
基于AdaBoost-SVM的葡萄酒品质分类模型优化设计
2017-01-11 10:35卢美静穆天红
陕西科技大学学报 2017年1期
杨 云, 卢美静, 穆天红
(1.陕西科技大学 电气与信息工程学院, 陕西 西安 710021; 2.青海省农牧业市场信息中心,青海 西宁 810008)
基于AdaBoost-SVM的葡萄酒品质分类模型优化设计
杨 云1, 卢美静1, 穆天红2
(1.陕西科技大学 电气与信息工程学院, 陕西 西安 710021; 2.青海省农牧业市场信息中心,青海 西宁 810008)
针对传统葡萄酒品质分类中低品质类葡萄酒样本识别率低的问题,提出一种基于集成支持向量机的葡萄酒品质分类优化算法.首先,通过“一对多”支持向量机实现多分类;其次,把支持向量机作为基分类器,反复训练支持向量机分类样本,通过AdaBoost得到多个支持向量机基分类器组合的强分类器,运用AdaBoost算法动态调整样本权值,适当提高低品质类样本权重,使低品质类中错判的样本代价增大,从而改进不平衡样本分类性能;最后,以Wine Quality数据集为研究对象,建立以多分类器优化集成为核心的葡萄酒品质分类模型.仿真结果表明,与传统的SVM算法相比,所提方法显著提高了低品质类葡萄酒分类精度.
分类; 支持向量机; 集成学习; 葡萄酒品质; 不平衡数据
0 引言
随着我国市场经济的蓬勃发展和人们对葡萄酒消费需求的迅速增加,葡萄酒行业正处于一个高速发展的时期[1].葡萄酒品质一直以来都是消费者以及生产者最关心的问题,尤其是对于中高档的葡萄酒来说,葡萄酒品质高低近乎决定了其价值的高低[2].传统葡萄酒品质分类方法主要通过感官分析法,但这种方法易受到评酒人员嗜好、经验等因素的影响,通常使得评定存在一定主观性和不确定性[3].因此有学者研究基于数据挖掘的葡萄酒品质分类方法.最初,Cortez等[4]提出采用支持向量分类算法建立葡萄酒品质分类模型.之后,徐海涛[5]在Cortez工作基础上进行了优化,提出采用改进的近似支持向量机方法进行葡萄酒品质分类,其目标是改进其分类精度;刘延玲[6]提出基于一种新的Hopfield神经网络分类模型,使得该模型能够在较短收敛时间内实现葡萄酒品质分类.
现有研究虽然能够取得较高分类准确率,但没有考虑样本数据分布不平衡的特点,忽略了低品质类葡萄酒样本分类精度.实际在葡萄酒品质分类过程中,高品质葡萄酒被误判为低品质葡萄酒所产生的成本远小于忽视低品质问题而造成的损失.本文采用与上述文献同样的数据集,充分考虑葡萄酒样本数据分布,以提高低品质类葡萄酒识别率为目标,提出一种基于集成学习改进的支持向量机葡萄酒品质分类优化模型.提取样本数据特征,建立数据分析模型,通过实验验证,该方法可以准确识别葡萄酒品质类别,有效提高低品质葡萄酒分类精度.
1 不平衡数据分类
不平衡数据是指样本类之间呈现不相等的数据分布,其中某些类的样本数远远多于其他类的样本数.通常标准的分类算法是偏向样本数量多的类,没有将数据分布考虑在内并且使用总体精度作为训练目标[7].在最坏的情况下,少样本类会被视为多样本类的异常点而被忽略,从而导致少样本类分类性能下降.
随着集成学习理论体系的不断发展完善,集成学习方法通过使用不同权重加权的投票策略,有效解决了非平衡数据集分类问题[8].对于多类不平衡数据集分类问题,可以通过分解策略将多类分类问题转化为更容易解决的二分类问题[9].文中提出采用一对多支持向量机方法,在一类样本与剩余的多类样本之间构造分类平面,从而达到多类识别的目的.
