
融合知识图谱的查询扩展模型及其稳定性研究*
2017-01-18 08:15郝林雪宋大为候越先
计算机与生活 2017年1期
郝林雪,张 鹏,宋大为,候越先
天津大学 天津市认知计算与应用重点实验室,天津 300350
融合知识图谱的查询扩展模型及其稳定性研究*
郝林雪,张 鹏+,宋大为,候越先
天津大学 天津市认知计算与应用重点实验室,天津 300350
HAO Linxue,ZHANG Peng,SONG Dawei,et al.Research on knowledge graph based query expansion model and its retrieval stability.Journal of Frontiers of Computer Science and Technology,2017,11(1):37-45.
知识图谱;Freebase;查询扩展;有效性;稳定性
1 引言
随着大型结构化语义知识图谱的构建,如Google的Knowledge Graph、微软的Satori等,更多的商业搜索引擎开始将用户查询相关的知识体系和查询文档列表一并展示给用户,以满足用户的信息需求和搜索体验。由于目前大部分Web数据仍以文本形式出现(如Web页面、博客、微博等),如何利用知识图谱中丰富的实体信息提升查询文档列表的质量,也是信息检索领域一个重要的研究方向[1]。
基于外部语料库的查询扩展模型是一种提升检索系统性能的有效途径,其中常用的外部语料库包括半结构化的Wikipedia数据集,以及结构化的Concept-Net和Freebase等知识图谱。文献[1-4]分别研究了Wikipedia、Concept-Net和Freebase等外部语料库对查询扩展模型的影响。文献[2]主要研究了如何基于Wikipedia实现查询扩展模型,其中用到了与伪相关反馈[5]相似的策略,即在Wikipedia中检索查询,将与排序靠前的N篇文档看作与查询相关,并将其作为扩展词来源。故这种扩展方法和伪相关反馈模型有相同的不足,例如当前N篇文档中只有少数文档与查询真正相关时,基于这些文档得到的扩展模型反而会引入噪声,造成查询漂移,对检索结果产生不利影响,从而降低检索系统的性能[5-6]。与Wikipedia的半结构化组织方式不同,Concept-Net和Freebase都是基于图模型构建的知识图谱,其中顶点表示概念或实体,两点之间的边表示两者之间的语义关系(如图1所示)。与文献[3]中用到的Concept-Net相比,Freebase包含更丰富的实体信息,如实体别名、细粒度的分类信息等,并且大部分Web查询由实体(人名、地名等命名实体或者概念性实体)构成,故本文选用Freebase作为外部扩展词来源。另外,基于外部语料库构建的查询扩展模型是一种全局的扩展方法,不依赖于初始检索结果,故Freebase作为查询扩展词来源可在一定程度上稳定检索系统的性能,并减少类似于伪相关反馈给检索系统带来的不利影响[5-6]。文献[1,4]也利用了Freebase进行查询扩展模型的研究,但文献[4]将查询相关的实体处理成单个的扩展词,忽略了实体内部各词项之间的依赖关系。本文则将每个实体看作整体考虑,保留实体内部依赖关系。与文献[1]的不同之处在于,本文借鉴了文献[7]提出的投资组合理论中收益-风险分析方法在信息检索中的应用,研究了如何降低基于知识图谱的查询扩展模型给检索系统带来的查询漂移(query-drift)风险。
