的内容中提取出轮廓;②通过选取关键姿势可以处理几何信息丢失,为了对轮廓信息进行描述,本文提出了一种比较简单的方法,这种方法可以保持人体轮廓随着时间改变产生的空间变化;③当行为存在类间相似性和类内非相似性时将会减弱分类器的性能,为此,提出混合分类模型。
1 提出的方法
本文基于人体轮廓,利用分割技术从视频序列中提取人体动作。分割轮廓需要进行预处理以提高其质量,使其满足特征提取的要求。然后将不同轮廓图像生成的特征设置成一种可表示的形式。此外,还采用了维度消减和分类。本文方法的流程图如图1所示。
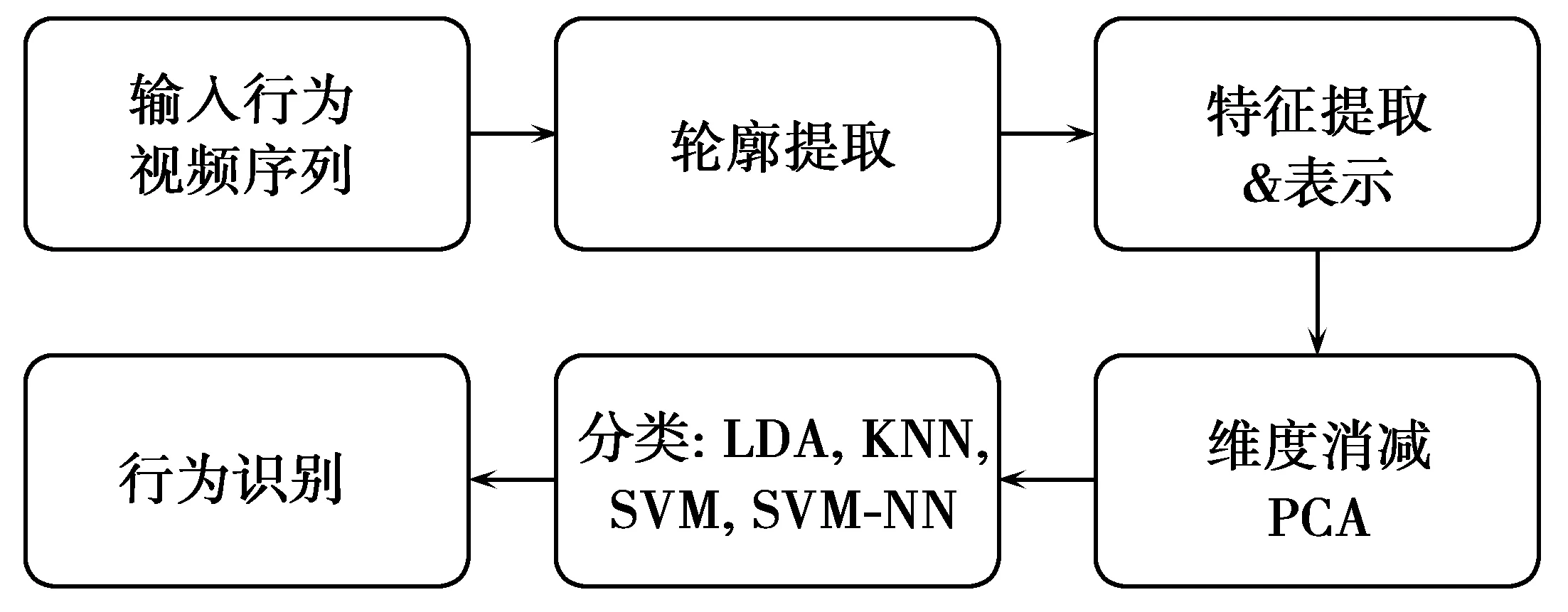
图1 本文方法的流程图Fig.1 Flow chart of proposed method
1.1 利用纹理信息提取轮廓
背景差分的基本思路是构建和更新背景的场景模型,如果前景目标的像素与背景模型的差异超出了一定的限制,那么就可以检测出前景目标上的这些像素点。广泛使用的背景模型有高斯混合模型(gaussian mixture model, GMM)和局部二值模式(local binary pattern, LBP)。
文献[12]提出了对不同纹理进行描述的方法,即灰度共生矩阵,文献[12]肯定了纹理的灰度共生矩阵的描述参数,这个矩阵可以在不同方向上对纹理的强度差异进行描述,信息熵是一种重要的参数,可对图像中的纹理信息进行描述,其表达式为
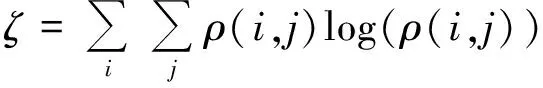
(1)

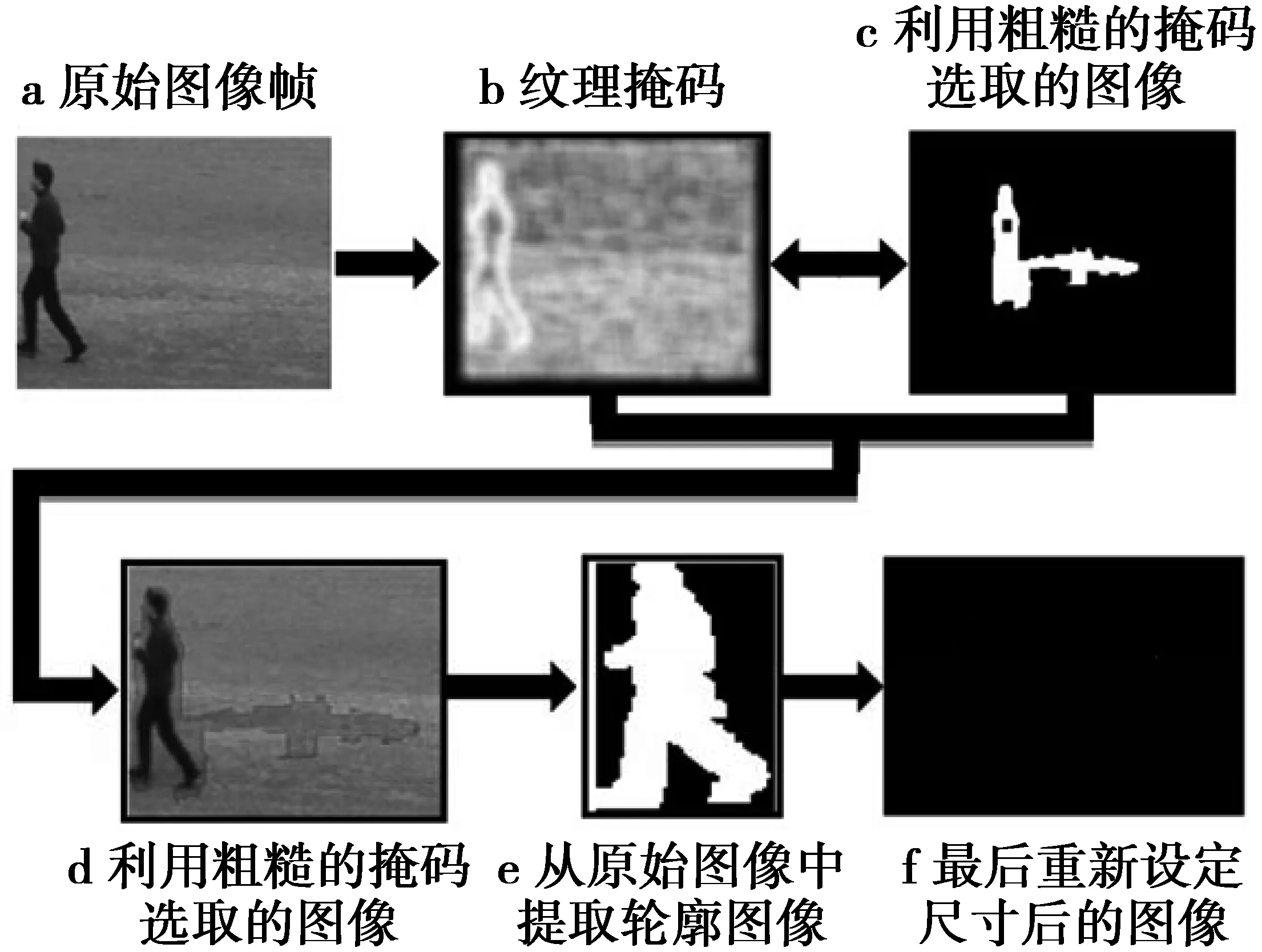
图2 轮廓提取的流程图Fig.2 Flow chart of contour extraction
分割后的图像可能含有不同的白色轮廓,但是并非所有的白色轮廓都是人体的轮廓。通过对这些轮廓的尺寸进行比较,可以找到面积最大的轮廓,如图2所示,2个部分含有相同的纹理,但是人体部分具有较大的连续面积,因此选取面积较大的区域作为人体轮廓。
1.2 特征提取
特征提取是视频序列分析的关键步骤,提取的特征必须具有鲁棒性并且不会随着检测条件,身体姿势等的变化而发生变化。
1.2.1 提取图像帧中的关键姿势
一般情况下,一些视频帧中不含有任何目标的内容信息。考虑到人在“行走”,而相机是静止的,人会在很短的时间内从相机前方穿过,因此大多数时间内视频帧中不含有任何视角的“人体blob”内容。为了选取含有最大内容信息的视频帧,需要提取出关键帧,并且利用这个关键帧进行特征提取。图3为从大量的视频帧中提取出关键帧的过程。选取含有较高能量值的关键帧图像进行进一步的处理,并根据最高能量帧图像将这些关键帧保存在一个时间序列中,对关键帧的这种处理可以随着时间发生的外形变化进行维护。
为了从动作序列的移动区域获得平稳度量,首先减去相邻帧,通过帧ni+1与帧ni相减得到一个中间帧ni+1/2去评估帧ni+1和帧ni的帧间差异。运用拉普拉斯算法计算相邻差异帧ni+1/2和帧ni-1/2之间的光流,这样做的好处是初始的差分操作减少了背景杂波的影响,因而产生更加平稳的评估。
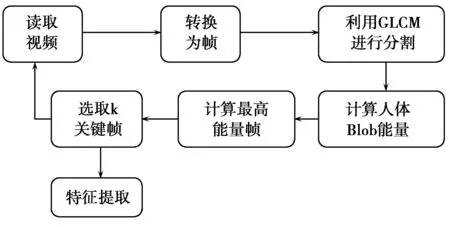