2 理论基础
2.1 支持向量机原理
支持向量机(Support Vector Machine,SVM)是 Vapnik等提出的一种应用于二类平衡数据集分类的有效算法,其核心思想是基于结构风险最小原理寻找最优分类平面[10].如图1所示,以二元线性可分问题为例,所谓最优分类面,就是能将两类样本点正确分类,且要使两类的分类空隙最大[11].线性分类平面描述如式(1)所示.
ωT·x+b=0,x∈Rd
(1)
式(1)中:ω和b分别表示权重向量和最优超平面偏移.
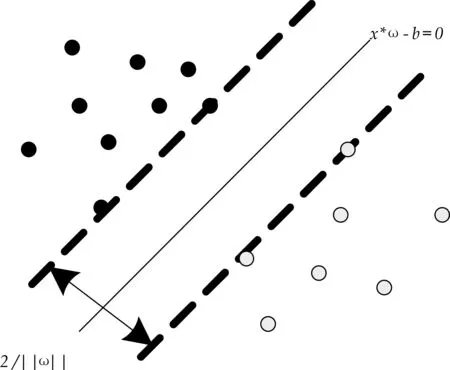
图1 最优分类超平面示意图
对于非线性分类问题,支持向量机通过引入核函数,通过一个非线性函数φ(·)将训练数据集X映射到某个高维线性特征空间,在变换空间求最优分类面,并得到分类器的决策函数[12].采用适当的核函数K(xi,xj),并使K(xi,xj)=φ(xi)·φ(xj),把优化问题中的所有点积运算都运用核函数运算代替,得到对偶最优化问题见式(2).
(2)
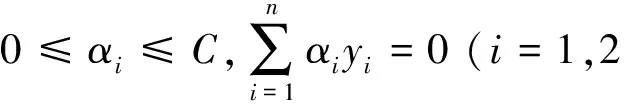
采用拉格朗日乘子法,得到最优判别函数见式(3).
(3)
2.2 AdaBoost算法
集成学习的基本思想是对同一问题通过集成多个基分类器共同决策的机器学习技术,通过调用简单的分类算法,获得多个不同的基分类器,并使用某种策略将基分类器组合成一个强分类器[13].Boosting算法[14]是被广泛使用的集成学习算法,AdaBoost算法[15]是Boosting算法的代表算法,其核心原则是反复修改训练样本集权重分布拟合一系列基分类器.在每次迭代过程中,增大错分类样本权重,减小正确分类样本权重,使得基分类器聚焦在那些很难分的样本上,根据调整权重后的训练样本重新进行学习,这使得分类器在下次迭代过程中更关注被错分的样本,循环迭代此过程,所有弱基分类器的预测通过加权多数投票法,最终得到一个强分类器[16].该方法对非平衡数据集分类有利.
3 AdaBoost-SVM分类算法设计
运用AdaBoost-SVM分类算法进行集成分类器设计,主要有两个问题,一是核函数及参数选择;二是改善标准支持向量机对非平衡数据集分类效果不佳问题.AdaBoost-SVM算法是把基于径向基核函数(RBF)的SVM作为AdaBoost的基分类器,并应用网格搜索法[17]进行参数优化.主要的设计思路:(1)基于随机采样,由原始样本D产生m个训练子集;(2)训练子集由Di(i=1,2,…,m)产生子分类器SVMi;(3)采用加权多数投票法组合得到强分类器.具体实现过程如图2所示.
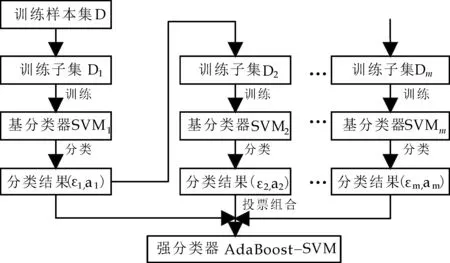
图2 AdaBoost-SVM算法流程图
AdaBoost-SVM具体算法描述如下:
输入:训练集D={(x1,y1),(x2,y2),…,(xm,ym)};基分类器RBFSVM,训练循环次数T.
Step1:初始化.训练集权值分布Dt(i)=1/N,循环次数t=1;
Step2:参数选择.利用网格搜索方法在D上进行十折交叉验证法求得SVM基分类器建模最优参数(C,σ);
Step3:训练基分类器.