Fig.1 What is inside Freebase?图1 Freebase内部结构举例
本文旨在研究基于Freebase的实体以及实体属性信息构建的查询扩展模型对检索系统有效性及稳定性的影响,所提出的扩展模型主要包括以下三部分内容:(1)从Freebase中自动匹配与查询相关实体和实体属性;(2)利用收益-风险分析方法计算并优化属性扩展词的权重;(3)将这些外部扩展信息与查询语言模型结合,构建一个性能相对稳定的查询扩展模型。
本文的实验在两个Web文档集上进行,主要分析了本文所提出的扩展模型对检索系统有效性和稳定性的影响。实验结果表明,基于Freebase的查询扩展模型,与一元语言模型LM相比平均检索性能有6%~15%的提升;与基于伪相关反馈的查询扩展模型RM3相比,有效性和稳定性都有不同程度的提升。总体而言,本文提出的基于知识图谱的查询扩展模型在两个测试数据集上整体性能更优。
2 模型描述
2.1 外部扩展词初始权重计算
给定一个用户查询Q,本文使用相邻查询词组成的子查询匹配实体信息[8],原因是相邻查询词之间存在依赖关系且包含上下文信息,匹配到的实体和用户信息需求更相关[4]。由于Freebase中实体之间,实体与自身属性之间均是以图结构存储的,以某个实体(图中的一个顶点)为起点,广度遍历即可得到与该实体的属性信息。本文将这些相关实体以及实体属性作为查询的外部特征,并计算其与查询的相关性。在计算实体与查询相关性时,考虑了两种因素的影响:一是子查询Qs相对于查询Q的重要性,由两者所包含词项数目的比值来定义;二是子查询与实体En的匹配得分rel(En,Qs)(由Freebase API[8]给出)。则实体En与查询Q的相关性得分定义为:
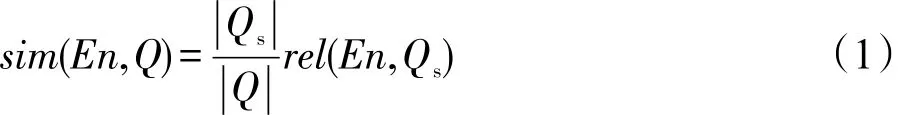
由于Freebase中较为完整地记录了实体的属性信息,但有的属性信息对本文的查询扩展任务没有使用价值,为了减少噪声词的引入,本文只考虑一些常见属性,如实体别名、类别、所属领域等进行查询扩展。将遍历得到属性信息处理成独立词项分布,每个属性词与查询的相似性得分定义如下:
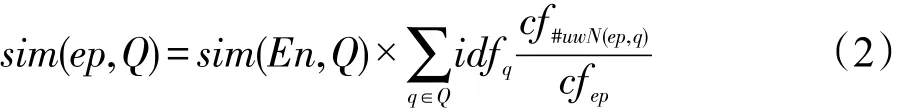
式(2)对属性词权重的计算也考虑了两方面的因素:一是属性词所属的实体相对于查询的权重;二是属性词与查询本身的相关性。在计算时考虑了属性词与各查询词的相关性。在式(2)中,idfq为查询词q的逆文档概率,代表其在查询中的重要性;cfep表示属性词ep在文档集中出现的次数;cf#uwN(ep,q)表示属性词ep和q共现在一个大小为N的窗口中的次数(本文取N为20)。
2.2 基于收益-风险分析方法优化属性词权重
利用式(2)计算外部扩展词初始权重时,只考虑了扩展词与查询的相关性,并假设扩展词之间相互独立,这样存在的问题是按照初始权重排序靠前的扩展词可能只与某些查询词相关,扩展后的检索结果向这些查询词偏移,从而偏离用户的信息需求。本文参考文献[7]提出的投资组合理论中收益-风险分析方法在文档排序上的应用,将整个扩展词列表看成一个整体,然后将外部扩展词权重优化问题建模成投资组合问题来求解。该优化问题中的“投资收益”,是指扩展词与查询的相关性大小,相关性越大,表示收益越大。“投资风险”来源有两种:一是每个扩展词可能带来的查询扩展失败的风险,即相关性收益的不确定性;二是考虑扩展词之间的相互影响,在同时选取这些扩展词可能带来的冗余性风险[9]。