图3 选取关键姿势帧的流程图Fig.3 Flow chart of the key frame selected
1.2.2 单元的构造
M×N大小的缩放图像含有的所有像素等于Γ,如图4所示将所有的这些像素划分为u×v大小的网格图像。由于需要将这些图像转化为二值的形式,因此可以计算出单元中的白色像素,对于特殊的单元和网格将白色像素的个数作为一个特征。
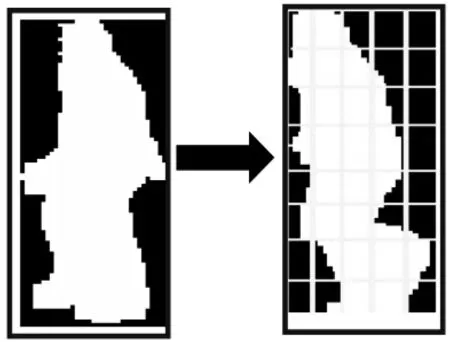
图4 利用关键帧构建单元Fig.4 Construction unit by key frame
1.2.3 特征计算和表示
一个行为的分割视频中含有有限数量的帧(R),用It(x,y)表示,其中,t表示帧的数量,即t∈{1,2,3,…,R},x和y表示图像帧的维度。为了保持一致性,下一步需要将每个帧图像缩放成尺寸M×N。
为了对动作进行有效的表示,选取具有较高能量帧图像中的关键姿势,在视频序列中这些帧的能量高于其他帧。图像帧能量的计算为
(2)
为了选取轮廓帧图像中的关键姿势,需要对一个确定数量的图像帧进行序列搜索操作以发现所有轮廓帧图像(U1,U2,U3,…,UR)中具有最高能量值的帧。将具有最高能量值的图像帧作为一个参考帧,选取与参考帧相比具有较大能量值的帧作为轮廓的k关键帧。现在,将每一个关键帧划分为单元图像Ci(x,y),在单元图像中每个单元的尺寸为u×v,因此,单元的总量为
(3)
(3)式中,Nc表示关键帧中单元总数,表示为(C1,C2,C3,C4,…,CNc)。由于轮廓图像是二值图像,白色像素的总量计为
(4)
(4)式中,wi表示第i个单元中白色像素的个数,一帧中每个单元的像素个数计数过程需要保持动作的时间序列,具体表示为
(5)
(5)式中,fi表示第i帧中含有的白色像素个数。因此,一个动作视频序列的特征向量表示为
(6)
(6)式中,VT表示一个数据集中视频的总个数。将(5)式带入(6)式,特征向量为
(7)
类似的,数据库中的所有类别的特征集含有VT个,维度为Nf=Nc×k,连接后可以将维度表示为1×Nf。因此,最终特征集Fv的维度可以表示为VT×Nf。最后,为了进行动作识别,将特征向量和其标签交给分类器进行处理。
1.3 分类模型
通常情况下,特征集数据具有相关性和非相关性数据,为了提高分类性能,必须对特征集的维度进行消减。主成分分析法(principal component analysis, PCA)是一种比较流行的降维方法,该方法通过最大化特征集的方差将特征集映射到一个低维空间,从而实现维度消减。
KNN(K nearest neighbor)分类器选取训练特征集中距离最近的K个样本作为新的实例,距离最近的类别具有最高的投票权,从而将距离最近的类别投影为测试实例。这种分类器最大的优势是其具有非参数特性,不需要任何的假设并且对于高维空间中的数据也能轻易分类。支持向量机(support vector machine, SVM)是一种基于结构风险最小化原则[13]的机器学习分类器。SVM分类器广泛应用于人体行为分类,最重要的数据位置由超平面确定。