Step3.1:Fort=1, 2 …T;
Step3.2:通过具有权值分布D1(i)的训练集得到第t次弱学习器Ht=L(D,Dt);
Step3.3:根据式(4)计算Ht的错误率εt;
(4)
Step3.4:
IF:0<εt<=0.5,根据式(5)计算权重值αt,根据式(6)更新样本权重;
(5)
(6)
t++;跳转至Step3.2继续执行.
ELSE:跳转至步骤4,结束循环.
Step4:构建基分类器的线性组合.训练T轮后得到T组弱分类器Ht(x),由T组弱分类器组合得到强分类器H(X)如式(7)所示.
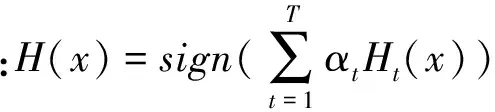
(7)
4 AdaBoost-SVM葡萄酒品质分类算法实现
基于AdaBoost-SVM的葡萄酒品质分类系统如图3所示,包括了分类器设计的核心模块.如上文所述,葡萄酒品质分类属于多类分类问题,文中采用一对余类支持向量机(1-against-the rest SVM)方法将其转换为多个二类分类,在某类样本与剩余多类样本间构造决策平面,从而达到多类分类的目的.如图3所示,AdaBoost-SVM分类器:AdaBoost-SVM1表示低等级(类0)和中(类1)、高(类2)等级间的分类器;AdaBoost-SVM2表示中等级(类1)和高等级(类2)间的分类器.
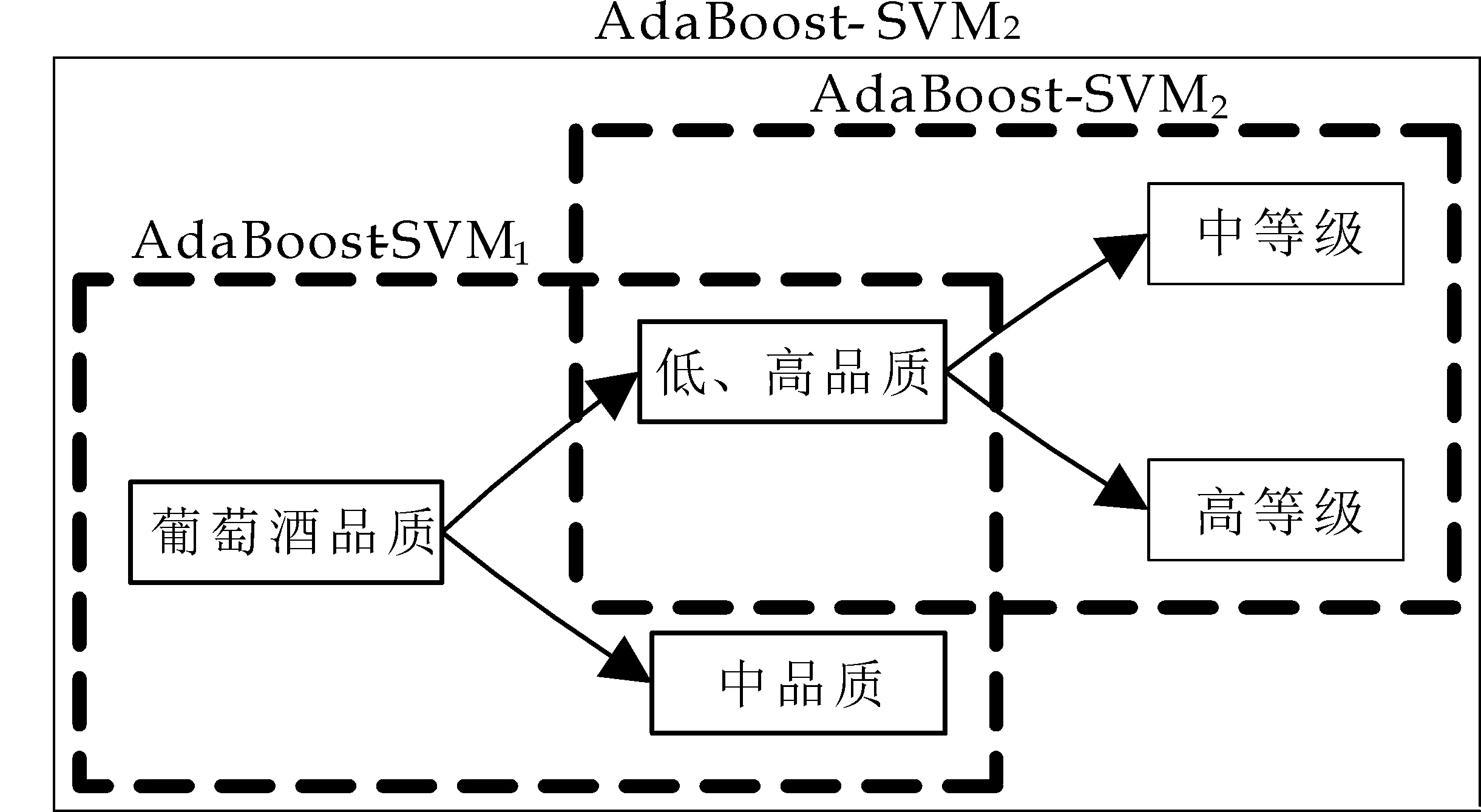
图3 葡萄酒品质分类系统框图
假设第k类样本看做正类(j=0,1,2),而将其余k-1类样本合并看做负类,通过二分SVM方法求出一个决策函数如式(8)所示:
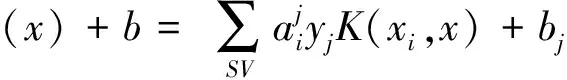
(8)
5 仿真实验
5.1 数据采集及预处理
实验数据来自UCI数据库[18]中的Wine Quality数据集,该数据集共4 898个样本数据,每一个样本由11个理化指标(特征变量)和1个感官指标(目标变量)组成,具体的理化指标统计量如表1所示.感官指标指的是品酒师的感官评价结果,也就是葡萄酒的品质等级,按照十分制的评分标准将葡萄酒分为0(最差)到10(最优),样本数据共7个等级:3~9.由于数据集中有些类别样本数过少,为了方便研究,文中依据感官评价结果将葡萄酒品质分为3个等级,具体等级划分标准以及每个等级的样本分布如表2所示,三类样本的非平衡比例约为1∶20∶6.
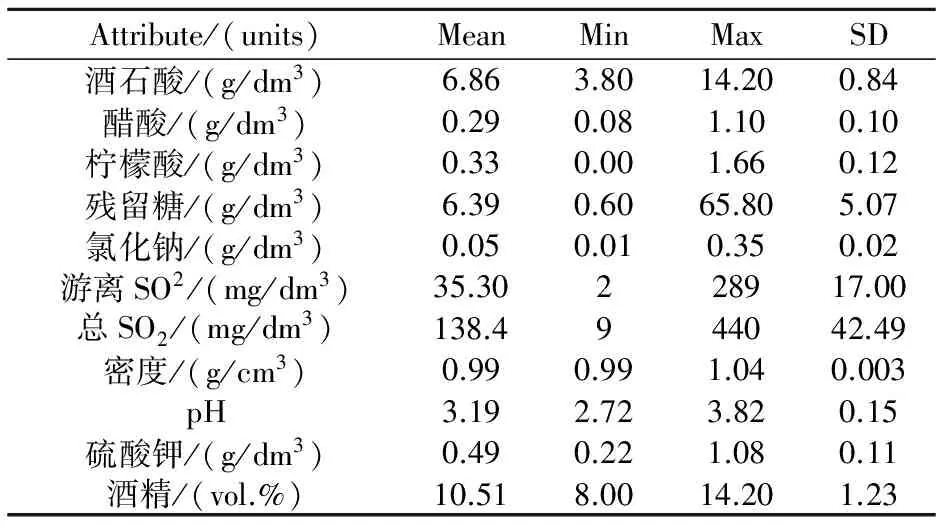
表1 葡萄酒理化指标

表2 等级划分及每个等级的样本分布情况
如表1所示,酒石酸的测量值介于[3.8,14.2] g/dm3之间,而总SO2的测量值则介于[9,400] mg/dm3之间,为了提高最后分类的准确率,对样本数据集进行归一化预处理.本文采用最大最小归一化法,将所有属性归一到[0,1]之间,计算方法见式(9):
(9)
在Python中使用StandardScaler().fit_transform (Data)函数对数据集归一化处理,如某样本酒石酸初始值为7.0,则xnormalization=(7.0-3.80)/(14.20-3.80)=0.31.