该扩展词权重优化模型可描述如下:设属性扩展词列表中所有扩展词的权重为随机向量(r1,r2,…,rn),其中每个变量的均值为E(ri),即期望收益,由式(2)给出的相似性得分sim(epi,Q)为ri的一个估计值。该随机向量对应的协方差矩阵记为C,由于各随机变量之间不独立,C中的非对角元素cij表示扩展词权重ri和rj的协方差,由第二种风险来源产生,可解释为在epi为扩展词的条件下,再选取epj作为扩展词的冗余性风险;C的对角元素cii代表第一种风险来源。本文参考文献[9],将协方差矩阵C中的元素用式(3)或式(4)来估计:
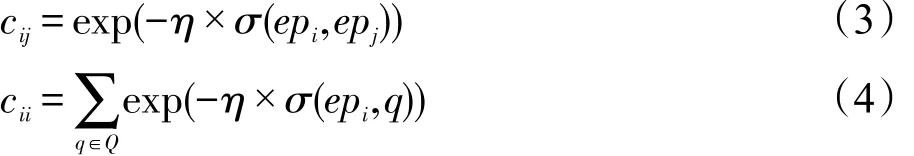
其中,η为归一化因子;σ(epi,epj)表示两个扩展词之间的相似性,本文用Jaccard相似性系数来计算。每个扩展词权重的方差cii则用其与所有查询词的相似度之和定义。
基于以上对扩展词期望收益以及协方差矩阵的说明,本文定义外部扩展词列表的相关性收益E(Rn)为所有扩展词收益的加权平均(如式(5)所示)。wi表示每个扩展词对总收益所贡献的比重,其中wi=1 2i-1,表示与查询Q相似性得分sim(epi,Q)排在第i位的属性扩展词为总收益所贡献的。式(5)中的Var(Rn)定义为扩展词列表中所有扩展词的协方差之和,表示该扩展词列表用来做查询扩展时检索性能存在的风险。
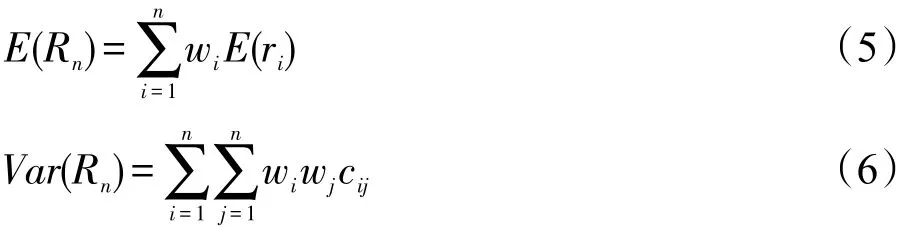
该优化模型的目标为最大化期望收益E(Rn),最小化方差Var(Rn),即最大化函数为On=E(Rn)-bVar(Rn),其中b为风险偏好参数,b>0表示规避风险,本文取b=0.05。在优化模型实现过程中,本文借鉴了文献[7]的序列最大化文档排序得分收益的方法,并对其进行了适当的改进,得到了序列最优化扩展词权重收益的算法,具体优化步骤如下:
(1)按照式(2)计算出的属性词初始权重,选取权重较大的n个扩展词组成候选扩展词集合E;并设已选扩展词集合为S,初始状态为空。
(2)将E中权重最大的扩展词加入S,并将其从E中删除。
(3)将E中其余的扩展词依次加入集合S,第k个加入S的扩展词满足如下条件,该扩展词加入S可以使目标函数的增量最大,即选取一个扩展词使式(7)最大化。式(7)的值也作为扩展词优化后的权重,记为sim′(epk,Q)。
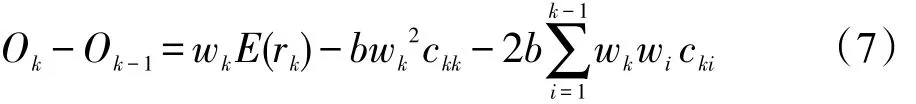
用以上权重优化模型得到的扩展词既考虑了扩展词与查询的相关性,又考虑了降低扩展词之间的冗余以及查询扩展失败的风险。
2.3 外部扩展词与查询语言模型的结合
基于Freebase得到的与查询相关的扩展实体及实体属性词两种加权特征,可作为影响文档与查询相关性得分的因素整合到文档排序函数中:
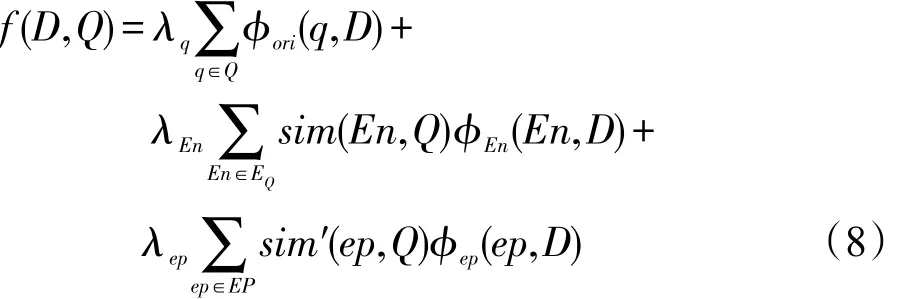
式(8)由三部分组成:第一部分表示原始查询Q与文档D的相似性得分;第二部分表示查询相关的实体EQ与文档D的相似性得分;最后一部分则表示实体属性词集合EP与文档D的相似性得分。sim′(ep,Q)即为基于式(7)优化后的属性扩展词与查询Q的相似性得分。参数λq、λEn和λep用来调节三部分特征在排序函数的权重,且三者和为1。表达式φori(q,D)用来估计查询词q在文档D对应的语言模型中的生成概率,该表达式的计算如下:
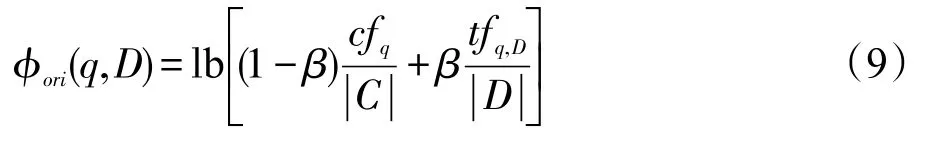
其中,tfq,D和cfq表示查询词q在文档D以及文档集C中的词频;|D|表示文档D的长度;|C|表示文档集C的词项总数;β表示用文档集平滑该生成概率的平滑系数。表达式φEn(En,D)和φep(ep,D)的计算参照式(9)。
3 实验
3.1 实验设置
本文在两个TREC标准数据集WT10G和Clue-Web12B上对所提出的基于知识图谱的查询扩展模型进行了实验。两个数据集的基本情况如表1所示,并且两个数据集都由Web页面组成,文档内容以及文档长度区别较大,属于异构类型的数据集。实验所用到的查询为TREC提供的测试topics的title部分,该部分一般用查询关键词来描述,更符合Web用户的查询习惯。

Table 1 Statistics of two TREC test collections表1 两个TREC测试数据集的统计信息
本文采用了3种策略来验证基于Freebase的外部扩展信息的有效性:(1)取权值最大的NEn个相关实体构建查询扩展模型(对应扩展模型记为KF-En);(2)取权值最大的Nep个实体属性词进行扩展(对应模型记为KF-EP);(3)综合考虑实体和实体属性的影响(对应模型记为KF-En-EP)。
用一元语言模型LM和基于伪相关反馈的查询扩展模型RM3[10]进行了对比实验。实验中所有模型都是基于Indri[11]的语言模型框架实现的,文档集中所有文档和查询均按以下方式进行预处理:根据标准的停用词表去除停用词,然后用Porter Stemmer算法提取词干。
在RM3模型实现过程中,有3个重要的参数需要调整,即初次检索返回的前K(5≤K≤10)篇文档,扩展词个数N(10≤N≤100),以及扩展词与原始查询的插值系数λ(0≤λ≤1)。在每个数据集上,3个参数分别以步长5、10、0.1进行逐步调整,直至找到平均准确率(mean average precision,MAP)最优的参数设置。在调整本文提出的3种基于Freebase的扩展模型的参数时,采用了与RM3模型类似的调参方法。KF-En模型包含两个参数,外部扩展实体的个数NEn(1≤NEn≤5)以及扩展实体与原始查询的插值系数λEn(0≤λEn≤1),两个参数的调整步长分别为1、0.1;KFEP模型中也包含两个参数,外部属性词个数NEP(5≤NEP≤50)及其与原始查询的插值系数λEP(0≤λEP≤1),两个参数的调整步长分别为5、0.1。鉴于4个参数NEn、λEn、NEP和λEP同时在模型KF-En-EP中出现,参数调整策略参考模型KF-En和KF-EP。
3.2 评价指标
本文采用了基于检索返回的前1 000文档平均准确率(MAP)作为模型有效性的评价指标,MAP也是TREC最为常规的检索模型评价指标。由于两个测试数据集均为Web文档集,本文也用了TREC Web Track任务评价时常用的NDCG@20和ERR@20两个评价指标来评价模型的有效性。
在评价模型稳定性时,本文选用了文献[12]提出的Urisk评价方法,2013 TREC Web Track任务将该指标作为模型稳定性评价的重要参考指标[13]。该评价指标在使用时,需要有一个基准模型作为参照,本文选择LM作为基准模型,Urisk定义如下:
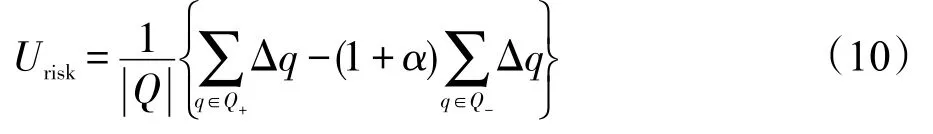