为了提高识别精度,本文构建了一种混合形式的“SVM-KNN”分类模型,这种混合模型利用了SVM和KNN模型的各自优点,图5给出了本文的“SVM-KNN”分类模型。在这种模型中,开始利用SVM对输入的特征集进行分类,在这些特征集中,一些特征正确分类,另一些则错误分类,错误分类的特征集位于分类超平面附近,即为支撑向量。具体步骤描述如下(设T为测试集,Tsu为支持向量集,k为KNN的个数,∅表示空集)。
步骤1 利用SVM算法求出相应支持向量,以及系数及常数b;
步骤2 如果T≠∅,取x∈T;如果T=∅,则停止;
步骤4 若|g(x)|>ε,则直接计算f(x)=sgn(g(x))作为分类器的输出;若|g(x)|<ε,则带入KNN分类器进行分类。
步骤5T←T-{x},转到步骤2。
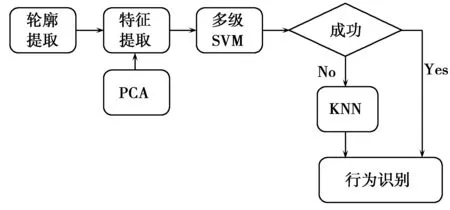
图5 SVM-NN混合分类模型流程图Fig.5 Flow chart of SVM-NN hybrid classification model
这里将支持向量集Tsu中的每个支持向量作为分类器的代表点集合。利用KNN对这些支撑向量进行分类,可以弥补SVM的不足。两者结合提高了分类的准确性。
2 实验与分析
为了对本文方法的有效性进行评估,在4个公共基准数据集Weizmann数据集[14]、KTH数据集[7]、Ballet数据集[15]和TUM数据集[17]上进行实验。考虑了光线变化、遮挡、混乱背景和不规律运动等条件。为了对数据集的所有视频进行表示,采用31个尺寸为40×25的关键帧对动作序列进行表示,每个帧中含有40个单元,每个单元的尺寸为5×5。因此,一个轮廓的维度为31×40=1 240,连接之后轮廓特征向量表示为1×1 240。为了对动作分类的输出结果进行评估,选取交叉验证方法对所有数据集进行处理。
利用下面的(8)式计算平均识别精度(average recognition accuracy, ARA)。
(8)
(8)式中:TP,TN,FP和FN分别表示真阳性、真阴性、假阳性和假阴性。将这些分类器获取的精度与当前较先进方法进行了比较。比较的文献有[5-10,16-17],这些方法中,文献[5]是基于局部时空编码方法,文献[6-7,16-17]是基于提取轮廓的方法,文献[16]利用adaboost提取关键帧,文献[8]是基于流形学习理论,文献[9]是基于压缩传感和稀疏理论,文献[10]是基于文字包模型。
2.1 数据集
Weizmann数据集:含有90个视频,帧率均为25帧/s,视频帧的尺寸为144×180,9个人做出了10个不同的动作,类别包括:行走、快跑、上顶跳跃、弯腰、单腿上跳、两腿跳跃、单手挥舞和双手挥舞。这是用于人体动作识别评估的标准数据集,图6给出了这个数据集的样本帧。

图6 Weizmann人体动作数据集的样本帧图像Fig.6 Sample frame images on Weizmann data set of human action
KTH数据集:与Weizmann数据集相比,这个数据集更有挑战性。集中含有6个基本动作,即:“拍手”“挥手”“慢跑”“跳跃”“快跑”和“行走”。每个动作有100个视频,共含有4种不同的场景,如光线条件的变化、室内和室外条件。所有这些视频均用一个帧率为25帧/s的静态相机在背景相同的情况下拍摄,并且对空间分辨率为160×120像素的图像进行下采样。KTH数据集中视频的拍摄条件不是很稳定,因为拍摄过程中相机存在大量的移动,在某些情况下光线条件也发生了变化。因此,轮廓的提取并不十分容易,图7中给出了数据集的样本图像。