5.2 模型构建
经过数据预处理后,根据建模样本数据建立基于AdaBoost-SVM算法的葡萄酒品质分类模型.在建立分类模型过程中,为了防止过拟合,样本数据集分为训练数据集和测试数据集如表3所示.

表3 样本数据
在训练支持向量机的时候,选取高斯径向基核(RBF)作为支持向量机核函数,包括两个核参数:C和σ.选择适当的C和σ,对于支持向量的性能是至关重要的,过低的参数C使决策表面光滑,而过高的C会出现训练样本过拟合现象.文中使用网格搜索法选取有效的参数(C,σ).设C和σ的搜索范围分别为[10-1,103]和[10-5,105],可以尝试5×11= 55种参数组合,选择使得分类器的正确率保持在50%~60%之间的参数组合,经过多次实验当(C,σ)取(1, 0. 01)时训练得到的分类器就可以满足系统算法的需要.
当C=10,σ=0.01时,使用训练数据集训练支持向量机模型.构建2个子分类器,AdaBoost-SVM1和AdaBoost-SVM2.建立模型之后,首先使用训练数据集进行回判,然后使用测试数据集进行测试,分类结果如表4和表5所示.对于训练数据集和测试数据集来说,AdaBoost-SVM1和AdaBoost-SVM2子分类器的分类准确率均达到90%以上.最后,将子分类器的分类结果通过加权多数投票法得到AdaBoost-SVM的分类结果混淆矩阵如表5所示.混淆矩阵对角线上元素表示每个等级类被正确分类的样本数,第一行说明类0的60个样本有44个分类正确,16个错分为类1.最终,测试数据集共有892个样本被正确分类, AdaBoost-SVM分类器取得了91.02%(892/980)的准确率.
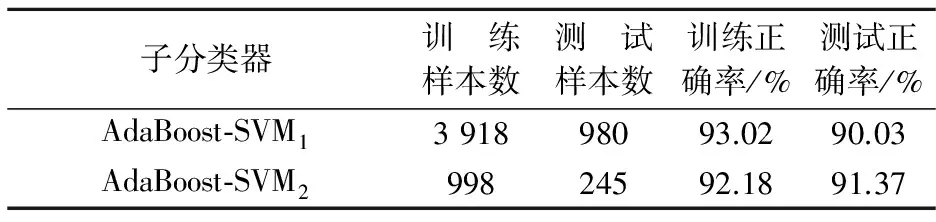
表4 AdaBoost-SVM子分类器分类结果
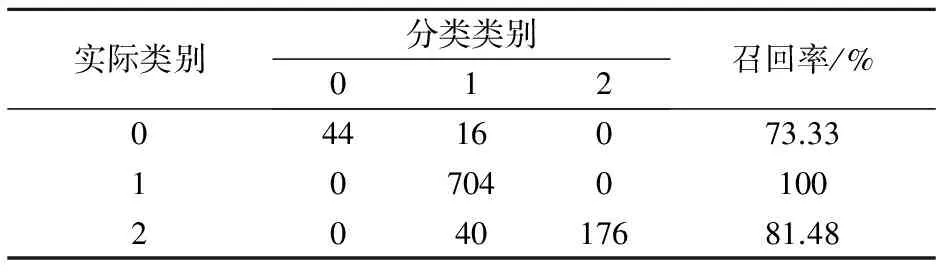
表5 AdaBoost-SVM分类结果混淆矩阵
5.3 对比分析
为了比较AdaBoost-SVM的分类性能,基于同一样本数据集,以及相同的参数值(C,σ),采用标准SVM算法再次进行分类实验,分类结果如表6和表7所示.对比发现,表6和表7基于AdaBoost-SVM算法的分类结果均优于表4和表5基于标准SVM算法的分类结果.并且从实验的结果上可以看出,基于AdaBoost-SVM分类器各等级的分类正确率都有了明显的提升,例如类0的分类准确率由原来的46.67%提高到优化后的73.33%.同理,由表7的混淆矩阵计算可得,最终SVM分类器的分类准确率为85.51%(838/980).