其中,|Q|表示查询个数;Q+表示与基准模型相比,检索性能提升的查询集合;Q-表示与基准模型相比,检索性能降低的查询集合。Δq表示待测模型与基准模型之间的性能差值,对于Q+集合中的查询,Δq>0;对于Q-集合中的查询,Δq<0。α是对性能下降的查询的惩罚系数,α值越大,惩罚力度越大,本文实验中设置α=10。由式(10)可以看出,Urisk越大表示模型越稳定。
另外,本文也采用文献[14-15]提出的一种基于偏差方差分解的评价方法评价了所提出的扩展模型的整体性能。若用平均有效性AP作为单个查询的检索有效性评价指标,该评价方法可用以下公式定义:
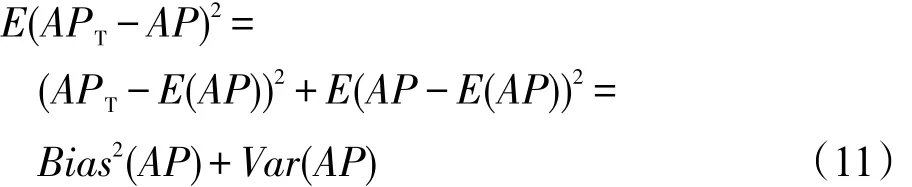
其中,APT表示单个查询的最优性能,本文取APT=1。式(11)表示待评价模型的AP与最优值APT的期望平方误差,该误差项可以分解为偏差方差两部分:偏差Bias2(AP)可用来评价模型有效性,偏差越小表示模型越有效;方差Var(AP)可用来评价模型的稳定性,方差越小模型越稳定,故该评价指标的值越小,模型整体性能越好。
3.3 实验结果分析
表2给出了KF-En、KF-EP、KF-En-EP扩展模型,以及基准模型LM和对比模型RM3在两个测试数据集上的评价结果。在每个数据集上,性能表现最优的模型用粗体标出,4种扩展模型MAP提高的百分比均是相对于基准模型LM而言的。
由表2的实验结果可知,本文提出的3种基于知识图谱的查询扩展模型在两个测试数据集上MAP有6%~15%不等的提升。而相比之下,常用的查询扩展模型RM3在两个数据集上的检索效果不如本文提出的扩展模型,且在ClueWeb12B上性能有所下降。出现该现象的原因是ClueWeb12B的初始检索结果中排在前面的K篇文档与查询相关的很少(LM的MAP较低),从中提取的扩展词造成了查询偏移,从而使检索性能下降,而基于外部知识图谱的查询扩展模型则不会受到初始检索结果的影响。另外,表2也表明本文提出的3种扩展模型的检索性能之间也存在差异,KF-En的检索性能均低于另外两个模型,原因是与查询最为相关的实体个数较少,从而无法很好地扩展查询来更好地表达用户的信息需求。而基于实体属性词的扩展模型则充分挖掘了Freebase中与查询相关的实体属性,故检索性能提升更为显著。
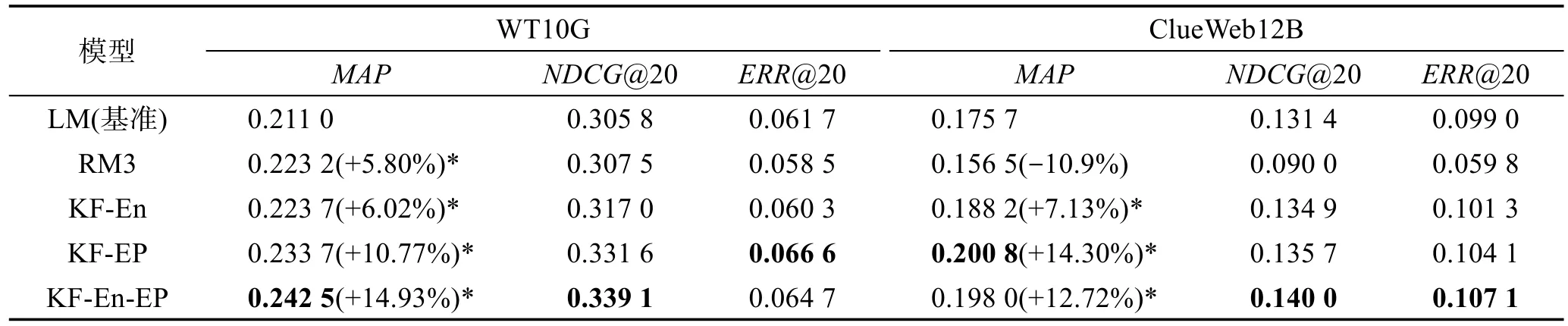
Table 2 Average performance of 5 retrieval models on two test collections表2 5个模型在两个数据集上的平均性能比较
在分析了本文提出的扩展模型有效性相比基准模型和RM3有所提升之后,接着主要分析了扩展模型对检索系统稳定性的影响。表3列出了模型的稳定性评价指标Urisk以及总体性能评价指标Bias2+Var在各个模型上的评价结果。Urisk列中最大值用粗体标出,表示该模型最稳定,Bias2+Var列中最小值用粗体标出,表示该模型的整体性能最优。由表3可知,本文提出的3个扩展模型均表现得比RM3稳定,并且提升了检索系统的有效性。
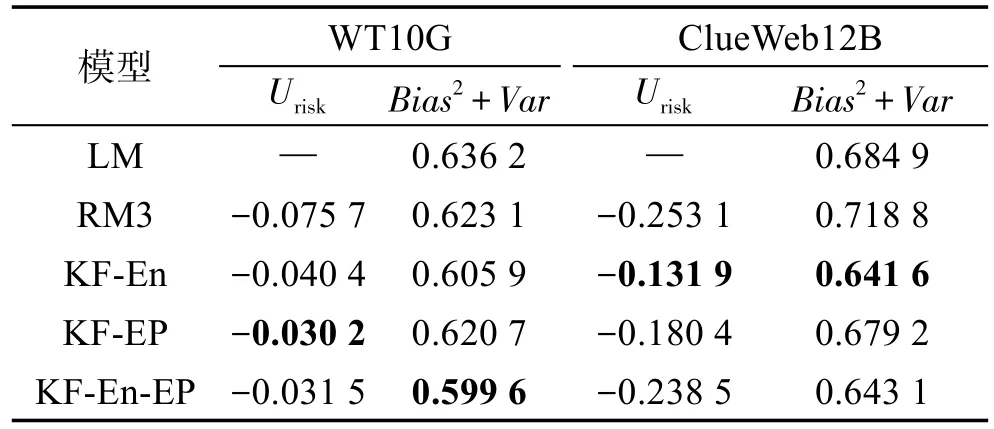
Table 3 Comparison of model stability and overall performance表3 模型的稳定性以及总体性能的比较