图7 KTH数据集的样本帧图像Fig.7 Sample frame images on KTH data set
Ballet数据集:是一个复杂的人体动作数据集,由3个演员的8种Ballet动作构成,动作包括:“跳跃(hop, HP)”“跳起(jump, JP)”“由左至右伸开手臂(left-right hand outstretched, LRHO)”“腿摆动(leg swing, LS)”“由右至左伸开手臂(right-left hand outstretched, RLHO)”“手伸开站立(stand hand outstretched, SHO)”“直立(straight stand, SS)”和“转向(turn, TR)”。该数据集中存在高度的空间和时间尺度、速度和衣物的类内差异性,图8给出了这个数据集的一些样本图像。

图8 Ballet数据集中表示8种动作的图像Fig.8 Eight kinds of actions represented on Ballet data set
TUM数据集:是由20个按表中设定的人物序列组成,并制成表。首先利用原始数据集提供的前景模板提取边界框,并将其尺寸规范化为100×100×70。提取每一帧的多尺度金字塔运动特征。在关键帧的选取阶段,在每个运动序列上选取前10个最具辨识度的帧,最后利用相应的相关图进行测试训练。与文献[16]相似,应用2种不同的策略:使用一组序列{0-2,0-4,0-6,0-8,0-10,0-11,1-6 }作为测试集,而其他用于训练。运用“站立”和“行走”划分。图9是使用TUM数据集中的2D特征和动态捕捉信息。
图9 学习和测试数据图例Fig.9 Study and test data legends
2.2 分类结果
表1中给出了本文方法在4个不同数据集上采用4种不同分类模型获得的分类结果,其中包括本文提出的“SVM-NN”模型。表1主要用于说明本文描述符的有效性以及提出的分类模型与已经存在的分类模型相比的性能优势。
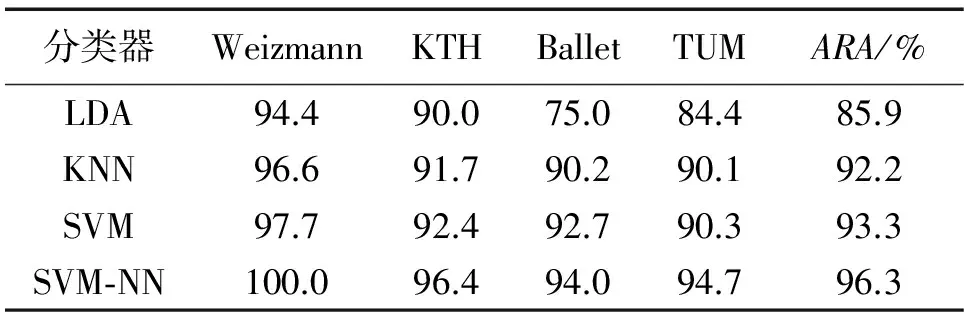
表1 数据集分类结果的识别精度
由表1可知,线性判别分析(linear discriminant analysis, LDA)方法获取的识别精度低于其它种类的分类器,这是因为“快跑”“跳起”和“行走”之间存在很大的相似性,因此很难利用LDA模型对这些行为进行区分。本文采用混合“SVM-KNN”分类模型获取了最高点ARA,由于这个混合分类器结合了2种非线性分类器,适合处理类间的相似性以及类内的判别性,因此提高了识别精度。
对于KTH数据集,由于其拍摄条件与Weizmann数据集相比变化因素过多,因此很难在这个数据集中提取出轮廓。在Weizmann数据集中利用简单的帧差法可能会提取较好的轮廓信息,但是在KTH数据集中很难利用这种方法提取出正确的轮廓信息。实验中,KTH数据集上获取的最高ARA为96.4%(见表1)。从表1可知,各种分类器对于KTH数据集的性能一直在提高。