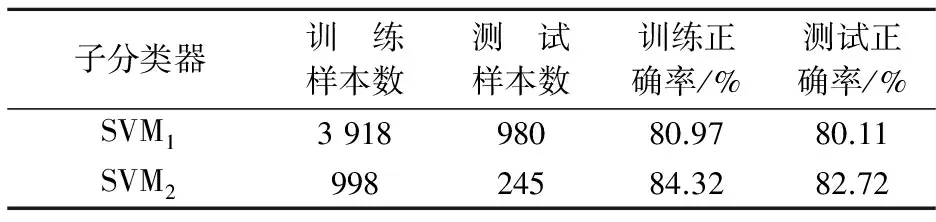
表6 SVM子分类器分类结果
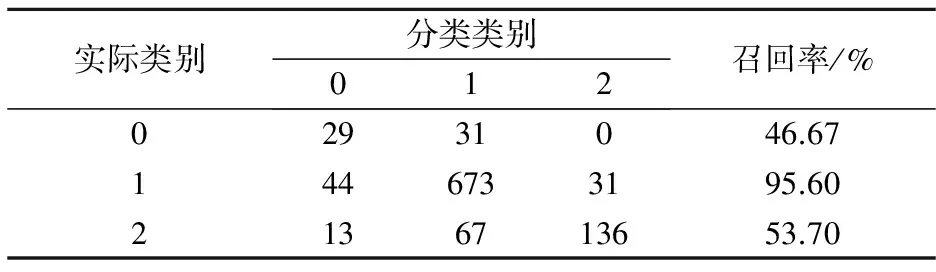
表7 SVM分类器分类结果混淆矩阵
非平衡数据集分类器常用正类覆盖率(True Positive Rate,TPR)和负类覆盖率(False Positive Rate,FPR)来衡量其分类性能,正类覆盖率是指在葡萄酒样本中正确识别出低品质葡萄酒的概率,负类覆盖率是指在非低品质样本中分类结果是否定的比例,分别表示为公式(10)、(11):
TP/(TP+FN)
(10)
FN/(TP+TN)
(11)
式(10)、(11)中,其中TP为正确的肯定、FN为错误的否定、FP为错误的肯定,TN为正确的否定.
以TPR为纵轴,FPR为横轴,绘制标准支持向量机与集成支持向量机的葡萄酒品质分类器的ROC曲线,分别绘制在如图4~5中,曲线下面积记为AUC,AUC越大则模型分类效果越好.当且仅当AUC>0.5 and AUC<=1,分类器才是有价值的.ROC分析结果显示,标准支持向量机AUC约为0.85±0.045,表现为82.80%的TPR和100%的FPR,集成支持向量机AUC约为0.89±0.045,表现为86.72%的TPR和100%的FPR,说明基于AdaBoost-SVM的葡萄酒品质分类器有良好的分类性能.