最后,本文主要分析了查询相关的实体及属性信息能够提高检索系统稳定性的原因。将数据集WT10G和ClueWeb12B对应的查询按难度大小分成5组,查询的难度参考了LM模型在该查询上的平均准确率AP,AP越小表示查询越难。如图2所示,查询难度从左至右依次降低,最左侧的直方图“0%~20%”表示最难的查询分组上的MAP值,最右侧的柱状图“80%~100%”表示最容易的查询分组上的MAP值。由图2(a)可知,对于数据集WT10G,在最难的查询分组“0%~20%”上,本文提出的3个扩展模型MAP值稍微高于LM和RM3;在较难的查询分组“20%~40%”上,KF-En和KF-En-EP的MAP值显著高于LM和RM3;在难度适中的查询分组“40%~60%”以及“60%~80%”上,KF-En-EP的MAP值高于其他模型,而KFEn和KF-EP的检索效果与RM3相似;在最容易的查询分组“80%~100%”上,RM3检索结果最优。由图2(b)可知,对于数据集ClueWeb12B来说,在前3个较难的查询分组上模型KF-En和KF-En-EP的MAP值高于其他模型;在较简单的查询分组“60%~80%”上,KF-En、KF-EP和KF-En-EP的性能均优于LM和RM3;而在最简单的查询分组“80%~100%”上,KFEn-EP则表现得优于其他模型。综上对不同难度查询分组的分析可知,基于知识图谱的查询扩展模型不仅有利于提升难查询的检索性能,又能减少噪声词的引入来保证简单查询的检索性能不被降低,故可以同时提高检索系统的有效性和稳定性。
Fig.2 MAPof different query subsets on WT10G and ClueWeb12B图2 数据集WT10G和ClueWeb12B上不同难度的查询分组平均性能
4 结束语
本文提出了一种基于知识图谱的查询扩展模型,该模型主要解决了自动匹配与查询相关的实体以及实体属性,并利用收益-风险分析方法计算并优化实体属性词的权重。该方法既考虑了最大化整个属性词列表与查询的相关性收益,又兼顾了最小化该属性词列表可能带来的查询扩展失败的风险。最后将这些外部特征与查询语言模型结合构建性能更加稳定的查询扩展模型。本文实验在两个Web数据集上进行,实验结果表明,本文提出的扩展模型与基准模型LM以及常用扩展模型RM3相比,检索有效性有显著提升;模型稳定性在两个数据集上都优于RM3模型;最后通过对不同难度查询分组的分析可知,本文提出的查询扩展模型对难查询检索性能的提升显著,对简单查询的检索性能影响较小,故可以使检索系统更加稳定。
未来的研究工作主要包括:(1)本文的研究集中在探索Freebase对检索模型有效性和稳定性的影响,后续工作拟在其他外部语料库上验证外部知识对查询扩展的有效性;(2)本文在计算实体与查询的相似度时,只考虑到了查询本身,而用户查询一般以少量的关键词表示,可用的上下文信息较少,下一步工作将考虑融合查询在文档中的上下文信息来更准确地估计实体与查询的相似度。
[1]Dalton J,Dietz L,Allan J.Entity query feature expansion using knowledge base links[C]//Proceedings of the 37th International ACM SIGIR Conference on Research and Development in Information Retrieval,Gold Coast,Queensland,Australia,Jul 6-11,2014.New York:ACM,2014:365-374.