对于Ballet数据集,SVM-KNN分类器获取的最高ARA为94.5%,本文方法在Ballet和TUM数据集上获取的精度低于在Weizmann数据集和KTH数据集上获取的识别精度,这是由于Ballet和TUM中的运动模型更加复杂,需要在对演员做出的动作进行区分。“跳脚”很容易与相关动作“跳跃”混淆,因此引起了错误分类。
2.3 识别精度的比较
通过平均分类误差(mean classification error, MCE)对分类器的性能进行比较,利用平均识别精度(mean recognition accuracy, MRA)计算平均分类误差。LDA,KNN,SVM和SVM-KNN分类器的MCE分别为13.6,7.2,5.72和3.2。本文的分类器MCE最低。
表2和表3分别为本文方法与几种动作识别方法在Weizmann和KTH数据集上的比较结果。这些方法包括文献[5-8,16-17]提出的方法。在这些方法比较较为公平,因为这些方法所采用的测试策略有:交叉验证留一法(leave one out, LOO)、交叉验证留一人法(leave one person out, LOPO)和交叉验证留一序列法(leave one sequence out, LOSO),这些策略之间非常类似,所采用的实验设置也与本文方法类似。如表2所示,本文方法在Weizmann数据集上获取的ARA为100%。
本文方法之所以能够获得这么高的ARA,是因为轮廓提取质量较高,对轮廓进行了有效的表示,且分类时能够处理行为间的类内变化。类似的,从表3可以看出,本文方法在KTH数据集上的ARA为97.6%,高于其他方法。表4和表5分别给出了各方法在Ballet和TUM数据集上的结果比较,比较的文献有[5,8-10,16-17],虽然Ballet和TUM数据集是一个非常复杂的数据集,但本文方法的ARA依然保持最高。
下面对实验数据进行简单总结:
1)从表2-5中可以看出,本文方法对动作的识别能力优于其他方法,这体现在对轮廓信息的获得,另外分类器的性能也起到了一定促进作用;
2)本文方法在KTH和Ballet数据集上获得了显著的性能提高,因为这2个数据集含有苛刻的环境条件,并且在速度、时空尺度、放大、缩小和衣物等方面发生了显著的类内变化,这些因素直接与输入数据相关。与KTH和Ballet数据集相比,Weizmann数据集上的轮廓提取过程相对简单并且准确,这是因为Weizmann数据集的采集条件存在较少的变量,而TUM数据集与Ballet数据集的难度差不多。
3)随着关键姿势数量的增加,复杂性也相应的增加,但是在识别精度上却没有发生显著的增加。另一方面,随着单元数量的增加,本文方法的有效性发生了轻微的增加,维度依然较高。
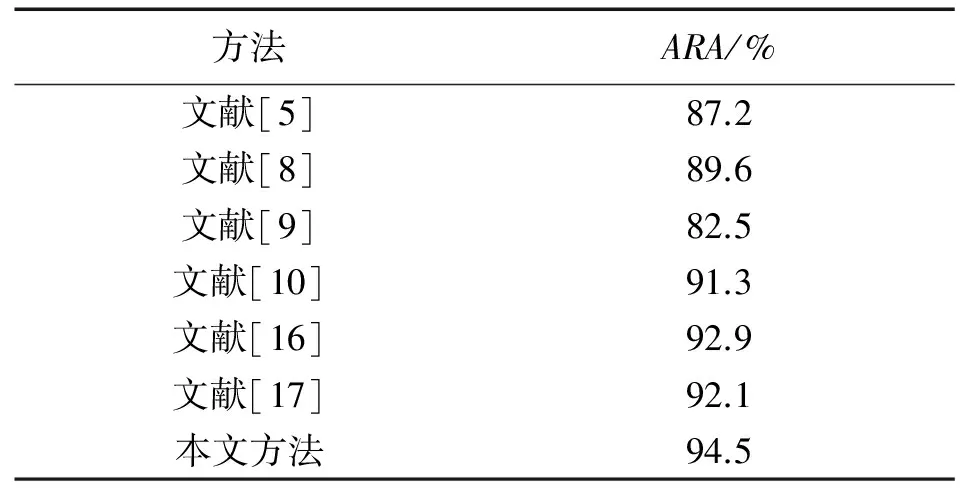
表4 各方法在Ballet数据集上的比较结果
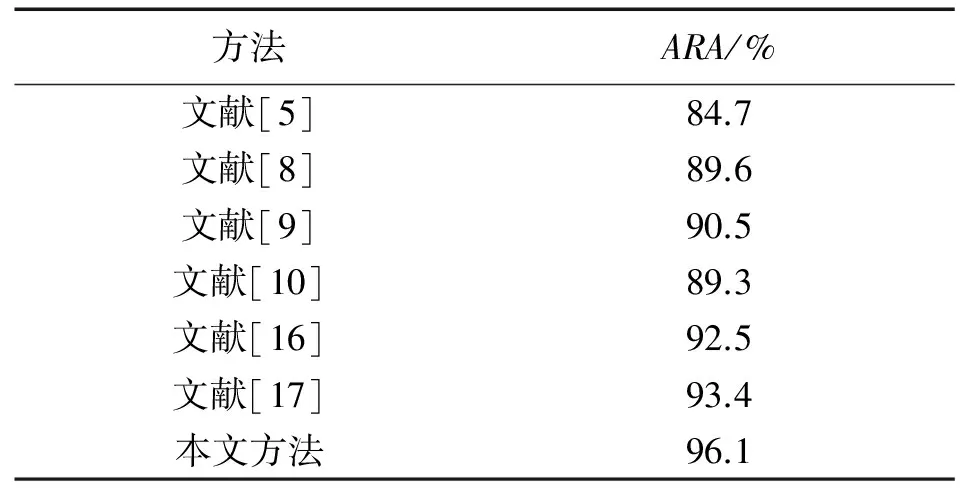
表5 各方法在TUM数据集上的比较结果
2.4 早期识别效果
如果能在动作没有完全结束时,就能准确识别动作类型,那将非常有益。而本文方法在动作完成之前的识别比较有潜力,图10所示为4个数据集上的识别率,动作完成范围从50%到100%。