图4 ROC Curve of SVM
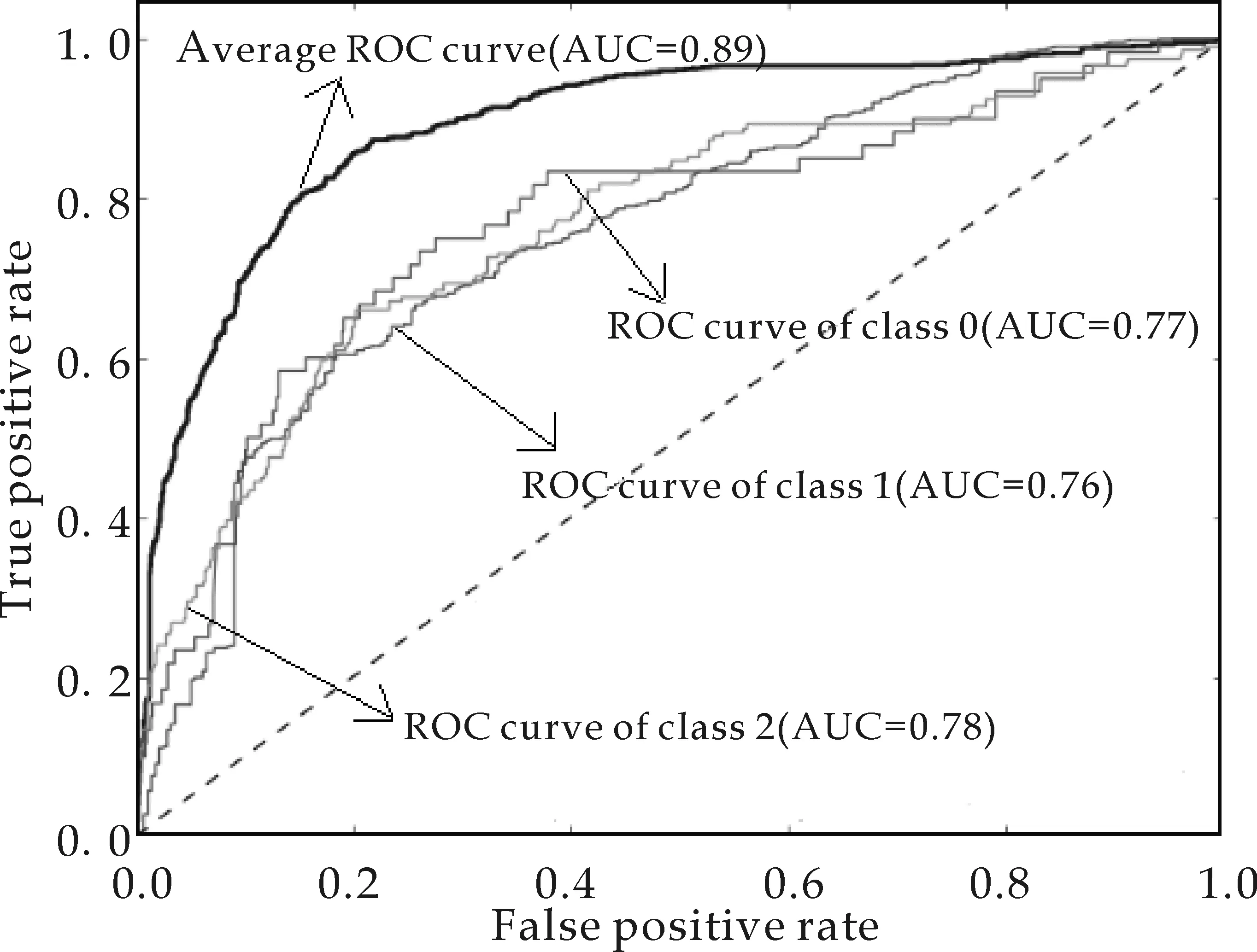
图5 ROC Curve of AdaBoost-SVM
6 结论
基于AdaBoost-SVM分类算法的葡萄酒品质分类模型,克服了现有葡萄酒品质分类方法存在的缺点,有效解决了非平衡葡萄酒样本数据分类效果不佳的问题.文中所提算法与标准SVM算法分类结果进行对比分析,分析结果表明文中算法有效地改善了标准SVM对非平衡数据集的分类效果,使得低品质类葡萄酒样本识别率得到了很大提高的同时,整体样本分类性能以及泛化能力也得到了提升.因此该方法也可以被集成到支持决策系统中,辅助提高酿酒师的酿酒速度以及质量.
[1] 何 瑜.中国葡萄酒产业竞争力研究[D].杨凌:西北农林科技大学,2014.
[2] Baker A K,Ross C F.Sensory evaluation of impact of wine matrix on red wine finish: A preliminary study[J].Sensory Studies,2014,29(2):139-148.
[3] 邵志芳.葡萄酒品质分析方法研究进展[J].中国酿造,2015,34(4):17-20.
[4] Paulo Cortez,Antonio Cerdeira,Fernando Almeida,et al.Modeling wine preferences by data mining from physicochemical properties[J].Decision Support Systems,2009,47(4):547-553.
[5] 徐海涛.改进的近似支持向量机在葡萄酒质量鉴定中的应用[J].安徽农业科学,2010,38(29):16 105-16 106.