[2]Xu Yang,Jones G J F,Wang Bin.Query dependent pseudorelevance feedback based on Wikipedia[C]//Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval,Boston,USA, Jul 19-23,2009.New York:ACM,2009:59-66.
[3]Kotov A,Zhai Chengxiang.Tapping into knowledge base for concept feedback:leveraging concept net to improve search results for difficult queries[C]//Proceedings of the 5th ACM International Conference on Web Search and Data Mining,Seattle,USA,Feb 8-12,2012.New York:ACM, 2012:403-412.
[4]Pan Dazhao,Zhang Peng,Li Jingfei,et al.Using Dempster-Shafer's evidence theory for query expansion based on freebase knowledge[C]//LNCS 8281:Proceedings of the 9th Asia Information Retrieval Societies Conference,Singapore,Dec 9-11,2013.Berlin,Heidelberg:Springer,2013: 121-132.
[5]Amati G,Carpineto C,Romano G.Query difficulty,robustness,and selective application of query expansion[C]//LNCS 2997:Proceedings of the 26th European Conference on Information Retrieval,Sunderland,UK,Apr 5-7,2004.Ber-lin,Heidelberg:Springer,2004:127-137.
[6]Collins-Thompson K,Callan J.Estimation and use of uncertainty in pseudo-relevance feedback[C]//Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,Amsterdam,The Netherlands,Jul 23-27,2007.New York:ACM, 2007:303-310.
[7]Wang Jun,Zhu Jianhan.Portfolio theory of information retrieval[C]//Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval,Boston,USA,Jul 19-23,2009.New York:ACM, 2009:115-122.
[8]Bollacker K,Evans C,Paritosh P,et al.Freebase:a collaboratively created graph database for structuring human knowledge[C]//Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data,Vancouver,Canada,Jun 10-12,2008.New York:ACM,2008:1247-1250.
[9]Collins-Thompson K.Estimating robust query models with convex optimization[C]//Advances in Neural Information Processing Systems 21:Proceedings of the 22nd Annual Conference on Neural Information Processing Systems,Vancouver,Canada,Dec 8-11,2008:329-336.
[10]Zhai Chengxiang,Lafferty J.Model-based feedback in the language modeling approach to information retrieval[C]// Proceedings of the 10th International Conference on Information and Knowledge Management,Atlanta,USA,Nov 5-10,2001.New York:ACM,2001:403-410.
[11]Strohman T,Metzler D,Turtle H,et al.Indri:a languagemodel based search engine for complex queries[R].University of Massachusetts Amherst,Center for Intelligence Information Retrieval.
[12]Wang Lidan,Bennett P N,Collins-Thompson K.Robust ranking models via risk-sensitive optimization[C]//Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval,Portland,USA,Aug 12-16,2012.NewYork:ACM,2012:761-770. [13]Collins-Thompson K,Bennett P,Diaz F,et al.TREC 2013 Web track guidelines[EB/OL].(2013)[2015-09-28].http:// research.microsoft.com/en-us/projects/trec-web-2013.
[14]Zhang Peng,Song Dawei,Wang Jun,et al.Bias-variance decomposition of IR evaluation[C]//Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval,Dublin,Ireland, Jul 28-Aug 1,2013.New York:ACM,2013:1021-1024.
[15]Zhang Peng,Hao Linxue,Song Dawei,et al.Generalized bias-variance evaluation of TREC participated systems[C]// Proceedings of the 23rd ACM International Conference on Information and Knowledge Management,Shanghai,China, Nov 3-7,2014.New York:ACM,2014:1911-1914.

HAO Linxue was born in 1990.She is an M.S.candidate at Tianjin University.Her research interests include query expansion,information retrieval risk,knowledge base mining and model evaluation,etc.
郝林雪(1990—),女,河南南阳人,天津大学硕士研究生,主要研究领域为查询扩展,信息检索模型风险研究,知识库挖掘,模型评价方法设计等。

ZHANG Peng was born in 1983.He received the Ph.D.degree from Robert Gordon University in 2013.Now he is a lecturer and M.S.supervisor at Tianjin University,and the member of CCF.His research interests include information retrieval,quantum cognitive computing and machine learning,etc.He has published more than 20 papers including journal papers and conference papers.
张鹏(1983—),男,山西高平人,2013年于英国罗伯特戈登大学获得博士学位,现为天津大学计算机学院讲师、硕士生导师,CCF会员,主要研究领域为信息检索,量子认知计算,机器学习等。发表20余篇期刊及会议论文,主持1项国家自然科学基金和1项教育部博士点新教师类基金。

SONG Dawei was born in 1972.He received the Ph.D.degree from Chinese University of Hong Kong in 2000. Now he is a professor and Ph.D.supervisor at Tianjin University,and the member of CCF.His research interests include theory and formal models for context-sensitive information retrieval,multimedia and social media information retrieval,domain-specific information retrieval,user behavior,interaction and cognition in information seeking, text mining and knowledge discovery,etc.He has published more than 100 papers including many top tier international journal papers and conference papers.