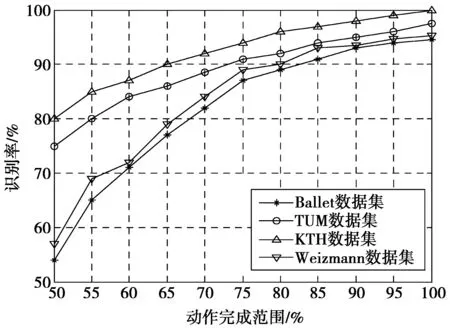
图10 各数据集上的识别结果Fig.10 Identification results on each data set
由于Ballet和TUM数据集动作比较复杂,因此动作全部完成的识别率与动作完成50%时,相比没有明显增加,其主要是因为该数据集大部分辨别信息分布在整个过程中,而不是前一半过程中,然而,KTH和Weizmann数据的动作过程较短,动作进程达到50%时,识别率已经很高。对于瞬时动作几乎可以完全匹配,大大地提高了识别率。这说明了对于动作较短的数据集,在动作进程达到50%时,动作的特征提取具有非常高的有效性。
3 结论与展望
本文提出了一种基于视觉的人体动作识别,其主要思想是利用人体轮廓的关键姿势进行动作识别。通过如下策略解决了环境条件变化引起的低识别率问题:①通过基于纹理的背景差分方法提取人体轮廓信息;②利用网格和单元的方法对人体轮廓进行了简单有效的表示;③提出了一种有效的混合分类模型“SVM-KNN”。4个公共数据集上的实验结果表明了本文方法对于光线变化、室内/室外变化具有鲁棒性。
尽管提出的方法获得了较好的识别效果,但仍存在一些问题:①一个很重要的问题是视频序列中仅存在一个人;②部分参数需要进一步优化,如关键姿势、网格和单元的尺寸;③当目标发生遮挡时,提出的方法识别效果欠佳。在以后的研究工作中,需要对这些参数进一步的优化处理,使得特征表示更加有效和准确。此外,将提出类似的方法应用于其他研究领域,如人体风格识别、手势识别和人脸识别等。
[1] AGGARWAL J K, RYOO M S. Human activity analysis: A review[J]. Acm Computing Surveys, 2011, 43(3): 194-218.
[2] 肖玲.无线体域网中人体动作监测与识别若干方法研究[D]. 湖南:湖南大学, 2014. XIAO Ling. Research on several methods of human motion monitoring and recognition in wireless body area network[D]. Hunan: Hunan University, 2014.
[3] CHAARAOUI A A, CLIMENT P P, FLREZ R F. A review on vision techniques applied to Human Behaviour Analysis for Ambient-Assisted Living[J]. Expert Systems with Applications, 2012, 39(12): 10873-10888.
[4] 陈国兴,刘作军,陈玲玲,等.假肢穿戴者跌倒预警系统设计[J].华中科技大学学报:自然科学版, 2015, 32(S1): 246-251. CHEN Guoxing, LIU Zuojun, CHEN Lingling, et al. Design of a stumble pre-warning system for lowerlimb amputees[J]. Journal of Huazhong University of Science and Technology: Nature Science Edition, 2015, 32(S1): 246-251.