[6] 刘延玲.新的Hopfield神经网络分类器在葡萄酒质量评价中的应用[J].价值工程,2012,35(2):181-182.
[7] Jose A.Seas,Bartosz Krawczyk, Michal Wozniak.Analyzing the oversampling of different classes and types of examples in multi-class imbalanced datasets[J].Pattern Recognition,2016,3(12): 164-178.
[8] 黄久玲.面向失衡数据集的集成学习分类方法及其应用研究[D].黑龙江:哈尔滨理工大学,2015.
[9] Zhong liang Zhang, Bartosz Krawczyk,Salvador Garcia,et al.Empowering one-vs-one decomposition with ensemble learning for multi-class imbalanced[J].Knowledge-Based Systems,2016,5(48):251-263.
[10] 顾燕萍,赵文杰,吴占松.最小二乘支持向量机鲁棒回归算法研究[J].清华大学学报(自然科学版),2015,55(4):396-402.
[11] 袁兴梅,杨 明,杨 杨.一种面向不平衡数据的结构化SVM 集成分类器[J].模式识别与人工智能,2013,26(3):315-320.
[12] 吕 锋,李 翔,杜文霞.基于MultiBoost的集成支持向量机分类方法及其应用[J].控制与决策,2015,30(1):81-85.
[13] 李 勇,刘战东,张海军.不平衡数据的集成分类算法综述[J].计算机应用研究,2014,31(5):1 287-1 291.
[14] 李秋洁,茅耀斌.基于数据重平衡的AUC优化Boosting算法[J].自动化学报,2013,39(9):1 467-1 475.
[15] Ebenezer Owusu,Yong Zhao Zhan,Qi Rong Mao. An SVM-adaBoost-based face detection system[J].Journal of Experimental & Theoretical Artificial Intelligence,2014,26(4):477-491.
[16] 李 垒,任越美.基于改进AdaBoost集成学习的空间目标识别[J].计算机系统应用,2015,32(8):202-205.
[17] 魏 峻.一种有效的支持向量机参数优化算法[J].计算机技术与发展,2015,25(12):97-100,104.
[18] Paulo Cortez.Center for machine learning and intelligent systems[DB/OL].http://archive.ics.uci.edu/ml/datasets/Wine+Quality,2009-10-07.
【责任编辑:陈 佳】
Optimal design of wine quality classification model based on AdaBoost-SVM
YANG Yun1, LU Mei-jing1, MU Tian-hong2
(1.College of Electrical and Information Engineering, Shaanxi University of Science & Technology, Xi′an 710021,China; 2.Qinghai Agriculture and Animal Husbandry Market Information Center, Xining 810008, China)
Focused on the issue that traditional classification algorithms for wine quality classification have a low recognition rate to low-quality wines,an optimization algorithm based on ensemble Support Vector Machine (SVM) was proposed. Firstly,muti-class was accomplished by 1-against-the rest SVM;Secondly,SVM was repeatedly trained as weaker classifier and a strong classifier was gotten by grouping a number of base classifiers based on SVM.The sample weight were dynamically adjusted by using AdaBoost algorithm,the sample weight of low quality were appropriately increased,and then the cost of misjudge samples was also increased for improving classification performance of unbalanced datasets;Finally, the wine quality datasets of UCI database was taken as research object,the classification model of wines quality was established that using muti-classifiers optimal integration as the core.The simulation results show that compared with the standard SVM algorithm, classification accuracy of low quality wine was significantly improved based on AdaBoost-SVM.
classification; support vector machine; ensemble learning; wine quality; unbalanced data
2016-08-19
陕西省科技厅社会发展科技攻关计划项目(2015SF277,2016SF-444); 陕西省科技厅科学技术研究发展计划项目(2014K15-03V06); 西安市科技计划项目(NC1403(2),NC1319(1))
杨 云(1965-),女,山东青岛人,教授,博士,研究方向:嵌入式应用、材料计算机应用
1000-5811(2017)01-0178-05
TP391
A
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
基层中医药(2021年3期)2021-11-22
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
收藏界(2018年3期)2018-10-10
计算机应用(2017年4期)2017-06-27
中国商界(2017年4期)2017-05-17
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