宋大为(1972—),男,河北沧州人,2000年于香港中文大学获得博士学位,现为天津大学计算机学院教授、博士生导师,CCF会员,主要研究领域为信息检索理论与模型,多媒体与社会媒体信息检索,特定领域信息检索,信息检索用户交互与认知,文本挖掘与知识发现等。发表学术论文百余篇,主持英国国家工程和物理科学研究基金委员会基金项目4项,参与国家重点基础研究发展计划(973)2项,主持国家自然科学基金项目1项。

HOU Yuexian was born in 1972.He received the Ph.D.degree from Tianjin University in 2001.Now he is a professor and Ph.D.supervisor at Tianjin University,the director of the Institute of Computational Intelligence and Internet Application,Tianjin University,and the senior member of CCF.His research interests include machine learning, information retrieval and natural language processing,etc.He has published more than 50 papers on main international conferences and journals.
候越先(1972—),男,天津人,2001年于天津大学获得博士学位,现为天津大学计算机科学与技术学院教授、博士生导师,天津大学网络智能信息技术研究所主任,中国中文信息处理学会理事,CCF高级会员,主要研究领域为机器学习,信息检索,自然语言处理等。近年来在主要国际学术期刊和会议上发表学术论文50余篇。
Research on Knowledge Graph Based Query Expansion Model and Its Retrieval Stability*
HAO Linxue,ZHANG Peng+,SONG Dawei,HOU Yuexian
Tianjin Key Laboratory of Cognitive Computing andApplication,Tianjin University,Tianjin 300350,China
+Corresponding author:E-mail:pzhang@tju.edu.cn
This paper aims to construct a query expansion model based on query-related entities and their properties in Freebase,which are used to reconstruct the query for better expressing the user's needs.The relevance score between each property term and the query is measured by the risk-reward analysis in portfolio theory,which is expected to maximize the reward of the relevance scores of property terms and minimize the risk of query expansion failure using these property terms.This paper also proposes a method to integrate these entities and associated properties into the language modeling framework for query expansion.In the experiments,the retrieval effectiveness and stability of the query expansion model solely based on Freebase are evaluated on two Web collections,in comparison with the baseline language model LM and the traditional query expansion model based on pseudo relevance feedback RM3.The experimental results show that the expansion model proposed in this paper outperforms baseline LM by 6%~15%in MAP(mean average precision),and it also performs more effectively and stably than RM3.
knowledge graph;Freebase;query expansion;effectiveness;stability
A
:TP391.3
10.3778/j.issn.1673-9418.1511043
*The National Natural Science Foundation of China under Grant Nos.61402324,61272265(国家自然科学基金);the National Basic Research Program of China under Grant Nos.2013CB329304,2014CB744604(国家重点基础研究发展计划(973计划));the Specialized Research Fund for the Doctoral Program of Higher Education of China under Grant No.20130032120044(高等学校博士学科点专项科研基金).
Received 2015-10,Accepted 2015-12.
CNKI网络优先出版:2015-12-03,http://www.cnki.net/kcms/detail/11.5602.TP.20151203.1407.006.html
摘 要:旨在构建一种基于知识图谱Freebase的查询扩展模型,通过从Freebase中抽取与查询相关的若干实体及实体属性作为扩展词来重构查询,从而更好地表达用户的信息需求。在计算扩展词权重时,参考了投资组合理论中收益-风险分析方法,最大化扩展词和查询的相关性收益,同时也最小化扩展词可能带来的查询漂移的风险。最后将查询相关的实体和实体属性作为两种特征和查询语言模型结合实现查询扩展。在两个Web数据集上进行实验,用来检验所提出的扩展模型对检索系统的有效性和稳定性的影响。实验结果表明,提出的查询扩展模型与一元语言模型LM相比,检索结果的平均准确率(mean average precision,MAP)在两个数据集上有6%至15%的显著提升;和基于伪相关反馈的查询扩展模型RM3相比,有效性及稳定性都有不同程度的提升。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
少先队活动(2020年12期)2021-01-14
科学与财富(2019年27期)2019-10-25
电子制作(2019年14期)2019-08-20
自动化学报(2018年2期)2018-04-12
中成药(2017年3期)2017-05-17
电脑爱好者(2017年7期)2017-05-06
领导科学论坛(2016年9期)2016-06-05