[5] 王斌,刘煜,王炜,等.面向人体动作识别的局部特征时空编码方法[J].四川大学学报:工程科学版, 2014, 37(2): 72-78. WANG Bin, LIU Yu, WANG Wei, et al. Local Feature Space Time Coding for Human Action Recognition[J]. Journal of Sichuan University: Engineering Science Edition, 2014, 37(2): 72-78.
[6] 胡石,梅雪.人体行为动作的形状轮廓特征提取及识别[J].计算机工程, 2012, 38(2): 198-200. HU Shi, MEI Xue. Shape contour feature extraction and recognition of human behavior motion[J]. Computer Engineering, 2012, 38(2): 198-200.
[8] 王鑫,沃波海,管秋,等.基于流形学习的人体动作识别[J].中国图象图形学报, 2014, 19(6): 125-130. WANG Xin, WO Bohai, GUAN Qiu, et al. Human action recognition based on manifold learning[J]. Journal of Image and Graphics, 2014, 19(6): 125-130.
[9] 肖玲,李仁发,罗娟.体域网中一种基于压缩感知的人体动作识别方法[J].电子与信息学报, 2013, 34(1): 119-125. XIAO Ling, LI Renfa, LUO Juan. Recognition of human activity based on compressed sensing in body sensor networks[J]. Journal of Electronics & Information Technology, 2013, 24(1): 119-125.
[10] WU D, SHAO L. Silhouette Analysis-Based Action Recognition Via Exploiting Human Poses[J]. IEEE Transactions on Circuits & Systems for Video Technology, 2013, 23(2): 236-243.
[11] 魏莱.基于关节点的人体动作识别及姿态分析研究[D].北京:北京邮电大学, 2014. WEI Lai. Research on human motion recognition and pose analysis based on joint point[D]. Beijing: Beijing University of Posts and Telecommunications, 2014.
[12] 白雪冰,王克奇,王辉.基于灰度共生矩阵的木材纹理分类方法的研究[J].哈尔滨工业大学学报, 2005, 37(12):1667-1670. BAI Xuebing, WANG Keqi, WANG Hui. Research on the classification of wood texture based on Gray Level Co-occurrence Matrix[J]. Journal of Harbin Institute of Technology, 2005, 37(12): 1667-1670.
[13] 哈明虎,田景峰,张植明.基于复随机样本的结构风险最小化原则[J].计算机研究与发展, 2009, 46(11):1907-1916. HA Minghu, TIAN Jingfeng, ZHANG Zhiming. Structural risk minimization principle based on complex random samples[J]. Journal of Computer Research and Development, 2009, 46(11): 1907-1916.
[14] GOUDELIS G, KARPOUZIS K, KOLLIAS S. Exploring trace transform for robust human action recognition[J]. Pattern Recognition, 2013, 46(12): 3238-3248.
[15] FATHI A, MORI G. Action recognition by learning mid-level motion features.[C]// IEEE Computer Society Conference on Computer Vision and Pattern Recognition. IEEE Computer Society Conference on Computer Vision and Pattern Recognition.[S.l.]:IEEE Press 2008:1-8.
[16] 王刘涛,王建玺,鲁书喜.基于Adaboost关键帧选择的多尺度人体动作识别方法[J].重庆邮电大学学报:自然科学版, 2015, 27(4): 549-555. WANG Liutao, WANG Jianxi, LU Shuxi. Multi-scale human action recognition method based on Adaboost key-frame selecting[J]. Journal of Chongqing University of Posts and Telecommunications: Natural Science Edition, 2015, 27(4): 549-555.
[17] JI S, XU W, YANG M, et al. 3D convolutional neural networks for human action recognition[J]. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 2013, 35(1): 221-231.
(编辑:张 诚)
Human activity recognition based on contour feature extraction on key-frame
WANG Liutao1, LIAO Mengyi1, WANG Jianxi1, MA Fei2
(1. College of Software, Pingdingshan University, Pingdingshan 467000, P.R. China; 2. School of Computer Science, Wuhan University, Wuhan 430072, P.R. China)
In order to acquire more accurate of foreground segmentation and prevent the loss of critical geometry information in human action recognition, a human action recognition method based on extracting key-gesture features by key-frame is proposed. Concerning that foreground obtained from background modeling and background differential is not accurate, the action contour is extracted by using texture-based gray level co-occurrence matrix with segmentation on original image frame. Then, body energy Blob is calculated, and frame of maximum information content is selected as key-frame. Key-frame makes feature extraction robust to the change of time. The last is the stage of feature classification. support vector machine-K nearest neighbor (SVM-KNN) hybrid classifier is used so as to improve the classification accuracy. The effectiveness of the proposed method has been verified by experiments on the four public data sets Weizmann, KTH, Ballet and TUM. The recognition accuracy of the proposed method is higher than local feature method, global feature method, key-point method and etc. In addition, the experimental results show that early identification of data sets KTH and Weizmann is better than that of Ballet data set.
human activity recognition; foreground segmentation; contour feature; gray level co-occurrence matrix; key-frame
10.3979/j.issn.1673-825X.2017.01.015
2016-02-19
2016-09-25 通讯作者:王刘涛 wangltpds@126.com
国家自然科学基金项目(61503206);河南省科技厅科技发展计划项目(142102210226)
Foundation Items:The National Natural Science Foundation of China(61503206); The Technology Development Plan Project of Henan Science and Technology Department(142102210226)
TP391
A
1673-825X(2017)01-0098-08

王刘涛(1981-),男,河南项城人,硕士,讲师,研究领域为图像处理、模式识别等。E-mail:wangltpds@126.com。 廖梦怡(1983-),女,河南南阳人,硕士,讲师,研究领域为图像处理、虚拟现实技术等。 王建玺(1981-),女,河南社旗人,硕士,讲师,研究领域为图像处理、模式识别等。 马 飞(1980-),男,山东鱼台人,博士生在读,副教授,研究领域为图像处理、模式识别等。
猜你喜欢
课堂内外·小学版(低年级)(2023年6期)2023-04-29 00:44:03
制造技术与机床(2019年11期)2019-12-04 05:50:54
电子测试(2018年1期)2018-04-18 11:52:35
大连理工大学学报(2017年4期)2017-08-07 07:03:20
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
重庆交通大学学报(自然科学版)(2016年1期)2016-05-25 00:37:00
西北工业大学学报(2015年3期)2015-12-14 13:08:46
计算机工程(2015年4期)2015-07-05 08:27:39
文艺生活·中旬刊(2014年12期)2015-01-06 03:03:56
